KubeBlocks for MSSQL 高可用实现
背景
Microsoft SQL Server(MSSQL)是由微软开发的一款关系型数据库管理系统。最初仅支持在 Windows 平台上运行,自 2017 版本起开始支持 Linux 系统,这一变化为 MSSQL 的容器化部署提供了可能。
MSSQL 提供了名为 Availability Group(可用性组,下文简称AG) 的多数据库复制管理特性,该特性支持在多个节点上实现数据库的多副本冗余,从而提升数据可靠性和服务连续性。在 Windows 平台上,MSSQL 通过与 Windows Server Failover Cluster(WSFC) 集成,实现了完整的高可用能力。
在 Linux 平台上,MSSQL 提供了基于 Pacemaker + Corosync 的替代方案来构建高可用架构。然而,在云原生和容器化场景下,官方尚未提供对应的高可用方案,目前推荐使用第三方商业方案 DH2I 来实现。
KubeBlocks 在接入 MSSQL 时,面临如何在其平台上构建高可用能力的选择问题。主要有两种实现路径:
第一种方案是基于 Pacemaker 构建"富容器"架构,即将 Pacemaker、Corosync 和 MSSQL 等组件打包进同一个容器中运行。其优势在于可复用已有的开源组件,无需额外开发工作;但缺点是运维复杂度较高,Pacemaker 和 Corosync 的配置较为繁琐,且在容器化环境中由于 Pod 稳定性难以完全保障,可能导致整体高可用系统的管理成本高,且稳定性难以保证。
第二种方案是自主研发一套轻量级、面向云原生的分布式高可用框架,以模拟 WSFC 的核心功能。虽然该方案在前期开发成本和技术难度方面相对较高,但具备更高的自主可控性,并能避免对 Pacemaker 的依赖,提供更加简洁一致的用户体验。
考虑到 KubeBlocks 已经构建了一套统一的高可用管理框架 ------ Syncer,只需新引擎实现若干关键接口,即可快速完成高可用能力的集成,整体开发与维护成本均处于可控范围内。同时,该方式还能为 MSSQL 提供与其他数据库(如 MySQL、MongoDB 等)一致的高可用体验。
因此,KubeBlocks 最终选择基于 Syncer 框架实现 MSSQL 的高可用能力。
高可用概览
Syncer 是一款为应对数据库在云原生环境中高可用挑战而自主研发的轻量级分布式高可用服务。它的核心目标非常明确:让数据库在云原生环境下像其它有状态服务一样被统一调度和管理,而无需开发者或运维人员深入理解其内部复杂的状态流转和数据同步机制。它不仅提升了系统的可观测性和可维护性,还显著降低了数据库高可用功能研发的门槛。
作为一款面向多数据库引擎的通用组件,Syncer 抽象出一套标准化的高可用接口,包括:
