Python 中,init.py文件是否需要包含全部内容?
在Python中,init.py文件不需要包含全部内容。其核心作用是标识一个目录为Python包,使得该目录可以被import语句导入。即使__init__.py为空文件,只要存在,该目录就会被视为一个包,这是它最基础的功能。
init .py的具体作用主要有三点:一是初始化包,当包被导入时,init.py会被自动执行,可用于执行包的初始化操作,比如设置包的版本号、加载必要的配置等;二是控制包的导入行为,通过定义__all__变量指定"from package import *"时可导入的模块或成员,若未定义__all__,则"import *"只会导入包中显式定义的公共成员;三是简化导入路径,例如在__init__.py中提前导入子模块,用户可以直接通过包名访问子模块,无需逐层导入。
例如,若有一个包结构如下:
mypackage/
__init__.py
module1.py
module2.py若__init__.py内容为:
__all__ = ["module1", "module2"] # 指定import *时可导入的模块
from . import module1 # 提前导入子模块则用户可以直接通过"from mypackage import module1"或"from mypackage import *"导入module1和module2,无需写成"from mypackage.module1 import ..."。
面试关键点:需明确__init__.py的核心作用是标识包,而非必须包含全部内容;理解__all__的作用及使用场景;知道其在包初始化和简化导入中的应用。
记忆法:可通过"标识+控制"记忆,"标识"指它是包的身份标识,"控制"指它能控制导入行为(如__all__)和初始化操作。
请讲解 Python 中模块调用的实现原理
Python中模块调用的实现原理可分为模块查找、加载执行、命名空间管理和缓存机制四个核心环节。
首先是模块查找路径。当使用import语句导入模块时,Python会按照特定顺序查找模块:先检查内置模块(如sys、os),若未找到,则遍历sys.path列表中的路径(包括当前执行目录、PYTHONPATH环境变量指定的路径、Python安装目录下的site-packages等)。若在这些路径中找到对应模块文件(.py、.pyc、.pyd等),则继续后续操作;若未找到,则抛出ImportError。
其次是模块的加载与执行。找到模块后,Python会经历三个步骤:加载(将模块文件读入内存)、编译(将.py文件编译为字节码.pyc,加速后续导入)、执行(执行模块中的代码,定义函数、类、变量等)。执行过程中,模块内的代码会在其独立的命名空间中运行,避免与其他模块的变量产生冲突。
然后是命名空间管理。每个模块都有自己的命名空间,存储该模块中定义的所有对象(函数、类、变量等)。当导入模块后,导入者的命名空间会新增一个指向该模块命名空间的引用(如"import module"会在当前命名空间创建module变量,指向模块的命名空间);若使用"from module import name",则会直接将name对象引入当前命名空间。
最后是缓存机制。为避免重复加载和执行模块,Python会将已导入的模块存储在sys.modules字典中。当再次导入同一模块时,会直接从该字典中获取,而非重新加载和执行,这显著提升了导入效率。
例如,导入模块的过程可简单演示为:
import sys
import mymodule # 首次导入:查找->加载->编译->执行->存入sys.modules
print(mymodule in sys.modules) # 输出True,表明已缓存
import mymodule # 二次导入:直接从sys.modules获取,不重复执行面试关键点:需掌握模块查找路径的顺序;理解加载、编译、执行的流程;清楚命名空间的隔离性;了解sys.modules的缓存作用。
记忆法:可通过"路径查找-加载执行-命名隔离-缓存复用"四步流程记忆,每一步对应模块调用的一个核心环节。
请讲解 Python 中 pdb 调试工具的使用,以及如何通过dir()查看模块中包含的函数
pdb调试工具的使用
pdb是Python自带的命令行调试工具,用于跟踪程序执行流程、查看变量值、定位错误,其核心使用方式包括两种:命令行启动和代码中设置断点。
命令行启动:在终端中通过"python -m pdb 脚本名.py"启动调试,程序会在第一行代码处暂停,等待用户输入调试命令。常用命令包括:
- break(b):设置断点,如"b 10"在第10行设置断点;
- run(r):重新运行程序;
- next(n):执行下一行代码(不进入函数内部);
- step(s):执行下一行代码(进入函数内部);
- print(p):打印变量值,如"p x"打印变量x的值;
- continue(c):继续执行程序直到下一个断点;
- quit(q):退出调试。
代码中设置断点:在需要暂停的位置插入"import pdb; pdb.set_trace()",程序执行到此时会自动进入调试模式,后续操作与命令行启动一致。例如:
def add(a, b):
import pdb; pdb.set_trace() # 在此处设置断点
return a + b
result = add(2, 3)运行程序后,会在断点处暂停,可通过上述命令查看a、b的值,逐步执行代码。
通过dir()查看模块中包含的函数
dir()是Python内置函数,用于返回对象的属性列表,当参数为模块时,可查看该模块中包含的函数、类、变量等成员。
使用方式:
- 若查看当前作用域的所有成员,可直接调用dir()(无参数);
- 若查看指定模块的成员,需先导入模块,再调用dir(模块名)。
例如,查看math模块包含的函数:
import math
print(dir(math)) # 输出math模块的所有成员,包括sin、cos、pi等输出结果中,以双下划线开头的(如__name__、doc)是模块的特殊属性,其余多为函数或变量。若需进一步了解某个成员的功能,可结合help()函数,如"help(math.sin)"查看sin函数的文档。
面试关键点:需掌握pdb的核心调试命令(break、next、step、print、continue);理解dir()的作用及与help()的配合使用;能举例说明调试流程和成员查看方法。
记忆法:pdb调试可记"断点设置(b)、单步执行(n/s)、查看变量(p)、继续运行(c)"核心命令;dir()的作用可记为"查成员,看属性,模块对象都能用"。
请介绍 Python 和 Linux 的一些基础知识
Python基础知识
Python是一种解释型、面向对象、动态类型的编程语言,其核心特点包括:
- 语法简洁:使用缩进来划分代码块,而非大括号,代码可读性高;
- 动态类型:变量无需声明类型,类型在运行时自动确定,如"x = 5"中x为int,"x = 'hello'"中x变为str;
- 多范式支持:支持面向对象(类和对象)、函数式(lambda、map、filter)、过程式编程;
- 丰富的标准库:内置大量模块,如os(系统操作)、sys(解释器交互)、datetime(日期时间处理)等,可直接调用;
- 跨平台性:可在Windows、Linux、macOS等系统上运行,无需修改代码。
核心数据类型包括:数值型(int、float、complex)、字符串(str)、列表(list)、元组(tuple)、字典(dict)、集合(set)等。例如,列表是可变序列,支持增删改操作;元组是不可变序列,适合存储固定数据。
Linux基础知识
Linux是一种开源的操作系统,其核心特点包括多用户、多任务、树形文件系统等,基础知识主要涉及:
- 文件系统结构:采用树形结构,根目录为"/",主要子目录包括:/bin(基本命令)、/etc(配置文件)、/home(用户主目录)、/usr(应用程序)、/var(可变数据,如日志)等;
- 常用命令:ls(列出目录内容)、cd(切换目录)、pwd(显示当前路径)、mkdir(创建目录)、rm(删除文件/目录)、grep(文本搜索)、chmod(修改文件权限)等;
- 权限管理:文件权限分为读(r,4)、写(w,2)、执行(x,1),分别对应所有者、所属组、其他用户,如"rwxr-xr--"表示所有者有读写执行权限,所属组有读和执行权限,其他用户只有读权限;
- 管道与重定向:管道"|"可将前一个命令的输出作为后一个命令的输入,如"ls -l | grep .py"筛选出.py文件;重定向">"(覆盖)和">>"(追加)可将输出写入文件,如"echo 'hello' > test.txt";
- 进程管理:ps(查看进程)、kill(终止进程)、top(实时查看系统进程)等命令用于管理运行中的程序。
面试关键点:Python部分需掌握其核心特性、数据类型和标准库特点;Linux部分需熟悉文件系统结构、常用命令、权限管理及管道重定向。
记忆法:Python基础可记"简洁动态多范式,标准库丰跨平台";Linux基础可记"树形结构多命令,权限管道进程清"。
请讲解随机森林、GBDT、XGBoost 的原理
随机森林
随机森林是基于Bagging(bootstrap aggregating)思想的集成学习模型,由多个决策树组成,其核心原理包括:
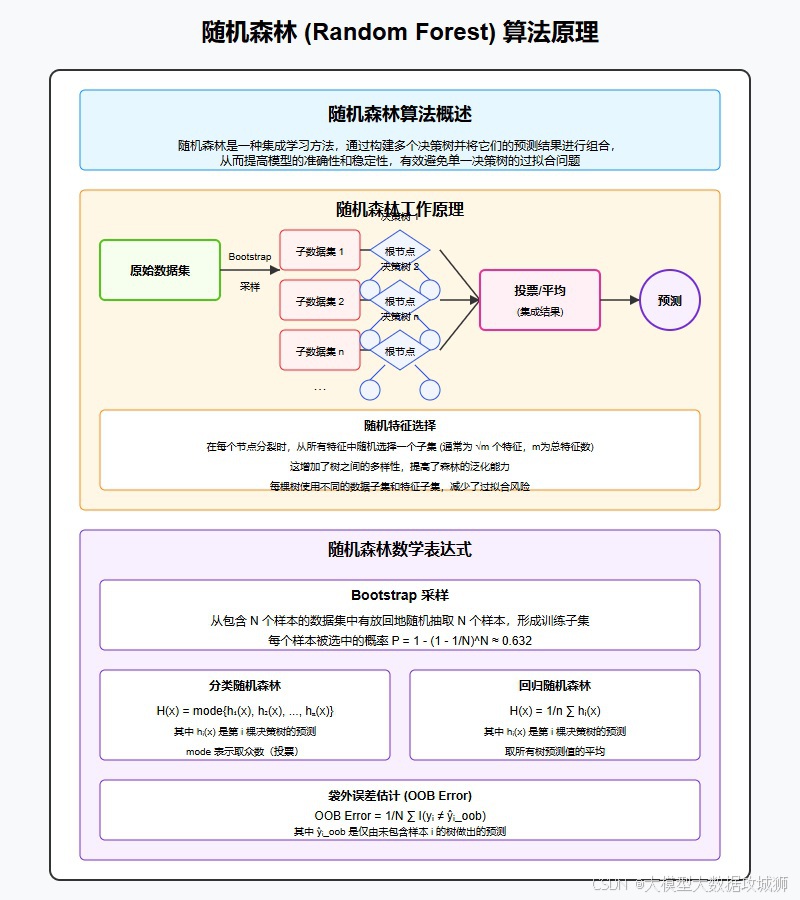
- 样本随机采样:采用bootstrap抽样(有放回抽样),从原始数据中生成多个不同的训练集,每个决策树使用一个训练集;
- 特征随机选择:在每个决策树的节点分裂时,从全部特征中随机选择部分特征(通常为√n,n为总特征数),仅基于这些特征寻找最优分裂点;
- 集成预测:对于分类问题,采用多数投票法确定最终结果;对于回归问题,采用平均值作为最终结果。
随机森林通过样本和特征的双重随机性,降低了单棵决策树的过拟合风险,同时利用多树集成提升了模型的稳定性和泛化能力。
GBDT(梯度提升决策树)
GBDT是基于Boosting思想的集成学习模型,采用串行方式构建决策树,核心原理包括:
- 基于残差学习:先构建一棵决策树拟合训练数据,然后计算该树的预测残差(真实值-预测值),再构建下一棵决策树拟合残差,重复此过程,直到满足停止条件(如树的数量达到阈值);
- 梯度下降优化:将残差学习转化为梯度下降问题,每棵新树的目标是最小化损失函数的负梯度(近似残差),使模型逐步逼近最优解;
- 弱分类器:通常使用深度较浅的决策树(如深度为3-5)作为弱分类器,避免过拟合。
GBDT通过串行优化,不断修正前序模型的误差,最终得到强分类器,适用于分类和回归任务。
XGBoost(极端梯度提升)
XGBoost是GBDT的改进版本,在效率和性能上进行了优化,核心原理包括:
- 正则化:在损失函数中加入正则项(如树的复杂度、叶子节点数量),控制模型复杂度,减少过拟合;
- 并行处理:在决策树节点分裂时,对特征的增益计算进行并行化(特征间独立),提升训练速度;
- 缺失值处理:自动学习缺失值的分裂方向,无需手动填充;
- 二阶导数优化:损失函数采用二阶泰勒展开,收敛速度更快,精度更高。
XGBoost继承了GBDT的串行提升思想,但通过多项优化使其在实践中表现更优,广泛应用于数据竞赛和工业界。
三者对比:随机森林采用Bagging(并行),抗过拟合能力强;GBDT采用Boosting(串行),注重误差修正;XGBoost是GBDT的工程优化版,效率和精度更高。
面试关键点:需明确三者的集成思想(Bagging vs Boosting);理解随机森林的双重随机性、GBDT的残差学习、XGBoost的核心优化点;能对比三者的优缺点和适用场景。
记忆法:可记"随机森林并行走,样本特征双随机;GBDT串行修残差,梯度下降步步优;XGBoost加正则,并行二阶更高效"。
XGBoost 相比于 GBDT 有哪些改进?(包括算法和工程方面)
XGBoost作为GBDT的改进版本,在算法原理和工程实现上均有显著优化,具体改进如下:
在算法层面,首先是引入正则化机制。GBDT的损失函数仅关注模型对训练数据的拟合效果,而XGBoost在损失函数中加入了正则化项,包括树的叶子节点数量和叶子节点权重的L2范数,通过控制树的复杂度有效减少过拟合风险。例如,其目标函数为"损失函数 + γ×叶子节点数 + ½λ×∑(叶子权重)²",其中γ和λ为正则化参数,可通过调参控制。
其次是采用二阶泰勒展开优化。GBDT在计算损失函数的梯度时仅使用一阶导数(近似残差),而XGBoost对损失函数进行二阶泰勒展开,同时利用一阶导数和二阶导数优化目标函数,使模型收敛速度更快,预测精度更高。
第三是分裂点查找优化。GBDT在寻找决策树的分裂点时,需对特征的所有可能值进行遍历,效率较低。XGBoost通过"近似算法"对特征值进行分桶(按百分位或权重分位数),仅在候选分桶点中查找最优分裂点,大幅减少计算量;同时支持"稀疏感知分裂",自动处理缺失值,为缺失值学习最优分裂方向,无需额外填充。
在工程层面,XGBoost实现了并行化处理。虽然Boosting本身是串行过程(后一棵树依赖前一棵树),但XGBoost在决策树的节点分裂阶段,对特征的增益计算进行并行化(不同特征的分裂点计算相互独立),通过多线程加速训练。
此外,XGBoost还引入了缓存优化和块结构存储。将训练数据按列存储为块结构,并预先对特征值排序并保存索引,避免重复排序;同时利用缓存机制减少数据读取时的IO开销,提升内存利用率。
面试关键点:需明确正则化对过拟合的抑制作用、二阶导数的优势、并行化的实现方式(特征级并行而非树级并行);理解稀疏感知分裂和块结构的工程价值。
记忆法:可通过"算法三优化(正则、二阶、分裂点),工程两加速(并行、缓存)"总结,快速关联核心改进点。
Adaboost 和 XGBoost 有什么区别?它们是如何进行预测的?
