大家好,这里是架构资源栈 !点击上方关注,添加"星标",一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!

最近,Channable 团队发布了一个新的开源项目 ------ Opsqueue。这是为了解决"重批处理"需求所设计的一套轻量级队列系统,现在终于公开了!
说白了,Opsqueue 是为那些动辄几百万操作、强调吞吐量、注重处理顺序、又不想部署一整套 Kafka 或 Celery 的团队准备的。
为什么需要另造一个轮子?
有几个明确的需求:
- 轻量简洁:用 Rust 写的小巧代码库,依赖少,部署容易。
- 批处理优先:强调吞吐量,而非实时性,适合"今天生成,明天处理"的模式。
- 弹性可扩展:支持水平扩展,能够处理十亿级别的操作量。
- 技术栈扎实:SQLite + 对象存储(S3、GCS 等)+ Rust,稳定、可靠、性能高。
- 部署简单:单个二进制,嵌入式数据库,最小配置即可上手。
Channable 团队之前试过各种方案,从 Redis 列表到 PostgreSQL 表格队列,还有数据库元数据 + 对象存储混合方案......但总归不是特别理想:不是易错就是扩展性差。于是我们决定,"干脆造一个真正通用的队列系统"!
设计核心:"生成 - 执行" 模式
在很多服务中都看到类似的流程:
- A 服务生成数百万个操作(例如一堆图像处理任务、API 调用、LLM 推理等);
- 把这些操作扔进"输入队列";
- B 服务(或多台服务)并行执行这些任务;
- 然后把结果写回"输出队列";
- A 服务再根据结果做下一步处理(例如拼装成结果、触发后续逻辑等)。
我们把这个流程称为 "generate-execute" 模式,它是 Producer-Consumer 的一个进阶变种 ------ 类似于 MapReduce,但没有 reduce,也可以看作是并行 Map 操作的分布式实现。
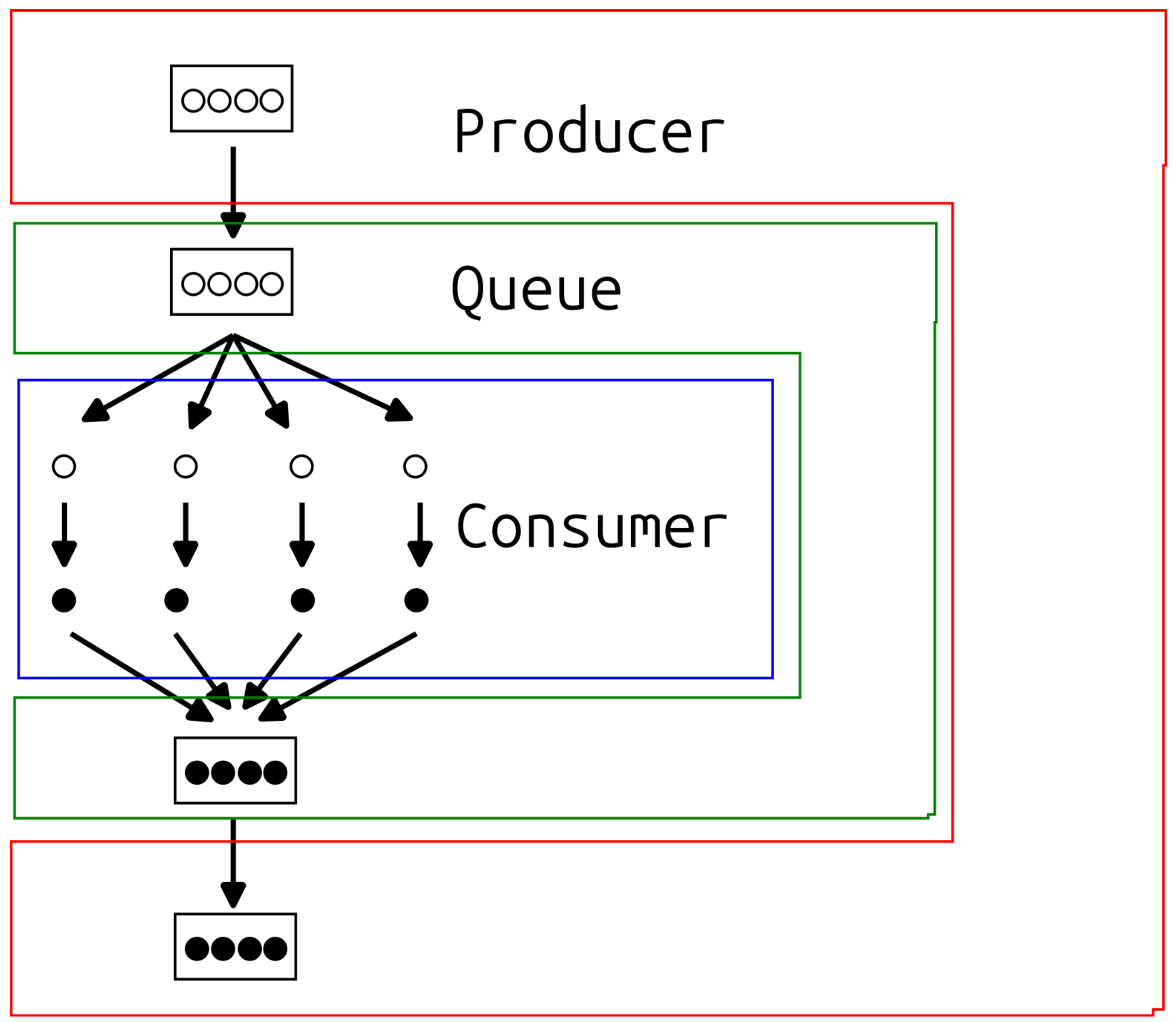
我们希望的是:生产者(Producer)只管提交任务,消费者(Consumer)按需并行处理,并且结果可以有序地回传给生产者。这个闭环非常重要。
为什么不选现有的队列系统?
