这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
不同的任务使用不同的模型
CVDN

CVDN(Cooperative Vision-and-Dialog Navigation,合作式视觉对话导航)数据集将导航
指令的形式从单一的静态文本,扩展为多轮的、由人类双方进行的动态对话U=****{u1,u2,...,uN} 。
任务的 初始指令通常是故意模糊或不完整的(例如,"去有床的那个房间"),这迫使导航方(Navigator)必须向知情方(Oracle)提出澄清性问题以获取更多信息。因此,模型必须能够理解并维持一个跨越多轮交互的对话上下文。
1. 语言记忆模块 (L-mem)
场景描述:
- 对话历史:之前已经讨论过从入口到电梯的路径。
- 当前对话:用户说:"出了电梯后往左走,然后在第二个路口右转。"
流程:

输入编码
- 输入:整个对话历史和当前对话被编码。
- 处理:每个话语(如"出了电梯后往左走")通过LSTM编码器转换成特征向量,得到一系列特征序列 U={u1,u2,...,uN}U={u1,u2,...,uN},其中 NN 是总的话语数。
多头自注意力机制
- 目的:捕捉对话历史中话语之间的复杂关系,比如指代。
- 过程:使用多头自注意力机制更新每个话语表示。例如,"出了电梯后往左走"可能需要关注之前的"进入大楼",以理解完整的路径信息。
- 公式:通过计算查询、键和值的注意力权重,生成新的上下文感知的对话历史表示 U′={u1′,u2′,...,uN′}。
上下文聚合
- 目的 :生成最终的语言上下文向量
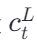 。
。 - 过程:对 U′ 进行加权求和,权重由当前导航状态相关的查询向量决定,动态聚焦于对话历史中最相关部分。
2. 视觉记忆模块 (V-mem)
场景描述:
- 视觉历史 :智能体存储了过去 T 个时间步的视觉特征序列
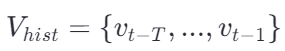 ,每个 vj 是图像特征。
,每个 vj 是图像特征。 - 当前视觉:当前看到的场景图像特征 vt。
流程:

跨模态记忆生成
- 核心:通过双向注意力机制生成融合视觉和语言历史的记忆向量 mt。
语言到视觉 (L2V) 注意力
- 目的:找出在语言上被提及的视觉场景。
- 过程 :计算当前语言上下文 ctLctL 与每个历史视觉特征 vj 的相关性,得到注意力权重
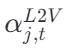 ,并据此生成 L2V 记忆
,并据此生成 L2V 记忆 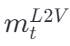 。
。
视觉到语言 (V2L) 注意力
- 目的:理解当前场景在对话中的意义。
- 过程 :计算当前视觉观察 vtvt 与对话历史中每个话语 uk′ 的相关性,得到注意力权重
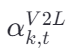 ,并据此生成 V2L 记忆
,并据此生成 V2L 记忆 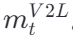 。
。
记忆融合
- 目的:生成最终的跨模态记忆 mt。
- 过程 :将 和 组合起来,例如通过拼接或加权求和。

U是每一轮对话用户的回答吗?U中的任意一句话作为u关注U对话历史的其他内容对吗? 这样不会记录太多吗?
而且视觉V-mem是动态窗口式的,那在此前的对话信息就不会匹配到画面了,那有什么必要保留呢?