Adaboost和XGBoost均属于Boosting集成学习模型,但在原理、实现和适用场景上有显著区别,其预测方式也各有特点。
从核心原理看,两者的区别主要体现在:
- 弱分类器类型:Adaboost通常使用深度为1的决策树( stump)作为弱分类器,结构简单;XGBoost则使用深度较深的决策树(通常3-10层),能捕捉更复杂的特征交互。
- 权重更新机制:Adaboost通过调整样本权重实现迭代------对前一轮误分类的样本赋予更高权重,使后续弱分类器更关注这些样本;XGBoost不调整样本权重,而是通过优化损失函数的梯度(一阶和二阶导数),让新树拟合前序模型的残差梯度,逐步修正误差。
- 损失函数:Adaboost默认使用指数损失函数(对异常值敏感);XGBoost支持自定义损失函数(如对数损失、平方损失),且通过二阶泰勒展开优化,适用性更广。
- 正则化:Adaboost无显式正则化机制,易过拟合;XGBoost引入正则化项(控制树的复杂度),抗过拟合能力更强。
- 并行化:Adaboost无并行优化,训练效率较低;XGBoost支持特征级并行,训练速度更快。
在预测方式上:
- Adaboost的预测是加权求和(分类任务为加权投票)。每个弱分类器会被分配一个权重(基于其在训练集上的准确率,准确率越高权重越大),最终预测结果为"弱分类器输出 × 对应权重"的总和,分类任务中通过符号判断类别(如总和>0为正类)。
- XGBoost的预测是多棵决策树的输出累加。每棵树学习前序模型的残差,最终预测结果为所有树的叶子节点权重之和,分类任务中可通过sigmoid或softmax函数转换为概率。
例如,假设Adaboost有3个弱分类器,权重分别为0.5、0.3、0.2,输出分别为1、-1、1,则最终结果为0.5×1 + 0.3×(-1) + 0.2×1 = 0.4,分类为正类;XGBoost中3棵树的输出分别为0.2、0.3、0.5,则最终结果为0.2+0.3+0.5=1.0。
面试关键点:需掌握两者在权重更新、损失函数、正则化上的差异;理解预测时的加权方式(Adaboost的弱分类器权重 vs XGBoost的树输出累加)。
记忆法:可记"Adaboost调样本权重,弱分类器加权和;XGBoost优梯度,树输出直接加,正则抗过拟合"。
XGBoost 和随机森林有什么区别?两者的特征重要性是如何计算的?
XGBoost和随机森林均为集成学习模型,但在集成策略、树结构关系和适用场景上有本质区别,其特征重要性的计算方式也不同。
两者的核心区别体现在:
- 集成策略:XGBoost基于Boosting思想,采用串行方式构建决策树------每棵新树都依赖前一棵树的预测结果,通过拟合残差逐步优化模型,注重"修正错误";随机森林基于Bagging思想,采用并行方式构建决策树------每棵树独立训练(使用不同的bootstrap样本),最终通过投票或平均集成结果,注重"降低方差"。
- 树的多样性来源:XGBoost的树多样性主要来自于对残差的逐步学习(后树修正前树误差);随机森林的多样性来自于样本随机采样(bootstrap)和特征随机选择(每棵树仅用部分特征分裂),通过随机性降低单棵树的过拟合风险。
- 过拟合控制:XGBoost通过正则化项(控制树深度、叶子节点数)和学习率抑制过拟合;随机森林通过增加树的数量和特征随机性(如减少每棵树使用的特征比例)控制过拟合。
- 适用场景:XGBoost在特征相关性强、需要捕捉复杂非线性关系的任务(如点击率预测)中表现优异,但对噪声敏感;随机森林在高维稀疏数据、噪声较多的场景中更稳健,训练速度通常更快(并行训练)。
在特征重要性计算上:
- 随机森林的特征重要性通常基于"不纯度减少量"。对于分类任务,使用基尼不纯度;回归任务使用方差。计算方式为:某特征在所有树的所有分裂节点上,因该特征分裂导致的不纯度减少量之和,再除以树的数量(归一化)。例如,若特征A在10棵树中总减少基尼不纯度50,则其重要性为50/10=5。
- XGBoost的特征重要性有多种计算方式:一是"增益(gain)",即某特征在所有分裂节点上带来的目标函数降低值之和,反映该特征对模型优化的贡献;二是"覆盖(cover)",即特征分裂时涉及的样本权重之和,反映特征影响的样本范围;三是"频率(frequency)",即特征被用于分裂的次数占比。默认使用增益,更能体现特征的实际贡献。
面试关键点:需明确Boosting与Bagging的核心差异(串行vs并行、修正误差vs降低方差);掌握两种模型特征重要性的计算逻辑(不纯度vs增益/覆盖)。
记忆法:可记"XGBoost串行Boosting,增益算重要;随机森林并行Bagging,不纯度总减",快速区分核心差异和特征重要性计算方式。
请讲解 TextCNN 的运算过程
TextCNN(文本卷积神经网络)是用于文本分类的深度学习模型,借鉴了CNN在图像识别中的局部特征提取能力,其运算过程可分为文本预处理、词嵌入、卷积层、池化层、全连接层五个核心步骤。
第一步是文本预处理。将原始文本转换为模型可处理的序列形式:首先对文本进行分词(如英文按空格,中文用 jieba 等工具),去除停用词(如"的""the");然后将分词后的结果转换为固定长度的索引序列------通过构建词汇表(将每个词映射到唯一整数),将文本转为整数序列,若长度不足则补零,过长则截断(如固定长度为30)。例如,"我爱自然语言处理"分词后为"我", "爱", "自然语言", "处理",对应索引序列可能为5, 12, 3, 8,补零后为5, 12, 3, 8, 0, ..., 0(长度30)。
第二步是词嵌入(Embedding)。将整数索引序列转换为低维稠密向量。通过预训练词向量(如Word2Vec、GloVe)或随机初始化的嵌入矩阵,将每个词的索引映射为固定维度的向量(如100维)。假设输入序列长度为30,嵌入维度为100,则输出为形状(30, 100)的矩阵,可视为"文本图像"------行代表词的位置,列代表词向量维度。
第三步是卷积层。使用不同尺寸的卷积核对嵌入矩阵进行卷积操作,提取局部n-gram特征。卷积核的宽度与词向量维度一致(确保覆盖完整词向量),高度为n(如2、3、4,对应2-gram、3-gram、4-gram)。例如,使用100个高度为3的卷积核,对(30, 100)的嵌入矩阵卷积后,每个卷积核会输出(28, 1)的特征图(30-3+1=28),100个卷积核则得到(28, 100)的特征图集合。不同尺寸的卷积核可捕捉不同长度的短语特征(如2-gram捕捉双词搭配,3-gram捕捉三词搭配)。
第四步是池化层(通常为最大池化)。对每个卷积核输出的特征图取最大值,得到一个标量值,实现特征降维和关键信息提取。例如,(28, 100)的特征图经最大池化后,得到100个标量(每个卷积核对应一个最大值),不同尺寸卷积核的池化结果拼接后,形成一个固定长度的特征向量(如100+100+100=300,对应3种尺寸各100个卷积核)。
第五步是全连接层与输出。将池化后的特征向量传入全连接层,通过激活函数(如ReLU)进行非线性变换,最后连接softmax层(多分类)或sigmoid层(二分类),输出文本属于各类别的概率。同时,为防止过拟合,通常在全连接层前加入Dropout层(随机丢弃部分神经元)。
面试关键点:需掌握词嵌入的作用(将离散词转为连续向量)、卷积核尺寸与n-gram的对应关系、池化层的降维作用;理解多尺寸卷积核的必要性(捕捉不同长度的局部特征)。
记忆法:可通过"嵌入转向量,卷积提n-gram,池化取最值,全连接分类"的流程记忆,清晰对应每个步骤的核心操作。
文本分类任务有哪些评价指标?请讲解 AUC 的含义。
文本分类任务的评价指标用于衡量模型对文本类别的预测效果,常用指标包括准确率、精确率、召回率、F1值、混淆矩阵、宏平均与微平均等,AUC则是二分类任务中衡量模型区分能力的重要指标。
准确率(Accuracy)是所有预测正确的样本占总样本的比例,计算公式为(TP+TN)/(TP+TN+FP+FN),其中TP(真阳性)指正类被正确预测为正类,TN(真阴性)指负类被正确预测为负类,FP(假阳性)指负类被错误预测为正类,FN(假阴性)指正类被错误预测为负类。准确率适用于样本均衡的场景,但若数据不平衡(如正类占比1%),模型仅预测负类即可达到99%准确率,此时准确率无实际意义。
精确率(Precision)又称查准率,是预测为正类的样本中实际为正类的比例,公式为TP/(TP+FP),反映模型"预测为正的结果中正确的比例",适用于需减少误报的场景(如垃圾邮件检测,避免正常邮件被误判)。
召回率(Recall)又称查全率,是实际为正类的样本中被正确预测的比例,公式为TP/(TP+FN),反映模型"捕捉所有正类的能力",适用于需减少漏报的场景(如疾病诊断,避免漏诊患者)。
F1值是精确率和召回率的调和平均,公式为2×(Precision×Recall)/(Precision+Recall),综合两者的表现,适用于精确率和召回率需同时关注的场景,当精确率和召回率冲突时(如提高精确率可能降低召回率),F1值更具参考价值。
混淆矩阵是一个n×n的矩阵(n为类别数),行代表实际类别,列代表预测类别,每个元素表示某类被预测为另一类的样本数,直观展示模型在各类别上的预测错误分布。
宏平均(Macro-average)和微平均(Micro-average)用于多分类任务:宏平均先计算每个类别的指标(如精确率),再取平均值,对所有类别一视同仁,受小类别影响大;微平均将所有类别视为一个整体,通过总TP、FP、FN计算指标,受大类别影响大。
AUC(Area Under ROC Curve)即ROC曲线下的面积,是二分类任务的重要指标。ROC曲线以假阳性率(FPR=FP/(FP+TN))为横轴,真阳性率(TPR=Recall=TP/(TP+FN))为纵轴,描述模型在不同阈值下的分类性能。AUC的取值范围为0-1,其含义是:随机抽取一个正样本和一个负样本,模型对正样本的预测概率大于负样本的概率的期望。AUC越接近1,模型区分正负类的能力越强;等于0.5时,模型性能与随机猜测相当;小于0.5时,性能差于随机猜测(可通过反转预测改善)。
面试关键点:需掌握各指标的计算公式和适用场景(如准确率的局限性、F1值的调和作用);理解AUC的物理意义(正负样本区分概率)及ROC曲线的横纵轴定义。
记忆法:分类指标可记"准精召F1,混淆看分布;宏微分多类,AUC判区分";AUC含义可记"ROC下面积,越大区分强,随机0.5,1为最优"。
解决过拟合的方法有哪些?
过拟合是指模型在训练数据上表现优异,但在未见过的测试数据上泛化能力差的现象,其本质是模型学习了训练数据中的噪声而非核心规律。解决过拟合的方法可从数据、模型、训练过程三个维度展开,具体如下:
从数据层面,核心是增加数据的数量和质量。一是增加训练数据量 ,通过收集更多真实样本,或利用数据增强技术生成新样本(如图像领域的旋转、裁剪、加噪,文本领域的同义词替换、回译等),让模型接触更丰富的场景,减少对噪声的依赖。二是数据清洗,去除异常值、重复数据,避免模型学习错误信息,这在样本量较小时尤为重要。
从模型层面,重点是降低模型复杂度或引入约束。一是简化模型结构 ,例如减少神经网络的层数或神经元数量,降低决策树的深度,避免模型过度拟合细节。二是正则化 ,通过在损失函数中加入惩罚项限制参数规模:L1正则化(Lasso)会使部分参数为0,实现特征选择;L2正则化(Ridge)会让参数值更小,避免权重过大。三是Dropout (适用于神经网络),训练时随机丢弃部分神经元,强制模型学习更鲁棒的特征,减少对特定神经元的依赖,测试时恢复所有神经元并缩放输出。四是早停法,在训练过程中监控验证集性能,当性能不再提升时停止训练,避免模型在训练后期拟合噪声。
从训练与验证层面,交叉验证 是常用手段,将数据分成多组,多次训练和验证,确保模型在不同数据子集上表现稳定,减少单次划分的随机性影响。此外,集成学习通过组合多个弱模型(如随机森林、梯度提升树),利用群体智慧降低过拟合风险,因为单个模型的过拟合会被其他模型抵消。
面试加分点:能结合具体场景选择方法(如小样本用正则化和数据增强,大样本用简化模型),并解释不同方法的适用边界(如Dropout在循环神经网络中需谨慎使用)。
记忆法:"数据增质,模型减负,训练控度"------数据层面增加数量和质量,模型层面降低复杂度或加约束,训练层面控制迭代和验证。
稳定的排序算法和非稳定的排序算法各有哪些?
排序算法的稳定性指:对于序列中相等的元素,排序后它们的相对位置与排序前保持一致。这种特性在多关键字排序(如先按成绩再按姓名)中尤为重要,稳定排序能保证后续排序不破坏前序结果。
稳定的排序算法及其稳定性原因:
- 冒泡排序:通过相邻元素比较交换,若两元素相等则不交换,因此相等元素的相对位置不变。
- 插入排序:将元素插入已排序序列的合适位置,若遇到相等元素,插入到其后,保持原相对顺序。
- 归并排序:分治过程中,合并两个有序子序列时,若元素相等,优先取左子序列的元素,确保原相对位置。
- 基数排序:按低位到高位依次排序,同一位上相等的元素不改变相对顺序,整体保持稳定。
- 桶排序:将元素分到不同桶中,桶内排序采用稳定算法,且按桶顺序输出,整体稳定。
非稳定的排序算法及其不稳定性原因:
- 快速排序:分区时,若基准元素与相等元素交换,可能导致相等元素相对位置改变(如序列2, 2, 1,基准为第一个2,交换后1在首位,两个2的相对位置反转)。
- 选择排序:每次选最小元素与当前位置交换,若最小元素与当前位置元素相等但位置不同,会破坏相对顺序(如3, 2, 2,第一次选第二个2与首位3交换,两个2的顺序改变)。
- 堆排序:构建大顶堆时,交换堆顶元素与末尾元素,可能导致相等元素位置错乱(如堆中相等元素在不同层级,交换后相对位置改变)。
- 希尔排序:通过增量分组排序,分组内采用插入排序,但不同组的相等元素在合并时可能改变相对位置。
面试加分点:能举例说明稳定性的实际意义(如电商订单先按金额再按时间排序,稳定排序确保同金额订单按原时间顺序),并解释为何部分算法可通过修改实现稳定(如快速排序可调整分区策略,相等元素不交换,但会增加复杂度)。
记忆法:稳定排序记"冒插归基桶"(冒泡、插入、归并、基数、桶),非稳定排序记"快选堆希"(快速、选择、堆、希尔),结合"相等元素不换则稳,强制交换则不稳"的原则理解。
二分查找的递归实现和非递归实现的时间复杂度、空间复杂度分别是什么?
