Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop生态系统中的核心资源管理框架,通过解耦资源管理和任务调度,提供了一个通用的分布式计算资源调度平台,使Hadoop从单一的MapReduce框架演进为支持多种计算模式的生态系统。YARN作为Hadoop 2.0版本引入的革命性设计,不仅提高了集群资源利用率,还支持多租户共享和多种计算框架共存,成为现代大数据处理的基础架构。本文将从YARN的基本概念、架构设计、工作流程、关键特性、与同类产品的对比以及实际应用场景等方面进行深入解析,帮助技术开发人员全面理解这一分布式资源管理平台。

一、YARN的基本概念与核心功能
YARN是Apache Hadoop生态系统中的资源管理器,全称为"Yet Another Resource Negotiator"(另一种资源协调者)。作为Hadoop 2.0的核心组件,YARN重新设计了Hadoop的资源管理架构,将原本由MapReduce框架独占的资源管理功能独立出来,为各种计算框架提供统一的资源调度服务。YARN的核心功能包括资源抽象、动态资源分配、任务调度与监控、多租户支持等,其设计目标是提高集群资源利用率,支持多种计算模式,以及简化系统设计。
YARN在Hadoop生态系统中的定位非常关键。在Hadoop 1.0版本中,资源管理与任务调度功能被集成在MapReduce框架的JobTracker组件中,导致扩展性差,难以支持新计算框架。YARN作为独立的资源管理平台,位于HDFS(分布式文件系统)和各种计算框架(如MapReduce、Spark等)之间,通过标准化的资源抽象机制,使不同计算框架能够共享集群资源。这种设计使Hadoop从单一的HDFS+MapReduce模式转变为开放、多元化的生态系统,支持批处理、流处理、交互式查询等多种计算场景 。
YARN的引入为集群带来了三大核心优势:首先,提高了资源利用率 ,通过动态资源分配机制,避免了资源的静态划分和浪费;其次,增强了系统扩展性 ,允许用户根据需求添加新的计算框架,而无需修改底层资源管理逻辑;最后,支持多租户共享集群,通过队列管理和资源隔离机制,确保不同团队或应用能够公平共享集群资源。这些优势使YARN成为现代大数据处理平台不可或缺的组成部分。
二、YARN的诞生背景与MapReduce 1.0的局限性
YARN的诞生源于对Hadoop 1.0版本中MapReduce框架局限性的深刻认识。在Hadoop 1.0时代,MapReduce是唯一支持的大数据处理框架,其JobTracker组件同时承担了资源管理和任务调度两大职责,导致系统在规模扩展和功能灵活性方面存在严重不足 。
MapReduce 1.0的局限性主要体现在以下几个方面:
首先,资源管理与任务调度的耦合导致系统扩展性差。JobTracker作为单一节点,负责整个集群的资源监控和任务分配,随着集群规模扩大,JobTracker成为性能瓶颈,难以支持数千节点的大规模集群。此外,JobTracker的故障会导致整个集群不可用,缺乏高可用性。
其次,资源抽象粒度粗。MapReduce 1.0采用静态的槽位(slot)划分资源,每个槽位固定为CPU和内存的组合,无法根据应用需求动态调整资源分配。这种设计导致资源利用率低,特别是当不同应用对资源需求不同时。
第三,任务调度策略单一。MapReduce 1.0仅支持FIFO(先进先出)调度策略,无法满足多租户、混合负载场景下的资源公平分配需求。随着大数据应用场景的多样化,需要更灵活的调度策略来平衡不同应用的资源需求。
最后,功能受限于MapReduce模型。MapReduce的"分而治之"思想虽然适合批处理场景,但在流处理、迭代计算等新兴场景下表现不佳。随着Spark、Flink等新计算框架的出现,Hadoop生态系统需要一个更通用的资源管理平台来支持这些框架。
正是基于以上局限性,Apache社区决定重新设计Hadoop的资源管理架构,将资源管理与任务调度分离,从而诞生了YARN。YARN的出现不仅解决了MapReduce 1.0的架构问题,还为Hadoop生态系统的扩展奠定了基础,使Hadoop能够适应更广泛的大数据应用场景。
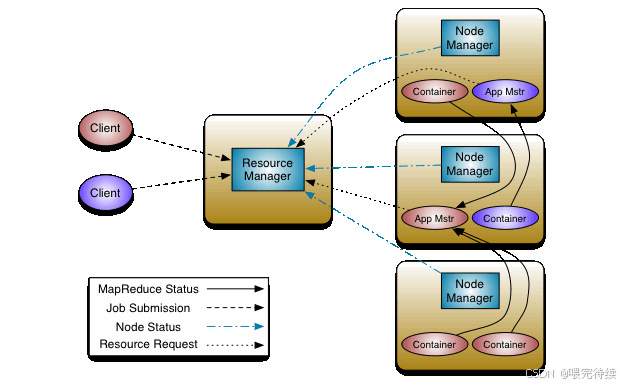
