作者:来自 Elastic Jessica Garson
使用 Ragas 指标和 Elasticsearch 评估 RAG 解决方案的质量。
想要获得 Elastic 认证吗?来看看下一次 Elasticsearch 工程师培训什么时候开始吧!
Elasticsearch 拥有大量新功能,可以帮助你根据使用场景构建最佳搜索解决方案。深入学习我们的示例笔记本,了解更多信息,开启免费的云试用,或者现在就在本地机器上尝试 Elastic。
Ragas 是一个评估框架,可以让你更深入地了解 LLM 应用的运行情况。它提供既定的指标和评分,用于对 LLM 应用的整体性能进行量化分析。像 Ragas 这样的评估框架能够揭示 LLM 系统中的问题,并提供标准化指标来指导改进,定位潜在问题所在。
使用像 Ragas 这样的框架非常有帮助,因为它可以减少使用 LLM 系统时的猜测性工作,使你能够衡量和改进过去的性能。它可以帮助你了解应用是否在某些方面容易产生幻觉,应用是否生成了合适的答案,或者检索是否拉取了不相关的信息。
这篇博客文章将带你通过一个示例,使用 Ragas 指标和 Elasticsearch 来评估一个检索增强生成(RAG)解决方案的质量。你可以在 GitHub 上找到完整代码和相关资源。
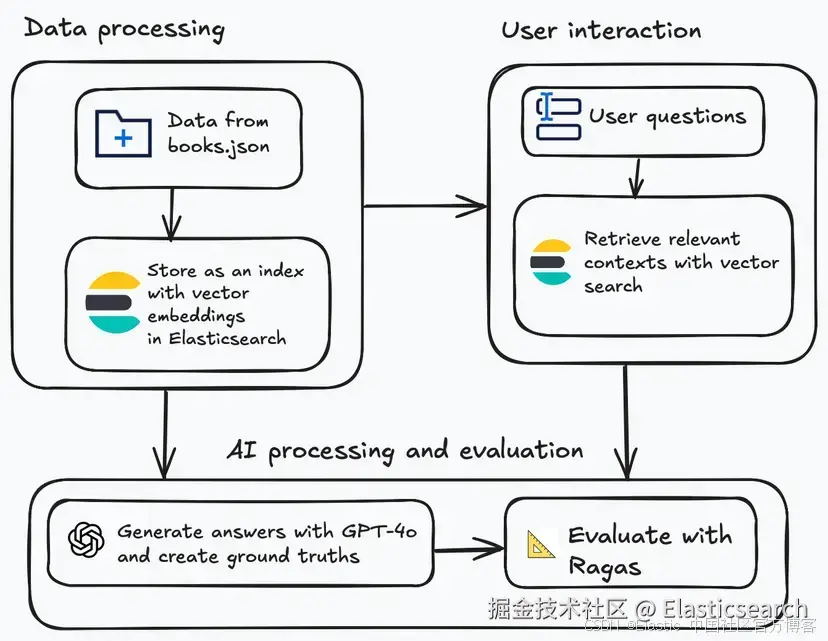
本文讨论的解决方案首先将一个 JSON 文件中的数据集上传到 Elasticsearch。所用的数据集是 books.json,它是来自 Goodreads 的 25 本书的子集,包括书名、作者姓名、书籍描述、出版年份和 Goodreads 链接。
在书籍数据加载完成后,下一步是在 Elasticsearch 中存储带有向量嵌入的索引。然后你可以创建评估问题,并使用这些问题通过向量搜索(vector search)检索相关上下文。
一旦为每个问题检索到上下文,你就可以生成答案和基准答案。基准答案本质上是理想答案。使用 GPT-4o,你可以基于检索到的上下文生成答案,而一个单独的函数会生成基准答案,应用评分逻辑对检索结果中最相关的书籍进行排序和选择,生成推荐,用作评估基准。基本上就是尝试弄清楚你真正寻找的内容,找到最匹配的响应,并向你解释原因。
最后,你将通过使用 Ragas 指标将生成的答案与基准答案进行比较,并查看结果来评估性能。
前提条件:
-
使用的 Python 版本是 Python 3.12.1,但你可以使用任何高于 3.10 的 Python 版本。
-
本示例使用的 Elasticsearch 版本是 9.0.3,但你可以使用任何高于 8.10 的 Elasticsearch 版本。
-
你需要一个 OpenAI API Key,可以在 OpenAI 开发者门户的 API keys 页面找到。
-
你还需要具备向量数据库和 RAG 的基础知识。如果你还不熟悉 Elastic 中的向量搜索概念,可以先查看以下资源:
指标
本示例中使用的指标是 context precision 、faithfulness 和 context recall。
-
Context precision 指生成答案与实际问题或主题的相关性,衡量答案中使用的检索上下文中有多少是真正与回答问题相关的。
-
Faithfulness 用于判断 LLM 是否出现幻觉,表示生成答案的准确性。
-
Context recall 衡量成功检索到的相关文档数量,重点在于不遗漏重要结果。
-
对于 context_precision ,高分意味着生成的答案能在上下文中找到。Faithfulness 得分高意味着生成的答案准确并与参考一致。Context_recall 得分高意味着生成的答案使用了全部或大部分相关上下文。
选择这三个指标的原因是它们可以为检索器和生成器的性能提供可操作的信号。它们能让你判断 RAG 系统是否检索到了正确的信息,是否回答了检索到的内容,以及答案是否正确或有支撑。
这只是 Ragas 提供的部分指标,你可以在 Ragas 文档中了解更多可用指标。
环境设置
首先你需要安装此应用所需的依赖包,包括:
-
Elasticsearch Python client------ 用于连接和认证 Elasticsearch,并执行向量搜索
-
Ragas ------ 用于通过标准指标评估 LLM 应用的质量
-
Hugging Face library datasets ------ 用于创建健壮的评估数据集
-
Langchain-OpenAI ------ 用于生成用户问题的答案和评估
css
`!pip install -q elasticsearch ragas datasets langchain-openai`AI写代码在安装完所需包之后,你现在可以导入以下模块:
-
os:用于设置环境变量和其他相关任务
-
json:用于解析包含书籍的 JSON 文件
-
getpass:用于传递 API keys 和 tokens 等敏感值
-
Elasticsearch Python client:用于连接 Elasticsearch
-
ragas:用于评估
-
ragas.metrics :用于评估 RAG 应用的指标
-
datasets:用于创建评估数据集
-
langchain_openai:用于模型对话功能
python
`
1. import os
2. import json
3. from getpass import getpass
4. from elasticsearch import Elasticsearch
