目录
[一、王牌组合:一个"过目不忘"的大脑 + 一个"收放自如"的开关](#一、王牌组合:一个“过目不忘”的大脑 + 一个“收放自如”的开关)
[1.1 "过目不忘"的记忆力](#1.1 “过目不忘”的记忆力)
[1.2 "收放自如"的思考力](#1.2 “收放自如”的思考力)
[二、 "小个子"的大能量:效率才是硬道理](#二、 “小个子”的大能量:效率才是硬道理)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 字节Seed-OSS开源
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
**在过去几年里,AI大模型的"军备竞赛"给我们上演了一场场数字奇观。**参数量从百亿飙到万亿,上下文窗口从几千卷到几十万。我们惊叹于AI能力的飞速膨胀,但对于真正想把AI用在业务里的开发者和企业来说,一个灵魂拷问始终挥之不去:
AI的"蛮力"越来越大,但它的"巧劲"在哪里?
我们常常感觉自己面对的是一个性能强大但脾气古怪的"黑箱"。它时而才华横溢,时而胡言乱语;你不知道它为了回答一个简单问题,在背后消耗了多少算力;你也无法控制它在面对一个复杂任务时,应该投入多少"思考深度"。
现在,字节跳动Seed团队带着他们首次开源的大语言模型Seed-OSS ,给出了一个响亮的回答。这款36B参数的模型,没有去参与万亿参数的豪赌,而是亮出了两张直击应用痛点的王牌:512K的原生超长上下文 和 可控的"思考预算"。

这不仅仅是一个新模型的发布,更像是一份"AI实用主义"的宣言。字节似乎在告诉全世界:AI的下一站,不应再是无休止的参数竞赛,而是如何让AI变得更聪明、更可控、更高效地为人类服务。
一、王牌组合:一个"过目不忘"的大脑 + 一个"收放自如"的开关
Seed-OSS最让人兴奋的,是它将两个看似独立、实则相辅相成的能力完美地结合在了一起。
1.1 "过目不忘"的记忆力
首先,是"长记性"。Seed-OSS原生支持512K的上下文窗口,这是什么概念?
**这意味着它能一次性"读"完并理解大约90万汉字的内容。**你可以把一整本厚厚的法律文书、一个包含了数百个文件的复杂代码库、或者一部长篇小说的手稿,直接扔给它,而不用担心它"前读后忘"。
**更关键的词是"原生支持"。**很多模型的长上下文是通过后续技术"扩展"出来的,就像给一辆小轿车加挂了几节车厢,虽然能装更多东西,但开起来总觉得别扭。而Seed-OSS的512K能力,是在"娘胎里"就通过训练获得的,这意味着它在处理长文本时,对全局逻辑的把握、对前后文细节的关联,会更加自然和精准。
在权威的长文本理解测试RULER中,它以94.6分刷新了开源模型的记录,这足以证明其"长跑"能力的含金量。
1.2 "收放自如"的思考力
如果说512K长上下文是赋予了AI一个"巨胃",那么"思考预算"就是给了用户一个控制"消化系统"的开关。
这是Seed-OSS最具革命性的创新之一。用户在向模型提问时,可以明确指定一个"思考预算",比如512、1024或8192个tokens。模型会先在内部进行"思考"(生成思维链),当预算用尽时,它会自动停止思考,并开始生成最终答案。
这个功能解决了AI应用中一个巨大的痛点:成本与效果的平衡。
(1)对于简单问题(比如"如何做意大利面?"),你可以给它一个很小的预算(甚至为0),让它快速直接地给出答案,避免不必要的算力浪费。