三、YARN的架构设计与组件职责
YARN采用主从(Master-Slave)架构,主要由三个核心组件构成:ResourceManager(RM)、NodeManager(NM)和ApplicationMaster(AM)。这种分层架构设计实现了资源管理与任务调度的分离,使YARN成为一个通用的资源调度平台。
1. 资源管理器(ResourceManager)
ResourceManager是YARN的全局资源管理器,运行在集群的主节点上,负责整个集群的资源监控和分配。RM主要由两个子组件构成:
-
调度器(Scheduler):负责根据应用程序的资源需求和集群资源情况,将资源分配给各个应用程序。调度器不负责应用程序任务的监控和状态反馈,只关注资源分配。
-
应用程序管理器(Applications Manager,ASM):负责接收用户提交的应用程序,启动应用程序的ApplicationMaster,并监督其运行状态。当AM失败时,ASM会提供重启服务。
调度器是YARN的核心组件,支持多种调度策略,包括FIFO Scheduler(先进先出)、Capacity Scheduler(容量调度)和Fair Scheduler(公平调度)。其中,Capacity Scheduler通过队列划分资源,保证不同团队或应用的资源隔离;Fair Scheduler则动态平衡资源,确保所有应用程序公平共享资源。用户可以根据需求选择合适的调度器,或实现自定义调度器 。
2. 节点管理器(NodeManager)
NodeManager是每个工作节点上的资源和任务管理代理,负责管理本节点上的资源(CPU、内存等)。NM的主要职责包括:
-
资源汇报:定期向RM发送心跳,汇报本节点的可用资源和已分配资源的使用情况。
-
Container生命周期管理:根据AM的请求,启动或停止Container,并监控其运行状态。
-
任务执行环境配置:为每个任务配置运行环境(如环境变量、JAR包、二进制程序等)。
NodeManager通过心跳机制与RM保持通信,心跳频率通常为几秒钟一次,确保RM能够及时了解集群状态变化 。当NM检测到节点故障或资源不足时,会向RM发送相应信号,触发资源重新分配。
3. 应用程序管理器(ApplicationMaster)
ApplicationMaster是用户应用程序的专属协调者,由每个应用程序在提交时创建,负责协调应用程序的资源请求、任务分配和监控。AM的主要职责包括:
-
资源协商:向RM申请资源(以Container形式表示),并根据应用程序需求动态调整资源请求。
-
任务分配:将获得的资源进一步分配给应用程序内部的各个任务,决定任务的执行位置和方式。
-
任务监控:与NM协作启动任务,并监控任务运行状态,当任务失败时重新申请资源重启任务。
-
进度与状态汇报:向客户端汇报应用程序的进度和状态,客户端通过与AM交互获取详细信息。
YARN的架构设计采用了双层调度机制 :第一层由RM的调度器负责将资源分配给应用程序;第二层由AM负责将获得的资源分配给应用程序内部的具体任务 。这种设计使YARN能够同时支持全局资源管理和应用级任务调度,提高了系统的灵活性和可扩展性。
下表详细列出了YARN三大组件的职责与通信关系:
| 组件 | 主要职责 | 通信对象 | 通信协议 |
|---|---|---|---|
| ResourceManager | 全局资源监控与分配 接收应用程序提交 启动ApplicationMaster | NodeManager ApplicationMaster | ResourceTracker ApplicationMasterProtocol |
| NodeManager | 资源汇报 Container生命周期管理 任务执行环境配置 | ResourceManager | ResourceTracker |
| ApplicationMaster | 应用程序资源协商 任务分配与监控 进度与状态汇报 | ResourceManager<br NodeManager | ApplicationMasterProtocol ContainerManagementProtocol |
4. 资源抽象机制:Container
