💖💖作者:计算机编程小咖
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💜💜
网站实战项目
安卓/小程序实战项目
大数据实战项目
深度学习实战项目
目录
全球用水量数据可视化分析系统介绍
《基于大数据的全球用水量数据可视化分析系统》是一个专注于全球用水数据深度分析与可视化展示的高效系统。该系统采用先进的大数据处理框架 Hadoop 和 Spark,能够快速处理海量的全球用水数据,确保数据处理的高效性和准确性。系统支持 Python 和 Java 两种开发语言,分别提供 Django 和 Spring Boot 两种后端框架版本,以满足不同开发者的技术偏好和项目需求。前端采用 Vue、ElementUI、Echarts 等技术,结合 HTML、CSS 和 JavaScript,打造了交互性强、视觉效果出色的用户界面。
系统功能丰富,涵盖系统首页、用户信息管理、全球用水量数据管理、大屏可视化展示、多维关联聚类分析、多国用水横向对比、重点国家深度分析、全球用水时序分析以及稀缺状况归因分析等多个模块。通过 HDFS 分布式文件系统存储数据,利用 Spark SQL 进行高效的数据查询和分析,结合 Pandas 和 NumPy 等数据处理工具,系统能够精准地挖掘全球用水数据中的关键信息,为用户提供全面、深入的数据分析结果。同时,系统使用 MySQL 数据库进行数据存储和管理,确保数据的安全性和稳定性。无论是计算机专业学生进行毕设开发,还是相关领域的研究人员和从业者,该系统都能提供强大的技术支持和实用的功能体验。
全球用水量数据可视化分析系统演示视频
《基于大数据的全球用水量数据可视化分析系统》用Python+Django开发,为什么导师却推荐用Java+Spring Boot?真相揭秘......
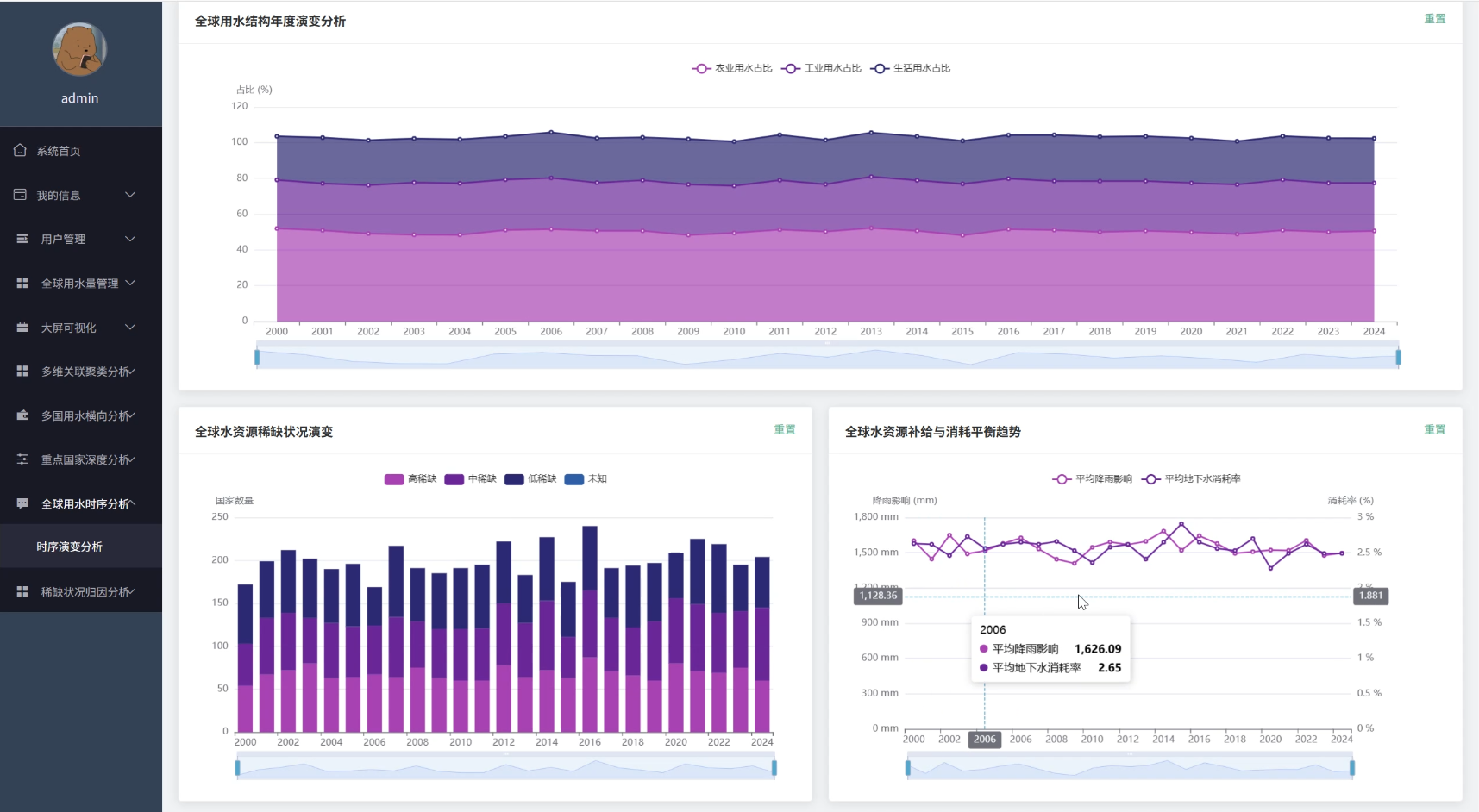
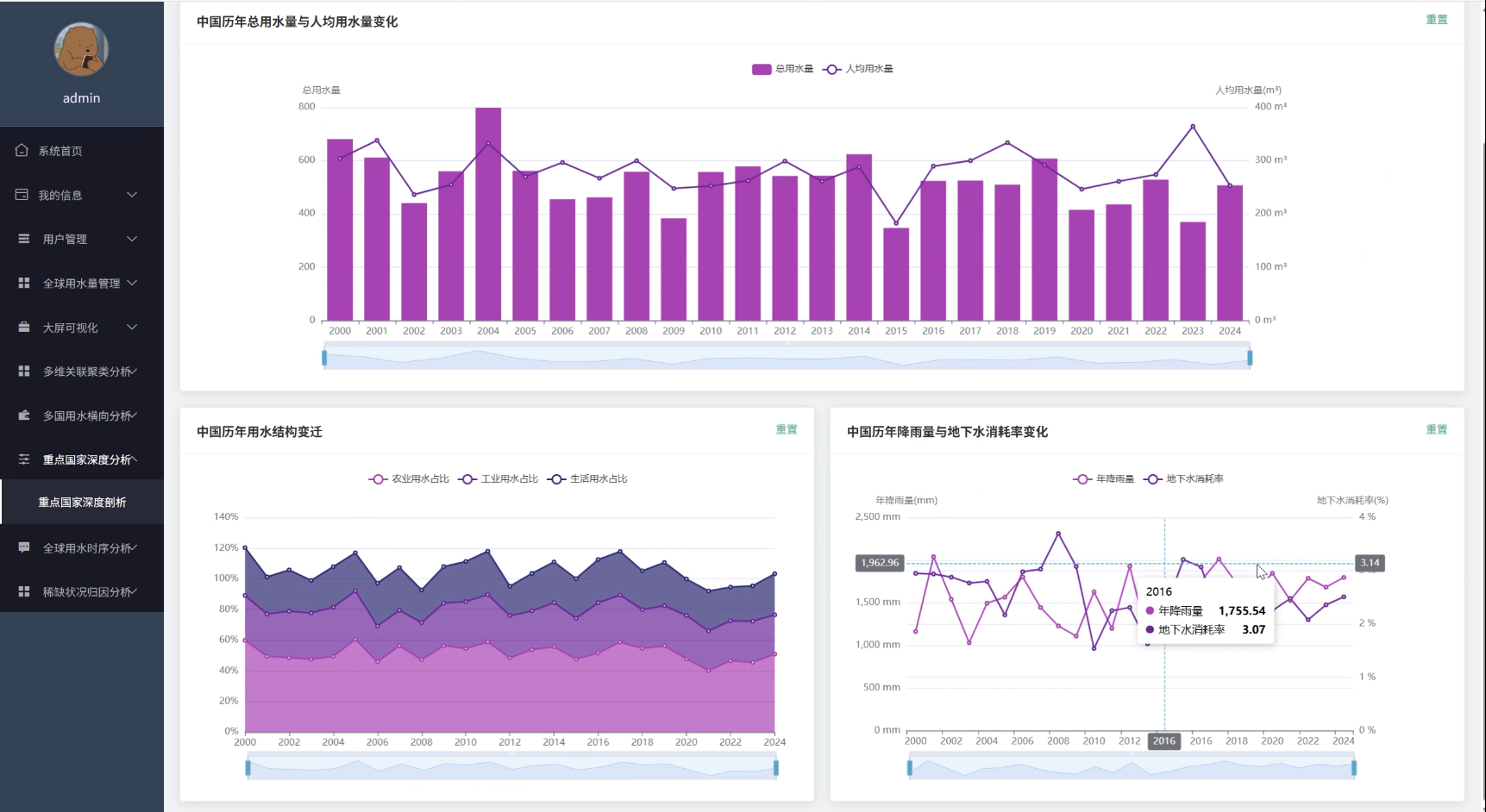
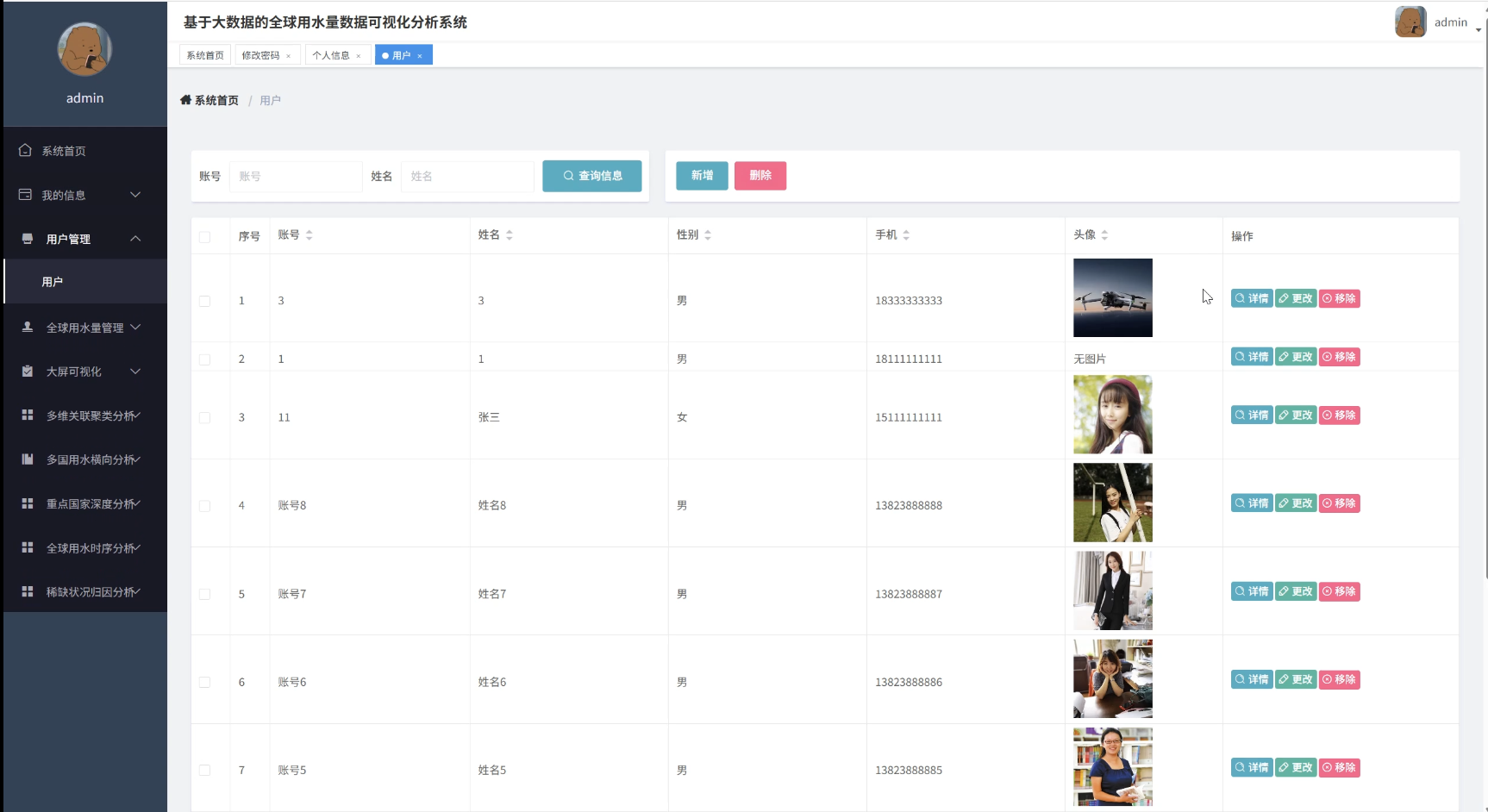
全球用水量数据可视化分析系统演示图片
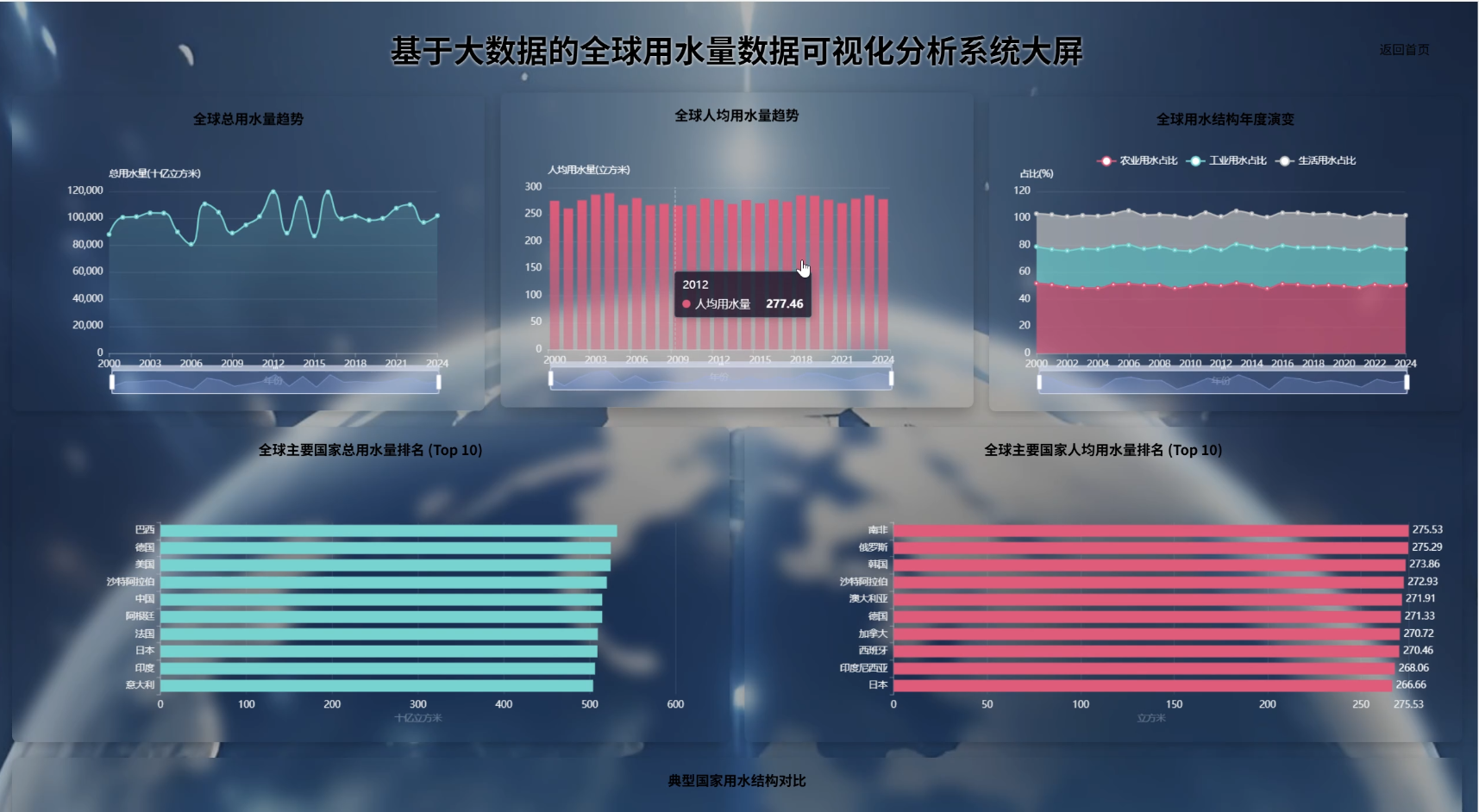
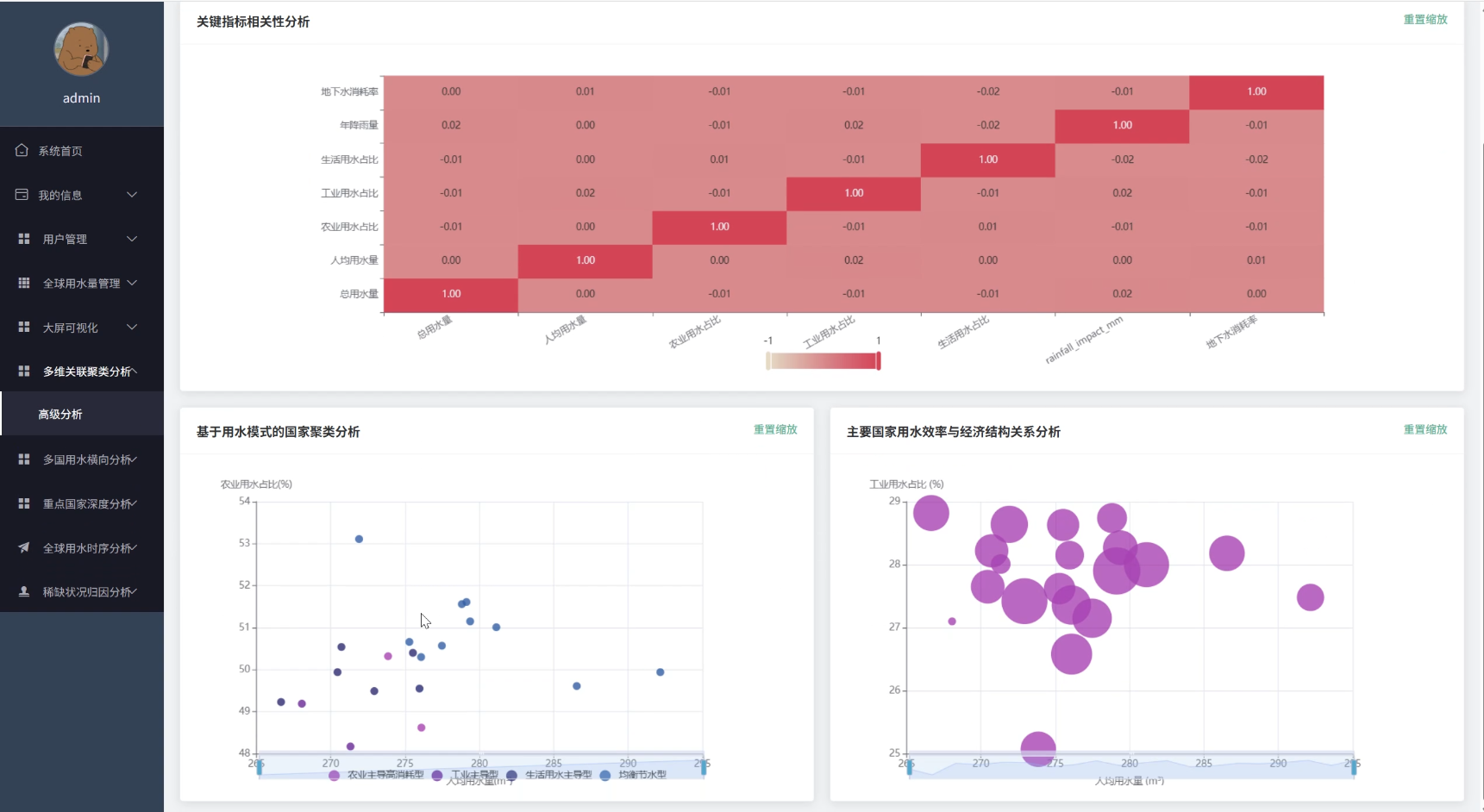