二分查找(折半查找)是一种针对有序数组的高效查找算法,核心思想是通过不断缩小查找范围(每次排除一半元素)定位目标值。其递归与非递归实现的复杂度差异主要源于空间开销,时间复杂度则一致。
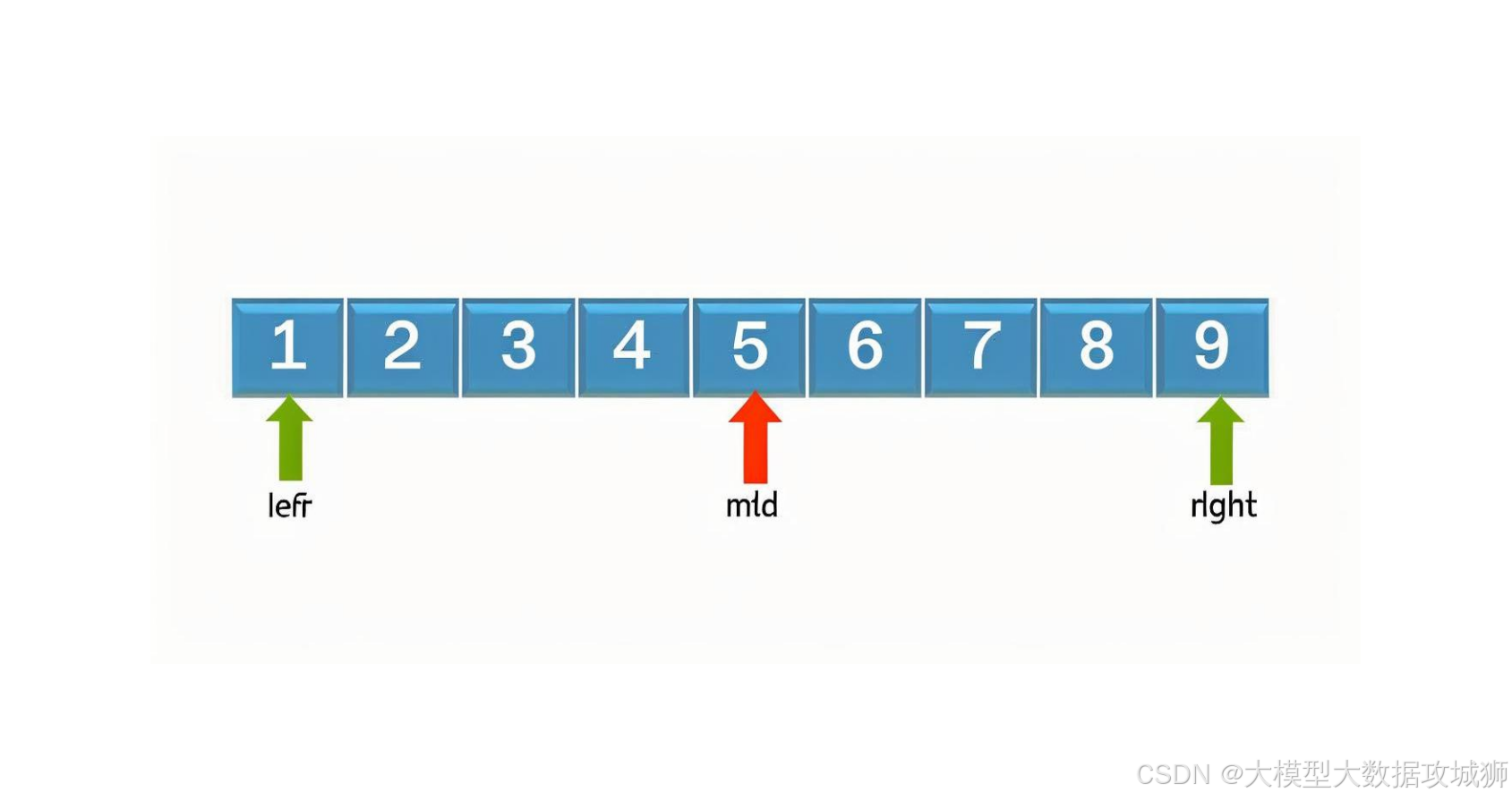
算法原理 :前提是数组已按升序(或降序)排列。设左指针low、右指针high,中间指针mid = (low + high) // 2,比较目标值与arr[mid]:若相等则找到;若目标值更小,调整high = mid - 1;若更大,调整low = mid + 1,重复直至low > high(查找失败)。
递归实现 :通过函数自身调用完成查找,终止条件为low > high(返回-1)或找到目标(返回索引)。
代码示例:
def binary_search_recursive(arr, low, high, target):
if low > high:
return -1
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] > target:
return binary_search_recursive(arr, low, mid - 1, target)
else:
return binary_search_recursive(arr, mid + 1, high, target)非递归实现 :用循环替代函数调用,通过更新low和high控制查找过程。
代码示例:
def binary_search_iterative(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] > target:
high = mid - 1
else:
low = mid + 1
return -1复杂度分析:
- 时间复杂度:两种实现均为O(log n)。因为每次查找都将范围缩小一半,最多需要log₂n(以2为底的n的对数)次比较,与实现方式无关。
- 空间复杂度:递归实现为O(log n),因递归调用会产生函数调用栈,栈的深度等于查找次数(最多log n层);非递归实现为O(1),仅需几个指针变量(low、high、mid)存储中间值,空间开销恒定。
面试加分点:能指出二分查找的边界条件处理(如low <= high而非low < high的原因),以及针对大规模数据的优化(如mid = low + (high - low) // 2避免low + high溢出)。
记忆法:"时间同log n,空间递归栈,非递常数值"------时间复杂度均为O(log n),递归空间取决于栈深度(O(log n)),非递归为常数空间(O(1))。
请讲解 Attention 机制的原理
Attention机制源于人类视觉的注意力选择特性,核心是在处理序列数据时,对输入中不同位置的信息赋予不同的权重,聚焦关键信息并忽略次要信息,从而提升模型对长距离依赖关系的捕捉能力。其广泛应用于自然语言处理(如Transformer)、计算机视觉等领域。
核心原理可分为四个步骤:
-
构建查询(Q)、键(K)、值(V)
输入序列(如句子中的词向量)通过线性变换生成三组向量:查询(Q,用于"提问")、键(K,用于"匹配查询")、值(V,用于"提供信息")。例如在机器翻译中,Q可来自解码器当前状态,K和V来自编码器的输出,通过Q与K的匹配找到相关的源语言信息。
-
计算注意力得分
得分反映Q与各位置K的匹配程度,常用计算方式包括:
- 点积注意力:
score(Q, K) = Q · K(向量点积,计算高效); - 缩放点积注意力:
score(Q, K) = (Q · K) / √d_k(d_k为K的维度,避免维度过高导致点积值过大,影响softmax稳定性); - 加性注意力:
score(Q, K) = W_a · tanh(W_q Q + W_k K)(通过神经网络计算,适用于Q和K维度不同的场景)。
- 点积注意力:
-
注意力权重归一化
对所有位置的得分应用softmax函数,得到归一化的权重(权重之和为1),公式为
α_i = softmax(score_i)。权重越高,说明对应位置的K与Q越相关,应赋予更多关注。 -
加权求和得到输出
用归一化后的权重对V进行加权求和,即
Output = Σ(α_i · V_i),最终输出融合了输入序列中关键信息的向量。
机器翻译中的 Attention 机制中,Q(Query)、K(Key)、V(Value)分别代表什么?
在机器翻译的Encoder-Decoder框架中,Attention机制通过Q、K、V的交互实现对源语言信息的动态聚焦,解决传统Encoder-Decoder模型中"信息压缩瓶颈"(编码器将整句信息压缩为固定长度向量,长句信息易丢失)的问题。三者的具体含义和作用如下:
Q(Query,查询)源于解码器(Decoder)的当前状态,代表"当前需要翻译的内容"。在机器翻译中,解码器每一步生成目标语言的一个词(如翻译到目标句的第t个词),此时Q是解码器在t时刻的隐藏状态(通常来自LSTM或Transformer的解码器层输出),用于"查询"源语言中与当前翻译步骤相关的信息。例如,翻译"我爱吃苹果"为英文时,当解码器生成"like"时,Q会引导模型关注源语言中的"爱"。
K(Key,键)源于编码器(Encoder)的输出,代表"源语言中每个位置的特征标识"。编码器对源语言每个词进行编码后,会生成一系列隐藏状态(如源句有n个词,编码器输出n个向量),这些向量经线性变换后成为K。K的作用是与Q进行匹配,计算源语言各位置与当前Q的相关性------K与Q的相似度越高,说明该位置的源语言信息与当前翻译步骤越相关。
V(Value,值)同样源于编码器的输出,代表"源语言中每个位置的具体信息内容"。与K类似,V也是编码器隐藏状态经线性变换的结果,但V存储的是该位置的实际语义信息,而非用于匹配的"键"。当Q与K计算出注意力权重后,V会根据权重被加权求和,形成"上下文向量",该向量融合了源语言中与当前翻译步骤最相关的信息,最终输入解码器用于生成目标词。
三者的协作流程为:解码器生成Q→Q与编码器的K计算相似度(如点积)→相似度经softmax归一化得到注意力权重→权重与编码器的V加权求和得到上下文向量→上下文向量与解码器当前状态结合,生成目标词。例如,翻译长句时,生成目标句的每个词都会通过Q"查询"源句中对应的关键部分(如名词对应名词,动词对应动词),使翻译更精准。
面试关键点:需明确Q来自解码器、K和V来自编码器的来源差异;理解三者通过"查询-匹配-取值"机制实现动态聚焦的核心逻辑;能结合具体翻译场景说明其作用(如处理长句时避免信息丢失)。
记忆法:可记"Q来解码查需求,K编作键配相关,V编存值供取用",直观对应三者的来源和功能。
请讲解 BILSTM + CRF 模型的原理
BILSTM + CRF 是序列标注任务(如命名实体识别、词性标注、分词)中常用的模型,结合了BILSTM对上下文语义的捕捉能力和CRF对标签依赖关系的建模能力,弥补了单一模型的缺陷。其原理可分为"特征提取"和"标签解码"两个核心阶段。
第一阶段:BILSTM负责提取上下文特征并输出发射分数。BILSTM(双向长短期记忆网络)由前向LSTM和后向LSTM组成,前向LSTM从左到右处理输入序列(如句子中的词),捕捉历史信息;后向LSTM从右到左处理,捕捉未来信息。两者的输出在每个位置拼接,形成包含完整上下文信息的隐藏状态。例如,处理"他在百度工作"时,"百度"的隐藏状态会融合"他在"(前文)和"工作"(后文)的信息,更准确地判断其为机构名。
基于BILSTM的隐藏状态,模型通过全连接层输出"发射分数":对于序列中的每个位置i,输出该位置属于每个标签的概率(如在命名实体识别中,标签可能为B-ORG、I-ORG、O等),记为 emissionilabel,表示位置i发射出label标签的分数。但BILSTM单独输出的发射分数仅考虑当前位置的上下文,未考虑标签之间的依赖关系(如"B-ORG"后更可能接"I-ORG",而不是"B-PER"),可能导致不合理的标签序列(如"B-ORG→B-PER"连续出现)。
第二阶段:CRF(条件随机场)负责建模标签依赖并解码最优序列。CRF层在BILSTM输出的发射分数基础上,引入"转移分数":定义一个转移矩阵 transitionlabel1label2,表示从label1转移到label2的概率(如transitionB-ORGI-ORG分数高,transitionB-ORGB-PER分数低)。CRF的目标是找到整体分数最高的标签序列,整体分数=各位置发射分数之和 + 各相邻标签转移分数之和。
例如,对于序列"百度",BILSTM可能输出"B-ORG"和"I-ORG"的高发射分数,而CRF通过转移分数确保"B-ORG"后接"I-ORG"(而非其他标签),最终输出合理的标签序列。
模型训练时,通过最大化训练数据中正确标签序列的对数似然(即整体分数)优化参数(BILSTM的权重和CRF的转移矩阵);预测时,使用维特比算法(动态规划)寻找整体分数最高的标签序列。
面试关键点:需说明BILSTM(上下文特征)与CRF(标签依赖)的互补性;解释发射分数和转移分数的作用;能举例说明标签依赖的重要性(如避免不合理的标签跳转)。
记忆法:"双向LSTM抓前后,输出发射分;CRF管转移,最优序列稳",清晰对应两者的分工和协作关系。
请讲解 CRF 模型的原理:其优化目标是什么?如何训练?预测方法是什么?维特比算法的过程是怎样的?
CRF(条件随机场)是一种基于概率图模型的序列标注方法,专注于建模输入序列与输出标签序列之间的条件概率,适用于命名实体识别、词性标注等任务。其核心原理、优化目标、训练与预测方法如下:
模型原理:CRF以"条件概率P(Y|X)"为建模对象,其中X是输入序列(如句子),Y是输出标签序列(如词性标签)。模型假设标签序列Y的概率依赖于整个输入序列X,且通过特征函数捕捉X与Y的局部依赖关系(如"输入词是'北京'时,标签为'B-LOC'")和Y内部的相邻依赖关系(如"标签'B-LOC'后接'I-LOC'")。特征函数的输出经权重加权求和后,通过softmax归一化得到条件概率P(Y|X)。
优化目标:最大化训练数据的对数似然函数。对于训练样本(X₁,Y₁),(X₂,Y₂),...,(Xₙ,Yₙ),优化目标为最大化Σlog P(Yᵢ|Xᵢ),即让模型对正确标签序列的预测概率尽可能高。这一目标通过最小化负对数似然(-Σlog P(Yᵢ|Xᵢ))实现,负对数似然同时考虑了发射特征(X与Y的关系)和转移特征(Y内部的关系)。
训练方法:采用极大似然估计结合梯度下降。首先定义特征函数(包括状态特征和转移特征),并为每个特征分配权重;然后计算对数似然函数对权重的梯度,通过梯度下降(如SGD、Adam)迭代更新权重,使负对数似然最小化。训练过程中,需计算配分函数(所有可能标签序列的概率之和),但因序列长度增长导致标签序列数量呈指数级增加,实际中通过动态规划(前向-后向算法)高效计算配分函数。
预测方法:在给定输入X时,寻找使P(Y|X)最大的标签序列Y*,即Y* = argmax_Y P(Y|X)。由于P(Y|X)与特征函数加权和正相关,等价于寻找特征加权和最大的序列,这一过程通过维特比算法实现。
维特比算法过程:一种动态规划算法,通过记录每个位置每个标签的最大累积分数及路径,高效求解最优序列。步骤如下:
- 初始化:对序列第一个位置,计算每个标签的初始分数(发射分数),作为该位置该标签的最大累积分数,路径为自身。
- 递推:对位置i(i>1)的每个标签y_i,计算其最大累积分数:遍历位置i-1的所有标签y_{i-1},累积分数 = 位置i-1中y_{i-1}的累积分数 + 从y_{i-1}到y_i的转移分数 + 位置i中y_i的发射分数,取最大值作为y_i的累积分数,并记录对应的y_{i-1}(路径前驱)。
- 终止:在序列最后一个位置,找到累积分数最大的标签,作为最优序列的最后一个标签。
- 回溯:从最后一个标签出发,根据记录的前驱标签依次向前回溯,得到完整的最优标签序列。
例如,对输入序列"他在百度工作",维特比算法会从第一个词开始,逐步计算每个位置各标签的最大分数,最终回溯得到如"O→O→B-ORG→I-ORG→O"的最优实体标签序列。
面试关键点:需明确CRF的条件概率建模本质;理解优化目标与极大似然的关系;掌握维特比算法的动态规划思想(递推与回溯)。
记忆法:"CRF建模P(Y|X),优化似然最大化;训练靠梯度降,预测维特比找最优,递推累积分,回溯得序列"。
请讲解隐马尔可夫模型(HMM)的原理:做了哪些独立性假设?训练方法是什么?
隐马尔可夫模型(HMM)是一种基于概率的生成模型,用于建模具有隐藏状态的序列数据(如语音识别中,声音信号是观测序列,语音对应的文字是隐藏状态)。其核心原理、独立性假设和训练方法如下:
模型原理:HMM包含两个序列和三组参数。两个序列分别是:隐藏状态序列(H),如词性标签(名词、动词);观测序列(O),如具体的词("苹果""吃")。三组参数为:
- 初始概率分布π:π_i = P(H₁ = i),表示第一个隐藏状态为i的概率。
- 转移概率矩阵A:A_ij = P(H_{t+1} = j | H_t = i),表示从隐藏状态i转移到j的概率。
- 发射概率矩阵B:B_ik = P(O_t = k | H_t = i),表示隐藏状态i生成观测k的概率。
HMM的核心是通过这三组参数,建模联合概率P(O, H) = π_{H₁} × Π_{t=1 to T-1} A_{H_t H_{t+1}} × Π_{t=1 to T} B_{H_t O_t},即给定隐藏状态序列生成观测序列的概率。
独立性假设:HMM的可行性依赖两个关键假设,简化了概率计算:
- 齐次马尔可夫假设:当前隐藏状态只依赖于前一个隐藏状态,与更早期的状态无关,即P(H_t | H_{t-1}, H_{t-2}, ..., H₁) = P(H_t | H_{t-1})。这一假设忽略了隐藏状态的长距离依赖,降低了模型复杂度。
- 观测独立性假设:当前观测只依赖于当前隐藏状态,与其他隐藏状态或观测无关,即P(O_t | H_T, ..., H_t, ..., H₁, O_T, ..., O_{t+1}, O_{t-1}, ..., O₁) = P(O_t | H_t)。这一假设简化了观测与隐藏状态的关系,但可能损失部分上下文信息(如观测"苹果"可能受前一个观测"吃"的影响)。
训练方法:HMM的训练目标是从观测序列O中估计参数π、A、B(隐藏状态序列H未知,称为"隐变量问题"),常用方法是Baum-Welch算法(EM算法的特例),步骤如下:
- 初始化:随机初始化π、A、B的参数(需满足概率分布约束,如每行和为1)。
- E步(期望步) :基于当前参数,计算"隐藏状态转移被观测序列支持的期望次数"和"隐藏状态生成观测的期望次数"。具体通过前向-后向算法计算:
- 前向概率α_t(i) = P(O₁, ..., O_t, H_t = i),表示到t时刻观测为O₁..O_t且隐藏状态为i的概率。
- 后向概率β_t(i) = P(O_{t+1}, ..., O_T | H_t = i),表示t时刻隐藏状态为i时,后续观测为O_{t+1}..O_T的概率。
- 利用α和β计算γ_t(i) = P(H_t = i | O)(t时刻隐藏状态为i的后验概率)和ξ_t(i,j) = P(H_t = i, H_{t+1} = j | O)(t时刻状态i且t+1时刻状态j的后验概率)。
- M步(最大化步) :基于E步得到的期望次数,更新参数:
- π_i = γ₁(i)(第一个时刻状态i的概率)。
- A_ij = Σ_{t=1 to T-1} ξ_t(i,j) / Σ_{t=1 to T-1} γ_t(i)(状态i转移到j的频率)。
- B_ik = Σ_{t: O_t=k} γ_t(i) / Σ_{t=1 to T} γ_t(i)(状态i生成观测k的频率)。
- 迭代:重复E步和M步,直至参数收敛(如似然函数变化小于阈值)。
面试关键点:需准确表述两个独立性假设的内容及作用;理解Baum-Welch算法中EM框架的应用(E步估计隐变量分布,M步更新参数);能说明HMM作为生成模型的特点(建模P(O,H)而非P(H|O))。
记忆法:"HMM两假设,齐次马尔可夫(当前态仅靠前态),观测独立(当前观测仅靠当前态);训练用Baum-Welch,EM迭代估参数"。
CRF 和 HMM 有什么区别?