Promote:将副本提升为主节点Demote:将主节点降级为副本HealthCheck:健康检查- ......
这些接口使得不同类型的数据库只需实现少量适配逻辑,即可快速接入 Syncer,并获得一致的高可用能力支持。
这也正是我们选择在 KubeBlocks for MSSQL 中采用自研方式的重要原因。借助 Syncer 提供的基础框架,我们可以更灵活地适配 MSSQL 的特性,避免依赖复杂的外部 HA 组件(如 Pacemaker),从而构建出一个更加轻量、可控且稳定的云原生高可用方案。
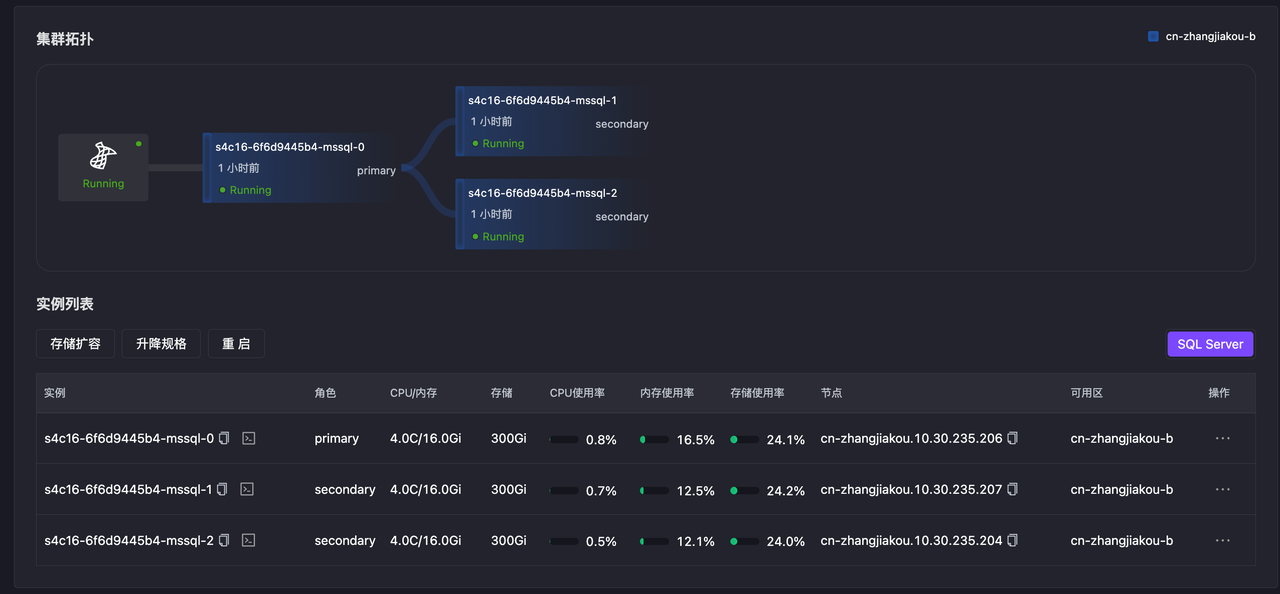
下图中展示了 MSSQL 三节点的高可用结构图,KubeBlocks for MSSQL最大支持 5 个同步节点,节点数最高不超过 9 个,与官方保持一致。
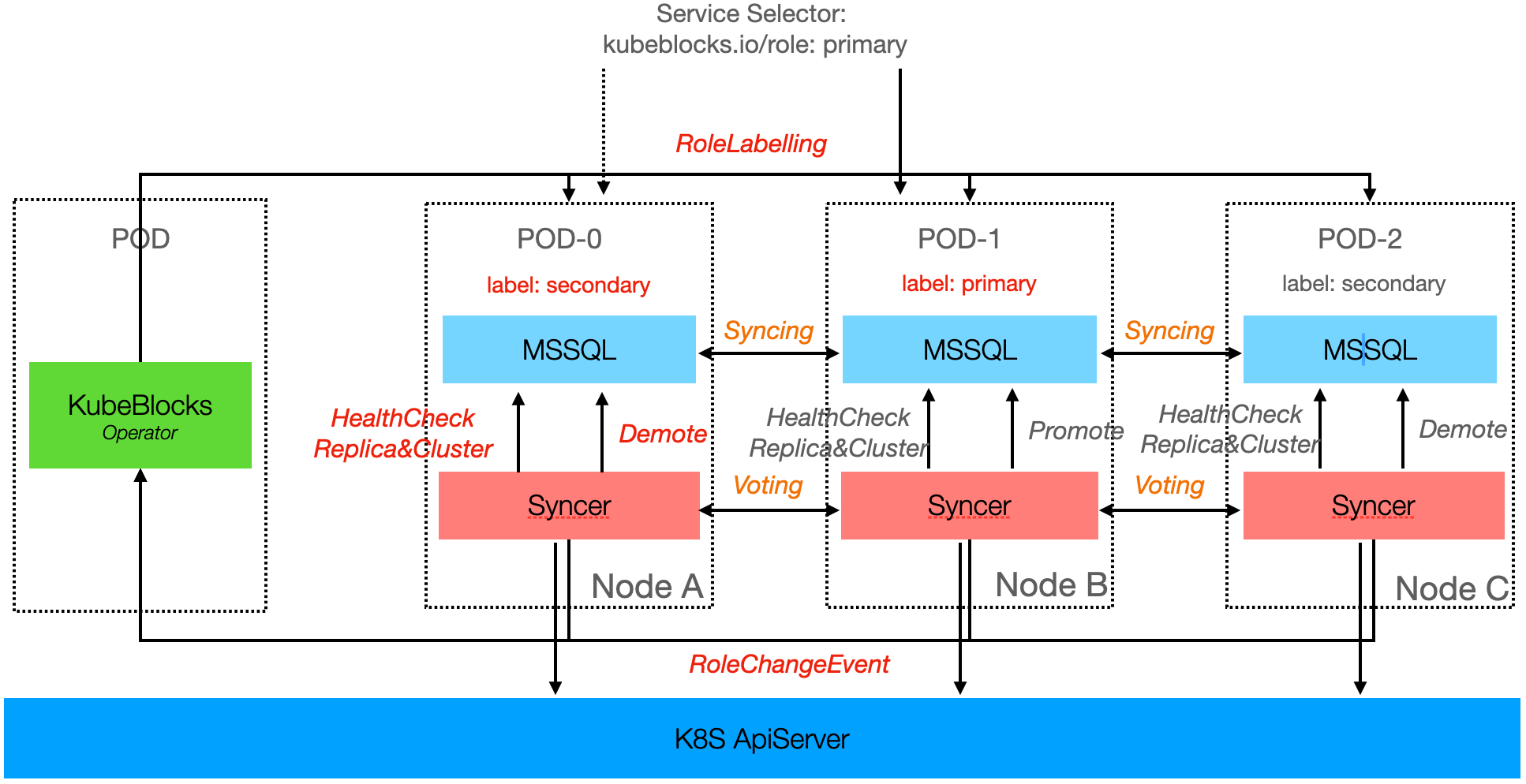
Syncer 采用分布式架构设计,以 Hypervisor 的方式运行在每一个数据库 Pod 上,负责节点本地和集群维度的健康探测。不同集群之间的高可用服务相互独立,各自通过内部选举机制管理副本角色。
在 K8S 上,Syncer 使用 ApiServer 作为分布式锁机制,结合节点的心跳信息和状态,对节点角色进行管理。当主节点发生异常时,Syncer 会触发 Failover,从现有的健康节点中选择状态最优的一个提升(Promote)为新主。旧主节点恢复正常后,则自动降级(Demote)为备节点。
更准更快的本地化探测
Syncer 使用本地化探测方式,可以更准确、更快速地发现异常,不受容器网络波动的影响。同时,它还能结合系统信息做出更可靠的判断:
- 当数据库连接异常时,Syncer 可实时获取当前 CPU 和内存使用情况,判断是否因负载过高导致;
- 若数据库写入异常,Syncer 还可检查磁盘是否已满或文件系统是否变为只读。
这种结合数据库状态与系统资源的综合探测机制,显著提升了故障识别的准确性。
自修复能力,降低运维复杂度
Syncer 还具备一定的自修复能力。当节点出现数据损坏等异常时,在完成 Failover 后,Syncer 可自动重建该节点的副本,确保集群恢复到健康状态,整个过程无需人工干预。
安全可控的进程管理
除了高可用能力,Syncer 还提供进程托管和一些基础运维支持,便于在云原生环境中进行精细化管理。
例如,数据库在关闭时通常需要等待事务结束并完成刷盘操作。而在 Kubernetes 中,Pod 仅能设置终止等待时间,超时后将强制关闭进程,可能导致数据不一致问题。
Syncer 在执行关闭操作时,会等待数据库正常退出后再上报停止状态,从而避免了直接强杀进程带来的风险,保障了数据库的安全性与一致性。
