粗排
在推荐系统链路中,排序阶段至关重要,通常分为召回、粗排和精排三个环节。粗排作为精排前的预处理阶段,需要在效果和性能之间取得平衡。

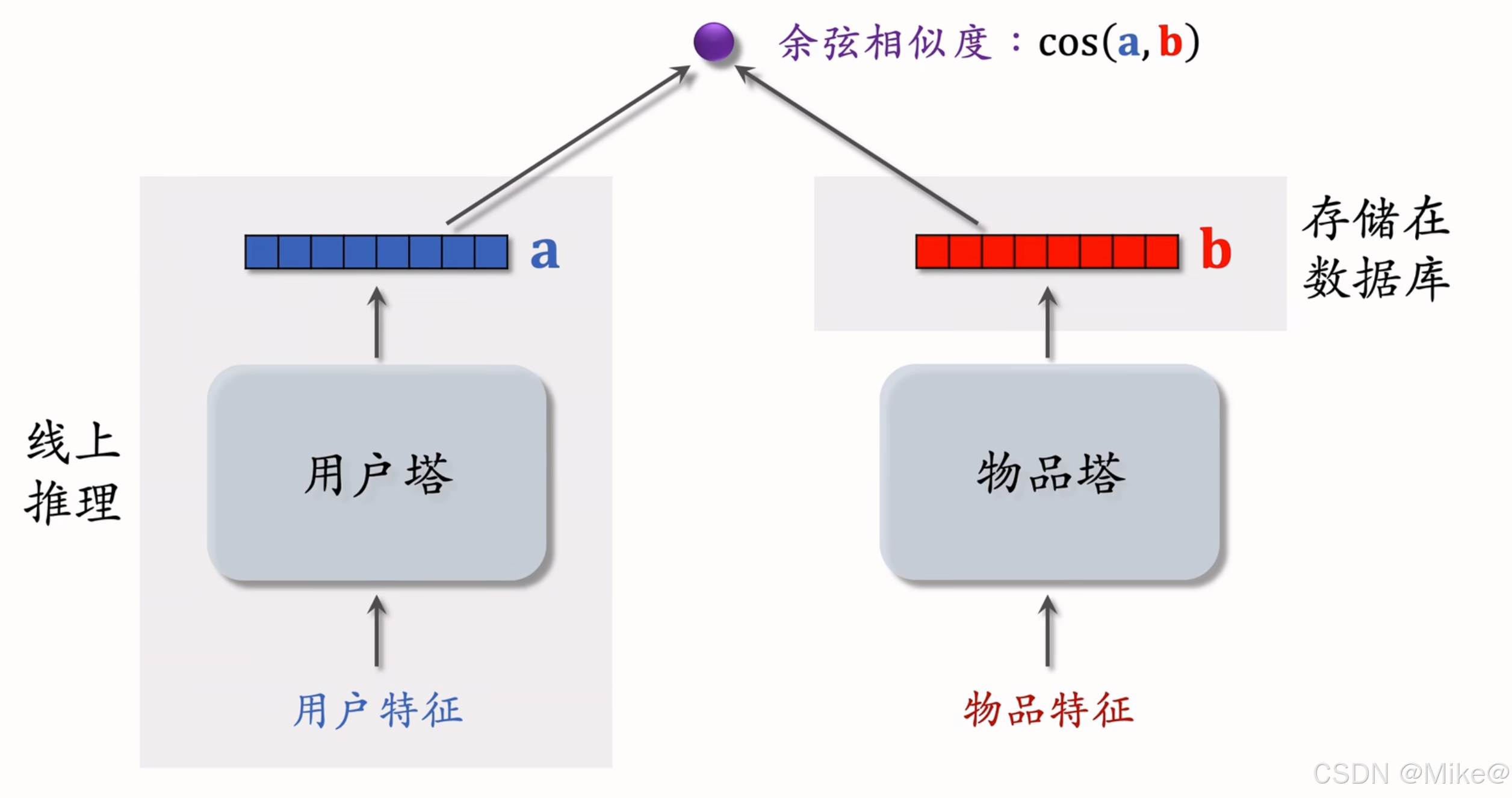
双塔模型
- 后期融合:把用户、物品特征分别输入不同的神经网络,不对用户、物品特征做融合
- 线上计算量小:
- 用户塔只需要做一次线上推理,计算用户表征a
- 物品表征b事先储存在向量数据库中,物品塔在线上不做推理。
- 预估准确性不如精排模型。
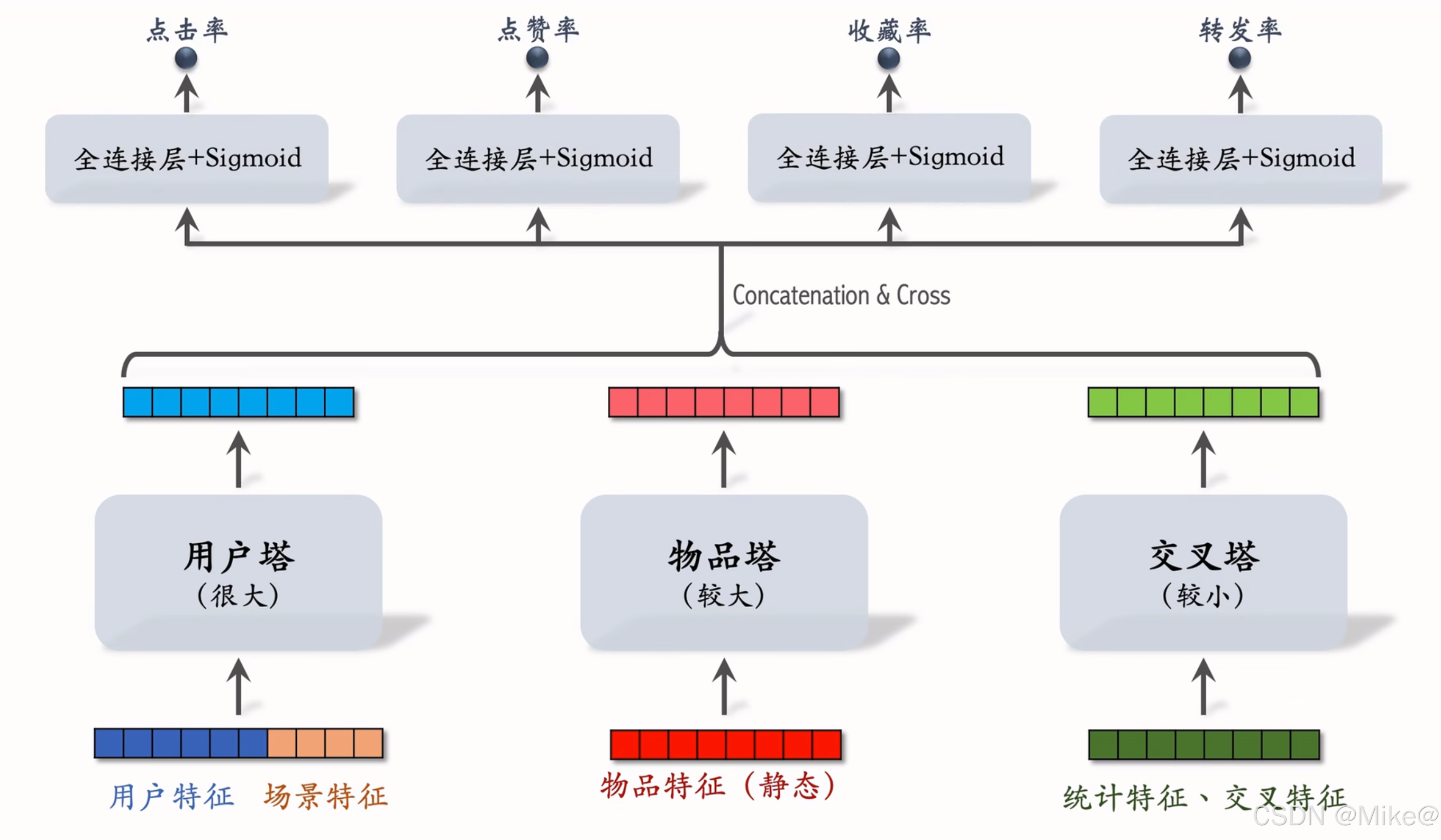
三塔模型
阿里巴巴2020年论文《COLD: Towards the Next Generation of Pre-Ranking System》(Zhe Wang et al., DIP.KDD 2020)的核心思想
-
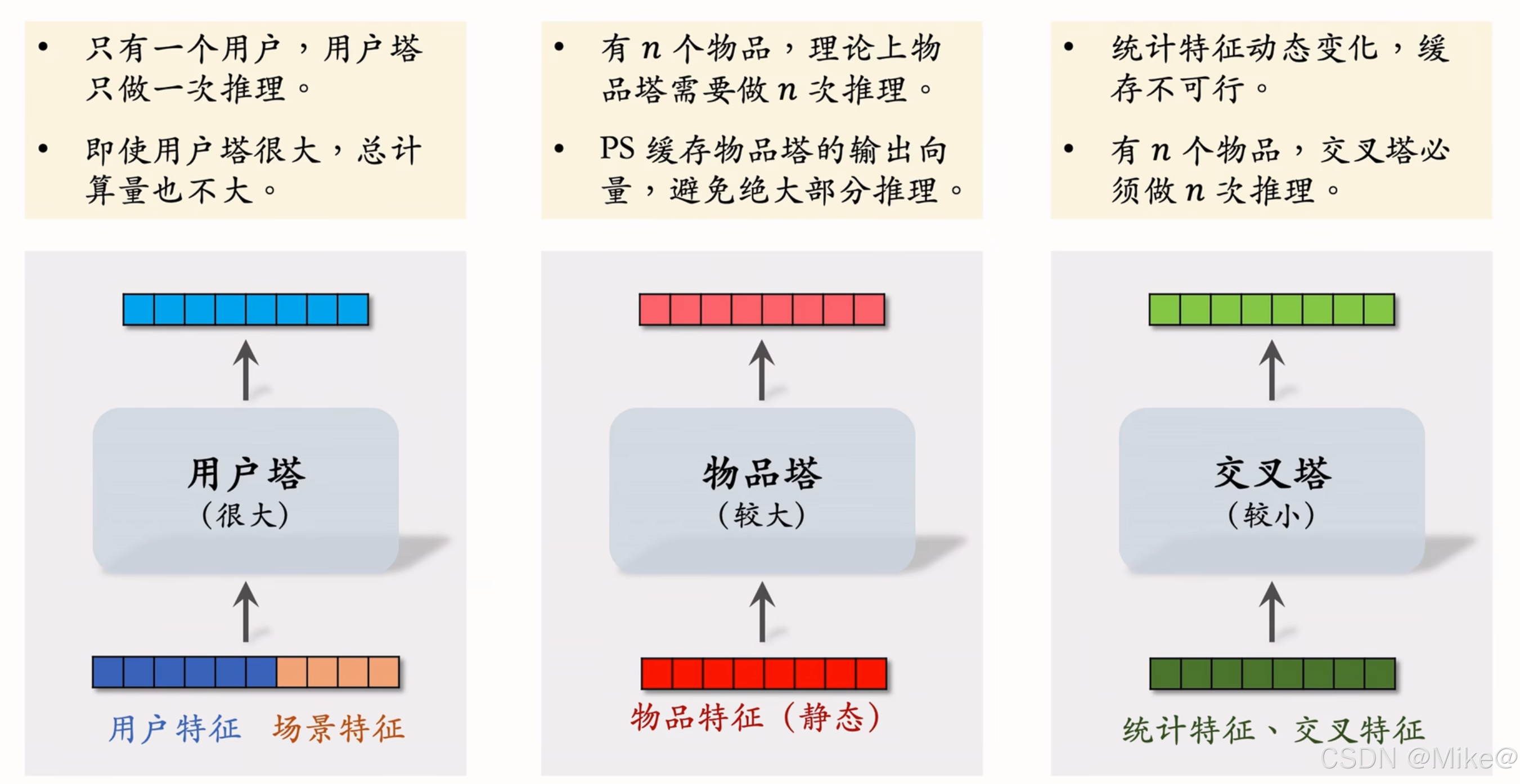
用户塔(很大)
- 用户特征和场景特征
- 每次只有一个用户,用户塔只作一次推理,即使用户塔很大,总计算量也不大
-
