(1)Flume概述
Flume是的一个分布式、高可用、高可靠的海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时提供了对数据进行简单处理并写到各种数据接收方的能力 。Flume的设计原理是基于数据流的,能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中 。 Flume能够做到近似实时的推送,并且可以满足数据量是持续且量级很大的情况。比如它可以收集社交网站日志,并将这些数量庞大的日志数据从网站服务器上汇集起来,存储到HDFS或 HBase分布式数据库中。
Flume的应用场景:比如一个电商网站,想从网站访问者中访问一些特定的节点区域来分析消费者的购物意图和行为。为了实现这一点,需要收集到消费者访问的页面以及点击的产品等日志信息,并移交到大数据 Hadoop平台上去分析,可以利用 Flume做到这一点。现在流行的内容推送,比如广告定点投放以及新闻私人定制也是基于这个道理
(2)Flume架构
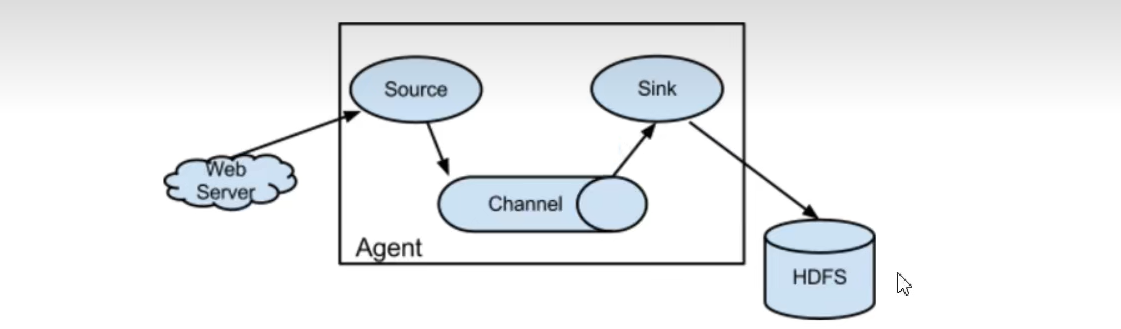
①Agent:Flume的核心角色,Agent 是一个JVM进程,通过三个组件将事件流从一个外部数据源收集并发送给下一个目的地。flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道。Flume的agent有以下三个组件。每一个agent相当于一个数据(被封装成Event对象)的传递员,内部有三个组件:
1 Source:采集组件,用于跟数据源对接,以获取数据;它有各种各样的内置实现;
2 Channel:Channel将从Source处接收到的 Event格式的数据缓存起来,当Sink成功地将 Events发送到下一跳的Channel或最终目的地后, Events从 Channel移除。Channel是一个完整的事务,这一点保证了数据在收发的时候的一致性。可以把 Channel看成一个FIFO(先进先出)队列,当数据的获取速率超过流出速率时,将Event保存到队列中,再从队中一个个出来。
3 Sink:下沉组件,sink从channel中移除事件,并将其发送到下一个agent(简称下一跳)或者事件的最终目的地,比如HDFS

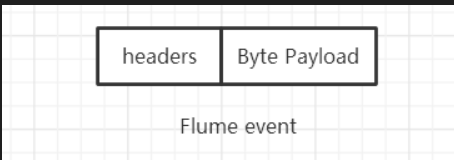
②event:事件是Flume内部数据传输的最基本单元,将传输的数据进行封装。事件本身是由一个载有数据的字节数组和可选的headers头部信息构成,如下图所示 。Flume以事件的形式将数据从源头传输到最终的目的地。
PS:Flume使用事务的办法来保证Events的可靠传递。Source和Sink分别被封装在事务中,事务由保存Event的存储或者Channel提供。这就保证了Event在数据流的点对点传输中是可靠的。在多跳的数据流中,上一跳的sink和下一跳的source均运行事务来保证数据被安全地存储到下一跳的channel中
(3)Flume使用案例
①监听Netcat
使用Flume监听某个端口,使用Netcat向这个端口发送数据,Flume将接收到的数据打印到控制台。Netcat是一款TCP/UDP测试工具,可以通过以下命令安装:yum install -y nc。使用的组件如下:
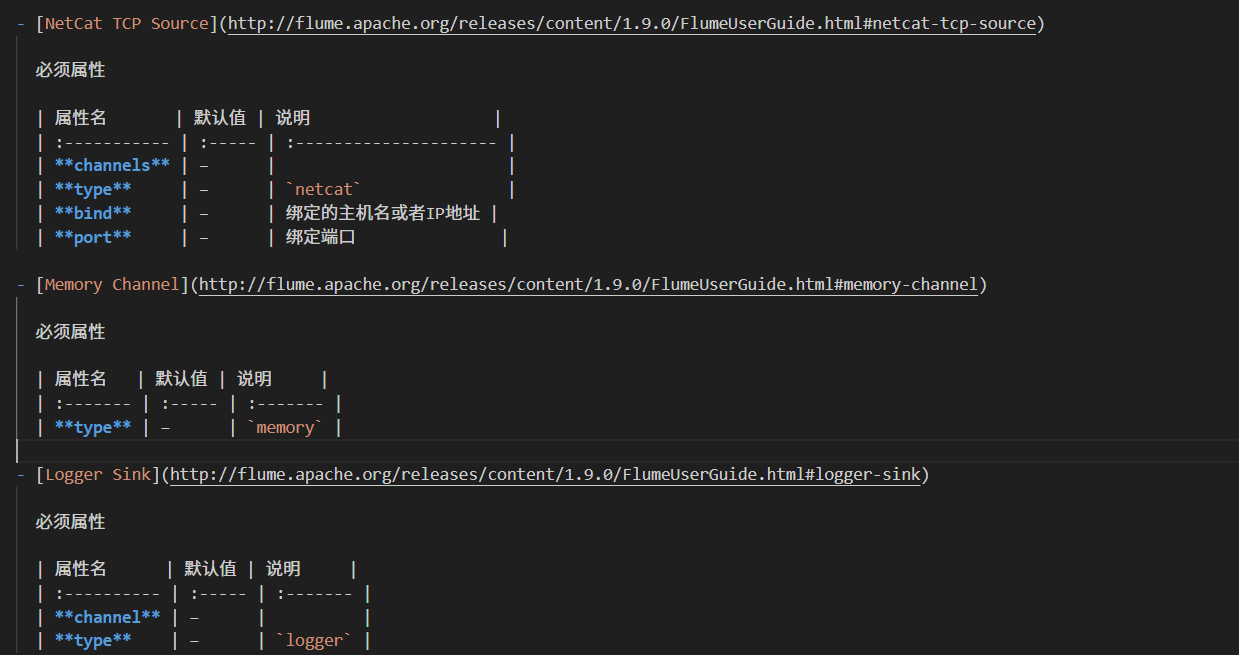
而后在apache-flume-1.9.0-bin/conf目录下添加配置文件example.conf
properties
# example.conf: 单节点Flume配置
# 定义agent名称为a1
# 设置3个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source类型为NetCat,监听地址为本机,端口为44444
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置sink类型为Logger
a1.sinks.k1.type = logger
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1PS:在另外一台虚拟机通过Netcat连接,需要更改配置文件
