引言:11w行测试代码只需要一晚
成果:我用大模型自动生成了11万行单元测试代码 ,覆盖了一个Java微服务项目的265个类。整个过程耗时5小时,使用5个并发的Claude会话。最终达到了平均86%的行覆盖率和78%的分支覆盖率。
Jason Wei(前OpenAI Agent首席工程师)在其文章《验证的不对称性与验证者定律》中提出了一个观点:AI攻克任务的可能性取决于任务的可验证性。
单测是一项非常符合可验证性定律的事情
- 输入输出明确(给定输入,期望输出)
- 验证简单(跑一下就知道过没过)
- 可批量验证(可以同时跑几百个测试)
- 结果清晰(要么绿色通过,要么红色失败)
在接下来的内容中,我会详细分享整个探索过程------从最初的理论思考,到实际的工程实践,再到踩过的坑和未解决的问题。需要提前说明的是,这不是一个完美的产品化解决方案,而是一次工程化的探索。(完整prompt🔗 测试工作流prompt)
验证性理论:为什么单测是AI最容易攻克的领域
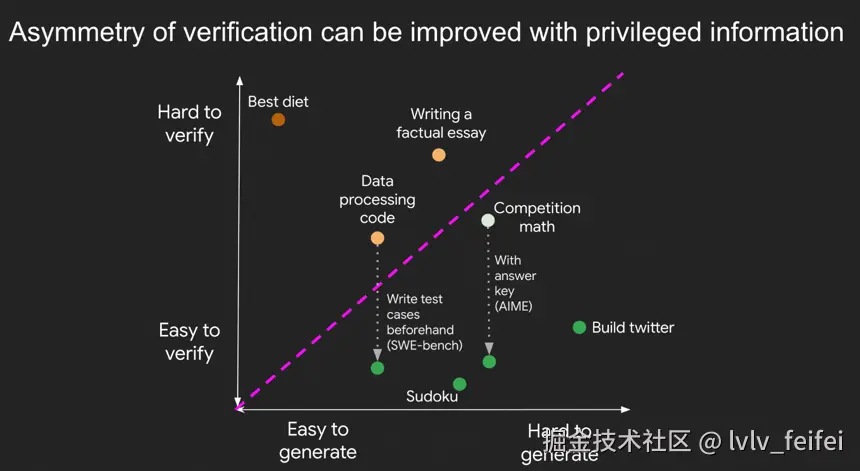
AI能力的锯齿状发展
Jason Wei在文章中画了一个很有意思的图:AI的能力不是均匀发展的,而是呈现锯齿状。有些任务AI已经远超人类(比如下围棋),有些任务AI还差得远(比如写诗)。为什么会这样?
关键在于验证的不对称性。
什么意思呢?简单说,就是"判断一个答案对不对"比"想出这个答案"要容易得多。比如:
- 验证"2的100次方等于多少"的答案很容易,但心算出来很难
- 验证一段代码能不能跑通很容易,但写出这段代码可能很难
- 验证一首诗写得好不好很难,因为没有客观标准
这就是为什么AI在某些领域进展神速,在另一些领域举步维艰。
可验证性的五个要素
Jason Wei总结了五个关键要素,决定了一个任务是否容易被AI攻克:
-
客观真理性(Objective Truth)
什么意思?就是所有人都认同什么是"对的"。
比如单测:测试通过就是通过,失败就是失败,没有中间状态。不像代码风格,有人喜欢这样写,有人喜欢那样写。
-
快速可验证性(Fast to Verify)
验证要快,最好几秒钟就能知道结果。
单测完美符合:
mvn test一跑,几秒钟就知道红还是绿。不需要人工review,不需要开会讨论。 -
可扩展验证性(Scalable to Verify)
能同时验证很多个解决方案。
我可以同时跑100个测试类,每个类都独立验证。这就是为什么我能并发5个Claude会话同时生成测试。
-
低噪声(Low Noise)
验证结果要准确,不能今天说对明天说错。
单测的验证结果是确定的:同样的代码,同样的测试,结果永远一样(当然,前提是你mock了所有外部依赖)。
-
连续奖励(Continuous Reward)
不只是对错,还要能区分"好一点"和"更好"。
覆盖率就是连续奖励:60%覆盖率比50%好,80%比60%好。这给了AI优化的方向。
关键洞察:将工程任务转化为可验证任务
很多人让大模型直接写业务代码,然后抱怨代码质量不行。为什么?因为业务代码的"好坏"很难验证:
- 代码能跑通不代表逻辑正确
- 性能好坏需要压测才知道
- 可维护性更是见仁见智
但单测不一样。单测天生就是用来验证的,它本身就是验证标准!