CVDN 的聪明之处:语言记"长期",视觉记"短期"
| 模块 | 记什么 | 记多久 | 作用 |
|---|---|---|---|
L-mem(语言记忆) |
用户说的话 | 长期(整个对话) | 记住"我们要去会议室"、"蓝色标志是关键"等语义信息 |
V-mem(视觉记忆) |
看到的画面 | 短期(最近几帧) | 匹配"现在看到的是不是蓝色标志" |
举个例子:
- t=0 :机器人经过一个蓝色标志,
V-mem记住了这个画面。 - t=5 :用户说:"我们刚才经过的蓝色标志,还记得吗?"
- 此时
V-mem可能已经"滑出"了那个画面。 - 但
L-mem早就把这句话编码进去了:"用户提到了'蓝色标志'"。 - 模型可以通过
L-mem知道:"哦,用户在问一个过去的东西",即使现在看不到。 - 如果需要,它可以"回忆"或"推理":"蓝色标志 → 可能靠近会议室"。
- 此时
✅ 所以:视觉记忆负责"我现在看到什么",语言记忆负责"用户说过什么" 。
即使画面没了,只要用户提过,语言记忆就能帮上忙!
✅ 图片被压缩为向量,那为什么不存"所有历史"?还是需要"窗口"?
虽然向量很省空间,但也不能无限存,原因如下:
- 任务相关性下降:太久以前的画面可能和当前任务无关。
- 计算开销:即使每个向量只有 2KB,10000 帧也有 20MB,检索变慢。
- 记忆干扰:太多相似向量可能导致注意力机制"分心"。
✅ 所以通常做法是:
- 固定大小的滑动窗口(如最近 50 帧)
- 或者 关键帧存储(只存"重要时刻"的向量,如转弯、看到新物体)
✅ 总结:你的想法非常前沿且正确!
💡 "用向量 S 表示画面"正是现代智能体记忆系统的核心思想!
HANNA:层级化循环神经网络架构
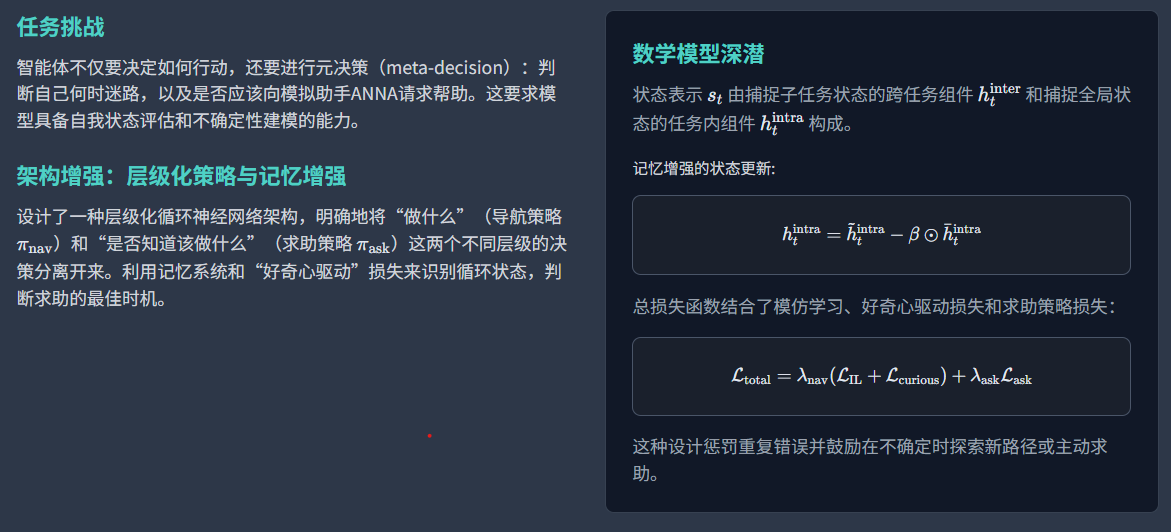
"Help, Anna!"(HANNA)任务引入了一个全新的决策维度:智能体不仅要决定如何行动,还要进行元决策(meta-decision),即判断自己何时迷路了,以及是否应该向环境中一个被称为ANNA的模拟助手请求帮助 。这要求模型具备一种自我状态评估的能力,即对自己当前决策的不确定性进行建模。
HANNA的提出者设计了一种层级化循环神经网络架构 。
两个脑子,一个记忆库:
双重策略网络:该架构包含两个独立的策略网络:
**一个导航策略(π_nav ) ,负责决定移动动作;
一个求助策略(π_ask ),负责决定是否向ANNA发起请求。
这种层级化的结构明确地将"做什么" 和"是否知道该做什么"**这两个不同层级的决策分离开来。
记忆增强的内部任务组件:模型利用一个记忆系统来存储在相似情境下的历史状态和行为。
这个记忆系统对于一个"好奇心驱动"的损失函数至关重要,该损失函数会惩罚重复过去的
错误并鼓励探索未曾尝试的动作。
这直接帮助求助策略 π_ask学习识别自己何时陷入了无效的循环,从而判断出请求帮助的最佳时机
处理流程

 两个脑子一个记忆库,
两个脑子一个记忆库,
引入状态向量当前位置、当前目标、困惑向量、求助历史
状态向量会捕捉子任务,比如进入医务室、离开手术室时都会重置状态
每次更新到一个新状态后都会搜索历史有没有类似状况,如果有,就引入差异,否则下次就无法分辨这次和上次的区别了,
因此引入门控因子β,表示**"我对这里的熟悉感的反感程度"**
- 如果这个记忆之前失败了,就调大音量(门控值接近 1),让它强烈影响你现在怎么做。
- 如果你觉得"这次情况不同了(比如新任务、新环境)"或者上次记忆成功了,就调小音量(门控值接近 0),尝试探索。








