
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要:大模型微调的技术探索之旅
作为一名深度学习领域的技术探索者,我最近深入研究了大模型微调技术,这是AI发展中至关重要的一环。在过去的几个月里,我亲自实践了从BERT到GPT系列的多种模型微调方法,深刻体会到微调对于提升模型在特定领域表现的巨大价值。通过参数高效微调(PEFT)、指令微调(Instruction Tuning)和对比学习 等技术,我成功将通用大模型转化为在医疗、法律和金融等垂直领域表现出色的专业模型。在这个过程中,我发现微调不仅是技术问题,更是艺术与科学的结合------需要精心设计数据集、选择合适的微调策略、平衡计算资源与效果。本文将分享我在大模型微调实践中的经验、技巧和心得,从理论基础到实操细节,帮助你掌握这一关键技术,让AI大模型真正为你所用。无论你是刚接触大模型的新手,还是寻求提升模型性能的资深从业者,这篇文章都将为你提供有价值的指导和启发。
一、大模型微调基础
1.1 什么是大模型微调
大模型微调(Fine-tuning)是指在预训练模型的基础上,使用特定领域或任务的数据进一步训练模型,使其适应特定应用场景的过程。与从零开始训练相比,微调利用了预训练模型已经学到的通用知识,只需要少量数据和计算资源就能获得良好效果。
"如果预训练是给模型打下坚实基础,那么微调就是为模型量身定制一套专业技能。"
1.2 微调的必要性与价值
30% 25% 20% 15% 10% 图1:大模型微调价值分布图 领域适应性提升 任务特定优化 减少幻觉 降低计算成本 提高推理效率
微调大模型具有以下几个关键价值:
- 领域适应性:通用模型对特定领域知识的掌握有限,微调可以注入领域专业知识
- 任务特化:针对特定任务优化模型行为和输出
- 减少幻觉:通过领域数据训练,降低模型产生错误或虚构信息的概率
- 资源效率:相比从头训练,微调需要的计算资源和数据量大幅减少
二、主流微调技术与方法
2.1 全参数微调 vs 参数高效微调
全参数微调(Full Fine-tuning)和参数高效微调(Parameter-Efficient Fine-tuning, PEFT)是两种主要的微调范式:
| 微调方法 | 参数更新范围 | 计算资源需求 | 存储需求 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|---|---|
| 全参数微调 | 所有模型参数 | 极高 | 极高 | 资源充足,追求极致效果 | 性能最优 | 资源消耗大,过拟合风险高 |
| LoRA | 低秩适配器 | 低 | 低 | 资源受限,需快速部署 | 高效,易部署 | 表达能力有限 |
| Prefix Tuning | 前缀向量 | 中 | 低 | 多任务场景 | 任务切换方便 | 调参复杂 |