shell
# 将绑定端口配置为IP地址,绑定为localhost或者127.0.0.1在另外一台机器上无法连接
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.85.132 #你想要连上的主机
a1.sources.r1.port = 44444以下是命令的用法:
bash
/opt/soft/apache-flume-1.9.0-bin/bin/flume-ng <command> [options]...以下是示例:
(1)启动Flume
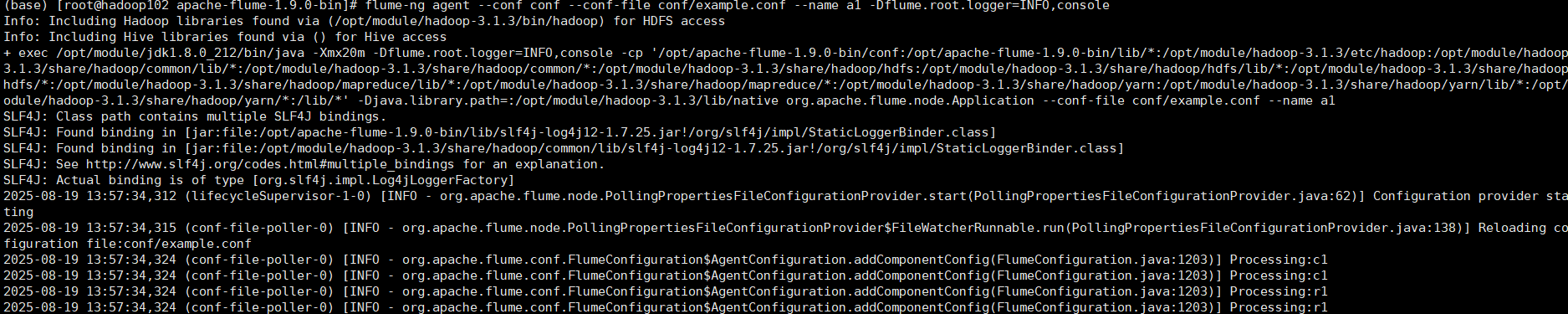
(2)从另一个端口启动Netcat连接到44444端口,发送一些字符串

(3)观察Agent端口:可看到接收到了数据

②数据持久化:可以在窗口上面看到以前的数据
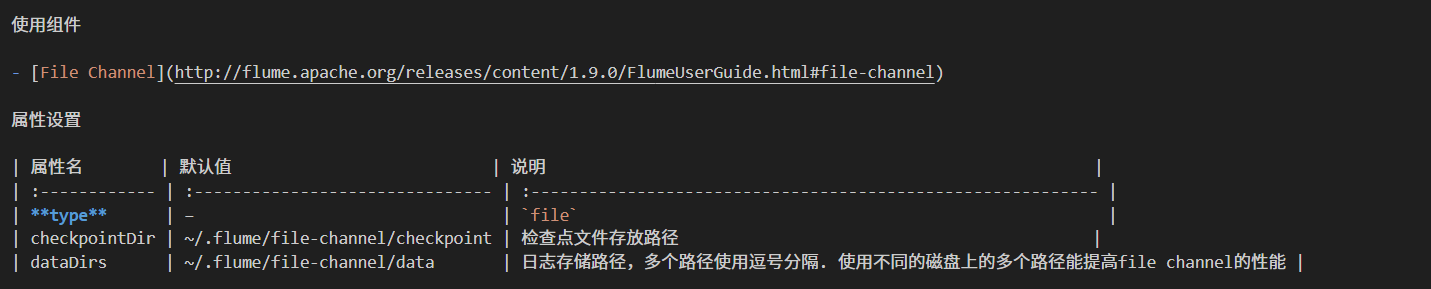
添加配置文件file-channel.conf,添加一个FileChannel
shell
# 定义agent名称为a1
# 设置3个组件的名称
a1.sources = r1
a1.sinks = k1
# 多个channel使用空格分隔
a1.channels = c1 c2
# 配置source类型为NetCat,监听地址为本机,端口为44444
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置sink类型为Logger
a1.sinks.k1.type = logger
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置FileChannel,checkpointDir为检查点文件存储目录,dataDirs为日志数据存储目录,
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/soft/bak/flume/checkpoint
a1.channels.c2.dataDirs = /opt/soft/bak/flume/data
# 将source和sink绑定到channel上
# source同时绑定到c1和c2上
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1为了方便日志打印,可以将-Dflume.root.logger=INFO,console添加在conf的环境配置中,从模板复制一份配置
shell
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
# 添加JAVA_OPTS
export JAVA_OPTS="-Dflume.root.logger=INFO,console"启动Flume
shell
flume-ng agent -n a1 -c ./ -f conf/file-channel.conf通过Netcat发送数据,,此时发送到c2的数据没有被消费,关闭Flume,修改配置文件
shell
# 将sink绑定到c2上
a1.sinks.k1.channel = c2③日志文件监控:企业中应用程序部署后会将日志写入到文件中,可以使用Flume从各个日志文件将日志收集到日志中心以便于查找和分析。(Exec Soucre的应用)
本次案例使用的组件是Exec Soucre,Flume的Exec Source是一个通过执行外部命令来采集数据的输入源组件,它允许用户将任意命令行工具的输出作为数据流接入Flume系统。该组件会持续运行指定的shell命令(如tail -F、cat或其他自定义脚本),并将其标准输出(stdout)转换为Flume事件写入Channel 。Exec Source的典型应用场景包括实时监控日志文件变化、采集系统命令输出或捕获脚本执行结果等。具体案例步骤如下
(1)添加配置文件exec-log.conf
shell
# 设置3个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source类型为exec,命令为 tail -F app.log
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/apache-flume-1.9.0-bin/conf/app.log