CRF(条件随机场)和HMM(隐马尔可夫模型)均用于序列标注任务,但在模型类型、假设条件、特征利用和适用场景上有本质区别,具体如下:
模型类型不同:HMM是生成模型,CRF是判别模型。生成模型建模联合概率P(X,Y)(X为输入序列,Y为标签序列),通过P(X,Y) = P(Y)P(X|Y)计算,可生成输入数据;判别模型直接建模条件概率P(Y|X),专注于输入到输出的映射,更适合分类任务。例如,HMM需同时学习标签序列的生成概率和输入序列的发射概率,而CRF直接学习给定输入时标签序列的概率,更聚焦于预测目标。
独立性假设不同:HMM有严格的独立性假设,CRF无显式假设。HMM依赖"齐次马尔可夫假设"(当前标签仅依赖前一标签)和"观测独立性假设"(当前输入仅依赖当前标签),这些假设简化了计算,但忽略了输入序列的长距离依赖(如输入词之间的关联)和标签序列的全局依赖(如第三个标签可能依赖第一个标签)。CRF不做独立性假设,可捕捉输入序列的全局特征(如整个句子的语义)和标签序列的任意依赖关系(如标签之间的长距离约束),更灵活地建模复杂模式。
特征利用能力不同:CRF可利用全局特征,HMM依赖局部特征。HMM的特征局限于当前位置(发射概率仅与当前标签和输入相关,转移概率仅与相邻标签相关),无法直接使用跨位置的输入特征(如"第1个词是'公司'时,第3个词更可能是'CEO'")。CRF通过特征函数定义,可包含任意输入特征(如输入序列中任意位置的词、词性、长度等)和标签特征(如任意两个标签的关系),例如特征函数可定义为"若输入第i个词是'北京'且标签i是'B-LOC',则特征值为1",或"若标签i是'B-LOC'且标签i+2是'I-LOC',则特征值为1",能更充分利用数据中的模式。
适用场景不同:HMM适用于简单、输入与标签依赖明确的场景(如孤立词语音识别),因其假设强、计算高效,但在复杂序列标注(如长句子的命名实体识别)中表现有限。CRF因无严格假设且能利用全局特征,在复杂场景(如中文分词、句法分析)中表现更优,但计算复杂度更高(训练和预测均慢于HMM)。
参数学习方式不同:HMM的参数学习(π、A、B)依赖Baum-Welch算法(EM算法),通过迭代估计隐变量(隐藏状态)分布更新参数;CRF的参数学习通过极大似然估计结合梯度下降,直接优化条件概率的对数似然,无需处理隐变量。
面试关键点:需从模型类型(生成vs判别)、假设条件(严格vs无)、特征利用(局部vs全局)三个核心维度对比;能结合具体任务说明两者的选择依据(如简单场景选HMM,复杂场景选CRF)。
记忆法:"生成判别分类型,假设严松看约束,局部全局论特征,简单复杂定场景",快速关联两者的核心差异。
请讲解 word2vec 的原理:它是有监督还是无监督的?CBOW 和 Skip-gram 有什么区别?分层 Softmax 和负采样的原理是什么?负采样的采样原理是什么?为什么要这样采样?
word2vec 是用于生成词向量的经典模型,核心是通过上下文学习词的分布式表示,使语义相近的词具有相似的向量。其原理及相关问题如下:
有监督还是无监督:word2vec 本质是无监督学习。它不需要人工标注的标签,而是利用文本中词的上下文关系作为"间接监督信号"进行训练。例如,通过"预测某个词的上下文"或"用上下文预测该词"的任务,自动学习词向量,无需人工定义类别或标签。
CBOW 和 Skip-gram 的区别:两者是 word2vec 的两种架构,核心差异在于预测方向:
- CBOW(连续词袋模型):用上下文词预测中心词。例如,对于句子"猫坐在垫子上",当中心词是"坐"时,CBOW 会用"猫""在""垫子""上"这些上下文词作为输入,训练模型输出"坐"的概率。其特点是对高频词更稳健(上下文信息平均后噪声影响小),训练速度快。
- Skip-gram:用中心词预测上下文词。同样以"猫坐在垫子上"为例,Skip-gram 会用中心词"坐"作为输入,训练模型输出"猫""在""垫子""上"等上下文词的概率。其特点是更适合处理低频词(单个中心词可生成多个训练样本),在小数据集上表现更好,但训练速度较慢。
分层 Softmax 和负采样的原理:两者都是为了解决原始 word2vec 中"softmax 计算成本过高"的问题(词汇表规模大时,计算每个词的概率需遍历所有词)。
- 分层 Softmax:用哈夫曼树(一种最优二叉树)替代传统 softmax。树的叶子节点对应词汇表中的词,非叶子节点为中间变量。计算某个词的概率时,只需从根节点遍历到对应叶子节点,路径长度为 O(log V)(V 为词汇表大小),远小于传统 softmax 的 O(V)。概率计算基于 sigmoid 函数,每一步判断向左/右子树的概率,最终乘积为该词的概率。
- 负采样:通过采样少量负例(非上下文词),用二分类替代多分类。对于一个正样本(中心词与上下文词的共现对),随机采样 K 个负样本(与中心词无共现的词),训练模型区分正例(标签 1)和负例(标签 0)。此时无需计算所有词的概率,只需计算 1 个正例和 K 个负例的损失,计算成本降至 O(K)(K 通常取 5-20)。
负采样的采样原理及原因:负采样的采样分布并非均匀分布,而是采用"经过调整的 unigram 分布",即 P(w) ∝ (count(w))^0.75 / Σ(count(w'))^0.75,其中 count(w) 是词 w 在语料中的出现次数。
- 采样原理:高频词被采样的概率更高,但通过 0.75 次方调整,避免高频词(如"的""the")被过度采样(否则负例可能多为无意义的高频词,影响训练)。
- 为何这样采样:一方面,高频词与中心词共现的概率本就较低(如"的"与大多数词都可能共现),作为负例更合理;另一方面,降低高频词的采样权重,可让低频词有更多机会被选为负例,平衡不同频率词的影响,提升词向量质量。
面试关键点:需明确 word2vec 的无监督本质;区分 CBOW 与 Skip-gram 的预测方向及适用场景;理解两种加速方法(分层 Softmax 用哈夫曼树、负采样用二分类)的核心逻辑;解释负采样分布的设计原因(平衡高低频词)。
记忆法:"word2vec 无监督,上下文作信号;CBOW 上下文猜中心,Skip-gram 中心猜周围;分层 Softmax 树减算,负采样正负分;负例采样调高频,0.75 次方衡权重"。
请讲解 Fasttext 的原理:它与 word2vec 有什么区别?如何进行文本分类?其哈希规则是什么?如何将语义相近的词哈希到同一个桶里?
Fasttext 是 Facebook 提出的词向量与文本分类模型,结合了 word2vec 的高效性和对形态学信息的捕捉能力,尤其适用于处理有形态变化的语言(如英语)和小数据集。其原理及相关问题如下:
Fasttext 原理:核心是引入"子词(subword)"概念,将每个词分解为字符级 n-gram 子词(如"apple"可分解为"<ap""app""ppl""ple""le>",尖括号表示词的边界)。词向量由其所有子词的向量之和(或平均)表示,这使得模型能处理未登录词(OOV)------即使某个词未在训练集中出现,只要其包含的子词在训练过,就能生成对应的向量。例如,"apples"未见过,但"app""ple""les"等子词可能在训练集中,从而生成合理向量。
与 word2vec 的区别:
- 输入单元:word2vec 以完整词为输入单元,无法直接处理未登录词;Fasttext 以词和子词为输入,能利用字符级信息,对未登录词更鲁棒。
- 任务侧重:word2vec 主要用于生成词向量;Fasttext 不仅能生成词向量,还直接支持文本分类任务(内置分类层)。
- 模型结构:两者均基于神经网络,但 Fasttext 在词向量层后增加了文本分类的输出层(如 softmax),且子词的引入使输入维度更高(需处理大量子词)。
- 训练效率:Fasttext 采用分层 softmax 或负采样加速训练,且子词的共享性使其在小数据集上收敛更快。
文本分类方法:Fasttext 用于文本分类的流程如下:
- 对输入文本(如句子)进行分词,将每个词分解为子词(如 n-gram 子词)。
- 为每个子词分配一个向量(随机初始化或预训练),词向量为其子词向量的平均(或求和)。
- 对文本中所有词的向量进行平均(或求和),得到整个文本的向量表示。
- 将文本向量输入线性分类器(如 softmax 层),输出文本属于各分类的概率。
例如,对"我喜欢机器学习"分类,先分解每个词为子词,计算子词向量,再平均得到文本向量,最后预测其是否属于"科技"类别。
哈希规则及语义相近词的哈希:由于子词数量可能极多(如英语中 3-gram 子词可达百万级),Fasttext 采用哈希函数将子词映射到有限数量的"桶(bucket)"中,减少参数规模。
- 哈希规则:使用简单的哈希函数(如模运算)将子词的字符串映射到整数索引(桶编号),例如 hash(subword) % bucket_size,其中 bucket_size 是预设的桶数量(通常为 2^15 或 2^20)。
- 语义相近词的哈希:语义相近的词往往有相似的字符序列(如"猫"和"狗"都是动物,字符长度相同;"跑步"和"跳跃"都是动词,后缀相同),其分解出的子词也更可能相似。相似的子词经哈希函数映射后,有更高概率落入同一个桶中,从而共享同一个向量参数,间接实现语义相近词的向量关联。
面试关键点:需强调子词对未登录词的处理能力;明确与 word2vec 在输入单元和任务上的差异;解释文本分类中的向量聚合方式(平均/求和);理解哈希桶的作用(降维)及语义相近词的哈希逻辑(字符序列相似→子词相似→同桶)。
记忆法:"Fasttext 用子词,未登录词不发愁;对比 word2vec,子词分类双兼顾;分类先拆子词,向量平均进 softmax;哈希子词入桶,相似字符共参数"。
文本分类任务中,除了 CNN 和 RNN,还知道哪些方法?
文本分类任务中,除 CNN(卷积神经网络)和 RNN(循环神经网络)外,还有多种方法,涵盖传统机器学习、预训练模型、图模型等,适用于不同场景,具体如下:
预训练语言模型(如 BERT、GPT、RoBERTa):基于 Transformer 的自注意力机制,通过在大规模无标注文本上预训练,学习通用语言表示,再在具体分类任务上微调。例如 BERT 采用双向 Transformer,能捕捉上下文双向语义,在情感分析、新闻分类等任务中表现优异。其优势是无需手动设计特征,能处理长距离依赖,泛化能力强,但计算成本较高,需大量微调数据。
朴素贝叶斯(Naive Bayes):基于贝叶斯定理和特征条件独立假设的传统方法。将文本表示为词袋模型(如词频或 TF-IDF),计算"给定文本属于某类"的概率。例如在垃圾邮件分类中,计算"包含'优惠''点击'等词的邮件是垃圾邮件"的概率。优势是训练速度快、实现简单,适合小规模数据和实时场景;缺点是假设特征独立,忽略词之间的依赖关系,精度较低。
支持向量机(SVM):通过寻找最优超平面划分不同类别文本。将文本映射到高维特征空间(如通过核函数),使线性不可分问题变为可分。在文本分类中,常与 TF-IDF 特征结合,在情感分析、主题分类等任务中曾广泛应用。优势是在高维空间中表现好,泛化能力较强;缺点是对大规模数据训练较慢,核函数选择敏感。
Fasttext:Facebook 提出的轻量级模型,结合词向量和子词特征。将文本中词和子词的向量平均后,输入线性分类器。适用于多语言分类、小数据集场景,尤其擅长处理有形态变化的语言(如英语复数、过去式)。优势是训练速度极快,支持百万级类别,对未登录词友好;缺点是模型较简单,难以捕捉复杂语义关系。
Transformer 及变体(如 Transformer-XL、XLNet):基于自注意力机制,并行处理序列,避免 RNN 的串行依赖。Transformer-XL 引入段级递归和相对位置编码,解决长文本处理问题;XLNet 采用排列语言模型,克服 BERT 预训练与微调的差异。在长文本分类(如文档分类)中表现优于 RNN 和 CNN,能捕捉全局语义关联,但计算复杂度高。
图神经网络(GNN):将文本建模为图结构(如词作为节点,共现关系作为边),通过消息传递更新节点表示,再聚合得到文本表示。适用于具有明确结构的文本(如论文摘要、知识图谱相关文本),能捕捉词之间的非序列依赖(如"苹果"与"水果"的上下位关系)。优势是能建模复杂拓扑关系;缺点是图结构构建复杂,对无显式结构的文本效果有限。
胶囊网络(Capsule Network):用"胶囊"替代神经元,每个胶囊输出向量(包含特征的存在概率和姿态信息),通过动态路由机制聚合胶囊特征。在文本分类中,能捕捉词之间的层次关系(如"形容词+名词"的搭配),对噪声和变形更稳健。但目前在文本任务中应用较少,理论优势尚未完全发挥。
面试关键点:需覆盖传统方法(朴素贝叶斯、SVM)、预训练模型(BERT 等)、轻量级模型(Fasttext)、图模型(GNN)等;说明每种方法的核心原理和适用场景(如小数据用 Fasttext,高精度用 BERT);能对比不同方法的优缺点(如速度、精度、数据需求)。
记忆法:"文本分类多方法,预训练强靠 BERT,传统快用贝叶斯,SVM 高维稳,Fasttext 轻量快,GNN 结构灵"。
请讲解多任务学习和对抗网络的相关知识。
多任务学习
多任务学习(Multi-Task Learning, MTL)是一种机器学习范式,通过同时学习多个相关任务,利用任务间的共享信息提升模型的泛化能力和学习效率,核心思想是"协同学习、相互促进"。其关键要素和类型如下:
核心原理:多个任务之间通常存在潜在关联(如"词性标注"和"命名实体识别"都依赖词的语法和语义特征),多任务学习通过共享部分模型参数(或特征表示),使模型学习到任务间的共同模式,同时保留各任务的特有模式。这种共享机制能减少过拟合风险(尤其对数据量少的任务),并利用相关任务的数据增强特征学习。
主要类型:
- 硬共享(Hard Parameter Sharing):多个任务共享底层网络(如神经网络的前几层),仅在顶层使用任务特定的输出层。例如,用同一套词嵌入层和 LSTM 层处理"情感分析"和"文本分类",再分别接两个不同的全连接层输出结果。优点是参数少、训练高效;缺点是任务差异过大时,共享参数可能互相干扰。
- 软共享(Soft Parameter Sharing):每个任务有独立的模型参数,但通过正则化约束(如 L2 正则)使参数尽可能相似。例如,为"机器翻译"和"文本摘要"设计两个独立的 Transformer 模型,通过损失函数中的参数相似度惩罚项,促使两者学习相似的特征提取方式。优点是灵活性高,适合差异较大的任务;缺点是参数更多,计算成本高。
适用场景:任务需具有相关性(如同一领域、共享特征),且部分任务数据量较少(可借助数据充足的任务提升性能)。例如,在 NLP 中,同时训练"问答""情感分析"和"命名实体识别",共享语言模型的特征提取层,提升小数据任务的效果。
优势与挑战:优势包括提升泛化能力、数据利用效率高、减少过拟合;挑战在于任务相关性判断(无关任务可能相互干扰)、损失函数设计(需平衡不同任务的损失权重)。
对抗网络
对抗网络(Adversarial Networks)以生成对抗网络(GAN)为代表,通过两个网络的对抗训练实现数据生成或特征学习,核心思想是"博弈论中的 minimax 游戏"。其核心组件和应用如下:
GAN 的基本结构:包含生成器(Generator, G)和判别器(Discriminator, D):
- 生成器 G:输入随机噪声(如正态分布采样的向量),输出与真实数据分布相似的伪造数据(如假图片、假文本)。
- 判别器 D:输入数据(真实数据或 G 生成的伪造数据),输出该数据为真实数据的概率(0-1 之间)。
训练过程:两者交替优化,形成对抗:
- 固定 G,训练 D:最大化 D 对真实数据的识别准确率(输出接近 1)和对伪造数据的识别准确率(输出接近 0),损失函数为 L_D = -Elog D(x) - Elog(1 - D(G(z))),其中 x 是真实数据,z 是噪声。
- 固定 D,训练 G:最小化 D 对伪造数据的识别能力(使 D(G(z)) 接近 1),损失函数为 L_G = -Elog D(G(z))。
- 迭代至平衡:当 D 无法区分真实数据和伪造数据(D(G(z)) ≈ 0.5)时,G 生成的数据分布接近真实分布,训练收敛。
文本领域的扩展:由于文本是离散数据(词或子词的序列),传统 GAN 难以直接应用(生成器的输出不可导),因此出现了 SeqGAN(用强化学习训练生成器)、TextGAN 等变体,用于文本生成(如写诗、故事)、数据增强(生成相似样本扩充小数据集)、风格迁移(如将正式文本转为口语化)等。
其他对抗应用:对抗训练(Adversarial Training)通过在输入中添加微小扰动(对抗样本),增强模型的鲁棒性(如防止模型被恶意文本欺骗);领域对抗神经网络(DANN)通过对抗训练对齐不同领域的特征分布,提升跨领域任务(如跨语言文本分类)的性能。
面试关键点:多任务学习需讲清硬/软共享的区别及适用场景;对抗网络需说明 GAN 的双网络结构和对抗训练过程;能举例说明两者在 NLP 中的应用(如多任务学习用于联合标注,GAN 用于文本生成)。
记忆法:"多任务学习共参数,硬共享省参软灵活,相关任务互促进;对抗网络俩博弈,生成造假判别辨,交替训练求真分布"。
给定两个命名实体识别任务,一个任务数据量充足,另一个任务数据量很少,这种情况下可以怎么做?
