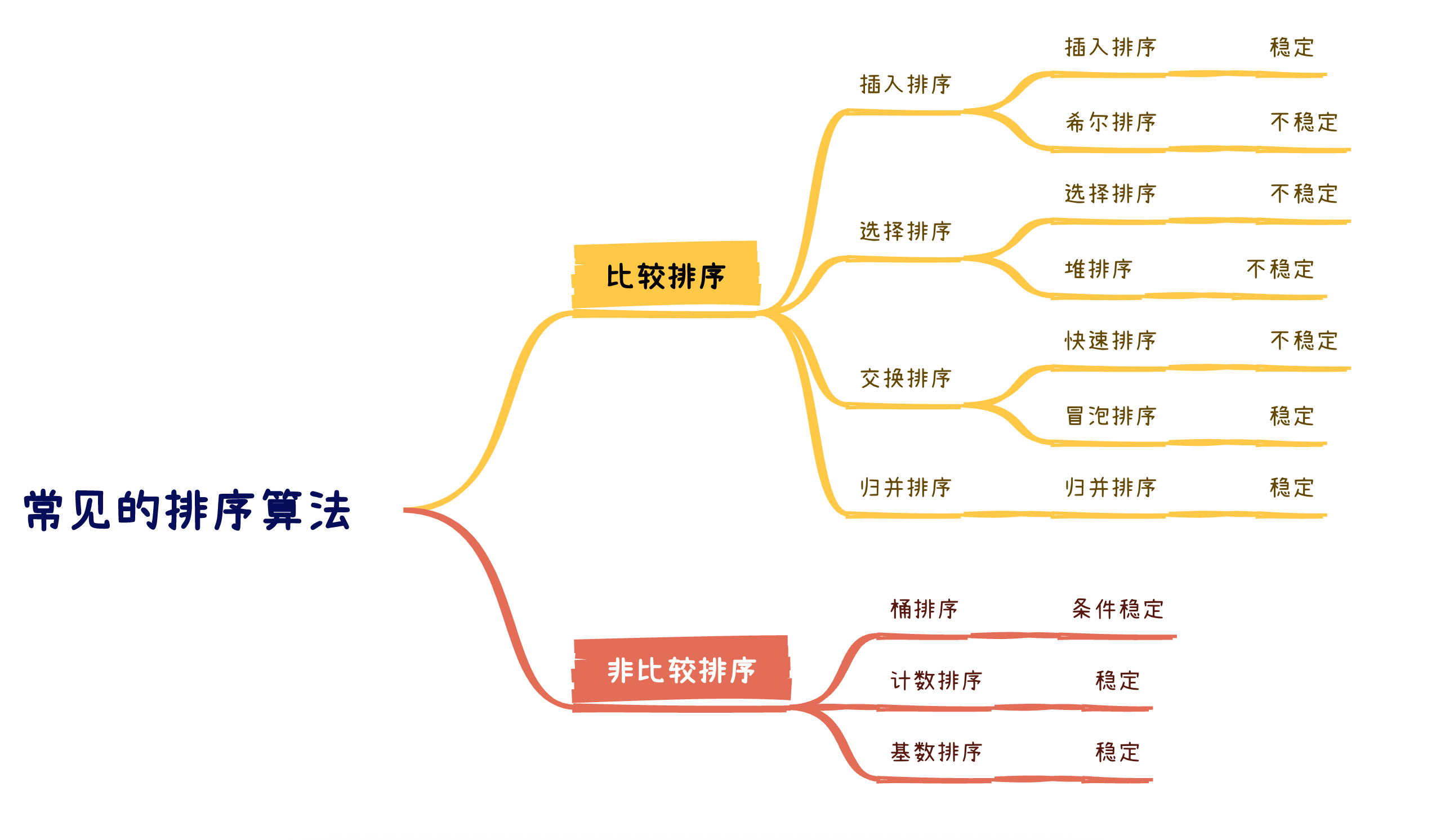
2.0 十大排序算法
2.5 非比较排序
之前学习的排序算法都是比较排序------借助比较大小,来实现排序。
非比较就是不借助比较大小,来实现排序。------小众的、局限的
非比较排序大致有这些:计数排序、桶排序、基数排序。
桶排序、基数排序在实践中意义不大,面试也基本上不会考。
计数排序在实践中有所应用、校招也会有涉及。
2.5.1 计数排序
基本思想
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。
动图演示
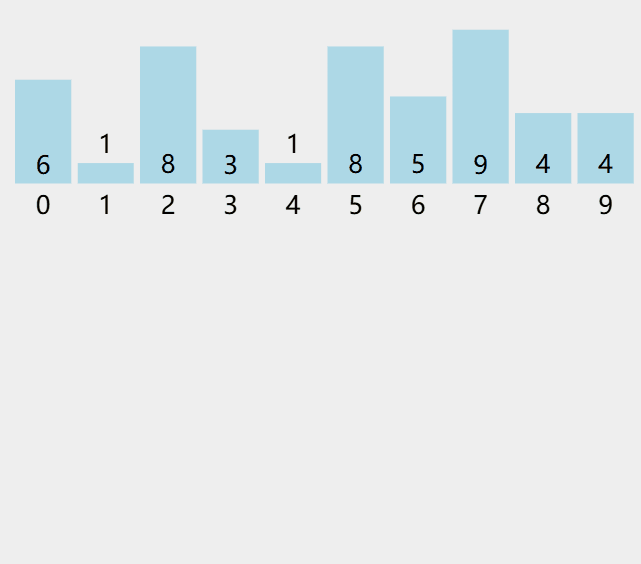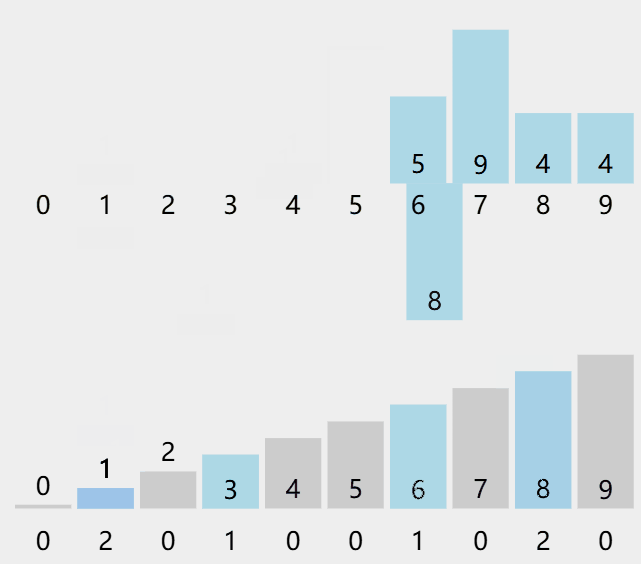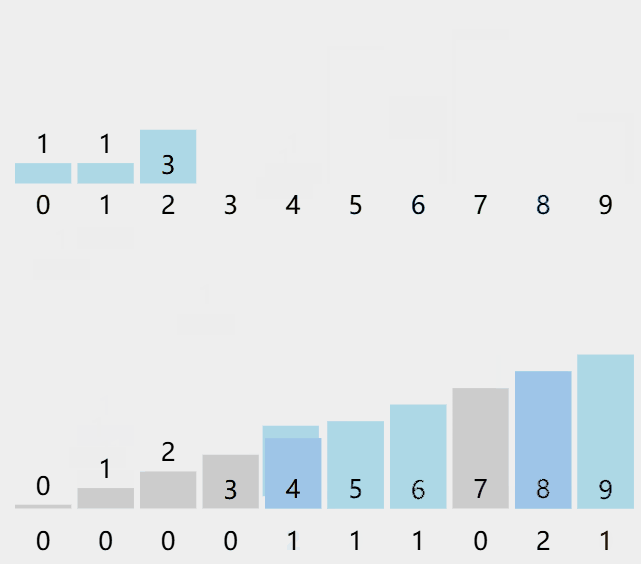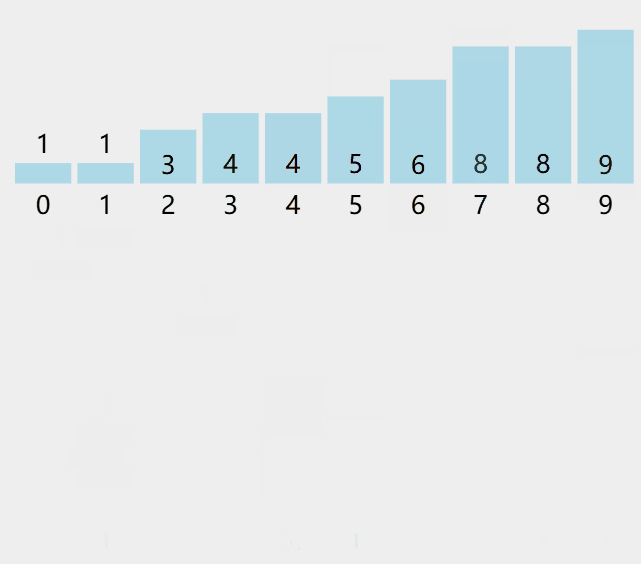
算法步骤
-
统计相同元素出现次数。
-
根据统计的结果将序列回收到原来的序列中。
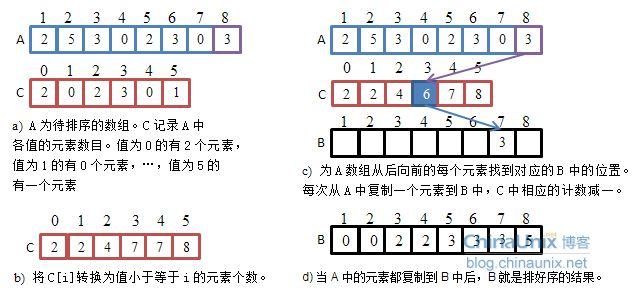
- A:原数组
- C:统计次数的数组
图解演示。

适合:数据上界、下界差值小(<1000) ------数据范围集中的数组。
即不管数据大小, 只看数据集不集中。
不做绝对映射 ------即数据109不必要映射到数组的109位置, 只需要做相对映射。
数组的大小=最大值-最小值+1------找最值:遍历一遍(还是要比较)。
负数不是问题:min=-5 ------则-5-(-5)=0还是没问题。
反映射:5 + min = 105。
核心思想不是通过比较来达到有序的,找最值还是需要比较------遍历一遍O(N)。
A:原数组
↓ (次数映射)
C:统计次数的数组
↓ (通过次数来排序------相对映射)
A:排序后的数组
代码实现
cpp
//计数排序
void CountSort(int* a, int n)
{