故障模拟
接入 Syncer 后,MSSQL 在 KubeBlocks 平台上获得了与 MySQL、PostgreSQL、MongoDB 等数据库接近的高可用能力,并在统一框架下实现了一致的高可用体验。
为了验证 MSSQL 的高可用机制是否符合预期,我们进行了全面的故障模拟测试。为使测试环境更贴近真实业务场景,我们在测试前导入了 90GB 的测试数据,并在整个测试过程中保持一个服务对其进行持续写入,以模拟实际负载。
由于篇幅限制,本文仅列出几种典型的故障场景进行说明,完整的故障测试报告可从 KubeBlocks 官网 获取。
主动切换
在日常运维中,如进行节点升级或维护时,通常需要主动发起实例的角色切换(Switchover),以滚动方式操作节点,从而最小化数据库不可用时间。Switchover 可以将非预期的故障转化成可控的运维事件,是保障高可用性和系统可维护性的关键操作之一。
Switchover 支持通过控制台界面操作,也可通过下发 OpsRequest 的方式进行。通常情况下,角色切换耗时约为 10 秒。新主节点恢复正常访问前,需先完成 Availability Group 中所有数据库的恢复(restore),因此实际数据可访问时间会受到数据量和当前业务负载的影响。
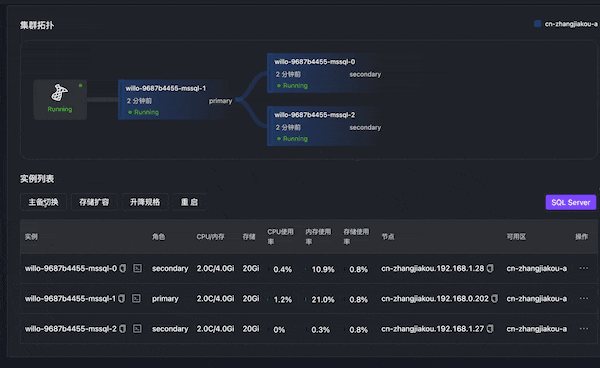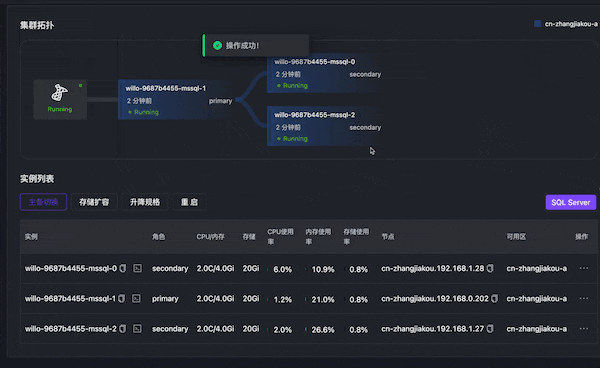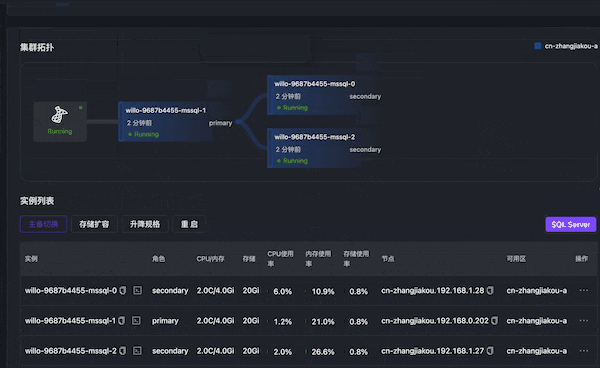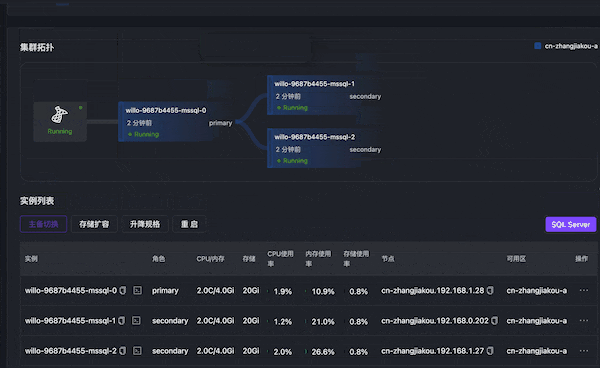
内存 OOM
通过 Chaos Mesh 模拟主节点内存 OOM,数据库无法访问,主备切换,15s 左右主节点切换成功。
- 最开始节点 0 为主节点
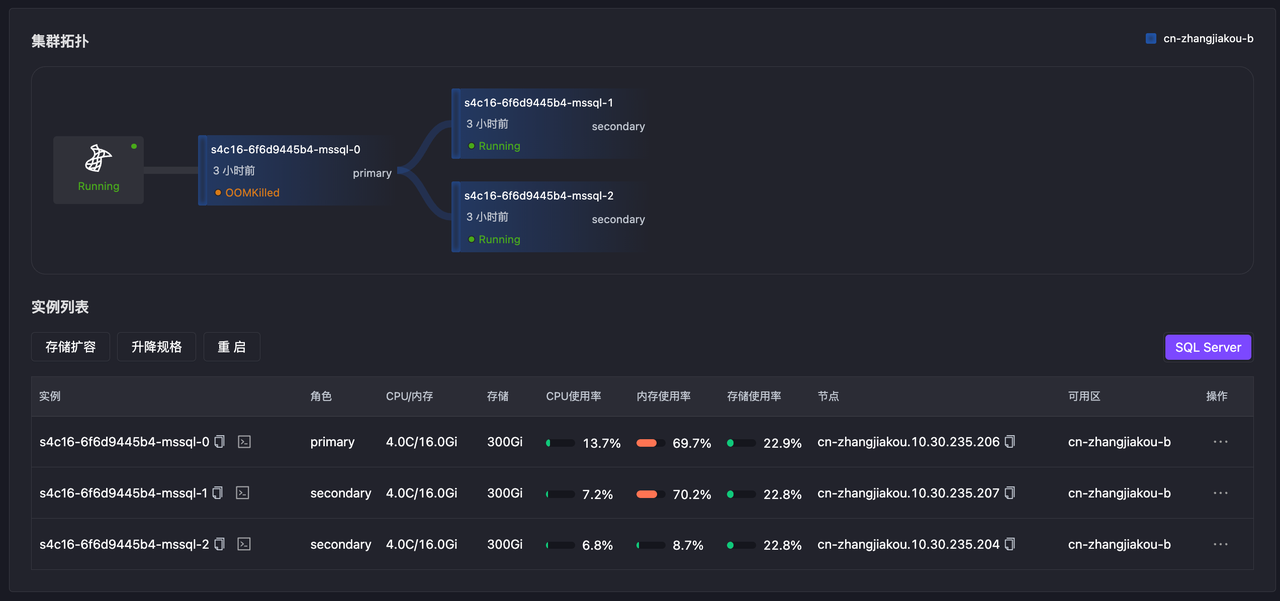
- Chaos Mesh 模拟 OOM 故障
YAML
kubectl create -f -<<EOF
kind: StressChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
generateName: test-primary-memory-oom-
namespace: default
spec:
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: s4c16-6f6d9445b4
kubeblocks.io/role: primary
mode: all
containerNames:
- mssql
stressors:
memory:
workers: 1
size: "100GB"
oomScoreAdj: -1000
duration: 30s
EOF- Pod 状态显示 OOMKilled
Bash
kubectl get pod -w -n kubeblocks-cloud-ns s4c16-6f6d9445b4-mssql-0
NAME READY STATUS RESTARTS AGE
s4c16-6f6d9445b4-mssql-0 3/4 OOMKilled 1 (56s ago) 151m
s4c16-6f6d9445b4-mssql-0 2/4 OOMKilled 1 (65s ago) 151m
s4c16-6f6d9445b4-mssql-0 2/4 CrashLoopBackOff 1 (11s ago) 151m
s4c16-6f6d9445b4-mssql-0 3/4 Running 2 (11s ago) 151m
s4c16-6f6d9445b4-mssql-0 4/4 Running 2 (17s ago) 151m- 故障发生后,15s 时节点 2 切换为新主
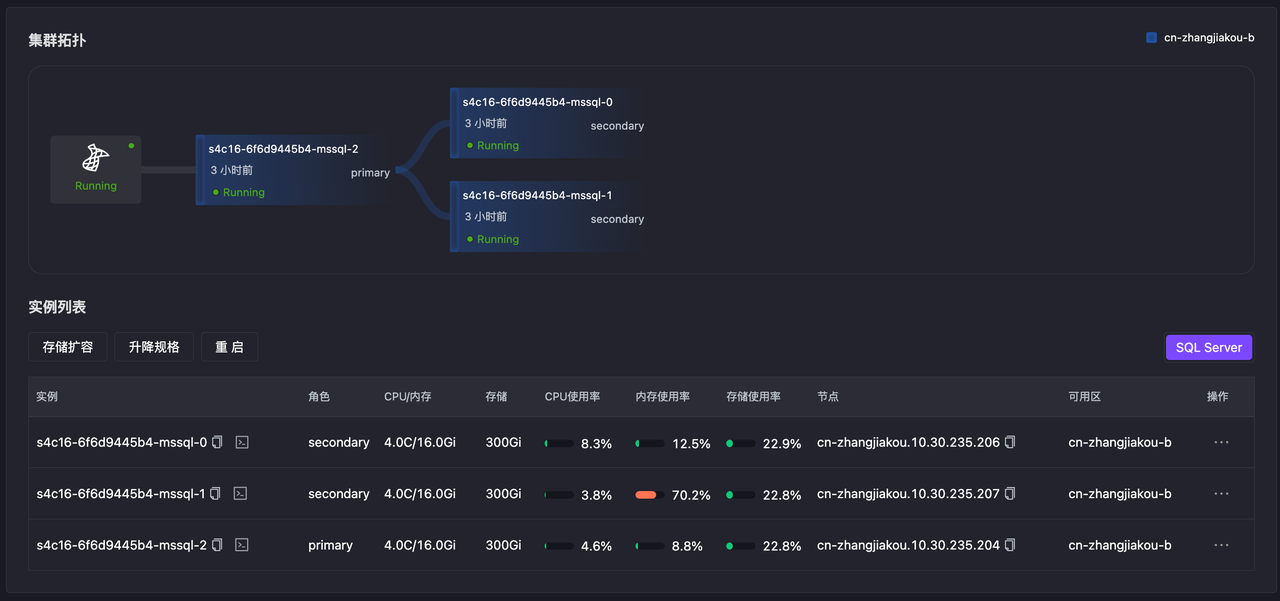
Pod 故障
通过 Chaos Mesh 模拟主节点 Pod Failure,致使数据库无法访问触发 Failover,1s 左右主节点切换成功。
-
初始状态,节点 0 为主节点
-
Chaos Mesh 模拟 Pod Failover
kubectl create -f -<<EOF
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
generateName: test-primary-pod-failure-
namespace: default
spec:
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: s4c16-6f6d9445b4
kubeblocks.io/role: primary
mode: all
action: pod-failure
duration: 2m
EOF -
1s 后节点 1 选为新主,节点 0 处于异常状态
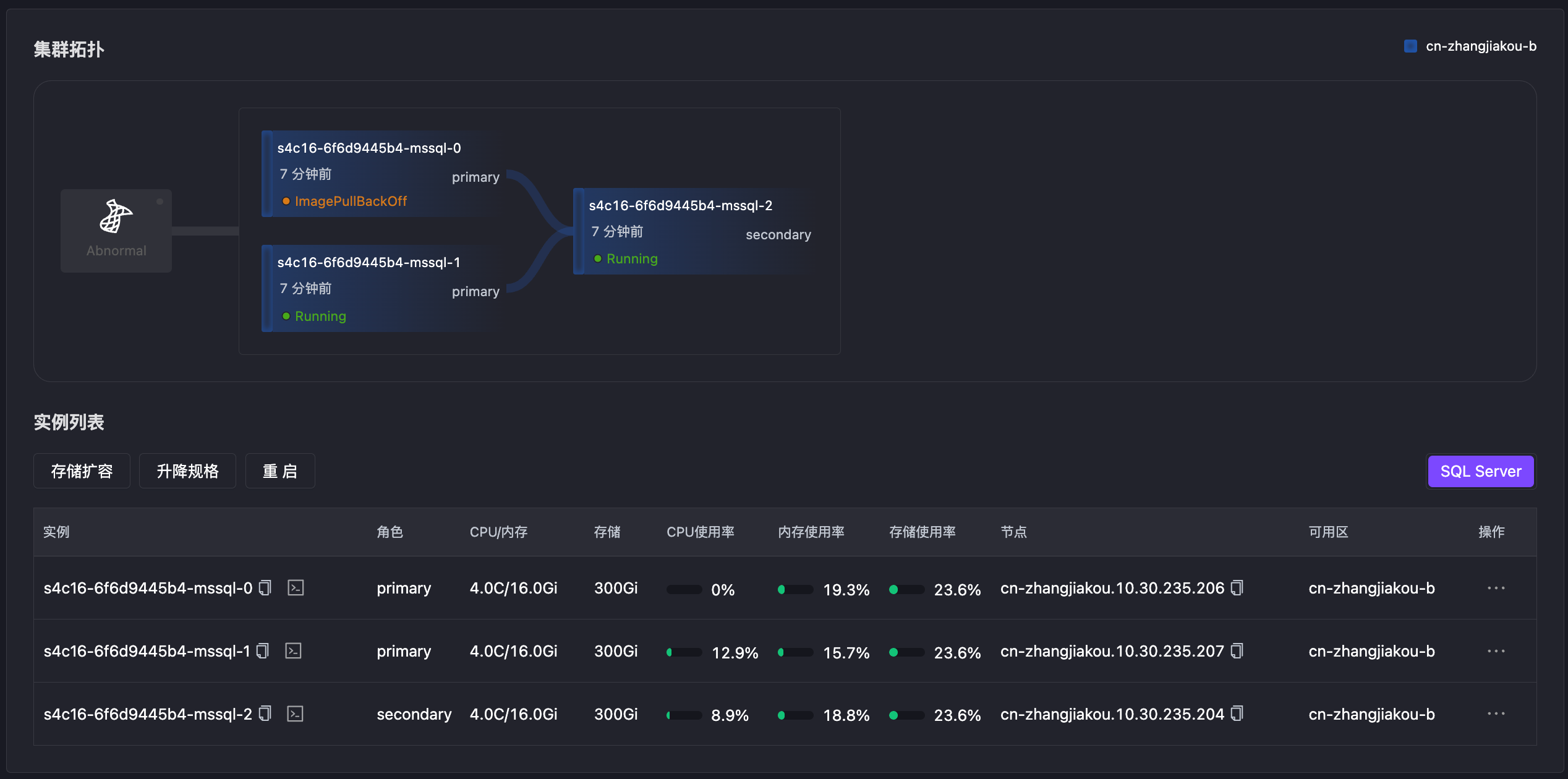
网络延迟
模拟主节点网络延迟两分钟,主节点服务无法访问触发主备切换,15s 后发生切换。
- Chaos Mesh 模拟 Pod网络故障
YAML
kubectl create -f -<<EOF
kind: NetworkChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