YARN的核心资源抽象是Container,它封装了某个节点上的多维度资源,如内存、CPU等。与MapReduce 1.0中的固定槽位不同,YARN的Container是动态资源划分单位,可以根据应用程序的需求灵活调整资源量。当AM向RM申请资源时,RM返回的资源即以Container形式表示,每个任务只能使用其Container中描述的资源。
Container包含以下关键信息:
-
优先级:任务的执行优先级 。
-
期望节点:任务希望运行的节点 。
-
资源量:所需的CPU和内存资源 。
-
Container数目:所需的Container数量。
-
是否松弛本地性:是否接受非本地数据的Container 。
YARN通过Linux Cgroups实现资源隔离,确保不同应用程序和任务之间的资源使用不会互相干扰。Cgroups提供了一种轻量级的资源隔离机制,可以限制应用程序对CPU、内存等资源的使用。
四、YARN解决的核心问题与工作流程
YARN解决了Hadoop 1.0版本中MapReduce框架面临的几个核心问题:
1. 资源管理与任务调度的耦合
YARN将资源管理与任务调度分离,RM专注于全局资源分配,AM专注于应用级任务调度。这种分离使系统能够独立优化资源管理和任务调度逻辑,提高了系统的灵活性和可扩展性。
2. 资源利用率低
通过动态资源分配机制,YARN能够根据应用程序的需求灵活分配资源,避免了MapReduce 1.0中槽位固定导致的资源浪费。YARN的Container机制允许应用程序按需申请资源 ,提高了集群的整体资源利用率。
3. 功能受限于单一计算框架
YARN提供了通用的资源调度接口,使各种计算框架(如MapReduce、Spark、Flink等)能够共享集群资源。这种设计使Hadoop生态系统能够扩展到支持多种计算模式,满足不同应用场景的需求。
4. 多租户支持不足
YARN通过队列管理和资源隔离机制,支持多租户共享集群,确保不同团队或应用能够公平使用集群资源。用户可以根据需求配置不同的队列,为不同团队或应用分配特定的资源配额和优先级。
YARN的工作流程可以分为以下几个主要阶段:
-
应用程序提交:用户将应用程序提交到YARN,其中包括用户程序、启动AM的命令等内容 。
-
启动ApplicationMaster:ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求其启动应用程序的AM 。
-
资源申请与分配:AM向RM注册后,开始为应用程序的各个任务申请资源。AM采用轮询的方式,通过RPC协议向RM申请和领取资源 。
-
任务执行与监控:当AM申请到资源后,会与对应的NM通信,要求其启动任务 。NM为任务配置运行环境后,将任务启动命令写入脚本并执行 。任务运行过程中,定期向AM汇报状态和进度,以便AM监控任务执行情况并处理失败任务 。
-
应用程序完成:当应用程序的所有任务完成后,AM向RM申请注销并关闭自己,释放占用的资源 。
YARN采用拉式(pull-based)通信模型,资源分配过程是异步的。RM调度器将资源分配给应用程序后,不会立即推送给对应的AM,而是暂时放到缓冲区,等待AM通过周期性的心跳来取 。这种设计减少了RM的负载,提高了系统的可扩展性。
五、YARN的关键特性与优势
YARN作为Hadoop 2.0的核心资源管理框架,具有以下关键特性与优势:
1. 高吞吐量资源调度
YARN可以每秒调度超过1000个容器,适合处理大规模数据集和高并发任务。这种高性能调度能力使YARN能够快速响应应用程序的资源需求,减少任务等待时间,提高整体系统吞吐量。
2. 动态资源分配
YARN支持两种资源请求模式:静态模式和动态模式 。静态模式适用于资源需求在应用程序提交时确定的场景;动态模式则允许应用程序在运行时根据实际需求调整资源请求,提高了资源使用的灵活性和效率 。
3. 多框架支持
YARN为各种计算框架提供统一的资源调度服务,包括MapReduce、Spark、Flink、Hive等。这种设计使用户可以在同一集群上运行多种计算框架,避免了为每种框架单独维护集群的开销,提高了资源利用率和系统管理效率。
4. 层级队列管理