5. from ragas import evaluate
6. from ragas.metrics import faithfulness, context_recall, context_precision
7. from datasets import Dataset
8. from langchain_openai import ChatOpenAI
`AI写代码创建 Elasticsearch 索引和向量搜索
现在,你需要创建一个名为 es 的变量,在其中传入你的 Elasticsearch 主机地址和 Elasticsearch API key。
ini
`
1. es = Elasticsearch(
2. getpass("Host: "),
3. api_key=getpass("API Key: "),
4. )
`AI写代码你还需要创建一个名为 index_name 的变量,可以设置为任意你想给索引起的名字。在这个示例中,你可以将索引命名为 ragas-books。
ini
`index_name = "ragas-books"`AI写代码为了给数据集添加向量嵌入,你需要创建一个函数,将查询字符串转换为向量,使用的 Elastic 机器学习模型是 .multilingual-e5-small-x86_64 。请务必查看我们关于 E5 模型的文档以了解更多信息。如果遇到问题,你可能需要先部署该模型,代码才能正常运行。
ini
`
1. def embed_query(text: str):
3. res = es.ml.infer_trained_model(
4. model_id=".multilingual-e5-small_linux-x86_64",
5. body={"docs": [{"text_field": f"query: {text}"}]}
6. )
8. vec = res["inference_results"][0]["predicted_value"]
10. return vec
`AI写代码现在,你应该检查是否存在同名索引。如果存在,则删除旧索引。之后,你可以使用适当的映射创建一个新索引。由于使用的数据集是来自 Goodreads 的书籍片段,映射将与该示例的标题匹配。
bash
`
1. if es.indices.exists(index=index_name):
2. es.indices.delete(index=index_name)
3. print(f"Deleted existing index '{index_name}'")
5. es.indices.create(index=index_name, body={
6. "mappings": {
7. "properties": {
8. "book_title": {"type": "text"},
9. "author_name": {"type": "text"},
10. "book_description": {"type": "text"},
11. "rating_score": {"type": "float"},
12. "embedding": {
13. "type": "dense_vector",
14. "dims": 384,
15. "index": True,
16. "similarity": "cosine"
17. }
18. }
19. }
20. })
21. print(f"Created index '{index_name}'")
`AI写代码此时,你需要从 books.json 文件中提取数据,循环处理每条记录,为书籍描述生成嵌入,并将其加载到 Elasticsearch 索引中。由于原始数据集包含书名、作者姓名、书籍描述、出版年份和 Goodreads 链接,书籍描述是生成嵌入的最佳选择,因为它包含超越关键词的语义信息。你可以查看这篇 LinkedIn 帖子,了解哪些字段适合语义搜索(semantic search)。
虽然可以从多个字段(如书名和描述)生成嵌入,但仅使用描述的方法更简单,避免了来自较短字段如书名的噪声。这种方法有一个权衡:可能会错过一些特定于书名的匹配。
python
`
1. with open("books.json") as f:
2. books = json.load(f)
4. for i, book in enumerate(books, 1):
5. try:
6. book["embedding"] = embed_query(book["book_description"])
7. es.index(index=index_name, document=book)
8. print(f"Indexed {i}: {book['book_title']}")
9. except Exception as e:
10. print(f"Failed to index '{book.get('book_title', 'Unknown')}': {e}")
`AI写代码现在数据已加载到 Elasticsearch,你可以创建一个名为 vector_search 的函数来执行 k 最近邻(KNN)搜索。top_k 值选择为 3,因为这是从 Elasticsearch 为每个问题检索的最近邻上下文块数量。这个值通常足够小以保持上下文相关,同时也足够大,为模型提供多个选项,避免因检索错误而遗漏信息。如果你发现 RAG 应用的结果不准确,可以调整 top_k 值。要了解选择 K 值的更多信息,请查看我们关于该主题的博客文章。
