本文聚焦《LevelDB 辅助工具类》,系统梳理其核心组件。开篇解析 Bloom Filter 在数据检索中的高效过滤机制,继而阐释 LRU 缓存对提升访问性能的关键作用。同时涵盖其他实用工具类的功能特性,辅以参考资料佐证。通过多维度剖析,为理解 LevelDB 底层优化逻辑提供清晰指引。
Bloom Filter
代码位于:util/bloom.cc
接口位于:include/leveldb/filter_policy.h
接口中的三个函数:
 构造函数
构造函数 这里的
这里的k_是哈希函数的个数,固定为 1 - 30
bits_per_key 表示每个元素使用的 位个数
布隆过滤器的存储空间大小m,哈希函数个数k和元素总的个数n之间存在如下一个计算公式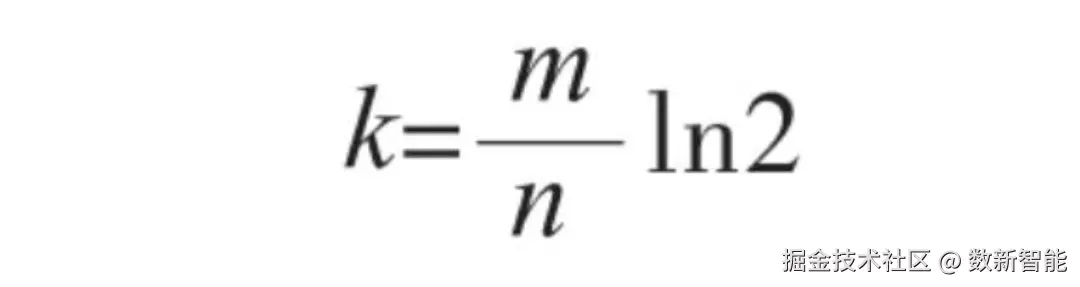 创建 过滤器
创建 过滤器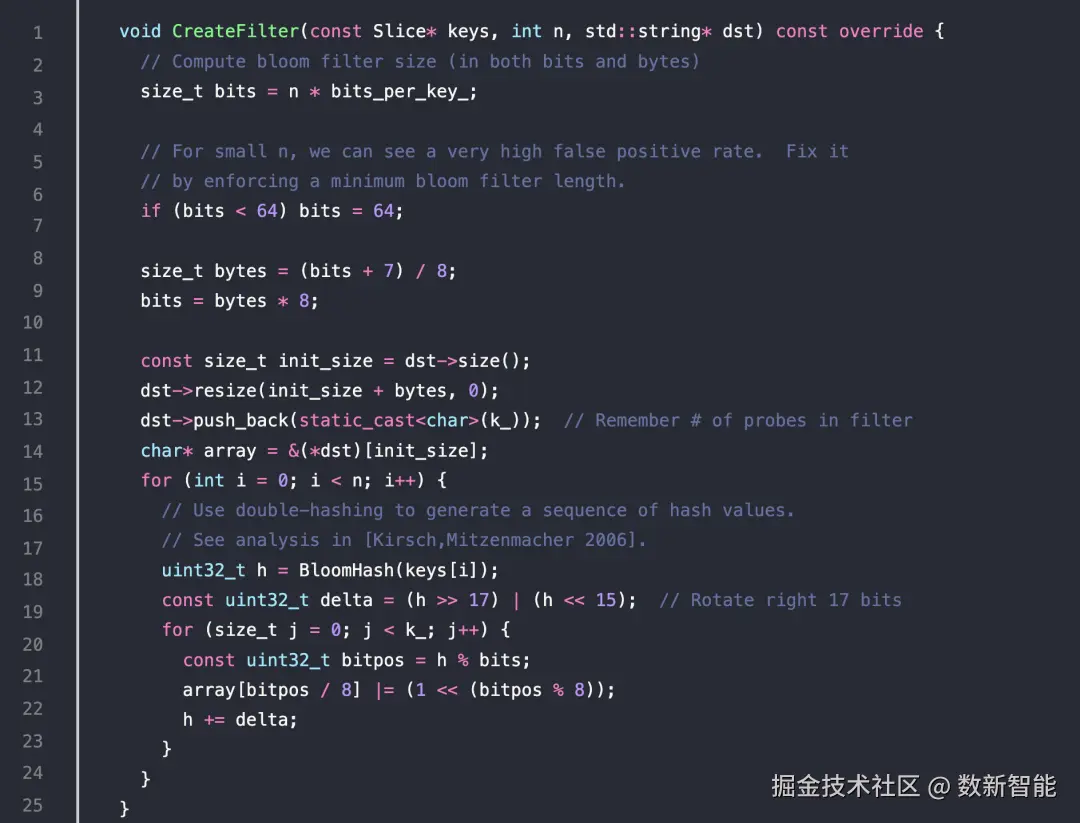
向上取整,为 8的倍数,然后将 bloom filter 函数个数,push 到 dst 中
遍历 n 个元素,对每个元素计算 哈希值
这里并没有计算k个哈希,而是只计算了一次,获得了一个原始值h
之后遍历k次,然后计算h的增量
