前两篇我们完成了 无泄露 PCA 预处理 与 k-NN 分类 。链接,https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzkwMTE0MjI4NQ==\&action=getalbum\&album_id=4119240160615596034#wechat_redirect
本篇引入更强的 支持向量机 (SVM) 与 随机森林 (RF),利用交叉验证自动调参,形成可靠的基线模型,并增加整图预测与参数可视化。
🎯 本文目标
- 保持严格无数据泄露:
StandardScaler和PCA仅在训练集上fit。 - 使用 GridSearchCV 在训练集上做超参数搜索。
- 输出完整评估指标:OA / AA / Kappa + 分类报告。
- 绘制混淆矩阵(新配色)与 PCA 累计解释方差曲线。
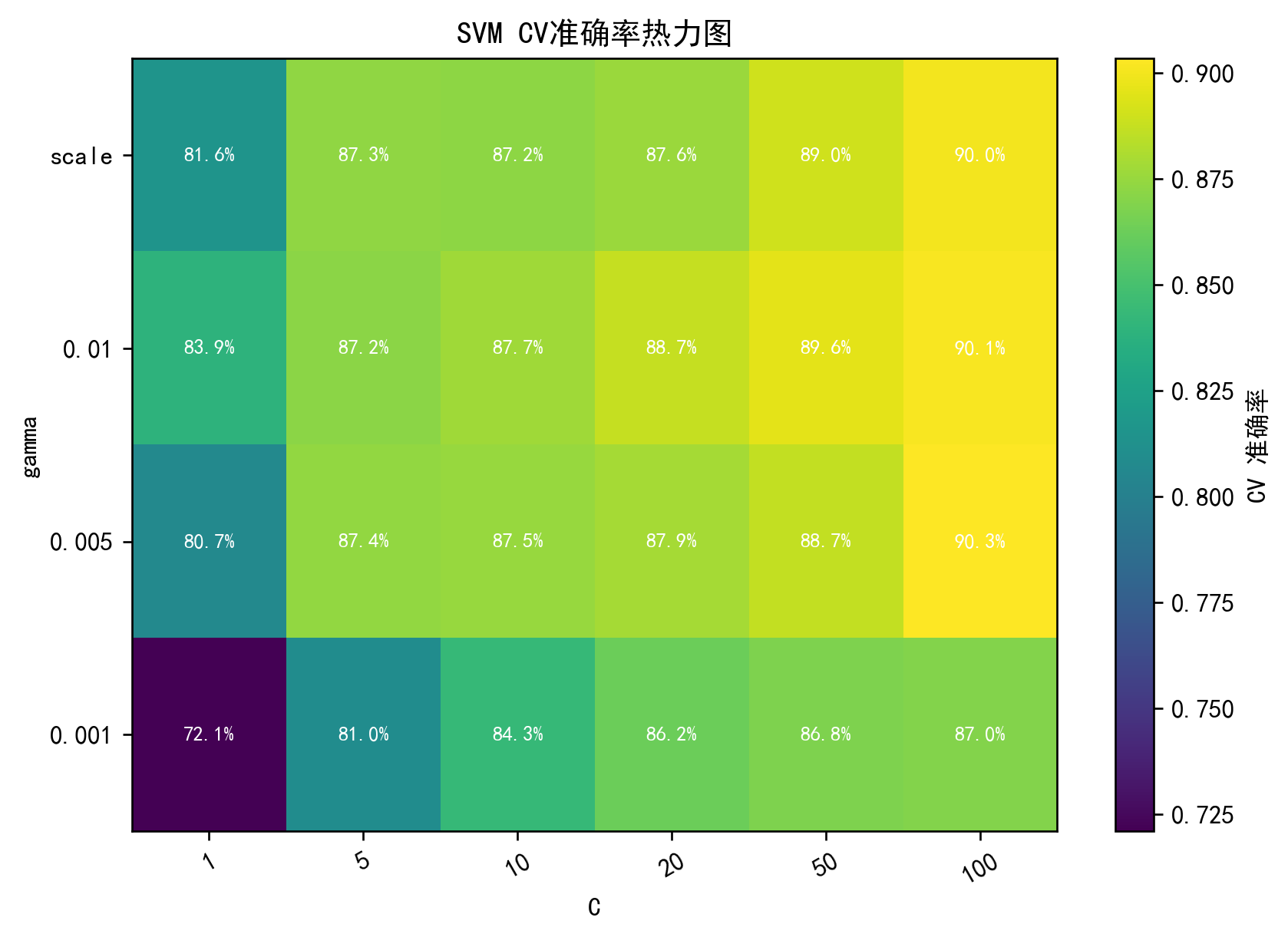
- 可视化参数影响:SVM 的
C×gamma热力图,RF 的n_estimators×max_depth热力图。 - 整图预测:不遮挡未知区域,完整渲染。
📂 数据准备
与前篇相同:
- KSC.mat :高光谱数据
(H, W, B) - KSC_gt.mat :标签图
(H, W),其中 0=背景,1...C 为类别
plaintext
your_path/
├─ KSC.mat
└─ KSC_gt.mat只需修改脚本中的 DATA_DIR = r"your_path"。