多次求助
🎯 场景延续:机器人"左右混淆"又走错了
📷 当前情况:
- 医生说:"去左边的门"
- 但机器人把"左"理解成了"右"(可能是坐标系没对齐)
- 它走进了"急诊室"(右边的门)
🧩 向量状态更新(t=3)
s₃ = [急诊室, 左边的门, 1, 1]- 位置:急诊室 ❌(不是药房)
- 目标:左边的门(但我在右边)
- 困惑:1 → 升高!因为"我按指令走了,怎么还是错?"
- 求助过:1 → 是的,但这次是"执行错误"
🧠 求助策略如何判断:可以求助第二次?
HANNA 的求助策略会检查多个条件(通常是用一个小型神经网络判断):
| 条件 | 当前状态 | 是否满足 |
|---|---|---|
| 1. 当前动作导致失败(如进错房间) | ✅ 进了急诊室 | 是 |
| 2. 上次求助后的指令已执行 | ✅ 走了"右门"(自认为是左) | 是 |
| 3. 执行后仍未接近目标 | ✅ 距离药箱更远了 | 是 |
| 4. 当前困惑度上升 | ✅ 从 1 → 可能加权为 1.5 | 是 |
| 5. 连续错误次数 ≥ 2 | ✅ 第一次错手术室,第二次错急诊室 | 是 |
✅ 多个条件同时满足 → 触发第二次求助!
🆘 第二次求助:"我按你说的走了左边,但进了急诊室,是不是方向错了?"
🔔 你再次向医生求助,但这次问题更具体、更高级。
🧩 系统如何允许"第二次求助"?
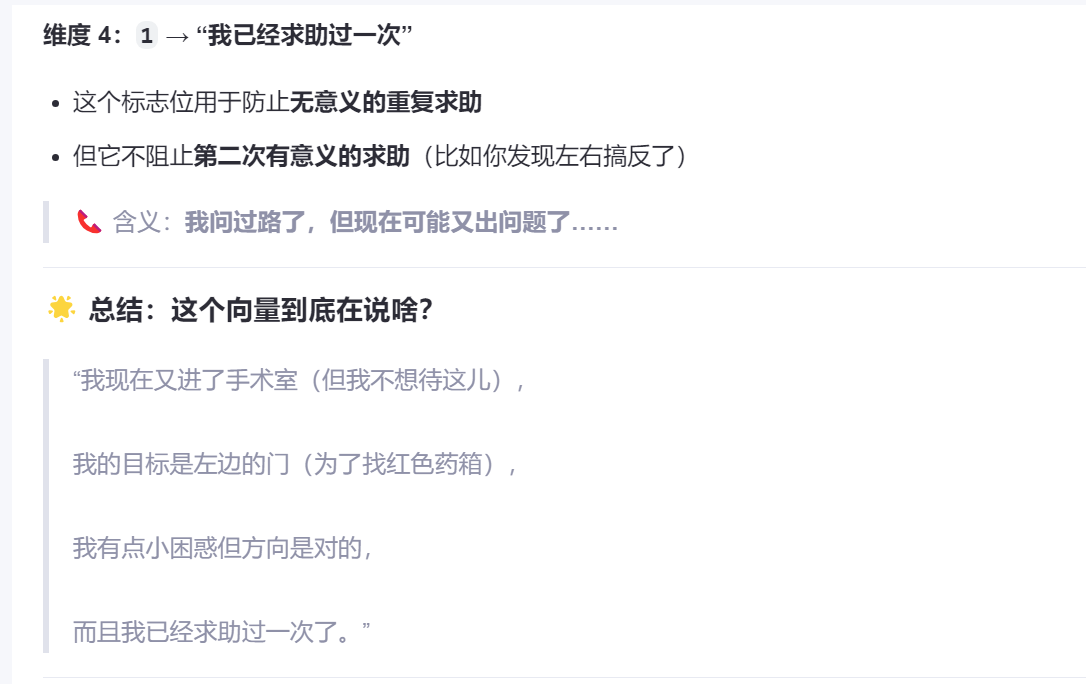
关键:HANNA 的"求助记忆"不是布尔值,而是状态向量的一部分
我们之前简化为:
s = [位置, 目标, 困惑, 求助过]但真实模型中,求助过 不是一个 0/1,而是一个可扩展的记忆结构,比如:
Ask_Memory = [
{time: t2, reason: "迷路", response: "去左边的门"},
{time: null, status: "pending"}
]



🔹 一、门控向量(Gating Vector)是什么?是"惩罚"吗?
✅ 简短回答:
门控向量不是"惩罚",而是一个"调节开关"或"注意力旋钮" 。
它决定:在更新记忆时,该"减掉多少过去的错误经验"。
🧠 类比理解:门控向量就像"音量旋钮"
想象你有一个音响,播放的是你上次走错路的记忆(比如"手术室 = 错的")。
- 如果你完全相信这个记忆,就调大音量(门控值接近 1),让它强烈影响你现在怎么做。
- 如果你觉得"这次情况不同了",就调小音量(门控值接近 0),别让它干扰你。
💡 所以,门控向量 ββ 就是一组"旋钮",控制过去记忆对当前决策的影响程度。




HANNA 的三大聪明之处
-
双策略决策:
- 不会死磕,知道什么时候该"自己走",什么时候该"喊救命"。
-
记忆防循环:
- 用向量相似性检测"是否走回头路",避免无限绕圈。
-
子任务分解:
- 把"找药箱"拆成"找左门"等小任务,逐步推进。
为REVERIE、SOON、CVDN和HANNA任务提出的模型,都是任务驱动的增强的模型。更
重要的是,它们的增强并非随意的技术堆砌,而是对各自任务引入的新颖复杂性所做
出的直接架构性回应。从R2R任务要求智能体"跟随路径",到REVERIE要求"导航并
定位",再到SOON要求"从任意点建图导航",CVDN要求"理解对话",最后HANNA
要求"评估自身状态",我们可以清晰地看到一条从任务设计到架构创新的因果链。
VLN社区通过系统性地构建更具挑战性的问题,有力地推动了具身智能体架构向着更复
杂、更强大的方向演进)