YARN原生支持层级队列管理,用户可以根据组织结构或业务需求创建多级队列,并为每个队列分配特定的资源配额和优先级。这种设计使YARN能够支持多租户共享集群 ,确保不同团队或应用能够公平使用集群资源,同时可以根据业务需求进行资源优先级调整。
5. 资源弹性扩展
YARN支持资源弹性扩展,允许应用程序在运行过程中动态调整资源需求 。当应用程序需要更多资源时,AM可以向RM申请额外的Container;当资源过剩时,应用程序可以释放多余的资源,供其他应用使用。这种弹性设计提高了资源利用率,减少了资源浪费。
6. 支持混合负载
YARN能够同时处理批处理、流处理、交互式查询等多种类型的计算任务,使集群能够应对复杂的混合负载场景。通过合理配置调度策略和队列,用户可以确保不同负载类型之间的资源公平分配,提高集群的整体利用率。
7. 高可用性设计
YARN支持高可用性(HA)模式,通过主备RM和ZooKeeper协调,避免了单点故障问题 。当主RM故障时,备用RM可以快速接管,确保集群的持续可用性,提高了系统的可靠性和稳定性。
8. 安全认证机制
YARN支持多种安全认证机制,包括Kerberos、SASL消化-MD5认证等 。这些机制确保了组件之间的安全通信,防止未授权访问和恶意操作,提高了系统的安全性。
六、YARN与同类产品的对比
YARN作为分布式资源管理平台,与Kubernetes、Mesos等产品有相似之处,但也存在显著差异。这些差异主要源于设计目标、适用场景和架构设计的不同。
1. YARN与Kubernetes对比
YARN和Kubernetes都是分布式资源管理平台,但它们的设计目标和适用场景有所不同:
-
设计目标 :YARN专注于大数据处理场景,优化了对数据密集型应用的支持;Kubernetes则专注于容器编排,优化了对微服务和云原生应用的支持。
-
调度性能:YARN可以每秒调度超过1000个容器,适合处理大规模数据集和高并发任务;Kubernetes因依赖etcd存储大量数据,调度性能受限,每秒只能调度约100个容器。
-
资源管理粒度:YARN以Container为单位管理资源,支持CPU和内存的动态分配;Kubernetes以Pod为单位管理资源,支持更细粒度的资源类型(如GPU显存)。
-
队列管理:YARN原生支持层级队列管理,适合多租户共享集群;Kubernetes需要依赖第三方工具(如YuniKorn)实现类似功能。
-
生态集成 :YARN深度集成Hadoop生态系统(如HDFS、Spark、Hive等),为这些框架提供无缝的资源调度支持 ;Kubernetes则需要这些框架进行额外适配才能在Kubernetes上运行。
2. YARN与Mesos对比
YARN和Mesos都是通用的分布式资源管理平台,但它们的架构和调度策略有所不同:
-
架构设计:YARN采用双层调度架构(全局RM调度+应用级AM调度),调度决策集中在RM;Mesos采用双层调度架构(资源调度器+框架调度器),资源调度器仅将可用资源推送给各个框架,由框架决定是否接受和使用这些资源。
-
资源分配模式:YARN采用拉式模式,应用程序主动向RM申请资源;Mesos采用推式模式,资源调度器将资源推送给各个框架,由框架决定是否接受。
-
资源隔离机制:YARN依赖Linux Cgroups实现资源隔离;Mesos支持更细粒度的资源类型(如GPU显存),但资源隔离机制相对简单。
-
调度策略:YARN支持多种调度策略(如FIFO、Capacity、Fair),用户可以根据需求选择或实现自定义调度器;Mesos的调度策略相对固定,用户需要通过框架调度器实现自定义逻辑。
-
生态集成 :YARN深度集成Hadoop生态系统,为这些框架提供优化的资源调度支持 ;Mesos则需要这些框架进行额外适配才能在Mesos上运行。
3. YARN与Slurm对比
YARN和Slurm都是集群资源管理系统,但它们的适用场景和设计重点有所不同:
-
适用场景:YARN专注于大数据处理和分布式计算场景;Slurm则专注于高性能计算(HPC)场景,优化了对计算密集型任务的支持。
-
资源管理粒度:YARN以Container为单位管理资源,适合处理大规模数据集和高并发任务;Slurm以作业为单位管理资源,适合处理长时间运行的计算密集型任务。
-