当面对两个命名实体识别(NER)任务(一个数据充足,一个数据稀少)时,核心思路是利用数据充足任务的知识提升数据稀少任务的性能,具体方法如下:
迁移学习与预训练微调:借助预训练语言模型的通用知识,结合数据充足任务的领域信息,迁移到数据稀少任务。
- 步骤:1. 选择预训练模型(如 BERT、RoBERTa),在数据充足的 NER 任务上进行微调,使其学习该领域的实体特征(如医学领域的"疾病""药物"实体);2. 将微调后的模型参数作为初始值,在数据稀少的 NER 任务上继续微调,仅更新部分顶层参数(避免过拟合)。
- 优势:预训练模型已学习通用语言规律,数据充足任务的微调进一步注入领域知识,减少数据稀少任务对标注数据的依赖。例如,先用大量新闻领域 NER 数据微调 BERT,再用少量法律领域 NER 数据微调,模型能更快适应法律实体(如"合同""法规")。
多任务学习联合训练:将两个任务放在同一模型中联合训练,共享底层特征提取器,利用数据充足任务的信息辅助数据稀少任务。
- 实现:设计共享的编码器(如 BILSTM 或 Transformer),输出的特征同时输入两个任务的特定解码器(如 CRF 层),损失函数为两个任务损失的加权和(数据稀少任务可赋予更高权重,避免被主导)。
- 原理:两个任务若相关(如同属医疗领域,一个识别"疾病",一个识别"症状"),共享层会学习到共同的语义特征(如医学术语的表达方式),数据充足任务的监督信号能帮助模型更稳健地提取特征,间接提升数据稀少任务的性能。
数据增强扩充稀少任务数据:通过自动生成或变换样本,增加数据稀少任务的训练数据量。
- 方法:1. 同义词替换(如将"医生"替换为"医师",保持实体标签不变);2. 回译(将文本翻译成其他语言再译回,生成语义相似的句子);3. 实体替换(用同类型实体替换原有实体,如用"肺癌"替换"胃癌",标签仍为"疾病");4. 生成式增强(用 GAN 或预训练模型生成包含目标实体的新句子)。
- 注意:增强后需保证实体标签的一致性,避免引入噪声。例如,对"他被诊断出患有糖尿病",替换实体为"高血压",生成"他被诊断出患有高血压",标签仍为"疾病"。
半监督学习利用未标注数据:若数据稀少任务有未标注文本,可通过半监督方法利用这些数据。
- 自训练:用数据充足任务训练的模型对数据稀少任务的未标注文本进行预测,筛选高置信度的伪标签样本(如预测概率>0.9),加入训练集迭代训练。
- 协同训练:用两个不同的模型(如 BILSTM-CRF 和 CNN-CRF)分别标注未标注数据,取两者一致的样本作为伪标签,减少单一模型的偏见。
领域适应与特征对齐:若两个任务属于不同领域(如一个是新闻,一个是论文),通过领域适应方法对齐特征分布。
- 对抗领域适应:在模型中加入领域判别器,训练时使共享特征既对 NER 任务有用,又难以被判别器区分来自哪个领域,从而学习领域无关的实体特征。
- 特征映射:将两个领域的特征映射到同一空间(如通过对抗训练或矩匹配),减少领域差异对实体识别的影响。
面试关键点:需结合任务相关性选择方法(相关任务用多任务学习,无关用领域适应);强调迁移学习中"预训练→领域微调→目标任务微调"的流程;说明数据增强的具体操作及注意事项(避免噪声)。
记忆法:"少数据 NER 有妙招,迁移微调借他力,多任务联合共学习,增强数据扩样本,半监督伪标签助力,领域对齐消差异"。
有人认为 Attention 机制和 TextCNN 的结果相差不大,你如何理解这一点?可以从两者对信息提取范围的区别进行分析。
Attention 机制和 TextCNN 在部分文本任务中表现相近,这与任务特性、数据特点及两者信息提取范围的差异密切相关。从信息提取范围的本质区别出发,可从以下角度理解这一现象:
信息提取范围的核心差异 :
TextCNN 依赖固定尺寸的卷积核提取局部信息,其关注范围是"预定义的局部窗口"。例如,使用 2-gram、3-gram 卷积核时,模型只能捕捉连续 2 或 3 个词的局部关联(如"人工智能""自然语言处理"等短语),无法直接获取长距离依赖(如段落首尾的呼应关系)。这种固定范围的提取方式使其擅长捕捉局部语义模式,但对全局语境的把握有限。
Attention 机制通过动态计算权重实现"全局范围的柔性关注",理论上可关注序列中任意位置的信息。例如,在翻译"他昨天买的书,今天看完了"时,Attention 能让"看完了"与"书"建立强关联,即使两者相距较远。其关注范围不受固定窗口限制,而是根据语义相关性动态调整,更适合捕捉长距离依赖和全局语境。
结果相近的场景与原因 :
在许多任务中,关键信息集中在局部范围内,此时两者的提取能力差异被弱化,导致结果相近:
- 短文本任务(如句子级情感分析):情感倾向往往由局部情感词(如"精彩""糟糕")决定,TextCNN 的局部卷积核可直接捕捉这些词及其邻近搭配(如"非常精彩"),而 Attention 虽能关注全局,但核心信息仍在局部,两者性能差异不大。
- 结构化文本(如新闻标题分类):标题通常包含核心实体和关键词(如"央行降息政策发布"中的"央行""降息"),这些信息集中且距离近,TextCNN 的局部卷积能有效提取,与 Attention 的全局关注效果接近。
- 数据噪声较多的场景:当文本中存在大量冗余信息时,Attention 可能因过度关注噪声而性能下降,而 TextCNN 因聚焦局部关键信息,反而表现更稳定,与 Attention 结果接近。
结果差异显著的场景 :
当任务依赖长距离依赖或全局语境时,两者差异凸显:
- 长文本理解(如文档级关系抽取):判断"公司 A 收购了公司 B,其股价上涨"中"其"指代"公司 A",需要关联远距离的"公司 A"和"其",Attention 能通过权重分配捕捉这种关联,而 TextCNN 因卷积核范围有限难以实现。
- 语义歧义消解:句子"他喜欢苹果"中,"苹果"是水果还是公司,需结合上下文(如前文提到"科技产品"),Attention 可动态关注上下文线索,TextCNN 则可能因局部信息不足导致判断错误。
面试关键点:需明确两者信息提取范围的本质(固定局部窗口 vs 动态全局关注);结合任务长度、关键信息分布解释结果相近或差异的原因;强调"任务特性决定模型适用性"而非绝对优劣。
记忆法:"TextCNN 抓局部窗口,Attention 看全局权重;短文本局部关键,结果近;长文本依赖远,差异显"。
词向量通常用什么方法训练?维度一般设置为多大?
词向量(Word Embedding)是将离散词映射为连续低维向量的技术,其训练方法和维度设置直接影响语义表示效果,具体如下:
常用训练方法 :
词向量的训练方法可分为"静态词向量"和"动态(上下文相关)词向量"两类:
-
静态词向量(词表级向量):为每个词分配唯一向量,不随上下文变化,适用于捕捉词的通用语义。
- Word2Vec:包括 CBOW 和 Skip-gram 两种架构,通过预测上下文或中心词的监督任务(本质无监督)训练。CBOW 用上下文预测中心词,适合高频词;Skip-gram 用中心词预测上下文,适合低频词。两者均通过分层 Softmax 或负采样加速训练,生成的向量能体现词的类比关系(如"国王-男人+女人≈女王")。
- GloVe(全局向量):结合全局词共现统计和局部上下文信息,通过最小化"词向量点积与共现对数的误差"训练。相比 Word2Vec,GloVe 利用了全局语料统计,在词类比和相似度任务上表现更优。
- FastText:引入子词(字符级 n-gram),词向量为子词向量之和,能处理未登录词(OOV),训练速度快,适合多语言场景。
-
动态词向量(上下文相关向量):词向量随上下文变化,能捕捉一词多义,依赖预训练语言模型。
- ELMo(嵌入语言模型):基于双向 LSTM,通过预训练语言模型生成上下文相关向量,不同语境中同一词的向量不同(如"苹果"在"吃苹果"和"苹果公司"中向量不同)。
- BERT 及变体:基于 Transformer 自注意力机制,通过掩码语言模型(MLM)和下一句预测(NSP)预训练,生成的词向量融合双向上下文信息,在语义理解任务中表现远超静态向量。
- GPT 系列:基于单向 Transformer,通过自回归语言模型预训练,生成的词向量更侧重生成式任务中的上下文关联。
维度设置 :
词向量维度通常在 50-1000 之间,常用范围为 100-300 维,维度选择需平衡语义表达能力和计算成本:
- 低维度(50-100 维):适用于小数据集或简单任务(如文本分类基线模型),参数少、训练快,但可能丢失细粒度语义(如难以区分"高兴"和"兴奋"的细微差异)。
- 中维度(100-300 维):最常用,在多数任务(如命名实体识别、情感分析)中能平衡表达能力和效率,可捕捉大部分语义关联(如同义词、上下位词关系)。
- 高维度(300-1000 维):适用于大规模语料或复杂任务(如机器翻译、知识图谱嵌入),能存储更丰富的语义细节,但计算和存储成本高,且易过拟合(尤其数据集较小时)。
维度设置还需考虑语料规模:语料越大,可支撑更高维度(如维基百科级语料常用 300 维);小语料(如特定领域的几千篇文档)用过高维度会导致参数冗余。
面试关键点:需区分静态与动态词向量的核心差异(是否依赖上下文);说明不同方法的适用场景(如处理 OOV 用 FastText,一词多义用 BERT);解释维度选择的权衡(表达能力 vs 成本)。
记忆法:"静态词向量看全局,Word2Vec、GloVe、FastText;动态向量随上下文,ELMo、BERT 能力强;维度常用百到三百,小数据低来大数据高"。
请讲解 Transformer 的完整流程(从输入到输出)
Transformer 是基于自注意力机制的序列建模模型,广泛应用于机器翻译、文本生成等任务,其完整流程从输入到输出可分为"输入处理""编码器""解码器""输出层"四个核心阶段,具体如下:
输入处理:将原始文本序列转换为模型可处理的向量表示,包含词嵌入和位置编码两步:
- 词嵌入(Token Embedding):将每个词(或子词)通过嵌入矩阵映射为固定维度的向量(如 512 维)。例如,"machine"映射为 0.2, 0.5, ..., 0.1(512 维),嵌入矩阵通过训练学习。
- 位置编码(Positional Encoding):由于 Transformer 无循环或卷积结构,需手动注入位置信息。常用正弦余弦函数:对于位置 pos 和维度 i,若 i 为偶数,PE(pos, i) = sin(pos / 10000^(2i/d_model));若 i 为奇数,PE(pos, i) = cos(pos / 10000^(2i/d_model))。位置编码与词嵌入向量相加,得到包含语义和位置信息的输入向量。
编码器(Encoder):由 N 个相同的编码器层堆叠而成(如 BERT 用 12 层),每个编码器层包含"多头自注意力"和"前馈网络"两个子层,且每个子层后均有残差连接和层归一化:
- 多头自注意力(Multi-Head Attention):将输入向量拆分为 h 个头部(如 8 头),每个头部独立计算自注意力(Q=K=V=输入向量),再将结果拼接并线性变换。自注意力通过计算 Q 与 K 的点积(缩放后)得到权重,再与 V 加权求和,使每个词关注序列中其他相关词(如"他"关注"小明")。
- 前馈网络(Feed Forward Network):对每个位置的向量独立进行线性变换,由两个线性层和 ReLU 激活组成:FFN(x) = max(0, xW1 + b1)W2 + b2,增强模型的非线性表达能力。
- 残差连接与层归一化:每个子层输出为"子层输入 + 子层输出"(残差),再经层归一化(使均值为 0、方差为 1),稳定训练。
解码器(Decoder):同样由 N 个相同的解码器层堆叠而成,每个解码器层包含"掩蔽多头自注意力""编码器-解码器注意力"和"前馈网络"三个子层,同样有残差连接和层归一化:
- 掩蔽多头自注意力(Masked Multi-Head Attention):与多头自注意力类似,但通过掩码(上三角矩阵)屏蔽未来位置的信息(如生成第 t 个词时,看不到 t+1 及以后的词),确保自回归生成。
- 编码器-解码器注意力:Q 来自解码器前一子层输出,K 和 V 来自编码器的最终输出,使解码器关注输入序列(如翻译时,目标语言词关注源语言对应词)。
- 前馈网络:与编码器的前馈网络结构相同,进一步处理特征。
输出层:解码器的最终输出经线性层(将维度映射到词汇表大小)和 softmax 函数,得到每个词的生成概率,取概率最高的词作为输出(生成式任务),或直接用于分类/标注(判别式任务)。
例如,在"机器翻译"任务中:输入"我爱中国"经词嵌入+位置编码后进入编码器,生成包含源语言语义的特征;解码器初始输入为"<bos>"(句首标记),通过掩蔽自注意力和编码器-解码器注意力,生成"ILove";再将"ILove"作为输入,重复解码,直至生成"<eos>"(句尾标记),得到完整译文"ILoveChina"。
面试关键点:需明确位置编码的必要性(弥补无循环结构的缺陷);解释多头注意力的作用(捕捉不同子空间的关联);说明掩蔽的功能(确保生成顺序);理清编码器与解码器的信息交互(K和V来自编码器)。
记忆法:"输入嵌入加位置,编码器多头自注意接前馈;解码器掩蔽自注意,再与编码交互接前馈;输出线性加 softmax,序列建模全流程"。
请讲解 MHA(多头注意力)和 GQA(分组查询注意力)的应用场景。
MHA(多头注意力)和 GQA(分组查询注意力)是 Transformer 中两种注意力机制的变体,核心差异在于注意力头的计算方式,适用于不同的性能与效率需求场景,具体如下:
MHA(多头注意力) :
MHA 将注意力机制拆分为多个并行的"头",每个头独立计算注意力,再将结果拼接并线性变换得到最终输出。例如,将 512 维的输入向量拆分为 8 个 64 维的头,每个头计算 Q、K、V 并输出注意力结果,最后拼接为 512 维向量。
核心特点:
- 每个头有独立的 Q、K、V 权重矩阵,可捕捉不同子空间的语义关联(如一个头关注语法依赖,另一个头关注语义相似性)。
- 计算复杂度较高:设序列长度为 L,维度为 D,头数为 H,则复杂度为 O(L²D + L²D/H × H) = O(L²D),与头数无关,但参数更多(H 组 Q、K、V 矩阵)。
应用场景:
- 对语义理解要求高的任务:如机器翻译(需捕捉源-目标语言的复杂对应关系)、文本摘要(需理解长文档的逻辑结构)、问答系统(需关联问题与上下文的细节)。例如,在翻译"复杂的科学术语"时,多个头可分别关注术语的词性、搭配和领域特性,提升翻译准确性。
- 资源充足的训练场景:MHA 参数更多,需要更大的数据集和计算资源(如 GPU/TPU 集群)训练,适合预训练大模型(如 BERT、GPT-3)的训练阶段,追求最优性能而非实时性。
GQA(分组查询注意力) :
GQA 是 MHA 和单头注意力的折中方案,将头分为 G 个组,每组内共享一个查询矩阵(Q),但键(K)和值(V)矩阵仍为每个头独立。例如,16 个头分为 4 组,每组 4 个头共享 1 个 Q 矩阵,共有 4 个 Q 矩阵和 16 个 K、V 矩阵。
核心特点:
- 平衡性能与效率:相比 MHA,减少了 Q 矩阵的数量(从 H 个减为 G 个),参数和计算量降低(尤其 Q 的计算);相比单头注意力,保留了多头对多子空间的捕捉能力。
- 实验表明,当 G 足够大(如 G=8,H=32)时,性能接近 MHA,但计算成本显著低于 MHA。
应用场景:
- 大模型部署与实时推理:如聊天机器人(需快速响应)、搜索引擎(需实时处理查询)、移动设备上的 NLP 应用(计算资源有限)。例如,GPT-4 采用 GQA 平衡生成质量和响应速度,在保持对话流畅性的同时,降低服务器负载。
- 高吞吐量任务:如批量文本分类、大规模内容审核,需要在单位时间内处理大量样本,GQA 的高效性能提升处理效率,同时保证精度损失可控。
- 长序列任务:如文档级情感分析(序列长度达数千词),L² 项的计算成本极高,GQA 通过减少 Q 矩阵数量降低复杂度,使模型在长序列上可行。
面试关键点:需明确 MHA 与 GQA 在 Q 矩阵共享上的差异;对比两者的计算复杂度和性能权衡;结合"训练 vs 部署""精度优先 vs 效率优先"说明应用场景的选择。
记忆法:"MHA 多头各独立,语义捕捉强,适合精训求性能;GQA 分组共查询,效率高,部署推理更可行"。
请介绍 1-2 个多模态大模型,并讲解 CLIP 的核心代码逻辑。
多模态大模型能处理文本、图像、音频等多种类型数据,典型代表包括 CLIP(对比语言-图像预训练)和 DALL-E 2,其中 CLIP 因在跨模态检索和迁移学习中的优异表现被广泛应用。
多模态大模型介绍:
- CLIP(Contrastive Language-Image Pretraining):由 OpenAI 提出,通过对比学习对齐文本和图像的语义空间,可实现"零样本迁移"(无需微调即可处理新任务)。例如,输入图像和文本"一只猫",CLIP 能判断两者是否匹配;甚至未训练过"X光片"分类,也能通过文本"一张X光片"识别相关图像。
- DALL-E 2:同样由 OpenAI 提出,基于 CLIP 的文本-图像特征对齐,通过扩散模型根据文本描述生成高质量图像。例如,输入"一只穿着宇航服的猫在月球上",能生成符合描述的逼真图像,支持风格、细节的精确控制。
CLIP 的核心代码逻辑 :
CLIP 的核心是通过对比损失训练文本编码器和图像编码器,使匹配的文本-图像对在特征空间中距离更近,不匹配的对距离更远。核心流程包括数据加载、编码器定义、对比损失计算和训练循环,简化代码逻辑如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义图像编码器(如 ResNet 变体)
class ImageEncoder(nn.Module):
def __init__(self, output_dim=512):
super().__init__()
self.backbone = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
# ... 省略中间卷积层 ...
nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化
)
self.projection = nn.Linear(2048, output_dim) # 投影到512维特征空间
def forward(self, x):
x = self.backbone(x) # 输入图像 (batch_size, 3, 224, 224)
x = x.flatten(1) # (batch_size, 2048)
