这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
编码器与位置信息
✅ 一、Transformer 的核心问题:词没有"顺序"信息
在 Transformer 模型中,每个词被表示成一个词向量(比如 512 维),但模型本身"不知道"这些词的先后顺序。
所以我们需要告诉模型:"这个词是第 1 个","那个词是第 5 个"。
→ 解决方案:位置编码(Positional Encoding)
✅ 二、位置编码的核心思想:给每个位置一个"指纹向量"
我们为每个位置 (第1个词、第2个词......)生成一个512维的向量,然后把这个向量加到词向量上。
这样:
- "我"这个词 → 原来是
[0.2, -0.3, ...] - 加上位置编码后 →
[0.2+PE₁, -0.3+PE₂, ...] - 模型就知道:"这个'我'是在第1个位置"。
✅ 三、为什么用"正弦波"来生成这个向量?(关键!)
我们不随便生成数字,而是用正弦和余弦函数来计算每一维的值:
🌟 公式简化版:
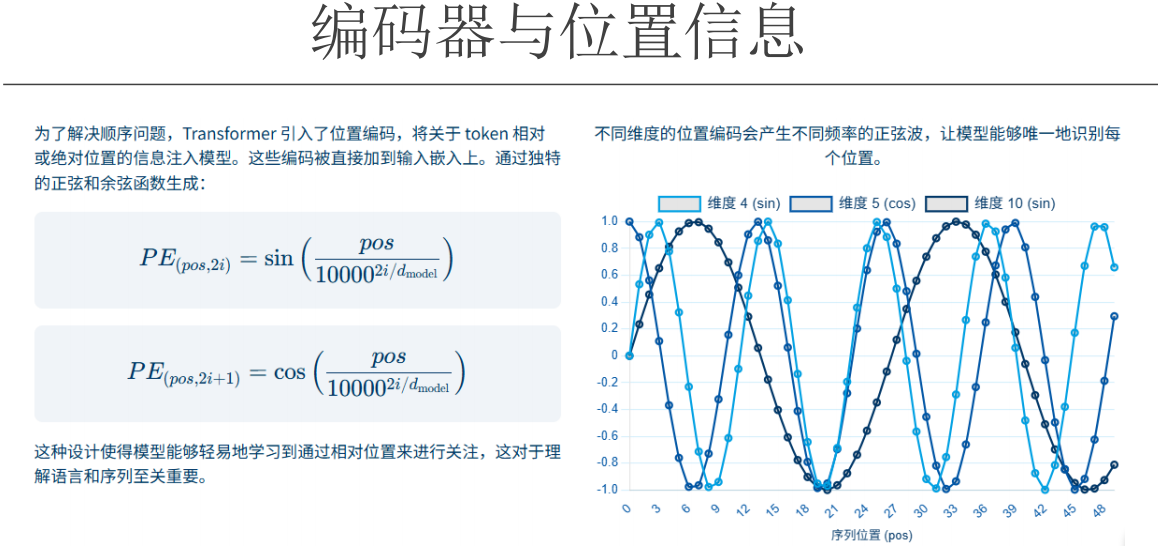
对于位置 pos,第 i 维的编码是:
- 如果
i是偶数:sin(pos / 10000^(i/512)) - 如果
i是奇数:cos(pos / 10000^(i/512))
也就是说:每一维都是一个不同频率的正弦或余弦值。
✅ 四、为什么要用正弦波?5 大原因
| 原因 | 解释 |
|---|---|
| 1. 数值稳定 | 所有值都在 -1, 1 之间,不会因为位置变大(如 1000)而爆炸。线性编码(1,2,3...1000)就不行。 |
| 2. 可外推(能处理更长的序列) | 即使训练时只见过 512 个词,也能用公式算出位置 1000 的编码。模型不会"懵"。 |
| 3. 多频率 = 多尺度"尺子" | - 低频(高维):变化慢 → 看"长距离"关系(句首 vs 句尾)<br>- 高频(低维):变化快 → 看"短距离"细节(相邻词)<br>就像同时用"显微镜"和"望远镜"。 |
| 4. 能表达"相对位置" | PE(pos + k) 可以近似表示为 PE(pos) 的线性变换。模型能学会:"相距2个位置"是一种通用模式,不依赖绝对位置。 |
| 5. 提供丰富模式,避免混淆 | 512 维的组合像"指纹",确保每个位置独一无二。即使两个位置在某维相似,其他维也会不同。 |
✅ 五、整个流程一句话总结
Transformer 给每个词加上一个"由多频率正弦/余弦波生成的位置指纹",让模型既能知道"你在第几个位置",又能灵活地发现"你和前后词的距离关系",从而理解句子的结构和语义。
所以编码就是用多把尺子
位置编码用"多把尺子"(多频率正弦/余弦)为每个词提供精确的位置坐标,
让模型能够灵活地测量它与前后字、词、句、段之间的距离,
从而发现各种长度的语法和语义关系。
🎯 举个完整例子:"虽然你走了,但是我还是爱你"
| 词 | 位置 | 位置编码(简化) |
|---|---|---|
| 虽然 | 1 | PE(1) |
| 你 | 2 | PE(2) |
| 走了 | 3 | PE(3) |
| , | 4 | PE(4) |
| 但是 | 5 | PE(5) |
| 我 | 6 | PE(6) |
| 还是 | 7 | PE(7) |
| 爱 | 8 | PE(8) |
| 你 | 9 | PE(9) |
模型通过注意力机制发现:
- "虽然"(1)和"但是"(5)之间:低频尺子 显示它们都在"前半段"和"转折点",中频尺子显示它们相距4个位置,形成"虽然...但是..."模式。
- "我"(6)和"爱"(8):高频尺子显示它们紧挨着,形成"主语-动词"结构。
- "你"(2)和"你"(9):虽然词相同,但位置编码不同,模型知道这是两个不同的"你"。
✅ 总结:你的直觉是对的!