该函数首先使用 embed_query 函数为输入查询生成嵌入。它在指定索引上执行搜索,返回结果,并根据书名创建上下文。最后,它返回 RAG 使用的文本上下文和书籍的元数据。
css
`
1. def vector_search(query, top_k=3):
3. query_vector = embed_query(query)
5. body = {
6. "knn": {
7. "field": "embedding",
8. "k": top_k,
9. "num_candidates": 100,
10. "query_vector": query_vector
11. },
12. "_source": ["book_title", "author_name", "book_description", "rating_score"]
13. }
15. res = es.search(index=index_name, body=body)
16. hits = res["hits"]["hits"]
17. contexts, books_info = [], []
19. for hit in hits:
20. book = hit["_source"]
21. context = f"{book['book_title']} by {book['author_name']}: {book['book_description']}"
22. contexts.append(context)
23. books_info.append(book)
25. return contexts, books_info
`AI写代码实现 RAG 生成组件
此时,你需要检查是否为 OpenAI API Key 设置了环境变量,如果没有,可以使用 getpass 来设置一个。
获取 OpenAI API Key 后,你可以创建一个名为 chat_llm 的变量,用于 RAG。该变量调用 ChatOpenAI ,传入你要使用的模型、控制 LLM 输出随机性/创造性的 temperature (较低值通常更稳妥)以及 OpenAI API Key。虽然本示例使用 gpt-4o ,你也可以通过调整参数 model="模型名称" 来轻松更换模型。
ini
`
1. if "OPENAI_API_KEY" not in os.environ:
2. os.environ["OPENAI_API_KEY"] = getpass("OPENAI_API_KEY: ")
4. API_KEY = os.environ["OPENAI_API_KEY"]
6. chat_llm = ChatOpenAI(
7. model="gpt-4o",
8. temperature=0.1,
9. api_key=API_KEY
10. )
`AI写代码接下来,你可以创建一个名为 generate_answer 的函数,该函数首先将上下文字符串合并为一个文本块。然后,你可以生成一个提示,指示 LLM 仅使用提供的上下文,并将该提示传递给 LLM 获取响应。之后,需要去掉响应的空白字符。该函数表示 RAG 中的生成过程,在使用 Ragas 评估生成答案质量时起关键作用。
ini
`
1. def generate_answer(question, contexts):
3. context_text = "\n\n".join(contexts)
5. prompt = f"""You are a helpful assistant that recommends books.
6. Use only the information from the context below to answer the question.
7. Do not include any books, authors, or details that are not explicitly present in the context.
9. Repeat the exact book title and author from the context in your answer.
11. Context:
12. {context_text}
14. Question:
15. {question}
17. Answer:"""
18. response = chat_llm.invoke(prompt)
20. return response.content.strip()
`AI写代码在创建表示已知正确答案的基准答案之前,你可以使用一个函数从用户问题中提取意图模式和其他关键属性。函数 analyze_question_intent 旨在识别书籍类型、提取质量偏好,并判断问题是否与特定作者相关。
css
`
1. def analyze_question_intent(question):
2. question_lower = question.lower()
4. intent_patterns = {
5. 'genre_specific': {
6. 'science fiction': ['science fiction', 'sci-fi', 'space', 'future', 'alien', 'technology'],
7. 'fantasy': ['fantasy', 'magic', 'dragon', 'wizard', 'medieval', 'kingdom'],
