第一章:软件包管理器
1-1 什么是软件包
- 在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序。
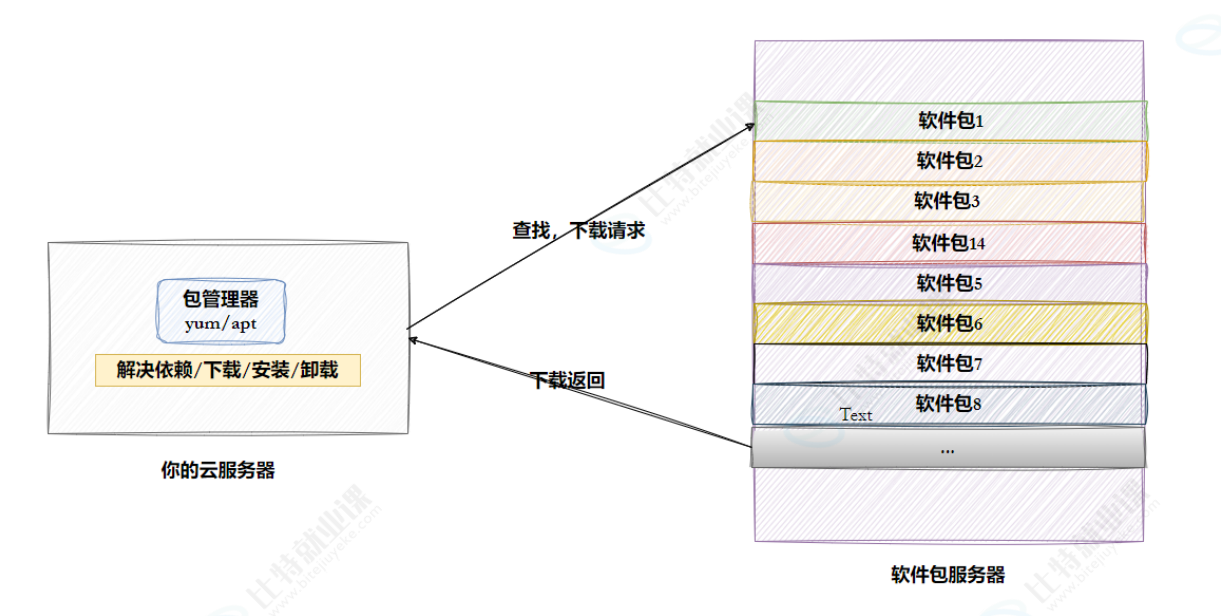
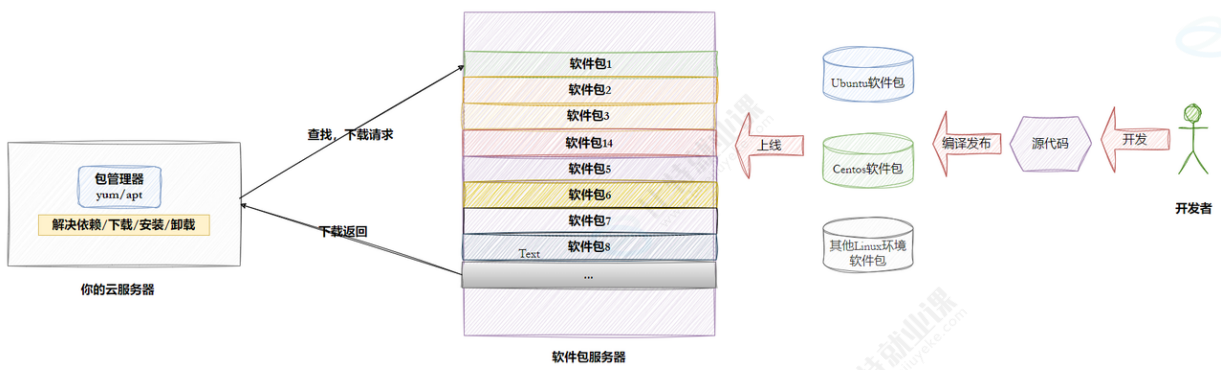
- 但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装。
- 软件包和软件包管理器, 就好比 "App" 和 "应用商店" 这样的关系。
- yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora, RedHat, Centos等发行版上。
- Ubuntu:主要使用apt(Advanced Package Tool)作为其包管理器。apt同样提供了自动解决依赖关系、下载和安装软件包的功能。
1-2 Linux软件生态
Linux下载软件的过程(Ubuntu、Centos、other)
操作系统的好坏评估 --- 生态问题
为什么会有人免费特定社区提供软件,还发布?还提供云服务器让你下载?
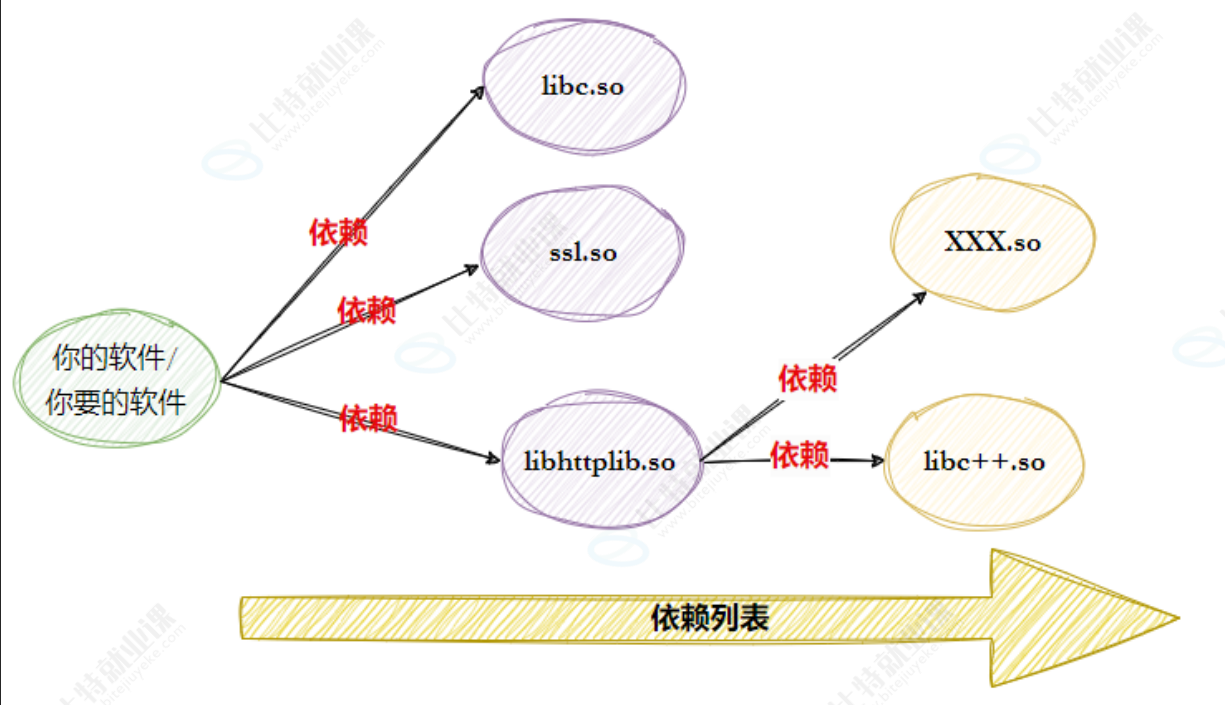
软件包依赖的问题
1-3 yum具体操作
1-3-1 查看软件包
通过 yum list 命令可以罗列出当前一共有哪些软件包. 由于包的数目可能非常之多, 这里我们需要使用grep 命令只筛选出我们关注的包。例如:
bash
$ yum list | grep lrzsz
lrzsz.x86_64 0.12.20-36.el7 @base注意事项:
- 软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构。
- "x86_64" 后缀表示64位系统的安装包, "i686" 后缀表示32位系统安装包. 选择包时要和系统匹配。
- "el7" 表示操作系统发行版的版本. "el7" 表示的是 centos7/redhat7. "el6" 表示centos6/redhat6。
- 最后一列, base 表示的是 "软件源" 的名称, 类似于 "小米应用商店", "华为应用商店" 这样的概念。
1-3-2 安装软件
通过 yum, 我们可以通过很简单的一条命令完成 gcc 的安装.
bash
$ sudo yum install -y lrzsz新建普通用户不能使用sudo

yum/apt 会自动找到都有哪些软件包需要下载, 这时候敲 "y" 确认安装。
出现 "complete" 字样或者中间未出现报错, 说明安装完成。
注意事项:
- 安装软件时由于需要向系统目录中写入内容, 一般需要 sudo 或者切到 root 账户下才能完成。
- yum/apt安装软件只能一个装完了再装另一个. 正在yum/apt安装一个软件的过程中, 如果再尝试用yum/apt安装另外一个软件, yum/apt会报错。
1-3-3 卸载软件
仍然是一条命令:
bash
sudo yum remove [-y] lrzsz1-3-4 注意事项
关于 yum / apt 的所有操作必须保证主机(虚拟机)网络畅通!!!