调度策略:YARN支持多种调度策略,适合处理混合负载场景;Slurm专注于优化作业调度,适合处理单一批次的计算任务。
-
生态集成:YARN深度集成Hadoop生态系统,为这些框架提供资源调度支持;Slurm则与HPC生态系统集成紧密,适合处理科学计算和工程模拟等任务。
YARN在大数据处理领域具有明显优势,其高性能调度、层级队列管理和对Hadoop生态系统的深度集成使其成为数据工程领域的首选。然而,对于需要细粒度GPU资源管理或长期运行的应用,Kubernetes可能更具优势。用户可以根据具体应用场景和需求选择合适的资源管理平台。
七、YARN的资源抽象与扩展能力
YARN的资源抽象机制是其灵活性和可扩展性的关键。YARN将物理资源抽象为逻辑资源单位(Container) ,允许应用程序根据需求动态申请和释放资源。这种设计使YARN能够适应不同计算框架的需求,提高集群资源利用率。
1. 资源类型支持
YARN的核心资源抽象是Container,它封装了某个节点上的多维度资源。在YARN的早期版本中,主要支持内存和CPU两种资源类型,这是数据密集型应用的主要资源需求。随着Hadoop 3.0版本的发布,YARN开始支持GPU和FPGA等异构计算资源 。
然而,YARN对GPU等异构资源的支持仍然存在局限性:
-
粗粒度分配:YARN将GPU作为整块设备分配给应用程序,无法实现同一GPU上多个任务的共享 。这种设计虽然简单,但可能导致资源浪费,特别是在处理中小型GPU任务时。
-
依赖第三方工具:由于CUDA在Java语言方面的不足,YARN需要依赖第三方监视框架来监控GPU的使用状况 。
-
资源隔离机制:YARN通过Linux Cgroups对GPU进行限制,也支持通过Docker进行资源限制 。这种设计虽然能够实现基本的资源隔离,但不如Kubernetes的容器化隔离机制灵活。
2. 资源模型的双重表示
为了更好地管理异构资源,YARN采用了资源模型的双重表示机制 :
-
实际资源状态:表示集群中实际在用的资源状态,由各节点的资源汇报进程汇总得出。
-
逻辑资源状态:表示应用程序所需最小资源的总和,作为任务调度的标准 。
这种设计使YARN能够在资源弹性分配的情况下,更合理地判断队列是否能够满足新任务的需求,避免资源过度分配或不足的问题 。
3. 扩展能力与未来方向
YARN的架构设计使其具有良好的扩展能力:
-
可插拔调度器:用户可以根据需求实现自定义调度器,只需继承AbstractYarnScheduler抽象类并实现调度器接口规范 。
-
事件驱动模型:RM调度器采用事件驱动的编程模型,处理多种类型的事件(如NODE_REMOVED、NODE_ADDED、APPLICATION_ADDED等),通过状态机管理资源状态 。
-
标签化资源管理:YARN支持通过物理标注方法,为挂载不同计算资源的机器打上不同的标签,并依据标签将集群划分为不同的逻辑集群 。例如,可以为没有计算加速部件的节点打上normal标签,为带有GPU的节点打上gpu标签。
YARN的未来发展方向包括对GPU等异构资源的细粒度管理 ,以及与容器技术(如Docker)的更深度集成。目前,学术界对GPU资源的细粒度管理已有研究,包括时间分片(多个Kernel函数依次共享计算资源)和空间分片(将GPU按照流多处理器粒度进行调度)两种方式 。这些研究为YARN的资源管理能力提供了潜在的改进方向。
八、YARN的实际应用场景
YARN的通用性和高性能使其适用于多种大数据处理场景。以下是YARN的几个典型应用场景:
1. 混合负载集群
YARN能够同时处理批处理、流处理、交互式查询等多种类型的计算任务,使集群能够应对复杂的混合负载场景。例如,一个企业可以在同一YARN集群上同时运行MapReduce批处理作业、Spark Streaming流处理任务和Hive交互式查询,根据业务需求动态调整资源分配。
2. GPU加速的大数据任务
随着深度学习和机器学习的普及,YARN支持GPU资源分配,为需要GPU加速的数据处理任务提供支持 。虽然YARN对GPU的支持是粗粒度的,但通过节点标签划分和资源隔离机制,可以确保GPU资源的合理使用。例如,可以将带有GPU的节点划分为一个逻辑集群,专门处理需要GPU加速的任务。
3. 企业级多租户环境