换句话说,与其让大模型判断业务代码实现是否符合需求文档要求,不如让它写容易验证的测试代码。当你的任务符合上面五个要素,AI就能很好地完成它。
读到这里大家也可以联想到非常经典的开发范式 TDD。测试驱动开发在大模型时代获得了新的生命力。在最近的Claude Code官方分享会中,其主持人明确表示Claude Code的项目工程就是典型的TDD范式实践,这个官方视频教程详细展示了Claude Code在实际开发中的最佳实践和TDD开发模式。
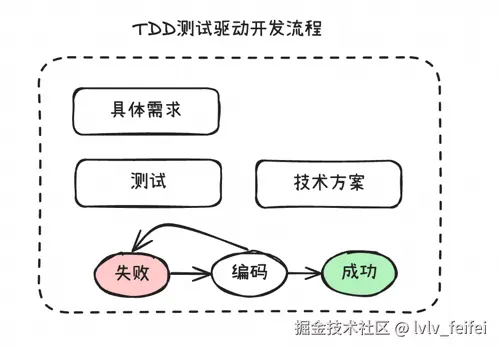
这种实践的核心思想可以简化为:
- 需求即测试:基于需求直接生成测试用例
- 声明式开发:通过测试用例声明期望的行为
- 迭代式实现:大模型不断尝试直到所有测试通过
为什么LeetCode被轻松攻克
所以大模型可以轻松高效的刷LeetCode,以及最近比较火的openAI IMO金奖
LeetCode的每道题都完美符合五要素:
- 答案唯一确定(要么AC要么WA)
- 在线判题系统秒出结果
- 可以同时提交多个解法
- 判题结果100%准确
- 还有执行时间和内存占用的排名
所以大模型刷LeetCode就像开了挂。现在GPT-4、Claude都能秒杀大部分算法题,不是因为它们突然变聪明了,而是因为这类任务天然适合它们。
单测:软件工程领域的LeetCode
回到单测,你会发现它简直就是软件工程领域的LeetCode:
| LeetCode | 单元测试 |
|---|---|
| 输入输出明确 | 给定输入,断言输出 |
| 在线判题 | mvn test |
| 测试用例 | 覆盖各种场景 |
| AC/WA | 测试通过/失败 |
| 执行时间 | 覆盖率指标 |
既然大模型能攻克LeetCode,那它一定也能攻克单测。问题只是如何设计一个合适的工程化方案。
单元测试构建的实践方法
说实话,一开始我的想法很简单:让Claude帮我写几个测试类。但真正动手后,我发现这事儿没那么简单。
问题的分解:单测天然适合分解
单测有个特点:天然适合分解。
为什么?因为单元测试的"单元"二字就决定了它的独立性。每个类的测试是独立的,不需要了解其他类;每个方法的测试也是独立的,只要mock掉依赖就行。
这意味着什么?意味着我可以把"为整个项目写单测"这个大任务,分解成"为每个类写单测"的小任务。而每个小任务都是独立的,可以并行处理。
从0到1:第一个测试类的诞生
但知道可以分解还不够,关键是怎么让大模型为一个类生成高质量的单测。
第一个问题是:用什么测试框架?
- JUnit 4还是JUnit 5?
- Mockito还是PowerMock?
- Spring Test还是纯单元测试?
这些选择看似简单,但对生成效果影响很大。我的项目用的是Spring Boot 2.1.13,自带JUnit 4和Mockito。但Mockito 2.x不支持静态方法mock,而我的代码里有大量工具类的静态方法调用。
我实践中的技术栈:
- JUnit 4(项目既定)
- Mockito 3.11.2(支持静态mock)
- Spring Boot Test(处理Spring容器)
第二个问题是:怎么验证生成的测试质量?