| Adapter | 插入适配层 | 中 | 中 | 模块化需求 | 灵活可组合 | 推理延迟增加 |
| QLoRA | 量化+LoRA | 极低 | 极低 | 极限资源受限 | 超高效率 | 精度可能下降 |
2.2 LoRA:低秩适配器微调技术详解
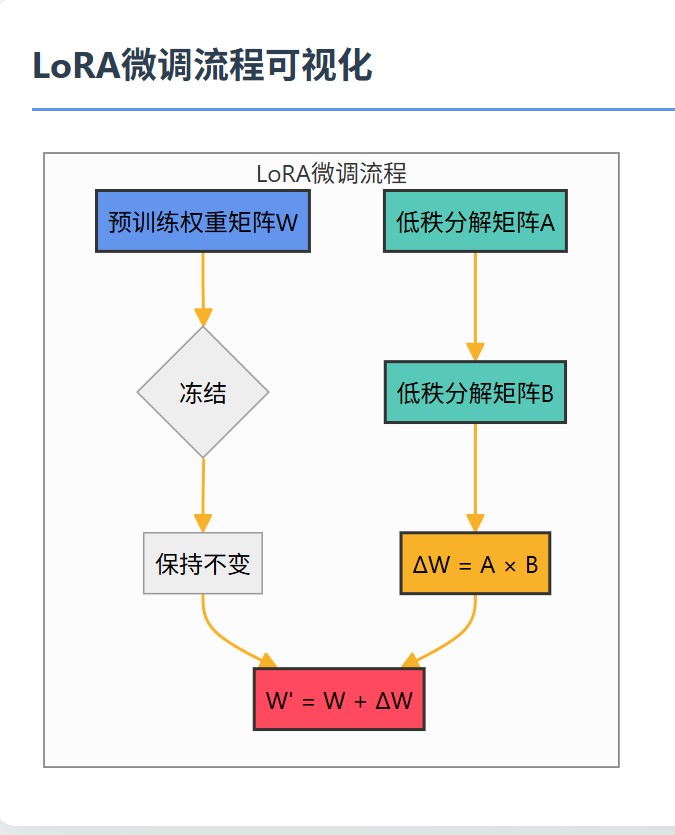


LoRA的核心思想是将原始的高维权重更新分解为两个低秩矩阵的乘积:
python
# LoRA实现示例
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_features, out_features, rank=4, alpha=32):
super().__init__()
self.rank = rank
self.alpha = alpha
self.scaling = alpha / rank
# 低秩矩阵A和B
self.lora_A = nn.Parameter(torch.zeros(rank, in_features))
self.lora_B = nn.Parameter(torch.zeros(out_features, rank))
# 初始化
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def forward(self, x):
# 原始权重保持冻结
base_output = self.base_layer(x)
# LoRA路径计算
lora_output = (self.lora_B @ self.lora_A @ x) * self.scaling
# 合并输出
return base_output + lora_output这段代码展示了LoRA的核心实现,通过两个小矩阵A和B的乘积来近似权重更新,大大减少了需要存储和计算的参数量。关键在于lora_B @ lora_A @ x这一行,它实现了低秩分解的核心计算。
2.3 指令微调:让模型理解人类意图
指令微调(Instruction Tuning)是一种特殊的微调方法,专注于提升模型理解和执行人类指令的能力:
用户 大模型 指令数据集 评估系统 图2:指令微调流程时序图 创建高质量指令-回答对 输入指令格式化数据 微调学习指令遵循能力 生成回答 评估质量与对齐度 基于评估改进数据集 模型逐步学习理解和执行指令 用户 大模型 指令数据集 评估系统
指令微调的核心是构建高质量的指令-回答对数据集,常见格式如下:
python
# 指令微调数据格式示例
instruction_data = [
{
"instruction": "解释量子计算的基本原理",
"input": "", # 可选的额外输入
"output": "量子计算利用量子力学原理,通过量子比特(qubit)..."