# 配置sink类型为Logger
a1.sinks.k1.type = logger
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动Flume
shell
flume-ng agent -n a1 -c conf -f file-log.conf -Dflume.root.logger=INFO,console通过命令更新app.log文件
shell
echo "abcdef">> app.log可以查看agent控制台接收到了最新的日志,把对应文件的内容全部打印再Flume控制台上面

④多个agent模型
有多种组合模型,以下是其中一种
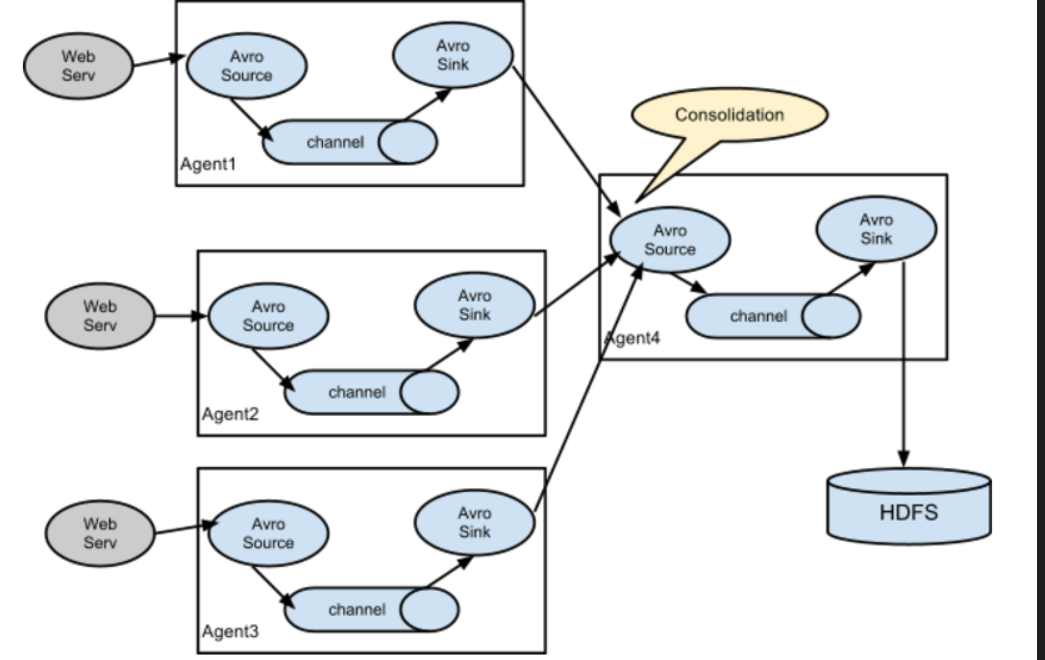
将前面两个示例组合应用
第一个agent从Netcat接收数据,增加一个channel和sink,将这个sink发送到第二个agent
第二个agent在监控文件变化的同时监控从sink发送来的事件,最终输出到控制台
使用的组件为:
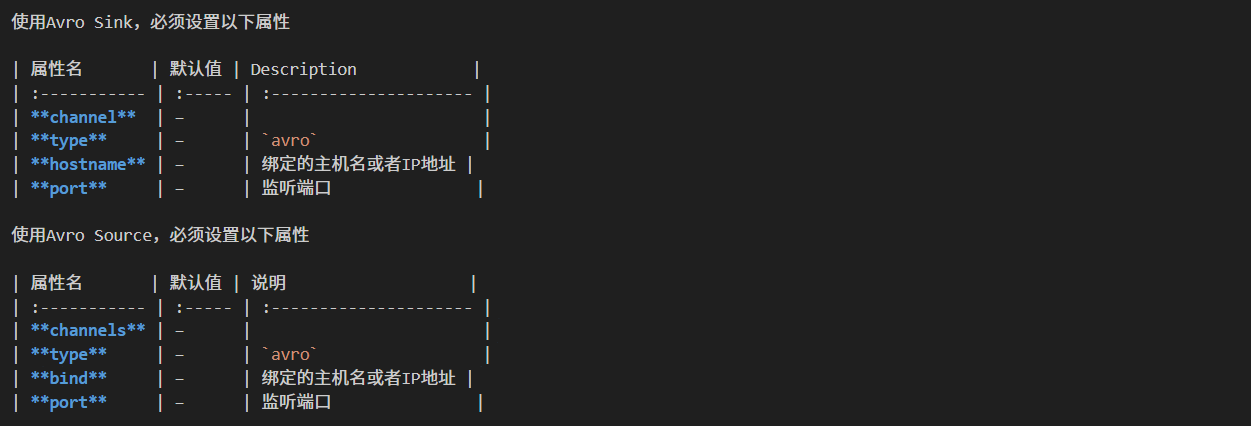
添加agent1配置文件
shell
# 定义agent名称为a1
# 设置3个组件的名称
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 配置source类型为NetCat,监听地址为本机,端口为44444
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置sink1类型为Logger
a1.sinks.k1.type = logger
# 配置sink2类型为Avro
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.85.132
a1.sinks.k2.port = 55555
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 将source和sink绑定到channel上
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2添加agent2配置文件
shell
# 定义agent名称为a2
# 设置3个组件的名称
a2.sources = r1 r2
a2.sinks = k1
a2.channels = c1
# 配置source类型为exec,命令为 tail -F app.log
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F app.log
# 配置source类型为avro
a2.sources.r2.type = avro
a2.sources.r2.bind = 192.168.85.132
a2.sources.r2.port = 55555
# 配置sink类型为Logger
a2.sinks.k1.type = logger
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上
a2.sources.r1.channels = c1
a2.sources.r2.channels = c1
a2.sinks.k1.channel = c1启动agent1和agent2
shell
flume-ng agent -n a1 -c conf -f agent1.conf
flume-ng agent -n a2 -c conf -f agent2.conf先往app.log中写入日志,可以在agent2看到最新数据
打开Netcat连接到44444,发送数据,可以同时在agent1和agent2看到最新数据。
PS:Flume 中一个非常经典和重要的 Avro Sink 配置。它用于将数据发送到另一个 Flume Agent(或其他支持 Avro RPC 的服务)
bash
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.85.132