8. 'mystery': ['mystery', 'detective', 'crime', 'murder', 'investigation', 'thriller'],
9. 'romance': ['romance', 'love', 'relationship', 'romantic'],
10. 'horror': ['horror', 'scary', 'ghost', 'supernatural', 'fear'],
11. 'historical': ['historical', 'history', 'war', 'period', 'ancient'],
12. 'biography': ['biography', 'memoir', 'life story', 'autobiography'],
13. 'non-fiction': ['non-fiction', 'nonfiction', 'factual', 'real', 'educational']
14. },
15. 'quality_indicators': {
16. 'high_rating': ['high rating', 'highly rated', 'best rated', 'top rated', 'excellent'],
17. 'popular': ['popular', 'bestseller', 'well-known', 'famous', 'acclaimed'],
18. 'award_winning': ['award', 'prize', 'winner', 'acclaimed', 'celebrated'],
19. 'classic': ['classic', 'timeless', 'masterpiece', 'legendary'],
20. 'recent': ['recent', 'new', 'latest', 'modern', 'contemporary']
21. },
22. 'author_focus': ['author', 'writer', 'by', 'written by']
23. }
25. detected_genres = []
26. for genre, keywords in intent_patterns['genre_specific'].items():
27. if any(keyword in question_lower for keyword in keywords):
28. detected_genres.append(genre)
30. quality_preferences = []
31. for quality_type, keywords in intent_patterns['quality_indicators'].items():
32. if any(keyword in question_lower for keyword in keywords):
33. quality_preferences.append(quality_type)
35. author_focused = any(keyword in question_lower for keyword in intent_patterns['author_focus'])
37. return {
38. 'genres': detected_genres,
39. 'quality_preferences': quality_preferences,
40. 'author_focused': author_focused,
41. 'question_lower': question_lower,
42. 'genre_keywords': intent_patterns['genre_specific']
43. }
`AI写代码你还需要根据意图数据对书籍与用户查询进行评分。你会得到一个数值评分,分数越高表示匹配度越好,同时会返回解释评分的原因列表,以及书籍的评分和元数据。
scss
`
1. def calculate_book_score(book, intent_data):
2. score = 0
3. reasons = []
5. rating = float(book.get('rating_score', 0))
6. score += rating * 10
8. book_title = book.get('book_title', '').lower()
9. book_desc = book.get('book_description', '').lower()
10. author_name = book.get('author_name', '')
12. for genre in intent_data['genres']:
13. genre_keywords = intent_data['genre_keywords'][genre]
14. if any(keyword in book_desc or keyword in book_title for keyword in genre_keywords):
15. score += 30
16. reasons.append(f"matches {genre} genre")
17. break
19. if 'high_rating' in intent_data['quality_preferences'] and rating >= 4.0:
20. score += 20
21. reasons.append("high rating")