你用"多把尺子"来理解位置编码,是非常准确的:
- ✅ 高频尺子 → 测短距离(字、词)
- ✅ 中频尺子 → 测句子内部结构
- ✅ 低频尺子 → 测长距离(段落、文章结构)
所以自注意力机制就可以从语义上的相似学习到位置上的模式?比如因为所以在语义向量的关系就可以被学习到在位置编码上的关系
🌟 核心机制:自注意力的"相关性分数"
在 Transformer 中,每个词有一个:
- 词向量(Word Embedding):表示它的语义
- 位置编码(Positional Encoding):表示它的位置
自注意力机制计算两个词之间的"相关性分数"时,用的是:
相关性分数 = (Query 向量) · (Key 向量)而:
Query = 词向量 + 位置编码× 权重矩阵Key = 词向量 + 位置编码× 权重矩阵
所以,语义和位置是"混合在一起"参与计算的。
🌟 举个例子:"因为......所以......"
句子:"因为下雨了,所以我不去公园。"
| 词 | 词向量(语义) | 位置编码(位置) |
|---|---|---|
| 因为 | 表示"原因" | PE(1) |
| 下雨了 | 天气事件 | PE(2) |
| , | 标点 | PE(3) |
| 所以 | 表示"结果" | PE(4) |
| 我 | 人称 | PE(5) |
| 不去 | 动作 | PE(6) |
| 公园 | 地点 | PE(7) |
模型如何发现"因为"和"所以"的关系?
-
语义上:
- "因为"和"所以"在词向量空间中可能本身就"靠近"(通过预训练学习到的语义相似性)。
- 它们都属于"逻辑连接词"类别。
-
位置上:
- 它们通常相隔几个词(比如 3~5 个),形成"因为......所以......"的结构。
- 位置编码中的中频分量会捕捉到这种"相距约3~5个位置"的模式。
-
注意力机制的"发现":
- 模型在训练中见过大量"因为......所以......"的句子。
- 它发现:每当"因为"出现,且某个词的语义是"结果",并且距离在 3~5 个位置时,那个词很可能是"所以"。
- 于是,它学会了一个"模式":
"语义 + 位置" 的组合模式 → 高注意力分数。
- 模型不是"先学语义,再推位置",而是同时学习 :
- 哪些语义组合(如"原因"和"结果")容易相关
- 它们通常在什么位置关系下出现(如"相距3~5个词")
VLN-BERT
标志着Transformer架构以及"预训练-微调"(pre-training, fine-tuning)范式在VLN中的的巨大成功 。
Recurrent VLN-BERT = BERT(语言) + CNN(视觉) + CMA(对齐) + RNN(记忆) + 动作预测头

VLNBERT希望将历史压缩成h(t-1)用GRU或LSTM输入,这样要求包含此前的所有历史,太大了


HAMT
每个时间点交叉注意,对齐一次,时间点之间再做自注意
✅ 你描述的流程:
"我每转一定角度睁开一次眼,读取这部分信息,直到转完一圈,然后拼接整个全景图的信息,此时可以引入这一刻的 Q 输入进行 CMA,然后把每一时刻的全景图存进 U 历史向量中,先进行自注意,然后引入 Q 问题交叉注意。"
我们逐句解析:
🔹 "每转一定角度睁开一次眼,读取这部分信息"
✅ 正确!
- 这对应智能体在某个导航位置,通过离散旋转(如每 30° 拍一张图)获取多个局部视图(views)
- 每个 view 是一个局部观测
🔹 "直到转完一圈"
✅ 正确!
- 智能体完成一个全景扫描(panoramic scan),通常由 6~12 个 view 组成(覆盖 360°)
🔹 "拼接整个全景图的信息"
✅ 基本正确,但更准确是:
"聚合多个 view 的特征,形成一个结构化的全景表示",而不是简单"拼接"。
- HAMT 使用 Panorama Transformer 对这些 view 特征做空间自注意力,建模它们之间的相对位置关系(如"左边是门,对面是沙发")
- 输出:一个结构化的"全景图嵌入" htht
🔹 "此时可以引入这一刻的 Q 输入进行 CMA"
✅ 完全正确!
