本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛中的演讲,演讲嘉宾:王丁丁,工业互联网数据库专家,PostgreSQL ACE。
本文将从以下五个方向展开:
- 参数调优基础
- 性能优化进阶
- 架构设计实践
- AI 诊断工具链
- 未来方向
两个场景
场景一:数据库突然变慢了,我们该怎么办?
在日常的应用中,我们有时会发现,数据库突然变慢了。遇到这种问题,我们该怎么办?上一体机?换数据库?换硬件换架构?但通常很多应用跟数据库之间是兼容的,做迁移、升级或替换,工作量是特别大的。所以以上方式都不是很好的方式。那么,我们就要从优化方向去做一些相关的工作。
我总结了以下 6 个方向:
- 业务层面
- 系统资源不足
- 系统内核参数配置不合理
- 并发问题
- 数据库参数配置不合理
- 慢 SQL
场景二:Oracle 迁移到 PostgreSQL 的迁移后性能如何保障?
去年我们做了一次边缘系统的迁移。虽然通过 OGG 工具可以平滑的将 Oracle 迁移到 PostgreSQL,但迁移完成之后出现很多问题,比如 SQL 语句兼容性、存储过程和触发器、性能优化、应用程序接口以及测试与验证。
通过以上两个场景,我们可以看到,调优占比很重。
参数调优基础
PostgreSQL 参数调优需从核心资源分配、I/O 优化、并发控制、维护机制四大维度切入,结合行业实践经验,以下是具体分类及优化优势详解:
1. 内存的调优
核心:平衡 OS 缓存与 PG 内存

以上参数都涉及到 OS 的缓存与 PostgreSQL 的内存。所以,内存调优的核心就是平衡 OS 的缓存与 PostgreSQL 的内存:
- 避免 shared_buffers 超过内存 80%(需保留空间给 OS 文件缓存)
- 高并发时 work_mem 按连接数动态计算(例:总内存 / (max_connections * 2))
2. WAL 与持久化调优
核心:吞吐 vs. 安全权衡