generateName: test-primary-network-delay-
namespace: default
spec:
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: s4c16-6f6d9445b4
kubeblocks.io/role: primary
mode: all
action: delay
delay:
latency: 10000ms
correlation: '100'
jitter: 0ms
direction: to
duration: 5m
EOF- Pod 内存服务访问异常
YAML
kubectl describe pod -n kubeblocks-cloud-ns s4c16-6f6d9445b4-mssql-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal checkRole 5m43s lorry {"event":"Success","operation":"checkRole","originalRole":"waitForStart","role":"{\"term\":\"1749106874646075\",\"PodRoleNamePairs\":[{\"podName\":\"s4c16-6f6d9445b4-mssql-0\",\"roleName\":\"primary\",\"podUid\":\"c3a4f05f-cc25-48ca-9f16-30d4621b7393\"},{\"podName\":\"s4c16-6f6d9445b4-mssql-1\",\"podUid\":\"b2014bb1-848e-4ebc-900b-e5849b9b0104\"}]}"}
Warning Unhealthy 67s kubelet Readiness probe failed: Get "http://10.30.237.94:3501/v1.0/checkrole": context deadline exceeded (Client.Timeout exceeded while awaiting headers)- 节点 0 选为新主,旧主在网络故障恢复后,角色恢复正常
进程异常
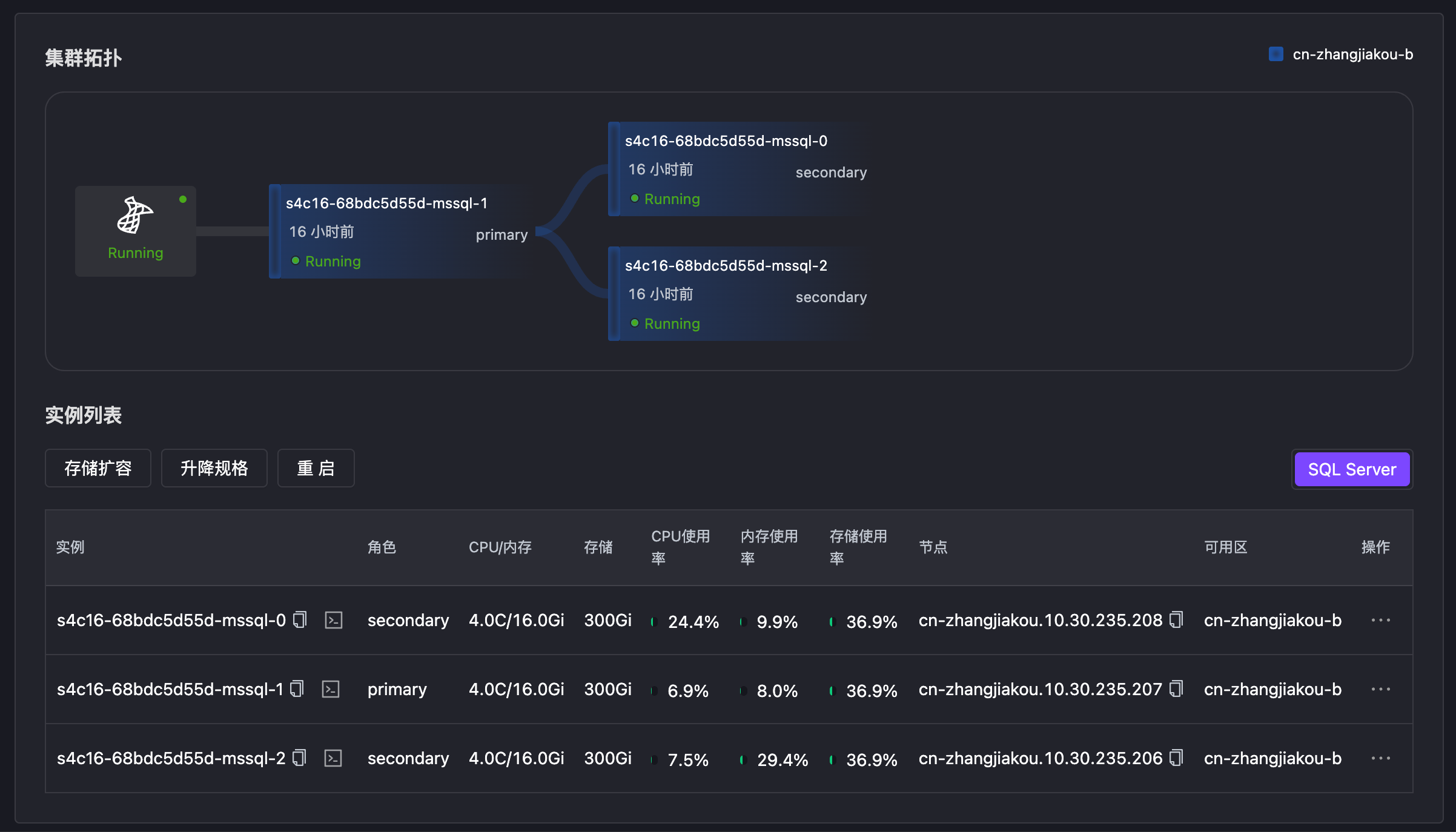
Kill 主节点 1 号进程,模拟进程异常触发 Failover,1s时主节点切换成功。
- Kill 1 号进程
Bash
