《Java零基础教学》是一套深入浅出的 Java 编程入门教程。全套教程从Java基础语法开始,适合初学者快速入门,同时也从实例的角度进行了深入浅出的讲解,让初学者能够更好地理解Java编程思想和应用。
本教程内容包括数据类型与运算、流程控制、数组、函数、面向对象基础、字符串、集合、异常处理、IO 流及多线程等 Java 编程基础知识,并提供丰富的实例和练习,帮助读者巩固所学知识。本教程不仅适合初学者学习,也适合已经掌握一定 Java 基础的读者进行查漏补缺。
前言
在Java开发中,数据结构是我们用来存储和组织数据的工具。无论是处理小型项目还是大型系统,理解和使用正确的数据结构都能极大地提高代码的效率和可维护性。数组 和集合是Java中两种常见的、非常重要的数据结构,它们在程序设计中起着至关重要的作用。
作为一名Java开发者,我深刻意识到数组和集合之间的差异,以及在不同场景下如何灵活选择最合适的数据结构。掌握这两者的特点和应用场景,不仅能帮助我们优化程序性能,还能让代码更加简洁和高效。
在本期内容中,我将带大家一起深入剖析Java中的数组和集合,并帮助大家理解如何灵活地选择和处理不同的数据结构,这也是我写本期的初衷。
1. 数组:基础数据结构,固定大小
1.1 什么是数组?
首先,我们先来常温个概念,什么是数组 ?它是Java中最基本的数据结构,它用于存储相同类型的元素 。数组的长度在创建时确定,并且一旦确定,就不能更改。因此,数组的大小是固定的,它是一个静态数据结构。
特点:
接着,它的主要特点也比较明显,例如:
- 固定大小:数组的大小在创建时确定,不能动态调整。
- 类型一致:数组中的元素必须是相同类型。
- 直接存储数据:数组在内存中以连续块的形式存储数据,因此可以通过索引快速访问元素。
示例:定义和使用数组