这里有两个参数,我们要注意:
fsync:该参数涉及到事务提交之后落盘的机制,将该参数设置为 on 时,就可以保证每次事务提交之后立即落盘,而不是缓存在 OS 层。synchronous_commit:该参数与主备相关,控制事务提交确认时机,其作用 是定义事务提交成功返回客户端的时机,决定是否等待 WAL 日志持久化。
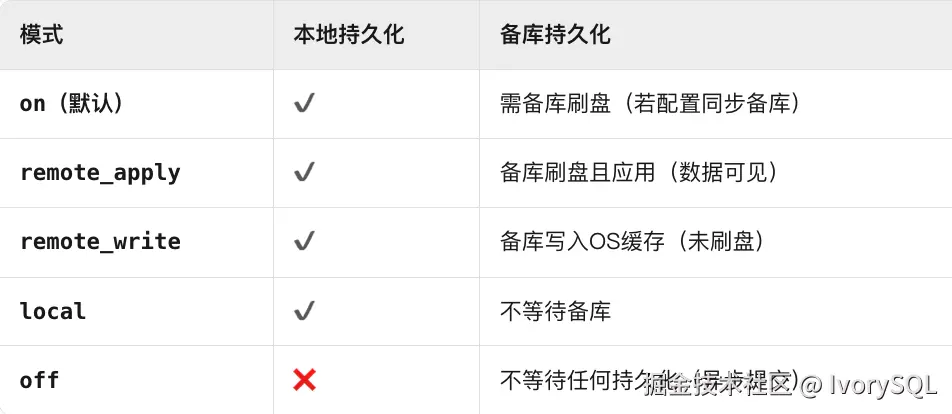
但是参数的设置是分场景的,不同的场景,参数的设置有所差异:
- ⾦融系统保持
fsync=on + synchronous_commit=on - 物联⽹⽇志处理可设
fsync=off + synchronous_commit=off
3. 并发与连接调优
核⼼:避免连接⻛暴
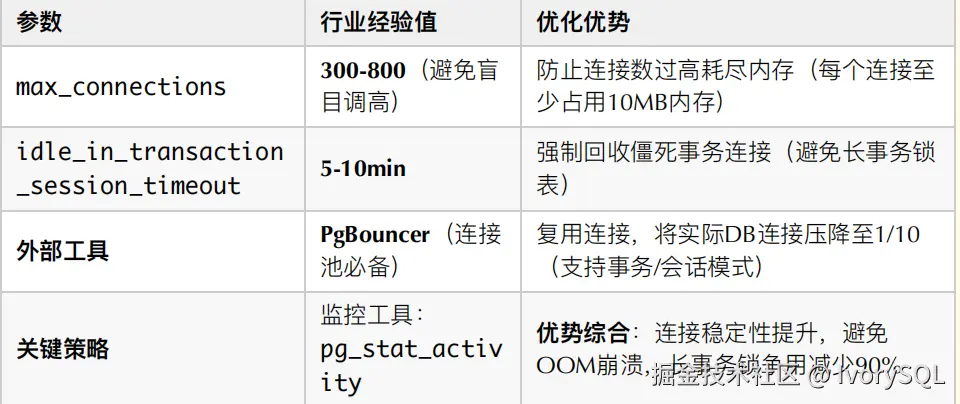
PostgreSQL 在处理应用连接时,会通过主进程为每个连接分配一个服务器进程,因此涉及大量并发连接管理。我们通常建议使用连接池来优化,比如常用的 PgBouncer,或在高可用架构中常用的 Pgpool-II。这些工具能有效降低连接压力。
具体来说,连接池涉及几个关键参数:首先是最大连接数,其次是会话(session)的超时时间(timeout)和事务(transaction)的回收机制。建议在生产环境中开启强制回收空闲或"僵死"连接的功能,以拦截慢 SQL,为后续性能调优提供依据。
4. Autovacuum 调优
核⼼:平衡清理效率与性能影响
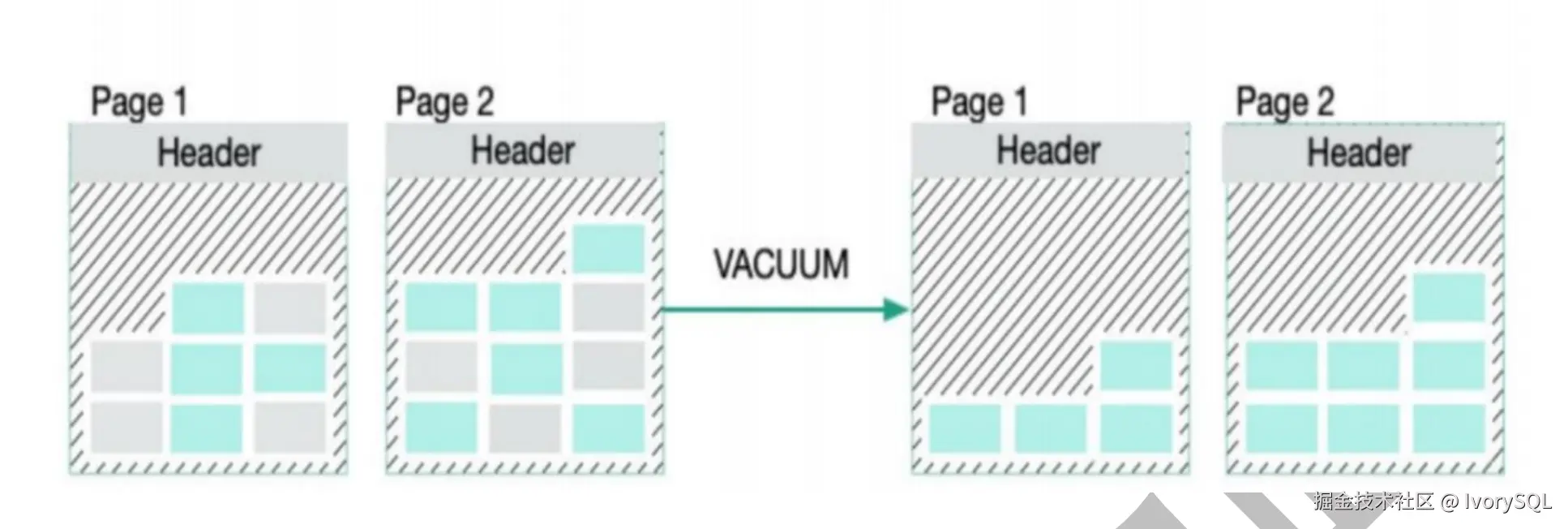
在数据页之间,元组(tuple)经过 DML 操作后会产生死元组(dead tuple)。通过 VACUUM 操作,这些死元组会被清理并重排页面。这是我们讨论的第一个机制------普通 VACUUM。
第二个机制是 VACUUM FULL,它会强制回收存储空间,力度更大。相关参数包括: 
- 大表膨胀时建议停机 VACUUM FULL
- 监控
n_dead_tup > 10000的表⽴即触发清理
这些参数支持后台自动 VACUUM 任务的优化,提升数据库性能。
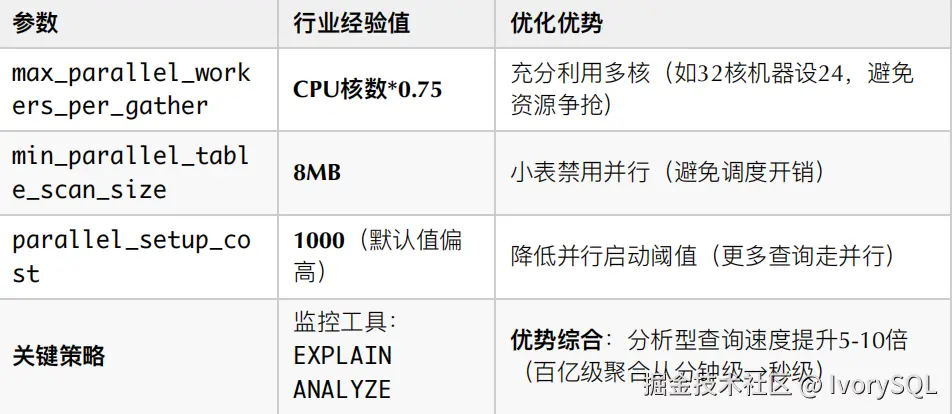
5. 查询并⾏化调优
核⼼:OLAP 场景核⼼加速点
通过系统化调参,可达成以下⽣产级收益:
- 吞吐量提升:OLTP 场景 TPS 增⻓(内存+WAL 优化)
- 延迟降低:查询延迟下降(连接池+并⾏查询)
- 稳定性增强:消除周期性 I/O ⻛暴(检查点+Autovacuum 调优)
- 资源利⽤率优化:CPU/内存/磁盘 I/O 均衡利⽤,避免单点瓶颈
性能优化进阶
1. 获取执行计划
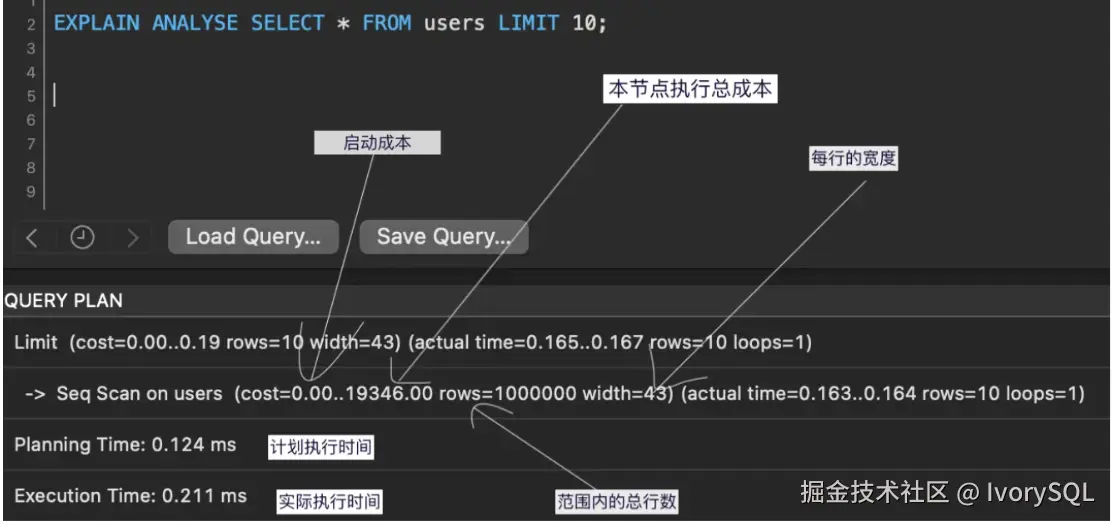
通过 explain analyze 执行 SQL 语句。