物品塔(较大)
- 物品特征(静态)
- 有n个物品,理论上物品塔需要做n次推理,PS缓存物品塔的输出向量,避免绝大部分推理,
- 由于用到缓存,物品塔只需要在遇到新物品的时候才需要计算,粗排给几千个物品打分,粗排只需要给几十个进行推理,物品塔规模可以比较大
-
交叉塔(较小)
- 统计特征,交叉特征(用户特征与物品特征做交叉)
- 统计特征动态变化,比如用户的点击率,物品的被点击量,缓存不可行。
- 有n个物品,交叉塔必须做n次推理,线上推理避免不掉,所以交叉塔必须足够小,计算够快,通常只有几层,宽度也比较小。,
- 粗排上层介绍
- 有n个物品,模型上层需要做n次推理。
- 粗排推理的大部分计算都在模型上层
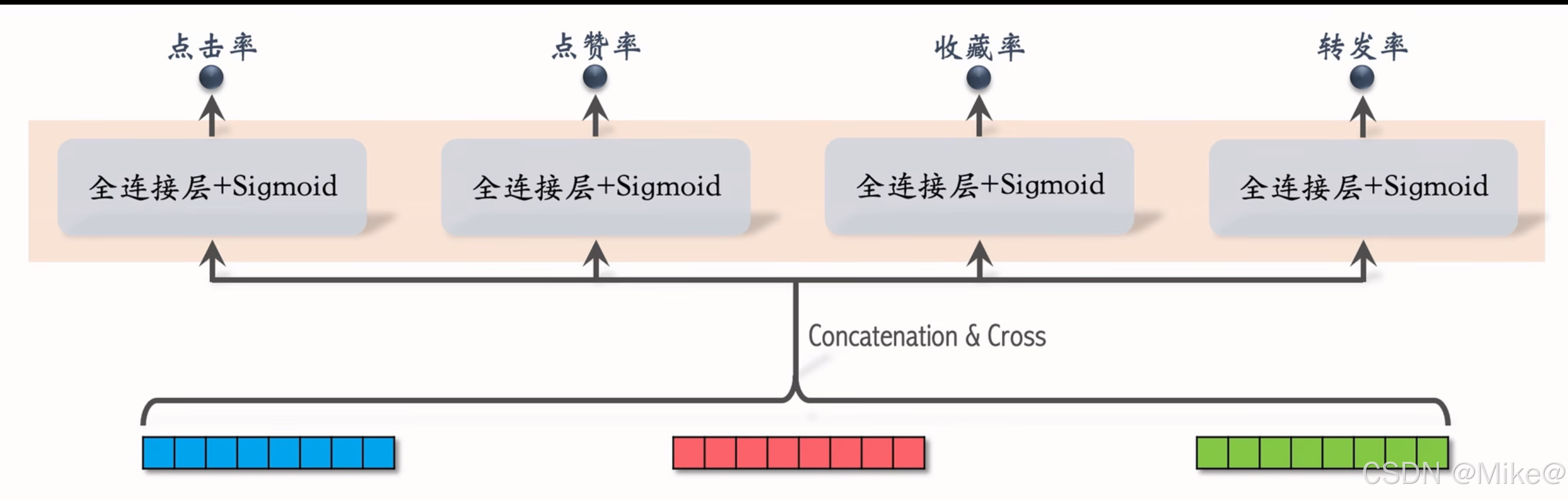
三塔模型的推理
- 从多个数据源提取特征:
- 1个用户的画像、统计特征
- n个物品的画像、统计特征
- 用户塔:只做1次推理
- 物品塔:实现缓存,未命中时需要做推理。实际上缓存命中率非常高
- 交叉塔:必须做n次推理(统计特征都是动态特征)
- 上层网络必须做n次推理,给n个物品打分。
