前言
Netty从底层Java通道读取ByteBuf二进制数据,传入Netty通道的流水线,随后开始入站处理。在入站处理过程中,需要将ByteBuf二进制类型解码成Java POJO对象。这个解码过程可以通过Netty的Decoder(解码器)去完成。
在出站处理过程中,业务处理后的结果(出站数据)需要从某个Java POJO对象编码为最终的ByteBuf二进制数据,然后通过底层Java通道发送到对端。在编码过程中,需要用到Netty的Encoder(编码器)去完成数据的编码工作。
解码器:入站处理过程中,将ByteBuf二进制类解码为Java POJO对象;
编码器:出站处理过程中,将Java POJO对象编码为ByteBuf二进制数据。
Decoder原理与实战
Netty解码器是什么?
(1)它是一个InBound入站处理器,负责处理"入站数据"。
(2)它能将上一站Inbound入站处理器传过来的输入(Input)数据进行解码或者格式转换,然后发送到下一站Inbound入站处理器。
一个标准的解码器的职责为:将输入类型为ByteBuf的数据进行解码,输出一个一个的Java POJO对象。Netty内置了yteToMessageDecoder解码器。
Netty中的解码器都是Inbound入站处理器类型,都直接或者间接地实现了入站处理的超级接口ChannelInboundHandler。
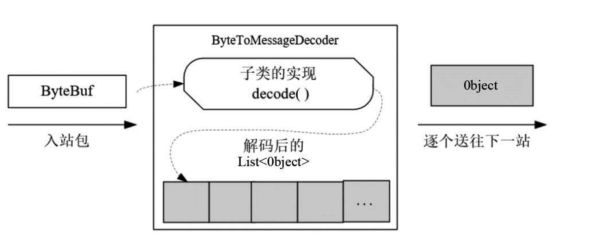
ByteToMessageDecoder解码器处理流程
ByteToMessageDecoder是一个非常重要的解码器基类,是一个抽象类,实现了解码处理的基础逻辑和流程。ByteToMessageDecoder继承自ChannelInboundHandlerAdapter适配器,是一个入站处理器,用于完成从ByteBuf到Java POJO对象的解码功能。
ByteToMessageDecoder解码的流程大致如图所示。
自定义Byte2IntegerDecoder整数解码器
由于解码器的功能仅仅是完成ByteBuf的解码,不做其他业务处理,所以还需要编写一个业务处理器,用于在读取解码后的Java POJO对象之后完成具体的业务处理。
IntegerProcessHandler.class
ReplayingDecoder解码器
使用上面的Byte2IntegerDecoder整数解码器会面临一个问题:需要对ByteBuf的长度进行检查,有足够的字节才能进行整数的读取。这种长度的判断是否可以由Netty来帮忙完成呢?答案是可以的,可以使用Netty的ReplayingDecoder类省去长度的判断。
ReplayingDecoder对输入的ByteBuf进行了"偷梁换柱",在将外部传入的ByteBuf缓冲区传给子类之前,换成了自己装饰过的ReplayingDecoderBuffer缓冲区。也就是说,在示例程序中,Byte2IntegerReplayDecoder中的decode()方法所得到的实参in的直接类型并不是原始的ByteBuf类型,而是ReplayingDecoderBuffer类型。
实质上,ReplayingDecoder的作用远远不止于进行长度判断,它更重要的作用是用于分包传输的应用场景。
整数的分包解码器的实战案例
通道接收到的ByteBuf数据包和发送端发送的数据包不完全一致:
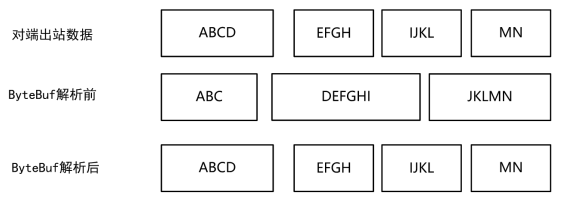
Netty通过什么样的解码器对图中接收端的3个ByteBuf缓冲数据进行解码,而后得到和发送端一模一样的4个字符串呢?理论上可以使用ReplayingDecoder来解决。在进行数据解析时,如果发现当前ByteBuf中所有可读的数据不够,那么ReplayingDecoder会一直等待,直到可读数据是足够的。这一切都是在ReplayingDecoder内部,通过与缓冲区装饰器ReplayingDecoderBuffer相互配合完成的。
Byte2IntegerReplayDecoderTester
字符串的分包解码器的实战案例
在原理上,字符串分包解码和整数分包解码是一样的,所不同的是:整数的长度是固定的,目前在Java中是4字节;字符串的长度是不固定的,是可变的。
如何获取字符串的长度信息呢?这是一个小小的难题,和程序所使用的具体传输协议是强相关的。一般来说,在Netty中进行字符串的传输可以采用普通的Head-Content内容传输协议。该协议的规则很简单:
(1)在协议的Head部分放置字符串的字节长度,可以用一个整数类型来描述。
(2)在协议的Content部分,放置字符串的字节数组。
MessageToMessageDecoder解码器
与前面不同的是,解码器需要继承一个新的Netty解码器基类MessageToMessageDecoder<I>。在继承它的时候,需要明确的泛型实参<I>,用于指定入站消息的Java POJO类型。
为什么继承MessageToMessageDecoder<I>时需要指定入站数据的类型,而在前面继承ByteToMessageDecoder解码ByteBuf时不需要指定泛型实参呢?原因很简单:ByteToMessageDecoder的入站消息类型是十分明确的,就是二进制缓冲区ByteBuf类型;MessageToMessageDecoder<I>的入站消息类型是不明确的,可以是任何POJO类型,所以需要指定。