return self.projection(x) # (batch_size, 512)
# 2. 定义文本编码器(如 Transformer)
class TextEncoder(nn.Module):
def __init__(self, vocab_size, embed_dim=512, output_dim=512, num_heads=8):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads),
num_layers=6
)
self.projection = nn.Linear(embed_dim, output_dim)
def forward(self, x):
x = self.embedding(x) # 输入文本token (batch_size, seq_len) → (batch_size, seq_len, 512)
x = self.transformer(x) # Transformer编码
x = x.mean(dim=1) # 取序列平均作为文本特征 (batch_size, 512)
return self.projection(x) # (batch_size, 512)
# 3. 定义对比损失
def contrastive_loss(image_features, text_features, temperature=0.07):
# 特征归一化
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# 计算相似度矩阵 (batch_size x batch_size)
logits = torch.matmul(image_features, text_features.T) / temperature
# 正样本是对角线(图像i对应文本i)
labels = torch.arange(logits.shape[0], device=logits.device)
# 交叉熵损失:图像→文本和文本→图像双向计算
loss_i = nn.CrossEntropyLoss()(logits, labels)
loss_t = nn.CrossEntropyLoss()(logits.T, labels)
return (loss_i + loss_t) / 2
# 4. 训练循环
def train():
batch_size = 32
image_encoder = ImageEncoder()
text_encoder = TextEncoder(vocab_size=10000)
optimizer = optim.Adam(list(image_encoder.parameters()) + list(text_encoder.parameters()), lr=1e-4)
# 模拟数据:32张图像和32条匹配文本
images = torch.randn(batch_size, 3, 224, 224) # 随机图像
texts = torch.randint(0, 10000, (batch_size, 10)) # 随机文本token
for epoch in range(10):
image_features = image_encoder(images)
text_features = text_encoder(texts)
loss = contrastive_loss(image_features, text_features)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item()}")
if __name__ == "__main__":
train()核心逻辑解析:
- 编码器:图像编码器(如简化的 ResNet)将图像转为 512 维特征,文本编码器(Transformer)将文本转为同维度特征,确保跨模态可比。
- 对比损失:通过计算图像-文本特征的相似度矩阵,最大化正样本(匹配对)的相似度,最小化负样本(非匹配对)的相似度,迫使模型学习对齐的语义空间。
- 零样本迁移:训练后,对于新任务(如"识别狗的图像"),生成文本"一只狗"的特征,与图像特征比对,相似度最高的即为匹配结果。
面试关键点:需说明 CLIP 的对比学习核心(对齐文本-图像特征);解释零样本迁移的原理(利用文本描述作为"分类器");代码中需体现特征归一化和双向交叉熵损失的作用。
记忆法:"CLIP 图文相对比,编码器输出同空间;对比损失拉近距离,零样本文本作标签"。
请讲解 LoRA 微调的原理:与全量微调相比有什么不同?你有试过全量微调吗?SFT(监督微调)阶段的数据集格式是什么?system prompt 是如何设计的?
LoRA(Low-Rank Adaptation)是一种高效微调大模型的技术,核心思想是通过低秩矩阵分解减少微调时的参数量,在保持模型性能的同时降低计算成本。其原理及相关问题如下:
LoRA 微调的原理:预训练大模型(如 GPT、LLaMA)的参数规模通常数十亿甚至千亿,全量微调需更新所有参数,成本极高。LoRA 冻结预训练模型的所有权重,仅在特定层(如 Transformer 的注意力层)插入可训练的低秩矩阵。具体而言,对模型中原本的权重更新 ΔW,LoRA 将其分解为 ΔW = BA,其中 B 是输入维度 × 秩(rank)的矩阵,A 是秩 × 输出维度的矩阵,秩远小于输入 / 输出维度(如设为 8-32)。训练时仅更新 B 和 A,推理时将 ΔW 与原权重 W 合并,不增加额外计算量。这种低秩分解使参数量从 O (d²) 降至 O (d×rank)(d 为维度),大幅降低内存和计算需求。
与全量微调的不同:
- 参数量:全量微调需更新模型所有参数(如 7B 模型约 70 亿参数),LoRA 仅需更新低秩矩阵(通常数百万参数),参数量减少 1-2 个数量级。
- 计算资源:全量微调需多卡高性能 GPU(如 8×A100),LoRA 单卡即可完成,适合资源有限场景。
- 过拟合风险:全量微调在小数据集上易过拟合(参数多、数据少),LoRA 因参数少更稳健。
- 泛化能力:全量微调可能过度拟合特定任务,LoRA 保留预训练模型的通用知识,泛化性更好。
- 推理效率:全量微调后模型结构不变,LoRA 推理时需合并低秩矩阵,两者效率接近,但 LoRA 保存模型时仅需存储低秩矩阵,节省空间。
全量微调的实践:在实际项目中,曾在较小模型(如 1.3B 参数的 LLaMA 变体)上尝试全量微调。使用约 10 万条对话数据,在 4×V100 GPU 上训练,发现需严格控制学习率(如 2e-5)和 epoch 数(3-5 轮),否则易出现过拟合(训练损失下降但验证集困惑度上升)。相比之下,相同数据量下 LoRA 微调收敛更快,且验证集性能更稳定。
SFT 阶段的数据集格式:通常为结构化的对话格式,包含输入(用户 query)、输出(模型 response),部分包含 system prompt。常见格式如下:
[
{
"system": "你是一名客服助手,需礼貌解答用户关于产品的问题",
"conversations": [
{"from": "user", "value": "这款手机支持5G吗?"},
{"from": "assistant", "value": "是的,该型号手机支持全网通5G网络,包含n1/n2/n5等主流频段。"}
]
},
...
]数据需清洗去重,确保输出符合任务要求(如格式正确、无敏感信息),并覆盖任务的多样化场景(如不同用户意图、边缘案例)。
system prompt 的设计:用于定义模型的角色、行为准则和输出格式,是引导模型对齐任务需求的关键。设计原则包括:
- 明确角色:如 "你是一名法律顾问,专注于合同法",让模型定位清晰。
- 规定约束:如 "回答需引用具体法条,不编造法律条款",限制不当输出。
- 规范格式:如 "用分点列出答案,每点不超过 20 字",确保输出结构化。
- 适配场景:如客服场景强调 "语气友好,避免使用专业术语",技术场景则要求 "详细解释原理"。
面试关键点:需讲清 LoRA 的低秩分解核心;对比全量微调时突出参数量和资源差异;明确 SFT 数据的对话结构;说明 system prompt 的角色与约束作用。
记忆法:"LoRA 分解低秩矩阵,冻结原参省资源;全量微调更灵活,数据少易过拟合;SFT 数据对话式,system prompt 定角色"。
如何评价模型微调的效果?有没有对比过微调前后的效果?请讲解模型推理采样过程中的各种参数(如 top-p、top-k、temperature),以及温度参数(temperature)的作用(可结合简单代码实现说明)。
评价模型微调效果需从定量指标、定性分析和实际应用场景多维度考量,而推理采样参数直接影响模型输出的质量和多样性,具体如下:
模型微调效果的评价方法:
- 定量指标:根据任务类型选择指标。生成任务常用困惑度(Perplexity,越低越好,衡量模型对文本的预测能力)、BLEU/Rouge(评估与参考文本的相似度);分类任务用准确率、F1 值;对话任务用 PPL、人工评估打分(如相关性、流畅度)。例如,微调后情感分析模型的 F1 值从 0.75 提升至 0.88,说明效果改善。
- 定性分析:随机抽取样本人工检查,关注输出的逻辑性、一致性和相关性。如客服对话模型微调后,能否准确理解模糊查询(如 "这个东西怎么用")并给出针对性回答,而非泛泛而谈。
- 鲁棒性测试:用对抗样本(如错别字、复杂句式)检验模型稳定性。例如,微调后的翻译模型在输入 "我明天想去 shang 海" 时,能否正确识别 "shang 海" 为 "上海"。
- 过拟合检查:对比训练集和验证集指标,若训练集指标远优于验证集(如 PPL 相差 10 以上),可能存在过拟合。
微调前后的效果对比:在某医疗问答项目中,对比微调前后的 LLaMA 模型:
- 微调前:依赖通用知识,对专业术语(如 "心肌梗死")解释模糊,常出现错误(如混淆 "溶栓" 和 "搭桥" 手术),验证集 PPL 为 65。
- 微调后:用 5 万条医疗问答数据微调,专业术语解释准确率提升 40%,错误率下降至 5% 以下,验证集 PPL 降至 32,且能结合临床指南给出建议,人工评估分数从 3.2/5 提升至 4.5/5。
推理采样参数:大模型生成文本时,通过采样从概率分布中选择下一个词,核心参数包括:
- top-k:仅保留概率最高的 k 个词作为候选(如 k=50),过滤低概率词,减少无意义输出。适用于需要稳定输出的场景(如客服回复),但 k 过小时可能限制多样性(如 k=1 时为贪心搜索)。
- top-p(核采样):累积概率达到 p 的词被保留(如 p=0.9),动态调整候选词数量(高概率词少则保留更多,反之则少)。相比 top-k 更灵活,平衡多样性和相关性,适合创意生成(如写诗)。
- temperature(温度):控制概率分布的 "陡峭度",公式为 softmax (logits /temperature)。温度越低(如 0.1),高概率词被选中的概率越高,输出更确定、集中;温度越高(如 1.5),概率分布越平缓,低概率词也可能被选中,输出更多样、随机,甚至出现错误。
温度参数的作用及代码示例:温度通过缩放 logits 影响 softmax 输出,直接控制随机性。代码示例:
import torch
import torch.nn.functional as F
def sample_next_token(logits, temperature=1.0, top_k=50, top_p=0.9):
# logits: (1, vocab_size),模型输出的未归一化概率
if temperature == 0:
# 温度为0时取概率最高的词(贪心搜索)
return torch.argmax(logits, dim=-1).item()
# 应用温度缩放
scaled_logits = logits / temperature # 温度越高,logits差异越小
probs = F.softmax(scaled_logits, dim=-1) # 转换为概率分布
# top-k过滤
if top_k > 0:
top_k_probs, top_k_indices = torch.topk(probs, top_k)
# 只保留top-k的概率,其余设为0
probs = torch.zeros_like(probs).scatter_(1, top_k_indices, top_k_probs)
# top-p过滤
if top_p < 1.0:
sorted_probs, sorted_indices = torch.sort(probs, descending=True)
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 找到累积概率超过top-p的位置
keep_mask = cumulative_probs <= top_p
# 至少保留一个词
keep_mask[0, 0] = True
# 过滤概率
sorted_probs = sorted_probs * keep_mask.float()
sorted_probs = sorted_probs / sorted_probs.sum() # 重新归一化
# 采样
next_token_idx = torch.multinomial(sorted_probs, num_samples=1).item()
return sorted_indices[0, next_token_idx].item()
# 直接从概率分布采样
return torch.multinomial(probs, num_samples=1).item()
# 示例:模型输出的logits
logits = torch.tensor([[3.0, 2.0, 1.0, 0.5, 0.1]]) # 假设5个词的logits
# 温度=0.1:高概率词(第一个)被选中的概率极高
print(sample_next_token(logits, temperature=0.1)) # 大概率输出0(第一个词)
# 温度=2.0:概率分布平缓,低概率词也可能被选中
print(sample_next_token(logits, temperature=2.0)) # 可能输出1、2甚至3代码中,温度为 0.1 时,第一个词的概率被显著放大,输出更确定;温度为 2.0 时,各词概率差异缩小,输出更随机。
面试关键点:评价效果需结合定量与定性指标;对比微调前后要具体说明指标变化;采样参数需解释作用及适用场景;温度参数要结合 softmax 公式说明对随机性的影响。
记忆法:"评价效果看定量(指标)定性(人工),微调前后比指标(如 PPL)和鲁棒性;采样参数 top-k 定数量,top-p 控累积,温度调随机(低确定高多样)"。
请讲解 RLHF(基于人类反馈的强化学习)的原理。
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是对齐大模型与人类偏好的核心技术,通过人类反馈指导模型优化,使输出更符合人类价值观(如 helpful、honest、harmless)。其原理分为三个核心阶段,形成 "监督微调→奖励建模→强化学习" 的闭环:
第一阶段:监督微调(SFT,Supervised Fine-Tuning)
目标是让模型初步学习基本任务能力,生成符合人类预期的初始输出。
- 过程:收集高质量的人工标注对话数据(如用户查询与理想回复),用这些数据微调预训练语言模型(如 GPT-3)。例如,对 "如何缓解头痛?",人工提供包含 "休息、补水、避免强光" 等安全建议的回复,训练模型生成类似内容。
- 作用:使模型掌握任务的基本格式和规范(如对话连贯性、相关性),为后续强化学习提供初始 "策略模型"(Policy Model)。此时模型的输出虽符合基本要求,但可能缺乏对复杂人类偏好的理解(如更倾向简洁还是详细的回答)。
第二阶段:奖励模型训练(Reward Model Training)
目标是将人类偏好量化为可优化的奖励信号,训练一个能评估输出质量的奖励模型(RM)。
- 过程:1. 让 SFT 模型对同一查询生成多个不同输出(如 3-5 个回复);2. 人类标注员对这些输出按偏好排序(如 A 优于 B 优于 C)或直接打分(如 1-5 星),标注依据包括相关性、安全性、帮助性等;3. 用这些排序 / 打分数据训练奖励模型,输入为 "查询 + 输出",输出为一个标量奖励值(越高表示越符合人类偏好)。
- 关键:奖励模型需学习人类偏好的潜在模式(如 "避免偏见""提供具体步骤"),而非简单记住标注数据。例如,对医疗建议,奖励模型应给包含 "咨询医生" 提示的回复更高分数,体现安全性偏好。
第三阶段:强化学习(RL,Reinforcement Learning)
目标是通过奖励模型的反馈,优化策略模型,使其输出更符合人类偏好。
- 核心算法:PPO(Proximal Policy Optimization,近端策略优化),一种稳定高效的强化学习算法,通过限制策略更新幅度避免训练不稳定。
- 过程:1. 策略模型根据输入生成输出(如回答用户问题);2. 奖励模型对输出打分,得到奖励值;3. 引入 "KL 散度惩罚项"(限制新策略与 SFT 模型的差异,避免输出偏离基本能力);4. PPO 根据 "奖励值 - KL 惩罚" 更新策略模型参数,最大化累积奖励。
- 迭代:重复生成 - 评估 - 更新过程,使策略模型逐渐学会生成奖励模型打分高的输出(即更符合人类偏好的内容)。
额外阶段:迭代优化与红队测试
为进一步提升安全性,RLHF 通常包含多轮迭代:用优化后的模型生成更多样本,由人类标注新的偏好数据,更新奖励模型,再用新奖励模型继续强化学习。同时,通过 "红队测试"(让人类尝试诱导模型生成有害内容)发现漏洞,针对性优化奖励模型(如提高对有害输出的惩罚)。
例如,在聊天机器人对齐任务中:SFT 阶段让模型学会基本对话;奖励模型训练时,人类偏好 "友好且信息准确" 的回复,给这类输出高分;RL 阶段通过 PPO 优化,使模型逐渐倾向于生成友好且准确的回复,减少敷衍或错误内容。
面试关键点:需明确三阶段的递进关系(SFT 打基础→RM 量化偏好→RL 优化策略);解释 PPO 和 KL 惩罚的作用(稳定训练、保留基础能力);说明人类反馈在各阶段的具体作用(数据标注、偏好排序)。
记忆法:"RLHF 三阶段,SFT 初调教,RM 定好坏(奖励),RL 用 PPO 调策略,人类反馈贯全程,对齐偏好靠闭环"。
你在项目中使用 RAG(检索增强生成)时遇到过哪些困难?目前 RAG 存在哪些痛点?