① 环境与依赖
python
import os, time, json
import numpy as np
import scipy.io as sio
import matplotlib
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score, cohen_kappa_score说明:导入 Numpy/Scipy 做数据处理,Matplotlib 绘图,Scikit-learn 提供 PCA、SVM、RF 与评估工具。
② 参数设置
python
DATA_DIR = r"your_path" # 修改为你的数据目录
PCA_DIM = 30
TRAIN_RATIO = 0.3
SEED = 42
N_FOLDS = 5说明:这里设置 PCA 主成分数=30,训练集占比=30%,并固定随机种子保证可复现。
③ 加载与划分数据
python
X = sio.loadmat(os.path.join(DATA_DIR, "KSC.mat"))["KSC"].astype(np.float32)
Y = sio.loadmat(os.path.join(DATA_DIR, "KSC_gt.mat"))["KSC_gt"].astype(int)
h, w, b = X.shape
coords = np.argwhere(Y != 0) # 有标签像素坐标
labels = Y[coords[:, 0], coords[:, 1]]-1 # 转为 0-based说明:只取有标签像素做监督学习,避免背景 0 干扰。
④ 无泄露预处理:仅用训练像素 fit
python
from sklearn.model_selection import train_test_split
train_ids, test_ids = train_test_split(
np.arange(len(coords)), train_size=TRAIN_RATIO,
stratify=labels, random_state=SEED)
train_pixels = X[coords[train_ids,0], coords[train_ids,1]]
scaler = StandardScaler().fit(train_pixels)
pca = PCA(n_components=PCA_DIM, random_state=SEED).fit(scaler.transform(train_pixels))说明:
- fit 仅用训练像素:防止测试信息泄露。
- 顺序:
StandardScaler→PCA。
⑤ 整图统一变换
python
X_flat = X.reshape(-1, b)
X_std = scaler.transform(X_flat)
X_pca_flat = pca.transform(X_std)
X_pca = X_pca_flat.reshape(h, w, PCA_DIM)
