- 三种高可用模式
主从复制、哨兵模式、集群模式
- 主从复制模式
主节点:读写请求; 从节点:只读请求
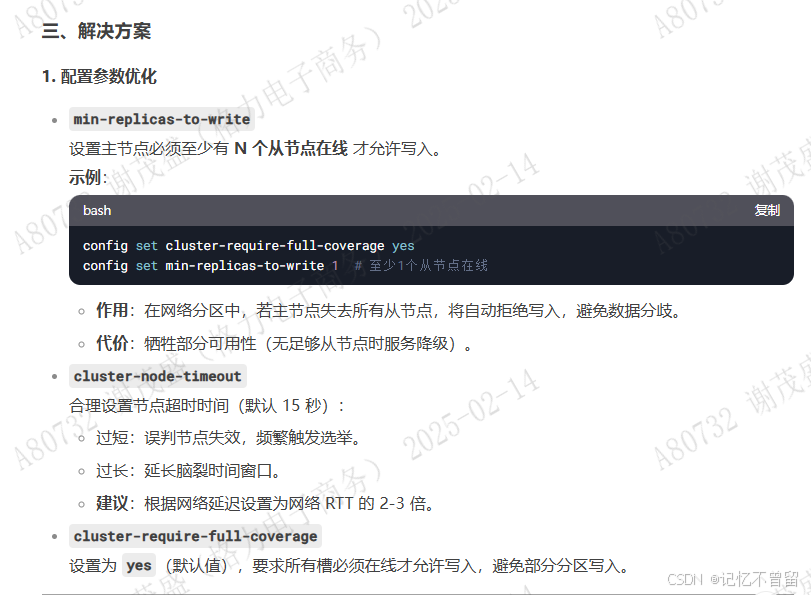
主从复制-全量复制:
1、建立连接:从节点和主节点建立连接 2、发送sync命令:从节点向主节点发送sync(同步)命令,请求全量数据同步。 3、数据传输:主节点收到请求后,会执行bgsave命令创建一个rdb快照文件,并将这个文件发送给从节点。 同时,主节点继续将所有新的写命令缓存在内存中。 4、载入数据:从节点接收rdb文件并加载到内存中。 5、主节点将缓存的写命令发送给从节点执行,以确保从节点与主节点一致。
什么情况会进行全量复制?
1、slave连接上master第一次复制的时候 2、从节点发送psync 同步命令 (runid、offset),当runid与当前主节点runid不匹配时则进行全量复制、或者偏移量offset不在主节点复制积压缓冲区内
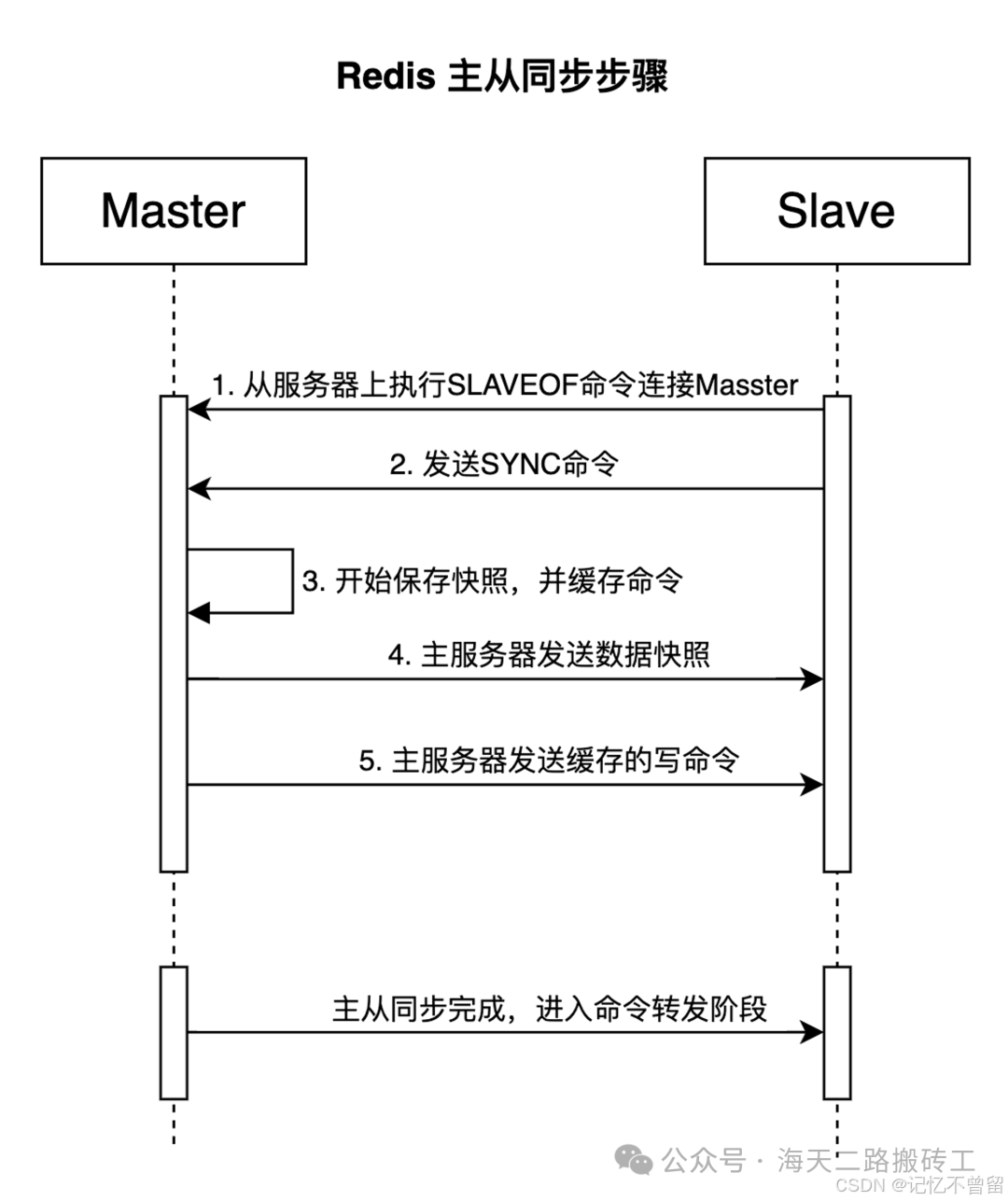
主从复制-增量复制:
一旦从节点完成初始数据同步,主节点将继续将新的写命令发送给从节点。 从节点接收到这些写命令并应用到自己的数据库中,保持与主节点的数据状态同步。 从节点定期向主节点发送心跳请求以确认连接是否存活,并在需要时重新同步数据
几个重要概念:
复制偏移量 (replication offset) 复制积压缓冲区 (replication backlog) 服务器运行ID (runID)
复制偏移量 (replication offset)
主从节点都维护这一个复制偏移量,它代表着当前节点接受数据的字节数,注意这里表示的是【字节数】。 想要知道主从是否一致,通过对比offset,也能知道
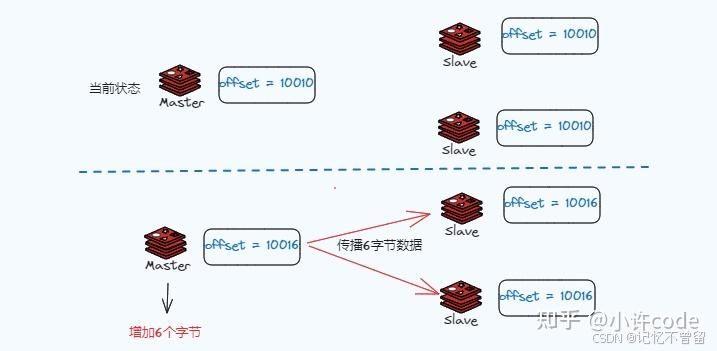
复制积压缓冲区 (replication backlog buffer)
复制积压缓冲区是由主节点维护的一个固定长度的环形缓冲区、是先进先出(FIFO)队列,默认大小为 1MB。 (从节点当前的复制偏移量offset)
服务器运行ID (runID)
不论主从都会有自己的运行ID,在Redis服务器启动时会自动生成,由40个随机16进制字符组成。 第一次复制master会发送这个ID给到slave,而断线重连时slave会带上这个ID发送给master
判断出salve要读取的数据还在 replication_backlog_buffer 里,那么主服务器将采用增量同步的方式; 判断出读取的数据已经不存在 replication_backlog_buffer 里 (比如被覆盖掉了),那么主服务器将采用全量同步的方式
replication_backlog_buffer 大小只有1M,数据被覆盖的概率挺大,该如何配置避免呢?