这样的话,效率会高很多,而且准确率也不差
查找的匹配函数
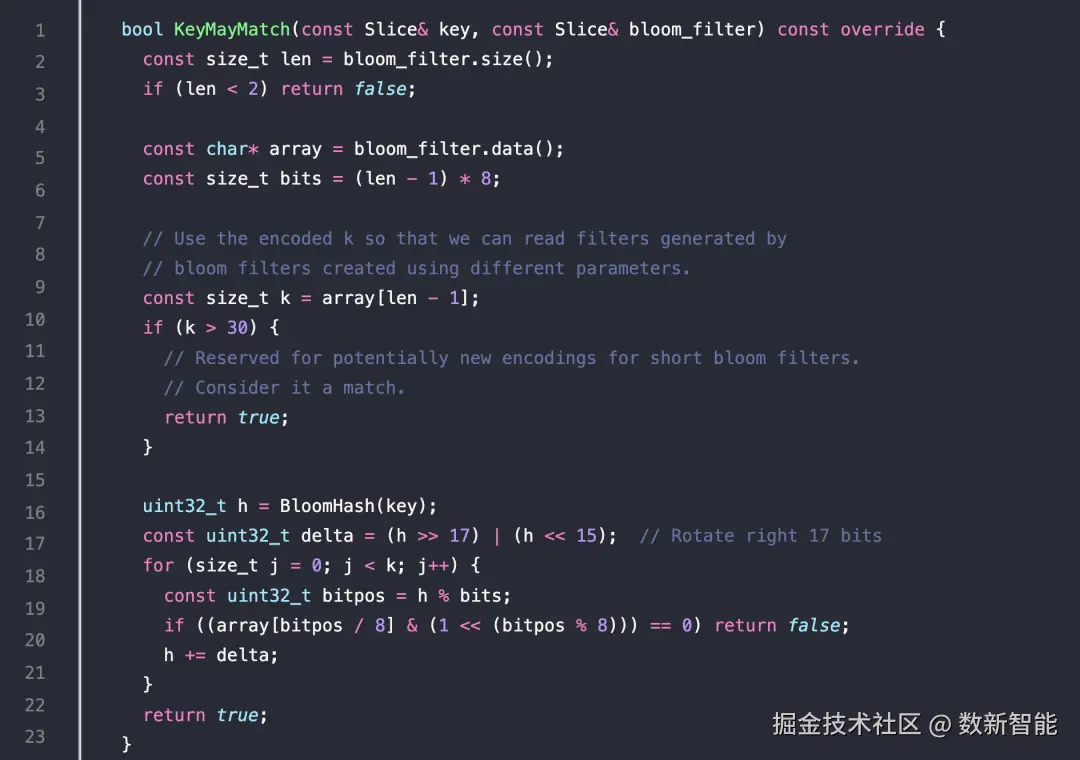
也是类似的
读取出 bloom filter的数据,以及长度,构建出 array 数组
首先计算出 hash值 然后遍历k次,也就是k个函数,然后跟创建的时候类似
通过h % bits,就得到了具体的位下标
然后看看数组中的这一位 是否设置为1,非1直接返回 false
否则计算增量,如果k次计算都满足,则返回 true
布隆过滤器的使用,两个类
- FilterBlockBuilder,创建布隆过滤器,并写入到 SSTable中
- FilterBlockReader,读取元数据块,调用 BloomFilterPolicy 检查是否匹配
FilterBlockBuilder
- 首先调用 Add,将 key进去,将所有的key直接拼在一起,比如 aa、bb、cc、dd,拼在一起就是aabbccdd,中间没有分割
- 记录没每个key的起始位置,根据每个key的起始位置,前后相减,就得到了长度
- 根据起始位置和长度,就封装出了 Slice,将这些 key都临时保存
- 如果数据超过了 2K,则生成 布隆过滤器,也就是调用 policy_->CreateFilter 创建