echo "kill 1" | kubectl exec -it $(kubectl get pod -n kubeblocks-cloud-ns -l app.kubernetes.io/instance=s4c16-68bdc5d55d,kubeblocks.io/role=primary --no-headers| awk '{print $1}') -n kubeblocks-cloud-ns -- bash- Pod 事件显示 CrashLoopBackOff
Bash
kubectl get pod -n kubeblocks-cloud-ns -w s4c16-68bdc5d55d-mssql-0
s4c16-68bdc5d55d-mssql-0 0/4 Error 16 15h
s4c16-68bdc5d55d-mssql-0 0/4 CrashLoopBackOff 16 (4s ago) 15h
s4c16-68bdc5d55d-mssql-0 3/4 Running 20 (27s ago) 15h
s4c16-68bdc5d55d-mssql-0 3/4 Running 20 (31s ago) 15h
s4c16-68bdc5d55d-mssql-0 4/4 Running 20 (33s ago) 15h- 旧主异常后,1s 时节点 1 被选为新主
Syncer vs Pacemaker
Pacemaker 是 MSSQL on Linux 推荐使用的高可用解决方案,它是一个开源且成熟的集群资源管理器,广泛用于管理高可用性集群中的各类资源。
Syncer 作为 KubeBlocks 默认提供的高可用方案,在设计上参考了 Pacemaker,但主要面向云原生场景。为了实现更高水平的高可用性,Syncer 在集成方式上采用了 Plugin 模式,而非 Pacemaker 所使用的 Agent 模式。同时,Syncer 内置了集群节点管理逻辑,使其在健康探测和角色切换方面更加轻量和高效。
接下来将具体对比 Pacemaker 与 Syncer 的能力差异。
两节点脑裂
在仅部署两个节点的场景下,Pacemaker 存在发生脑裂(Split-Brain)的风险。Pacemaker 通过 Quorum 机制来确保集群在节点故障时仍能做出一致性的决策:当节点之间无法通信时,仲裁机制用于判断哪些节点可以继续提供服务,以保障数据一致性和可用性。
在两节点配置中,为了维持高可用性,通常会启用 two_node 模式。然而,这种模式下仍存在脑裂的可能性,无法完全避免该问题。
相比之下,Syncer 采用"心跳 + 全局锁"的方式,有效解决了两节点场景下的脑裂风险。当两个节点无法通信时,可能出现以下两种情况:
- 其中一个节点成功获取全局锁,则该节点保持为主节点,另一节点自动降级为备节点;
- 两个节点均无法获取全局锁,则集群维持原有状态,不会触发重新选主。