X_train = X_pca[coords[train_ids,0], coords[train_ids,1]]
y_train = labels[train_ids]
X_test = X_pca[coords[test_ids,0], coords[test_ids,1]]
y_test = labels[test_ids]说明:整幅影像使用相同参数变换;之后提取训练/测试像素用于建模。
⑥ PCA 累计解释方差曲线
python
cum_var = np.cumsum(pca.explained_variance_ratio_)
plt.plot(np.arange(1, len(cum_var)+1), cum_var, marker='o')
plt.axhline(0.95, ls='--', label="95% 阈值")
plt.axvline(PCA_DIM, ls='--', label=f"n={PCA_DIM}")
plt.xlabel("主成分数"); plt.ylabel("累计解释方差比")
plt.title("PCA累计解释方差曲线"); plt.legend(); plt.show()说明:辅助判断保留多少维合适(常取解释方差 >95%)。
⑦ 模型与网格搜索
python
skf = StratifiedKFold(n_splits=N_FOLDS, shuffle=True, random_state=SEED)
svm_grid = GridSearchCV(SVC(kernel="rbf"),
param_grid={"C":[1,5,10,20,50,100],"gamma":["scale",0.01,0.005,0.001]},
cv=skf, n_jobs=-1).fit(X_train, y_train)
rf_grid = GridSearchCV(RandomForestClassifier(random_state=SEED,n_jobs=-1),
param_grid={"n_estimators":[200,400,800],"max_depth":[None,10,20,40]},
cv=skf, n_jobs=-1).fit(X_train, y_train)说明:使用分层K折交叉验证,在训练集上搜索最优参数。
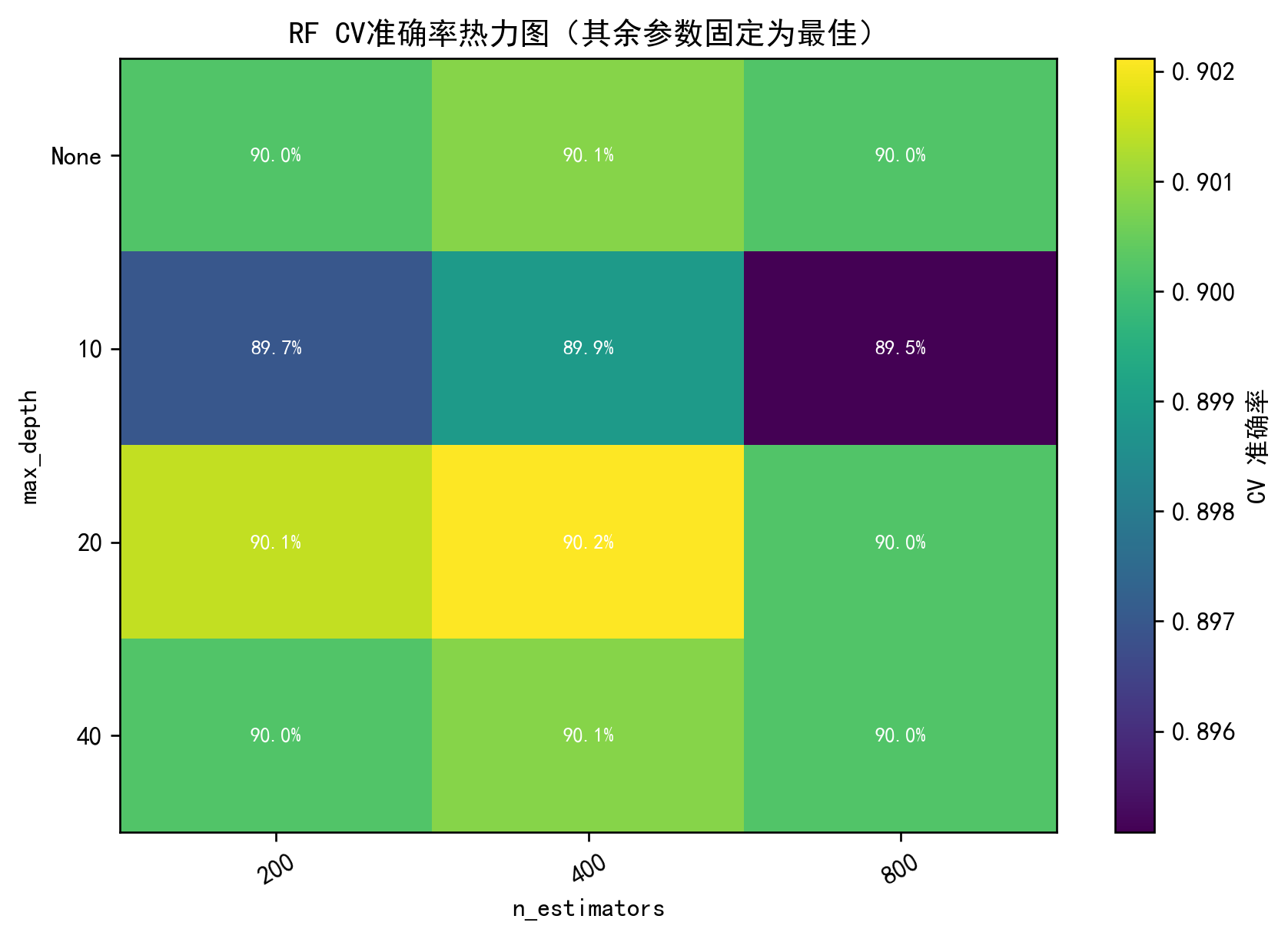
⑧ 参数可视化
SVM:C×gamma 热力图
python
Cs=[1,5,10,20,50,100]; Gs=["scale",0.01,0.005,0.001]
Z=np.full((len(Gs),len(Cs)),np.nan)
for mean,params in zip(svm_grid.cv_results_["mean_test_score"], svm_grid.cv_results_["params"]):