先看简单对比:
| 特性 | Kafka | RabbitMQ | Redis List | Opsqueue |
|---|---|---|---|---|
| 有序性保障 | 分区级顺序 | 仅支持 FIFO 队列 | 无强一致顺序保障 | 完整任务有序性 |
| 部署复杂度 | 高 | 中等偏上 | 低 | 极低(单文件即可运行) |
| 消费端灵活度 | 高(需自实现) | 中 | 低 | 高,支持动态调度策略 |
| 数据持久性 | 高 | 高 | 中 | 高(结合对象存储) |
| 支持大批量 | 适合但偏实时 | 支持但繁琐 | 不适合 | 极其适合批处理 |
| 使用门槛 | 较高 | 中等 | 极低 | 低(Rust 单二进制部署) |
-
Kafka 是高吞吐利器,但维护 ZooKeeper、Broker、Schema Registry 不易;
-
RabbitMQ 虽然灵活但 AMQP 配置繁琐;
-
Redis List 容易入门但扩展性差,且不具备任务元信息能力。
而 Opsqueue 以 Rust 编写、只依赖 SQLite 和对象存储,初始部署成本几乎为零,却在批处理吞吐、数据一致性、任务调度灵活性上做到了高度平衡。
虽然像 RabbitMQ、Kafka、SQS 等已经非常成熟,但对我们来说,它们存在如下几个痛点:
- 无法保证有序性:我们需要任务提交和返回能对齐。
- 提交要么全成要么全失败:不能部分成功,这样处理逻辑才干净。
- 要抗网络问题,还要保持一致性:我们偏向一致性而不是可用性。
- 队列不能饿死某些用户:要确保使用公平。
- 操作必须是任意格式:支持任何语言,任何数据类型。
- 优先级要由消费者决定:因为执行方才最清楚什么该先做(比如 GPU 使用率、API 限流等)。
市面上的系统几乎没有同时满足这些点的。
技术选型:Rust + SQLite + 对象存储
Opsqueue的目标是 部署简单,维护轻松,开发友好。所以Opsqueue选择:
- Rust 实现,编译成单个可执行文件;
- SQLite 存储操作元数据(轻量 + 嵌入式);
- S3/GCS 等对象存储保存真正的任务数据;
- 支持 Litestream 实时备份数据库;
- 所有网络交互尽量保持在亚毫秒级。
这种设计让Opsqueue可以轻松运行数百个独立队列,测试也非常容易 ------ 每个测试用例起一个 Opsqueue 实例毫秒级完成。
技术架构亮点
- 任务分片(chunking)设计:一次性提交几十万个操作分成多个 chunk,每个 chunk 几秒完成,提升并发度与容错能力;
- 元数据存 SQLite,任务体存对象存储(如 S3/GCS):减轻数据库压力,提高 I/O 性能;
- 消费者优先调度机制:任务优先级可由消费者决策,例如根据 GPU 利用率、用户 ID、API 调用限额等;
- Litestream 支持:通过持续同步 SQLite 数据库至远端对象存储实现高可用备份;
- 可视化性能分析:内置 OpenTelemetry,便于链路追踪和延迟分析。
消费者优先策略:我们最大的杀手锏
传统队列系统通常由 生产者来决定任务优先级 ,而 Opsqueue 反其道而行之:让消费者决定优先顺序。
为啥?因为消费者最清楚实际资源情况 ------ 哪台机器空闲?哪个用户快被限流了?哪个数据中心比较空?