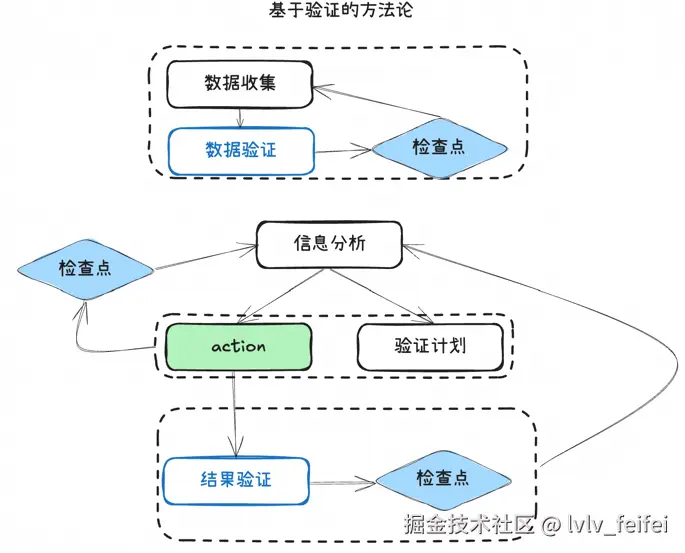
一开始我就意识到,不能让大模型生成了就完事,必须有验证机制。我设计了两个检查点:
- 运行检查:测试能不能跑通
- 覆盖率检查:覆盖率达不达标
这两个检查点构成了一个完整的验证链路。任何一个环节失败,就要让大模型重新生成。 再进一步你也无法保证大模型一定会按照检查点实际执行测试,所以检查点需要由代码把控并将错误的信息重新回吐给大模型做出优化
bash
# 验证测试是否通过
mvn test -Dtest=YourTestClass
# 验证覆盖率
mvn jacoco:report同时需要保证这两个脚本具有泛化性,可以应用在项目的所有类上。它们就像考试的评分标准,让大模型有了明确的优化目标。
检查点机制:让AI像TDD一样思考
我设计了一个基于检查点的迭代流程:
这个流程的精髓在于:每个检查点的失败都会触发针对性的改进。
比如:
- 编译失败 → 让AI检查导入和依赖
- 测试失败 → 让AI分析NPE和mock不完整的问题
- 覆盖率不足 → 让AI增加边界测试用例
优先级策略:筛选模块中复杂的类做先行验证
Prompt最开始构建的时候,肯定不可能满足所有场景的情况。需要对于每个模块中较为复杂的类进行先行验证,针对性地对所遇到的问题加以改善。
这样可以有效提升后续并发工程中生成单元测试的速度和成功率,同时减少会话消耗的token数。
单测构建实践:从理论到代码的落地
让我用一个实际案例展示整个过程。
实际案例:ClusterOperationServiceImpl
这是一个典型的Spring Service类,有174行代码,包含多个业务方法,依赖了7个其他服务。让我们看看AI是如何为它生成测试的。
原始类的特点:
java
@Service
@Slf4j
public class ClusterOperationServiceImpl implements ClusterOperationService {
@Autowired ClusterInstanceService clusterInstanceService;
@Autowired ResourceInfoService ResourceInfoService;
// ... 5个其他依赖
public boolean upDownGradeCluster(Long uid, String clusterId, ...) {
// 复杂的业务逻辑
// 涉及状态判断、工作流调用等
}
}生成的测试类核心部分:
java
@RunWith(MockitoJUnitRunner.class)
public class ClusterOperationServiceImplTest {
@InjectMocks
private ClusterOperationServiceImpl service;
@Mock
private ClusterInstanceService clusterInstanceService;
private MockedStatic<ThreadLocalManager> threadLocalManagerMock;
@Before
public void setUp() {
// 关键:mock静态方法避免NPE
threadLocalManagerMock = Mockito.mockStatic(ThreadLocalManager.class);
threadLocalManagerMock.when(ThreadLocalManager::getProduct)
.thenReturn(Product.);
}
@Test
public void testUpDownGradeCluster_UpgradeScenario() {
// Given: 准备测试数据
ClusterInstance instance = createTestInstance();
when(clusterInstanceService.getClusterInstanceByClusterId(anyLong(), anyString()))
.thenReturn(instance);
// When: 执行测试
boolean result = service.upDownGradeCluster(...);
// Then: 验证结果
assertTrue(result);
verify(updateFactory).startWorkflow(any(), anyString());
}
}生成效果:
- 行覆盖率:100%
- 分支覆盖率:100%
- 生成耗时:第1次尝试编译失败,第2次测试失败,第3次成功
- 总耗时:3轮迭代约13分钟
这个案例展示了几个关键点:
- AI能够识别并mock所有依赖
- AI学会了处理静态方法(ThreadLocalManager)
- AI能够构造合理的测试数据
- 通过迭代能够达到较高的覆盖率
从1到N:并发工程化
并发架构设计
解决方案是并发生成。但这里有个问题:Claude Code有rate limit,不能无限并发。
经过测试,我发现5个并发是个sweet spot:
- 太少:效率低
- 太多:触发限流,反而更慢
Claude Code:为什么选它?
