项目概述
本项目使用YOLO11n模型进行茶叶病害检测,能够识别8种不同类型的茶叶状态,包括6种病害类型和正常茶叶。这是一个典型的计算机视觉目标检测任务,对于茶叶种植业的智能化管理具有重要意义。
检测类别
本模型能够检测以下8种茶叶状态:
- Black rot of tea - 茶叶黑腐病
- Brown blight of tea - 茶叶褐斑病
- Leaf rust of tea - 茶叶锈病
- Red Spider infested tea leaf - 红蜘蛛侵染茶叶
- Tea Mosquito bug infested leaf - 茶蚊虫侵染叶片
- Tea leaf - 正常茶叶
- White spot of tea - 茶叶白斑病
- disease - 一般病害
训练配置
模型参数
- 模型: YOLO11n (轻量级版本)
- 预训练模型: 使用官方预训练权重
- 训练轮数: 100 epochs (实际训练了72轮)
- 批次大小: 16
- 图像尺寸: 640×640
- 设备: GPU (device: '0')
- 优化器: 自动选择
- 学习率调度: 余弦退火
数据增强设置
- 缓存: 启用数据缓存以加速训练
- 马赛克增强: 在训练最后10轮关闭
- 多尺度训练: 关闭
- 混合精度训练: 关闭
训练结果分析
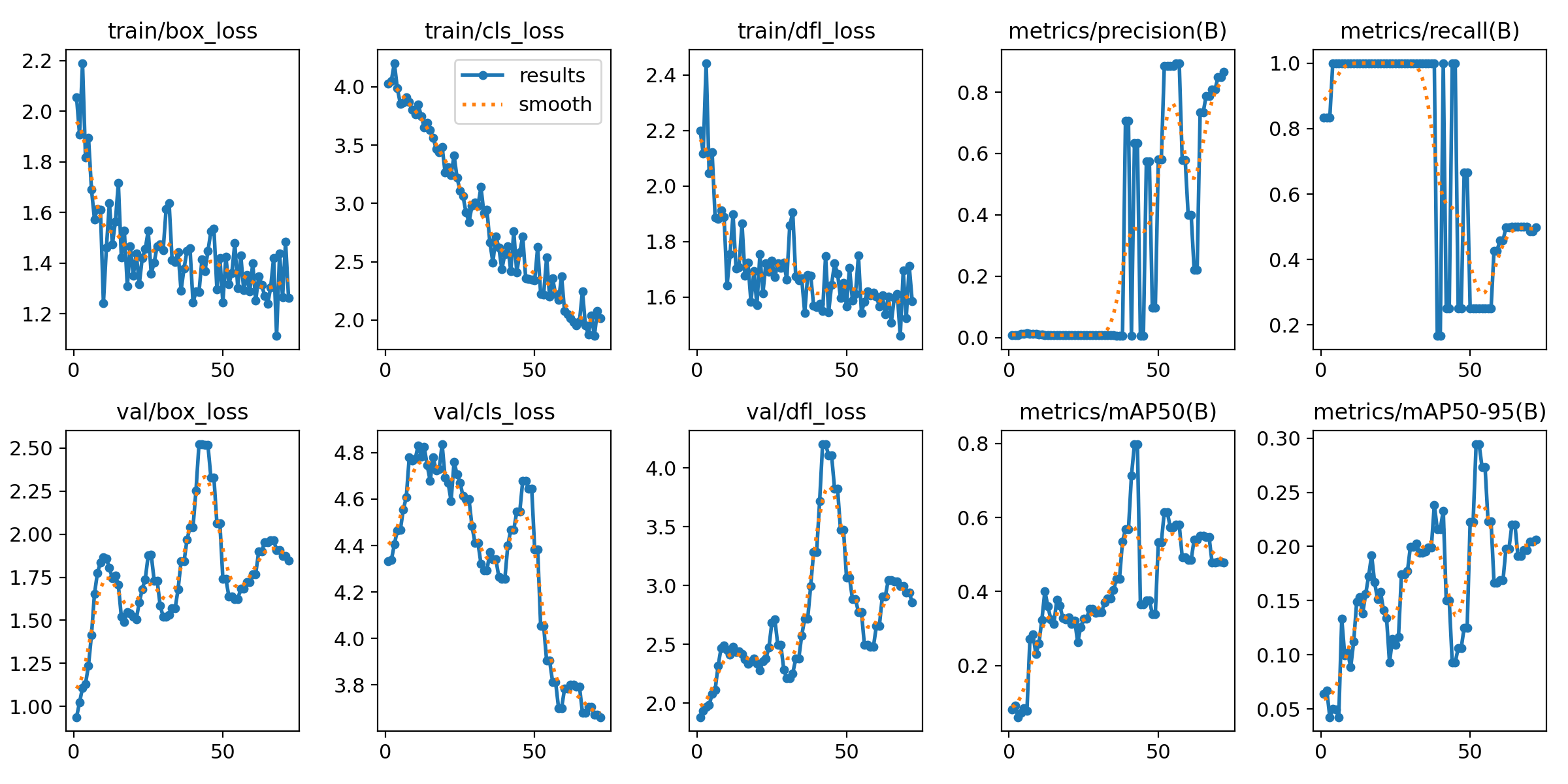
图1: 训练过程中各项指标的变化趋势
最终性能指标 (第72轮)
| 指标 | 数值 |
|---|---|
| 精确率 (Precision) | 86.58% |
| 召回率 (Recall) | 49.85% |
| mAP@0.5 | 47.89% |
| mAP@0.5:0.95 | 20.63% |
| 训练损失 | 4.86 |
| 验证损失 | 8.37 |
训练过程分析
从训练曲线可以看出:
-
损失变化趋势:
- 训练损失从初始的8.28逐步下降到4.86
- 验证损失相对稳定,最终为8.37
- 存在一定的过拟合现象
-
性能指标变化:
- 精确率稳步提升,最终达到86.58%
- 召回率相对较低,仅为49.85%,说明模型在检测所有病害方面还有提升空间
- mAP@0.5达到47.89%,表明模型在中等IoU阈值下有不错的表现
可视化结果
训练过程图表
本次训练生成了多个重要的可视化图表:
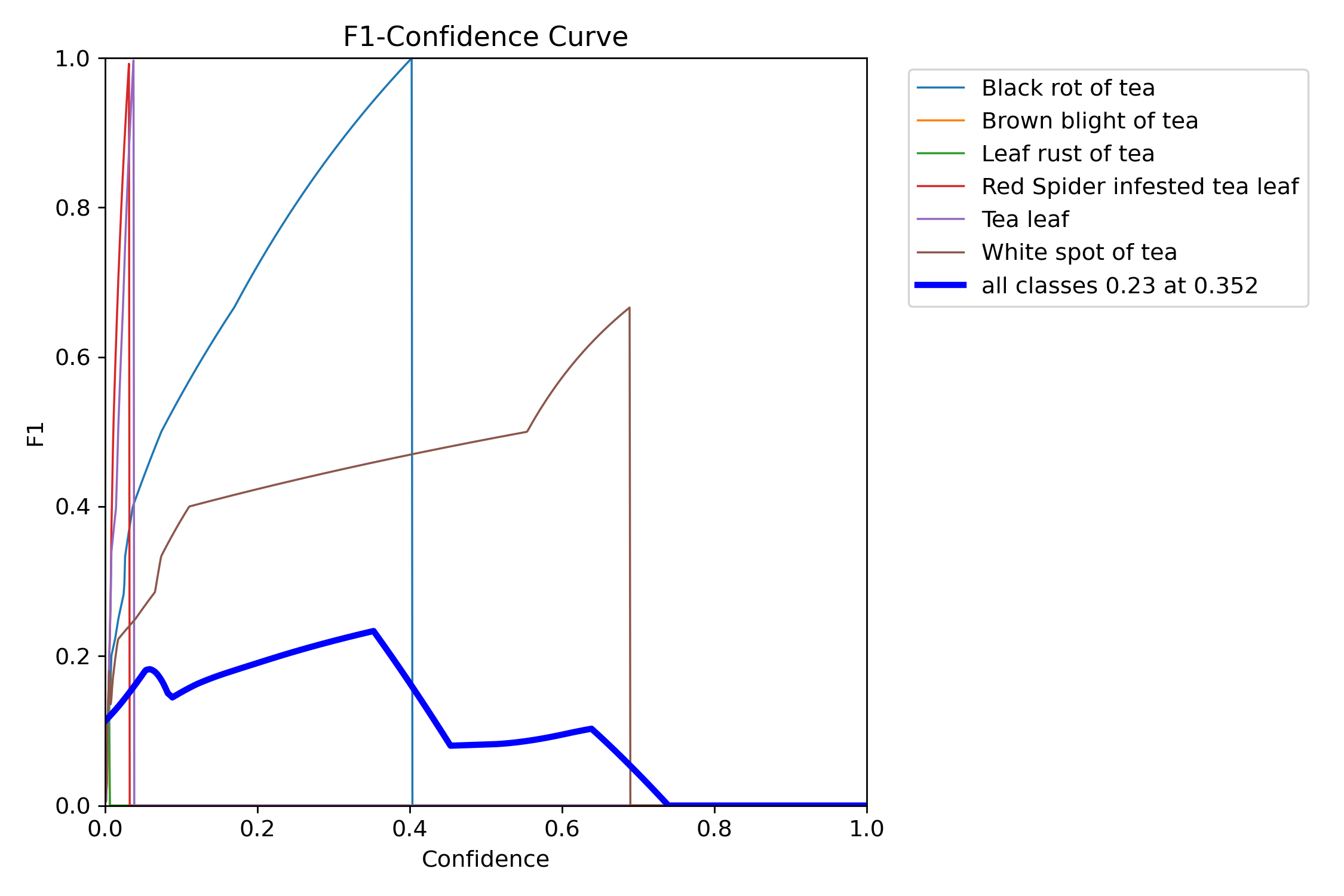
图2: F1分数随训练轮数的变化
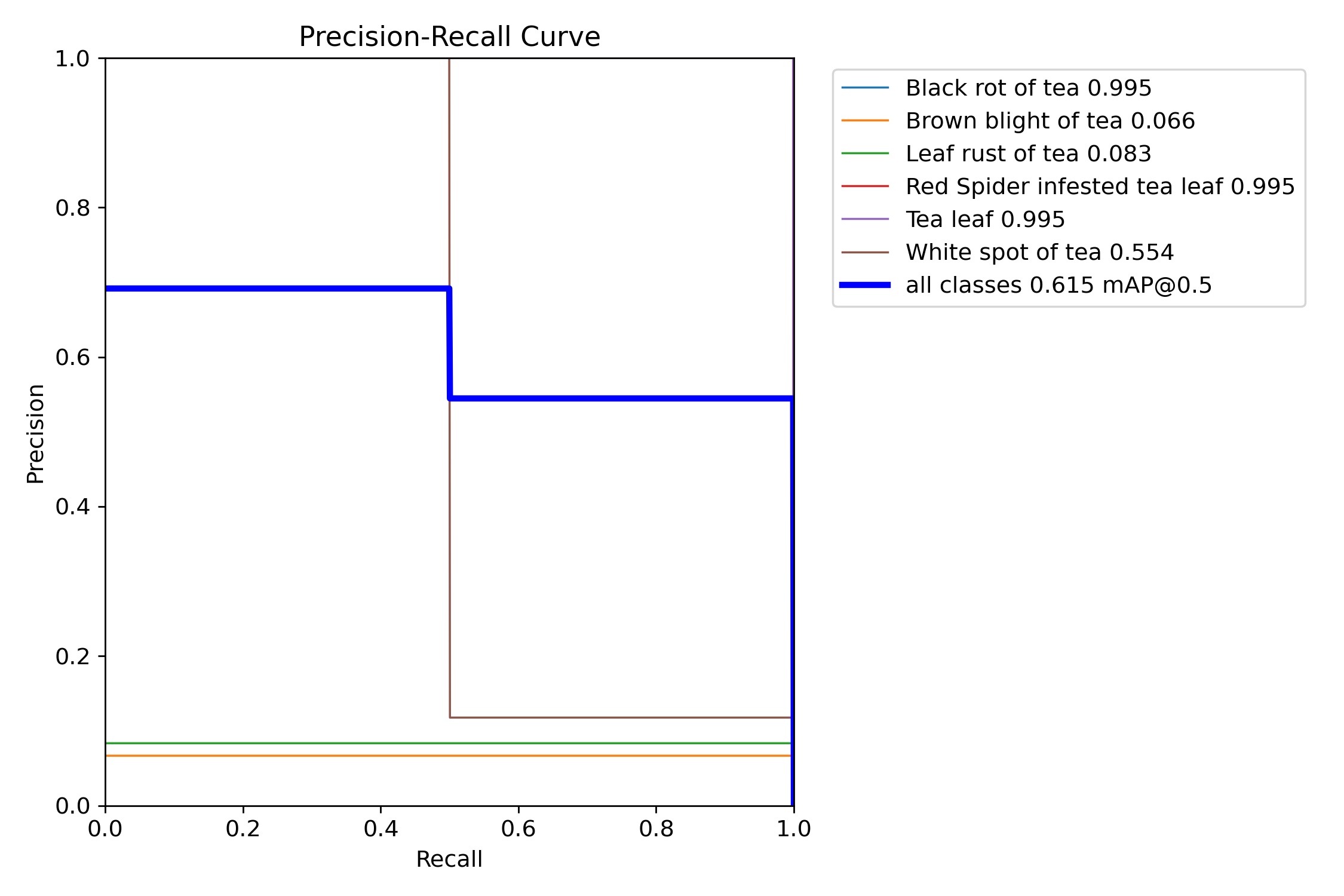