23. if 'popular' in intent_data['quality_preferences'] and len(book_desc) > 200:
24. score += 15
25. reasons.append("comprehensive description suggests popularity")
27. if intent_data['author_focused'] and author_name:
28. score += 10
29. reasons.append("has clear author attribution")
31. stop_words = ['a', 'an', 'the', 'is', 'are', 'what', 'can', 'you', 'me', 'i', 'book', 'books']
32. question_words = [word for word in intent_data['question_lower'].split() if word not in stop_words]
34. desc_matches = sum(1 for word in question_words if word in book_desc)
35. if desc_matches > 0:
36. score += desc_matches * 5
37. reasons.append(f"description matches {desc_matches} key terms")
39. return {
40. 'book': book,
41. 'score': score,
42. 'reasons': reasons,
43. 'rating': rating
44. }
`AI写代码要创建基准答案,你需要首先设置一个回退选项,以防未找到书籍。如果有可用书籍,它会选择排名最高的结果,并根据检测到的意图生成推荐。优先顺序为:先匹配类型,再考虑高评分偏好,然后是受欢迎度偏好,最后是特定作者请求。如果都不适用,则回退到通用推荐。该函数会尽可能优先选择评分较高的书籍,并在第二本书的分数接近最高书籍分数时,将其作为额外建议包含在内。
下面的函数是一个良好的起点,因为它使用检索上下文而非外部知识,应用了业务逻辑(如评分偏好和类型匹配),并生成一致且合理的响应。但手动生成基准答案难以扩展。在生产环境中,你可能希望让基准答案半自动生成并有人类审核,或通过 LLM 生成并进行验证。
ini
`
1. def generate_ground_truth_response(top_books, intent_data):
2. if not top_books:
3. return "No relevant books found."
5. top_book = top_books[0]
6. book = top_book['book']
7. title = book['book_title']
8. author = book['author_name']
9. rating = top_book['rating']
11. detected_genres = intent_data['genres']
12. quality_preferences = intent_data['quality_preferences']
13. author_focused = intent_data['author_focused']
15. if detected_genres:
16. genre = detected_genres[0]
17. if 'high_rating' in quality_preferences or rating >= 4.0:
18. response = f"For a highly-rated {genre} book, I recommend '{title}' by {author} (rating: {rating:.1f})."
19. else:
20. response = f"A good {genre} book from the available options is '{title}' by {author}."
22. elif 'high_rating' in quality_preferences:
23. response = f"Among the highest-rated books available, '{title}' by {author} stands out with a {rating:.1f} rating."
25. elif 'popular' in quality_preferences:
26. response = f"'{title}' by {author} appears to be a popular choice based on the comprehensive information available."
28. elif author_focused:
29. response = f"I recommend '{title}' by the author {author}."
31. else:
32. if rating >= 4.0:
33. response = f"I recommend '{title}' by {author}, which has a strong rating of {rating:.1f}."