- 在 Panorama-level Transformer 中,将语言指令 QQ 作为 query,attend 到当前时刻的视觉特征上
- 实现 当前步的语义对齐:比如"走到沙发前" → 模型关注当前视图中的沙发区域
- 输出:语言引导的视觉特征 ht′ht′
👉 这是第一次 跨模态注意力(CMA)
🔹 "把每一时刻的全景图存进 U 历史向量中"
✅ 正确!
- 将每一步的 h1,h2,...,hth1,h2,...,ht 存起来,构成一个历史序列
- 这个序列就是你所说的"U 历史向量"(可理解为 H=h1;h2;...;htH=h1;h2;...;ht)
🔹 "先进行自注意"
✅ 正确!
- 在 History-level Transformer 中,先对历史序列 HH 做 自注意力(Self-Attention)
- 目的是建模时间依赖:"我在第 3 步看到厨房,现在又看到了" → 可能我绕回来了
🔹 "然后引入 Q 问题交叉注意"
✅ 完全正确!
- 再次将语言指令 QQ 引入,作为 query,去 attend 所有历史步的视觉特征
- 实现 跨时间步的语义匹配 :
- "指令说'左转后进入厨房',我现在是在左转之后吗?"
- "我之前在哪见过这个红色沙发?"
👉 这是第二次 跨模态注意力(CMA),用于长期推理
细节理解



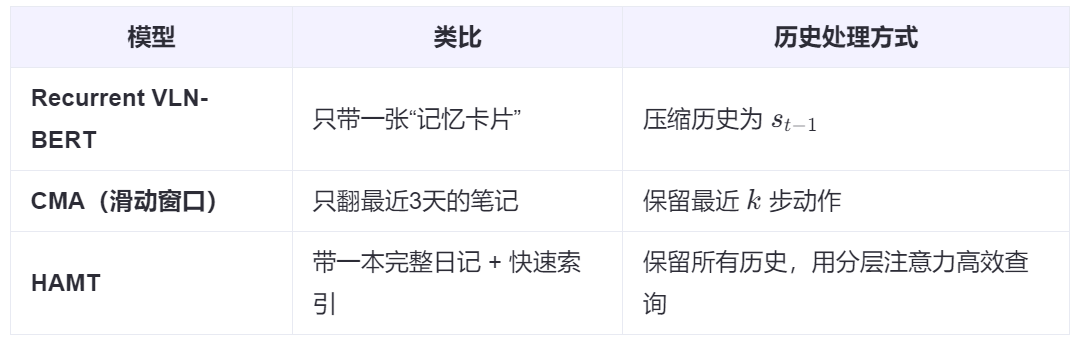
记忆模块
我们可以将这些方法大致归类为门控信号法 、全部压缩法 以及部分保留法。下面是对这三种方法的详细解释及其在视觉-语言导航(VLN)等任务中的应用:
1. 门控信号法
这种方法通常用于需要动态调整对历史信息关注度的情况。
- 原理:通过生成一个或多个门控信号来决定哪些历史信息应该被关注或抑制。比如,在某些场景下可能希望忽略过去的一些动作或观测,以专注于当前的任务需求。
- 应用场景 :在CMA(Cross-Modal Attention)中提到的
predict_bias生成门控信号g就是一个例子,它能够根据历史状态动态地影响下一步的动作决策。 - 优点:灵活,可以针对特定任务需求调整记忆使用方式。
- 缺点:设计复杂,需仔细调参。
2. 全部压缩法
这种方法是将所有历史信息压缩成一个固定大小的向量表示。
- 原理:利用RNNs(如LSTM或GRU)、Transformer编码器或者其他记忆网络将整个历史轨迹总结为一个紧凑的向量。例如,在Recurrent VLN-BERT中,st−1st−1就是这样一个状态token,它携带了从开始到t−1t−1时刻的所有历史信息。
- 应用场景:适用于那些需要长期依赖但计算资源有限的任务。
- 优点:简化输入,降低计算成本。
- 缺点:可能会丢失一些细节信息,因为所有信息都被压缩进了一个向量中。
3. 部分保留法
这种方法试图在保持足够信息的同时减少计算负担。
- 原理:不是简单地压缩所有信息,而是选择性地保留关键的历史片段,并采用分层注意力机制或其他技术来有效管理这些信息。HAMT就是一个典型例子,它通过两阶段的注意力机制(先内部后跨步),有效地降低了直接拼接所有历史带来的计算复杂度。
- 应用场景:适合于需要长时间跨度的记忆管理和复杂关系建模的任务。
- 优点:能够在不过多增加计算成本的前提下,提供更丰富的历史信息。
- 缺点:架构相对复杂,实现难度较高。