从小红书上爬取评论,但是目前还不能完全爬取子评论,使用GPT没能解决这个问题。
后续博主可能会改进。或者如果你懂的话,可以在博主代码基础上改进。
需要安装nodejs软件,部署环境变量。博主是在pycharm中运行的。
代码无套路获取。自行修改参数(中文在代码里标记了)即可。
java
var http = require('http');
var https = require('https');
var _ = require('lodash');
const XLSX = require('xlsx'); // 引入 xlsx 库
const path = require('path');
// API 请求配置
const options = {
hostname: 'edith.xiaohongshu.com',
port: 443,
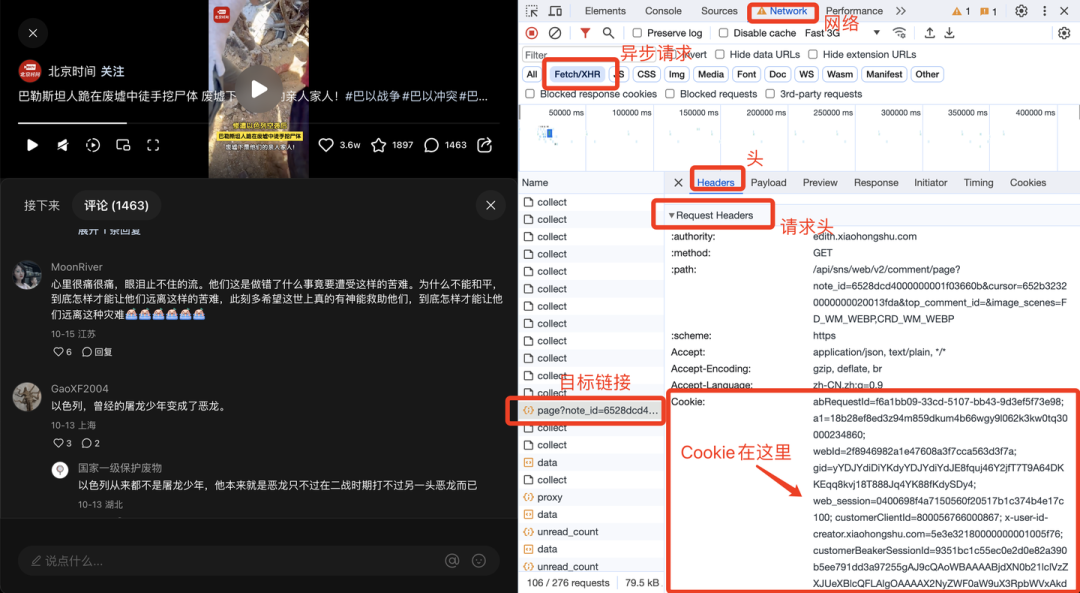
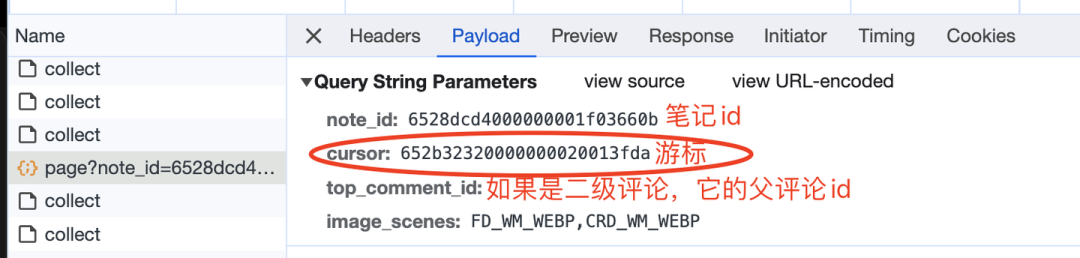
path: '/api/sns/web/v2/comment/page?note_id=你要爬取的笔记id&cursor=&top_comment_id=&image_formats=jpg,webp,avif',
method: 'GET',
headers: {
'Cookie': '你的cookie'
}
};
https.get(options, (resp) => {
let data = '';
resp.on("data", (chunk) => {
data += chunk;
});
resp.on('end', () => {
console.log('Response Data:', data); // Print the raw response
try {
const jsonResponse = JSON.parse(data);
// Check if the response contains the expected data structure
if (jsonResponse.data && jsonResponse.data.comments) {
const records = [];
let commentIdCounter = 1; // Initialize a counter for parent comment IDs
// Process parent comments
jsonResponse.data.comments.forEach(item => {
const parentComment = {
comment_id: commentIdCounter++, // Assign unique ID for parent comments
nickname: item.user_info && item.user_info.nickname ? item.user_info.nickname : 'No Nickname',
content: item.content || '',
url: item.pictures?.[0]?.url || '', // First image URL
parent_comment_id: 'Parent Comment', // Mark parent comments as 'Parent Comment'
};
records.push(parentComment);
// Process sub-comments and add indentation to show hierarchy
if (item.sub_comments && item.sub_comments.length > 0) {
item.sub_comments.forEach(subItem => {
const subComment = {
comment_id: commentIdCounter++, // Assign unique ID for sub-comments
nickname: subItem.user_info && subItem.user_info.nickname ? subItem.user_info.nickname : 'No Nickname',
content: ' ' + (subItem.content || ''), // Indent to show it's a sub-comment
url: subItem.pictures?.[0]?.url || '', // First image URL
parent_comment_id: parentComment.comment_id // Link sub-comment to parent comment
};
records.push(subComment);
});
}
});
// Sort records by the original order (comment_id) or creation time
records.sort((a, b) => a.comment_id - b.comment_id);
// Create a new workbook and add a sheet
const wb = XLSX.utils.book_new();
const ws = XLSX.utils.json_to_sheet(records);
// Add the sheet to the workbook
XLSX.utils.book_append_sheet(wb, ws, 'Comments');
// Save the workbook as an XLSX file
const filePath = path.join(__dirname, 'comments_with_parent_child_hierarchy.xlsx');
XLSX.writeFile(wb, filePath);
console.log('The XLSX file was written successfully at:', filePath);
} else {
console.error('No comments data found or data structure is incorrect');
}
} catch (error) {
console.error('Error parsing response data:', error);
}
});
}).on('error', (err) => {
console.error('Request failed:', err);
});