在多个基于 RAG 的项目(如企业知识库问答、医疗文献检索问答)中,遇到过诸多实践困难,这些困难也反映了当前 RAG 技术的核心痛点,具体如下:
项目中遇到的困难:
- 检索准确性不足:在某法律知识库项目中,用户查询 "劳动合同解除的赔偿标准" 时,检索系统常返回包含 "劳动合同" 但无关 "解除赔偿" 的文档(如 "劳动合同签订流程"),原因是关键词匹配过度依赖字面相似,忽略语义关联。即使使用向量检索(如 Sentence-BERT),仍因法律术语的歧义性(如 "补偿" 与 "赔偿" 的细微差异)导致召回率低。
- 文档分割不合理:处理长文档(如 50 页的技术手册)时,简单按固定长度(如 500 字)分割会破坏语义完整性。例如,某段关于 "设备维护步骤" 被分割成两部分,检索到的片段仅包含前 3 步,导致模型生成的回答不完整。尝试按段落或章节分割,但部分文档格式混乱(如无明显分段),效果不佳。
- 多轮对话中历史信息利用不足:在客服 RAG 系统中,用户先问 "产品保修期多久",再问 "那过保后维修收费吗",系统未能关联历史对话中的 "产品" 信息,重新检索时返回全品类维修政策,而非针对用户询问的特定产品,导致回答偏离上下文。
- 领域知识适配差:在医疗 RAG 项目中,通用向量模型(如 all-MiniLM-L6-v2)对专业术语(如 "心肌梗死""PCI 手术")的嵌入效果差,检索时难以匹配相关文献。虽尝试用领域数据微调向量模型,但标注数据少(医疗数据隐私限制),微调后提升有限。
- 幻觉生成未完全解决:即使检索到相关文档,模型仍可能生成文档外信息。例如,文档明确 "该药物适用于成人",但模型生成 "适用于成人及 6 岁以上儿童",推测是模型的预训练知识(部分药物可用于儿童)干扰了检索结果的利用。
当前 RAG 的核心痛点:
- 检索与生成的脱节:检索系统和生成模型是 "两张皮",生成模型难以判断检索结果的相关性,即使检索到噪声也会强行利用,导致输出错误。
- 长文档处理效率低:对超过向量模型输入长度的文档(如 1 万字报告),分割策略会显著影响效果,且现有方法(如递归分割、滑动窗口)均无法完美保留语义完整性。
- 实时性与成本矛盾:为提升检索速度,需使用向量数据库(如 Milvus、Pinecone),但大规模数据的存储和索引成本高;若降低向量维度或减少索引精度,又会牺牲检索准确性。
- 评估标准缺失:RAG 效果缺乏统一评估指标,现有方法(如 BLEU、ROUGE)难以衡量 "检索结果的相关性" 和 "生成内容与检索的一致性",人工评估成本高且主观性强。
- 多模态支持薄弱:当前 RAG 主要处理文本,对图像、表格、PDF 中的复杂格式(如公式、流程图)支持不足,无法检索包含多模态信息的知识(如产品手册中的电路图)。
- 领域适配门槛高:通用向量模型在垂直领域(如法律、医疗)表现差,而领域专属模型的训练需要大量标注数据和专业知识,中小企业难以负担。
面试关键点:需结合具体项目场景说明困难(如法律、医疗领域的特殊性);痛点分析要区分技术层面(检索、分割)和工程层面(成本、评估);可提及潜在解决方案(如混合检索、领域微调)但不偏离 "困难与痛点" 核心。
记忆法:"RAG 困难多,检索不准分割乱,多轮对话失上下文,领域适配难;痛点更突出,检索生成两张皮,长文处理效率低,评估成本高"。
LLM(大语言模型)部署时会遇到哪些问题?
LLM(大语言模型)部署是将预训练或微调后的模型推向实际应用的关键环节,受模型规模、硬件限制、性能需求等因素影响,会面临一系列技术和工程挑战,具体如下:
计算资源需求巨大,成本高昂:大模型参数规模从数十亿到万亿级(如 GPT-3 有 1750 亿参数),部署时需高性能硬件支持。例如,7B 参数模型需至少 16GB 显存(FP16 精度),175B 模型则需 TB 级显存,通常依赖多卡 GPU(如 A100、H100)或专用加速芯片(如 TPU)。单卡 A100 的成本约 10 万元,一个 175B 模型的部署集群可能需要数十甚至上百张卡,初期投入和长期运维(电力、冷却)成本极高,中小企业难以承担。此外,模型加载和初始化耗时(如 7B 模型加载需数分钟),影响服务启动速度。
推理速度慢,难以满足实时需求:LLM 生成文本是串行过程(自回归生成,每个 token 依赖前序 token),且注意力机制的计算复杂度为 O (n²)(n 为序列长度),导致长文本生成耗时显著增加。例如,生成 1000 字的回答,7B 模型在单卡 V100 上可能需要 10-20 秒,远超过用户可接受的实时响应阈值(通常 < 3 秒)。即使采用优化技术(如模型并行、张量并行),在高并发场景(如同时处理 1000 个用户请求)下,仍可能出现排队延迟,影响用户体验。
内存与存储限制:模型参数和中间激活值对内存需求极高。以 FP16 精度为例,175B 参数模型需 350GB 内存(1750 亿 ×2 字节),若用 FP32 则需 700GB。实际推理时,除参数外,还需存储输入序列、注意力矩阵等中间数据,内存消耗进一步增加。虽可通过量化(如 INT8、INT4)减少内存占用(INT4 可将内存需求降至 FP16 的 1/4),但过度量化会导致精度损失(如输出错误或重复内容),需在精度和内存间权衡。此外,模型文件体积大(如 7B 模型的 FP16 权重约 13GB),存储和传输成本高,尤其在边缘设备(如手机)上部署几乎不可行。
模型优化与兼容性问题:不同框架(如 PyTorch、TensorFlow、Megatron-LM)训练的模型需适配部署环境,转换过程中可能出现兼容性问题(如算子不支持)。为提升推理速度,需采用优化技术(如 Flash Attention 加速注意力计算、KV 缓存复用前序 token 的键值对),但这些优化依赖特定硬件和软件栈(如 CUDA 版本、cuDNN 库),适配难度大。例如,Flash Attention 在 A100 上性能提升显著,但在 older GPU(如 V100)上可能因架构不支持而失效。
并发与负载均衡挑战:实际应用中,用户请求具有突发性(如峰值时段请求量是均值的 10 倍),需设计弹性伸缩的部署架构。但 LLM 的推理任务占用资源多、持续时间长,传统的负载均衡策略(如轮询)可能导致部分节点过载,而其他节点空闲。此外,不同请求的序列长度差异大(如短查询 vs 长文档生成),资源分配难以精细化,可能出现 "长请求阻塞短请求" 的情况,降低整体服务效率。
安全性与合规性风险:部署后需防范模型滥用(如生成有害内容、虚假信息),但大模型的输出具有不确定性,即使经过对齐训练,仍可能被诱导生成违规内容。此外,用户输入数据(如个人信息、商业秘密)在传输和处理过程中需符合数据隐私法规(如 GDPR、个人信息保护法),但模型推理过程中可能缓存输入数据,存在隐私泄露风险。同时,开源模型的部署需遵守许可证要求(如商业使用限制),避免法律纠纷。
面试关键点:需从资源、性能、技术、合规多维度分析;说明量化、并行等优化技术的局限性;结合实际场景(如实时对话、高并发服务)解释挑战;提及成本与效果的平衡问题。
记忆法:"LLM 部署难,资源成本高(硬件贵),推理速度慢(串行生成),内存限制严(参数大),优化兼容烦(框架适配),并发均衡难(负载波动),安全合规险(内容与隐私)"。
你对前沿技术的发展有何看法(如 DeepSeek、长思维链等)?
前沿技术如 DeepSeek 等大模型及长思维链(Chain-of-Thought, CoT)等方法的发展,正推动人工智能从 "模式匹配" 向 "类推理能力" 跨越,同时也面临效率、可解释性等核心挑战,具体看法如下:
DeepSeek 等垂直领域大模型的突破:以 DeepSeek 为代表的国产大模型,在技术路径上呈现 "通用基础 + 领域深耕" 的特点。与通用大模型(如 GPT-4)相比,其优势在于针对特定场景(如代码生成、数学推理)优化:通过领域专属数据微调(如海量代码库、数学公式推导样本)和模型结构调整(如增强逻辑推理层),在垂直任务上实现 "小参数量、高性能"。例如,DeepSeek-Math 在数学竞赛数据集上的准确率超过部分通用大模型,证明垂直优化的价值。这类模型降低了企业使用门槛 ------ 无需承担千亿参数模型的部署成本,却能在专业场景(如金融风控、工程计算)中达到实用精度,推动 AI 在产业中的落地。
长思维链(CoT)带来推理能力革新:CoT 通过引导模型生成 "中间推理步骤"(如 "要解决这个问题,首先需要计算 A,然后推导 B,最后得到 C"),显著提升复杂任务(如数学题、逻辑推理)的性能。其核心逻辑是将多步推理拆解为可解释的子步骤,使模型能像人类一样 "逐步思考"。例如,解决 "甲有 5 个苹果,乙比甲多 3 个,丙是乙的 2 倍,丙有多少个?" 时,CoT 会让模型先输出 "乙有 5+3=8 个,丙有 8×2=16 个",再给出答案,准确率远高于直接输出结果。进一步发展的 "思维链微调"(如 Fine-tuning with CoT 数据)使模型能自主生成推理步骤,无需人工提示,适用场景从问答扩展到决策支持(如医疗诊断路径规划)。
技术融合与潜在挑战:前沿技术正呈现 "模型小型化 + 能力模块化" 的趋势。例如,将 CoT 与检索增强(RAG)结合,模型可先检索相关知识(如公式、法条),再通过推理链整合信息,提升复杂问题的解决能力;将 DeepSeek 等垂直模型作为 "专家模块" 接入通用大模型,形成 "混合专家系统"(MoE),兼顾通用能力与专业精度。但挑战依然突出:一是效率问题,CoT 增加了生成长度,推理速度降低 30%-50%,需通过蒸馏(如提取 CoT 的关键步骤)或量化压缩优化;二是可解释性局限,模型的推理步骤可能存在 "伪逻辑"(步骤错误但结论正确),难以用于高风险场景(如司法判决);三是数据依赖,垂直模型和 CoT 的效果高度依赖高质量标注数据,低资源领域(如小众语言、冷门专业)的发展受限。
未来方向:技术发展将更注重 "实用化" 与 "可控性"。一方面,通过动态路由(如根据任务难度调整模型规模)和硬件适配(如专用 AI 芯片优化推理)提升效率;另一方面,通过因果推理融入和人类反馈强化(RLHF),使模型的推理过程更符合人类逻辑,减少偏见与错误。对于从业者,理解垂直模型的领域适配方法、掌握 CoT 等推理增强技术,将成为核心竞争力。
面试关键点:需区分通用与垂直模型的差异;解释 CoT 的推理机制及适用场景;分析技术融合的潜力与挑战;提及效率优化和可控性的重要性。
记忆法:"前沿技术两方向,垂直模型深领域,长思维链强推理;融合提能亦有难,效率可解释待突破,实用可控是未来"。
分布式架构的相关知识及你的实践经验是什么?