可以通过 ping 指令验证
bash
ping www.baidu.com1-4 安装源
Cetnos 安装源路径:
bash
$ ll /etc/yum.repos.d/
total 16
-rw-r--r-- 1 root root 676 Oct 8 20:47 CentOS-Base.repo # 标准源
-rw-r--r-- 1 root root 230 Aug 27 10:31 epel.repo # 扩展源
# 安装扩展源
# $ sudo yum install -y epel-release第二章:编辑器Vim
IDE例子
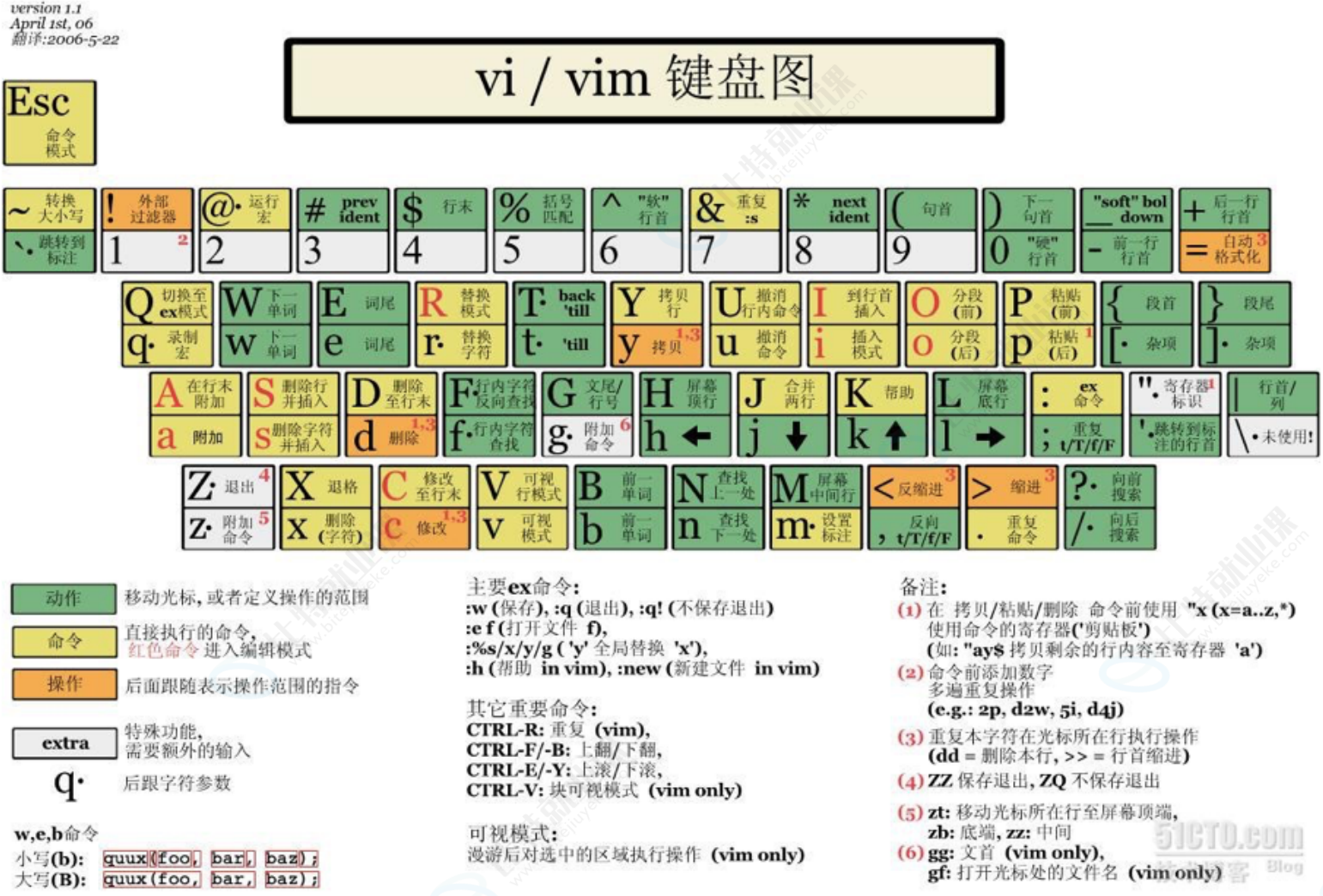
2-1 Linux编辑器-vim使用
vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,而且还有一些新的特性在里面。例如语法加亮,可视化操作不仅可以在终端运行,也可以运行于x window、 mac os、windows。后续,统一按照vim来进行讲解。
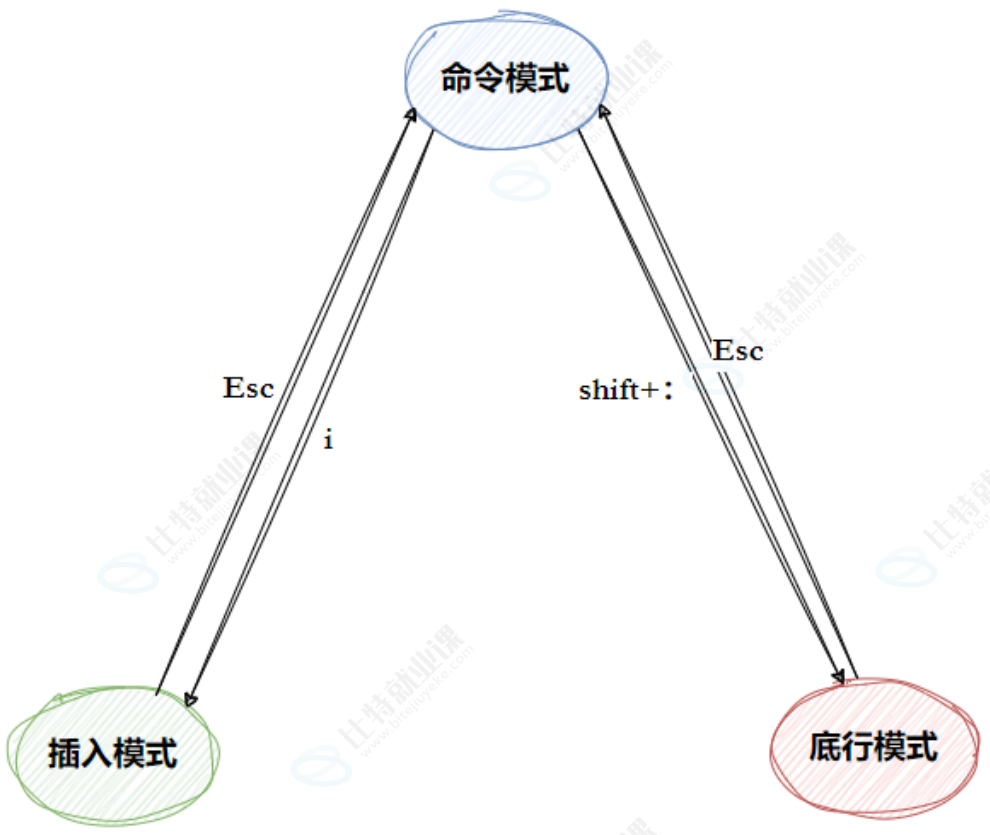
2-2 vim的基本概念
课堂上我们讲解vim的三种模式(其实有好多模式,目前掌握这3种即可),分别是命令模式(command mode)、插入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下:
正常/普通/命令模式(Normal mode)
控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode
插入模式(Insert mode)
只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。
末行模式(last line mode)
文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。 在命令模式下,shift+: 即可进入该模式。要查看你的所有模式:打开vim,底行模式直接输入 :help vim-modes
这里一共有12种模式:six BASIC modes和six ADDITIONAL modes
2-3 vim的基本操作
进入vim,在系统提示符号输入vim及文件名称后,就进入vim全屏幕编辑画面
bash
$ vim test.c不过有一点要特别注意,就是你进入vim之后,是处于正常模式,你要切换到插入模式才能够输入文字。
正常模式\]切换至\[插入模式
输入a
输入i
输入o
插入模式\]切换至\[正常模式
目前处于插入模式,就只能一直输入文字,如果发现输错了字,想用光标键往回移动,将该字删 除,可以先按一下「ESC」键转到正常模式再删除文字。当然,也可以直接删除。
正常模式\]切换至\[末行模式
「shift + ;」, 其实就是输入「:」
退出vim及保存文件,在正常模式下,按一下「:」冒号键进入「Last line mode」,例如:
: w (保存当前文件)
: wq (输入「wq」,存盘并退出vim)
: q! (输入q!,不存盘强制退出vim)
2-4 vim正常模式命令集
插入模式
按「i」切换进入插入模式「insert mode」,按"i"进入插入模式后是从光标当前位置开始输入文件;
按「a」进入插入模式后,是从目前光标所在位置的下一个位置开始输入文字;
按「o」进入插入模式后,是插入新的一行,从行首开始输入文字。
从插入模式切换为命令模式
按「ESC」键。
移动光标
vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、「l」,分别控制光标左、下、上、右移一格
按「G」:移动到文章的最后
按「 $ 」:移动到光标所在行的"行尾"
按「^」:移动到光标所在行的"行首"
按「w」:光标跳到下个字的开头
按「e」:光标跳到下个字的字尾
按「b」:光标回到上个字的开头
按「#l」:光标移到该行的第#个位置,如:5l,56l
按[gg]:进入到文本开始
按[shift+g]:进入文本末端
按「ctrl」+「b」:屏幕往"后"移动一页
按「ctrl」+「f」:屏幕往"前"移动一页
按「ctrl」+「u」:屏幕往"后"移动半页
按「ctrl」+「d」:屏幕往"前"移动半页
删除文字
「x」:每按一次,删除光标所在位置的一个字符
「#x」:例如,「6x」表示删除光标所在位置的"后面(包含自己在内)"6个字符
「X」:大写的X,每按一次,删除光标所在位置的"前面"一个字符
「#X」:例如,「20X」表示删除光标所在位置的"前面"20个字符
「dd」:删除光标所在行
「#dd」:从光标所在行开始删除#行
复制
「yw」:将光标所在之处到字尾的字符复制到缓冲区中。
「#yw」:复制#个字到缓冲区
「yy」:复制光标所在行到缓冲区。
「#yy」:例如,「6yy」表示拷贝从光标所在的该行"往下数"6行文字。
「p」:将缓冲区内的字符贴到光标所在位置。注意:所有与"y"有关的复制命令都必须与"p"配合才能完成复制与粘贴功能。
替换
「r」:替换光标所在处的字符。
「R」:替换光标所到之处的字符,直到按下「ESC」键为止。
撤销上一次操作
「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次"u"可以执行多次回复。
「ctrl + r」: 撤销的恢复
更改
「cw」:更改光标所在处的字到字尾处
「c#w」:例如,「c3w」表示更改3个字
跳至指定的行
「ctrl」+「g」列出光标所在行的行号。
「#G」:例如,「15G」,表示移动光标至文章的第15行行首。
2-5 vim末行模式命令集
在使用末行模式之前,请记住先按「ESC」键确定您已经处于正常模式,再按「:」冒号即可进入末行模式。
列出行号
「set nu」: 输入「set nu」后,会在文件中的每一行前面列出行号。
跳到文件中的某一行
「#」:「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,再回车,就会跳到文章的第15行。
查找字符
「/关键字」: 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往后寻找到您要的关键字为止。
「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往前寻找到您要的关键字为止。
问题:/ 和 ?查找有和区别?操作实验一下

保存文件
「w」: 在冒号输入字母「w」就可以将文件保存起来
离开vim
「q」:按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim。
「wq」:一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件。
2-6 vim操作总结
三种模式
- 正常模式
- 插入模式
- 底行模式
vim操作
打开,关闭,查看,查询,插入,删除,替换,撤销,复制等等操作。
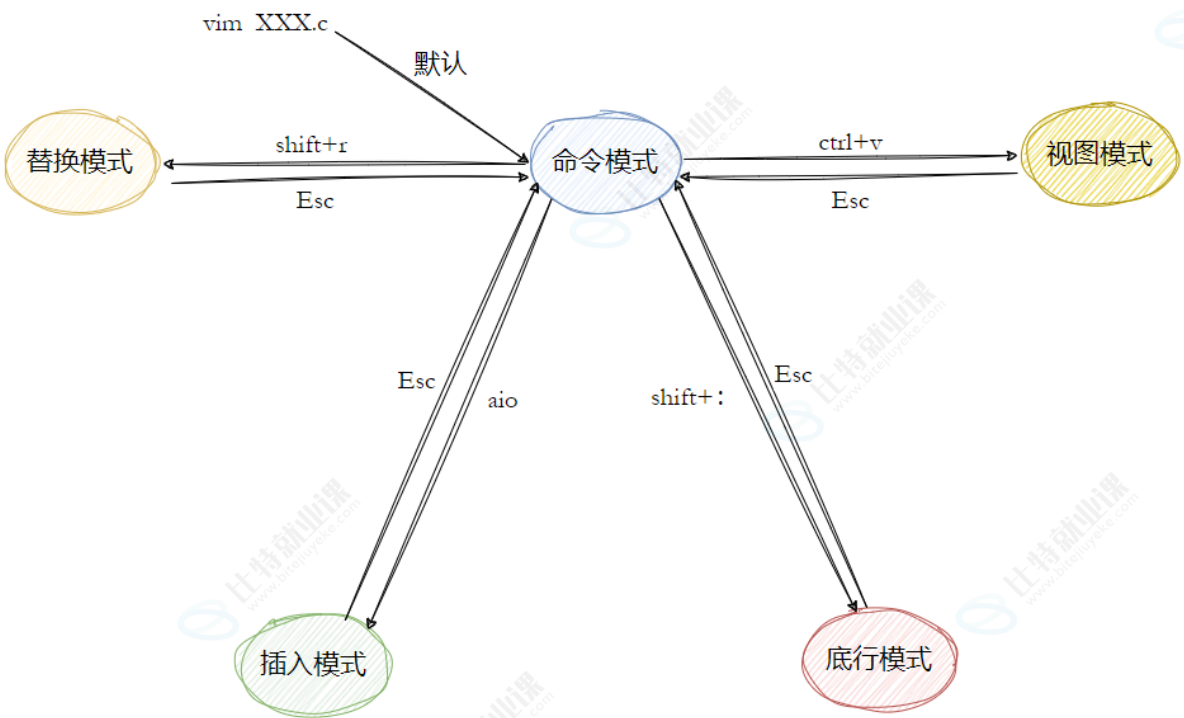
2-7 简单vim配置
配置文件的位置
- 在目录 /etc/ 下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,对所有用户都有效。