- 传入的是之前 生成的三个参数
- std::vector tmp_keys_、std::string result_、num_keys
FilterBlockReader
- 首先构建出 布隆过滤器
- 然后根据 key的偏移量,计算出这个key,封装为 Slice,调用 KeyMayMatch 进行判断
LRU缓存
包含了四个关键类
- LRUHandle
- HandleTable
- LRUCache
- ShardedLRUCache
ShardedLRUCache 是对 LRUCache 的封装,包含了 16个 LRUCache,目的是减少锁粒度

 其查找函数如下:
其查找函数如下:
HashSlice 就是根据 key 返回一个 hash值 Shard,则取这个 hash 值的 高 4位,这样就可以找到对应的 LRUCache 了
LRUHandle 是双链表的节点
 HandleTable 则是一个 hash 表,通过 双链表 + 自定义简单的 hash 表,就组成了 LRU
HandleTable 则是一个 hash 表,通过 双链表 + 自定义简单的 hash 表,就组成了 LRU
主要函数: 有好几处都调用了 FindPointer
有好几处都调用了 FindPointer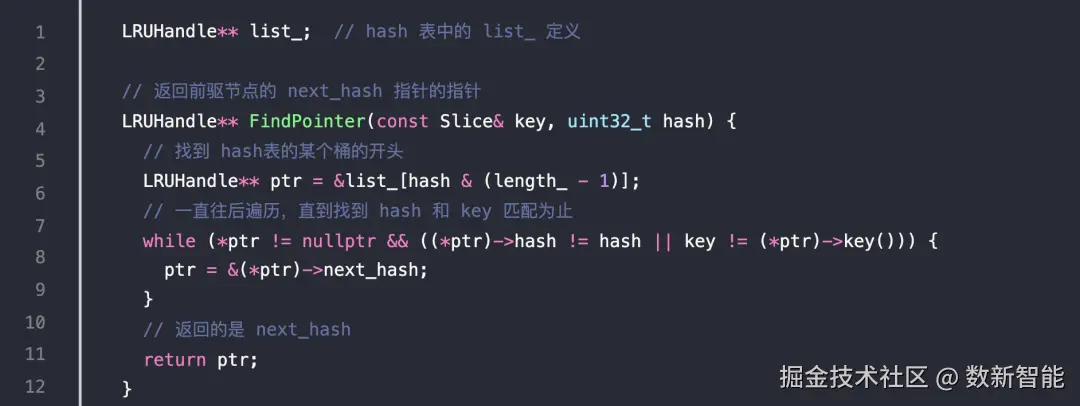 比如删除的时候,只要改变 next_hash 的地址内容就可以了
比如删除的时候,只要改变 next_hash 的地址内容就可以了
因为 FindPointer 返回的是 next_hash 的指针的指针,通过 *ptr 判断这个值是否为空
不空,则用下一个节点的 next_hash 值 替换掉即可 LRUCache 内部的几个重要变量
LRUCache 内部的几个重要变量 内部维护了两个链表,in_use、lru
内部维护了两个链表,in_use、lru
in_use 表示正在使用的,是乱序的
lru 就是正常的 lru 链表,有序的,如果空间不够了,则从这里删除
table_ 就是 hash 表
这几个的关系如下: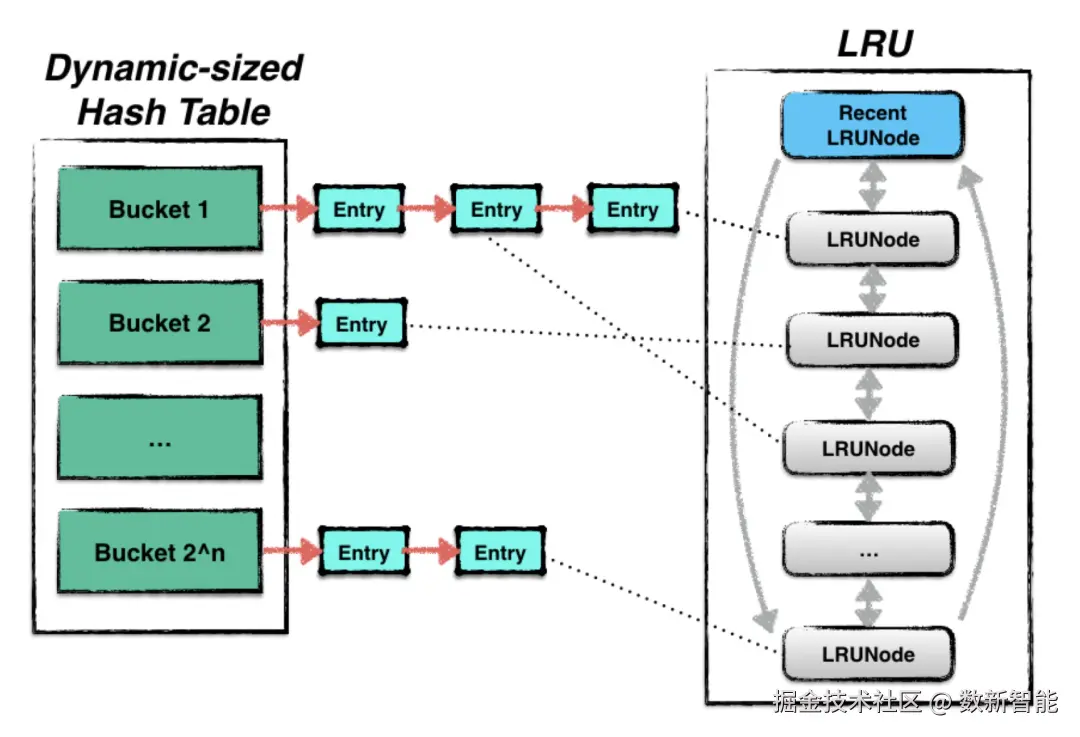 in_use 和 lru、hash 表的另一种视图
in_use 和 lru、hash 表的另一种视图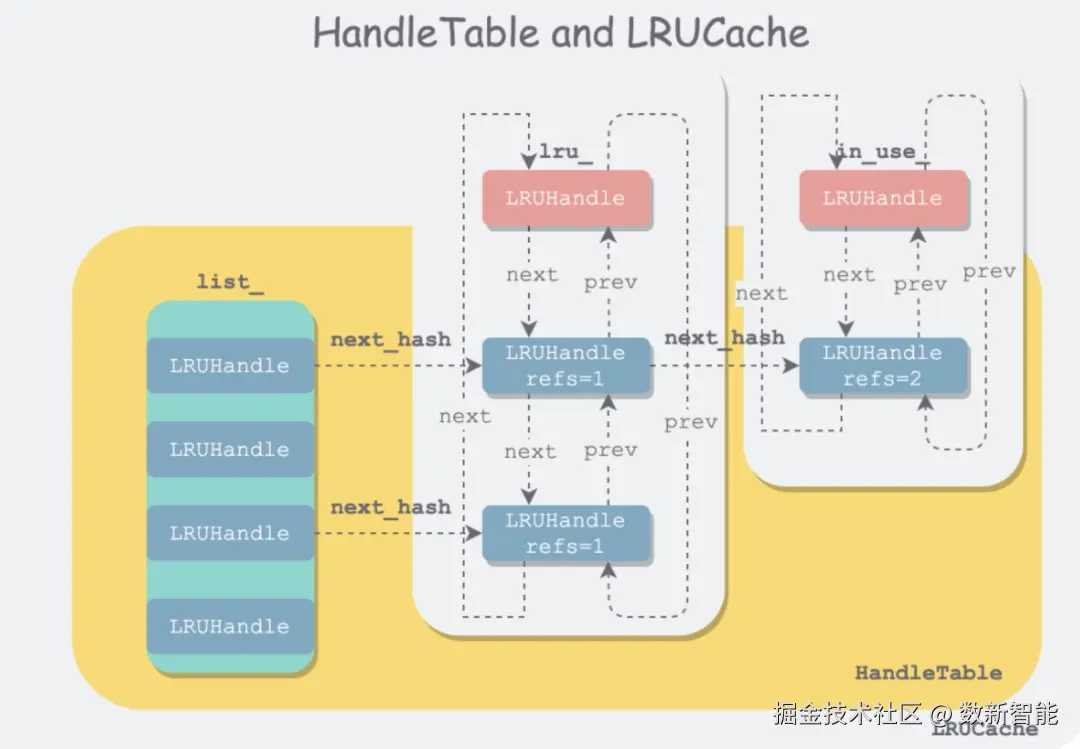 一开始的插入会放到 lru 链表中,如果 ref++,则会放到 in_use 链表中
