一、前言
我国随着2021年11月1日开始实施的《个人信息保护法》,对隐私数据的重视和监管也越来越严格。而企业与第三方公司共享消费者数据以改进服务或将数据资产货币化,这都会增加数据泄露的几率。隐私增强技术 (PET)可以帮助企业扩大数据应用规模,同时确保个人或敏感信息的安全。从而提高企业声誉并降低合规风险。其中隐私增强技术已经存在了几十年,大部分时间仅在幕后发挥作用。
二、什么是隐私增强技术 (PET)
同隐私增强技术(PET)是一种广泛的技术(硬件或软件解决方案),旨在提取数据价值,以充分发挥其商业、科学和社会潜力,同时不危及这些信息的隐私和安全。
三、十大隐私增强技术示例
3 .1、 同态加密(HE)
同态加密是一种加密方法,可以对加密数据进行计算操作。它生成一个加密的结果,当解密时,它与操作的结果相匹配,就好像它们是在未加密的数据(即纯文本)上执行的一样。这使得加密数据能够被传输、分析并返回给数据所有者,数据所有者可以解密信息并查看原始数据的结果。因此,公司可以出于分析目的与第三方共享敏感数据。它在将加密数据保存在云存储中的应用程序中也很有用。一些常见的同态加密类型是:
部分同态加密 :可以对加密数据执行一种类型的操作,例如仅加法或仅乘法,但不能同时进行。
某种程度的同态加密 :可以执行不止一种类型的操作(例如加法、乘法),但可以进行有限数量的操作。
全同态加密 :可以执行一种以上的操作,并且对执行的操作次数没有限制。
3 .2、多方安全计算(sMPC)
是指允许对多方输入的数据进行联合计算,每一参与方只能获得正确计算结果,对其他参与方的输入数据保密的输入端技术。多方安全计算常见的技术选择是混淆电路(Garbled Circuit)和线性秘密共享(linear secret sharing)。安全多方计算是同态加密的一个子领域,但有一个区别:用户能够计算来自多个加密数据源的值。因此,机器学习模型可以应用于加密数据,因为 SMPC 用于大量数据。
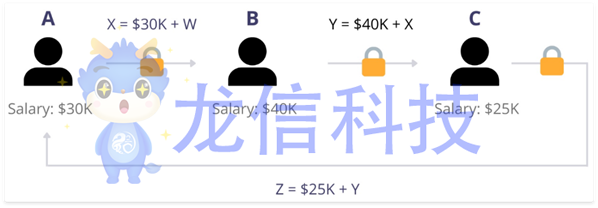
MPC可以通过以下一系列操作来解决这个问题:
按任意顺序对工人进行编号
第一个工人选择一个非常大的随机数,将其工资加到该数值上,然后将结果转发给第二个工人(见下图)
第二个工人将其工资添加到共享值上,然后将该结果转发给第三个工人,依此类推,直到所有工人都贡献了他们的工资
最后一个工人添加他们的工资并将最终结果发送给第一个工人
由于第一个工人选择了随机数,现在他们可以从总数中减去该数,从而得到所有工资的总和。然后,他们可以通过将这个结果除以工人的总数来计算平均值。
3 .3、去标识化技术
去标识化(de-identification),有时也称为"去标识化过程(de-identification process)"是指去除一组识别属性(identifying attribute)与数据主体(data principal)之间关联的过程。
个人信息去标识化(personal information de-identification ),是指通过对个人信息的技术处理,使其在不借助额外信息的情况下,无法识别个人信息主体(subject)的过程。个人信息去标识化的核心是利用技术手段,断开和个人信息主体的关联。
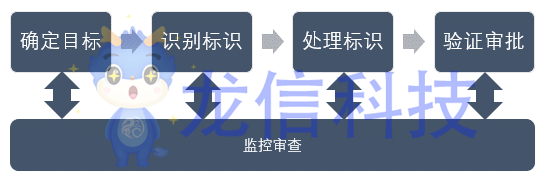
去标识化过程通常分为四个步骤,分别是确定目标、识别标识、处理标识和验证批准,而监控审查则贯穿于整个过程,如下图所示:
3 .4、伪匿名化
伪匿名化是一种通过用伪名替换字段值来隐藏个人的身份的混淆形式。通过伪匿名化,仅删除了识别数据的一部分,足以使数据值无法与其引用的个人或事物(数据主体)关联起来。
伪匿名化有多种方法,包括混淆,其中原始值与混淆的字母混合在一起,以及数据屏蔽,其中原始数据的某部分被隐藏。
在使用伪匿名化时,总会存在再识别的风险。不同的方法带来不同的风险,并且某些方法不符合某些法规。虽然伪匿名化具有许多用途,但仅仅依靠这一方法不足以成为完整的数据隐私解决方案。
3 .5、分布式学习
是指利用多个计算节点训练机器学习、深度学习模型的隐私协议,保证用户数据永远不会离开设备,可以分为联邦学习(FL)和拆分学习(SL)两种。
3 .6、零知识证明(ZK)
零知识证明是一种让一方向另一方证明给定的陈述是真实的,而不透露除该陈述为真以外的任何信息的方法。
零知识证明的一个经典示例是阿里巴巴洞穴,有两个角色,曾慧(证明者)和李磊(验证者)。曾慧和李磊都在洞穴的入口,洞穴有两个不同的入口通往两条不同的路径(A和B)。洞穴内有一扇连接两条路径的门,但只能用秘密代码打开。曾慧拥有该代码,李磊想要拥有它,但李磊首先想确保曾慧没有骗人。
曾慧如何向李磊展示她拥有秘密代码(钥匙)且不透露它?