a1.sinks.k2.port = 4040
⑤Flume的拦截器
Flume 拦截器的核心作用是在事件(Event)从 Source 到 Channel 的传输过程中,对事件进行轻量级的实时处理、过滤和修改 。集体可以做的事情如下:
拦截器的具体功能非常丰富,主要包括以下几个方面:
(1)数据清洗与标准化 :原始数据可能包含不需要的字符、乱码或格式不统一。拦截器可以移除无效字符、纠正格式错误、将时间戳转换为标准格式等。例如:将一个不规则的日志时间 19/Feb/2024:15:30:01 转换成标准格式 2024-02-19 15:30:01。
(2)数据过滤 :并非所有数据都需要被收集到存储系统(如 HDFS、HBase)中 。拦截器可以根据预定义的条件(如正则表达式匹配、关键词存在与否)来决定是保留事件还是丢弃事件。例如只收集包含 "ERROR" 或 "WARN" 关键词的日志事件,丢弃所有 "INFO" 级别的日志。
(3)添加元数据/标签 :为了后续数据处理时能区分数据的来源、类型或其他属性 。拦截器可以在事件的 Header(头部信息)中添加自定义的键值对(K-V)。例如为来自不同服务器的日志打上 hostname: server01 的标签。
(4)数据脱敏与加密 :保护敏感信息,如手机号、身份证号、邮箱等。拦截器可以识别敏感字段并将其进行掩码(如 138****1234)或加密处理。
(5)数据采样 :在数据量极大时,可能不需要100%的数据,只需一部分样本进行分析即可。拦截器可以按照一定比例(如 1%)随机让事件通过,丢弃其余事件。
以下是几种常见的的拦截器,这些拦截器都定义在source中
①Host Interceptor :这个拦截器将运行agent的hostname 或者 IP地址写入到事件的headers中
②Timestamp Interceptor :这个拦截器将当前时间 写入到事件的headers中
③Static Interceptor :运行用户对所有的事件添加固定的header
④UUID Interceptor :为每一个经过 Flume Agent 的事件(Event)生成一个全局唯一的标识符(UUID),并将其添加到事件的 Header 中 。
⑤Search and Replace Interceptor 的核心用途是使用正则表达式对事件(Event)的 Body(主体内容)或 Header(头部信息)进行搜索和文本替换操作 。 它是一种强大的数据清洗和实时ETL工具
下面是Host Interceptor拦截器的使用
打开另外一台虚拟机,安装好Flume
1 在flume/conf目录下新建app.log文件
shell
touch app.log2 添加agent3.conf,这个agent监控本地的app.log,将数据发送到虚拟机132上
shell
# 定义agent名称为a3
# 设置3个组件的名称
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# 配置source类型为exec,命令为 tail -F app.log
a3.sources.r1.type = exec
a3.sources.r1.command = tail -F app.log
# 配置拦截器为host
a3.sources.r1.interceptors = i1
a3.sources.r1.interceptors.i1.type = host
# 配置sink类型为avro
a3.sinks.k1.type = avro
a3.sinks.k1.hostname = 192.168.85.132
a3.sinks.k1.port = 55555
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c13 这里注意需要在132上开启防火墙端口
shell
firewall-cmd --zone=public --add-port=55555/tcp --permanent
firewall-cmd --reload4 启动agent3
shell