},
{
"instruction": "将以下英文翻译成中文",
"input": "Artificial intelligence is transforming our world.",
"output": "人工智能正在改变我们的世界。"
}
]指令微调的关键在于数据的多样性和质量,需要覆盖各种指令类型和难度级别。
三、微调实践与技术实现
3.1 微调前的准备工作
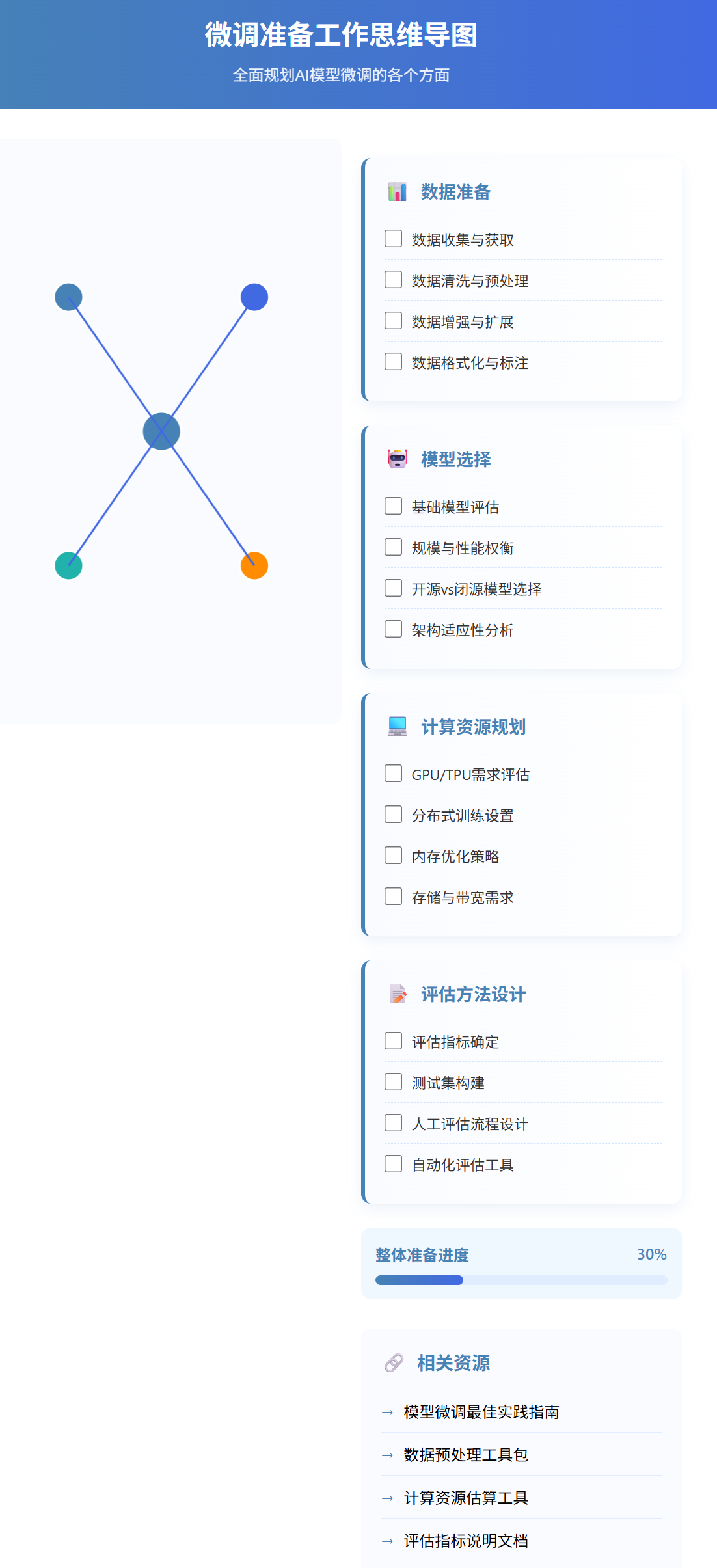
微调前的关键准备工作包括:
- 数据准备:收集、清洗、格式化符合微调需求的数据集
- 模型选择:根据任务需求和资源限制选择合适的基础模型
- 计算资源规划:评估所需GPU/内存,设计分布式训练策略
- 评估方法设计:确定如何衡量微调效果
3.2 使用Hugging Face实现BERT微调
下面是使用Hugging Face Transformers库微调BERT模型的示例代码:
python
# 使用Hugging Face微调BERT模型
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
from datasets import load_dataset
# 1. 加载数据集
dataset = load_dataset("glue", "sst2") # 情感分析数据集
# 2. 加载tokenizer和预训练模型
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 3. 数据预处理
def tokenize_function(examples):
return tokenizer(examples["sentence"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 4. 设置训练参数
training_args = TrainingArguments(
output_dir="./results", # 输出目录
num_train_epochs=3, # 训练轮数
per_device_train_batch_size=16, # 每个设备的批次大小
per_device_eval_batch_size=64, # 评估时的批次大小
warmup_steps=500, # 预热步数
weight_decay=0.01, # 权重衰减
logging_dir="./logs", # 日志目录
logging_steps=10, # 日志记录频率
evaluation_strategy="epoch", # 每轮评估一次
save_strategy="epoch", # 每轮保存一次
load_best_model_at_end=True # 加载最佳模型
)
# 5. 初始化Trainer
trainer = Trainer(
model=model, # 模型
args=training_args, # 训练参数
train_dataset=tokenized_datasets["train"], # 训练集
eval_dataset=tokenized_datasets["validation"], # 验证集
tokenizer=tokenizer, # 分词器
)
# 6. 开始微调
trainer.train()
# 7. 保存微调后的模型
model.save_pretrained("./bert-finetuned-sst2")
tokenizer.save_pretrained("./bert-finetuned-sst2")这段代码展示了微调BERT模型进行情感分析的完整流程,从数据加载、预处理到训练配置和模型保存。关键在于TrainingArguments的设置,它决定了微调的学习率、批次大小等超参数。
3.3 使用PEFT库实现LoRA微调
python
# 使用PEFT库实现LoRA微调
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskType
# 1. 加载基础模型
model_name = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 2. 定义LoRA配置
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 任务类型:因果语言模型