执行是由内而外、从上到下进行的:
- 看关键指标,比如 Disk(磁盘)、Memory(内存)
- 看 actual time
- 查看表的扫描方式、表的连接方式、索引等是否使用正确
- 估算的 cost 和 rows 是否准确
在 PostgreSQL 中,cost 具有特殊性,它包括启动成本和总成本。启动成本是返回第一行所需时间,总成本则是处理所有行的总时间,两者类似。
此外,还有一个参数宽度,表示每次扫描后每行的平均宽度。紧接着是 actual time,它有两个值:第一个值是返回第一行耗费的时间,第二个值是返回所有数据耗费的时间,反映了从开始到结束的整个执行过程。
另一个参数 loops 表示执行次数,即数据扫描完成后需要重复的次数。
向下看,可以看到表的连接方式,例如 Hash Join,类似于其他数据库的技术。更下方显示规划时间和执行时间,总时间(规划时间 + 执行时间)是整个查询的耗时。
要查看执行计划,还有其他方式,比如:
- EXPLAIN (ANALYSE,BUFFERS) SELECT _ FROM users LIMIT 10 OFFSET 500;
- EXPLAIN (ANALYSE,BUFFERS,VERBOSE) SELECT _ FROM users LIMIT 10 OFFSET 500;
2. 成本因子
接下来,我们来看 PostgreSQL 中 cost 的计算方式。成本是查询优化的核心,以下通过一个简单案例说明成本的估算过程。
PostgreSQL 使用初始化参数和统计信息计算成本。这些参数包括元组数和页面配置,存储在 pg_class 数据字典中。通过特定公式结合这些数据,得出估算成本值。这种估算对优化查询有重要作用。
需要注意的是,这些初始因子并非固定。随系统数据量增长或性能波动,需适时调整这些参数,否则估算的 cost 值可能不准确。与 Oracle 相比,Oracle 更依赖统计信息,而 PostgreSQL 除统计信息外,还需根据实际环境调整初始因子,这是其 cost 计算的独特之处。

