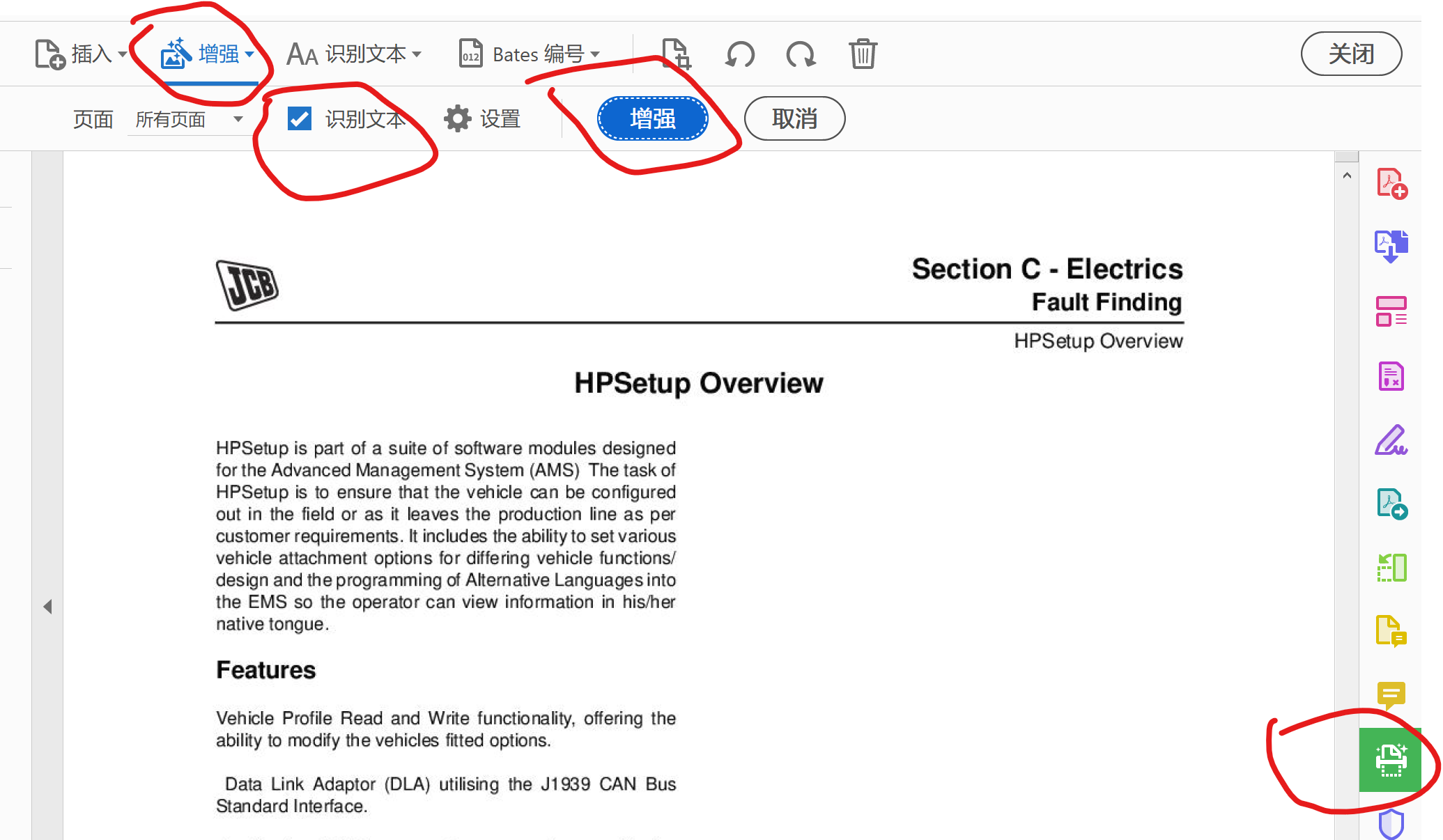
在Adobe Acrobat 中,OCR(光學字元辨識)用於將掃描的PDF 或圖像文件中的文字轉換為可編輯的文本。 要保存使用OCR 處理後的PDF,你需要先執行OCR,然後正常保存文件,就像保存任何其他PDF 文件一樣。
詳細步驟如下:
- 打開文件: 在Acrobat 中打開包含掃描文本的PDF 文件或圖像文件。
- 執行OCR:
- 轉到「工具」中心或右側窗格,然後選擇「掃描與OCR」。
- 選擇「掃描的檔」或「相機影像」,然後點擊「增強」來清理影像並自動辨識文字。
- 如果需要手動辨識文字,請點擊「識別文字」。
- 保存文件:
- 點擊「檔案」菜單,然後選擇「儲存」或「另存新檔」。
- 選擇一個文件夾,輸入文件名,然後點擊「儲存