i,j = Gs.index(str(params["gamma"])), Cs.index(params["C"])
Z[i,j]=mean
plt.imshow(Z,cmap="viridis"); plt.colorbar(label="CV准确率")
plt.xticks(range(len(Cs)),Cs); plt.yticks(range(len(Gs)),Gs)
plt.title("SVM参数热力图"); plt.show()说明 :直观展示不同 C 和 gamma 的组合对准确率的影响。
⑨ 测试集评估
python
from sklearn.metrics import classification_report
svm_best=svm_grid.best_estimator_; rf_best=rf_grid.best_estimator_
y_pred_svm=svm_best.predict(X_test); y_pred_rf=rf_best.predict(X_test)
print("SVM最佳参数:",svm_grid.best_params_)
print(classification_report(y_test,y_pred_svm))
print("RF最佳参数:",rf_grid.best_params_)
print(classification_report(y_test,y_pred_rf))说明:输出每类的 precision/recall/F1,以及整体 OA / Kappa。
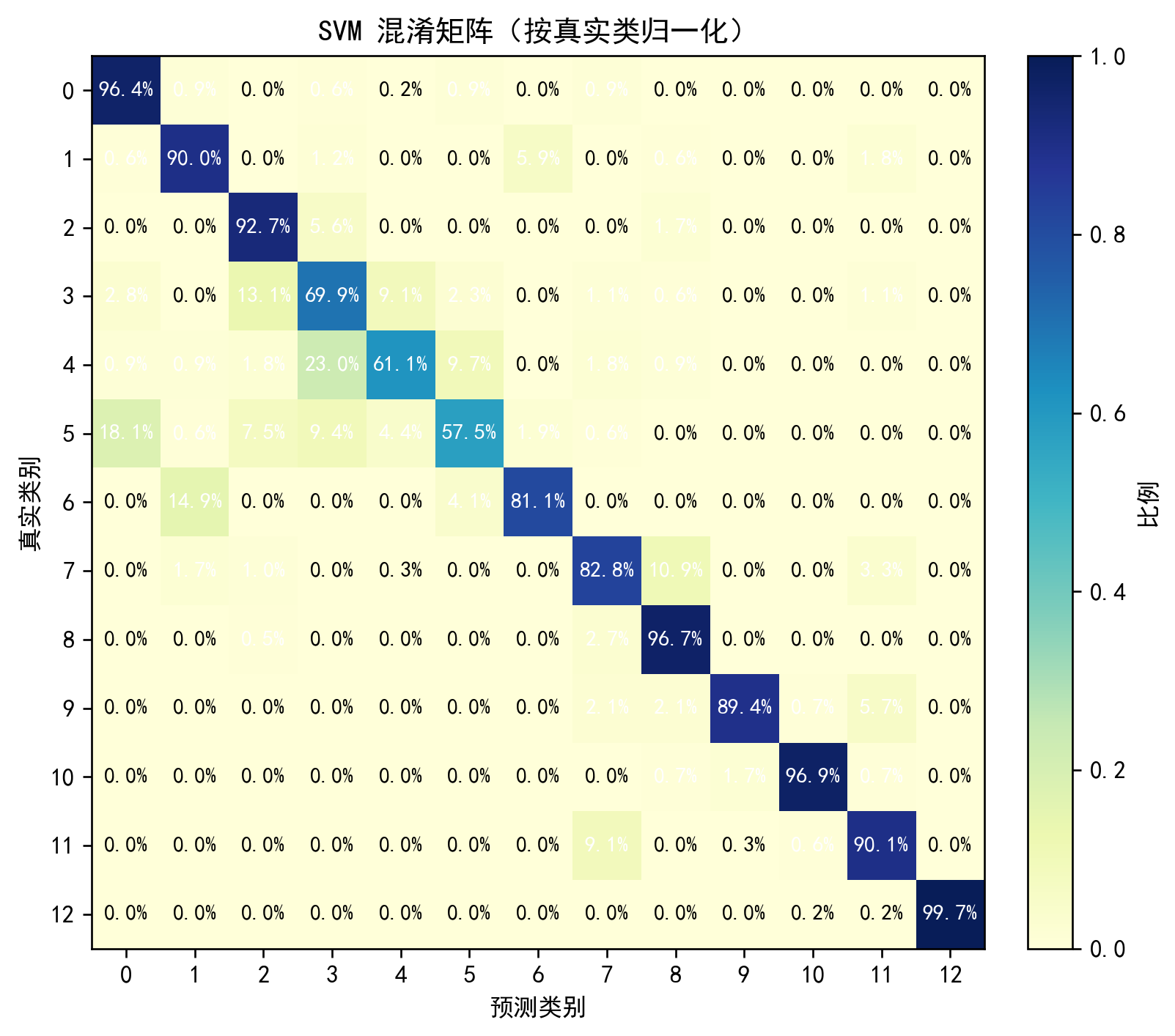
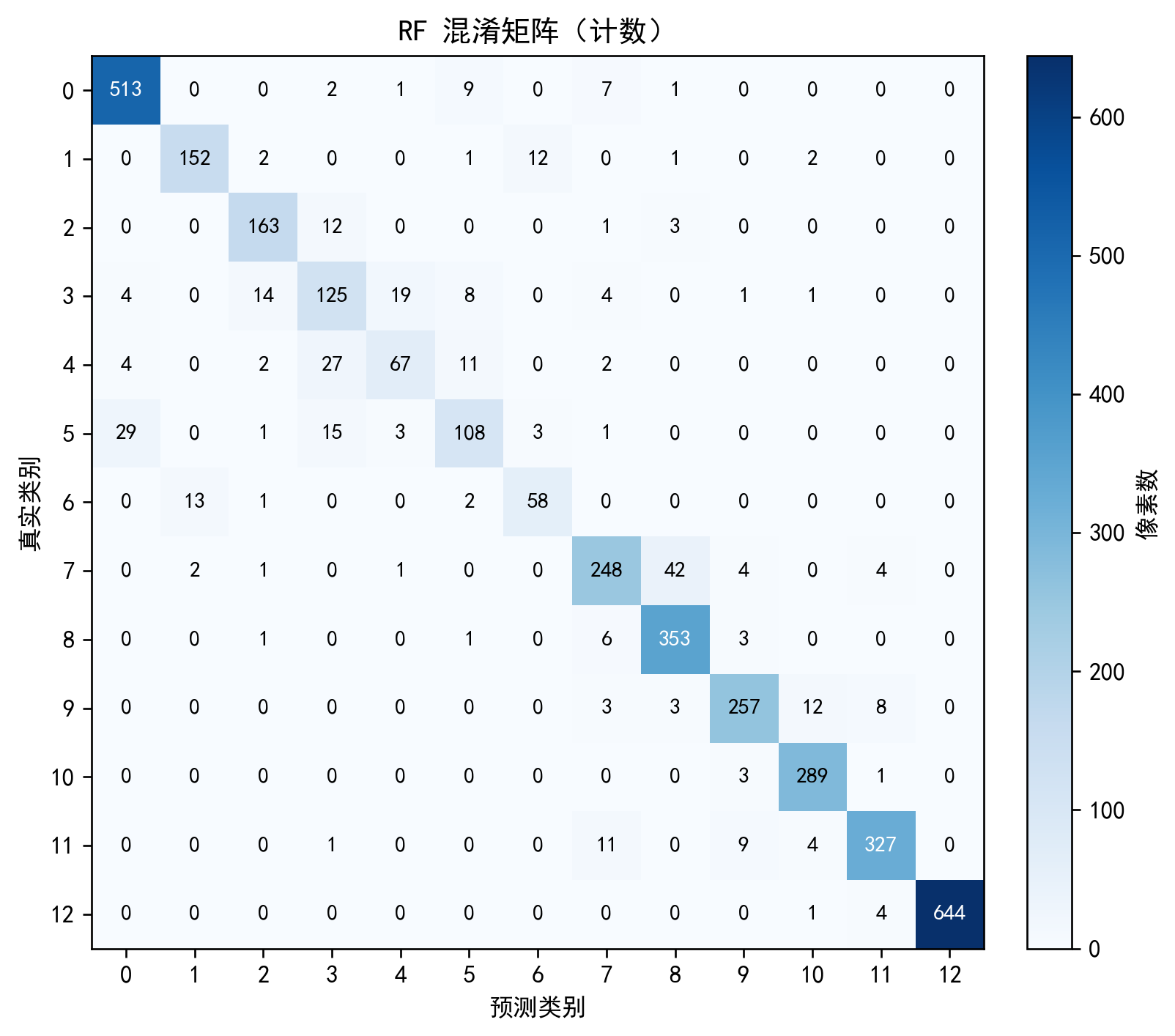
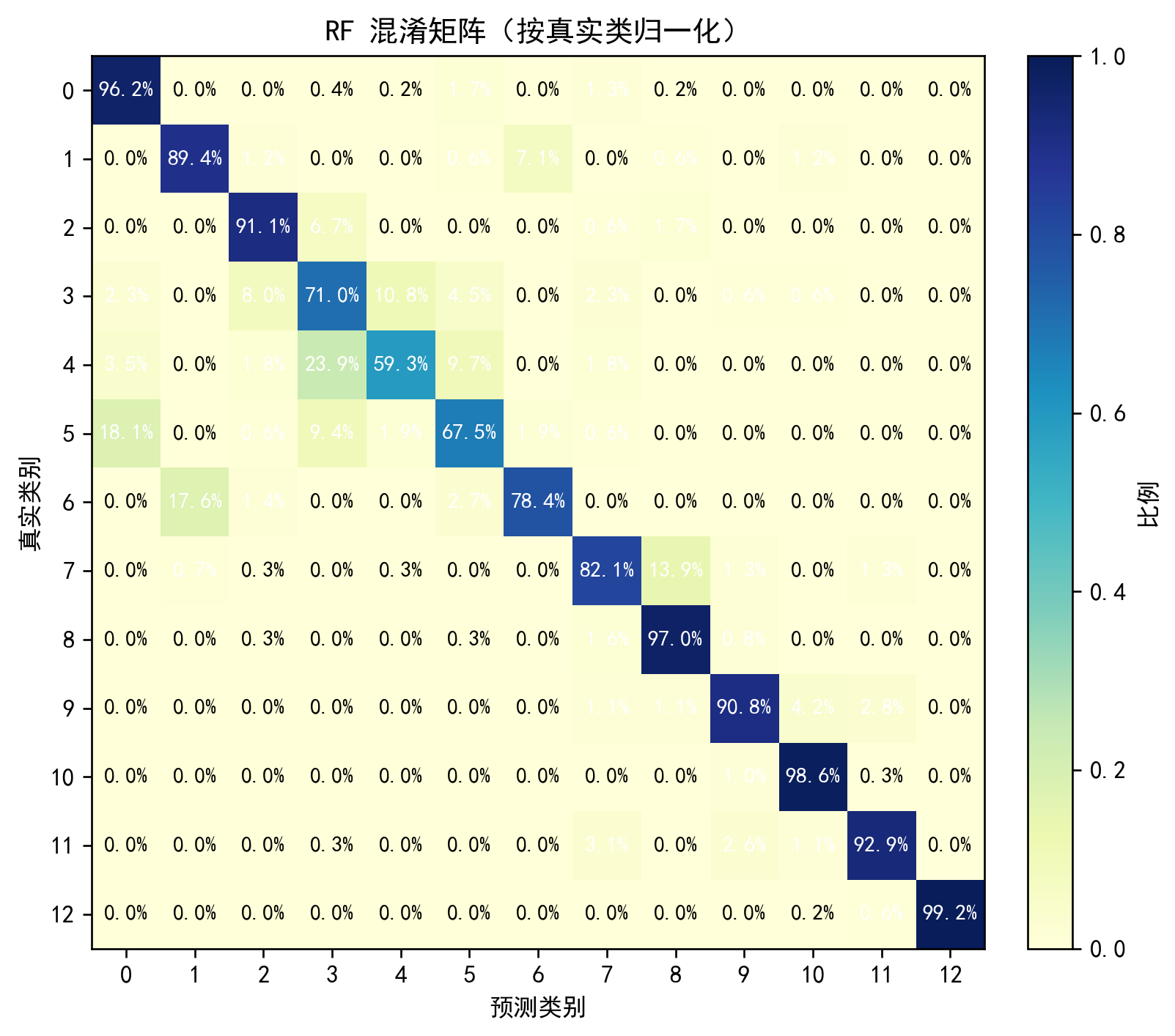
⑩ 混淆矩阵(新配色)
python
cm = confusion_matrix(y_test,y_pred_svm)
plt.imshow(cm,cmap="Blues"); plt.title("SVM混淆矩阵"); plt.colorbar(); plt.show()
cmn=cm/cm.sum(axis=1,keepdims=True)
plt.imshow(cmn,cmap="YlGnBu",vmin=0,vmax=1); plt.title("SVM混淆矩阵(归一化)")
plt.colorbar(); plt.show()说明:两版配色:计数=Blues,归一化=YlGnBu,更直观。
⑪ 整图预测(完整渲染)
python
best_model=svm_best if accuracy_score(y_test,y_pred_svm)>=accuracy_score(y_test,y_pred_rf) else rf_best
pred_map=best_model.predict(X_pca_flat).reshape(h,w)+1
from matplotlib.colors import ListedColormap