replication_backlog_buffer 最小的大小可以这样估算 repl_backlog_buffer = second * write_size_per_second second 为salve断线后重新连接上master所需的平均 时间(以秒计算)。 write_size_per_second 则是master平均每秒产生的写命令数据量大小
这个配置我们看情况去定,这个参数在配置文件中如下,我们可以去修改它
repl-backlog-size 1mb
哨兵模式
Redis的哨兵模式是在主从模式的基础上,增加了故障转移的功能。
哨兵(数量一般奇数个)主要三个功能:
1、监控:主从节点服务运行状态 2、提醒:监控到redis服务器出问题时,可以通过API向管理员或者其他应用程序发送通知。 3、自动故障迁移:当哨兵检测到主节点宕机,会自动在所有从节点服务器中挑选一个为主节点(自动切换)。然后同步发布订阅模式通知其他从节点,让它们切换主节点。
哨兵模式的工作原理和选举原理
- 主观下线
单个sentinel自己主观上检测到的关于master的状态,从sentinel的角度来看,如果发送了PING心跳,在一定时间内没有收到合法的回复,就达到了SDown的条件
- 客观下线
ODown需要一定数量的sentinel,多个哨兵达成一致意见才能认为一个master客观上已经宕机
- 选举出领导者哨兵(Raft算法)
当主节点被判断客观下线以后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点(兵王)并由该领导者节点,也即被选举出的兵王进行failover(故障迁移)
- 由领导者哨兵开始推动故障切换流程并选出一个新的master
1、redis.conf文件中,优先级slave-priority或者replica-priority最高的从节点(数字越小优先级越高) 2、复制偏移位置offset最大的从节点 3、最小Run ID的从节点

集群模式
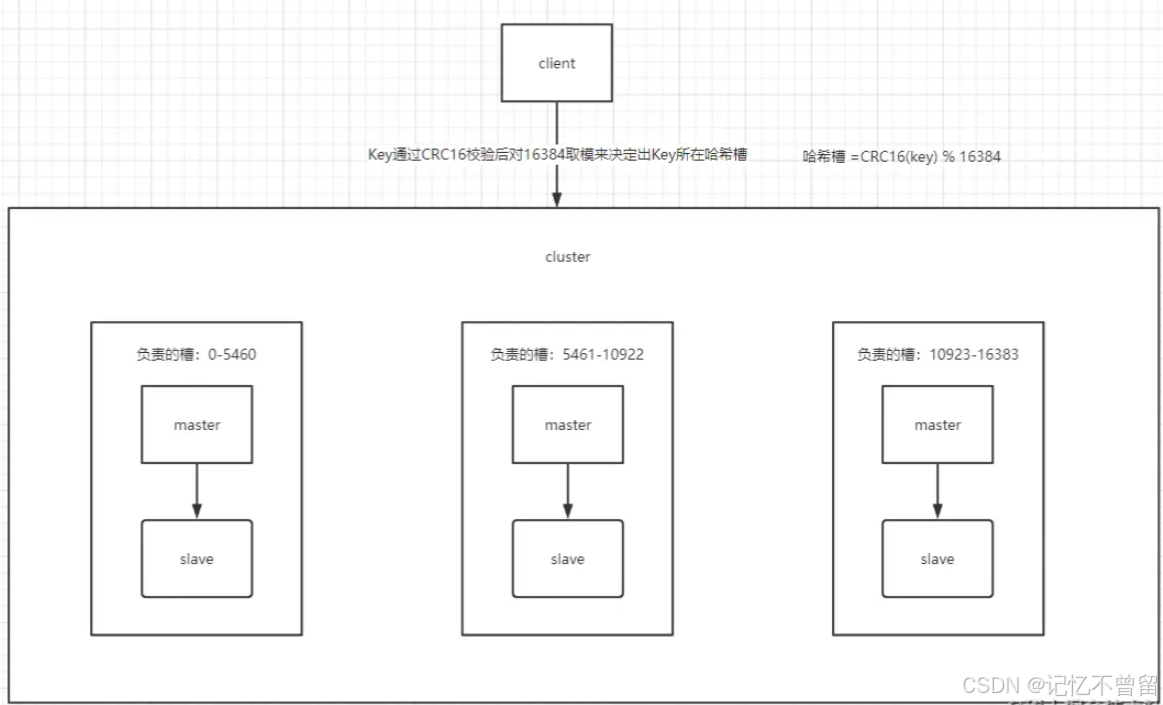
redis集群模式解决了写操作无法负载均衡,以及存储能力受到单机限制的问题。 redis集群将数据空间分为16384个哈希槽slots,分布到各个主节点中,集群中的每个主节点负责一部分的哈希槽。 集群中每个节点都会传播槽归属信息(传播当前节点处理哪些槽),让集群中每个节点都持有槽指派的元信息,知道槽位分派在哪个节点