该机制不仅适用于两节点场景,同样可扩展至多节点环境,具备良好的通用性和稳定性。
RPO 与 RTO
当 MSSQL 主节点发生异常时,高可用服务会触发 Failover,从健康的备节点中选择最优节点提升为新主,继续对外提供服务。
备节点提升为主节点的过程可分为两个阶段:
- 第一阶段:将副本(replica)角色变更为主(primary)角色。该阶段仅涉及角色状态的切换,耗时主要取决于高可用服务的响应速度。
- 第二阶段:对 AG 内所有数据库执行
restore操作,使其进入可读写状态。该阶段时间与数据量大小和当前负载情况密切相关,且不受高可用服务本身影响。
由于本文重点在于对比不同高可用方案的切换能力,因此测试中使用了 1 万条数据(少量),以降低第二阶段对整体结果的影响。关于高负载场景及更全面的测试结果,可参考 KubeBlocks 官网发布的完整测试报告。
| 分类 | 测试内容 | pacemaker | syncer |
|---|---|---|---|
| 连接压力 | 连接数 Full | 不切换 | 不切换 |
| CPU 压力 | 主节点 CPU Full | 不切换 | 不切换 |
| 备节点 CPU Full | 不切换 | 不切换 | |
| 主备节点 CPU Full | 不切换 | 不切换 | |
| 内存压力 | 主节点内存 OOM | RPO=0, RTO=25s | RPO=0, RTO=15s |
| 单备节点内存 OOM | 不切换 | 不切换 | |
| 多备节点内存 OOM | 不切换 | 不切换 | |
| 主备节点内存 OOM | 主先恢复,不切换 | 主先恢复,不切换 | |
| 备先恢复RPO=0, RTO=56s | 备先恢复RPO=0, RTO=33s | ||
| Pod 故障 | 主节点 Pod Failure | RPO=0, RTO=24s | RPO=0, RTO=1s |
| 单备节点 Pod Failure | 不切换 | 不切换 | |
| 多备节点 Pod Failure | 不切换 | 不切换 | |
| 主备节点 Pod Failure | 主先恢复,不切换 | 主先恢复,不切换 | |
| 备先恢复RPO=0, RTO=54s | 备先恢复RPO=0, RTO=33s | ||
| NTP异常 | 主节点时钟偏移 | 不切换 | 不切换 |
| 备节点时钟偏移 | 不切换 | 不切换 | |
| 主备节点时钟偏移 | 不切换 | 不切换 | |
| 网络故障 | 主节点网络延迟 | 短时间延迟,不切换 | 短时间延迟,不切换 |
| 长时间延迟RPO=0, RTO=37s | 长时间延迟RPO=0, RTO=15s | ||
