Kafka Broker 核心原理全解析:存储、高可用与数据同步
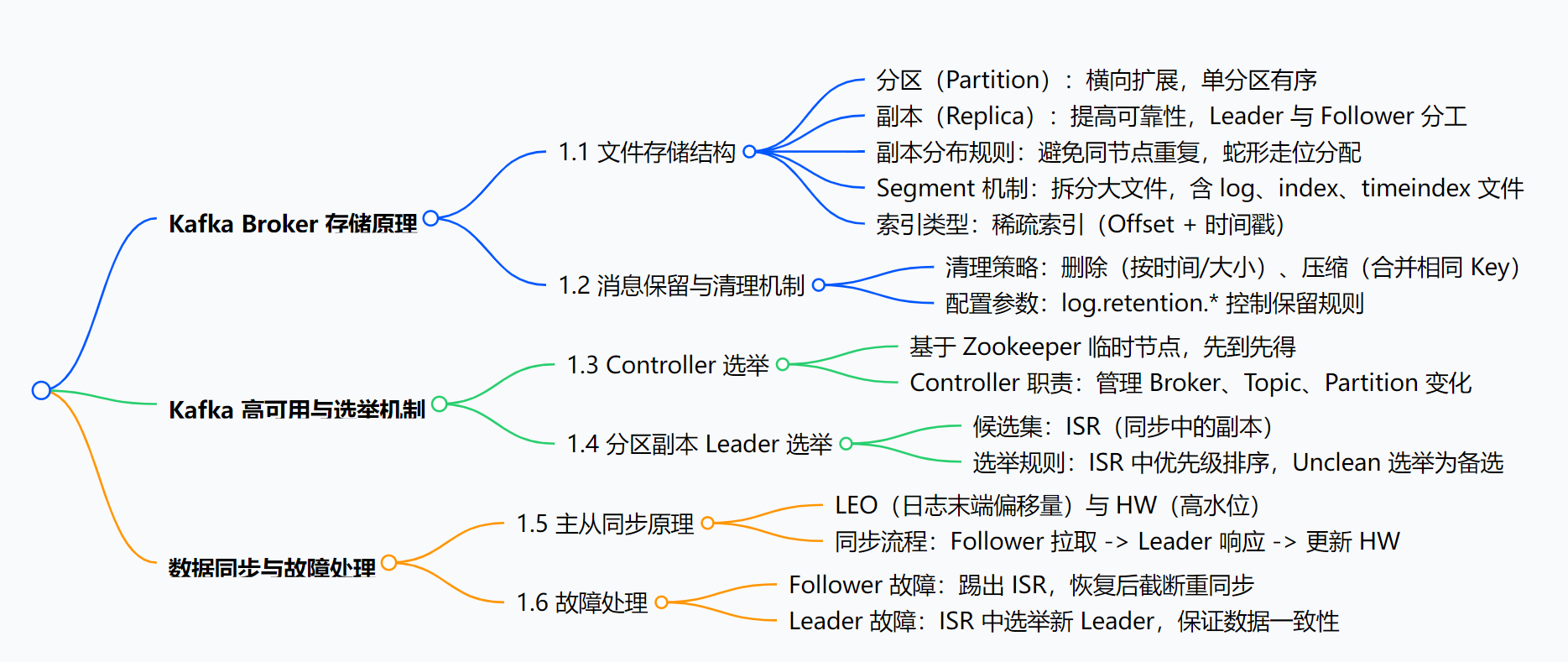
思维导图
正文:Kafka Broker 核心原理深度剖析
Kafka 作为高性能的分布式消息队列,其 Broker 节点的设计是支撑高吞吐、高可用的核心。本文将从存储结构、消息清理、高可用选举、数据同步四个维度,解析 Kafka Broker 的工作原理。
一、Kafka Broker 存储原理:如何高效管理海量消息?