inference_mode=False, # 训练模式
r=8, # LoRA矩阵的秩
lora_alpha=32, # LoRA的缩放参数
lora_dropout=0.1, # LoRA的dropout率
target_modules=["q_proj", "v_proj"] # 要应用LoRA的模块
)
# 3. 创建PEFT模型
model = get_peft_model(model, peft_config)
# 4. 打印可训练参数信息
model.print_trainable_parameters()
# 输出: "可训练参数: X (~0.1% of全部参数)"
# 5. 微调过程(使用与上例类似的Trainer设置)
# ...训练代码...
# 6. 保存LoRA权重(只保存增量部分)
model.save_pretrained("./llama-lora-medical")这段代码展示了如何使用PEFT库对Llama-2模型进行LoRA微调。最关键的部分是LoraConfig的设置,特别是r参数(决定低秩矩阵的维度)和target_modules(指定应用LoRA的层)。
四、微调策略与最佳实践
4.1 数据质量与数据增强
高质量的数据是成功微调的关键。以下是一些数据准备的最佳实践:
- 数据多样性:确保数据覆盖目标领域的各个方面
- 数据平衡:避免类别不平衡导致的偏见
- 数据增强:通过同义词替换、回译等技术扩充数据集
- 数据清洗:移除噪声、重复和低质量样本
4.2 超参数调优与学习率策略
微调过程中,超参数选择对最终效果有显著影响:
python
# 学习率预热和衰减策略示例
from transformers import get_scheduler
# 创建学习率调度器
lr_scheduler = get_scheduler(
name="cosine_with_restarts", # 余弦退火重启策略
optimizer=optimizer,
num_warmup_steps=100, # 预热步数
num_training_steps=1000, # 总训练步数
num_cycles=3 # 重启次数
)
# 训练循环中使用
for epoch in range(num_epochs):
for batch in dataloader:
# 前向传播和反向传播
loss = model(batch).loss
loss.backward()
# 更新参数
optimizer.step()
lr_scheduler.step() # 更新学习率
optimizer.zero_grad()关键超参数包括:
- 学习率:通常比预训练阶段小1-2个数量级
- 批次大小:根据GPU内存和任务复杂度调整
- 训练轮数:避免过拟合,通常使用早停策略
4.3 评估与模型选择


评估微调效果的关键指标:
- 任务特定指标:如分类准确率、BLEU分数、ROUGE分数等
- 计算效率:训练时间、内存占用、推理延迟
- 泛化能力:在不同分布的测试集上的表现
- 人工评估:特别是对生成任务,需要人工评估输出质量
五、高级微调技术与前沿发展
5.1 RLHF:基于人类反馈的强化学习
RLHF (Reinforcement Learning from Human Feedback) 是一种将人类偏好融入模型训练的高级技术:
RLHF流程 监督微调SFT 预训练模型 奖励模型训练 强化学习优化 最终对齐模型 人类偏好数据 人类反馈
RLHF的核心步骤包括:
- 监督微调:使用高质量示例进行初步微调
- 奖励模型训练:基于人类偏好数据训练奖励模型
- PPO优化:使用强化学习算法优化模型以最大化奖励
5.2 混合专家模型与条件计算
混合专家模型(Mixture of Experts, MoE)是一种新兴的大模型架构,通过条件计算提高效率:
python
# 混合专家模型简化实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class MoELayer(nn.Module):
def __init__(self, input_size, output_size, num_experts=8, top_k=2):
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.num_experts = num_experts