接着,我给大家展示下,结合理论与实战给大家把知识点讲透,案例代码如下:
java
/**
* @Author wf
* @Date 2025-08-23 10:02
*/
public class Test1 {
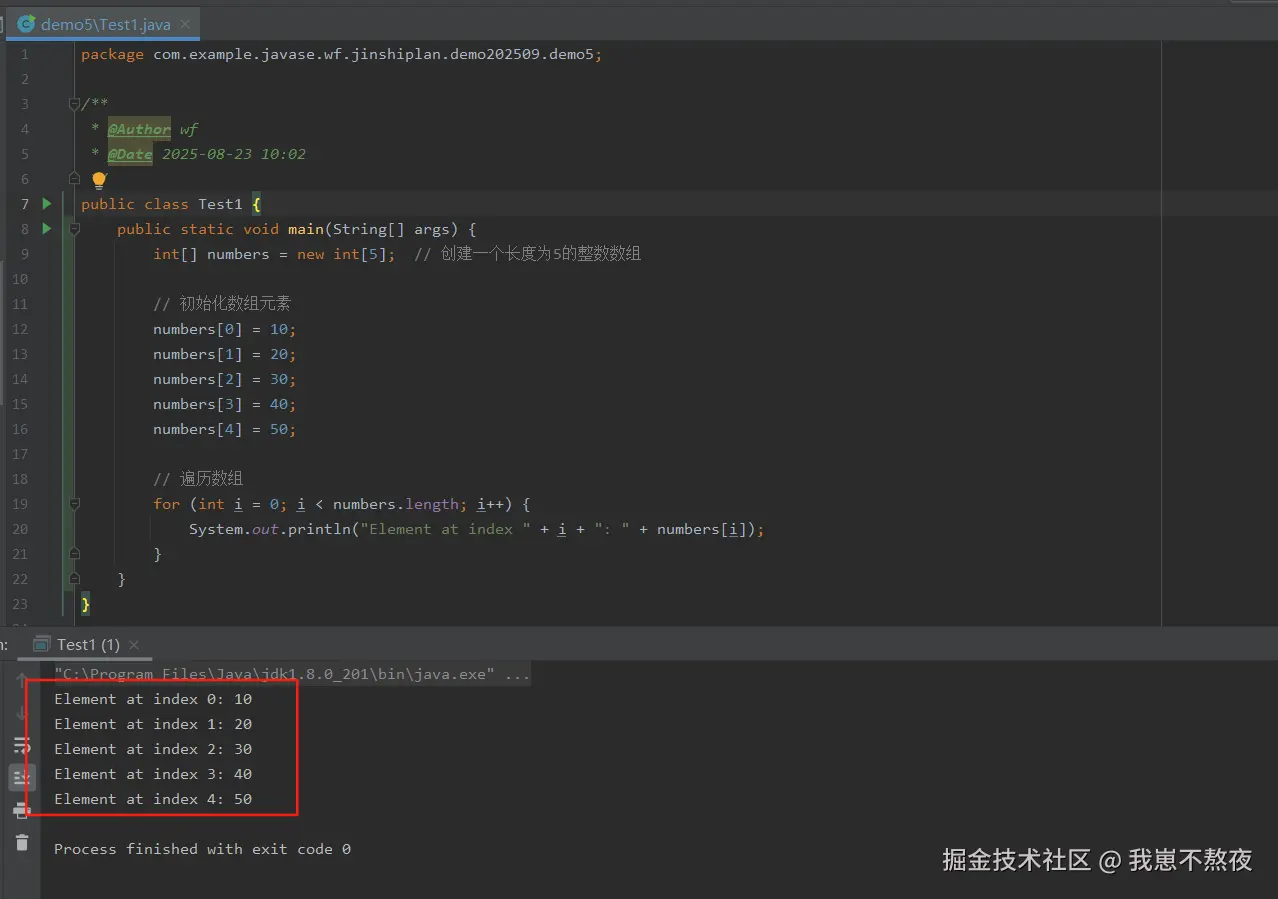
public static void main(String[] args) {
int[] numbers = new int[5]; // 创建一个长度为5的整数数组
// 初始化数组元素
numbers[0] = 10;
numbers[1] = 20;
numbers[2] = 30;
numbers[3] = 40;
numbers[4] = 50;
// 遍历数组
for (int i = 0; i < numbers.length; i++) {
System.out.println("Element at index " + i + ": " + numbers[i]);
}
}
}根据如上案例,本地实际结果运行展示如下,仅供参考:
优点:
- 快速访问:数组通过索引直接访问,时间复杂度为O(1),非常高效。
- 内存紧凑:由于数组是静态数据结构,内存分配非常紧凑。
缺点:
- 大小固定:数组一旦创建,大小不可更改。如果数组的大小不合适,可能会浪费内存或引发数组越界异常。
- 插入删除困难:数组的插入和删除操作较为复杂,尤其是在中间位置插入或删除元素时,必须移动大量数据。
1.2 使用场景
- 数据量固定:如果你知道数据的大小并且不会改变数组大小,使用数组是最合适的。例如:存储一个月的温度记录、学生的成绩等。
- 性能要求高:当你需要高效地随机访问元素时,数组的访问速度是最优的。
2. 集合:动态数据结构,灵活应对变化
2.1 什么是集合?