- 而在每个用户的主目录下,都可以自己建立私有的配置文件,命名为:".vimrc"。例如,/root目录下,通常已经存在一个.vimrc文件,如果不存在,则创建之。
- 切换用户成为自己执行 su ,进入自己的主工作目录,执行 cd ~
- 打开自己目录下的.vimrc文件,执行 vim .vimrc
常用配置选项,用来测试
- 设置语法高亮: syntax on
- 显示行号: set nu
- 设置缩进的空格数为4: set shiftwidth=4
使用插件
要配置好看的vim,原生的配置可能功能不全,可以选择安装插件来完善配置,保证用户是你要配置的用户,接下来:
- 安装TagList插件,下载taglist_xx.zip ,解压完成,将解压出来的doc的内容放到~/.vim/doc, 将解压出来的plugin下的内容拷贝到~/.vim/plugin
- 在~/.vimrc 中添加: let Tlist_Show_One_File=1 let Tlist_Exit_OnlyWindow=1 let Tlist_Use_Right_Window=1
- 安装文件浏览器和窗口管理器插件: WinManager
- 下载winmanager.zip,2.X版本以上的
- 解压winmanager.zip,将解压出来的doc的内容放到~/.vim/doc, 将解压出来的plugin下的内容拷贝到~/.vim/plugin
- 在~/.vimrc 中添加 let g:winManagerWindowLayout='FileExplorer|TagList nmap wm :WMToggle<cr>
- 然后重启vim,打开~/XXX.c或~/XXX.cpp, 在normal状态下输入"wm", 你将看到上图的效果。更具体移步:点我,其他手册,请执行 vimtutor 命令。
第三章:编译器gcc/g++
3-1 背景知识
-
预处理(进行宏替换/去注释/条件编译/头文件展开等)
-
编译(生成汇编)
-
汇编(生成机器可识别代码)
-
连接(生成可执行文件或库文件)

3-2 gcc编译选项
格式 gcc 选项 要编译的文件 选项 目标文件
3-2-1 预处理(进行宏替换)
预处理功能主要包括宏定义,文件包含,条件编译,去注释等。
预处理指令是以#号开头的代码行。
实例: gcc --E hello.c --o hello.i
选项"-E",该选项的作用是让 gcc 在预处理结束后停止编译过程。
选项"-o"是指目标文件,".i"文件为已经过预处理的C原始程序。
3-2-2 编译(生成汇编)
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
用户可以使用"-S"选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
实例: gcc --S hello.i --o hello.s
3-2-3 汇编(生成机器可识别代码)
汇编阶段是把编译阶段生成的".s"文件转成目标文件
读者在此可使用选项"-c"就可看到汇编代码已转化为".o"的二进制目标代码了
实例: gcc --c hello.s --o hello.o
3-2-4 连接(生成可执行文件或库文件)
在成功编译之后,就进入了链接阶段。
实例: gcc hello.o --o hello
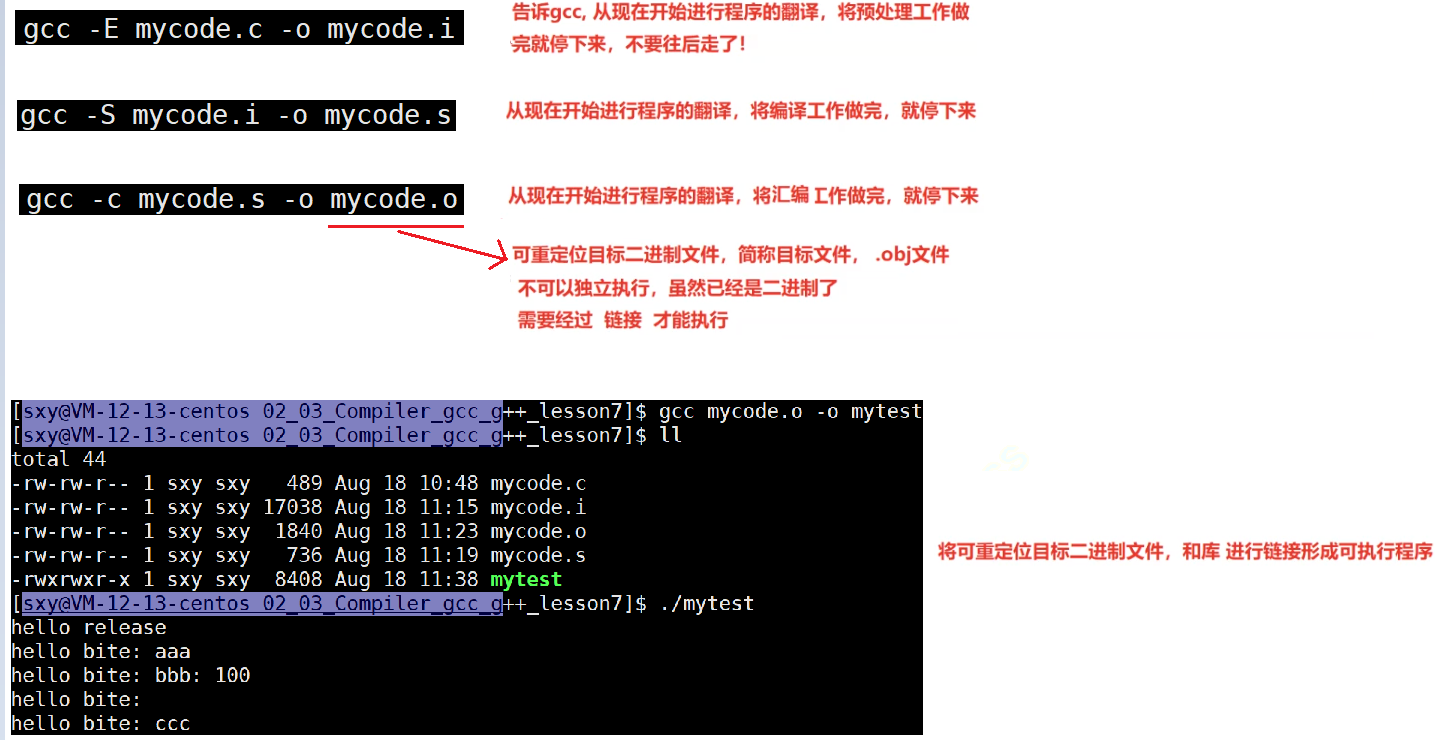
在这里涉及到一个重要的概念:函数库
- 我们的C程序中,并没有定义"printf"的函数实现,且在预编译中包含的"stdio.h"中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实"printf"函数的呢?
- 最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径"/usr/lib"下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数"printf"了,而这也就是链接的作用

3-3 静态库和动态库
- 静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为".a"
- 动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为".so",如前面所述的 libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件,如下所示。 gcc hello.o --o hello
- gcc默认生成的二进制程序,是动态链接的,这点可以通过 file 命令验证。

3-4 动态链接和静态链接
在我们的实际开发中,不可能将所有代码放在一个源文件中,所以会出现多个源文件,而且多个源文件之间不是独立的,而会存在多种依赖关系,如一个源文件可能要调用另一个源文件中定义的函数,但是每个源文件都是独立编译的,即每个*.c文件会形成一个*.o文件,为了满足前面说的依赖关系,则需要将这些源文件产生的目标文件进行链接,从而形成已个可以执行的程序。这个链接的过程就是静态链接。静态链接的缺点很明显:
- 浪费空间:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,如多个程序中都调用了printf()函数,则这多个程序中都含有printf.o,所以同⼀个目标文件都在内存存在多个副本;
- 更新比较困难:因为每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
动态链接的出现解决了静态链接中提到问题。动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
动态链接其实远比静态链接要常用得多。比如我们查看下 hello 这个可执行程序依赖的动态库,会发现它就用到了⼀个c动态链接库:
bash
ldd hello
linux-vdso.so.1 => (0x00007fffeb1ab000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff776af5000)
/lib64/ld-linux-x86-64.so.2 (0x00007ff776ec3000)
# ldd命令⽤于打印程序或者库⽂件所依赖的共享库列表。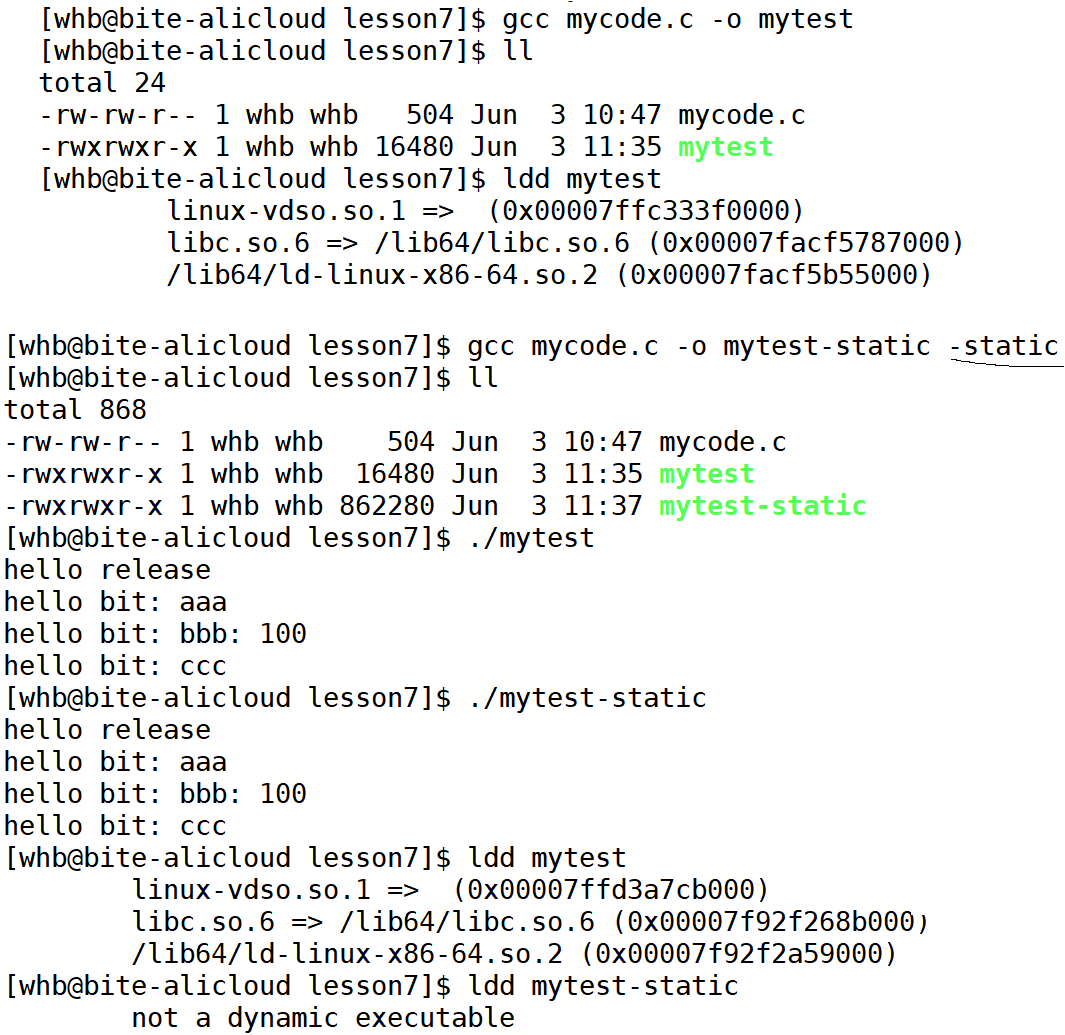

注意1:
• Linux下,动态库XXX.so, 静态库XXX.a
• Windows下,动态库XXX.dll, 静态库XXX.lib
一般我们的云服务器,C/C++的静态库并没有安装,可以采用如下方法安装
bash
yum install glibc-static libstdc++-static -y3-5 gcc其他常用选项
-E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
-S 编译到汇编语言不进行汇编和链接
-c 编译到目标代码
-o 文件输出到 文件
-static 此选项对生成的文件采用静态链接
-g 生成调试信息。GNU 调试器可利用该信息。
-shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库.