self.top_k = top_k
# 门控网络:决定激活哪些专家
self.gate = nn.Linear(input_size, num_experts)
# 专家网络:每个专家是一个前馈网络
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(input_size, 4 * input_size),
nn.GELU(),
nn.Linear(4 * input_size, output_size)
) for _ in range(num_experts)
])
def forward(self, x):
# 计算门控值
gate_logits = self.gate(x) # [batch_size, num_experts]
# 选择top-k专家
_, indices = torch.topk(gate_logits, self.top_k, dim=-1) # [batch_size, top_k]
gate_scores = F.softmax(torch.gather(gate_logits, -1, indices), dim=-1)
# 计算每个专家的输出并加权合并
final_output = torch.zeros(x.size(0), self.output_size, device=x.device)
for i, expert in enumerate(self.experts):
# 找出选择了当前专家的样本
mask = (indices == i).any(dim=-1)
if mask.any():
# 只对选择了当前专家的样本计算输出
expert_output = expert(x[mask])
# 找出每个样本中当前专家的权重位置
expert_positions = (indices == i).int()
expert_weights = gate_scores * expert_positions
expert_weights = expert_weights.sum(dim=-1, keepdim=True)[mask]
# 加权累加到最终输出
final_output[mask] += expert_output * expert_weights
return final_outputMoE的核心思想是只激活部分"专家"网络处理每个输入,大大提高了计算效率。关键在于gate网络,它决定了每个输入应该由哪些专家处理。
5.3 持续学习与灾难性遗忘
持续学习(Continual Learning)是解决大模型在微调过程中遗忘原有知识的关键技术:
python
# 弹性权重合并(EWC)实现示例
import torch
import torch.nn as nn
class EWC(object):
def __init__(self, model, old_tasks_data, importance=1000):
self.model = model
self.importance = importance
# 计算Fisher信息矩阵
self.fisher = self._calculate_fisher(old_tasks_data)
# 保存当前参数值
self.params = {n: p.clone().detach() for n, p in model.named_parameters() if p.requires_grad}
def _calculate_fisher(self, data_loader):
fisher = {n: torch.zeros_like(p) for n, p in self.model.named_parameters() if p.requires_grad}
# 计算每个参数的Fisher信息
self.model.eval()
for input, target in data_loader:
self.model.zero_grad()
output = self.model(input)
loss = F.cross_entropy(output, target)
loss.backward()
for n, p in self.model.named_parameters():
if p.requires_grad:
fisher[n] += p.grad.data ** 2 / len(data_loader)