常用的内置Decoder
Netty提供了不少开箱即用的Decoder(解码器),能够满足很多编解码应用场景的需求。
(1)固定长度数据包解码器------FixedLengthFrameDecoder
(2)行分割数据包解码器------LineBasedFrameDecoder
(3)自定义分隔符数据包解码器------DelimiterBasedFrameDecoder
(4)自定义长度数据包解码器------LengthFieldBasedFrameDecoder
LineBasedFrameDecoder解码器
LineBasedFrameDecoder,它是一个最为基础的Netty内置解码器。这个解码器的工作原理很简单,依次遍历ByteBuf数据包中的可读字节,判断在二进制字节流中是否存在换行符"\n"或者"\r\n"的字节码。如果有,就以此位置为结束位置,把从可读索引到结束位置之间的字节作为解码成功后的ByteBuf数据包。
LineBasedFrameDecoder,它是一个最为基础的Netty内置解码器。这个解码器的工作原理很简单,依次遍历ByteBuf数据包中的可读字节,判断在二进制字节流中是否存在换行符"\n"或者"\r\n"的字节码。如果有,就以此位置为结束位置,把从可读索引到结束位置之间的字节作为解码成功后的ByteBuf数据包。
DelimiterBasedFrameDecoder解码器
DelimiterBasedFrameDecoder解码器不仅可以使用换行符,还可以使用其他特殊字符作为数据包的分隔符,例如制表符"\t"。
LengthFieldBasedFrameDecoder解码器
传输内容中的Length(长度)字段的值是指存放在数据包中要传输内容的字节数。普通的基于Head-Content协议的内容传输尽量用内置的LengthFieldBasedFrameDecoder来解码。
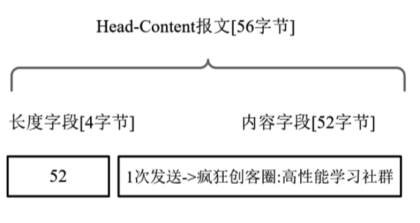
多字段Head-Content协议数据包解析的实战案例

Encoder原理与实战
在Netty的业务处理完成后,业务处理的结果往往是某个Java POJO对象需要编码成最终的ByteBuf二进制类型,通过流水线写入底层的Java通道,这就需要用到Encoder(编码器)。
在Netty中,什么叫编码器?首先,编码器是一个Outbound出站处理器,负责处理"出站"数据;其次,编码器将上一站Outbound出站处理器传过来的输入(Input)数据进行编码或者格式转换,然后传递到下一站ChannelOutboundHandler出站处理器。
MessageToByteEncoder编码器
MessageToByteEncoder是一个非常重要的编码器基类,位于Netty的io.netty.handler.codec包中。MessageToByteEncoder的功能是将一个Java POJO对象编码成一个ByteBuf数据包。
MessageToMessageEncoder编码器
能够通过Netty的编码器将某种POJO对象编码成另外一种POJO对象呢?答案是肯定的。需要继承另外一个Netty的重要编码器------MessageToMessageEncoder编码器,并实现它的encode()抽象方法。在子类的encode()方法实现中,完成原POJO类型到目标POJO类型的转换逻辑。在encode()实现方法中,编码完成后,将解码后的目标对象加入encode()方法中的实参list输出容器即可。
解码器和编码器的结合
在实际的开发中,由于数据的入站和出站关系紧密,因此编码器和解码器的关系很紧密。
前面讲到编码器和解码器是分开实现的。例如,通过继承ByteToMessageDecoder基类或者其子类,完成ByteBuf数据包到POJO的解码工作;通过继承基类MessageToByteEncoder或者其子类,完成POJO到ByteBuf数据包的编码工作。总之,具有相反逻辑的编码器和解码器分开实现在两个不同的类中,导致的一个结果是相互配套的编码器和解码器在加入通道的流水线时常常需要分两次添加。
ByteToMessageCodec编解码器
现在的问题是:具有相互配套逻辑的编码器和解码器能否放在同一个类中呢?答案是肯定的,这需要用到Netty的新类型------Codec(编解码器)。
编解码器ByteToMessageCodec同时包含了编码encode()和解码decode()两个抽象方法,这两个方法都需要我们自己实现:
(1)编码方法------encode(ChannelHandlerContext, I,ByteBuf)。
(2)解码方法------decode(ChannelHandlerContext, ByteBuf,List)。
CombinedChannelDuplexHandler组合器
前面的编码器和解码器相结合是通过继承完成的。继承的不足之处在于:将编码器和解码器的逻辑强制性地放在同一个类中,在只需要编码或者解码单边操作的流水线上,逻辑上不大合适。
编码器和解码器如果要结合起来,除了继承的方法之外,还可以通过组合的方式实现。与继承相比,组合会带来更大的灵活性:编码器和解码器可以捆绑使用,也可以单独使用。