YARN的层级队列管理和资源隔离机制使其非常适合企业级多租户环境 。企业可以根据部门或团队创建多级队列,并为每个队列分配特定的资源配额和优先级。这种设计确保了不同团队或应用能够公平使用集群资源,同时可以根据业务需求进行资源优先级调整。
4. 流数据处理
YARN为流数据处理框架(如Storm、Flink)提供了资源调度支持。通过动态资源调度和容器管理,YARN可以有效支持需要弹性资源的流数据处理任务 。例如,可以设计基于实时负载的动态资源调度模型,根据流数据处理的延迟情况实时调整集群资源分布,有效减小系统延迟。
5. 分布式机器学习
YARN支持分布式机器学习框架(如Spark MLlib、TensorFlow on YARN)的资源调度。通过为机器学习任务分配足够的内存和CPU资源,YARN可以加速模型训练和推理过程。可以为大规模数据集的机器学习任务分配更多的内存资源,提高模型训练效率。
九、YARN的使用方法与最佳实践
YARN提供了多种使用方式,包括命令行工具、Java API和REST API等。以下是YARN的使用方法和最佳实践:
1. 基本命令行操作
YARN提供了丰富的命令行工具,用户可以通过以下命令查看YARN用法和帮助:
yarn --help常用的YARN命令包括:
yarn top:列出当前正在运行的YARN应用程序及其状态。
yarn application -list:显示所有应用程序的详细信息。
yarn application -kill <application-id>:终止指定的应用程序。
yarn application -status <application-id>:查看指定应用程序的运行状态。
yarn logs -application-id <application-id>:获取应用程序的聚合日志。
2. 提交应用程序
用户可以通过命令行提交应用程序到YARN集群:
XML
配置和启动 HDFS 和 YARN 组件
<property>
<description>
Enable services rest api on ResourceManager.
</description>
<name>yarn.webapp.api-service.enable</name>
<value>true</value>
</property>
示例服务
{
"name": "sleeper-service",
"version": "1.0",
"components" :
[
{
"name": "sleeper",
"number_of_containers": 1,
"launch_command": "sleep 900000",
"resource": {
"cpus": 1,
"memory": "256"
}
}
]
}
可以使用以下命令在 YARN 上简单地运行预构建的示例服务:
yarn app -launch <service-name> <example-name>
yarn app -launch my-sleeper sleeper提交一个MapReduce作业:
yarn jar /path/to/example.jar org.apache.hadoop mapreduce.example WordCount /input/path /output/path3. 配置与调优
YARN的性能和行为可以通过配置文件进行调优。主要的配置文件包括:
yarn-site.xml:定义YARN的全局配置参数。
mapred-site.xml:定义MapReduce应用程序的配置参数。
capacity-scheduler.xml:配置Capacity Scheduler的队列和资源分配策略。
XML
<!-- yarn-site.xml核心配置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>rm-host</value> <!-- ResourceManager主机名 -->
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value> <!-- 每个节点可用内存(MB) -->