//找最值------假设修正法
int min = a[0], max = a[0];
for (int i = 1; i < n; i++)
{
//如果有更大------就更新一下最大值
if (a[i] > max)
max = a[i];
if (a[i] < min)
min = a[i];
}
//O(N)
//0.计算数据范围
int range = max - min + 1;
//1.开辟计数数组
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
perror("malloc fail");
return;
}
memset(count, 0, sizeof(int) * range);
//也可以在上面直接calloc------不过calloc的底层逻辑本来就是malloc + memset;
//2.统计次数------遍历原数组------count数组相对位置处值++
for (int i = 0; i < n; i++)
{
// (1)统计次数的时候"减"min------"对应"下标位置的值++
count[a[i] - min]++;
}
//3.排序------遍历count数组,将数据映射回原数组
// i控制count遍历、j控制a遍历
int j = 0;
for (int i = 0; i < range; i++)
{
//如果count对应位置不为0------为几走几次
while (count[i]--) //--k走k-1次;k--走k次
{
// 直接覆盖原数组
// (2)还原的时候再把min"加"回来,用下标i加回min就是对应的a中的值
a[j++] = i + min;
}
}
}时间复杂度:arr数组大小N和count数组大小range当中,较大的那个。
- O(N) 或者 O(range);
- 或者直接O(N+range);
显然当范围range和数据量在同一量级时,计数排序就是最优排序。------O(N)