34. else:
35. response = f"Based on the available books, '{title}' by {author} would be a good choice."
37. if len(top_books) > 1 and top_books[1]['score'] > top_books[0]['score'] * 0.8:
38. second_book = top_books[1]['book']
39. response += f" You might also consider '{second_book['book_title']}' by {second_book['author_name']}."
41. return response
`AI写代码运行演示
最后,你现在可以运行演示了。这个函数类似于 main 函数,将所有其他函数连接在一起以生成评估。首先,你需要定义一些演示问题来评估 RAG 应用。然后,初始化列表并循环处理每个问题。在循环过程中,你需要使用检索到的上下文生成答案,并使用最佳匹配书籍创建基准答案。接下来,收集用于评估的数据,并创建 Ragas 评估的数据集。一旦创建好评估数据集,你就可以运行评估、打印结果,并将结果保存到 CSV 文件中。
python
`
1. def run_ragas_demo():
2. print("🚀 Demo:\n")
4. demo_questions = [
5. "What's a good science fiction book with high ratings?",
6. "Can you suggest a fantasy book by a popular author?",
7. "What's a highly rated mystery novel?",
8. "Recommend a book with good reviews"
9. ]
11. questions, contexts_list, answers, ground_truths = [], [], [], []
13. for i, question in enumerate(demo_questions, 1):
14. print(f"\n📚 Question {i}: {question}")
16. try:
17. contexts, books_info = vector_search(question, top_k=3)
18. if not contexts:
19. print(f"No contexts found for question {i}")
20. continue
22. answer = generate_answer(question, contexts)
23. print(f"Answer: {answer[:100]}...")
24. ground_truth = create_dynamic_ground_truth(question, books_info)
25. print(f"Ground Truth: {ground_truth}")
26. questions.append(question)
27. contexts_list.append(contexts)
28. answers.append(answer)
29. ground_truths.append(ground_truth)
31. except Exception as e:
32. print(f"Error processing question {i}: {e}")
33. continue
35. if not questions:
36. print("\nNo valid Q&A pairs generated.")
37. return None
39. eval_dataset = Dataset.from_dict({
40. "question": questions,
41. "contexts": contexts_list,
42. "answer": answers,
43. "ground_truth": ground_truths,
44. })
46. print("\n✨ Running Ragas evaluation...")
47. try:
48. result = evaluate(
49. dataset=eval_dataset,
50. metrics=[context_precision, faithfulness, context_recall],
51. llm=chat_llm,
52. embeddings=None
53. )
55. df = result.to_pandas()
57. print("\n✨ Ragas Evaluation Results:")
58. print(df)
60. print("\✨ Averages:")
62. for metric, value in df.mean(numeric_only=True).items():
63. print(f"{metric}: {value:.3f}")
65. df.to_csv("ragas_evaluation.csv", index=False)
66. print("\nResults saved to 'ragas_evaluation.csv'")
67. return result
69. except Exception as e:
70. print(f"Ragas evaluation failed: {e}")
71. return None
`AI写代码最后,我们可以运行演示,并加入一些额外的错误处理。
swift
`
1. try:
2. results = run_ragas_demo()
3. if results:
4. print("\n🎉 Demo completed successfully!")
5. else:
6. print("\nDemo completed with issues.")