图3: 精确率-召回率曲线,展示模型在不同阈值下的性能
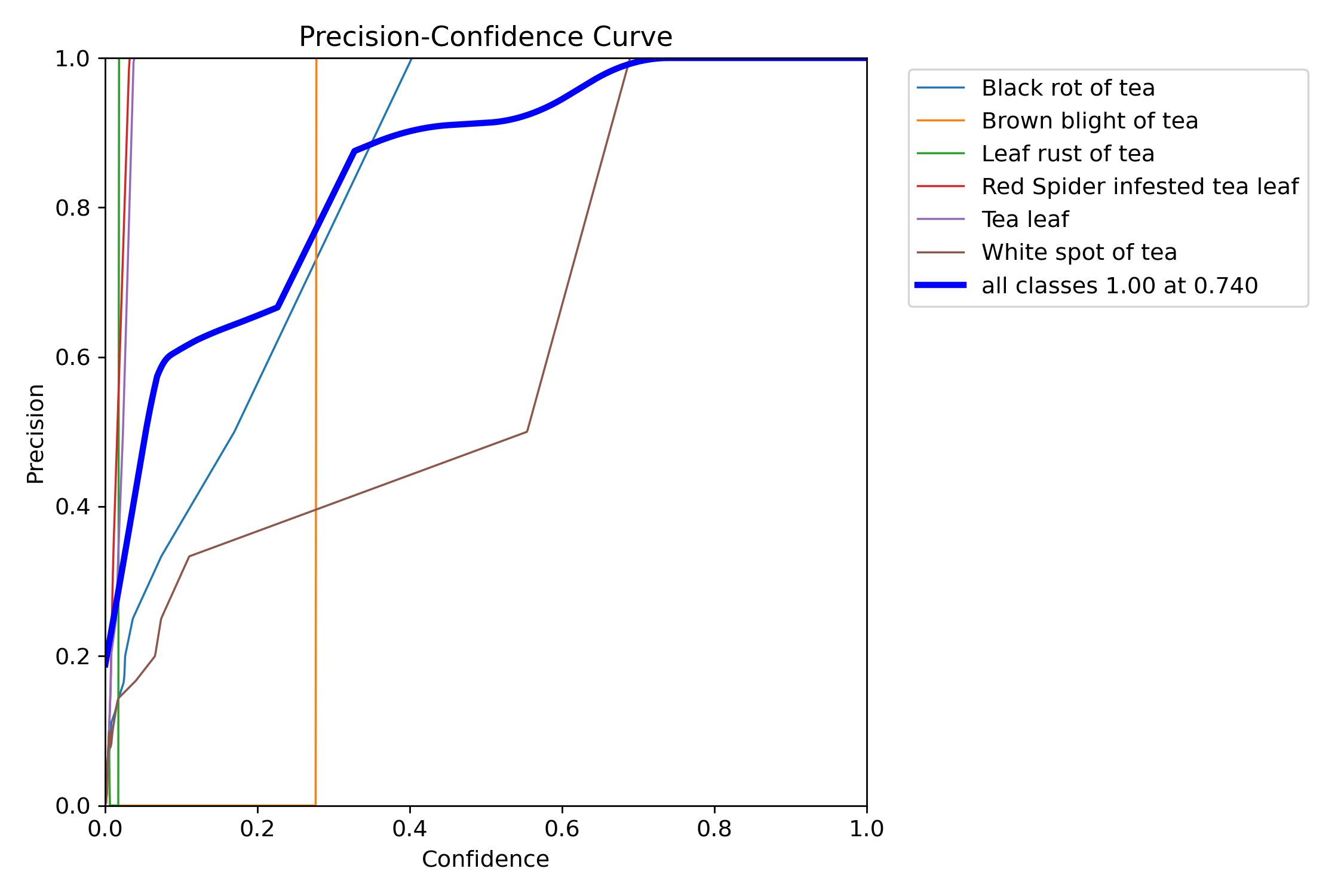
图4: 精确率随置信度阈值的变化
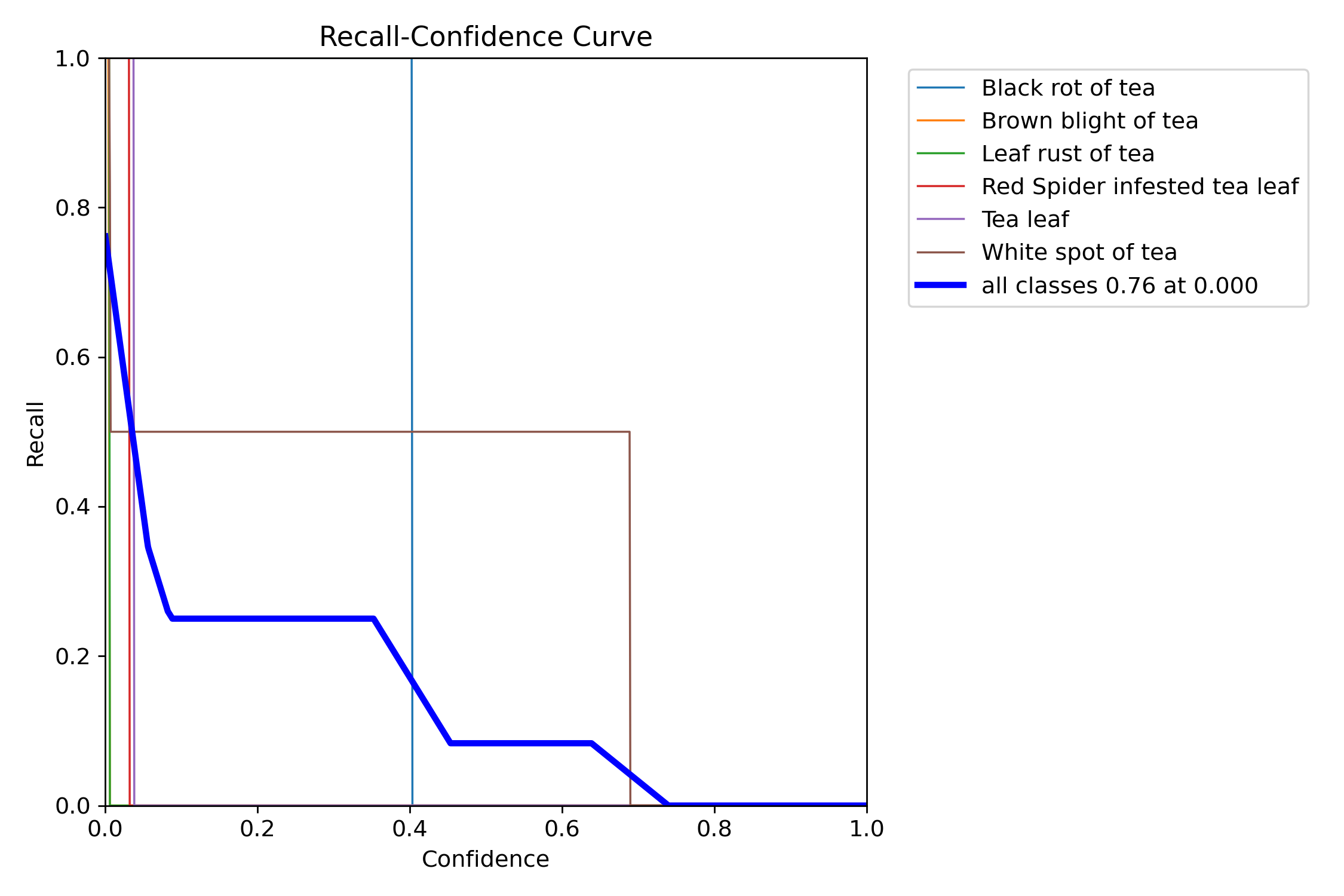
图5: 召回率随置信度阈值的变化
混淆矩阵分析
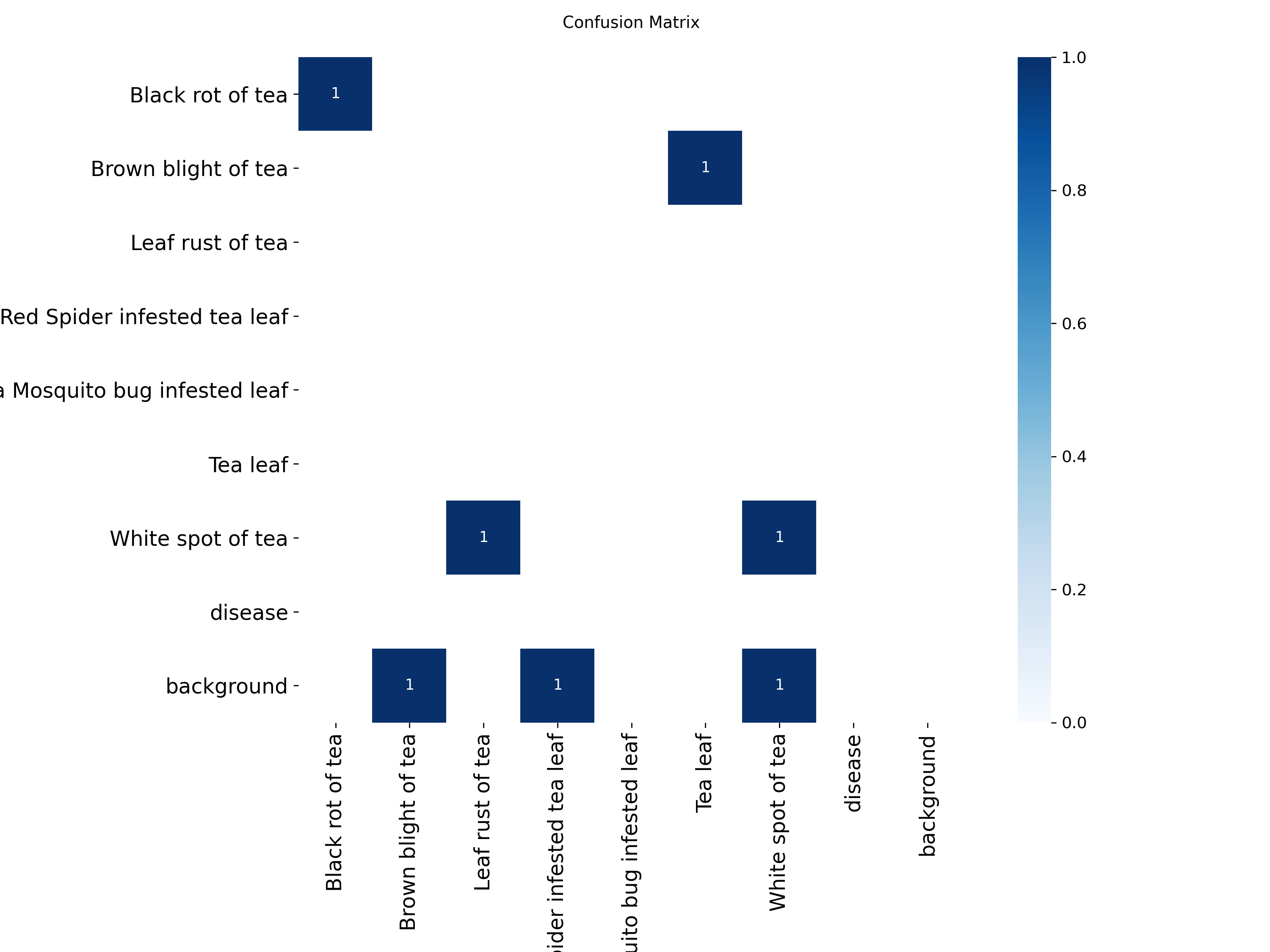
图6: 混淆矩阵 - 显示各类别的预测准确性
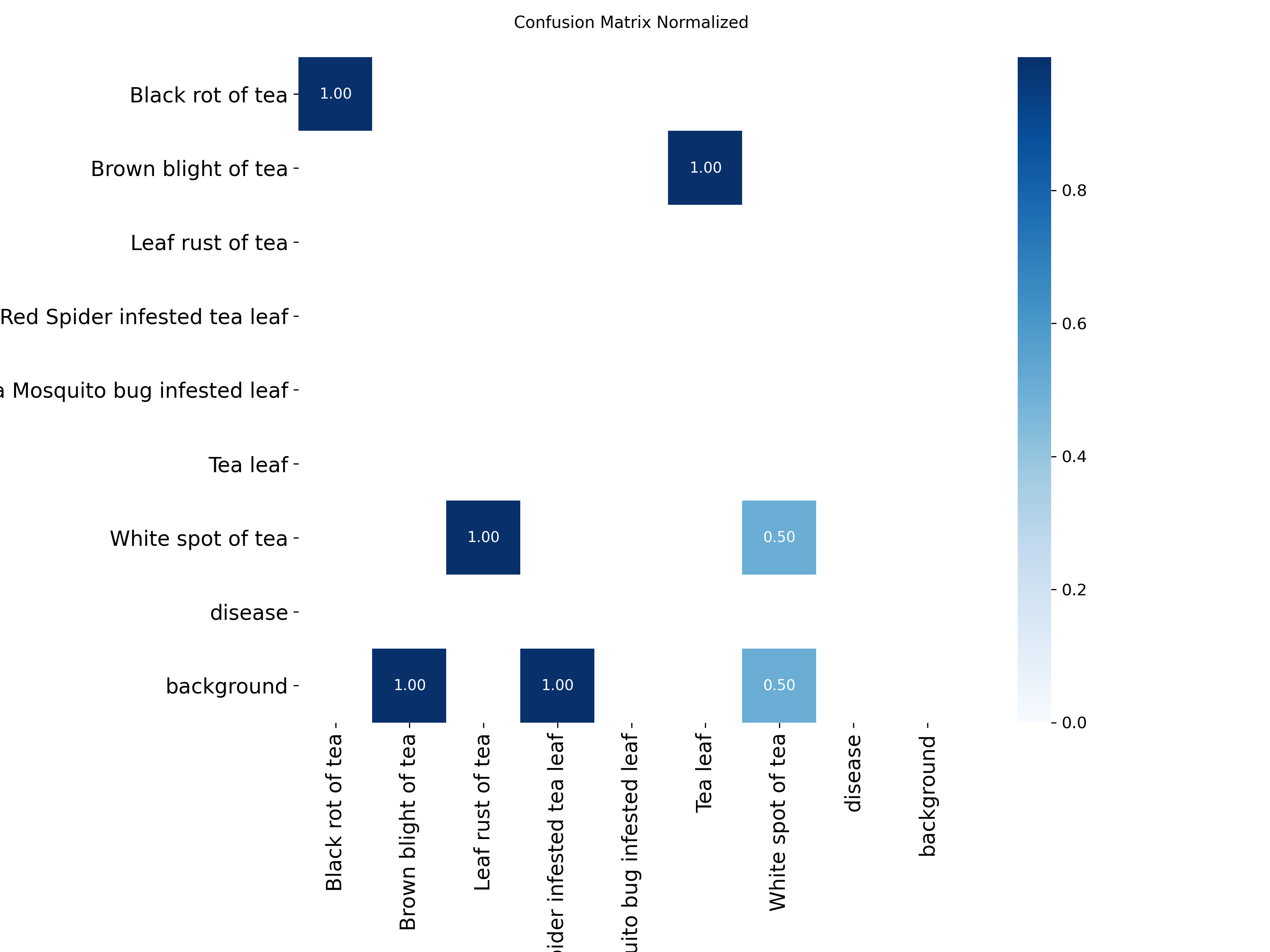
图7: 归一化混淆矩阵 - 更直观地展示各类别的识别准确率