市面上有很多代码生成工具,我为什么选Claude Code?
- 不依赖IDE:可以嵌入任何流程
- Session管理:可以保持上下文,进行多轮对话
- 分析和指令遵循的平衡:个人体验依旧是当前最为强大的通用代码agent,在遵循和延展思考上平衡得不错
Claude SDK调用方式对比
Claude提供了多种调用方式,各有优劣:
| 调用方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| API SDK | 原生支持各种语言 功能最全 | 费用较高 需要API密钥 | 生产环境 |
| Claude Code CLI | 本地token 经济实惠 | 需要本地安装 依赖Node.js | 开发测试 |
关键参数配置
以下是Claude Code CLI的核心参数配置,更多详细参数可以参考官方CLI参考文档。同时,这个演示视频展示了如何使用Claude Code构建无界面自动化工具,包括批处理和并发处理技巧。
| 参数 | 说明 | 推荐值 | 作用 |
|---|---|---|---|
--model |
模型选择 | sonnet | 平衡性能和成本 |
--output-format |
输出格式 | text | 便于解析处理 |
--verbose |
详细输出 | true | 调试时查看详情 |
--dangerously-skip-permissions |
跳过权限确认 | true | 自动化必需 |
-p |
非交互模式 | - | 批量处理必需 |
实际调用示例
bash
# 基础调用
claude -p --model sonnet "生成测试代码"
# 带session的调用(保持上下文)
claude --session $SESSION_ID --prompt "$PROMPT"
# Python封装调用
cmd = ["claude", "-p", "--model", "sonnet", "--output-format", "text", prompt]
result = subprocess.run(cmd, capture_output=True, text=True)最关键的是,Claude Code可以通过命令行调用,这意味着这个通用的agent可以以非常简单的bash指令形式嵌入到代码中,进一步可以控制其使用的工具、权限、乃至会话管理。
数据汇总展示
erlang
项目总体情况:
├── 模块数:8个
├── 需要测试的类:265个(排除了配置类等)
├── 实际尝试生成:265个
├── 生成代码行数:11万+
└──总耗时:5小时(5并发)
质量指标:
├── 平均行覆盖率:86%
├── 平均分支覆盖率:78%
├── 平均生成时间:6分钟/类
└── 平均重试次数:1.3次(大部分类结构相同只需要1次)
中间生成结果(统计在循环过程中失败次数):
├── 一次成功生成:203次
├── 测试运行失败次数:92次
└── 覆盖率不达标次数:25次成功率看起来不是100%,存在多次循环尝试依旧生成失败甚至输出对话中的内容在测试类文件中,但这个过程依旧远快于手搓。同时测试类初次生成不符合规范在迭代中变得更好,也充分说明构建检查点的必要性:
踩过的坑与未解决的问题
说实话,这个过程不是一帆风顺的。让我分享一些踩过的坑。
坑1:测试运行NPE
最开始生成的测试,10个有9个是NPE。为什么?