flume-ng agent -n a3 -c conf -f agent3.conf5 可以在132的agent2控制台看到agent3已经连接成功,接着往135的app.log中写入数据
shell
echo "data from 135" >> app.log6 可以在agent2上看到添加了headers
也可以自己定义拦截器,具体步骤如下:
①新建工程,添加pom引用
xml
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>②添加自定义拦截器
java
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
public class MyInterceptor implements Interceptor {
private static final Logger logger = LoggerFactory
.getLogger(MyInterceptor.class);
public void initialize() {
}
/**
* 拦截单个事件
* @param event
* @return
*/
public Event intercept(Event event) {
String host = event.getHeaders().get("host");
logger.info("接收到host为:"+host);
if (host.equals("192.168.85.135")) {
logger.info("丢弃事件");
return null;
}
return event;
}
public List<Event> intercept(List<Event> list) {
List<Event> newList = new ArrayList<Event>();
for (Event event : list) {
event = intercept(event);
if(event!=null){
newList.add(event);
}
}
return newList;
}
public void close() {
}
public static class Builder implements Interceptor.Builder{
public Interceptor build() {
return new MyInterceptor();
}
public void configure(Context context) {
}
}
}③将项目打成jar包后复制到Flume安装目录的lib目录中,之后修改agent2.conf
shell
# 配置拦截器
a2.sources.r2.interceptors = i1
a2.sources.r2.interceptors.i1.type = com.itheima.flume.interceptor.MyInterceptor$Builder④此时再从135发送数据过来,可以看到数据被拦截了,拦截后的数据不会进入channel,即不会被sink消费
⑥Channel 选择器(也是定义在source当中)
Channel 选择器 是 Flume Agent 中 Source 的一个组件 。它的作用就像一个交通警察或路由器,决定一个到来的事件(Event)应该被发送到哪个或哪些 Channel 中去。在一个 Flume Agent 中,一个 Source 可以将数据写入多个 Channel(这被称为"扇出"或"复用"),而一个 Sink 只能从一个 Channel 读取数据。这种架构允许非常灵活的数据流设计。选择器有两种:
①复制选择器(Replicating Channel Selector):这是默认的选择器。它会将 每一个事件 复制一份,然后发送到该 Source 配置的所有 Channel 中 。当你需要将完全相同的数据发送到多个后续流程时。例如,你既想将日志数据存入 HDFS 做长期存储,又想实时地发送到 Kafka 供流处理引擎(如 Spark Streaming、Flink)进行实时分析。以下是案例:
shell
a1.sources = r1
a1.channels = c1 c2 c3
a1.sources.r1.selector.type = replicating