混淆矩阵能够直观显示模型对各类茶叶病害的识别准确性,帮助我们了解哪些类别容易被混淆。
数据分布可视化
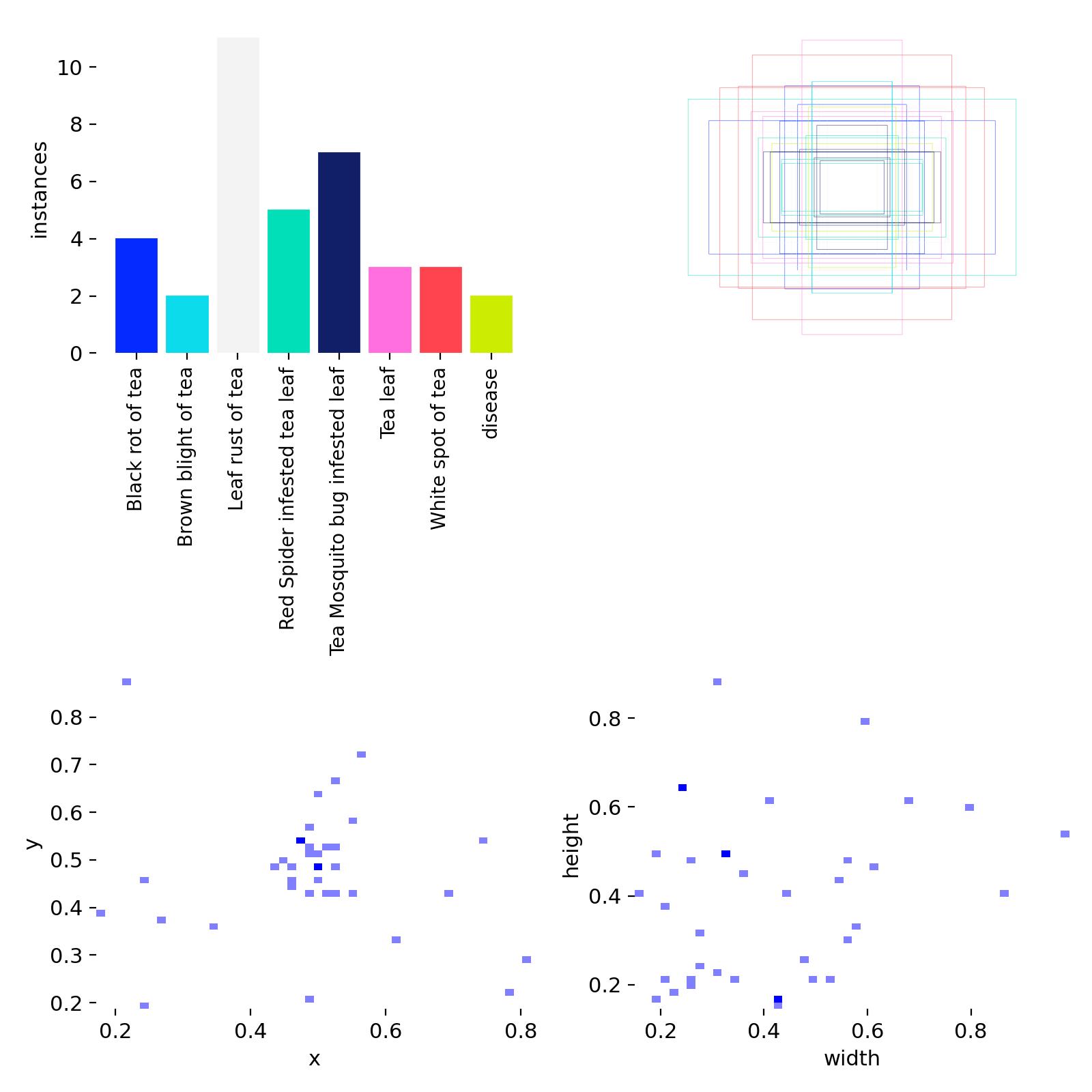
图8: 训练数据中各类别的分布统计
图9: 各类别标签之间的相关性分析
这些图表展示了训练数据中各类别的分布情况和相互关系。
训练样本展示

图10: 训练批次样本展示

图11: 验证集真实标签

图12: 验证集预测结果对比
模型性能评估
优势
- 高精确率: 86.58%的精确率表明模型的误报率较低
- 轻量化: YOLO11n模型参数量小,适合部署