精排模型的特征体系
用户画像
- 用户ID:
- 人口统计属性:年龄、性别等基本信息
- 用户账号信息:新老、活跃度等等(模型需要对新用户、低活用户做优化)
- 感兴趣的类目、关键词、品牌(可以用是用户填写,也可以是算法自动提取,用户兴趣的信息对于排序是非常有帮助的)
物品画像
现在业界的推荐系统都会使用用户画像和物品画像
- 物品ID(在召回、排序做Embedding)
- 发布时间(或年龄),发布时间越久,价值越低
- GeoHash(经纬编码)、所在城市
- 标题、类目、关键词、品牌,通常做法是做Embedding
- 字数、图片数、视频清晰度、标签数
- 内容信息量、图片美学(算法打分),事先使用人工标注的数据集训练cv和nlp模型,利用这些模型把内容信息量、图片美学这些分数写入物品画像中
用户统计特征
- 用户30天(7天、1天、1小时)的曝光数、点击数、点赞数、收藏数等,各种时间粒度反应用户的兴趣,长期、中长期和短期。
- 按照笔记图文/视频分桶(比如最近7天,该用户对图片的点击率、对视频笔记的点击率)
- 按照笔记类目分桶。(比如30天。用户对美妆笔记的点击率、对美食笔记的点击率、对数码科技笔记的点击率)。可以反应用户对哪些类目更感兴趣,如果一个用户对美食笔记的点击量和点击率等指标都偏高。说明这个用户对美食类目感兴趣
笔记统计特征
- 笔记 30天(7天、1天、1小时)的曝光数、点赞数、收藏数等指标,反应笔记的受欢迎程度,使用不同的粒度也是有道理的,某些笔记30天的点击率都很高,但是最近一天指标变得很差,说明这些笔记已经过时了,不应该给过多流量
- 按用户性别分桶、按照用户年龄、地域分桶
- 作者的统计特征
- 发布的笔记数量
- 粉丝数
- 消费指标(曝光数、点击数、点赞数、收藏数)(反应作者受欢迎程度和平均笔记质量)
场景特征
- 用户定位GeoHash(经纬度编码)、城市(对召回和排序都有用,用户可能对自己周围发生的事情比较感兴趣)
- 当前时刻(分段做Embedding),一个人在一天不同时刻的兴趣可能有所区别,在上班路上和晚上睡觉
- 是否周某,是否节假日
- 设备信息:手机品牌、手机型号、操作系统
特征处理
-
离散特征做Embedding
-
用户ID、笔记ID、作者ID。(几千万、几亿级别)
-