| 单备节点网络延迟 | 不切换 | 不切换 | |
| 多备节点网络延迟 | 不切换 | 不切换 | |
| 主备节点网络延迟 | 主先恢复,不切换 | 主先恢复,不切换 | |
| 备先恢复,主备切换RPO=0, RTO=28s | 备先恢复,主备切换RPO=0, RTO=28s | ||
| 主节点网络丢包 | RPO=0, RTO=43s | RPO=0, RTO=15s | |
| 单备节点网络丢包 | 不切换 | 不切换 | |
| 多备节点网络丢包 | 不切换 | 不切换 | |
| 主备节点网络丢包 | 主先恢复,不切换 | 主先恢复,不切换 | |
| 备先恢复RPO=0, RTO=82s | 备先恢复RPO=0, RTO=65s | ||
| Kill 进程 | 主节点进程 kill | RPO=0, RTO=40s | RPO=0, RTO=1s |
| 单备节点进程 kill | 不切换 | 不切换 | |
| 多备节点进程 kill | 不切换 | 不切换 | |
| 主备节点进程 kill | 主先恢复,不切换 | 主先恢复,不切换 | |
| 备先恢复RPO=0, RTO=74s | 备先恢复RPO=0, RTO=28s |
总结展望
在云原生环境下,MSSQL 面临着诸多挑战。由于其最初是为传统物理机或虚拟机环境设计的,在架构上并未充分适配云原生场景下的资源调度与运维模式。尤其是在高可用架构方面,受限于资源调度方式的差异以及 Pod 稳定性难以完全保障,MSSQL 已有的高可用机制难以发挥出理想效果。
KubeBlocks for MSSQL 正是在这样的背景下诞生的。它有效弥补了 MSSQL 在云原生场景下的能力短板,显著提升了其部署效率与运维管理体验。通过集成 Syncer 这一轻量级分布式高可用服务,KubeBlocks 成功实现了对 MSSQL 的云原生高可用支持,在故障探测、角色切换、自修复等方面表现稳定且高效。
当然,由于 MSSQL 是闭源系统,官方技术文档也较为有限,导致其高可用机制的深度集成面临较大挑战。目前我们主要依赖用户手册和数据库运维经验进行推导,并结合大量实验验证,确保最终实现符合预期。同时,MSSQL 的功能模块相对封闭,对外暴露的配置项和状态信息较少(如 SEED MODE 的配置参数和异常反馈),使得系统集成和运维管理仍显"粗粒度"。
我们期待未来 MSSQL 能够开放更多内部配置选项与运行状态指标,以支持更精细化的控制与自动化管理,从而更好地适配云原生平台的复杂需求。
最后,KubeBlocks Cloud 官网已开放 MSSQL 的免费试用,同时还支持 MySQL、PostgreSQL、Redis 等多款主流数据库引擎。欢迎体验并提出宝贵建议!