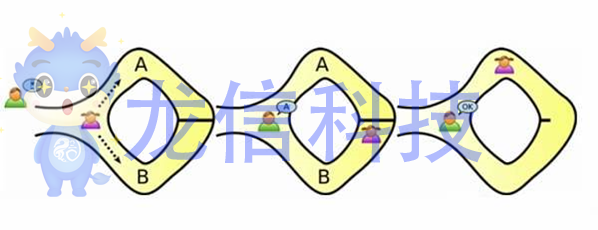
为此,曾慧可以通过任一门(A或B)进入洞穴。一旦在洞穴内,李磊会走近洞穴,并大声对曾慧喊,要求她沿着两个路径之一返回,选择是随机的。如果李磊喊曾慧返回 A 路径,但曾慧实际上在 B 路径上,那么只有在她确实拥有秘密代码(钥匙)的情况下,她才能通过 A 路径返回。当然,如果曾慧撒谎并且已经在 A 路径上了,她可能会幸运,但只要这个过程重复足够多次,只有当她拥有秘密代码(钥匙)时,她才能始终准确地返回。这是零知识证明的基本概念,即证明者可以在不透露陈述外的任何信息的情况下证明给定陈述的真实性。
关于零知识证明的挑战在于其答案并非百分之百保证,而且计算密集。为了将误差表现降低到可接受的水平,证明者和验证者之间需要多次交互。这使得这种方法对于缓慢或低功率设备来说并不实用。
3 .7、合成数据
合成数据(或"虚假数据")是人工生成的数据,它模拟了原始数据集的模式和组成,是一种数据匿名化的形式。合成数据在某些用例中是一个很好的解决方案,比如为工程师提供与生产数据类似的东西,用于测试目的,而不暴露实际客户个人信息。合成数据还广泛用于训练欺诈检测系统中使用的机器学习模型。
四、隐私增强技术(PET)的主要用例是什么
4 .1、测试数据管理
应用程序测试和数据分析有时由第三方提供商处理。 即使在内部处理它们,公司也应尽量减少对客户数据的内部访问。使用不会显著影响测试结果的合适 PET 对组织来说很重要。
4 .2、金融交易
由于公民可以自由进行私人交易和与其他方进行交易,金融机构有责任保护客户的隐私。
4 .3、医疗保健服务
医疗保健行业收集和共享(在需要时)患者的电子健康记录(EHR)。例如,临床数据可用于搜索各种药物组合的不良反应。在这种情况下,医疗保健公司通过使用 PET 来确保患者数据的隐私。
4 .4、包括中介在内的多方之间的数据传输
对于在两方之间充当中间人的企业,PET 的使用至关重要,因为这些企业负责保护双方信息的隐私。
五、结论
隐私增强技术(PET)是多方共享和分析数据的一种安全方式,这对用户、组织和社会具有巨大的潜在好处,因为高质量数据的可访问性和可用性是创新的第一步。隐私增强技术(PET)已经用于不同方面,比如应用程序和系统测试,尤其是在物联网、金融交易和医疗保健服务等领域。