1. 分区与副本:横向扩展与可靠性的基石
-
分区(Partition):
一个 Topic 被拆分为多个 Partition,分布在不同 Broker 上实现横向扩展。单个 Partition 内的消息顺序写入 ,但全局无序。例如
tom-topic可分为 Partition0、Partition1 等,每个分区对应独立的物理目录(如tom-topic-0)。 -
副本(Replica):
为避免单节点故障导致数据丢失,每个 Partition 可设置多个副本(通过
replication-factor配置)。副本分为:-
Leader:对外提供读写服务;
-
Follower:仅从 Leader 异步拉取数据,保持同步。
注意:副本数不能超过 Broker 节点数,否则会报错。
-
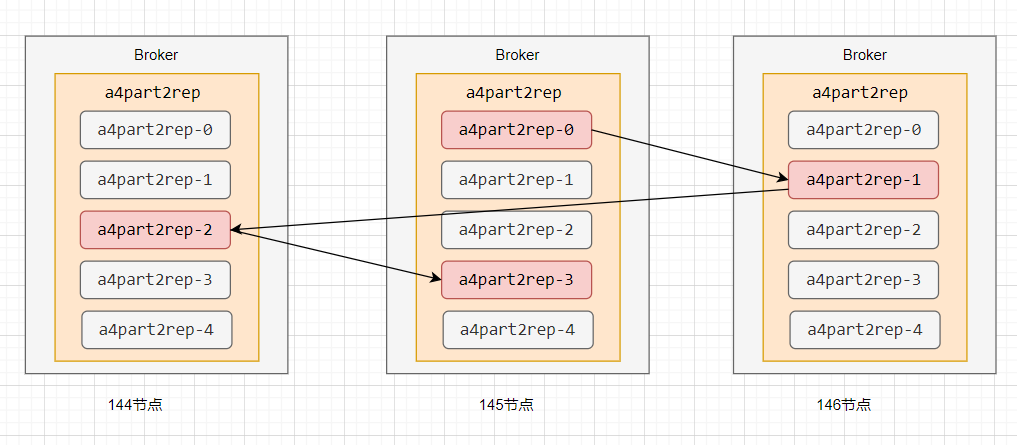
2. 副本分布规则:均衡负载与容灾
Kafka 通过 assignReplicasToBrokers 函数分配副本,核心规则包括:
-
分区 0 的第一个副本随机分配到某个 Broker;
-
其他分区的第一个副本按 "蛇形走位" 分布(如 Broker2→Broker3→Broker1→Broker2...);画图表示 "蛇形走位" ;
-
同一分区的副本必不在同一 Broker,避免单点故障。
例如,4 个分区、2 个副本的 Topic 会将 8 个副本均衡分布到 3 台 Broker 上(3:3:2),确保负载均衡。
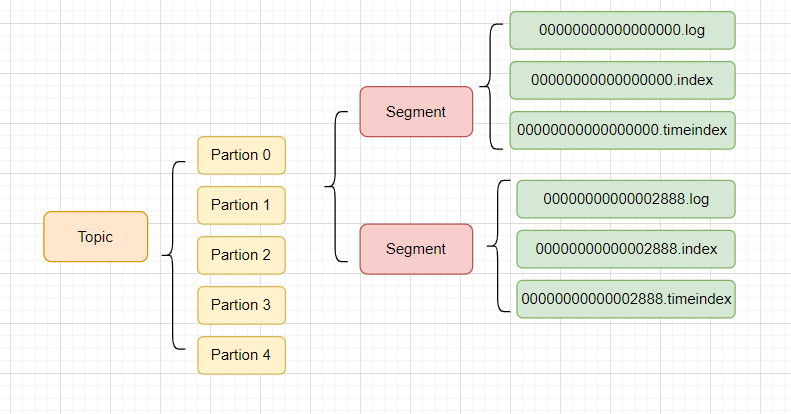
3. Segment 机制:避免文件过大的拆分策略
为防止单个日志文件无限膨胀,Kafka 将每个 Partition 拆分为多个 Segment,每个 Segment 包含:
-
.log:存储消息数据; -
.index:Offset 与消息物理位置的映射(稀疏索引); -
.timeindex:时间戳与 Offset 的映射。
Segment 切分触发条件:
-
大小达到阈值(默认 1G,由
log.segment.bytes控制); -
时间超过阈值(默认 1 周,由
log.roll.hours控制); -
索引文件满(默认 10M,由
log.index.size.max.bytes控制)。
4. 稀疏索引:平衡查询效率与存储成本
Kafka 采用 稀疏索引 (非每条消息都建索引),通过 log.index.interval.bytes(默认 4KB)控制索引密度:每写入 4KB 数据,生成一条索引记录。
-
优势:减少索引文件大小,降低维护成本;
-
查询流程:先通过二分法定位 Segment,再在索引中查找最近 Offset,最后在
.log文件中遍历匹配。
5. 总结
Kafka存储结构:
二、消息保留与清理机制:如何防止磁盘撑爆?