集合 (Collection)是Java提供的一种更加灵活、功能丰富的数据结构。与数组不同,集合的大小是动态的,支持元素的添加、删除、查找等多种操作,常见的集合类有List、Set、Map等。集合属于动态数据结构,它们通常用于存储和操作不定数量的数据。
集合的核心接口:
List:有序且允许重复的集合(如ArrayList、LinkedList)。Set:无序且不允许重复的集合(如HashSet、TreeSet)。Map:键值对存储的集合,键唯一(如HashMap、TreeMap)。
2.2 List:有序且允许重复的集合
List接口表示一个有序的集合,它允许存储重复的元素,并且可以通过索引来访问每个元素。
常见实现类:
ArrayList:基于动态数组实现,支持快速随机访问,但插入和删除操作较慢。LinkedList:基于链表实现,适合频繁插入和删除操作,但随机访问性能较差。
示例:使用ArrayList存储学生成绩
接着,我给大家展示下,结合理论与实战给大家把知识点讲透,案例代码如下:
java
/**
* @Author wf
* @Date 2025-08-23 10:02
*/
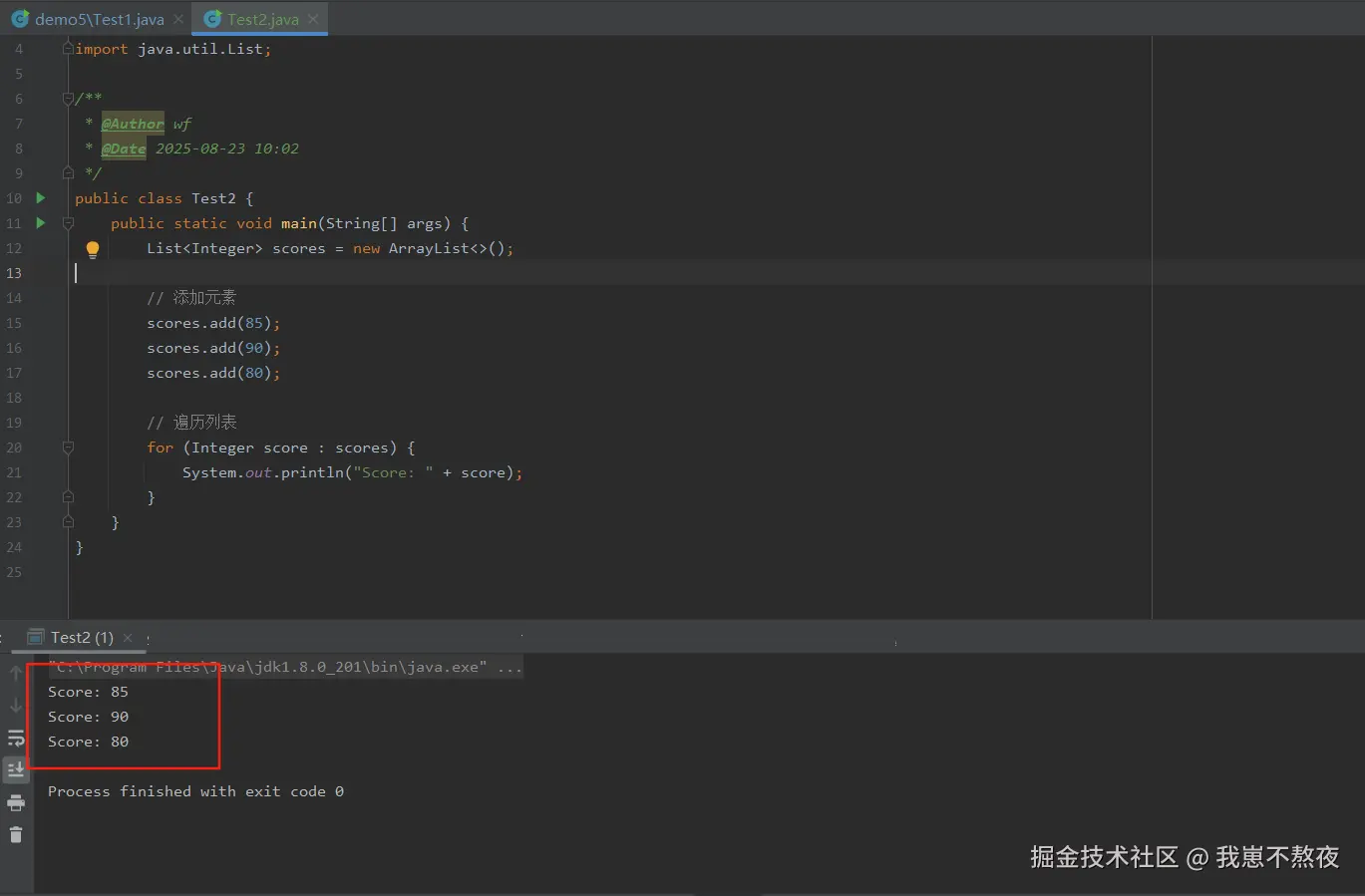
public class Test2 {
public static void main(String[] args) {
List<Integer> scores = new ArrayList<>();
// 添加元素
scores.add(85);
scores.add(90);
scores.add(80);
// 遍历列表
for (Integer score : scores) {
System.out.println("Score: " + score);
}
}
}根据如上案例,本地实际结果运行展示如下,仅供参考:
优点:
- 灵活:集合的大小可以动态调整,适应变化的数据需求。
- 丰富的功能:集合类提供了许多有用的方法,如排序、查找、删除等。
- 高效的插入删除 :
LinkedList在插入和删除操作上比数组更加高效,尤其是在中间位置插入或删除时。
缺点:
- 性能开销:与数组相比,集合类在内存上有额外的开销,并且某些操作的性能不如数组。
- 不适合存储大量固定大小数据:对于大量固定大小的数据,使用集合可能会引入不必要的内存开销。
使用场景:
- 数据量不确定或会动态变化:例如存储用户输入的日志信息,或处理不固定长度的数据流。
- 对元素顺序和重复有要求 :当你需要保持元素顺序或允许重复元素时,
List是理想选择。
2.3 Set:无序且不允许重复的集合
Set是一个无序且不允许重复的集合。它不允许存储重复的元素,并且元素的顺序是不可预期的。
常见实现类:
HashSet:基于哈希表实现,提供快速的查找操作,元素无序。TreeSet:基于红黑树实现,元素有序(按自然顺序或自定义顺序)。
示例:使用HashSet去重
接着,我给大家展示下,结合理论与实战给大家把知识点讲透,案例代码如下:
java
/**
* @Author wf
* @Date 2025-08-23 10:02
*/
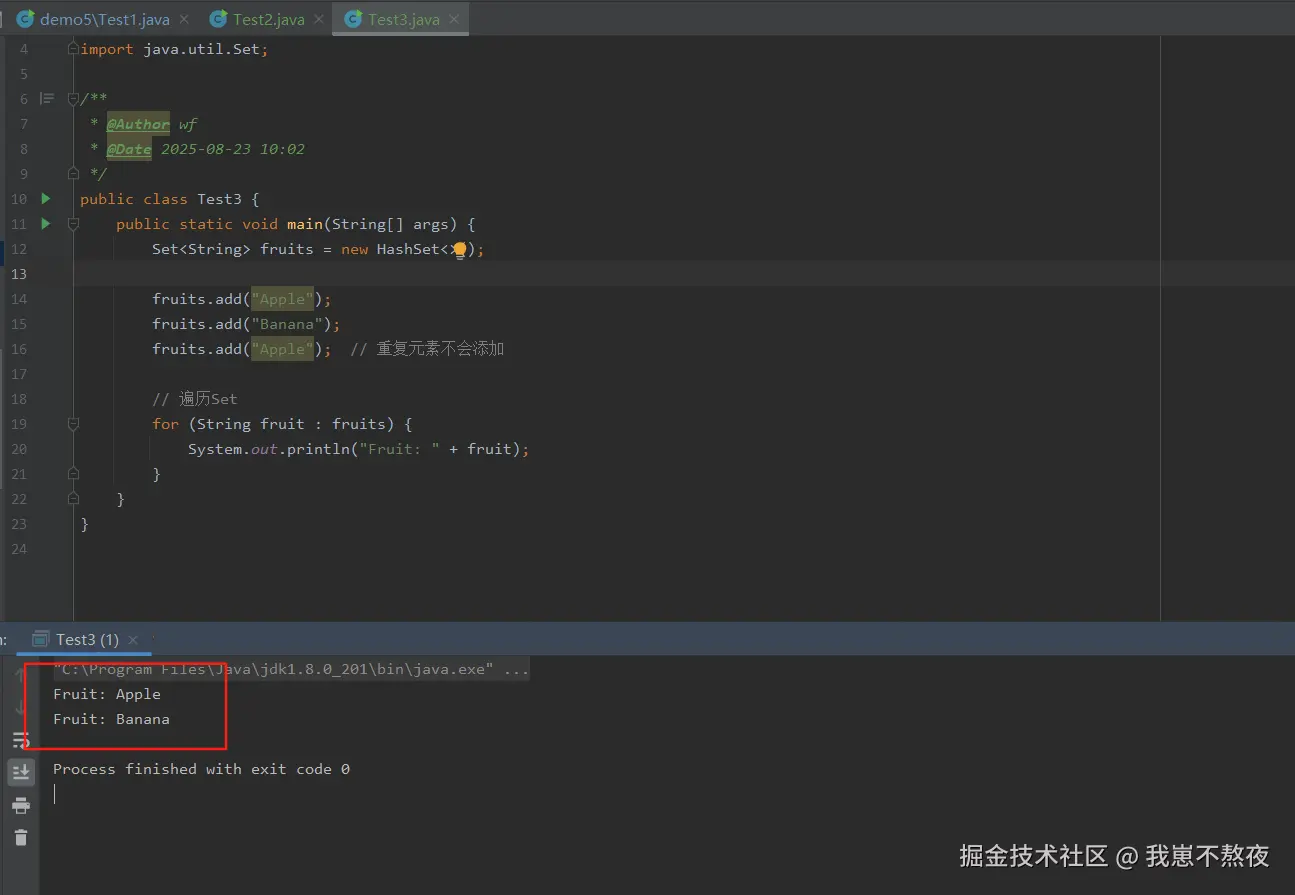
public class Test3 {
public static void main(String[] args) {
Set<String> fruits = new HashSet<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Apple"); // 重复元素不会添加
// 遍历Set
for (String fruit : fruits) {