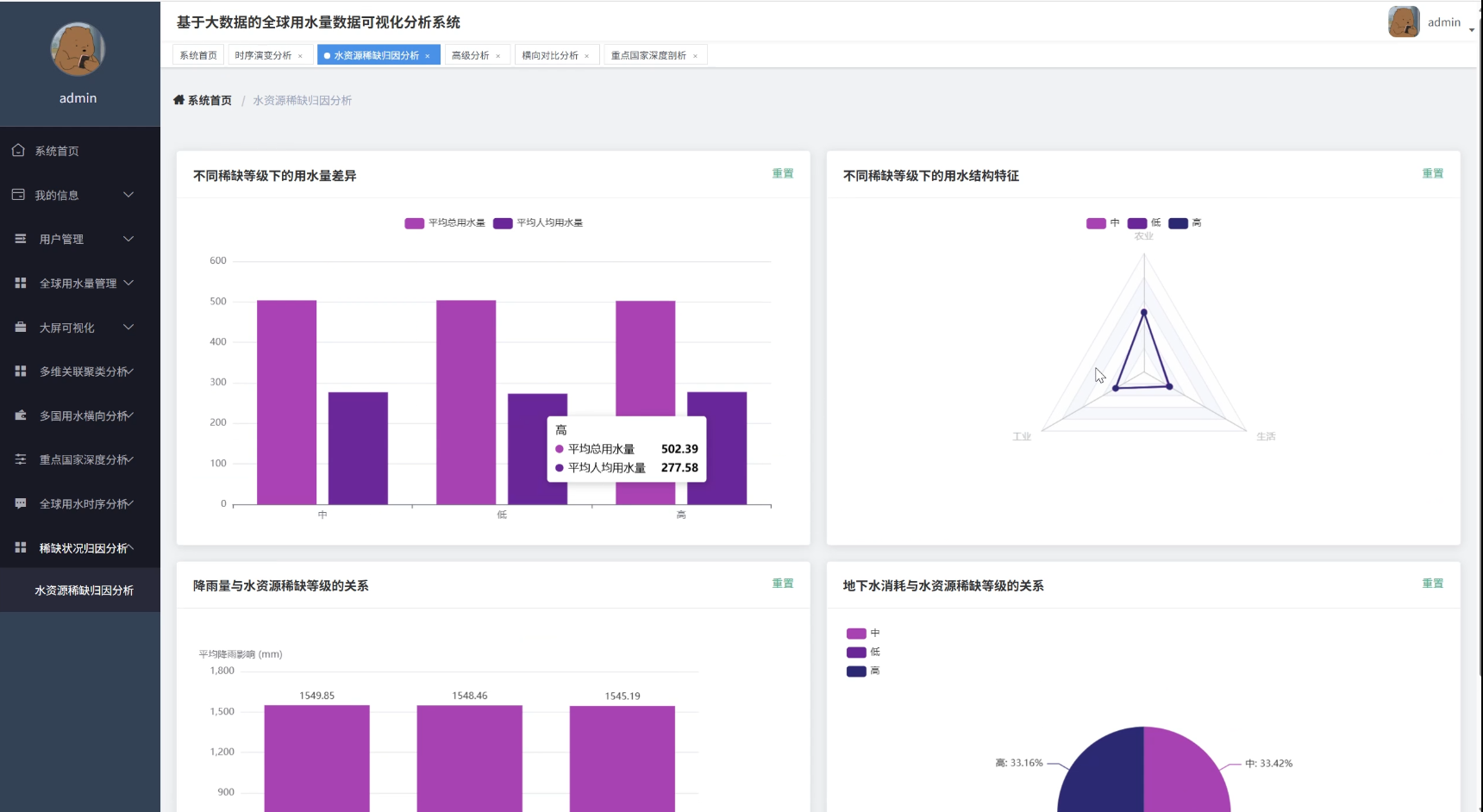
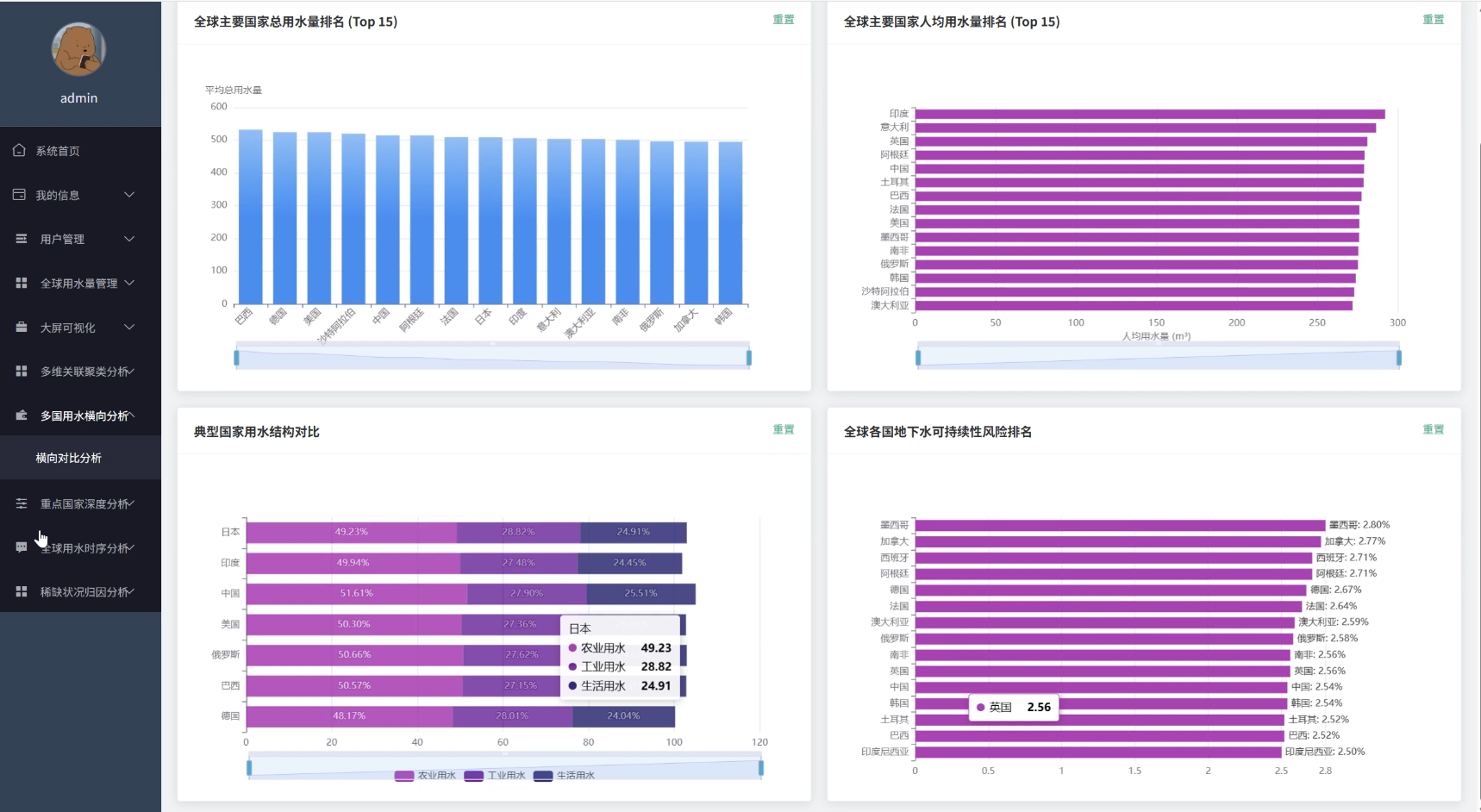
全球用水量数据可视化分析系统代码展示
csharp
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, sum, year, month
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
import pandas as pd
# 初始化SparkSession
spark = SparkSession.builder \
.appName("GlobalWaterUsageSystem") \
.getOrCreate()
# 全球用水量管理:计算全球用水总量
def global_water_usage_management():
# 加载用水数据
water_data = spark.read.csv("hdfs://path/to/global_water_usage.csv", header=True, inferSchema=True)