Opsqueue支持生产者附带元数据(比如用户 ID、优先级数字),但最终决策权归消费者所有。这种机制非常灵活,可以支持更复杂的调度策略,比如:
- 某类任务只能在指定区域执行;
- 保障用户公平;
- 优先执行短任务提高吞吐;
- GPU 资源有限时自动排队;
- 跨业务统一调度等。
性能与扩展性:小而美,也能顶得住大风浪
为了支持十亿级别操作,Opsqueue采取了一些设计策略:
- 任务按"chunk"提交:每个 chunk 处理时间控制在几秒内,降低协调成本;
- 数据存对象存储,SQLite 仅存元数据:存储压力低,查询快;
- chunk 大小可调节:更好地平衡并发度与通信开销;
- 支持分片(sharding):当规模再上去时,轻松横向扩展;
- 内置 OpenTelemetry tracing:性能指标一目了然。
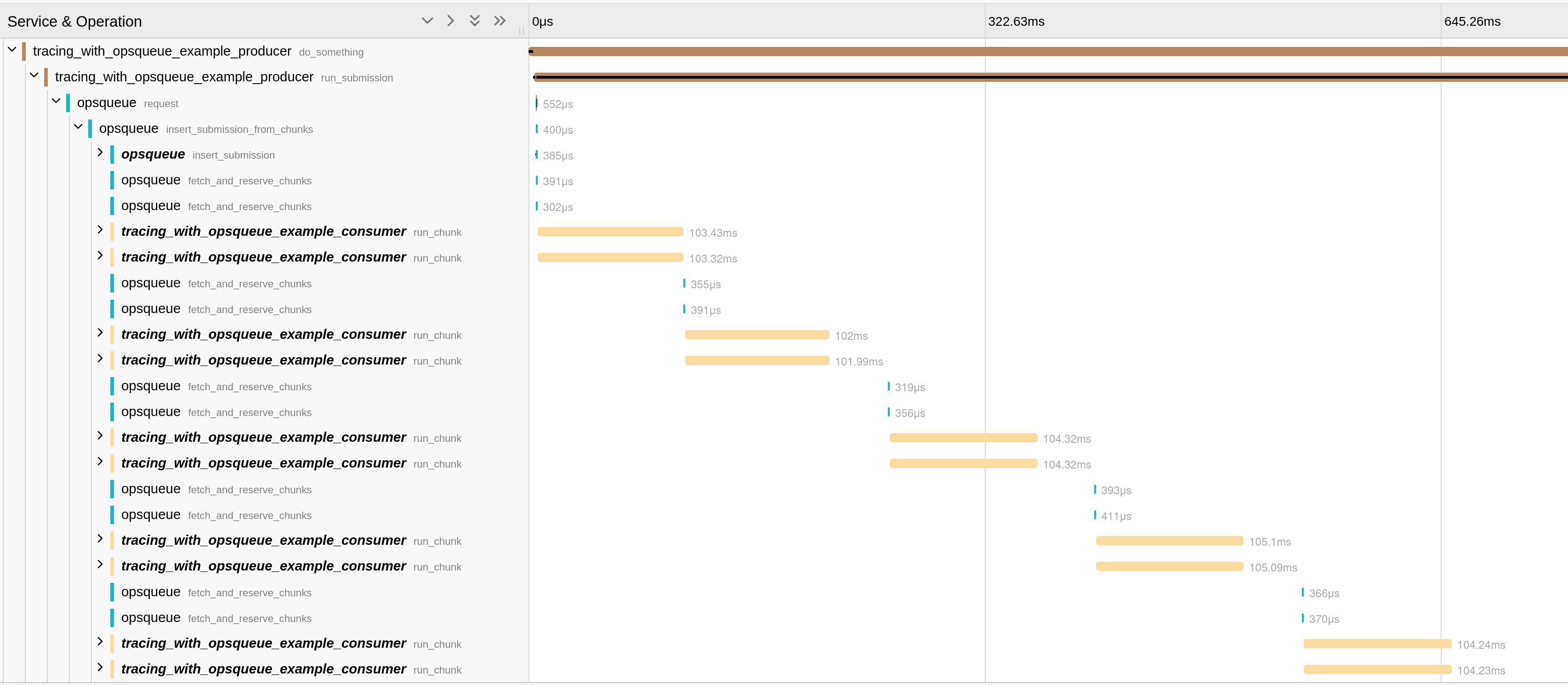
来看一张调试图,展示两个消费者同时连接队列时的 tracing 数据,注意 ------ 队列通信开销仅仅是亚毫秒级!
Rust:不是炫技,而是效率保障
Opsqueue不仅用 Rust 实现主程序,还通过 FFI 接口暴露给 Python 用作客户端。逻辑全在 Rust 中统一实现,避免多语言重复造轮子,也大大降低了 bug 风险。
目前Opsqueue已支持 Python 的客户端开发,入门示例点这里。未来要加 Java、Go、Node.js?可能一个下午就能搞定!
在生产环境的表现如何?
Opsqueue 已经在Channable 团队生产环境里跑了快半年。一条生产队列:
- 完成了 10 万次提交;
- 处理速率稳定在每小时 100 万操作;
- 通信延迟始终维持在毫秒级以内;
- 整体表现令人满意!
当然,Channable 团队不会强制重写已有的其他系统(毕竟重写是个大坑),但凡是要维护、扩展、或踩了老系统性能瓶颈的项目,Opsqueue 是可以考虑的替代方案!
写在最后
我相信:你可能也遇到过类似的需求。希望 Opsqueue 这个项目能帮上忙,或者激发你构建更好的队列系统!
祝你的任务队列永不卡顿,批处理永不爆炸!
喜欢就奖励一个"👍"和"在看"呗~