return fisher
def ewc_loss(self):
# 计算EWC正则化损失
loss = 0
for n, p in self.model.named_parameters():
if p.requires_grad and n in self.fisher:
loss += (self.fisher[n] * (p - self.params[n]) ** 2).sum() * self.importance / 2
return loss这段代码实现了弹性权重合并(Elastic Weight Consolidation)算法,通过计算参数的重要性(Fisher信息矩阵)并惩罚重要参数的大幅变化,减轻灾难性遗忘问题。
六、行业应用案例与实践经验
6.1 垂直领域大模型微调案例
不同行业对大模型微调有不同的需求和挑战:
| 行业 | 微调目标 | 数据特点 | 推荐微调方法 | 典型挑战 |
|---|---|---|---|---|
| 医疗 | 专业知识准确性 | 专业术语多,数据敏感 | LoRA + 指令微调 | 隐私保护,专业准确性 |
| 法律 | 法律文书生成与分析 | 结构化文本,专业术语 | 全参数微调 | 推理链完整性,引用准确性 |
| 金融 | 风险评估,市场分析 | 时序数据,结构化报表 | Adapter + RLHF | 实时性,风险控制 |
| 客服 | 多轮对话,情感理解 | 对话历史,多样化查询 | 指令微调 + RLHF | 个性化,一致性 |
| 教育 | 个性化教学,答疑 | 多学科知识,难度分级 | MoE + 持续学习 | 适应不同学习水平 |
6.2 微调过程中的常见问题与解决方案
在实践中,微调过程常见的问题及其解决方案包括:
-
过拟合
- 症状:验证集性能下降,训练集性能持续提高
- 解决方案:增加正则化,减少训练轮数,使用早停策略
-
学习率设置不当
- 症状:训练不稳定或收敛过慢
- 解决方案:使用学习率预热,尝试不同学习率调度策略
-
灾难性遗忘
- 症状:新任务表现提升但原有能力下降
- 解决方案:使用EWC、知识蒸馏或经验回放等持续学习技术
-
计算资源不足
- 症状:OOM错误或训练极慢
- 解决方案:使用梯度累积、混合精度训练、模型并行或LoRA等PEFT方法
6.3 微调效果评估与迭代优化
微调不是一次性工作,而是需要持续评估和迭代优化的过程:


迭代优化的关键步骤包括:
- 错误分析:系统性分析模型失败案例,找出模式
- 有针对性数据增强:针对弱点补充训练数据
- 技术迭代:尝试更先进的微调方法和架构
- 持续评估:建立自动化评估流水线,监控模型性能
七、未来展望与发展趋势
大模型微调技术正在快速发展,未来趋势包括:
- 更高效的参数更新方法:进一步降低计算和存储需求
- 多模态微调:跨文本、图像、音频等多模态的统一微调方法
- 自动化微调:自动选择最佳微调策略和超参数
- 个性化微调:针对个人或小群体的定制化微调
- 联邦微调:保护隐私的分布式微调方法
"微调技术的进步将使AI大模型从通用工具转变为专业助手,从而在各个垂直领域释放其真正潜力。"
总结:大模型微调的艺术与科学
作为一名深耕AI领域多年的技术探索者,我深刻体会到大模型微调既是一门科学,也是一门艺术 。在科学层面,它需要我们理解深度学习的基本原理、掌握各种微调技术的数学基础、熟悉不同架构的特点 ;而在艺术层面,它又要求我们具备数据设计的创造力、超参数调优的直觉、以及解决实际问题的灵活思维。
通过本文的分享,我希望能够帮助大家建立起对大模型微调的系统认识。从基础的全参数微调到高效的LoRA技术 ,从简单的监督学习到复杂的RLHF方法,每种技术都有其适用场景和独特价值。在实践中,我们需要根据具体任务、可用资源和性能要求,灵活选择和组合这些技术。
微调不仅仅是技术问题,更是连接通用AI与专业应用的桥梁。通过精心设计的微调策略,我们可以将强大但泛化的大模型转变为特定领域的专家系统,为各行各业带来实际价值。未来,随着计算效率的提升和方法论的成熟,微调技术将变得更加普及和易用,使更多开发者能够定制自己的AI助手。
在这个AI大模型蓬勃发展的时代,掌握微调技术将成为AI从业者的核心竞争力。希望本文能为你的大模型微调之旅提供一些启发和指导,让我们一起在这个充满可能性的领域中探索和创新!
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!