首先常见的异常如下,中断是异常的一种。
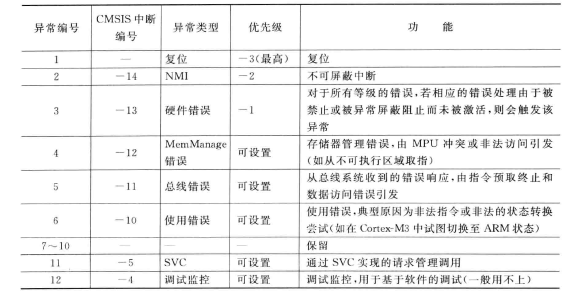

异常的压栈情况如下。
1. 中断等待 (Interrupt Latency)
中断等待(或称中断延迟)指的是从一个外部事件触发中断信号开始,到处理器开始执行该中断对应的服务程序(ISR)的第一条指令为止所经过的时间。
这个时间不是零,它由多个部分组成:
- 硬件延迟:中断信号在芯片内部传播并被中断控制器(如NVIC)检测到的时间。
- 同步延迟:将异步的中断信号与处理器内核时钟同步所需的时间。
- 上下文保存:这是延迟的主要来源。处理器必须将当前正在执行的程序的状态(如程序计数器PC、程序状态寄存器xPSR、通用寄存器R0-R3, R12)压入堆栈。这个过程需要多个时钟周期。
- 向量读取:处理器需要从向量表中读取中断服务程序的入口地址。
- 指令预取:处理器需要获取ISR的第一条指令。
优化的目标:就是尽可能缩短上述过程,特别是耗时最长的"上下文保存"和后续的"上下文恢复"(出栈)过程。
2. 多周期指令执行时的中断
问题 :如果处理器正在执行一条需要多个时钟周期才能完成的指令(例如 LDM 加载多个寄存器,或 DIV 除法指令),此时来了一个中断怎么办?
处理方式:
- 等待完成:如果等待指令执行完,会增加中断延迟,对于高优先级的实时任务是不可接受的。
- 放弃并重来:如果放弃当前指令,服务完中断后再重新执行,会浪费已经花费的周期。
Cortex-M的优化 :Cortex-M处理器的大多数多周期指令都是可中断-可恢复的。当在执行这类指令时中断到来,处理器会:
- 暂停当前指令的执行。
- 保存当前指令的状态。
- 响应中断,完成上下文保存并执行ISR。
- 中断返回后,恢复被中断指令的状态,并从暂停的地方继续执行,而不是从头开始。
好处:这种机制确保了即使是长指令也不会长时间阻塞高优先级中断的响应。
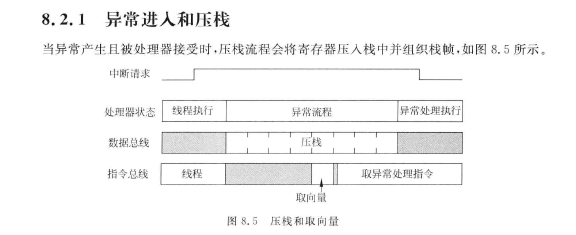
3. 末尾连锁 (Tail-Chaining)
场景:一个中断服务程序(ISR A)即将执行完毕,而此时恰好有另一个中断(中断B)正在等待处理。
常规处理流程 (低效):
- 出栈:处理器将ISR A的上下文从堆栈中恢复到寄存器。
- 返回:返回到主程序。
- 再次中断:处理器立刻检测到挂起的中断B。
- 入栈:处理器再次将主程序的上下文压入堆栈,为执行ISR B做准备。
末尾连锁优化 :
处理器在ISR A即将结束时,会检查是否有其他中断挂起。如果有,它会跳过第1步(出栈)和第3、4步(再次入栈)的冗余操作,直接开始执行ISR B。上下文的恢复(出栈)只会在所有挂起的中断都处理完毕后才执行一次。
好处 :极大地减少了背靠背中断处理的开销,通常可以节省20多个时钟周期,显著降低了整体中断处理时间。
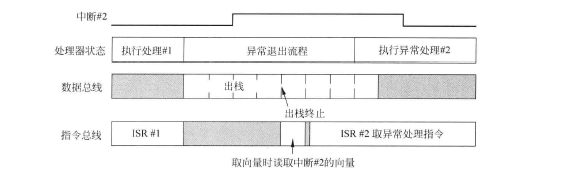
4. 延迟到达 (Late-Arriving)
场景 :这是末尾连锁的一种特例。当处理器已经开始为ISR A执行出栈操作时,一个更高优先级的中断B到来了。
常规处理流程 (低效) :
处理器会先完成整个出栈过程,返回主程序,然后再响应中断B,进行入栈操作。
延迟到达优化 :
处理器足够智能,它会:
- 中止当前的出栈操作。
- 立即响应更高优先级的中断B,并为其执行入栈(如果需要)。
- 执行ISR B。
- ISR B结束后,再继续之前被中止的出栈操作。
好处 :确保了最高优先级的中断能被最快地响应,即使它是在中断返回的瞬间到达。
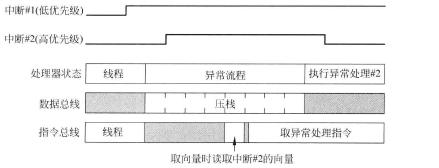
5. 出栈抢占 (Pop Preemption)
这个概念与"延迟到达"非常相似,描述的其实是同一个优化机制。当一个低优先级中断正在进行出栈恢复时,一个高优先级中断可以抢占这个出栈过程,从而被立即处理。
6. 惰性压栈 (Lazy Stacking)
场景:Cortex-M处理器在进入ISR时,硬件会自动保存一组核心寄存器(xPSR, PC, LR, R12, R3-R0)。但如果ISR需要使用浮点运算,还需要手动保存浮点寄存器(S0-S31)。
问题:如果一个中断来了,但它的ISR根本不使用浮点运算,那么保存和恢复所有浮点寄存器就是纯粹的浪费,会增加几十个周期的延迟。
惰性压栈优化 :
当FPU(浮点单元)被使能时,惰性压栈机制启动。
- 中断发生时,硬件只保存核心寄存器,不保存浮点寄存器。
- 处理器进入ISR并开始执行。
- 直到ISR中第一条浮点指令将要被执行时,处理器才会暂停,将浮点寄存器压栈。
- 同时,硬件会设置一个标志位,表示浮点上下文已经保存在栈中。
好处:
- 对于不使用FPU的ISR,完全没有保存/恢复浮点寄存器的开销,中断延迟大大降低。
- 对于使用FPU的ISR,虽然仍有开销,但这个开销被推迟到真正需要时才发生。
- 在中断嵌套时,如果高优先级中断不使用FPU,它可以快速抢占正在使用FPU的低优先级中断,而无需等待浮点寄存器保存完成。