a1.sources.r1.channels = c1 c2 c3
a1.sources.r1.selector.optional = c3上面的配置中c1 c2 c3都会从r1被写入数据,c3是一个可选的channel,写入c3失败的话会被忽略,c1和c2没有标记为可选,如果写入c1和c2失败会导致事务的失败。
②Multiplexing Channel Selector:根据事件 Header 中的某个属性的值,来动态地决定将事件发送到哪个 Channel 。这需要你预先配置一个映射规则 。案例如下:
使用案例:
shell
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1 c2
a1.sources.r1.selector.mapping.US = c1 c3
a1.sources.r1.selector.default = c1 c4这里通过事件的header值来判断将事件发送到哪个channel,可以配合拦截器一起使用。
⑦Sink处理器
Sink 处理器(Sink Processor) 是 Flume 中用于组织和控制一个 Sink 组(Sink Group) 内多个 Sink 如何工作的逻辑单元。它决定了多个 Sink 是作为主备容灾,还是负载均衡,或是单纯地批量操作。你可以把它想象成一个团队的管理者,它不直接干活(处理数据),而是指挥手下的员工(Sinks)如何更有效、更可靠地完成工作。
可以将多个sink放入到一个组中,Sink处理器能够对一个组中所有的sink进行负载均衡,在一个sink出现临时错误时进行故障转移具体如下所示:
shell
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover以下是Sink Processor
①Default Sink Processor:默认的Sink处理器只支持单个Sink
②Failover Sink Processor:是一种将多个 Sink 配置成 主备(Active-Standby)模式 的机制。它自动监控 Sink 的健康状态,如果主 Sink 失败,会自动将数据流量切换到备用的 Sink 上,从而保证数据流的持续性和可靠性。

③Load balancing Sink Processor:负载均衡处理器,可以通过轮询或者随机的方式进行负载均衡,也可以通过继承AbstractSinkSelector 自定义负载均衡。
⑦使用Flume导入数据到HDFS
使用HDFS Sink需要用到Hadoop的多个包,可以在装有Hadoop的主机上运行Flume,如果是单独部署的Flume,可以通过多个Agent的形式将单独部署的Flume Agent 日志数据发送到装有Hadoop的Flume Agent上。
创建hdfs.conf
properties
# 定义agent名称为a1
# 设置3个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source类型为NetCat,监听地址为本机,端口为44444
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置sink类型为hdfs
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:9000/user/flume/logs
a1.sinks.k1.hdfs.fileType = DataStream
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume
shell
bin/flume-ng agent --conf conf/ --conf-file conf/hdfs.conf -Dfile.root.logger=debug,info,console --name hdfs⑧自定义Source:允许你处理 Flume 内置 Source 无法满足的特殊数据采集需求

java