-O0
-O1
-O2
-O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
-w 不生成任何警告信息。
-Wall 生成所有警告信息。
第四章:自动化构建-make/Makefile
4-1 背景
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是------"自动化编译",一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
4-2 理解
依赖例子
4-3 基本使用
实例代码
cpp
#include <stdio.h>
int main() {
printf("hello Makefile!\n");
return 0;
}Makefile文件
bash
myproc:myproc.c
gcc -o myproc myproc.c
.PHONY:clean
clean:
rm -f myproc依赖关系
上面的文件myproc,它依赖myproc.c
依赖方法
gcc -o myproc myproc.c ,就是与之对应的依赖关系
依赖关系
上面的文件 mycode,它依赖 mycode.o
mycode.o , 它依赖 mycode.s
mycode.s , 它依赖 mycode.i
mycode.i , 它依赖 mycode.c
依赖方法
gcc mycode.* -option mycode.* ,就是与之对应的依赖关系
项目清理
- 工程是需要被清理的
- 像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令------"make clean",以此来清除所有的目标文件,以便重编译。
- 但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是,总是被执行的。
- 可以将我们的 myproc 目标文件声明成伪目标,测试一下。
当clean在最下面时,需要make clean指令
当clean在最上方时,只需要make指令
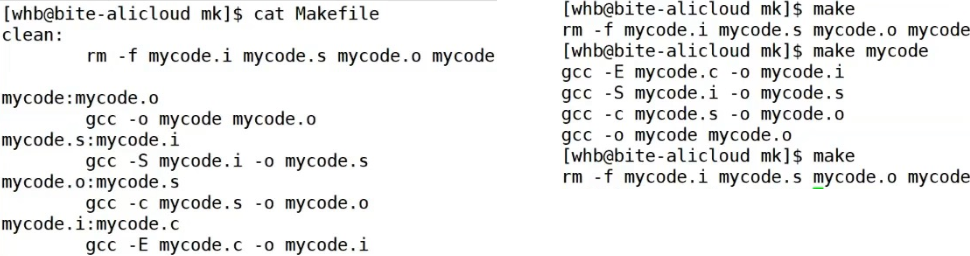
make是自顶向下扫描Makefile,把第一个形成的目标文件充当为make的默认动作
什么叫做总是被执行?
bash
stat XXX
File: 'XXX'
Size: 987 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 1321125 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ whb) Gid: ( 1000/ whb)
Access: 2024-10-25 17:05:30.430619002 +0800
Modify: 2024-10-25 17:05:25.940595116 +0800
Change: 2024-10-25 17:05:25.940595116 +0800
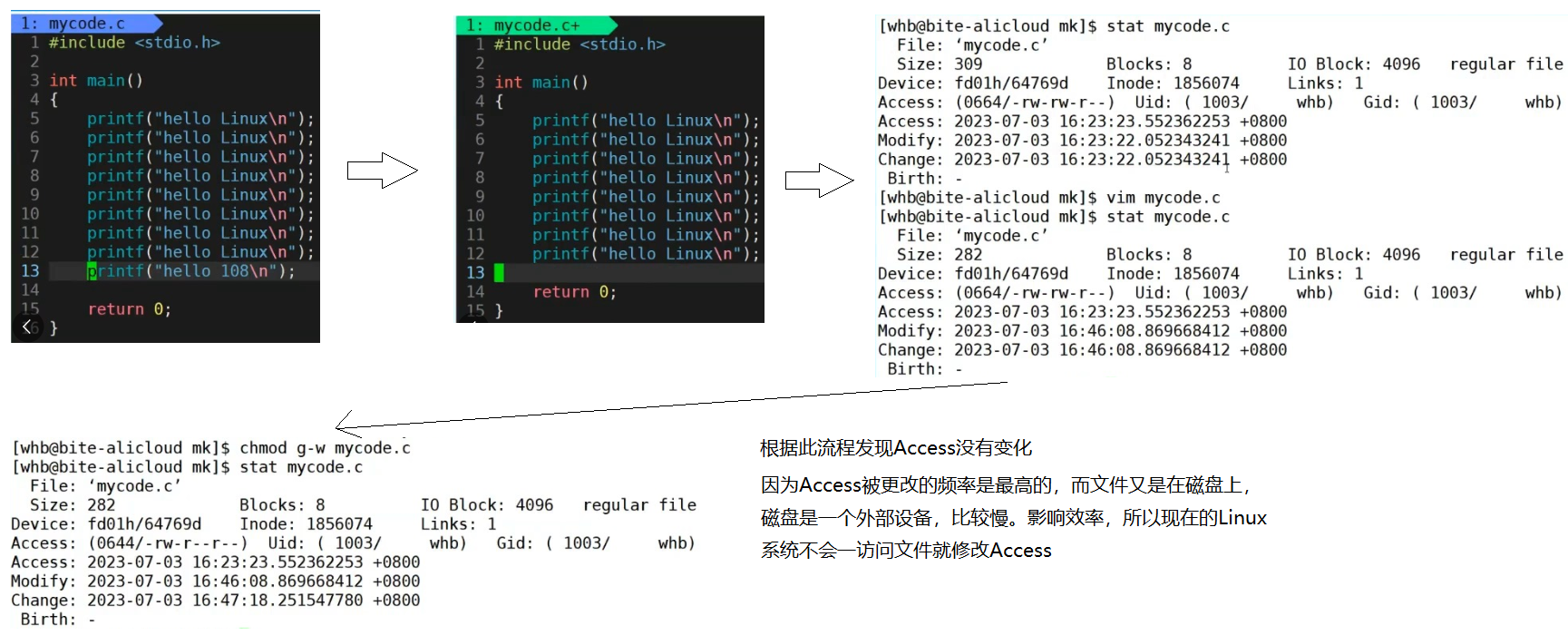
⽂件 = 内容 + 属性
Modify: 内容变更,时间更新
Change:属性变更,时间更新
Access:常指的是⽂件最近⼀次被访问的时间。在Linux的早期版本中,每当⽂件被访问时,其
atime都会更新。但这种机制会导致⼤量的IO操作。具体更新原则,不做过多解释。
结论:
.PHONY:让make忽略源文件和可执行目标文件的M时间对比
4-4 推导过程
bash
myproc:myproc.o
gcc myproc.o -o myproc
myproc.o:myproc.s
gcc -c myproc.s -o myproc.o
myproc.s:myproc.i
gcc -S myproc.i -o myproc.s
myproc.i:myproc.c
gcc -E myproc.c -o myproc.i
.PHONY:clean
clean:
rm -f *.i *.s *.o myprocMakefile文件乱序也能执行。可以理解为函数位置不重要,能找到即可。但少一个依赖关系不可行
编译
bash
$ make
gcc -E myproc.c -o myproc.i
gcc -S myproc.i -o myproc.s
gcc -c myproc.s -o myproc.o
gcc myproc.o -o myproc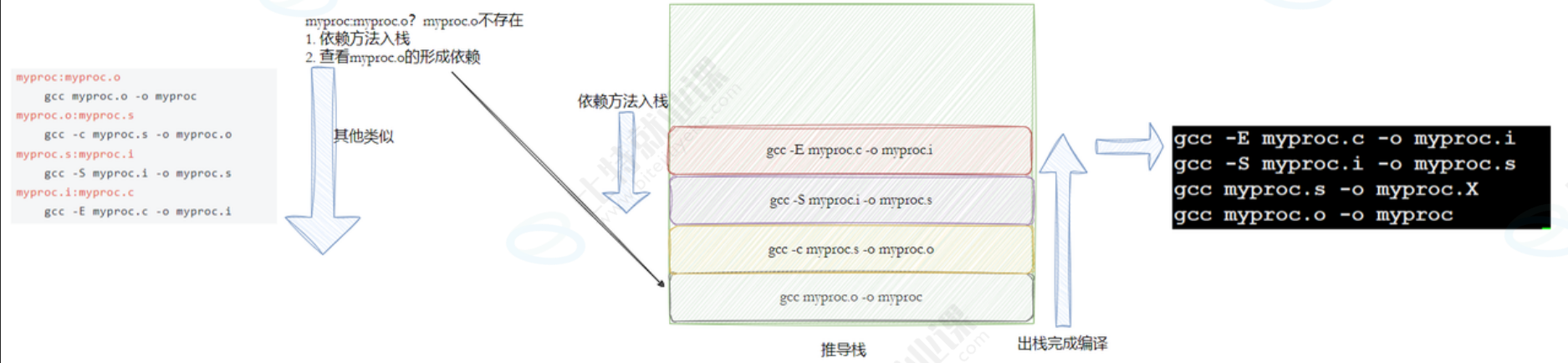
make是如何工作的,在默认的方式下,也就是我们只输入make命令。那么,
- make会在当前目录下找名字叫"Makefile"或"makefile"的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到"myproc"这个文件,并把这个文件作为最终的目标文件。
- 如果myproc文件不存在,或是myproc所依赖的后面的myproc.o文件的文件修改时间要比myproc这个文件新(可以用 touch 测试),那么,他就会执行后面所定义的命令来生成myproc这个文件。
- 如果myproc所依赖的myproc.o文件不存在,那么make会在当前文件中找目标为myproc.o文件的依赖性,如果找到则再根据那一个规则生成hello.o文件。(这有点像一个堆栈的过程)
- 当然,你的C文件和H文件是存在的啦,于是make会生成 myproc.o 文件,然后再用 myproc.o 文件声明make的终极任务,也就是执行文件myproc了。
- 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
- make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
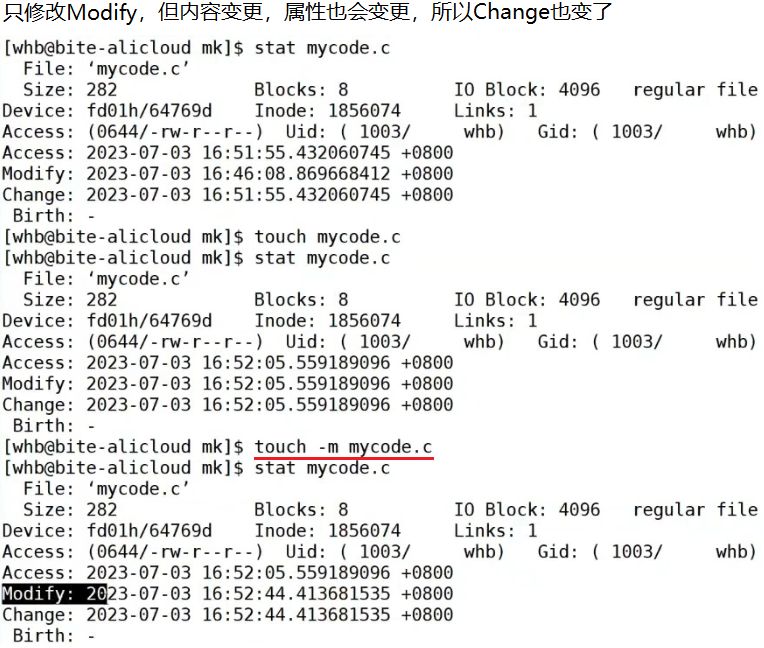
make编译一次后就不允许再次编译,修改代码后又可以编译。所以源代码无改动就不会再编译,为什么?因为没必要,提高编译效率。make会根据源文件和目标文件的新旧,判定是否需要重新执行依赖关系进行编译!
怎么做到的?