3. 使用合适的表扫描方式
接下来,我们需要掌握合适的表扫描方式。常见的包括顺序扫描(Parallel Seq Scan)、多索引扫描(Index Scan)和位图扫描(Bitmap Index Scan、Bitmap Heap Scan)。这些扫描方式在执行计划中反映其正确性,需根据情况进行调整。
| 扫描方式简称 | 扫描方式说明 |
|---|---|
| Seq Scan | 顺序扫描整个对象 |
| Parallel Seq Scan | 采用并行方式顺序扫描整个对象 |
| Index Scan | 采用离散读的方式,利用索引访问某个对象 |
| Index Only Scan | 仅通过索引,不访问表快速访问某个对象 |
| Bitmap Index Scan | 通过多个索引扫描后形成位图找到符合条件的数据 |
| Bitmap Heap Scan | 往往跟随 bitmap index scan,使用该扫描生成的位图访问对象 |

从执行计划中可见,此例使用了并行扫描(Parallel Seq Scan),并行耗费的 cost 值也清晰显示。当系统资源出现瓶颈时,并行可以有效提升性能。
然而,需注意近期案例:某数据仓库上线一体机(使用 Oracle 高端配置),但性能仍慢。分析发现,业务端过度使用了并行(包括跨节点和单节点并行),试图提升速度。然而,若并行设置不当,大量资源占用(如 I/O)可能反而造成瓶颈,而非硬件问题,这是第三点需要关注的关键。
4. 使用合理的索引


5. 使用正确的表连接方式
检查执行计划中表连接方式是否正确,与表间关联密切相关。以下是常见连接方式:
Nested Loop Join:小表作为驱动表,被驱动表有索引,返回结果集较大。Hash Join:小表用于构建哈希表,存入内存进行哈希运算,不依赖索引,但会占用较多内存。Merge Join:将表数据排序并合并,适合缓存较大记录,能显著降低内存占用。
| 类别 | Nested Loop | Hash Join | Merge Join |
|---|---|---|---|
| 使用条件 | 小表作为驱动表 被驱动表有索引 | 小表用于构造 hash 桶 Hash Join 不依赖于索引 | 小表作为驱动表 适用于很大的表 Join |
| 优点 | 当有高选择性索引时,效率比较高。 | 当缺乏索引或者索引条件模糊时,Hash Join 比 Nested Loop 有效。通常比 Merge Join 快。 | 与 Hash Join 需要将整个构建表加载到内存不同,Merge Join 在合并阶段采用流式处理,每次仅需缓存当前比较的记录,大幅降低内存占用 |
| 缺点 | 返回的结果集大,效率低。 | 需要大量内存。 | 所有表都需要排序。 |

执行计划显示,表连接方式是否正确直接影响性能。若不正确,会导致性能瓶颈。例如,之前同事常使用 WITH AS 构造子查询,逻辑虽简洁,但可能导致连接方式失衡。调整后移除 WITH AS,表连接恢复正确,性能显著提升。因此,执行计划中表的关联方式是决定性能优劣的关键。
6. pg_profile
pg_profile 的工作方式类似于 Oracle 的 AWR(Automatic Workload Repository),在指定时间间隔内生成快照,并通过 HTML 报告展示这些快照之间的统计数据差异,从而实现深入的性能分析和优化。
与 Oracle 不同,pg_profile 需手动配置定时任务,可在操作系统或数据库自带调度中设置,而非简单开关控制。
通过报告分析性能指标是关键。我近期利用脚本生成了 HTML 巡检报告(可关注公众号"IT 邦德"获取),并设置每日定时任务运行。报告生成后,性能数据会存入知识库,利用 AI 分析找出问题点,无需额外安装,执行后直接输出 HTML 格式。
建议大家学会解读报告并定期进行巡检。这些数据为后续性能优化提供支撑,优化需以数据为依据。这是性能进阶的关键内容。
架构设计实践
1. 高可用场景
高可用作为业务的支撑,设计的是否合理,决定了性能的优劣。
高可用方案目标:
- 保证业务连续性:支持
7*24*365业务运行 - 系统高效,稳定可靠
- 负载均衡,实现容灾
- 部署简单:简化维护和管理
- 性价比高,实惠好用
2. 分层架构优化
-
连接池配置方案
针对高并发场景可通过连接池技术优化数据库连接管理,合理配置连接数能有效提升系统响应速度和资源利用率。
-
读写分离实现
读写分离架构通过将查询请求分发到只读副本,显著降低主库负载压力并提高整体查询吞吐量。
-
缓存策略设计
多级缓存策略结合本地缓存与分布式缓存机制,可有效减少数据库直接访问频率,加速热点数据读取效率。
3. 冷热数据分离
随着企业数据量激增,存储需求日益增加,但高端存储如闪存成本高昂,且企业常利旧现有硬件(如惠普设备),因此冷热数据分离至关重要。
冷热数据分离是指将归档数据或历史备份等低频访问数据置于低成本、高容量存储中,作为缓冲;而高频访问数据保留在性能较高的存储中。此外,分区表可有效提升性能,减轻查询压力。表空间管理也需关注,Oracle 在此领域成熟,PostgreSQL 同样建议优化表空间配置以提升效率。
AI 诊断工具链
智能运维 RAG
目前我们在使用 Dify,搭建自己的知识库,通过其后台连接生产库的数据,做交互式 SQL 生成及智能体等等。
-
结构化输出控制
结构化输出控制是 Prompt 工程中的重要实践。要求 LLM 以 JSON 格式返回答案,可以方便前端进行解析。在 Dify 中,我们可以直接渲染 JSON 格式的答案,这大大简化了开发过程。
-
多轮对话上下文管理
在多轮对话中,上下文管理至关重要。在 Dify 的系统提示中添加对话历史变量,可以有效地管理对话历史。这需要开启会话存储功能,以便在对话过程中持续跟踪用户的问题和系统的回答。
-
Ollama 模型量化
Ollama 模型量化是一种有效的性能优化方法。通过下载量化版的模型,如 qwen:7b- q4_0,可以显著减少内存占用。例如,7B 模型从 28GB 降至 8GB,这对于内存受限的环境非常有帮助。
-
流式输出实现
流式输出是一种提升用户体验的技术。在 Dify 中启用流式响应,可以边生成边返回答案,这对于实时性要求高的应用场景非常有利。需要注意的是,流式输出需要模型和客户端的支持。
未来方向
1. AI 原生数据库与多模

未来数据库发展的方向在于原生 AI 数据库和多模支持,这将是满足业务需求的关键趋势。例如,后期可实现自动调优和异常预测模型,并推动数据库向高度自愈和自治方向发展。PostgreSQL 以其丰富的多模功能脱颖而出,通过插件实现即插即用。尽管安装包较小,其多模化需求满足能力尤为出色,未来潜力无限。
2. 智能运维体系
AI 赋能运维,实时监控预警,自动化处理故障,优化资源,提升效率。

其框架分为四部分:
- 监控管理:整合开源工具(如 Grafana)及 X 平台,统一管理工厂端硬件和数据库监控至集团平台。
- 流程管理:确保故障出现后形成闭环,包括故障报告、优化报告及问题解决。
- 资产管理:有效跟踪和管理资产。
- 日志管理:优化日志处理。
通过以上维度,结合 AI 大模型(如 LLM 和 RAG),为运维人员提供智能辅助,堪称"AI 小助理"。