# 计算全球用水总量
total_usage = water_data.agg(sum("water_usage")).collect()[0][0]
# 按国家统计用水量
country_usage = water_data.groupBy("country").agg(sum("water_usage").alias("total_usage"))
# 将结果存储到MySQL数据库
country_usage.write \
.format("jdbc") \
.option("url", "jdbc:mysql://localhost:3306/waterdb") \
.option("dbtable", "country_usage") \
.option("user", "root") \
.option("password", "password") \
.mode("overwrite") \
.save()
return total_usage
# 多维关联聚类分析:对不同国家的用水模式进行聚类
def multidimensional_clustering_analysis():
# 加载用水数据
water_data = spark.read.csv("hdfs://path/to/global_water_usage.csv", header=True, inferSchema=True)
# 选择聚类特征
assembler = VectorAssembler(inputCols=["water_usage", "population", "gdp"], outputCol="features")
water_data = assembler.transform(water_data)
# 使用KMeans聚类
kmeans = KMeans(k=5, seed=1)
model = kmeans.fit(water_data)
predictions = model.transform(water_data)
# 将聚类结果存储到MySQL数据库
predictions.write \
.format("jdbc") \
.option("url", "jdbc:mysql://localhost:3306/waterdb") \
.option("dbtable", "clustering_results") \
.option("user", "root") \
.option("password", "password") \
.mode("overwrite") \
.save()
return predictions
# 全球用水时序分析:分析全球用水量的年度变化趋势
def global_water_usage_timeseries_analysis():
# 加载用水数据
water_data = spark.read.csv("hdfs://path/to/global_water_usage.csv", header=True, inferSchema=True)
# 提取年份和用水量
water_data = water_data.withColumn("year", year(col("date")))