1,哈希槽是什么 Redis集群引入了哈希槽的概念 Redis集群有16384个哈希槽(编号0-16383) 集群的每个节点负责一部分哈希槽 每个Key通过CRC16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
2,哈希槽如何排布 #以3个节点组成的集群为例: 节点A包含0到5460号哈希槽 节点B包含5461到10922号哈希槽 节点C包含10923到16383号哈希槽
3,Redis集群的主从复制模型 集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用。 为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave节点组成,在节点B失败后,集群选举B1位为的主节点继续服务。当B和B1都失败后,集群将不可用。
如果主节点和该主节点下面所有的从节点都宕机不可用,则当前集群不可用了
集群默认是异步复制
使用异步复制(asynchronous replication)是redis 集群可能会丢失写命令的其中一个原因, 有时候由于网络原因,如果网络断开时间太长,redis集群就会启用新的主节点,之前发给主节点的数据就会丢失。 以下情况可能导致写操作丢失: 1、过期 key 被清理 2、最大内存不足,导致 Redis 自动清理部分 key 以节省空间 3、主库故障后自动重启,从库自动同步 4、单独的主备方案,网络不稳定触发哨兵的自动切换主从节点,切换期间会有数据丢失








事务与 Lua 脚本
事务限制:所有操作的键必须位于同一槽(通过 哈希标签 {} 强制绑定)。 Lua 脚本:脚本中所有键需在同一节点,否则报错(CROSSSLOT)。
动态扩容:
添加新节点后,通过CLUSTER ADDSLOTS 分配槽,使用 MIGRATE 命令迁移数据。
缩容
需先迁移槽到其他节点,再移除节点
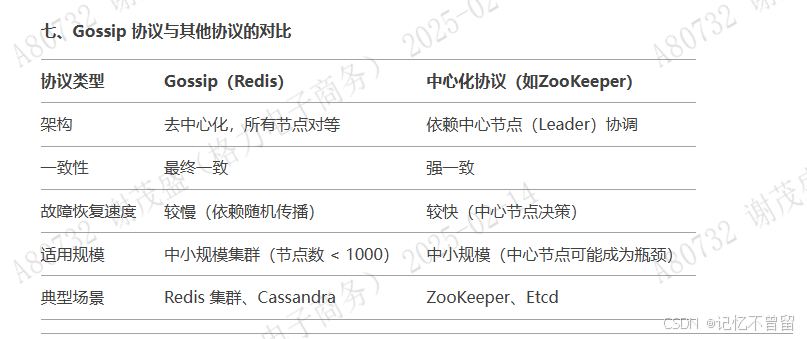
Redis Cluster 的 Gossip 通信机制
MEET:通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群,然后新节点就会开始与其他节点进行通信; PING:节点按照配置的时间间隔向集群中其他节点发送 ping 消息,消息中带有自己的状态,还有自己维护的集群元数据,和部分其他节点的元数据; PONG: 节点用于回应 PING 和 MEET 的消息,结构和 PING 消息类似,也包含自己的状态和其他信息,也可以用于信息广播和更新; FAIL: 节点 PING 不通某节点后,会向集群所有节点广播该节点挂掉的消息。其他节点收到消息后标记已下线。







Redis 集群主节点故障转移与 Raft 算法选举机制详解
- 故障检测阶段
当 Redis 集群中的主节点发生故障时,故障转移过程的核心是快速检测故障和选举新的主节点。以下是详细流程:
- 心跳检测机制:
所有节点通过Gossip 协议 定期(默认每秒)发送 PING/PONG 消息交换状态。 若某主节点在 cluster-node-timeout(默认 15 秒)内未响应,其他节点将其标记为 PFAIL(疑似下线)。
- 确认故障:
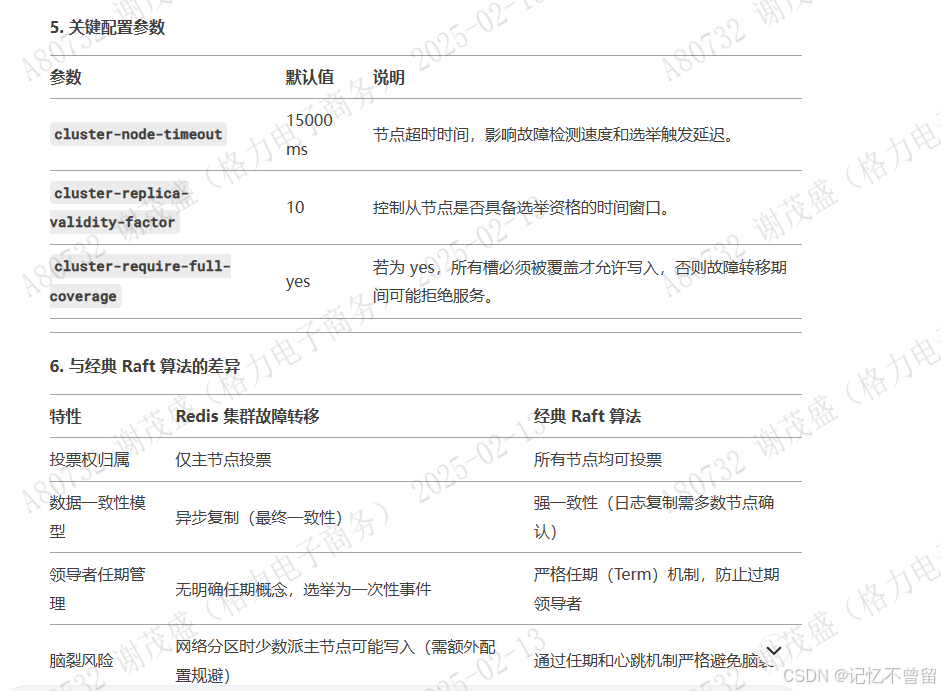
当超过半数的主节点确认该主节点不可达,其状态会被升级为 FAIL(确认下线)。 触发故障转移的前提条件:主节点处于 FAIL 状态,且该主节点至少有一个从节点在线。
- 从节点发起选举
故障确认后,该主节点对应的从节点会发起选举,尝试成为新的主节点:
资格检查:
从节点必须与主节点的数据同步差距(复制偏移量)在合理范围内。 从节点需满足 cluster-replica-validity-factor 配置(默认 10),即最后一次与主节点通信的时间不超过 (node-timeout * validity-factor) + 1000 毫秒
选举触发:
从节点检测到主节点FAIL后,等待一个随机延迟(防止多个从节点同时发起选举),随后向集群广播 FAILOVER_AUTH_REQUEST 消息,请求投票。



redis集群模式下 脑裂问题
在分布式系统中,脑裂通常指由于网络分区导致集群被分成多个独立的部分,每个部分可能认为其他部分已经失效,从而选举出新的主节点,导致多个主节点同时存在,进而引发数据不一致的问题。 在Redis集群中,这种情况可能会导致不同分区内的节点同时接受写请求,从而产生冲突的数据。
Redis集群使用分片(Sharding)和主从复制(Replication)来实现高可用性和数据分布。每个主节点负责一部分哈希槽,从节点作为备份。 当主节点失效时,从节点会通过选举机制晋升为主节点。然而,如果网络分区导致主节点被隔离,可能出现多个主节点同时处理写请求的情况