System.out.println("Fruit: " + fruit);
}
}
}根据如上案例,本地实际结果运行展示如下,仅供参考:
优点:
- 去重:自动去除重复的元素,适用于存储唯一数据的场景。
- 高效查找 :
HashSet提供常数时间的查找操作(O(1))。
缺点:
- 无序:元素存储没有顺序,不能通过索引访问元素。
- 不可重复 :
Set不允许重复元素,可能会丢失某些重复数据。
使用场景:
- 去重操作 :当你需要确保集合中的元素不重复时,
Set是最佳选择。例如:存储唯一的用户ID、标签等。
2.4 Map:键值对存储,快速查找
Map是一种键值对集合 ,它通过键(key)和对应的值(value)来存储数据。与List和Set不同,Map的键是唯一的,但值可以重复。
常见实现类:
HashMap:基于哈希表实现,提供快速的查找、插入、删除操作,键无序。TreeMap:基于红黑树实现,按键的自然顺序(或自定义顺序)排序。LinkedHashMap:继承自HashMap,保持元素的插入顺序。
示例:使用HashMap存储用户信息
接着,我给大家展示下,结合理论与实战给大家把知识点讲透,案例代码如下:
java
/**
* @Author wf
* @Date 2025-08-23 10:02
*/
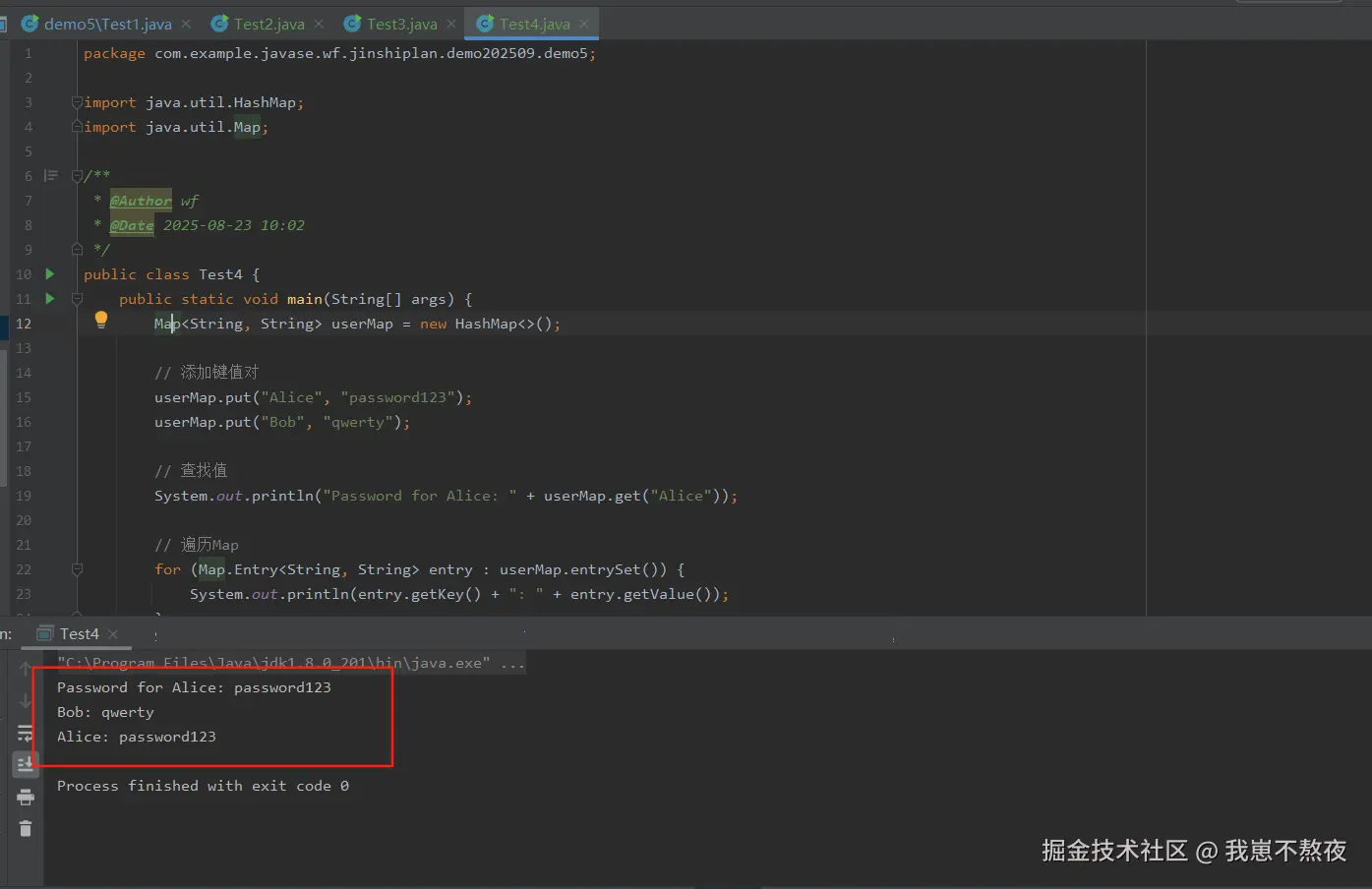
public class Test4 {
public static void main(String[] args) {
Map<String, String> userMap = new HashMap<>();
// 添加键值对
userMap.put("Alice", "password123");
userMap.put("Bob", "qwerty");