原因是大模型并没有充分发现间接依赖。比如:
java
// 测试这个Service类的buildData方法
@Service
public class PostOmsService extends AbstractOmsService {
@Autowired
private OmsUtils OmsUtils;
@Override
public PostMeasureData buildData(MeasureDataParam param) {
// inner()调用了外部依赖的方法
inner();
// buildData调用了内部工具类的方法
return new PostMeasureData(param,
OmsUtils.getOssStorageUsage(param)); // 这里是间接依赖
}
private void inner() {
// buildData调用了内部工具类的方法
return new PostMeasureData(param,
OmsUtils.getOssStorageUsage(param)); // 这里是间接依赖
}
}
// 生成的测试类中,如果只mock了service本身,会出问题
@Test
public void testBuildData() {
MeasureDataParam param = new MeasureDataParam();
// 忘记mock OmsUtils.getOssStorageUsage()
service.buildData(param); // NPE! 因为OmsUtils.getOssStorageUsage没有mock
}解决方案:在检测到错误让大模型修复测试的prompt中,明确遇到NPE需要思考间接依赖,给出示例以及错误信息等补充内容。
坑2:测试相互依赖
有些生成的测试竟然会相互影响!比如:
java
@Test
public void test1() {
System.setProperty("key", "value1");
// ...
}
@Test
public void test2() {
// 依赖于系统属性是默认值,但被test1改了!
String value = System.getProperty("key");
// 测试失败
}解决方案:要求每个测试方法完全独立,使用@After清理状态。
坑3:覆盖率虚高
有时候覆盖率数字很好看,但测试质量很差。我称之为"讨好型测试":
java
@Test
public void testComplexLogic() {
// 调用了方法,代码被覆盖了
service.complexMethod(null, null, null);
// 但没有任何断言!测试永远通过
}这种测试覆盖率很高,但没有验证任何东西,这种情况在claude code体验中遇到的很少,但是在资料查阅中还是有看到。
未解决的问题
坦白说,还有一些问题没有完全解决:
-
边界条件覆盖
大模型经常遗漏边界条件。比如对于一个处理列表的方法,它可能测试了正常情况,但忘了测试空列表、null、单个元素等边界情况。需要有充分的机制和检查点来保证这些case的构建。
可尝试的解决方案:先让AI分析所有可能的边界条件,生成一个边界测试清单,就如同单测的TDD,先给出完整的测试清单再在这个基础上逐个时间验证。
-
"讨好型"测试的识别
如何判断一个测试是真的在验证逻辑,还是只是为了覆盖率而覆盖?这需要更智能的验证机制。
可尝试是引入变异测试(Mutation Testing):故意修改被测代码,如果测试还能通过,说明测试没有真正验证逻辑。
未来的三个方向
基于这次探索,我看到了三个值得深入的方向:
1. 深化单测生成能力
当前方案还不完美,需要继续优化:
- 更智能的边界条件识别
- 更严格的测试质量验证
- 更好的错误自愈能力
- 最重要的是将这个部分泛化,真正做到在各种项目的背景下通过一套公用的 大模型测试编排方案解决单测问题。
2. 工具产品化
将这套方法论产品化,让更多团队受益:
- 基于N8n构建可视化工作流
- 提供Web界面,降低使用门槛
- 支持多语言、多框架
3. 扩展到集成测试和E2E
单测只是开始,同样的思路可以扩展到:
- 集成测试:基于API文档生成
- E2E测试:基于用户行为录制生成
- 性能测试:基于线上流量生成
写在最后:这不是终点
回顾整个过程,最大的感受是开头那篇博文思考:AI攻克任务的可能性取决于任务的可验证性。
当一项任务满足开头的5个条件 or 可以将任务拆解为符合条件的子任务时,意味着他可以被AI解决的日子就不远了。
这或许就是软件开发范式改变的开始。
本文基于真实的工程实践总结,所有数据和代码示例均来自实际项目。完整的代码和详细日志见附录。
附录
参考资料
理论基础
Jason Wei的经典文章《验证的不对称性与验证者定律》详细阐述了AI任务可解性的验证理论,是本文理论基础的核心来源。
Claude Code 技术文档
Claude Code CLI 参考文档提供了官方CLI命令行参数的详细说明,包含所有参数配置和使用示例。
视频教程
Claude Code 最佳实践是官方发布的视频教程,展示了Claude Code在实际开发中的最佳实践和TDD开发模式。
另一个有价值的资源是使用Claude Code构建自动化视频,演示了如何使用Claude Code构建无界面自动化工具,包括批处理和并发处理技巧。