深度定制 LLM 知识,除了 RAC ,现在又有新技术
假设有一份200页的产品手册,你想让 LLM 准确回答里面的相关问题,要实现这个目标,除了常用的检索增强生成技术 rep ,现在有了新思路,缓存增强生成 CAG ,它是什么,何时使用.

RAG检索增强是常规套路,CAG缓存增强是后起之秀让我们来对比一下他们的优缺点. 我们先来了解一下,检索增强生成 RAG 的工作流程
RAG检索增强流程
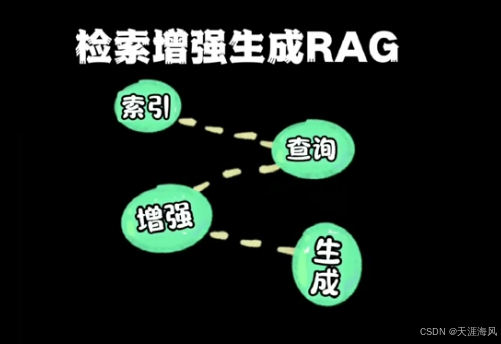
第一步 索引阶段 这个步骤在提前处理的情况下 也允许动态加入
就像煮饭备料一样
- RAG 会将文档切成小块
- 再转换成向量
- 存入向量数据库
第二步 查询阶段
用户提问后
- 系统将问题转为向量
- 在向量数据库中检索相似内容
第三步 增强阶段
- 将检索到的相关内容添加到提示词中
第四步 生成阶段
- LLM 基于增强后的提示词生成回答
RAG工作流程缺点
了解过 RAG的工作流程,它的局限性大家可能也都猜到了
- 检索存在延迟
- 检索的质量和内容影响回答准确性
- 架构复杂,需要费心维护向量数据库
CAG检索增强流程
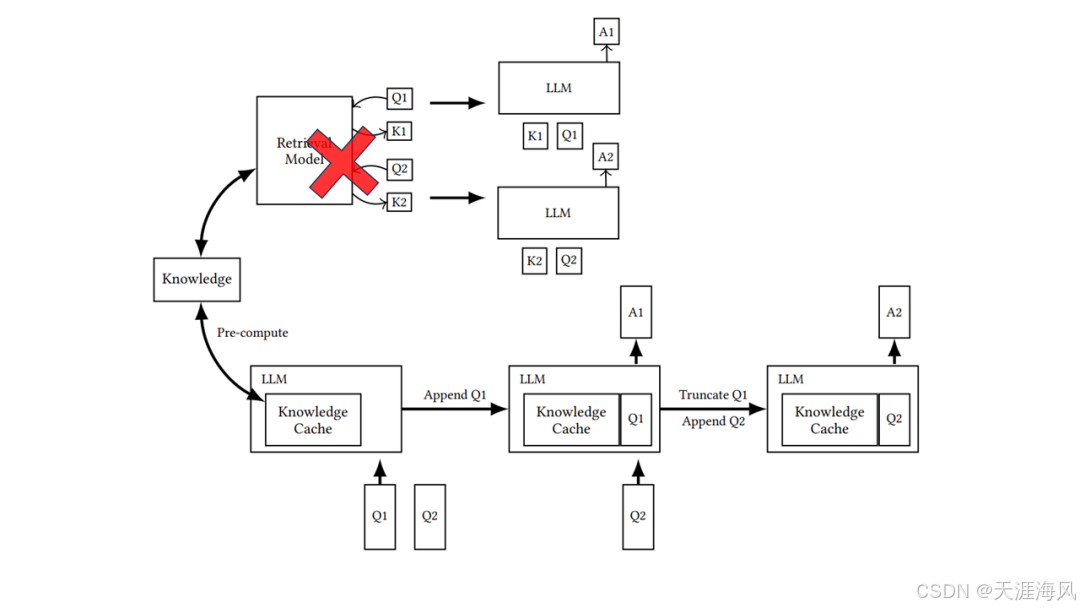
在 RAG 基础上,CAG 提供了另一种解题思路, 它比 RAG 工作流程更短 主要包括两个阶段
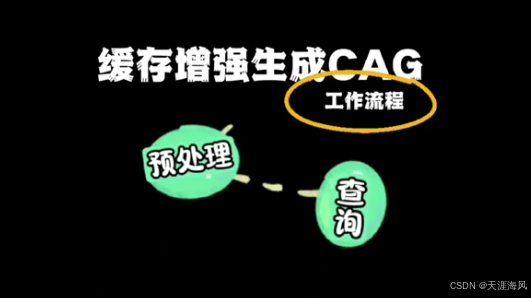
第一阶段 预处理流程
- 对知识源进行处理,提取关键信息
- 接着将信息结构化
- 利用 LLM 将文档转化为键值对缓存
以一本书为例, 就是把它的关键内容, 组成对应关系进行缓存. 像
章节标题对应章节摘要、人物名称对应人物描述、核心概对应概念解释、常见问题对应答案
第二阶段 查询流程
- 初始阶段,所有键值对都加载到缓存当中
- 把缓存加载到 LLM 的上下文窗口中
- 与用户提问一起发送给 LLM
- LLM 直接从上下文的知识缓存中检索, 并生成回答
CAG检索增强流优势
省略了检索步骤使 CAG 拥有了明显的优势,
- 无检索延迟,响应自然更快,
- LLM 直接加载所有缓存知识回答一致性更高,
- 无检索系统架构更简单,降低了维护的复杂性
最后我们来总结 一 RAG 和 CAG 到底何时用
何时使用 RAG的场景
- 有规模庞大的知识库, 如超出 LLM 上下文窗口容量的,
- 更新频繁的资料
- 面向开放领域的多样化问题
- 需要精准引用原文出处的
何时使用 CAG 的场景
- 知识领域固定且规模适中的: 如书籍
- 看重响应速度 用 CAG 能快几秒
- 需要全局理解和一致性: 如财务报表分析,
- 可以被有效提炼和结构化的知识
总结
RAG 和 CAG ,它们代表了两种不同的知识增强范式一个动态检索、一个预加载缓存
选择哪种技术取决于你的 具体需求,知识规模和性能要求

文章: