Canary
1.Introduction
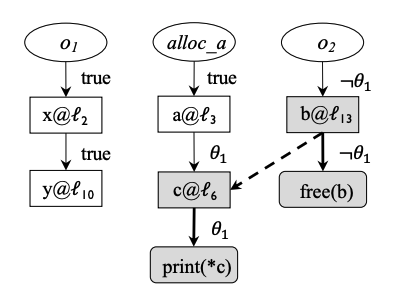
主要做跨线程value-flow bug检查,下面代码中两个函数中存在指向关系:1. x → o 1 x \rightarrow o_1 x→o1, b → o 2 b \rightarrow o_2 b→o2 以及赋值关系: o 1 = a o_1 = a o1=a。考虑跨线程的数据流存在 y = x y = x y=x、 o 1 = b o_1 = b o1=b(覆盖掉 a a a)。如果 θ 1 \theta_1 θ1 满足,那么 o 1 = a o_1 = a o1=a,因此 c = a c = a c=a,print 操作安全。如果 θ 2 \theta_2 θ2 满足,那么线程执行完后根本不会执行 print 操作,因此没有bug。但是现有静态分析工具可能会错误判断 free(b) 到 print(*c) 存在use-after-free。

作者提出了Canary,对上面代码可构造如下value-flow graph,其中 b @ l 13 → c @ l 6 b@l_{13} \rightarrow c@l_6 b@l13→c@l6 对应 *y = b 和 c = *x,x, y 都指向了共同的堆对象 o 1 o_1 o1,路径条件为 θ 1 ∧ ¬ θ 1 \theta_1 \wedge \neg \theta_1 θ1∧¬θ1。同时线程间执行需要保证语句的先后顺序,用 O 2 > O 1 O_2 > O_1 O2>O1 表示 l 2 l_2 l2 在 l 1 l_1 l1 后执行,那么还存在偏序关系 O 13 > O 3 ∧ O 14 > O 3 O_{13} > O_3 \wedge O_{14} > O_3 O13>O3∧O14>O3。随后Canary会调用SMT求解上面约束条件验证该bug存在条件不可行。
相比顺序程序,并发程序分析的核心在于,对于 l 1 : ∗ x = q l_1: *x = q l1:∗x=q, l 2 : p = ∗ y l_2: p = *y l2:p=∗y,不仅要分析 x , y x, y x,y 别名的路径条件;还要分析 l 1 → l 2 l_1 \rightarrow l_2 l1→l2 路径下 x , y x, y x,y 可能指向的内存是否会被其它线程覆写。
2.Approach
分为数据依赖分析和线程间依赖分析。
2.1.数据依赖分析
规则如下和pinpoint类似,自底向上对每个函数生成summary再分析其caller,先进行代码转换方便暴露每个函数的side-effect。转换的规则应该覆用了pinpoint的,对于下面代码。
cpp
int f(v1, v2, ...) {
...
return v0;
}转换后可能为:
cpp
int f(v1, v2, ... , F1, F2, ...) {
∗(vj, k) = Fi; /* for all (i, j, k). */
...;
Rp = ∗(vq,r); /* for all (p,q,r). */
return {v0, R1, R2, ...};
}对于调用点:
cpp
// 转换前
u0 = f(u1, u2, ...);
// 转换后
Ai = ∗(uj, k); /* for all (i, j, k). */
{u0, C1, C2, ... } = f(u1, u2, ... ,A1,A2, ...);
∗(uq,r) = Cp =; /* for all (p,q,r). */在分析函数 F F F 时按照每个指令在CFG中的逆后序处理每条指令。分析完后 Trans ( F ) \text{Trans}(F) Trans(F) 记录了 F F F 在其形参 v i v_i vi 的副作用。

线程内指令的分析规则基于flow-, path-sensitive指针分析,如下所示。这里暂时不考虑线程间的关系,碰到 fork 调用直接跳过。
| 指令类型 | 示例 | 规则 |
|---|---|---|
alloca |
l , φ : p = & o l, \varphi: p = \&o l,φ:p=&o | ( φ , o ) ∈ pts ( p ) (\varphi, o) \in \text{pts}(p) (φ,o)∈pts(p) |
copy |
l , φ : p = q l, \varphi: p = q l,φ:p=q | ( γ ∧ φ , o ) ∈ pts ( p ) ∣ ∀ ( γ , o ) ∈ pts ( q ) (\gamma \wedge \varphi, o) \in \text{pts}(p) \mid \forall (\gamma, o) \in \text{pts}(q) (γ∧φ,o)∈pts(p)∣∀(γ,o)∈pts(q) |
load |
l , φ : p = ∗ y l, \varphi: p = *y l,φ:p=∗y | ( γ ∧ φ , o ′ ) ∈ pts ( p ) ∣ ∀ ( _ , o ) ∈ pts ( y ) , ∀ ( γ , o ′ ) ∈ pts IN l ( o ) (\gamma \wedge \varphi, o^{'}) \in \text{pts}(p) \mid \forall (\, o) \in \text{pts}(y), \forall (\gamma, o^{'}) \in \text{pts}{\text{IN}l}(o) (γ∧φ,o′)∈pts(p)∣∀(,o)∈pts(y),∀(γ,o′)∈ptsINl(o) |
store |
l , φ : ∗ x = q l, \varphi: *x = q l,φ:∗x=q | (1). pts ( x ) = ∅ ∣ x → ( γ , o ) \text{pts}(x) = \emptyset \mid x \rightarrow (\gamma, o) pts(x)=∅∣x→(γ,o) (strong update), (2). ( γ ∧ φ , o ) ∈ pts ( o ′ ) ∣ ∀ ( γ , o ) ∈ pts ( q ) , ∀ ( γ ′ , o ′ ) ∈ pts ( x ) (\gamma \wedge \varphi, o) \in \text{pts}(o^{'}) \mid \forall (\gamma, o) \in \text{pts}(q), \forall (\gamma^{'}, o^{'}) \in \text{pts}(x) (γ∧φ,o)∈pts(o′)∣∀(γ,o)∈pts(q),∀(γ′,o′)∈pts(x) |
call |
l , φ : ( x 0 , . . . , x n ) = f ( v 1 , . . . , v n ) l, \varphi: (x_0, ..., x_n) = f(v_1, ..., v_n) l,φ:(x0,...,xn)=f(v1,...,vn) | ( φ , Trans ( f , pts ( v i ) ) ) ∈ pts ( x i ) ∣ ∀ i ∈ 1 , n (\varphi, \text{Trans}(f, \text{pts}(v_i))) \in \text{pts}(x_i) \mid \forall i \in 1, n (φ,Trans(f,pts(vi)))∈pts(xi)∣∀i∈1,n |
2.2.线程间依赖分析
这一步是Canary的核心,当 l 1 : ∗ x = q l_1: *x = q l1:∗x=q 和 l 2 : p = ∗ y l_2: p = *y l2:p=∗y 在不同线程时, x , y x, y x,y 别名的前提除了本身必须可能指向同一块内存外还必须满足 O 2 > O 1 O_2 > O_1 O2>O1,这步包括依赖边构造 和依赖条件计算两个步骤。
2.2.1.依赖边构造
需要识别线程共享内存,这些内存对象被称为escaped memory。用 EspObj \text{EspObj} EspObj 表示程序中所有escaped memory object, Pted ( o ) \text{Pted}(o) Pted(o) 表示指向 o o o 的所有指针。在线程内数据依赖分析基础上,作者定义下面规则,其中 t t t 表示某个线程, t ′ t^{'} t′ 表示其它线程。
-
计算 EspObj \text{EspObj} EspObj:
-
step 1: 将
fork调用中传递的object添加进 EspObj \text{EspObj} EspObj 。 -
step 2: 根据已有的 EspObj \text{EspObj} EspObj 和
store指令更新集合, o ′ ∈ EspObj ∣ ( c 1 ) . ∀ l : ∗ x = q ( c 2 ) ( , o ) ∈ pts ( x ) ( , o ′ ) ∈ pts ( q ) ( c 3 ) o ∈ EspObj o^{'} \in \text{EspObj} \mid (c1).\forall l: *x=q \;\; (c2) (, o) \in \text{pts}(x) \; (, o^{'}) \in \text{pts}(q) \;\; (c3) o \in \text{EspObj} o′∈EspObj∣(c1).∀l:∗x=q(c2)(,o)∈pts(x)(,o′)∈pts(q)(c3)o∈EspObj。
-
-
计算 Pted \text{Pted} Pted: 对 EspObj \text{EspObj} EspObj 中的每个 o o o 找到能传播到的所有指针,存入集合 N N N, σ \sigma σ 为遍历过程中的路径条件: ( n , σ ) ∈ Pted ( o ) (n, \sigma) \in \text{Pted}(o) (n,σ)∈Pted(o)。
-
计算依赖边:: l 1 → l 2 ∣ ( c 1 ) . ∀ l 1 , φ 1 : ∗ x = q ∈ t ( c 2 ) . ∀ l 2 , φ 2 : p = ∗ y ∈ t ′ ( c 3 ) . ( x , α ) , ( y , β ) ∈ Pted ( o ) , ( c 4 ) . o ∈ EspObj l_1 \rightarrow l_2 \mid (c1).\forall l_1, \varphi_1: *x = q \in t \;\; (c2).\forall l_2, \varphi_2: p = *y \in t^{'} \;\; (c3).(x, \alpha), (y, \beta) \in \text{Pted}(o), (c4).o \in \text{EspObj} l1→l2∣(c1).∀l1,φ1:∗x=q∈t(c2).∀l2,φ2:p=∗y∈t′(c3).(x,α),(y,β)∈Pted(o),(c4).o∈EspObj。
这个示例中 EspObj = { o 1 , o 2 } \text{EspObj} = \{o_1, o_2\} EspObj={o1,o2}, Pted ( o 1 ) = { x , y } \text{Pted}(o_1) = \{x, y\} Pted(o1)={x,y}, Pted ( o 2 ) = { b , c } \text{Pted}(o_2) = \{b, c\} Pted(o2)={b,c}(paper中这么写的,有点迷惑,fact的路径条件应该是被忽略了)。
2.2.2.依赖条件计算
一个value-flow edge: l 1 , φ 1 : ∗ x = q ⟶ l 2 , φ 2 : p = ∗ y l_1, \varphi_1: *x = q \longrightarrow l_2, \varphi_2: p = *y l1,φ1:∗x=q⟶l2,φ2:p=∗y 的路径条件包括 x , y x, y x,y 的别名条件 Φ alias \Phi_{\text{alias}} Φalias 以及 O 2 > O 1 O_2 > O_1 O2>O1 的条件 Φ ls \Phi_{\text{ls}} Φls。
Φ alias = ⋁ ( φ 1 ∧ φ 2 ∧ α ∧ β ) ∣ ∀ ( α , o ) ∈ pts ( x ) , ( β , o ) ∈ pts ( y ) \Phi_{\text{alias}} = \bigvee (\varphi_1 \wedge \varphi_2 \wedge \alpha \wedge \beta) \mid \forall (\alpha, o) \in \text{pts}(x), (\beta, o) \in \text{pts}(y) Φalias=⋁(φ1∧φ2∧α∧β)∣∀(α,o)∈pts(x),(β,o)∈pts(y),上面示例中:*y = b -> c = *x 的条件为 θ 1 ∧ ¬ θ 1 \theta_1 \wedge \neg \theta_1 θ1∧¬θ1。
Φ ls \Phi_{\text{ls}} Φls 的计算中需要保证 (1) store s 和 load l 的执行顺序 O l > O s O_l > O_s Ol>Os,同时 (2) s → l s \rightarrow l s→l 之间没有其它 store 语句会写入 o o o。让 S ( l ) S(l) S(l) 表示 l l l 数据依赖的所有 store 语句。那么 Φ ls = ⋀ s , s ′ ∈ S ( l ) ( O s < O l ⋀ ∀ s ′ ≠ s O s ′ < O s ∨ O l < O s ′ ) \Phi_{\text{ls}} = \bigwedge\limits_{s,s^{'} \in S(l)} (O_s < O_l \bigwedge\limits_{\forall s^{'} \neq s} O_{s^{'}} < O_s \vee O_l < O_{s^{'}}) Φls=s,s′∈S(l)⋀(Os<Ol∀s′=s⋀Os′<Os∨Ol<Os′)。 O s ′ < O s ∨ O l < O s ′ O_{s^{'}} < O_s \vee O_l < O_{s^{'}} Os′<Os∨Ol<Os′ 表示 s s s 和 l l l 之间不存在其它 store 语句会修改 l l l 引用的内存。
3.Bug检测
这里主要检测线程间use after free。其中source为 free 点,sink为 use 点。其中存在source - sink路径 π = ⟨ v 1 @ l 1 , v 2 @ l 2 , . . . , v k @ l k ⟩ \pi = \langle v_1@l_1, v_2@l_2, ..., v_k@l_k \rangle π=⟨v1@l1,v2@l2,...,vk@lk⟩,bug存在的条件 Φ all ( π ) = Φ guards ( π ) ∧ Φ po ( π ) \Phi_{\text{all}}(\pi) = \Phi_{\text{guards}}(\pi) \wedge \Phi_{\text{po}}(\pi) Φall(π)=Φguards(π)∧Φpo(π)。
-
Φ guards ( π ) = ⋀ i ∈ 1 , k − 1 Φ guards ( v i @ l i → v i + 1 @ l i + 1 ) \Phi_{\text{guards}}(\pi) = \bigwedge\limits_{i \in 1, k-1} \Phi_{\text{guards}}(v_i@l_i \rightarrow v_{i+1}@l_{i+1}) Φguards(π)=i∈1,k−1⋀Φguards(vi@li→vi+1@li+1) 为数据依赖的路径条件。
-
Φ po ( π ) = ⋀ i ∈ 1 , k − 1 ⋀ j ∈ i , k − 1 Φ po ( v i @ l i → . . . → v j @ l j ) \Phi_{\text{po}}(\pi) = \bigwedge\limits_{i \in 1, k-1} \bigwedge\limits_{j \in i, k-1} \Phi_{\text{po}}(v_i@l_i \rightarrow ... \rightarrow v_j@l_j) Φpo(π)=i∈1,k−1⋀j∈i,k−1⋀Φpo(vi@li→...→vj@lj) 为语句偏序关系约束。
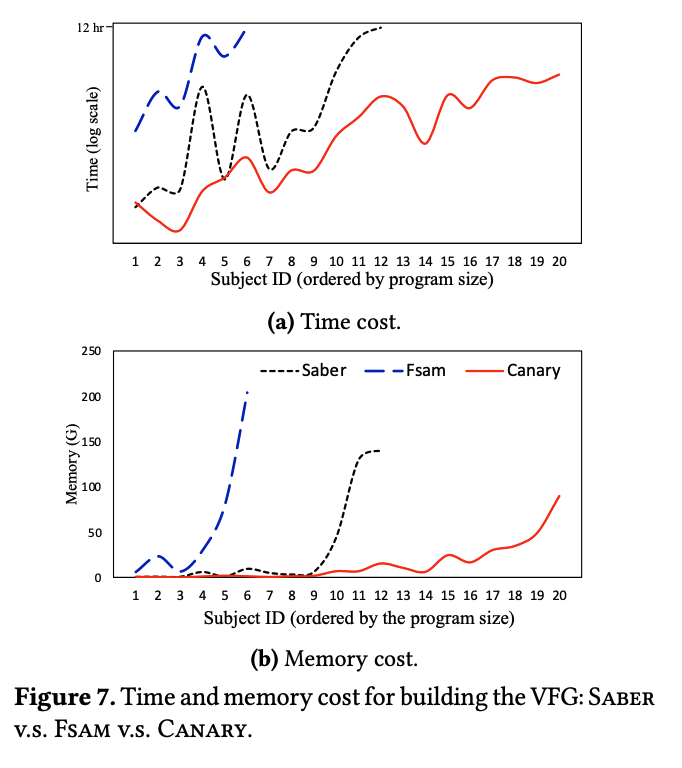
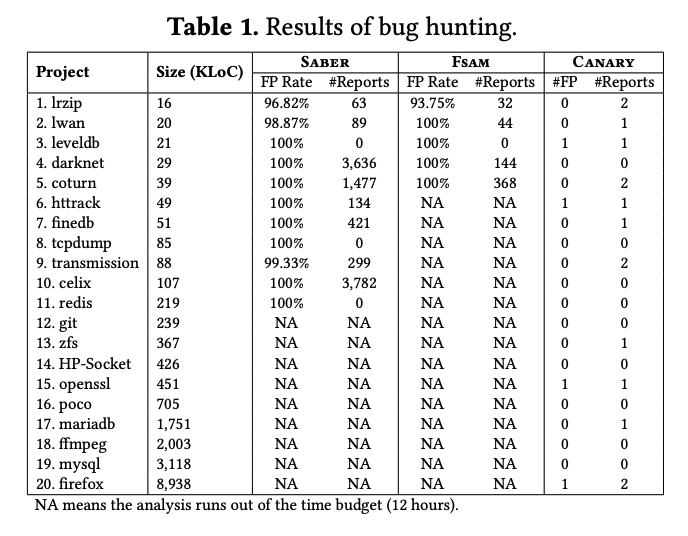
4.Evaluation
和FASM以及Saber进行了比较,采用了20个开源程序进行评估。