**(2)对于复杂问题(**比如"请分析这份财报并总结核心风险"),你可以给它一个充足的预算,让它进行深度、多步骤的推理,确保答案的质量。
模型甚至会在思考过程中,像一个尽职的助理一样,实时向你"汇报"预算使用情况:
<seed:cot_budget_reflect>I have used 129 tokens, and there are 383 tokens remaining for use.</seed:cot_budget_reflect>
这种"可控性",让AI从一个性能不稳定的"黑箱",变成了一个资源消耗可预测、思考深度可调节的"透明工具"。这对于企业进行成本控制和应用优化,意义非凡。
当"超长记忆"和"可控思考"这两个能力结合在一起时,一个全新的应用范式就诞生了。你可以让AI先用极低的预算快速通读一份50万字的报告,生成一份摘要;然后,针对你感兴趣的某个章节,再给它一个高额的预算,让它进行深入的细节分析和推理。这才是真正智能、高效的人机协作。
二、 "小个子"的大能量:效率才是硬道理
在参数动辄上千亿的时代,字节这次开源的36B模型,显得有些"小巧"。但这恰恰是它最可怕的地方。
Seed-OSS用实际的测试成绩证明了:聪明的架构和高效的训练,远比单纯的参数堆砌更重要。
在数学推理能力上(AIME24得分91.7),它刷新了开源模型的记录。
在编程能力上(LiveCodeBench V6得分67.4),它同样登顶开源第一。
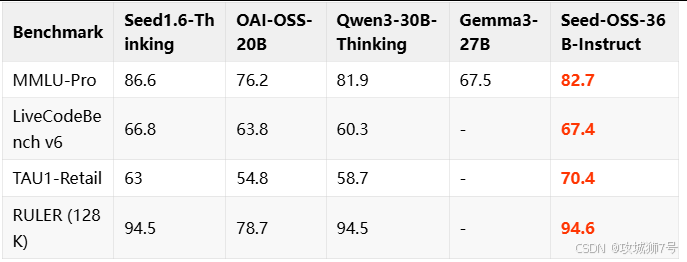
与OpenAI开源的GPT-OSS-120B相比 ,Seed-OSS以不到三分之一的参数量,在长上下文处理、编程等多项关键能力上实现了超越。
这背后,是GQA注意力机制、SwiGLU激活函数等一系列经过行业验证的高效技术组件的功劳。字节跳动向我们展示了一场精彩的"工程魔术":用更少的资源,办更大的事。
三、为开发者而生:一次真正彻底的开源
除了技术上的突破,字节这次的开源姿态,也充满了对开发者社区的诚意和尊重。
**(1)完全开放的Apache 2.0许可证:**这意味着无论是学术研究还是商业应用,你都可以自由地使用、修改甚至二次分发,没有任何后顾之忧。
**(2)两个基座版本:**同时提供"含合成数据"和"不含合成数据"两个版本。前者性能更强,适合追求极致效果的商业应用;后者数据更"纯净",为学术界进行数据污染分析等研究提供了宝贵的"对照组"。这种考量,体现了对社区不同需求的深刻理解。
**(3)低门槛的部署方案:**支持4-bit/8-bit量化,兼容vLLM框架,提供完整的API服务脚本。这意味着,你不需要顶级的服务器集群,甚至在消费级的GPU上,也有可能把这个强大的模型跑起来,极大地降低了个人开发者和中小企业的入门门槛。
结语:AI竞赛的下半场,实用主义为王
Seed-OSS的开源,可能预示着AI大模型竞赛的"下半场"已经到来。
上半场,是巨头们不计成本的"军备竞赛",比拼的是谁的参数更多、谁的训练数据更海量。而下半场,当大家的基础能力逐渐拉齐后,比拼的将是谁能更好地解决真实世界的问题,谁能为开发者提供更灵活、更高效、更可控的工具。
字节跳动用Seed-OSS这张牌,明确地站在了"实用主义"这一边。它没有去追求那个最耀眼的"参数皇冠",而是选择去做一个更接地气、更能解决问题的"效率大师"。
对于整个AI生态而言,这无疑是一个积极的信号。当越来越多的巨头开始"卷"效率、"卷"开放、"卷"实用性时,AI技术的落地和普及,才会真正地加速到来。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!