一开始的插入会放到 lru 链表中,如果 ref++,则会放到 in_use 链表中
同理,如果 unref,则会判断是否没有引用了,然后从 in_use 中删除,放到 lru 链表中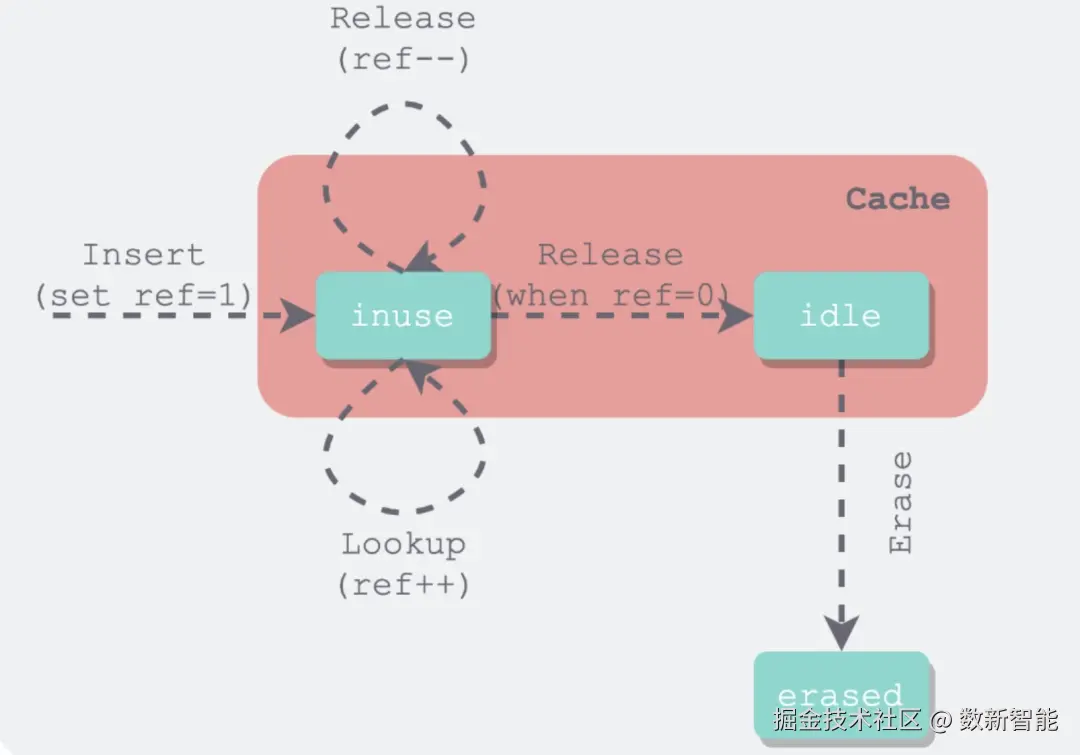
LRUCache 的主要变量 -使用两个双向链表将整个缓存分成两个不相交的集合:被客户端引用的 in-use 链表,和不被任何客户端引用的 lru_ 链表。
- 每个双向链表使用了一个空的头指针,以便于处理边界情况。并且表头的 prev 指针指向最新的条目,next 指针指向最老的条目,从而形成了一个双向环形链表。
- 使用 usage_ 表示缓存当前已用量,用 capacity_ 表示该缓存总量。
- 抽象出了几个基本操作:LRU_Remove、LRU_Append、Ref、Unref 作为辅助函数进行复用。
- 每个 LRUCache 由一把锁 mutex_ 守护。
LRUCache的函数
 LRUCache 中的私有函数
LRUCache 中的私有函数 LRUCache 的使用是在 db/table_cache.cc 中
LRUCache 的使用是在 db/table_cache.cc 中