8. except Exception as e:
9. print(f"\nError during demo: {e}")
10. import traceback
11. traceback.print_exc()
`AI写代码检查输出
在 LLM 应用中,这些指标的得分高于 0.8 通常表示性能较强,但具体情况可能因数据集、领域和使用场景而异。每个指标的更多信息可以在文档中找到。
在下面的输出中,平均 faithfulness 得分为 0.750,表明大多数答案总体上与检索到的上下文保持一致。Context_recall 平均值为 0.500,显示系统只有一半时间检索到了足够的信息以生成完整答案。同时,context_precision 平均值为 0.625,表明生成内容有相当一部分直接匹配检索到的上下文,但仍有提升空间。
查看每个问题时,问题 0 和问题 3 在 faithfulness 和 context precision 上得分都很高,显示检索与生成之间的一致性。问题 1 的召回率较高,但精确度中等,这意味着可能添加了一些超出检索上下文的细节。问题 2 在精确度和召回率上都得分较低,显示检索存在缺口,生成内容偏离了提供的上下文。
为了改善这些结果,你可以通过尝试不同的嵌入模型、优化分块策略或应用上下文工程来提升检索质量,更好地匹配用户查询。在生成方面,使用更严格的提示和其他提示工程策略有助于减少幻觉,并确保评估基准答案与检索内容紧密对齐,从而获得更准确的评分。
vbnet
`
1. ✨ Ragas Evaluation Results:
2. user_input \
3. 0 What's a good science fiction book with high r...
4. 1 Can you suggest a fantasy book by a popular au...
5. 2 What's a highly rated mystery novel?
6. 3 Recommend a book with good reviews
8. retrieved_contexts \
9. 0 [Light of the Jedi by Charles Soule: Two hundr...
10. 1 [Alien Warrior's Mate by Vi Voxley: He's damn ...
11. 2 [The Island of Doctor Moreau by H.G. Wells: Ra...
12. 3 [The Island of Doctor Moreau by H.G. Wells: Ra...
14. response \
15. 0 "Light of the Jedi" by Charles Soule
16. 1 The Book of Time by Guillaume Prévost
17. 2 "Human Nature" by Jonathan Green
18. 3 "The Island of Doctor Moreau" by H.G. Wells is...
20. reference context_precision \
21. 0 For a highly-rated science fiction book, I rec... 1.0
22. 1 A good fantasy book from the available options... 0.5
23. 2 For a highly-rated mystery book, I recommend '... 0.0
24. 3 Based on the available books, 'The Island of D... 1.0
26. faithfulness context_recall
27. 0 1.0 0.0
28. 1 0.5 1.0
29. 2 0.5 0.0
30. 3 1.0 1.0
31. \✨ Averages:
32. context_precision: 0.625
33. faithfulness: 0.750
34. context_recall: 0.500
36. Results saved to 'ragas_evaluation.csv'
38. 🎉 Demo completed successfully!
`AI写代码使用 Ragas 等评估框架的常见挑战
虽然像 Ragas 这样的评估框架可以作为有用的基线,但它们仅作为指导,设计目的是作为更广泛评估策略的一部分,而非系统质量的最终衡量标准。
评估框架存在一些常见问题,包括:过于简单的基准答案无法呈现全貌、样本量过小,以及 LLM 评估 LLM 时可能出现的循环性问题。
此外,评估结果有时与实际性能存在脱节。在真实用户场景和少见情况下,高评估分的系统可能表现不一致。此类框架可能过度关注特定维度,如事实准确性或相关性,而可能低估其他维度,如用户体验、响应延迟或对模糊查询的处理能力。
为缓解这些挑战,你可以探索 A/B 测试与真实用户、使用人类在环审查或 LLM 作为评判者的集成方式,以减少评估者偏差。
下一步
本文示例是使用 Ragas 的起点。在大规模应用此类解决方案时,还需考虑一些关键事项:
-
每当源数据发生变化时,定期在 Elasticsearch 中重新建立索引
-
使用广泛、现实的评估集来跟踪真实世界性能
-
在生产规模下衡量和优化系统速度及成本,以避免瓶颈或预算问题
结论
使用 Ragas 框架等评估方法可以帮助你判断 LLM 应用是否按预期运行,并提供准确性参考。它可以指导你决定是否切换到其他模型,如果当前模型表现不如预期,并可用于不同模型的并行对比,以评估每个模型在你的使用场景中的表现。
原文:Evaluating your Elasticsearch LLM applications with Ragas - Elasticsearch Labs