一、模型微调技术
1.模型微调简介
大模型微调(Fine-tuning),是指在已经预训练好的大语言模型基础上(基座模型),使用特定的数据集进行进一步训练,让模型适应特定任务或领域。通常LLM的预训练是无监督的,但微调过程往往是有监督的。当进行有监督微调时,模型权重会根据真实标记的差异进行调整。通过这个微调过程,模型能捕捉到标签数据中特定于某一项任务的模式和特点。
1)指令微调(Instruction Tuning/SFT)
通过使用任务输入与输出的配对数据进行训练,使得语言模型掌握通过问答形式进行任务求解的能力。一般来说,指令微调很难教会大模型预训练阶段没有学习到的知识与能力,它主要起到了对于模型能力的激发作用。
2)人类对齐
由于大语言模型可能会生成具有偏见、泄露隐私甚至对社会有害的内容,在实践应用中需要保证大模型能够较好的符合人类的价值观,对齐目标一般聚焦于有用性、诚实性和无害性三个方面。代表性的做法是OpenAI公司提出的基于人类反馈的强化学习算法RLHF,将人类偏好引入到大模型的对齐过程中。
2.微调手段
Adapter Tuning,PET,Prefix Tuning,P-Tuning,LoRA,QLoRA等。
二、PEFT参数高效微调
在不调整预训练模型的所有参数的情况下,通过仅微调一小部分参数来适应特定的下游任务,显著降低计算和存储成本。加快模型适应速度,避免了灾难性遗忘。
1)PEFT目标是在保留预训练模型大部分参数不变的情况下,只对模型的一小部分参数进行微调。
2)适用于数据量小的任务
PEFT的分类:
a.additive-增量模型
通过在预训练模型的特定位置添加可学习的模块或者参数,以最小化适配下游任务时模型的可训练的参数。
方法:Adapter:通过在Transformer块内添加小型Adapter层来实现参数高效微调。Soft Prompt:通过在输入序列的头部添加可学习的向量来实现参数高效微调。
b.soft prompt-软提示
软提示是可学习的连续向量,通过梯度优化方法针对特定数据集进行优化。
方法:Prefix-tuning:通过在每个Transformer层的键、值和查询矩阵前面添加可学习的向量,实现对模型表示的微调。Prompt Tuning:仅仅在首个词向量层插入可学习向量,以进一步减少训练参数。
c.adapters-适配器
适配器技术通过在模型的层之间插入小型神经网络模块(adapters),只训练这些模块的参数,而保持预训练模型的其他部分不变。
d.selective-选择性方法
选择性方法在微调过程中只更新模型中的一部分参数,而保持其余参数固定。
方法:包括非结构化掩码和结构化掩码技术。非结构化掩码通过在模型参数上添加可学习的二值掩码来确定可以微调的参数。结构化掩码对掩码的形状进行了结构化的限制,以提高效率。
e.reparameterizeation based-重参数化方法
通过构建预训练模型参数的(低秩的)表示形式用于训练,在推理时,参数将被等价的转化为预训练模型参数结构。
方法:LoRA通过将权重矩阵分解为俩个较低秩的矩阵来减少参数量,从而有效的减少需要更新的参数数量。
三、LoRA与QLoRA
1.LoRA
通过低秩分解来模拟参数的改变量,以极小的参数来实现大模型的间接训练。
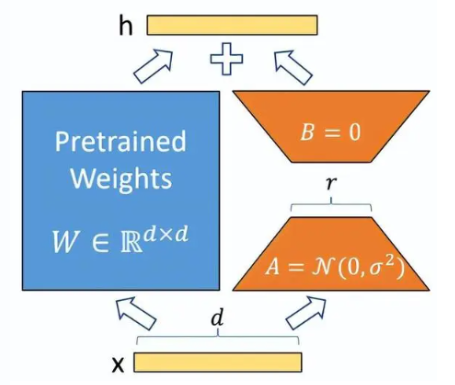
简单理解:外挂模型,训练时冻结预训练模型的权重,仅改变外挂模型的权重,r为秩,简答理解为做一次维度变换,提取不同维度的特征。
2.QLoRA
量化版LoRA,显著降低训练时所需显存资源。
特点:
1)定义了4位标准浮点数(NF4)量化,基于分块的分位数量化的量化策略。
2)双重量化,包含对普通参数的一次量化和对量化常数的再一次量化,可以进一步减小缓存占用。
3)分页优化器,用来在显存过高时用一部分内存代替。
四、模型量化技术
1.量化原理
默认情况下模型的权重参数以及偏置均使用float32位全精度浮点数进行存储,目的为了保证精度。但是精度增加的同时也带了模型体积增大,训练速度降低,预测速度慢等问题。由此诞生了量化技术。
2.量化目的
将原本使用浮点数表示的模型参数转换为整数表示,以此来减少模型的存储空间需求并加速计算和推理的过程,将原本使用float32类型的数据转换为int8类型的数据。
3.对称量化与非对称量化
对称量化:使用一个映射公式将输入数据映射到-128,127的范围内。
非对称量化:使用一个映射公式将输入数据映射到0,255的范围内。
4.NF4量化
基于分位数量化的基础上,理论上最优的数据类型,可以确保每个量化区间从输入张量中分配相同数量的值,实际计算过程中,需要先将数据归一化到合适的范围,并且对于确定的分布来说,分位点也是确定的,因此只需存储分位点的索引即可。
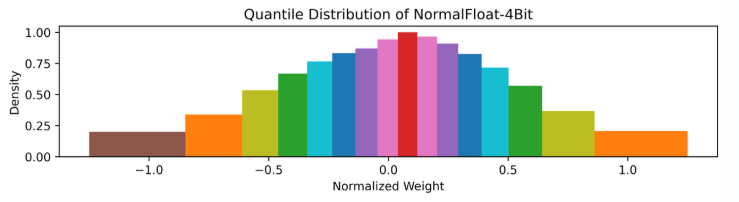
简单理解:NF4总共4bits,正态分布分为16块,将数据映射到这16块中,记录数据索引即为量化后的值。