// 查找值
System.out.println("Password for Alice: " + userMap.get("Alice"));
// 遍历Map
for (Map.Entry<String, String> entry : userMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}根据如上案例,本地实际结果运行展示如下,仅供参考:
优点:
- 快速查找 :
HashMap可以通过键快速查找对应的值,适用于需要快速存取数据的场景。 - 键唯一性 :保证每个键在
Map中唯一,适合存储一对一的映射关系。
缺点:
- 无序性 :
HashMap中的元素无序,不能保证元素插入的顺序。如果需要顺序,可以使用LinkedHashMap或TreeMap。 - 不支持索引访问 :与
List不同,Map无法通过索引访问元素,必须通过键来获取值。
使用场景:
- 存储映射关系 :当你需要存储键值对并通过键快速查找值时,
Map非常适合。例如:存储用户信息、配置项等。
3. 总结:如何灵活选择数据结构?
List:适用于需要保持元素顺序并且允许重复元素的场景,如存储学生成绩、用户输入等。Set:适用于需要去重且不关心元素顺序的场景,如存储唯一的标签、ID集合等。Map:适用于需要存储键值对并根据键快速查找值的场景,如用户信息存储、配置管理等。
总而言之,在实际开发中,选择合适的数据结构能够极大提高代码的效率和可维护性,避免不必要的性能问题。理解不同集合的特点,掌握它们的使用场景,才能帮助我们在不同需求下做出最佳选择,编写高效、简洁的代码,这也是我写此篇的衷心所在,希望能够帮到大家。
最后
大家如果觉得看了本文有帮助的话,麻烦给不熬夜崽崽点个三连(点赞、收藏、关注)支持一下哈,大家的支持就是我写作的无限动力。