一定是源文件形成可执行,先有源文件,才有可执行。一般而言,源文件的最近修改时间比可执行文件要老。如果我们更改了源文件,历史上曾经有可执行,那么源文件的最近修改时间一定要比可执行程序要新!
只需要比较可执行程序的最近修改时间和源文件的最近修改时间
.exe新于.c -> 源文件是老的,不需要重新编译
.exe老于.c -> 源文件是新的,需要重新编译
一般而言,.exe==.c? 一般不会
文件 =文件内容 +文件属性
打开文件会修改Access,删除文件内容会修改Modify,且文件变小了,所以Change也改变了
touch后面跟一个不存在的文件名,新建;如果后面跟一跟存在的文件名,会更新所有的时间因为源文件时间修改了,所以可以重新编译。

4-5 适度扩展语法
bash
1 mycode:mycode.c
2 # gcc -o mycode mycode.c
3 gcc -o $@ $^ # $@:代表目标文件名。 $^: 代表依赖文件列表
4
5 .PHONY:clean
6 clean:
7 @rm -f mycode # @:不回显命令 第五章:Linux第一个系统程序−进度条
5-1 补充 - 回车与换行
回车概念 \r 作用:将光标移动到当前行的行首(最左侧),不换到下一行。
换行概念 \n 作用:将光标移动到下一行的同一列位置(仅垂直下移一行,不改变水平位置)。
5-2 行缓冲区概念
cpp
#include <stdio.h>
int main() {
printf("hello Makefile!\n");
sleep(3);
return 0;
}什么现象?立即输出hello Makefile! 并休眠3秒。stdout 默认是行缓冲的。输出到终端(控制台)时,标准输出使用行缓冲模式。遇到 \n(换行符)时,缓冲区会自动刷新。
cpp
#include <stdio.h>
int main() {
printf("hello bite!");
sleep(3);
return 0;
}什么现象??休眠3秒,输出hello bite!
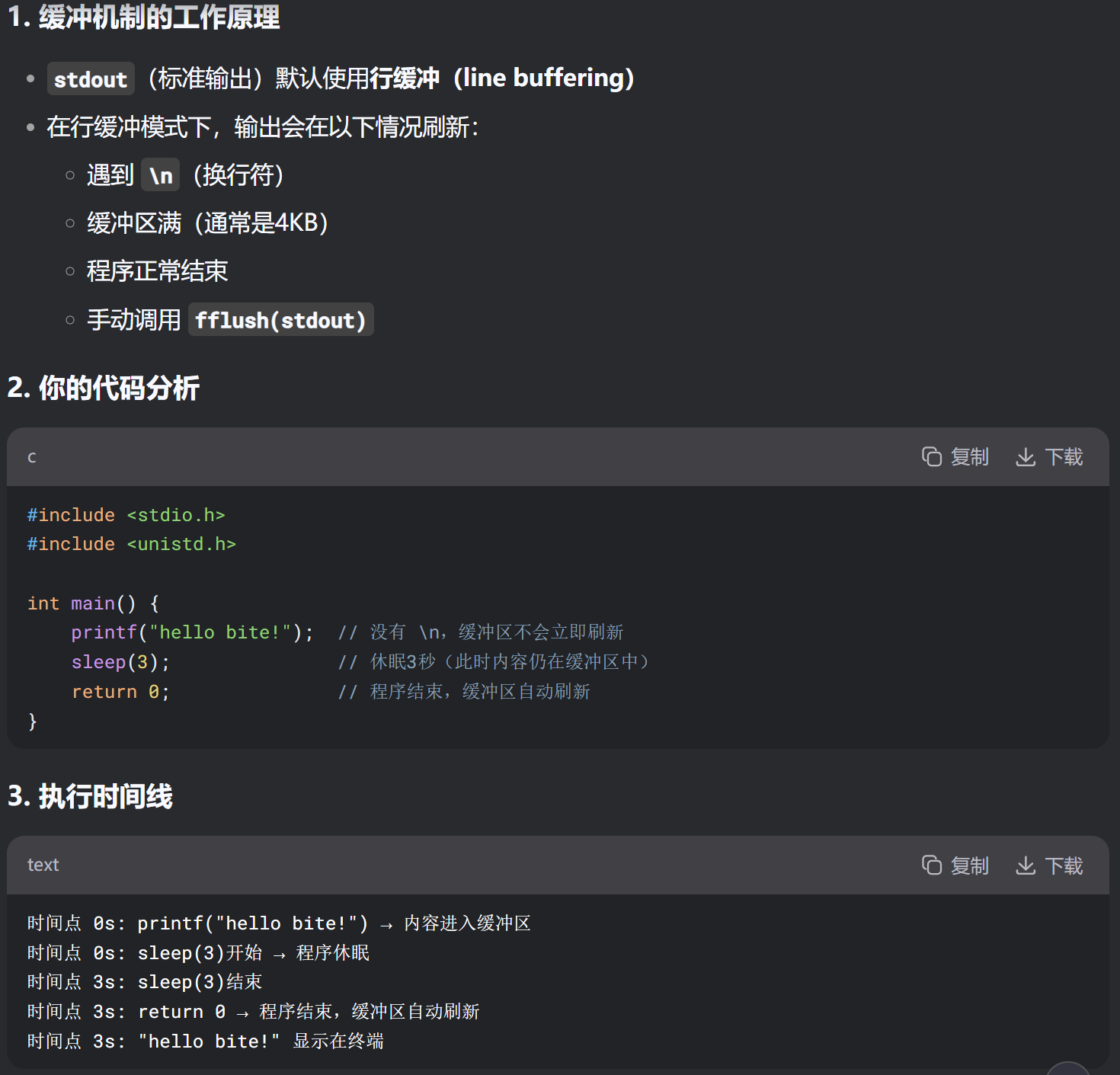
cpp
#include <stdio.h>
int main() {
printf("hello bite!");
fflush(stdout);
sleep(3);
return 0;
}什么现象?立即输出hello bite! 休眠3秒。因为手动调用fflush(stdout)
5-3 练手 - 倒计时程序
cpp
#include "processBar.h"
#include <unistd.h>
int main() {
int cnt = 10;
while (cnt >= 0) {
//printf("%d\r", cnt);//只能覆盖1个字符。倒计时变为10 90 80...
printf("%-2d\r", cnt);//改为覆盖2个字符且左对齐。\r是为了回到当前行的开始,就是为了覆盖
fflush(stdout);//立即刷新输出缓冲区,强制将缓冲区中的内容输出到终端
cnt--;
sleep(1);
}
printf("\n");
return 0;
}5-4 进度条代码
processBar.h
cpp
#pragma once
#include <stdio.h>
#define NUM 102
#define TOP 100
#define BODY '='
#define RIGHT '>'
extern void processbar(int rate);
extern void initbar();processBar.c
cpp
#include "processBar.h"
#include <string.h>
#include <unistd.h>
//版本二:如何被调用
const char* lable = "|/-\\";
char bar[NUM];
#define GREEN "\033[0;32;32m"
#define NONE "\033[m"
#define RED "\033[0;32;31m"
void processbar(int rate) {
if (rate < 0 || rate > 100) return;
int len = strlen(lable);
printf(GREEN"[%-100s]" NONE RED"[%d%%][%c]\r" NONE, bar, rate, lable[rate % len]);
fflush(stdout);
bar[rate++] = BODY;
if (rate < TOP) bar[rate] = RIGHT;
}
void initbar() {
memset(bar, '\0', sizeof(bar));
}
//版本一
const char* lable = "|/-\\";
void processbar(int speed) {
char bar[NUM];
memset(bar, '\0', sizeof(bar));
int len = strlen(lable);
int cnt = 0;
while (cnt <= TOP) { //循环101次,打印100个#,第一次打印空字符串
printf("[%-100s][%d%%][%c]\r", bar, cnt, lable[cnt % len]);
// [%-100s] - 进度条显示部分:左对齐,固定宽度为100个字符输出bar数组。显示效果:[########### ]
// [%d%%] - 百分比显示部分:显示百分号%(需要转义)。显示效果:[50%]
// [%c] - 旋转指示器部分:cnt % len:取模运算实现循环(0,1,2,3,0,1,2,3...)。显示效果:[|]、[/]、[-]、[\] 循 环变化。
// \r - 回车符(关键!):将光标移回行首,实现原地刷新。配合fflush(stdout)强制刷新输出缓冲区。
bar[cnt++] = BODY;
if (cnt < TOP) bar[cnt] = RIGHT;
fflush(stdout);//没有\n就没有立即刷新,因为显示器模式是行刷新
usleep(speed);
}
printf("\n");
}main.c
cpp
#include "processBar.h"
#include <unistd.h>
typedef void (*callback_t)(int);
void downLoad(callback_t cb) {
int total = 1000;
int cur = 0;
while (cur <= total) {
usleep(20000);//模拟下载花费时间
int rate = cur * 100 / 1000;//当前进度
cb(rate);//通过回调,展示进度
cur += 10;//进度更新
}
printf("\n");
}
int main() {
printf("download 1: \n");
downLoad(processbar);
//每次开始新进度条前初始化bar字符数组为空
initbar();
printf("download 2: \n");
downLoad(processbar);
initbar();
printf("download 3: \n");
downLoad(processbar);
initbar();
return 0;
}makefile
bash
processbar:processBar.c main.c
@gcc - o $@ $ ^ # $@:代表目标文件名。 $ ^ : 代表依赖文件列表
.PHONY : clean
clean :
@rm - f processbar
第六章:版本控制器Git
我们在编写各种文档时,为了防止文档丢失,更改失误,失误后能恢复到原来的版本,不得不复制出一个副本,比如:
"报告-v1"
"报告-v2"
"报告-v3"
"报告-确定版"
"报告-最终版"
"报告-究极进化版"
每个版本有各自的内容,但最终会只有一份报告需要被我们使用。
但在此之前的工作都需要这些不同版本的报告,于是每次都是复制粘贴副本,产出的文件就越来越多,文件多不是问题,问题是:随着版本数量的不断增多,你还记得这些版本各自都是修改了什么吗?
文档如此,我们写的项目代码,也是存在这个问题的!!
6-1版本控制器
为了能够更方便我们管理这些不同版本的文件,便有了版本控制器。所谓的版本控制器,就是能让你了解到一个文件的历史,以及它的发展过程的系统。通俗的讲就是一个可以记录工程的每一次改动和版本迭代的一个管理系统,同时也方便多人协同作业。
目前最主流的版本控制器就是Git。Git可以控制电脑上所有格式的文件,例如doc、excel、dwg、dgn、rvt等等。对于我们开发人员来说,Git最重要的就是可以帮助我们管理软件开发项目中的源代码文件!
6-2 git 简史
同生活中的许多伟大事物一样,Git诞生于一个极富纷争大举创新的年代。
Linux内核开源项目有着为数众多的参与者。绝大多数的Linux内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。到2002年,整个项目组开始启用一个专有的分布式版本控制系统BitKeeper来管理和维护代码。
到了2005年,开发BitKeeper的商业公司同Linux内核开源社区的合作关系结束,他们收回了Linux内核社区免费使用BitKeeper的权力。这就迫使Linux开源社区(特别是Linux的缔造者LinusTorvalds)基于使用BitKeeper时的经验教训,开发出自己的版本系统。他们对新的系统制订了若干目标:
- 速度
- 简单的设计
- 对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
- 完全分布式
- 有能力高效管理类似Linux内核一样的超大规模项目(速度和数据量)
自诞生于2005年以来,Git日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。它的速度飞快,极其适合管理大项目,有着令人难以置信的非线性分支管理系统。
6-3 安装git
bash
yum install git
$ git --version
git version 1.8.3.16-4 在Github创建项目
注册账号
这个比较简单,参考着官网提示即可.需要进行邮箱校验.