- 多类别检测: 能够同时识别多种茶叶病害
改进空间
- 召回率偏低: 49.85%的召回率说明存在较多漏检
- 类别不平衡: 可能存在某些病害类别样本不足
- 过拟合: 训练损失和验证损失差距较大
优化建议
数据层面
- 增加数据量: 特别是召回率低的类别
- 数据平衡: 确保各类别样本数量相对均衡
- 数据质量: 提高标注质量,减少噪声标签
模型层面
- 正则化: 增加dropout或权重衰减来缓解过拟合
- 学习率调整: 尝试更小的学习率或不同的调度策略
- 损失函数: 考虑使用focal loss来处理类别不平衡
训练策略
- 早停机制: 设置更严格的早停条件
- 交叉验证: 使用k折交叉验证评估模型稳定性
- 集成学习: 结合多个模型提高整体性能
实际应用价值
这个茶叶病害检测模型在实际应用中具有重要价值:
- 智能农业: 帮助茶农及时发现和诊断茶叶病害
- 成本降低: 减少人工巡检成本,提高检测效率
- 精准防治: 针对不同病害类型制定相应的防治措施
- 产量保障: 早期发现病害,减少经济损失
总结
本次YOLO11n茶叶病害检测模型训练取得了阶段性成果,模型在精确率方面表现良好,但在召回率和整体mAP方面还有提升空间。通过进一步的数据优化、模型调参和训练策略改进,相信能够获得更好的检测性能,为茶叶种植业的智能化发展贡献力量。