cmap=ListedColormap([plt.cm.tab20(i%20) for i in range(len(np.unique(labels)))])
plt.imshow(pred_map,cmap=cmap); plt.title("整图预测结果"); plt.axis("off"); plt.show()说明:直接对整幅图预测,不遮挡背景区域。
🔚 总结
- 我们在无泄露 前提下,对 SVM 与 RF 做了自动调参。
- 输出了完整指标、混淆矩阵、新配色图表。
- 可视化了超参数影响,帮助理解模型行为。
- 实现了整图预测,方便直观对比。
结果:

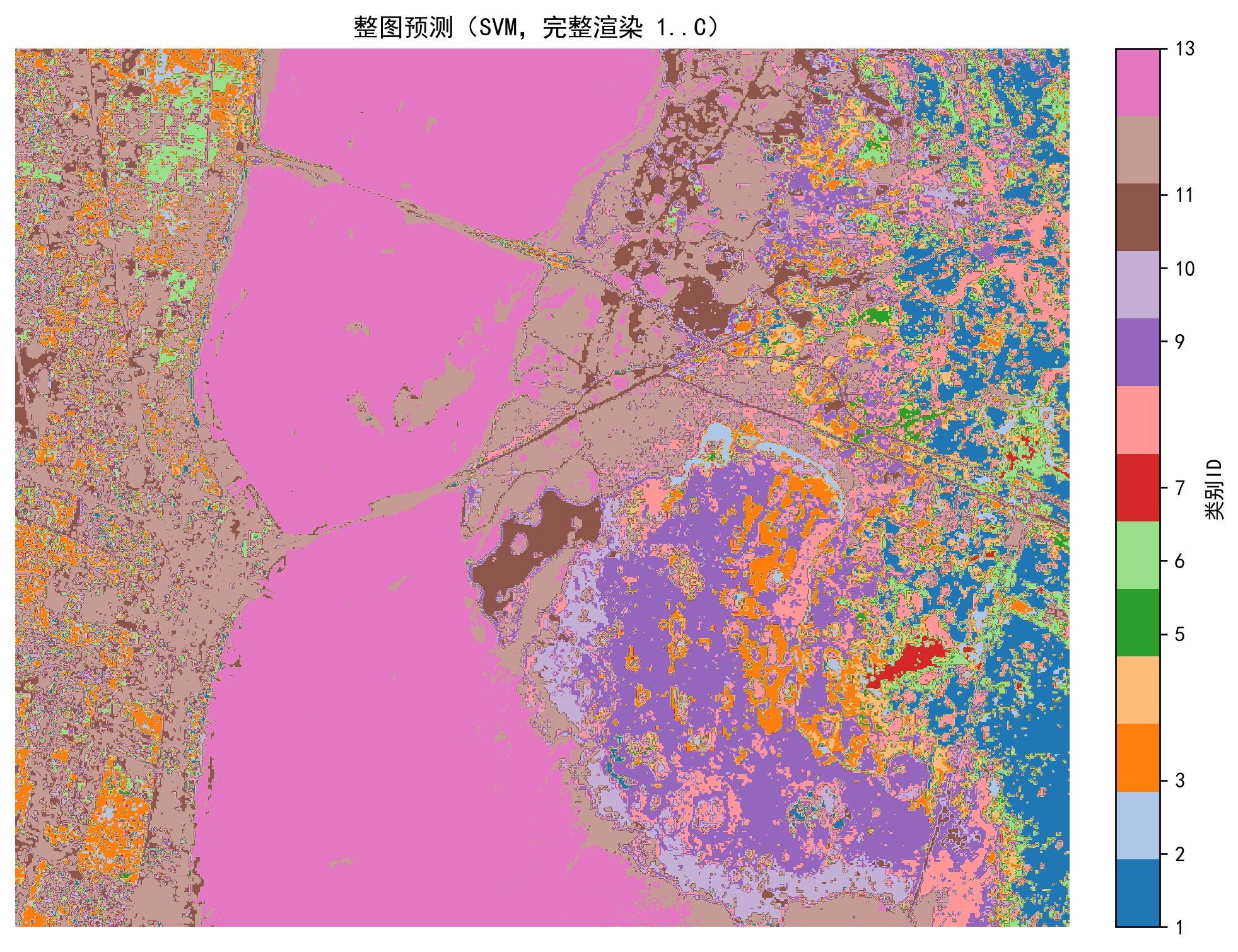
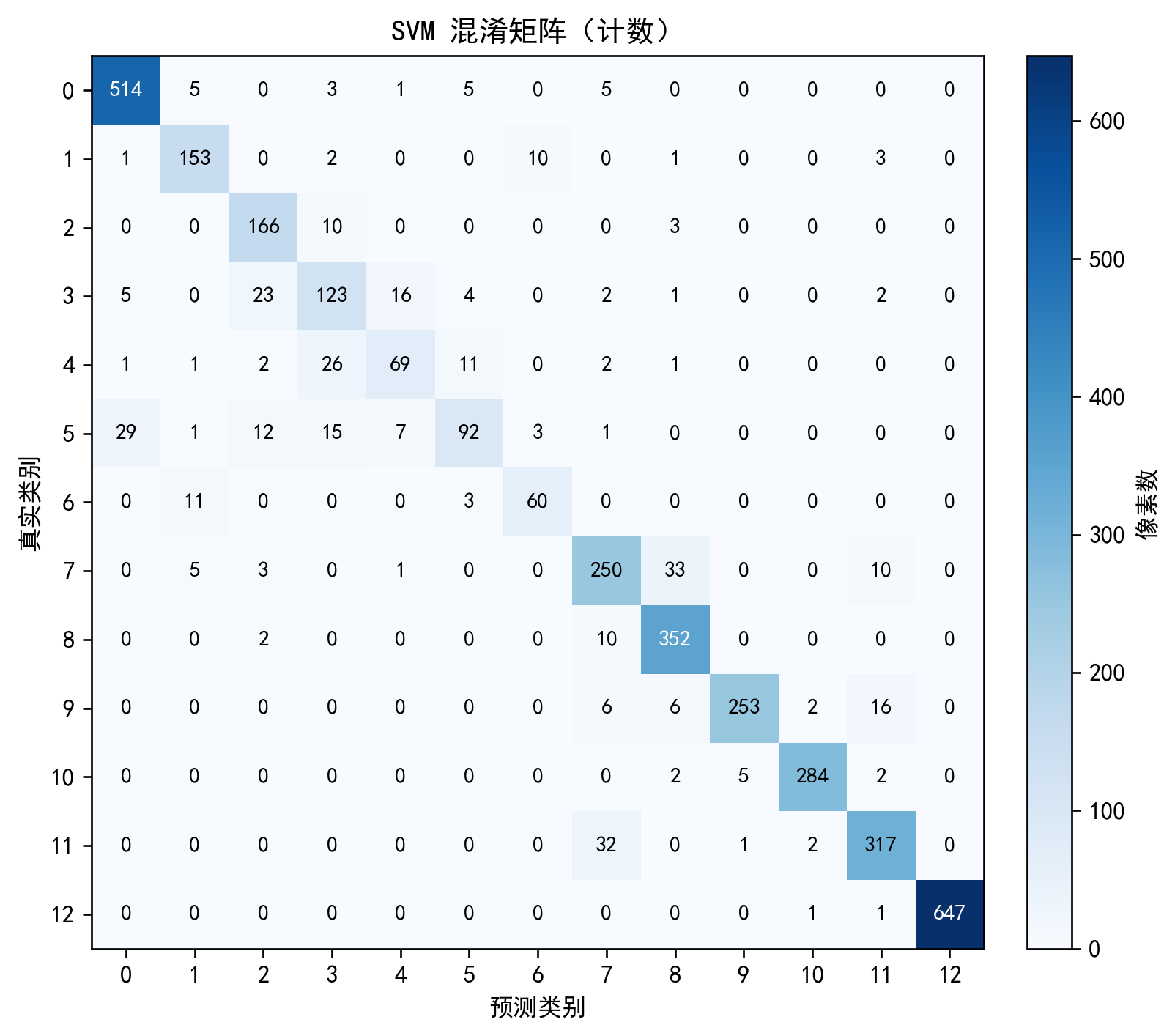
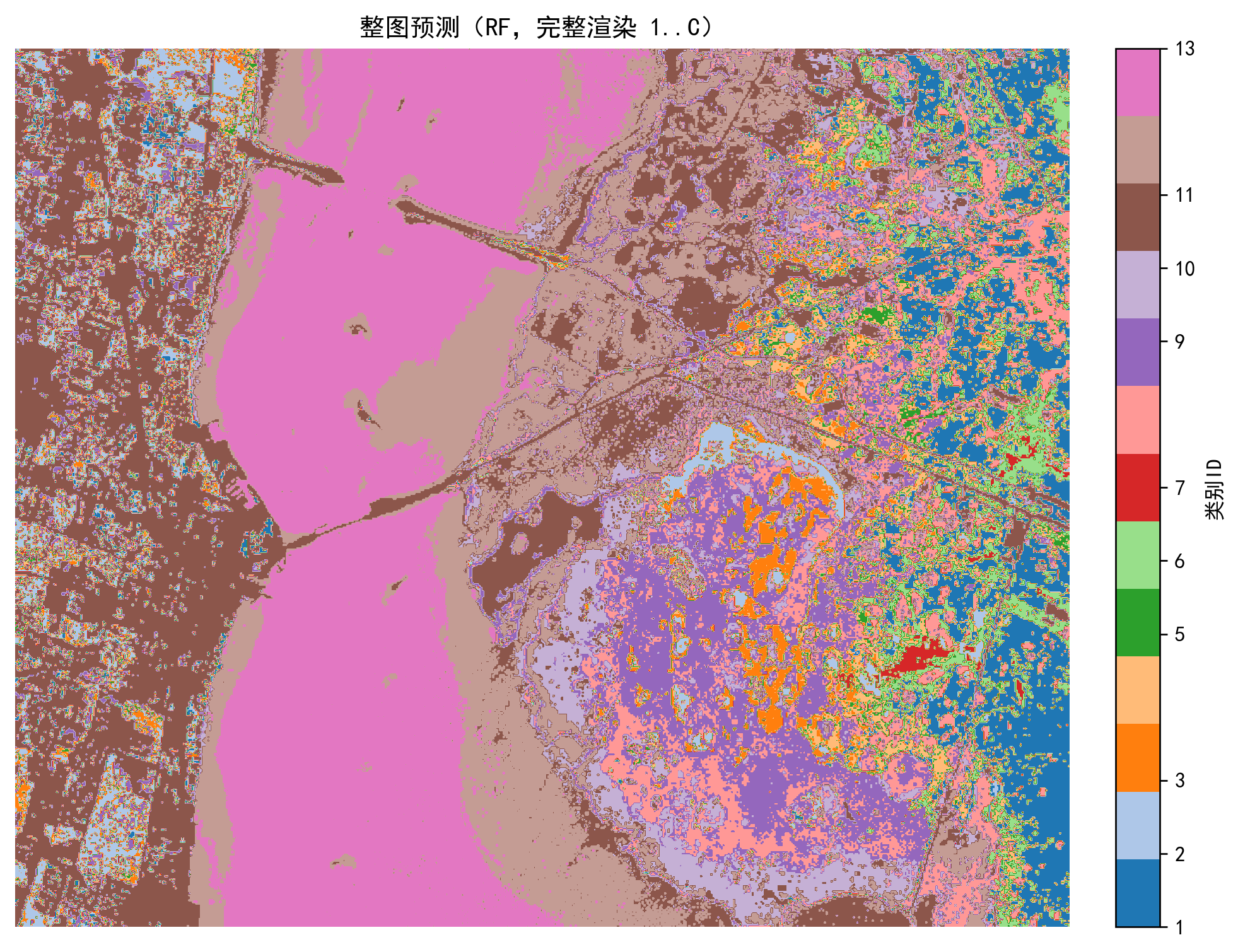
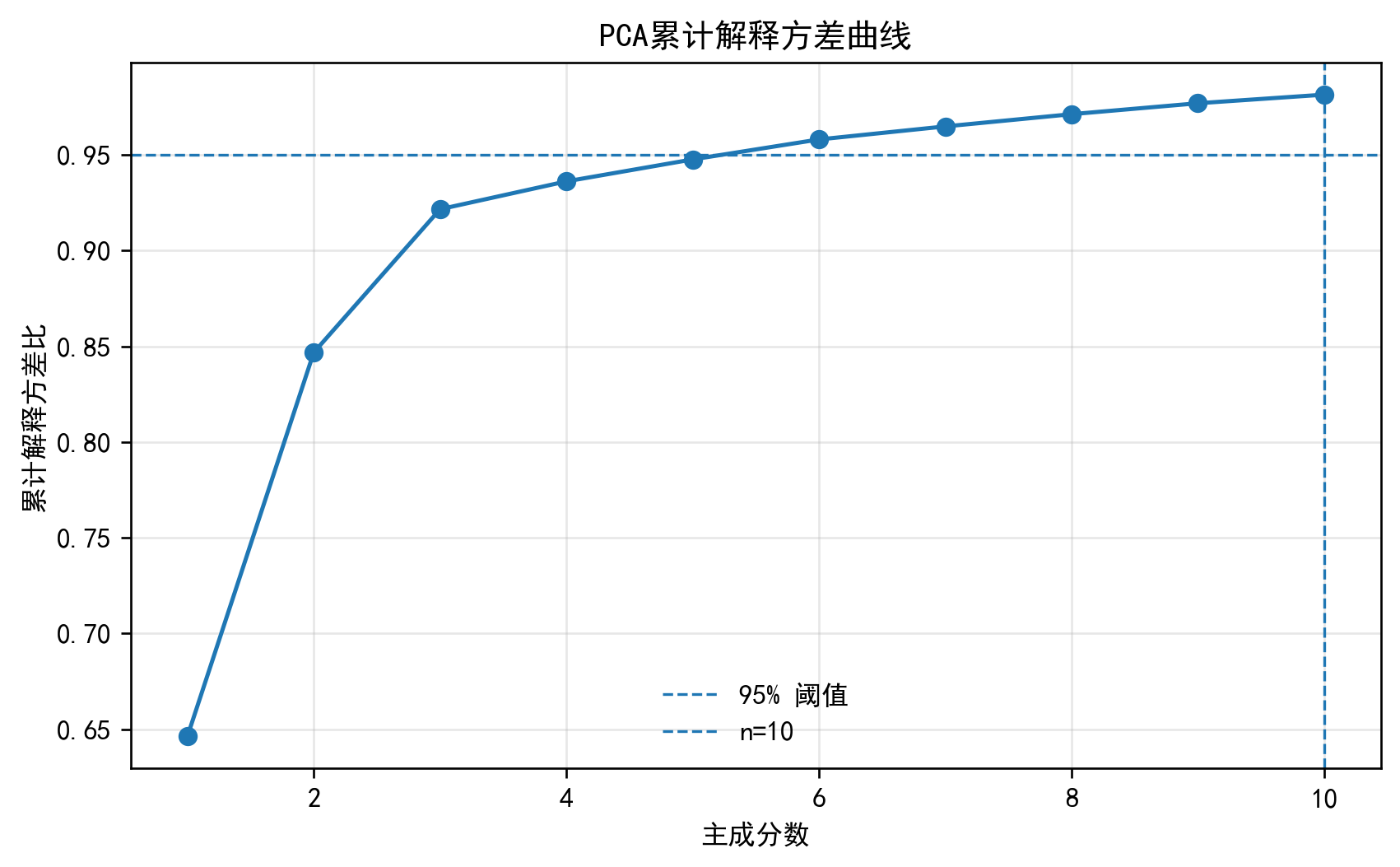
完整代码:通过网盘分享的文件:Sklearn 案例3.py
链接: https://pan.baidu.com/s/1a4rD0fvjqXBwlz3K9hELkg 提取码: 123z
--来自百度网盘超级会员v6的分享
🔗 下一篇预告
第④篇将引入 1D-CNN 深度学习基线,比较传统机器学习与深度模型在小样本高光谱分类中的差异。
欢迎大家关注下方我的公众获取更多内容!