创建项目
- 登陆成功后,进入个人主页,点击左下方的New repository按钮新建项目
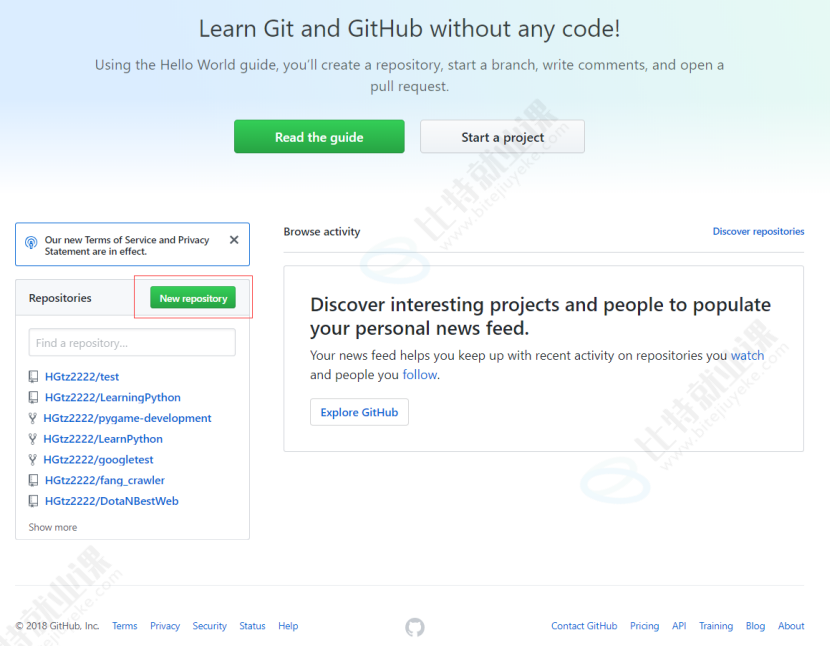
- 然后跳转到的新页面中输入项目名称(注意,名称不能重复,系统会自动校验.校验过程可能会花费几秒钟).校验完毕后,点击下方的Create repository按钮确认创建.
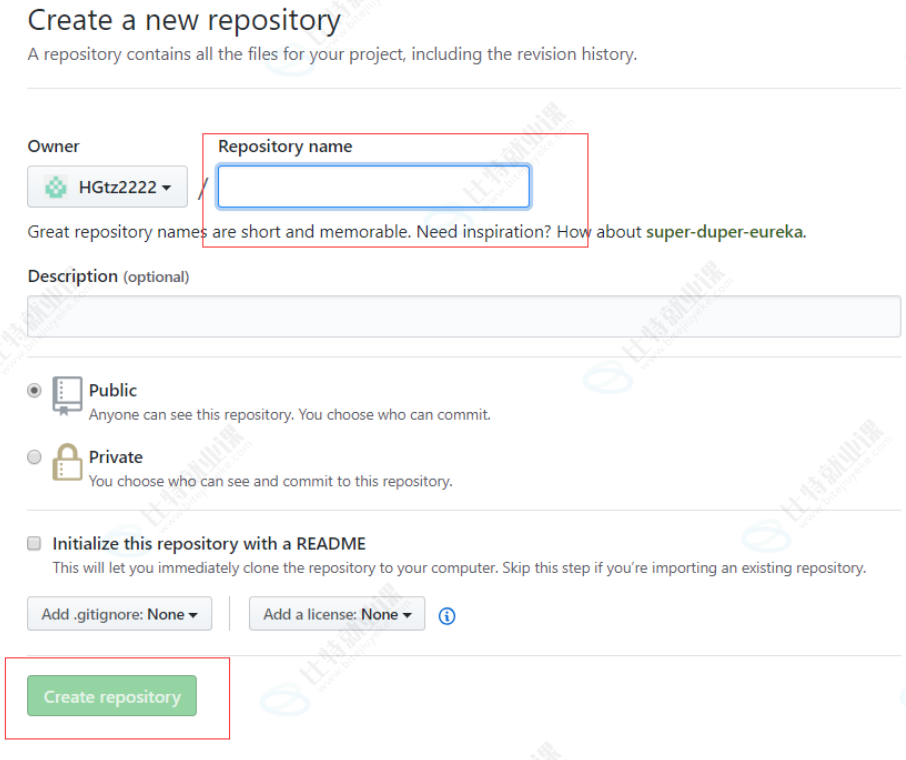
- 在创建好的项目页面中复制项目的链接,以备接下来进行下载.

下载项目到本地
创建好一个放置代码的目录.
bash
git clone [url]这里的 url 就是刚刚建立好的项目的链接.
6-5 三板斧
1. git add
将代码放到刚才下载好的目录中
bash
git add [⽂件名]将需要用git管理的文件告知git
2. git commit
提交改动到本地
bash
git commit -m "XXX"最后的"."表示当前目录
提交的时候应该注明提交日志,描述改动的详细内容.
3. git push
同步到远端服务器上
bash
git push需要填入用户名密码.同步成功后,刷新 Github 页面就能看到代码改动了.
配置免密码提交
https://blog.csdn.net/camillezj/article/details/55103149
4. 其他
git log/status/pull
.ignore
首次使用问题,需要现场看
第七章:调试器-gdb/cgdb 使用
7-1 样例代码
cpp
#include <stdio.h>
int Sum(int s, int e) {
int result = 0;
for (int i = s; i <= e; i++) {
result += i;
}
return result;
}
int main() {
int start = 1;
int end = 100;
printf("I will begin\n");
int n = Sum(start, end);
printf("running done, result is: [%d-%d]=%d\n", start, end, n);
return 0;
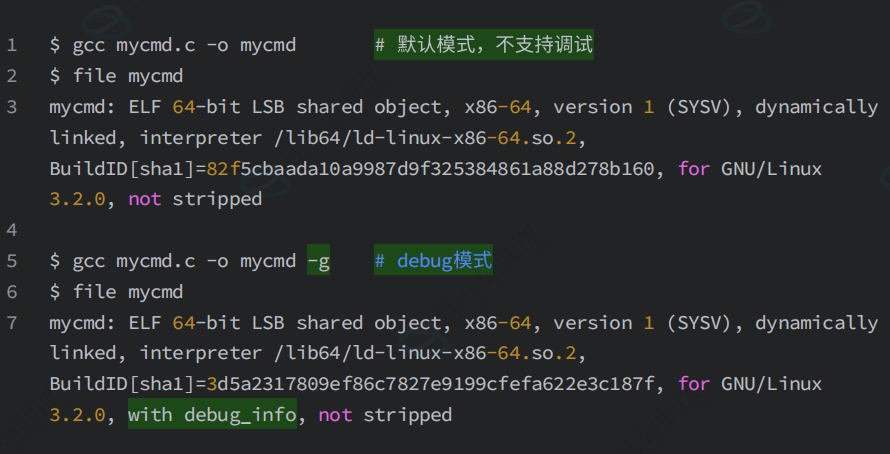
}7-2 预备
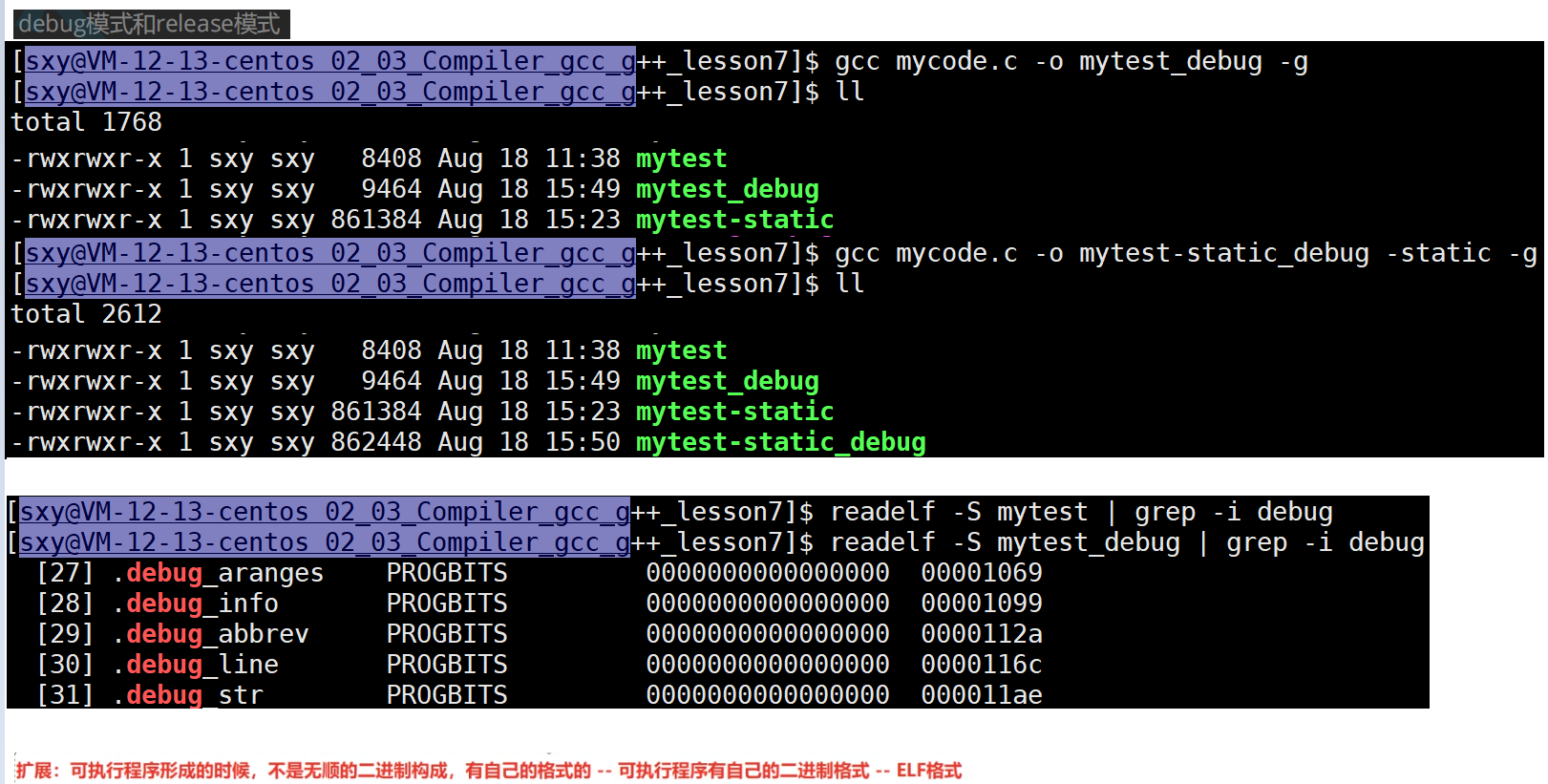
程序的发布方式有两种,debug 模式和release模式,Linux gcc/g++ 出来的二进制程序,默认是release模式。
要使用gdb调试,必须在源代码生成二进制程序的时候,加上-g 选项,如果没有添加,程序无法被编译。
7-3 常见使用
开始: gdb binFile
退出: ctrl + d 或 quit 调试命令

7-4 常见技巧-加餐
安装cgdb:
上面的基本调试还是麻烦,虽然是黑屏,但是还是想看到代码调试
推荐安装cgdb:
Ubuntu: sudo apt-get install -y cgdb
Centos: sudo yum install -y cgdb
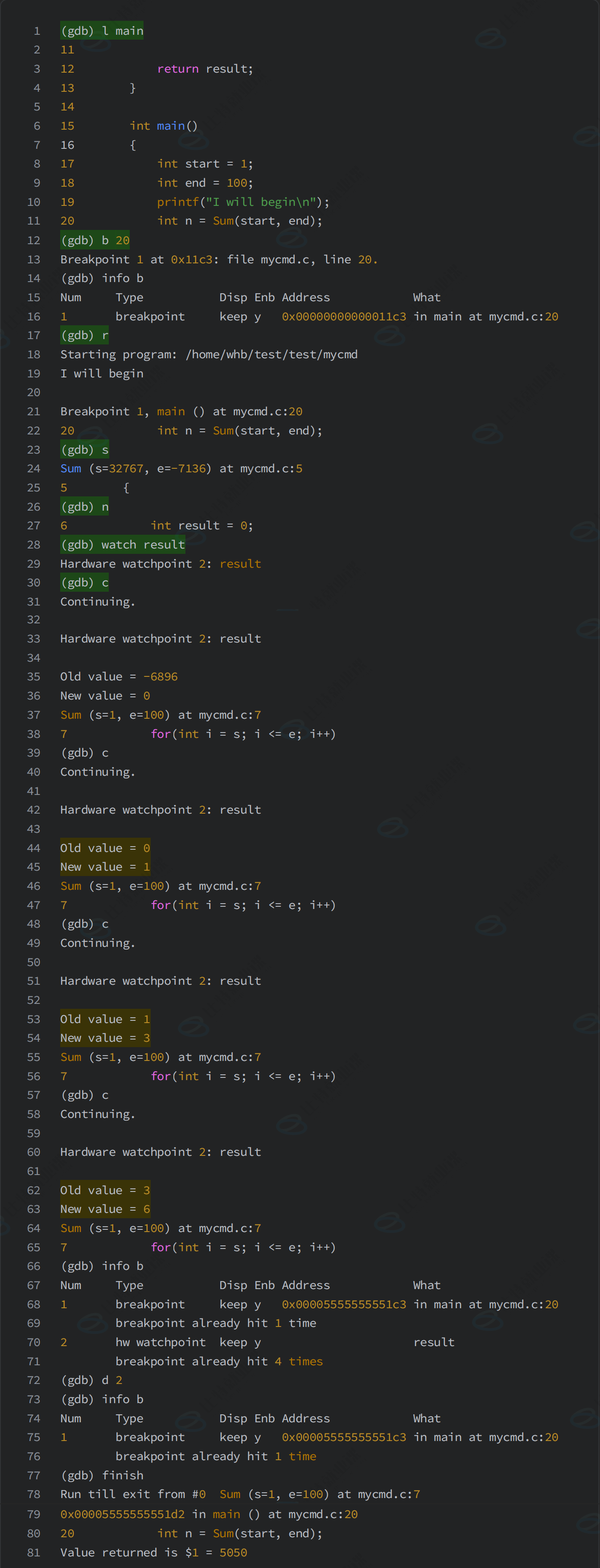
7-4-1 watch
执行时监视一个表达式(如变量)的值。如果监视的表达式在程序运行期间的值发生变化,GDB 会暂停程序的执行,并通知使用者
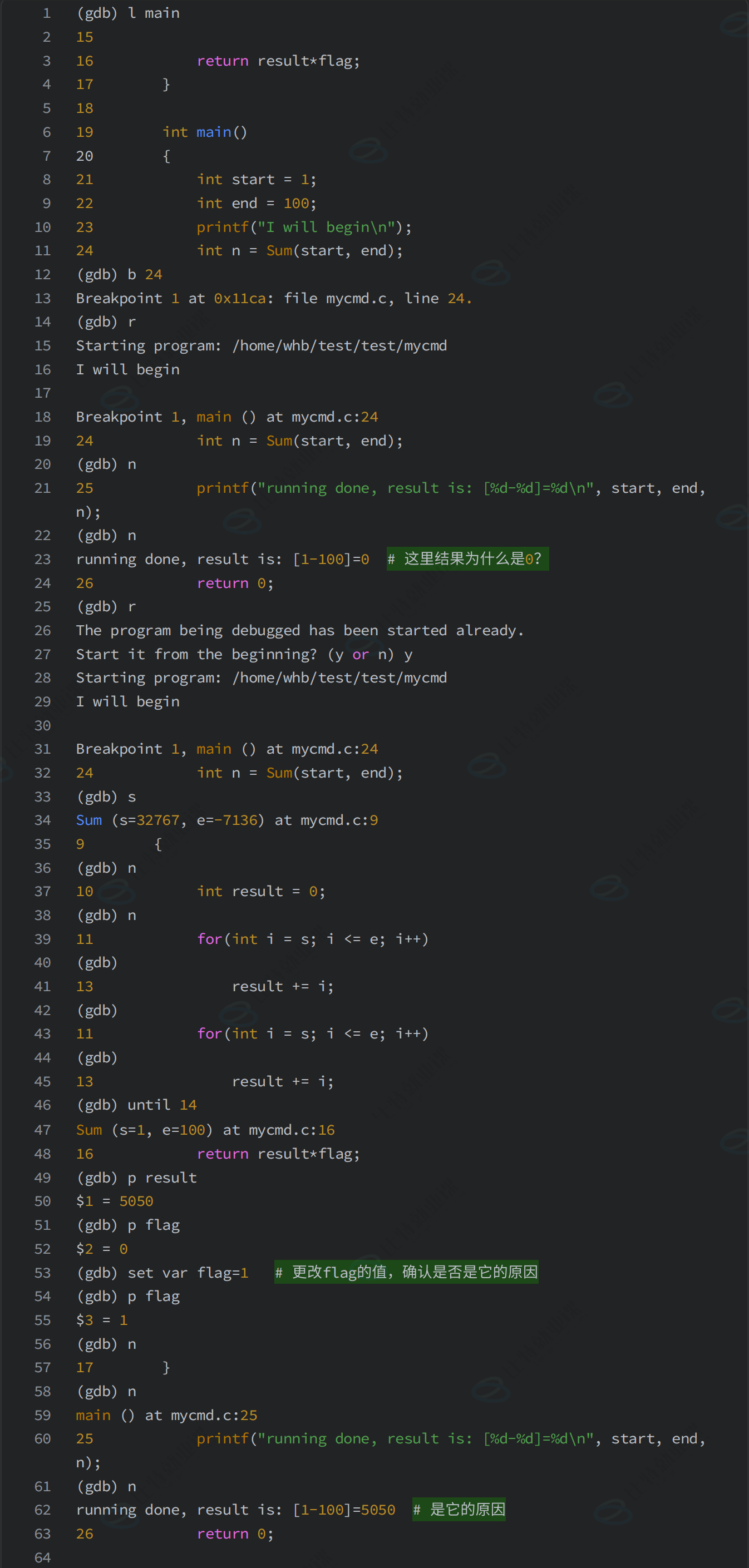
7-4-2 set var确定问题原因
更改一下标志位,假设我们想得到 +-result
cpp
// mycmd.c
#include <stdio.h>
int flag = 0; // 故意错误
//int flag = -1;
//int flag = 1;
int Sum(int s, int e) {
int result = 0;
for (int i = s; i <= e; i++) {
result += i;
}
return result * flag;
}
int main() {
int start = 1;
int end = 100;
printf("I will begin\n");
int n = Sum(start, end);
printf("running done, result is: [%d-%d]=%d\n", start, end, n);
return 0;
}
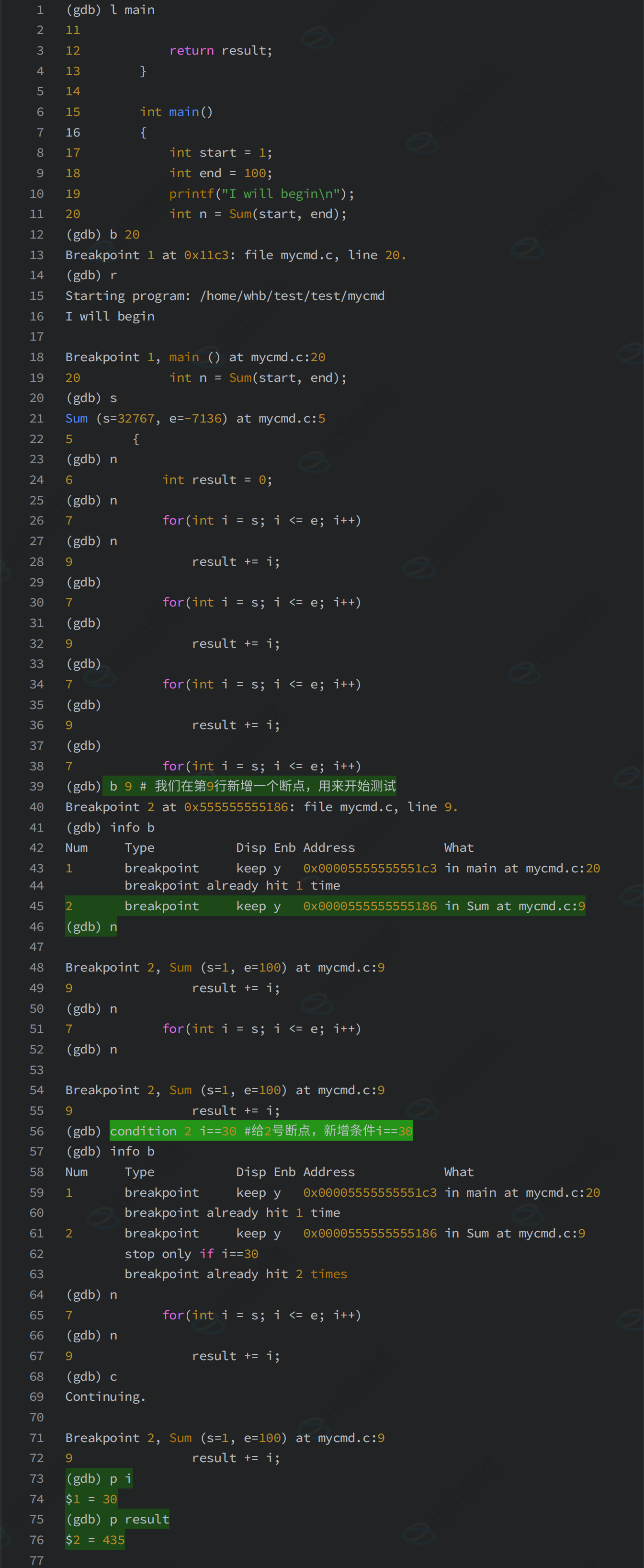
7-4-3 条件断点
7-4-3-1 添加条件断点
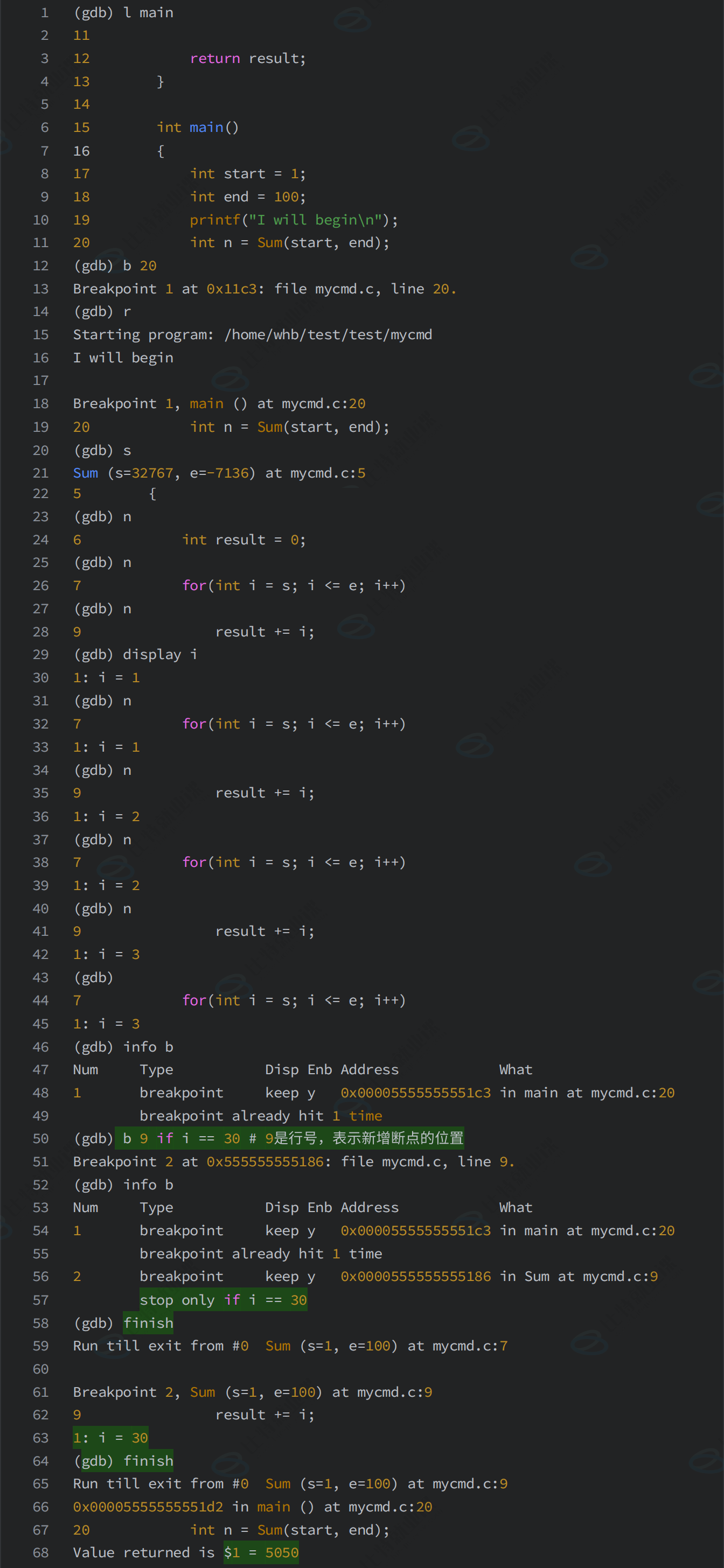
7-4-3-2 给已经存在的断点新增条件
作业
1. 以下命令正确的是:
A.yum makecache命令的功能是将服务器的软件包信息缓存到本地
B.yum search命令可以在所有软件包中搜索包含有指定关键字的软件包
C.yum clean all 命令可以清除缓存中老旧的头文件和软件包
D.yum upgrade命令可以更新所有的rpm软件包
答案:ABC