测试------100万个数据*(空间不大,大概不到1MB = 2^20 ≈ 10^6,整型就是4MB)*
cpp
void TestOP()
{
srand(time(0));//要产生随机需要一个种子,否则随机是写死的伪随机
const int N = 1000000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
//a1[i] = rand() % 100;
a1[i] = rand() % N; //产生100个数据------大小都在100万以内
//a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock(); //系统启动到执行到此的毫秒数
//InsertSort(a1, N);
int end1 = clock(); //系统启动到执行到此的毫秒数
int begin7 = clock();
//BubbleSort(a7, N);
int end7 = clock();
//int begin3 = clock();
//SelectSort(a3, N);
//int end3 = clock();
//ShellSort(a2, N);
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin4 = clock();
HeapSort(a4, N);
//QuickSort1(a2, 0, N - 1);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
//PrintArray(a4, N);
int begin6 = clock();
MergeSortNonR(a6, N);
int end6 = clock();
int begin3 = clock();
CountSort(a6, N);
int end3 = clock();
//printf("InsertSort:%d\n", end1 - begin1);
//printf("BubbleSort:%d\n", end7 - begin7);
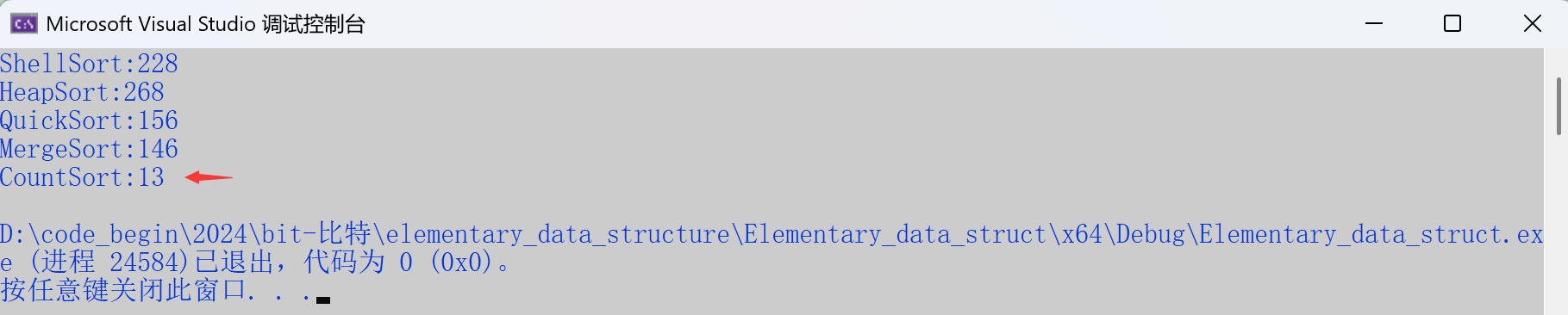
printf("ShellSort:%d\n", end2 - begin2);
//printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
//printf("QuickSort1:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("CountSort:%d\n", end3 - begin3);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}
int main()
{
//TestInsertSort();
//TestBubbleSort();
//TestShellSort();
//TestSelectSort();
//TestQuickSort();
//TestMergeSort();
//TestCountSort();
TestOP();
//MergeSortFile("sort.txt");
return 0;
}测试结果。
空间复杂度:
- O(range) ------数据越集中,空间复杂度越小
特性总结
计数排序的特性总结
特性
- 计数排序在数据范围集中时,效率很高*(几乎最高)*,但是适用范围及场景有限。
- 时间复杂度:O( MAX(N,range) )
- 空间复杂度:O(范围)
- 稳定性:稳定
局限性
- 数据要集中;
- 只适合整型;
- 有一定空间复杂度;(取决于数据的集中程度)
基数排序:先按个位排、再按十位排、再按百位排、......(只适合整型)
桶排序:把元素按区间分桶、桶内再排序,最后按桶顺序一次倒出来。(时间和空间都不占优)
实践中排序的对象大多都是结构体,所以计数排序在实践中的应用并不广泛。

而比较排序是通用的------只要能比较数据大小就能排------整型、浮点型、字符串、结构体......