yearly_usage = water_data.groupBy("year").agg(sum("water_usage").alias("total_usage"))
# 计算年度用水量的平均值和趋势
yearly_usage = yearly_usage.orderBy("year")
yearly_usage_pd = yearly_usage.toPandas()
# 使用Pandas进行进一步分析
yearly_usage_pd['moving_avg'] = yearly_usage_pd['total_usage'].rolling(window=3).mean()
# 将结果存储到MySQL数据库
spark.createDataFrame(yearly_usage_pd).write \
.format("jdbc") \
.option("url", "jdbc:mysql://localhost:3306/waterdb") \
.option("dbtable", "yearly_usage") \
.option("user", "root") \
.option("password", "password") \
.mode("overwrite") \
.save()
return yearly_usage_pd
# 调用核心功能
total_usage = global_water_usage_management()
predictions = multidimensional_clustering_analysis()
yearly_usage_pd = global_water_usage_timeseries_analysis()
# 打印结果
print("Total Global Water Usage:", total_usage)
print("Clustering Predictions:", predictions.show())
print("Yearly Water Usage Trends:", yearly_usage_pd)全球用水量数据可视化分析系统文档展示

💖💖作者:计算机编程小咖
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💜💜
网站实战项目
安卓/小程序实战项目
大数据实战项目
深度学习实战项目