这里包含了变量cache_, 引用的回调函数
引用的回调函数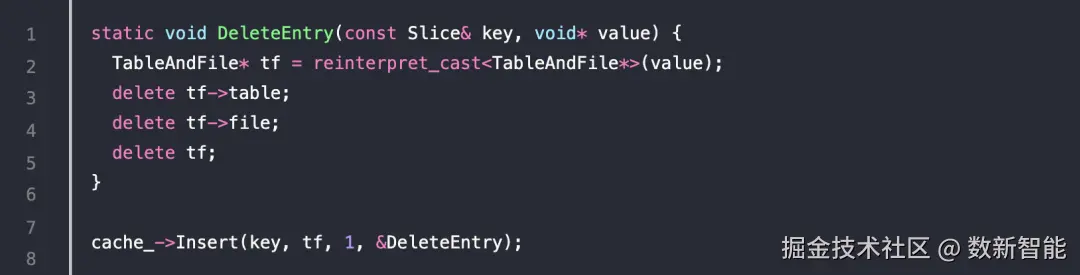 主要函数:
主要函数:
FindTable流程:
- 首先去 LRU 中查找,如果找不到,则创建一个随机文件的读写对象
- 然后 SSTable 打开,之后将其插入到缓存中

一些工具类
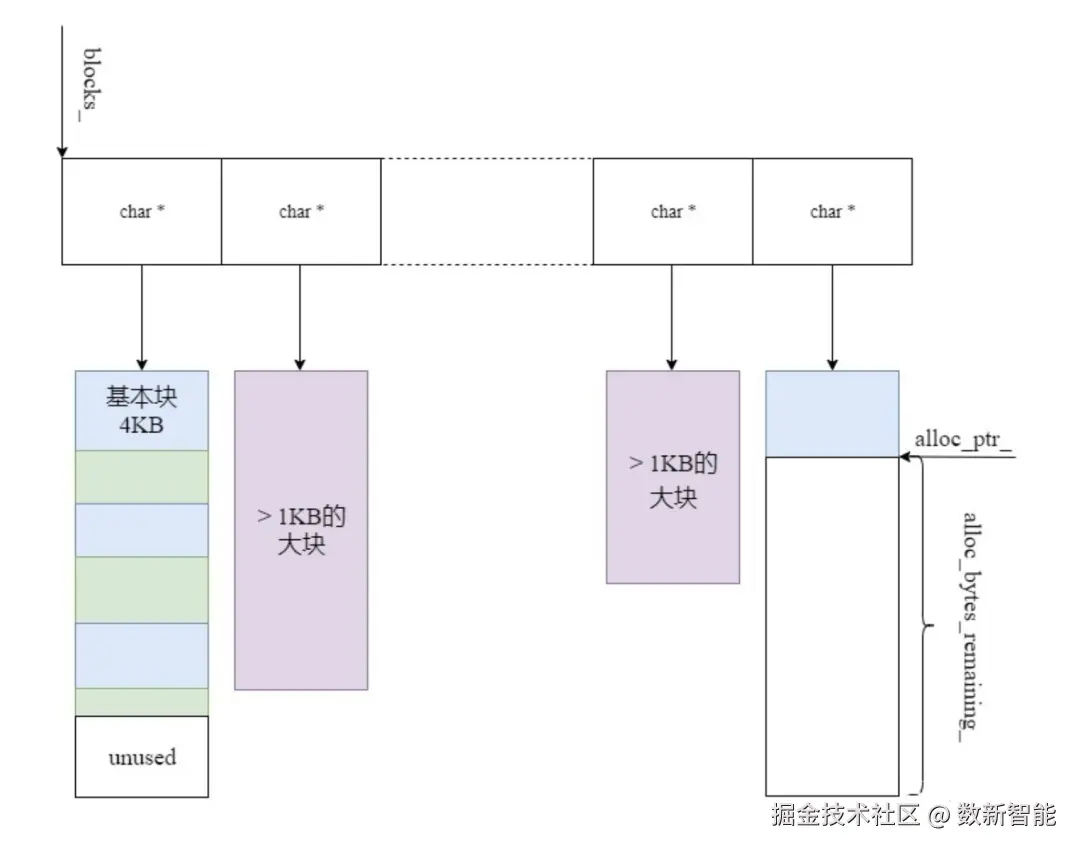
arena.cc,内存分配
- 使用一个char *的vector保存每个块;
- 当需要分配一块内存时,查看alloc_bytes_remaining_(就是当前块还有多少内存未分配)是否大于等于所需内存;
- 如果大于等于,直接分配,这时候只需要移动指针即可;
- 如果小于,要分两种情况,看所需要分配的内存是否大于1KB;
- 如果大于1KB,直接分配相应大小的块,并且插入到vector中;
- 如果小于等于1KB,则分配一个4KB的块,插入到vector中,从4KB的块上分配相应的内存;上一个块里没有分配的内存就浪费了
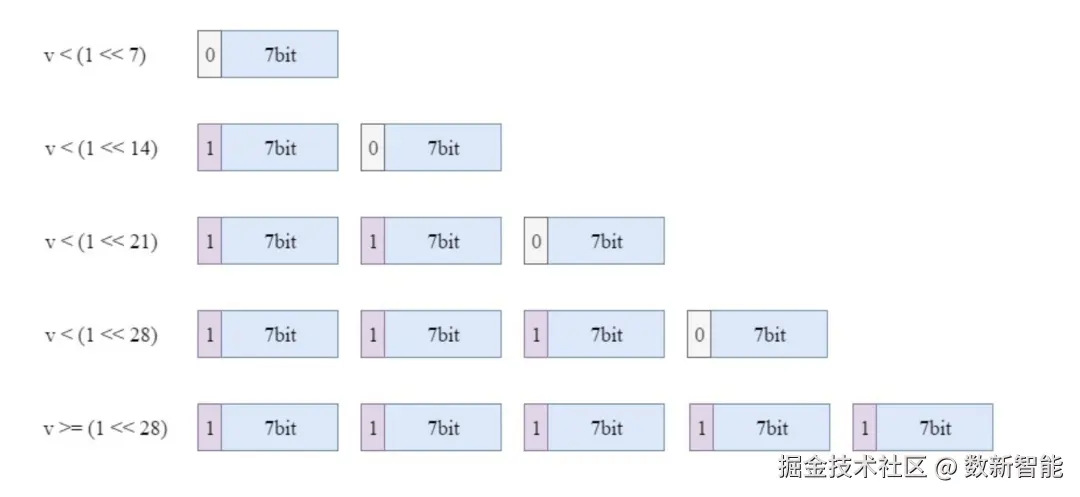
- 如果编码值 v < 1 << 7,只需要7位即可编码,可使用0 + v的方式;