Kafka 通过两种策略管理消息生命周期,可通过 log.cleanup.policy 配置(默认 delete)。
1. 删除策略(Delete)
定时任务(默认每 5 分钟,log.retention.check.interval.ms)触发删除,规则包括:
-
时间阈值 :默认保留 1 周(
log.retention.hours),支持分钟(log.retention.minutes)或毫秒级配置; -
大小阈值 :通过
log.retention.bytes限制总大小,超过后从最旧数据开始删除。
2. 压缩策略(Compact)
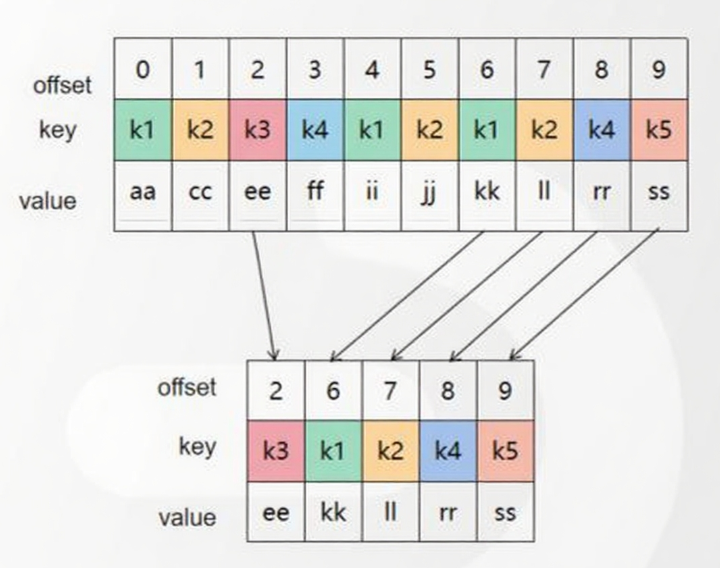
针对 Key 重复的消息(如 __consumer_offsets 主题),压缩后仅保留最新版本。例如:
-
原消息:
k1:aa → k1:ii → k1:kk -
压缩后:仅保留
k1:kk(最新 Offset)。压缩可减少存储空间,但会导致 Offset 不连续(不影响查询)。
三、高可用机制:如何保证服务不中断?
1. Controller 选举:集群的 "管理者"
Kafka 通过 Zookeeper 选举唯一的 Controller 节点,负责管理全集群元数据:
-
选举方式 :所有 Broker 竞争创建 Zookeeper 临时节点
/controller,成功创建者成为 Controller; -
故障转移:若 Controller 宕机,Zookeeper 临时节点消失,其他 Broker 重新竞争。
2. Leader 选举:分区级别的高可用
当 Leader 副本故障时,需从副本中选举新 Leader,核心逻辑如下:
-
候选集 :仅 ISR(In-Sync Replicas) 中的副本有资格(与 Leader 保持同步的副本);
-
选举规则 :ISR 列表中按优先级排序(如副本列表
[146,144,145]中优先选择 146); -
极端情况 :若 ISR 为空,可开启
unclean.leader.election.enable允许 OSR(落后的副本)参选,但可能导致数据丢失。
四、数据同步与故障处理:如何保证数据一致性?
1. 核心概念:LEO 与 HW
-
LEO(Log End Offset):每个副本中下一条待写入消息的 Offset(即当前最大 Offset + 1);
-
HW(High Watermark) :ISR 中所有副本的最小 LEO,消费者只能消费 HW 之前的消息(确保数据已同步到多数副本)。
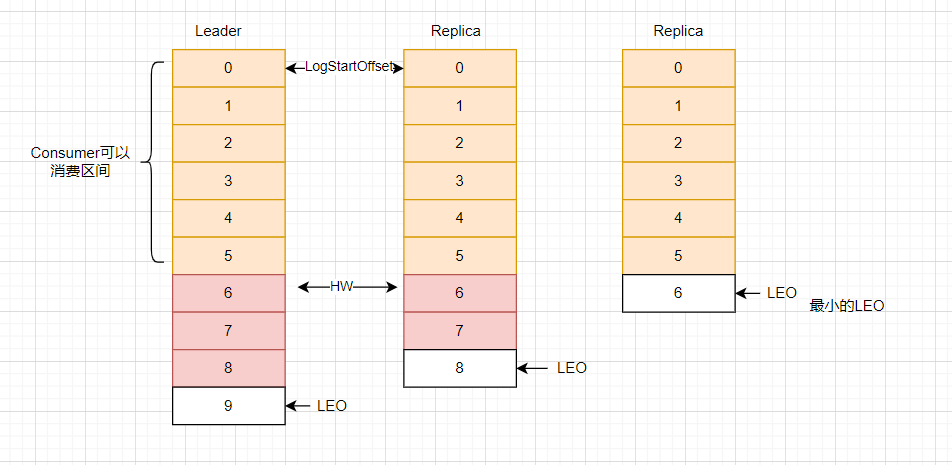
2. 同步流程:Follower 如何追平 Leader?
-
Follower 向 Leader 发送拉取请求(fetch);
-
Leader 响应数据,Follower 写入消息并更新自身 LEO;
-
Leader 收集所有 ISR 副本的 LEO,更新全局 HW。
3. 故障处理机制
-
Follower 故障:
故障时被踢出 ISR,恢复后先截断 HW 之后的消息(避免脏数据),重新同步追上 Leader 后,重新加入 ISR。
-
Leader 故障:
从 ISR 中选举新 Leader,其他 Follower 截断 HW 之后的消息,向新 Leader 同步数据,保证副本一致性。
总结
Kafka Broker 通过分区与副本 实现扩展与可靠性,通过Segment 与稀疏索引 高效管理存储,通过Controller 与 ISR 选举 保障高可用,通过LEO 与 HW 机制确保数据同步一致性。这些设计共同支撑了 Kafka 高吞吐、低延迟、高容错的核心能力,使其成为分布式系统中消息传递的首选方案。