public class MySource extends AbstractSource implements Configurable, PollableSource {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation, convert to another type, ...)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external client
}
@Override
public void stop () {
// Disconnect from external client and do any additional cleanup
// (e.g. releasing resources or nulling-out field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
try {
// This try clause includes whatever Channel/Event operations you want to do
// Receive new data
Event e = getSomeData();
// Store the Event into this Source's associated Channel(s)
getChannelProcessor().processEvent(e);
status = Status.READY;
} catch (Throwable t) {
// Log exception, handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
return status;
}
}添加MySource
java
package com.itheima.flume.source;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
public class MySource extends AbstractSource implements Configurable, PollableSource {
// 处理数据
public Status process() throws EventDeliveryException {
Status status = null;
try {
// 接收新数据
for (int i = 0; i < 10; i++) {
Event e = new SimpleEvent();
e.setBody(("data:"+i).getBytes());
// 将数据存储到与Source关联的Channel中
getChannelProcessor().processEvent(e);
status = Status.READY;
}
Thread.sleep(5000);
} catch (Throwable t) {
// 打印日志
status = Status.BACKOFF;
// 抛出异常
if (t instanceof Error) {
throw (Error)t;
}
} finally {
}
return status;
}
public long getBackOffSleepIncrement() {
return 0;
}
public long getMaxBackOffSleepInterval() {
return 0;
}
public void configure(Context context) {
}
}添加mySourceAgent.conf
shell
# 定义agent名称为a1
# 设置3个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source类型为mysource
a1.sources.r1.type = com.itheima.flume.source.MySource
# 配置sink类型为Logger
a1.sinks.k1.type = logger
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动Flume
shell
flume-ng agent -n a1 -c conf -f mySourceAgent.conf⑨自定义Sink