yum工具在每次安装指定软件包的时候,都会检测源服务器上的软件包信息,为了便捷不用每次都去搜索软件包信息,因此使用 yum makecache将软件包信息缓存到本地,使用 yum clean all 清理老旧的缓存信息。因此A和C是正确的
yum search 用于在搜索包含有指定关键字的软件包,B也是正确的
D选项:
yum -y update:升级所有包同时,也升级软件和系统内核;
yum -y upgrade:只升级所有包,不升级软件和系统内核,软件和内核保持原样。 所以D选项不完整严谨
2. 以下描述正确的是
A.在Centos中可以使用yum install 命令安装软件包
B.在Centos中可以使用yum uninstall 命令卸载软件包
C.在Centos中可以使用yum list 查看所有可安装软件包
D.在Centos中可以使用yum show查看所有可安装软件包
答案:AC
yum工具的常用选项有:
install 表示安装软件包
list 列出所有可供安装的软件包
search 搜索包含指定关键字的软件包
remove 卸载指定的软件包
根据常用操作的选项可排除出B和D是错误的。yum不具备这两个操作选项
3. 你使用命令"vi/etc/inittab"查看该文件的内容,你不小心改动了一些内容,为了防止系统出为,你不想保存所修改的内容,你应该如何操作
A.在末行模式下,键入:wq
B.在末行模式下,键入:q!
C.在末行模式下,键入:x!
D.在编辑模式下,键入"ESC"键直接退出vi
答案:B
A. 在末行模式下,键入 : wq 保存并退出编辑,就算没有修改也会写入,并修改文件时间属性
B. 在末行模式下,键入 : q!强制退出编辑,但并不保存当前修改
C. 在末行模式下,键入 : x!保存并退出编辑,仅当文件有修改时会保存,并修改文件时间属性
D. 在编辑模式下,键入"ESC"键并非直接退出vi编辑,而是用于返回普通模式
根据题意,想要退出编辑,但是又不想保存修改,因此选择B选项。
4. vi编辑器中,删除一行的命令是?
A.rm
B.dd
C.yy
D.pp
答案:B
A. rm没有这个指令
B. dd删除光标所在行内容
C. yy复制光标所在行内容
D. pp没有这个指令
5. Vi编辑器中,怎样将字符AAA全部替换成yyy?
A.p/AAA/yyy/
B.s/AAA/yyy/g
C.i/AAA/yyy/
D.p/AAA/yyy/h
答案:B
在vim的底行模式中,
:s 表示substitute,也就是替换, 格式为以下
: range substitute / {pattern} / {string} / flagscount
range 表示区间 % 用于表示全文, 2, 3 表示从第2行开始到第3行
{ pattern } 表示字符串匹配规则,要匹配什么样的字符串 , 比如 ^ a 表示以a字符起始的字符串
{ string } 表示要将匹配到的字符串替换为的新的string字符串
flags s_flags中,g比较常用,通常使用g表示全部替换,默认如果不给的话,表示只替换一次
count 表示在一行中匹配多少次,很少会用到....
如果想要将文件中所有 nihao 替换为 hello 则命令为: % s / nihao / hello / g
:p 用于打印指定区间的行
: range printflags
: i 在指定行上方添加文本
: {range}insert!
根据这些选项能够确定B选项正确,其他错误。
6. 在编译过程中,产生parse tree的过程是哪个阶段?
A.语法分析
B.语义分析阶段
C.词法分析
D.目标代码生成阶段
答案:A
- 编译过程为 扫描程序-->语法分析-->语义分析-->源代码优化-->代码生成器-->目标代码优化;
- 扫描程序进行词法分析,从左向右,从上往下扫描源程序字符,识别出各个单词,确定单词类型
- 语法分析是根据语法规则,将输入的语句构建出分析树,或者语法树,也就是我们答案中提到的分析树parse tree或者语法树syntax tree
- 语义分析是根据上下文分析函数返回值类型是否对应这种语义检测,可以理解语法分析就是描述一个句子主宾谓是否符合规则,而语义用于检测句子的意思是否是正确的
- 目标代码生成指的是,把中间代码变换成为特定机器上的低级语言代码。
- 根据以上各个阶段的理解,可以分析出正确选项为A选项。
7. 程序的完整编译过程分为是:预处理,编译,汇编等,如下关于编译阶段的编译优化的说法中不正确的是
A.死代码删除指的是编译过程直接抛弃掉被注释的代码
B.函数内联可以避免函数调用中压栈和退栈的开销
C.for循环的循环控制变量通常很适合调度到寄存器访问
D.强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令
答案:A
- 死代码删除是编译最优化技术,指的是移除根本执行不到的代码,或者对程序运行结果没有影响的代码,而并不是删除被注释的代码,因此A选项错误
- 内联函数,也叫编译时期展开函数, 指的是建议编译器将内联函数体插入并取代每一处调用函数的地方,从而节省函数调用带来的成本,使用方式类似于宏,但是与宏不同的是内联函数拥有参数类型的校验,以及调试信息,而宏只是文本替换而已。因此B选项正确
- for循环的循环控制变量,通常被cpu访问频繁,因此如果调度到寄存器中进行访问则不用每次从内存中取出数据,可以提高访问效率,因此C选项正确