类目、关键词、城市、手机品牌 (笔记的类目也就几百个,关键词就几百万个,给他们做embedding比较容易,消耗内存也不多)
-
-
连续特征:分桶变成离散特征
- 年龄(10个年龄段、one-hot)或者Embedding,笔记长度、视频长度
-
连续特征:其他变换
- 曝光数、点击数、点赞数等数值做 log ( 1 + x ) \log (1+x) log(1+x)
- 转化为点击率、点赞率等指标,并做平滑处理
特征覆盖率
- 很多特征无法覆盖100%样本 ,存在缺失
- 很多用户注册的时候不填写年龄,因此用户年龄特征的覆盖率远小于100%
- 例:很多用户设置隐私权限,APP 不能获得用户地理定位,因此场景特征有缺失。
- 做特征工程需要提高特征覆盖率,让排序模型更准,需要考虑当特征缺失的时候要用什么作为默认值
数据服务
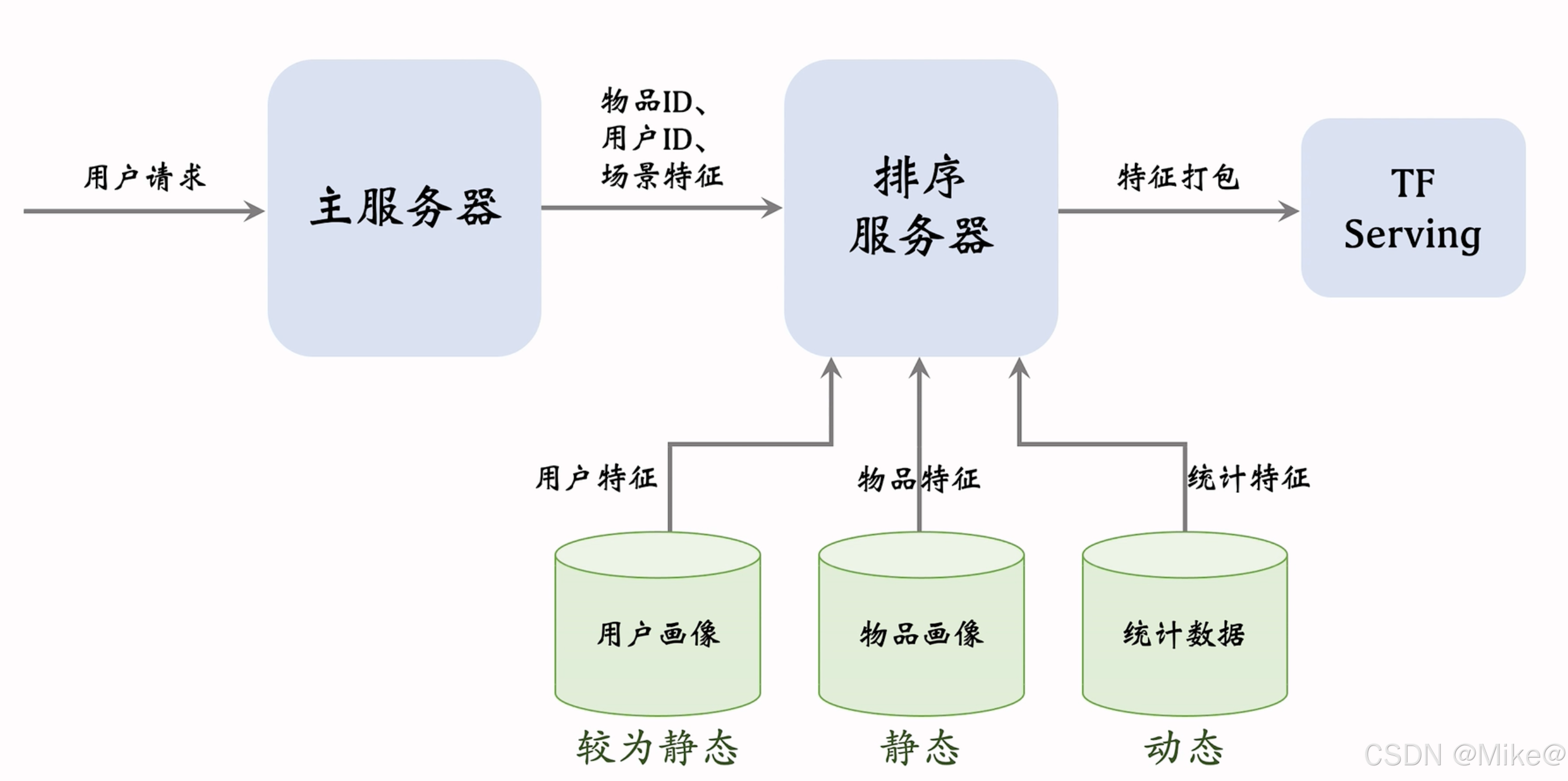
排序服务器会从是三个数据源取回所需要的数据
- 用户画像(User Profile)
- 物品画像(Item profile)
- 统计数据