自定义 Sink 允许你将数据发送到任何 Flume 官方不支持的第三方系统或自定义目的地。

java
public class MySink extends AbstractSink implements Configurable {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external repository (e.g. HDFS) that
// this Sink will forward Events to ..
}
@Override
public void stop () {
// Disconnect from the external respository and do any
// additional cleanup (e.g. releasing resources or nulling-out
// field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
Event event = ch.take();
// Send the Event to the external repository.
// storeSomeData(e);
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
// Log exception, handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
}
return status;
}
}添加MySink,可以参考LoggerSink
java
package com.itheima.flume.sink;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MySink extends AbstractSink implements Configurable {
private static final Logger logger = LoggerFactory
.getLogger(MySink.class);
public Status process() throws EventDeliveryException {
Status status = null;
// 开启事务
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
try {
txn.begin();
// 从channel中获取数据
Event event = ch.take();
if(event==null){
status = Status.BACKOFF;
}
// 将事件发送到外部存储
// storeSomeData(e);
// 打印事件
logger.info(new String(event.getBody()));
// 提交事务
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
// 打印异常日志
status = Status.BACKOFF;
// 抛出异常
if (t instanceof Error) {
throw (Error)t;
}
}finally {
txn.close();
}
return status;
}
public void configure(Context context) {
}
}修改上面的mySourceAgent.conf
shell
# 定义agent名称为a1
# 设置3个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source类型为mysource
a1.sources.r1.type = com.itheima.flume.source.MySource
# 配置sink类型为MySink
a1.sinks.k1.type = com.itheima.flume.sink.MySink
# 配置channel类型为内存,内存队列最大容量为1000,一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1