- 强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令,比如 num % 128 与 num & 127 相较,则明显&127更加轻量, 故D也是正确的
8. 将一个test.c文件仅仅进行汇编而不生成可执行程序的命令是?
A.gcc -S test.c
B.gcc -E test.c
C.gcc -c test.c
D.gcc test.c
答案:C
gcc常见选项:
-
c 汇编完成后停止,不进行链接
-
E 预处理完成后停止,不进行编译
-
S 编译完成后停止,不进行汇编
-
o 用于指定目标文件名称
-
g 生成debug程序。向程序中添加调试符号信息
题目要求为仅执行到汇编就结束,而不生成可执行程序,因此选择C选项。
9. 以下哪项命令可以完成, 在gdb调试中,查看断点信息的功能( )
B.show break
C.set scheduler-locking off
D.info break
答案:D
A. bt 查看函数调用栈
B. show break info break 用于查看断点信息
C. set scheduler - locking off 用于后期多线程调试,关闭调度锁(所有线程同步执行)
D. info break 查看断点信息
根据各个指令功能,分析正确答案为D选项
10. 若基于Linux操作系统所开发的源文件名为test.c,生成该程序代码的调试信息,编译时使用的GCC命令正确的是?
A.gcc -c -o test.o test.c
B.gcc -S -o test.o test.c
C.gcc -o test test.c
D.gcc -g -o test test.c
答案:D
gcc常见选项:
-
c 汇编完成后停止,不进行链接
-
E 预处理完成后停止,不进行编译
-
S 编译完成后停止,不进行汇编
-
o 用于指定目标文件名称
-
g 生成debug程序。向程序中添加调试符号信息
根据各个选项作用分析,得到正确答案为D,使用 - g选项生成包含有调试信息的可执行程序
11. 下列关于make/Makefile描述正确的有?
A.make会生成Makefile中定义的所有目标对象
B.make会自动根据依赖对象检测目标对象是否需要重新生成
C.Makefile中伪对象的功能是目标对象存在则不需要生成
D.Makefile中声明伪对象使用 .PHONY
答案:BD
- make的执行规则是,只生成所有目标对象中的第一个,当然make会根据语法规则,递归生成第一个目标对象的所有依赖对象后再回头生成第一个目标对象,生成后退出。因此A选项错误。
- make在执行makefile规则中,根据语法规则,会分析目标对象与依赖对象的时间信息,判断是否在上一次生成后,源文件发生了修改,若发生了修改才需要重新生成。因此B选项正确
- makefile中的伪对象表示对象名称并不代表真正的文件名,与实际存在的同名文件没有相互关系,因此伪对象不管同名目标文件是否存在都会执行对应的生成指令。伪对象的作用有两个,1. 使目标对象无论如何都要重新生成。2. 并不生成目标文件,而是为了执行一些指令。 根据对伪对象的理解,C选项错误
- makefile中使用 .PHONY 来声明伪对象, .PHONY: clean。 D选项正确
根据makefile的理解,可以分析出 B D选项正确
12. 下列关于makefile描述正确的有?
A.makefile文件保存了编译器和连接器的参数选项
B.主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释
C.默认的情况下,make命令会在当前目录下按顺序找寻文件名为"GNUmakefile"、"makefile"、"Makefile"的文件, 找到了解释这个文件
D.在Makefile不可以使用include关键字把别的Makefile包含进来
答案:ABC
-
makefile文件中,保存了编译器和链接器的参数选项,并且描述了所有源文件之间的关系。make程序会读取makefile文件中的数据,然后根据规则调用编译器,汇编器,链接器产生最后的输出。根据makefile的功能理解,A选项是正确的
-
Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释, B选项是正确的
- 显式规则说明了,如何生成一个或多个目标文件。
- make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写makefile,比如源文件与目标文件之间的时间关系判断之类
- 在makefile中可以定义变量,当makefile被执行时,其中的变量都会被扩展到相应的引用位置上,通常使用 $(var) 表示引用变量
- 文件指示。包含在一个makefile中引用另一个makefile,类似C语言中的include; 根据这一项可以推导D选项是错误的。
- 注释,makefile中可以使用 # 在行首表示行注释
-
默认的情况下,make命令会在当前目录下按顺序找寻文件名为"GNUmakefile"、"makefile"、"Makefile"的文件,C选项也正确
-
根据以上对makefile的理解,可以分析出正确的选项包含:A B C