用户发送请求给主服务器,主服务器发生召回请求给召回服务器,召回服务器把几千个召回结果发回主服务器,主服务器把物品ID、用户ID、场景特征(用户地点、当前时刻、是否节假日、手机型号,操作系统)发往排序服务器。排序服务器从三个源中获取 用户画像、物品画像、统计数据。排序服务器把特征打包传递给TF serving tensorflow会给笔记打分,把分数返回给排序服务器,排序服务会用排序融合分数,业务规则给笔记做排序。把排名最高的几十篇笔记返回给主服务器
- 用户画像压力比较小,每次只提取一个用户
- 物品画像压力比较大,粗排要给几千笔记做排序,读取几千笔记的特征
- 存用户统计的压力小,存物品统计的压力很大
- 在工程实现里,用户画像可以存的很长很大,但是尽量不要在物品画像存很大向量,否则物品画像会承受很大的压力
- 用户画像较为静态,只需要天刷新就好,物品画像则是静态,算法给物品内容打分基本不变,这两类读取需要快,有时候可以把物品画像和用户画像缓存在排序服务器本地
- 但是不能把统计数据缓存,统计数据是动态变化的,实效性很强 ,用户刷了5篇笔记,用户点击,点赞等统计量都发生了变化,要尽快刷新数据库