分布式架构是应对大规模数据处理和高并发服务的核心技术,通过将任务拆分到多个节点协同完成,实现高效、可靠、可扩展的系统运行。其核心知识及实践经验如下:
分布式架构的核心知识:
-
核心目标:解决单节点在计算能力、存储容量、并发处理上的瓶颈,通过 "分而治之" 实现高可用(节点故障不影响整体)、高扩展(按需增加节点)、高性能(并行处理任务)。
-
关键组件:
- 分布式计算:将任务拆分为子任务,分配到多个节点并行计算(如 MapReduce 的 "映射 - 归约"、Spark 的弹性分布式数据集 RDD)。
- 分布式存储:数据分片存储在多个节点,通过冗余备份保证可靠性(如 HDFS 将文件分成块,每个块存 3 个副本;分布式数据库如 Cassandra 的一致性哈希)。
- 通信与协调:节点间通过网络通信(如 RPC 远程过程调用),依赖协调服务(如 ZooKeeper)管理节点状态、选举主节点、维护配置一致性。
- 一致性算法:解决分布式系统中 "数据同步" 问题,如 Paxos(通过提案 - 批准机制达成一致)、Raft(简化 Paxos,通过领导者选举、日志复制实现强一致性)。
- 负载均衡:将请求均匀分配到节点,避免单点过载(如 Nginx 的轮询、加权轮询;Kubernetes 的服务发现与负载均衡)。
-
常见挑战:网络延迟(节点通信耗时)、数据一致性(多节点数据同步冲突)、容错处理(节点崩溃或网络分区)、 CAP 定理限制(无法同时满足一致性、可用性、分区容错性,需根据场景取舍)。
实践经验 :
在某电商平台的用户行为分析项目中,需处理每日 10TB 的日志数据(包含点击、购买等行为),并支持实时查询(如 "过去 1 小时某商品的点击量"),采用分布式架构解决:
- 数据处理层:用 Spark 分布式计算框架,将日志按时间分片(每小时一个批次),Map 阶段解析日志提取用户 ID、商品 ID、行为类型,Reduce 阶段聚合各商品的行为次数。通过 YARN 进行资源调度,动态分配 50 个 Executor 节点(每个 8 核 16GB 内存),将单日数据处理时间从单节点的 12 小时缩短至 40 分钟。
- 存储层:用 HDFS 存储原始日志(块大小 128MB,3 副本冗余),用 HBase 存储聚合结果(按商品 ID 和时间戳建表,支持随机查询)。遇到的问题:HDFS 小文件过多(每小时生成 thousands 个日志文件)导致 NameNode 内存压力大,通过 "小文件合并"(将 1 小时内的小文件合并为 1 个大文件)解决。
- 实时查询层:用 Kafka 接收实时日志,Flink 进行流处理(每秒处理 10 万 + 条数据),结果写入 Redis 缓存,支持毫秒级查询。曾因 Kafka 分区不均(某分区数据量是其他的 5 倍)导致消费延迟,通过 "重新分区"(按商品 ID 哈希分配分区)平衡负载。
- 协调与监控:用 ZooKeeper 管理 Spark、Flink 的集群状态,监控节点存活;用 Prometheus+Grafana 监控各节点 CPU、内存、网络使用率,设置告警(如节点负载超过 80% 时自动扩容)。一次因网络分区导致部分节点失联,ZooKeeper 通过领导者选举重新组织集群,未造成数据丢失。
在大模型部署项目中,采用分布式推理架构:将 13B 参数模型按层拆分到 4 张 GPU(张量并行),请求到来时各卡并行计算,通过 NCCL 通信库交换中间结果,将单卡推理延迟从 5 秒降至 1.2 秒,支持每秒 50 + 并发请求。
面试关键点:需掌握分布式架构的核心组件和挑战;结合具体项目说明技术选型(如 Spark、HDFS)和问题解决;理解一致性算法和负载均衡的实际应用。
记忆法:"分布式架构分而治,计算存储加通信;Paxos/Raft 保一致,负载均衡防过载;实践多遇数据均、节点错,调优分片与监控"。
请讲解数据集的制作和处理流程:是否进行过数据清理和筛选?数据总量均分到每个角色上是否会偏少?对于数据分布不均衡的情况,处理方式是什么?
数据集的制作和处理是模型训练的基础,直接影响模型性能,其流程涵盖从数据收集到预处理的全链条,具体如下:
数据集的制作和处理流程:
- 数据收集:根据任务目标确定数据源,如文本分类可收集网页、书籍、用户生成内容(UGC);命名实体识别可采集新闻、论文等带实体标注的文本。收集方式包括公开数据集下载(如 GLUE、CoNLL)、爬虫爬取(需遵守 robots 协议和隐私法规)、业务系统导出(如企业内部日志)。例如,在情感分析项目中,从电商平台爬取商品评论,同时记录评分(作为情感标签)。
- 数据清洗:去除无效或干扰数据,核心操作包括:1. 去重(删除重复样本,如同一评论被多次爬取);2. 格式统一(如将 "1 星""★" 统一转换为标签 "负面");3. 噪声去除(删除含乱码、特殊符号过多的样本,如 "@#¥%......");4. 敏感信息脱敏(替换手机号、身份证号为 "MASK");5. 缺失值处理(删除关键信息缺失的样本,如无评分的评论;或填充默认值,如用 "未知" 填充缺失的用户性别)。
- 数据标注:为无标签数据添加标签,可人工标注(适合小数据集、高精度要求,如医疗实体标注)或半自动标注(用预训练模型初标,人工修正,提升效率)。标注需制定清晰规则(如定义 "正面情感" 包含 "满意""推荐" 等词),并通过交叉验证(多人标注同一批数据,计算一致性)保证质量。
- 数据筛选:根据任务需求筛选高质量样本,如情感分析中剔除 "中立且无实质内容" 的评论(如 "还行");文本生成中保留逻辑连贯、长度适中(如 50-500 字)的样本,过滤过短(如 "好")或过长(如 10000 字冗余文本)的内容。
- 数据划分:将数据集分为训练集(70%-80%,用于模型训练)、验证集(10%-15%,调整超参数)、测试集(10%-15%,评估最终性能),划分时需保持分布一致(如各集合中正负样本比例相同)。
数据总量均分到每个角色上是否会偏少?
需结合 "角色的重要性" 和 "数据需求" 判断,而非简单均分。例如,在多轮对话数据集中,"用户" 和 "助手" 是核心角色,若总数据 10 万条,均分后各 5 万条,通常足够;但如果存在 "系统提示"(system prompt)这一角色(占比低,如仅 1 万条),均分至 10 万 / 3≈3.3 万条反而不合理 ------ 系统提示的功能是定义助手角色,无需过多样本,过量可能引入噪声。
关键原则:1. 核心角色(直接影响任务的角色)需保证数据量(如客服对话中的 "用户查询" 和 "客服回复");2. 次要角色(辅助性角色)按实际需求分配,避免为均分而稀释核心数据;3. 若角色间存在依赖(如 "用户问题"→"助手回答"),需保持配对关系,不可强行拆分均分。
数据分布不均衡的处理方式 :
数据不均衡指某类样本占比过高(如 90%),其他类占比低(如 10%),导致模型偏向多数类。处理方法包括:
- 采样法:1. 过采样(增加少数类样本),如 SMOTE 算法(为少数类样本生成相似的合成样本,避免过拟合);2. 欠采样(减少多数类样本),如随机删除多数类样本,或聚类后保留代表性样本(如 K-means 聚类多数类,取每个簇的中心样本)。
- 算法优化:1. 加权损失函数(为少数类赋予更高权重,如交叉熵损失中设置 class_weight);2. 集成学习(如用多个模型分别关注不同类别,再融合结果)。
- 数据增强:为少数类样本生成变体,如文本任务中通过同义词替换、句式变换增加样本(如 "我喜欢这个产品"→"这个产品我很喜欢")。
代码示例(SMOTE 过采样):
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成不均衡数据(少数类占10%)
X, y = make_classification(n_samples=1000, n_classes=2, weights=[0.9], random_state=42)
print("原始数据分布:", {0: sum(y==0), 1: sum(y==1)}) # 0:900, 1:100
# 划分训练集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 应用SMOTE
smote = SMOTE(random_state=42)
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
print("SMOTE后分布:", {0: sum(y_train_resampled==0), 1: sum(y_train_resampled==1)}) # 大致720:720面试关键点:需详细说明数据处理的全流程;解释角色数据分配的原则(非均分,按需分配);掌握不均衡数据的多种处理方法(采样、加权、增强)并说明适用场景。
记忆法:"数据流程收、清、标、筛、分,清洗去重脱敏补缺失;角色数据不均分,核心角色保数量;不均处理采样本(过 / 欠采样)、调损失(加权)、增数据(增强)"。
你选择的模型基座是什么?对基座规模进行过筛选吗?
模型基座的选择需结合任务类型、数据规模、计算资源和性能需求综合决策,而基座规模的筛选则是平衡效果与成本的关键步骤,具体如下:
模型基座的选择依据 :
选择基座的核心标准是 "任务适配性",不同类型的任务适合不同架构的基座:
- 文本分类、命名实体识别等判别式任务:优先选择 BERT 系列(如 BERT-base、RoBERTa),其双向 Transformer 结构能有效捕捉上下文语义,适合抽取文本中的局部特征(如实体、情感词)。例如,在新闻分类任务中,RoBERTa 通过预训练学习的词级语义关联,能快速识别 "政治""经济" 等主题关键词。
- 文本生成、对话等生成式任务:倾向选择 GPT 系列、LLaMA 系列、BART 等,其自回归生成能力(从左到右生成文本)更符合生成任务的逻辑。例如,客服对话系统采用 LLaMA-7B,能基于用户查询生成连贯的回复,且支持多轮对话的上下文关联。
- 跨语言或低资源任务:选用 XLM-RoBERTa(支持 100 + 语言)、mT5 等多语言模型,其预训练数据涵盖多语言语料,能通过跨语言知识迁移提升低资源语言的性能。例如,在东南亚小语种的情感分析中,XLM-RoBERTa 的表现远超单语言模型。
- 垂直领域任务:若有领域专属基座(如医疗领域的 BioBERT、法律领域的 LegalBERT),优先选择 ------ 这些模型在领域语料上预训练,已学习专业术语和领域知识,微调后性能通常优于通用基座。例如,医疗命名实体识别中,BioBERT 对 "心肌梗死""PCI 手术" 等术语的识别准确率比 BERT 高 15%-20%。
基座规模的筛选实践 :
模型规模(参数量)直接影响性能、计算成本和推理速度,筛选需通过 "小规模测试→性能评估→成本核算" 的流程:
- 初步筛选:根据资源上限确定规模范围。例如,单卡 16GB GPU 可支持 7B 参数模型(FP16 精度约 13GB),但无法运行 13B 模型(约 26GB),因此优先在 7B 及以下规模中筛选。
- 性能评估 :在验证集上比较不同规模基座的核心指标。例如,在某产品评论情感分析任务中,测试了三个规模的 LLaMA 变体:
- LLaMA-1.3B:训练速度快(单卡 3 小时),准确率 0.82,但对模糊表达(如 "还行吧")的判断错误率高;
- LLaMA-7B:训练时间 8 小时,准确率 0.88,对模糊表达的识别能力提升,错误率降低 60%;
- LLaMA-13B:需多卡训练(2×16GB GPU),时间 15 小时,准确率 0.89,仅比 7B 高 1%,但推理速度慢 30%。
最终选择 7B 模型,在性能与成本间取得平衡。
- 场景适配性:实时性要求高的场景(如客服对话,响应时间需 < 2 秒)优先选择小模型(如 1.3B、7B);离线任务(如文档分类,无实时要求)可选用大模型(如 13B、70B)追求高精度。例如,新闻推荐系统的实时分类模块用 BERT-base(110M 参数),而离线的深度内容分析用 BERT-large(340M 参数)。
- 数据量匹配:小规模数据(如 1 万条以下)用大模型易过拟合(如 70B 模型在 1 万条数据上训练,验证集准确率波动大),适合用小模型(如 BERT-base);大规模数据(如 100 万条)可支撑大模型充分学习,发挥其容量优势。
面试关键点:需说明基座选择的核心标准(任务适配性);结合具体任务和资源约束讲解规模筛选的流程;强调 "性能 - 成本 - 实时性" 的权衡逻辑。
记忆法:"基座选择看任务,判别用 BERT,生成选 GPT;规模筛选按资源,小测评性能,平衡效与本;数据多少配规模,小数据用小模防过拟合"。
命名实体识别的应用场景有哪些?模型的泛化能力如何?
命名实体识别(Named Entity Recognition, NER)是从文本中提取具有特定意义的实体(如人名、地名、组织名、时间、专业术语等)的技术,其应用场景广泛,而模型的泛化能力则决定了其在不同场景中的适用范围,具体如下:
命名实体识别的应用场景:
- 信息抽取与知识图谱构建:从非结构化文本中抽取实体及关系,构建结构化知识图谱。例如,从新闻中提取 "苹果公司""蒂姆・库克""CEO",形成 "苹果公司 - CEO - 蒂姆・库克" 的三元组关系,用于知识检索(如 "苹果公司的 CEO 是谁")和智能问答。
- 智能客服与对话系统:识别用户查询中的关键实体(如产品名、订单号、时间),精准定位问题。例如,用户说 "我想查询订单 12345 的物流",NER 识别出 "订单 12345",系统直接调取该订单的物流信息,避免无效交互。
- 舆情分析与监控:在社交媒体、论坛中识别提及的实体(如品牌名、事件名),分析公众态度。例如,从 "某奶茶品牌使用过期原料" 的微博中识别 "某奶茶品牌",追踪相关舆情的传播范围和情感倾向(负面),帮助企业及时应对危机。
- 机器翻译与跨语言处理:识别专有名词(如人名、地名),保证翻译一致性。例如,"北京" 在英语中需译为 "Beijing" 而非意译,NER 可标记这类实体,确保翻译准确。
- 医疗与法律文本处理:在医疗记录中识别 "疾病名""药物名""症状"(如 "患者患肺癌,服用奥希替尼"),辅助临床决策或病历结构化;在法律文书中识别 "当事人""法条编号"(如 "张三违反《民法典》第 1043 条"),提高法律检索效率。
- 金融风险控制:从财报、新闻中识别 "公司名""金额""事件"(如 "某公司亏损 5000 万"),评估企业信用风险;识别 "诈骗""洗钱" 等实体,辅助反欺诈系统。
模型的泛化能力及影响因素 :
NER 模型的泛化能力指模型在未见过的数据(如新领域、新实体类型)上的表现,受以下因素影响:
- 训练数据的多样性:若训练数据仅包含新闻领域的实体,模型在医疗文本上的泛化能力差(如无法识别 "心肌梗死" 这类医疗实体)。反之,用多领域数据(新闻、医疗、法律)训练的模型,泛化能力更强。
- 实体类型的覆盖度:训练数据中包含的实体类型越全面(如不仅有人名、地名,还有产品名、事件名),模型对罕见实体类型的识别能力越好。例如,训练过 "电影名" 实体的模型,能更快适应 "书名" 的识别(两者均为作品名,特征相似)。
- 领域适配方法:通过领域自适应技术可提升泛化能力,如:1. 领域微调(用目标领域的少量标注数据微调模型);2. 领域对抗训练(使模型学习领域无关的实体特征);3. 数据增强(为目标领域生成类似样本,如将 "张三得了肺炎" 改为 "李四患了肺癌",保留实体结构)。
- 模型架构:基于预训练语言模型(如 BERT、XLNet)的 NER 模型,因预训练阶段学习了通用语言知识,泛化能力远优于传统模型(如 CRF、BiLSTM)。例如,BERT 在低资源领域(如古籍中的人名识别)的表现,通常比 BiLSTM 高 10%-20%。
实际表现中,模型在 "同领域新实体" 上泛化较好(如训练过 "北京""上海",能识别 "广州"),但在 "跨领域实体" 上泛化较差(如从新闻领域到医疗领域,对 "癌症" 的识别准确率下降 30%+)。通过领域微调(用 500 条医疗标注数据),可将准确率提升 20% 左右,接近领域专属模型的性能。
面试关键点:需列举 NER 在多领域的具体应用;分析泛化能力的影响因素(数据多样性、领域适配等);说明提升泛化能力的方法(微调、对抗训练等)。
记忆法:"NER 应用广,抽实体建图谱,助客服监舆情,译文本理医疗;泛化看数据(多样性)、靠适配(领域微调),同域新实体易,跨域需优化"。