- 如果编码值 1 << 7 <= v < 1 << 14,需要两个字节编码,第一个字节使用1 + v的低7位,表示需要查看下一个字节,下一个字节使用0 + v的高7位,表示不需要查看下一个字节;
- 以此类推
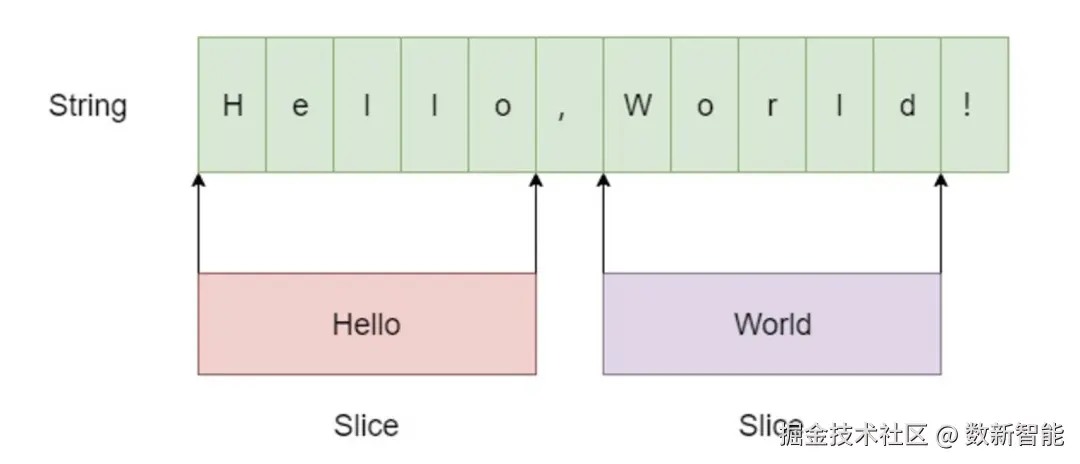
include/leveldb/slice.h
- Slice有一个字段char* data_保存字符串的指针
- 另一个字段size_t size_表示字符串的长度,也就是Slice指向另外一个字符串
其他
 logging 主要函数:
logging 主要函数:
comparator
histogram
crc32c
参考
- 论文《Less hashing, same performance:Building a better Bloom filter》
- github index
- Bloom Filters by Example
- 漫谈 LevelDB 数据结构(一):跳表(Skip List)
- 漫谈 LevelDB 数据结构(二):布隆过滤器(Bloom Filter)
- 漫谈 LevelDB 数据结构(三):LRU 缓存( LRUCache)
- LevelDB源码剖析
- SF-Zhou's Blog
- leveldb-handbook
- 庖丁解LevelDB
- rust使用
- LevelDB使用介绍
- LeveLDB维基百科
- dbdb.io的LevelDB介绍
- MariaDB的插件
- 书籍:精通LevelDB
- leveldb 实现解析
- POSIX™ 1003.1 Frequently Asked Questions (FAQ Version 1.18)
- Spurious wakeup
- Memory barrier
- Memory Barriers: a Hardware View for Software Hackers
- Bean Li的LevelDB文章汇总
- LevelDB设计与实现 - Compaction
- LevelDB设计与实现 - MVCC等
- leveldb源码剖析 系列
- HBase file format with inline blocks (version 2)
相关文章
- LevelDB SSTable模块
- LevelDB MemTable模块
- LevelDB Log模块
- LevelDB 公开的接口
- LevelDB 基本概念