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value> <!-- 每个节点可用CPU核心数 -->
</property>YARN的调优主要集中在资源分配策略、队列配置和容器大小设置等方面 。用户可以根据应用程序的特点和集群规模,调整这些参数以优化YARN的性能。
4. 安全配置
YARN支持多种安全认证机制,包括Kerberos、SASL消化-MD5认证等 。用户可以通过配置yarn-site.xml中的相关参数启用这些安全机制,确保YARN集群的安全性。
5. 监控与诊断
YARN提供了多种监控和诊断工具,帮助用户了解集群状态和应用程序性能:
-
YARN Web UI:提供图形化界面,显示集群状态、应用程序列表和详细信息。
-
YARN REST API:允许用户通过编程方式获取集群状态和应用程序信息。
-
日志聚合功能:聚合工作节点上所有容器的日志,存储在默认文件系统中,便于问题排查。
-
资源监控工具:如Ganglia、Prometheus等,可以监控YARN集群的资源使用情况。
YARN的监控与诊断是确保集群高效运行的关键。用户应该定期检查集群状态,分析应用程序性能,及时发现和解决潜在问题。
十、YARN的局限性与发展趋势
尽管YARN在大数据处理领域表现出色,但仍存在一些局限性:
1. 局限性
-
不支持低延迟任务:YARN的调度策略对实时计算(如低延迟流处理)支持较弱,任务调度延迟较高。
-
资源隔离依赖Container:YARN的资源隔离机制(Cgroups)虽然有效,但不如容器技术(如Docker)灵活,特别是在处理非Hadoop生态系统的应用时。
-
GPU资源管理粗粒度:YARN对GPU等异构资源的支持是粗粒度的,无法实现同一GPU上多个任务的共享,可能导致资源浪费 。
-
生态局限性:YARN深度集成Hadoop生态系统,但对非Hadoop生态系统的应用支持相对有限。
2. 发展趋势
-
细粒度资源管理:未来YARN可能会支持更细粒度的资源管理,如GPU显存、FPGA资源等,提高资源利用率 。
-
与容器技术的深度集成:YARN可能会与Docker等容器技术更深度集成,提供更灵活的应用部署和资源隔离机制。
-
混合云支持:YARN可能会增强对混合云环境的支持,允许应用程序在跨云集群上运行和调度。
-
智能化调度:YARN可能会引入更多智能化调度算法,如基于机器学习的资源预测和动态调整,提高集群的整体性能和利用率。
YARN作为Hadoop生态系统的资源管理平台,将继续演进以适应不断变化的大数据处理需求。随着Hadoop生态系统的扩展和云原生技术的发展,YARN可能会在保持其核心优势的同时,增强对异构资源和新应用场景的支持,进一步巩固其在数据工程领域的地位。
十一、总结与展望
Apache Hadoop YARN作为分布式资源管理平台,通过解耦资源管理和任务调度,提供了一个通用的资源调度框架,使Hadoop生态系统能够支持多种计算模式,满足不同应用场景的需求。YARN的核心优势在于其高性能调度、层级队列管理和对Hadoop生态系统的深度集成,使其成为数据工程领域的首选资源管理平台。
在实际应用中,YARN能够有效支持混合负载集群、GPU加速的大数据任务、企业级多租户环境等多种场景,提高了集群资源利用率和系统整体性能。然而,YARN在低延迟任务支持、资源隔离机制和异构资源管理方面仍存在局限性,需要进一步优化和扩展。
随着大数据技术的发展和云原生架构的普及,YARN可能会在以下几个方向继续演进:
首先,YARN可能会增强对GPU等异构资源的支持 ,实现细粒度资源管理和共享,提高资源利用率。其次,YARN可能会与容器技术(如Docker)更深度集成,提供更灵活的应用部署和资源隔离机制。最后,YARN可能会引入更多智能化调度算法,如基于机器学习的资源预测和动态调整,提高集群的整体性能和利用率。
对于技术开发人员来说,深入理解YARN的架构设计、工作流程和关键特性,不仅有助于更好地利用YARN平台,还能为构建更高效的分布式计算系统提供有价值的参考。随着YARN的不断演进,它将继续在大数据处理领域发挥重要作用,成为连接数据存储(如HDFS)和计算框架(如Spark、Flink)的桥梁,推动大数据技术的发展和应用。