排序的核心思想还是"比较"
- 比较排序实用性广 && 大。
- 非比较排序就是小众的 && 局限的,在特定情境下有自己的实践意义。
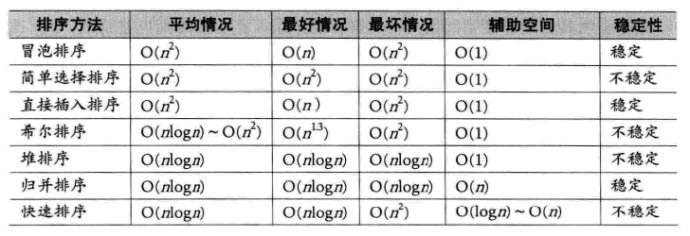
3. 排序算法复杂度及稳定性分析
稳定性:一个数组里面相同的数据,在排序前后的相对位置变不变。
------只排序整型当然没有意义(两个5没差)
------故计数排序不考虑稳定性
------排序结构体就有意义了(两个5不一样)
稳定性的应用:
例1:同样分数的考试成绩,先交卷的同学,在排序时名字排在前面。------需要稳定排序
例2:同分数的同学,数学分数高的排名靠前------先按数学排序,再按总分排序。
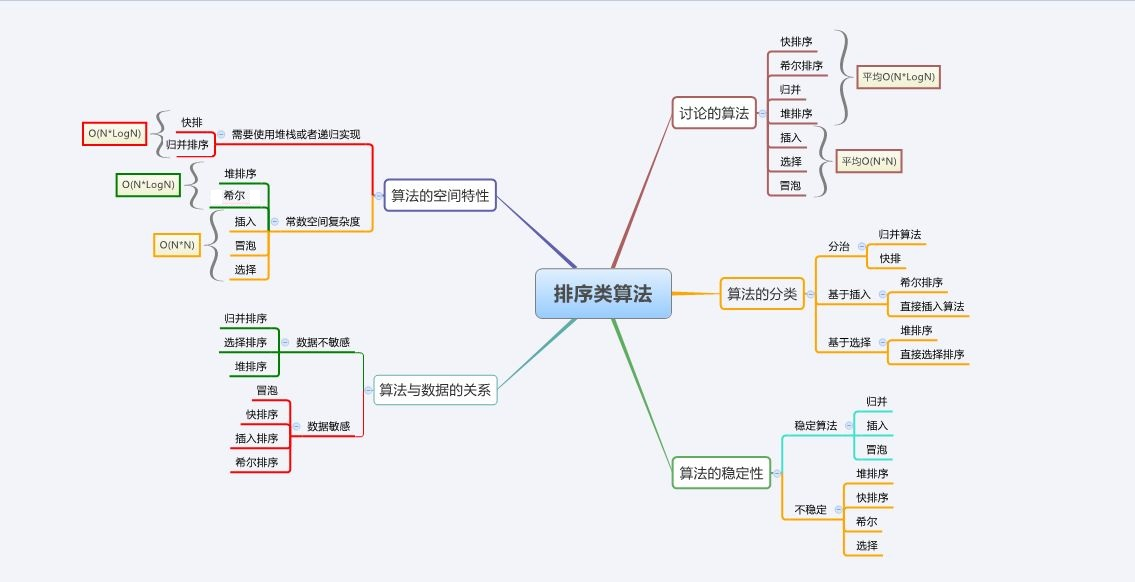
最好不要靠背,要注重理解。
(1)三种O(N^2)的排序算法,++只有选择排序不稳定++,空间复杂度都是O(1)。
时间处理上呈现等差数列------>O(N^2)
空间处理上不开额外空间------>O(1)
直接插入排序:相等的时候选择插入在后面,就稳定。
直接选择排序:乍一想感觉稳定,一些书上也说稳定,实际上不稳定。

选min的时候遇到相等(第二个1)就不更新min,可以保证1稳定。
但是在1和3交换后,就没办法保证3稳定。
冒泡排序:相邻比较,大的往后交换,相等就不换------稳定。
(2)一种O(?)的希尔排序,不稳定,空间复杂度O(1)。
希尔排序:相同的数据,预排时可能分到不同的组,就不稳定。
(3)三种O(nlogn)的排序算法,++只有归并稳定,只有堆排序空间复杂度O(1)++。
堆排序可以原地操作,不额外开空间
快速排序是递归,有空间复杂度的消耗的------要建立logN层栈帧
归并排序要建立一个辅助归并数组tmp
堆排序:举例说明不稳定------5 5 3,升序建好大堆,把第一个5(最大值)放到最后------不稳定。
快速排序:要把key交换到数组中间,比key小的在左边,比key大的在右边,和key相等的则在左边和右边都可以。
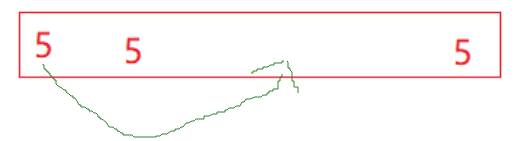
归并排序:归并的时候,取小的尾插到tmp数组,相等的时候优先尾插左区间的数据------稳定。
即:左 <= 右,就尾插左。
- "三稳四不稳"
- 只有快速排序、归并排序有空间复杂度的消耗
- 只有直接插入排序、冒泡排序、无优化快速排序时间复杂度分最好最坏。
(因为和数据是否有序有关)
整体看来,作为内排序,归并排序确实和其他几个一样有不错的效率,但是考虑到其必有O(N)的空间复杂度,相比之下还是快速排序更优。
4. 选择题练习



-
没有递归法。
-
没有简单排序。
-
hoare版本、挖坑法、前后指针法,得到的快排序列不一样。