自己的原文哦~https://blog.51cto.com/whaosoft/11739891
#CLIP系列模型如何补短板再升级
CLIP(Contrastive Language--Image Pre-training)模型自推出以来,在图像-文本跨模态理解和生成领域取得了显著成果。然而,经典模型CLIP还是存在许多短板,对此,学界对CLIP模型的改造与增强还在持续进行中,希望通过改造CLIP模型架构、添加某些模块来弥补CLIP的能力短板,不断提升其在跨模态、少样本任务中的泛化性能与适用性。具体如下:
- 细化CLIP的视觉识别颗粒度
- 即提升其识别图像中细微差异和局部特征的能力,可以在视觉编码器部分引入更精细的特征提取机制。
- 可以采用多尺度特征融合策略,通过并行处理不同尺度的图像输入,并将多尺度特征进行有效融合,以捕捉图像中的多层次信息。
- 还可以引入注意力机制,使模型能够自动聚焦于图像中的关键区域或特征点。
- 结合弱监督学习或自监督学习方法,利用图像中的自然标注(如颜色、纹理等)或自生成标签(如聚类结果)来指导特征学习,也是提升视觉识别颗粒度的有效途径。
- 延长CLIP处理的文本长度并细化CLIP提取的文本信息
- 可以通过增加网络层数或采用更复杂的网络结构(如Transformer)来扩展文本编码器的容量,以支持更长的文本输入。
- 可以引入文本分段或分层处理机制,将长文本划分为多个子序列或段落,并分别进行编码和表示学习,最后再将各部分的表示进行有效融合。
- 为了细化文本信息的提取,可以设计更精细的文本表示学习方法,如基于词嵌入的向量表示、基于句法结构的图表示或基于语义角色的框架表示等。
- 对CLIP的图像文本输入做数据增强
- 对于图像数据增强,可以采用旋转、缩放、裁剪、翻转、颜色变换等传统方法,以及基于生成模型的对抗性样本生成等高级方法。
- 对于文本数据增强,则可以采用同义词替换、回译、随机删除、句子重组等方法来生成多样化的文本样本,或生成伪字幕改善输入数据的质量。
- 其他方法如, 通过文本到图像的扩散模型生成反馈来实现CLIP的自监督学习、增强模块以提升CLIP在某一少样本分类任务上的泛化能力等,还有的方法将CLIP输入扩展到视频......
本期推送再次盘点了CLIP模型架构还能如何改造,让我们一起来看看吧!
GroupViT: 从文本监督中实现语义分割
文章介绍了一个名为GroupViT(Grouping Vision Transformer)的模型 ,它是为了实现仅通过文本监督进行语义分割的任务而设计的。GroupViT通过一个分层的Transformer架构 进行视觉概念的逐步分组,从较小的图像片段合并成较大的任意形状的语义段。GroupViT首先将输入图像划分为多个不重叠的小patch,并将每个patch线性投影到潜在空间,形成输入的image token。在每个分组阶段 ,image token和group token通过Transformer层进行信息传播,通过自注意力机制(self-attention)聚合全局信息。每个分组阶段的末尾都有一个grouping block ,负责将相似的image token合并为更大的语义段(segment)。Grouping block通过计算group token和segment token之间的相似性矩阵来实现合并。在Grouping Block中,使用Gumbel-Softmax操作和直通技巧(straight through trick)来进行硬分配,使得segment tokens能够明确地分配给不同的group tokens。为了训练GroupViT执行分层分组,模型采用了特别设计的对比损失函数,包括原始的图像-文本对比损失和多标签对比损失。
相对于CLIP,GroupViT引入了分组机制 ,允许模型自动地将图像区域分组为语义段,而CLIP是一个基于对比学习的模型,主要用于图像和文本的联合表示学习,并没有显式的分组机制。GroupViT还采用了分层的Transformer架构 ,能够处理任意形状的图像段,而CLIP通常处理的是固定大小的图像patch。此外,GroupViT特有的Grouping Block模块 ,用于将图像tokens合并为更大的语义段。最后,GroupViT使用了多标签对比损失,通过从文本中提取名词并使用句子模板生成额外的文本标签,增强了模型对视觉分组的学习能力。
FFF:在对比性预训练中修复有缺陷的基础产生的视觉语言模型
文章提出了一种改进的对比性预训练方法,称为FFF(Fixing Flawed Foundations),旨在通过解决现有视觉-语言模型训练中的两个关键问题来增强模型性能:错误分配的负对(false negative pairs)和低质量及多样性不足的字幕(captions)。
- 在对比学习中,通常假设每个样本只有一个正对(positive pair),但实际中,由于图像和/或字幕在语义上的相似性,一些负对(negative pairs)可能被错误地标记。这导致训练过程和模型质量受限。为了解决这个问题,文章提出了一种基于图像-文本、图像-图像和文本-文本相似性的算法,用于发现并纠正这些错误分配的负对,并挖掘新的真正例(true positives)。
- 现有的网络收集的数据集往往包含质量低下、描述简短或不相关的字幕,这不利于训练。文章通过使用最先进的图像字幕技术生成伪字幕 (pseudo-captions),作为给定图像的新真正例,从而提高字幕的质量和描述性。为了进一步提升训练数据的多样性,文章提出了批量文本增强策略 。在同一个批次中,为每个训练图像生成多个伪字幕(例如,通过束搜索选择的五个字幕),这样可以有效增加字幕的多样性。
- 由于上述方法导致每个图像的正对数量可能不同,文章提出使用sigmoid loss作为训练损失函数。这种损失函数允许每个样本的正对数量动态变化,且对挖掘过程中的潜在错误具有鲁棒性。
文章展示了FFF方法在图像识别(在11个数据集上平均提高了约6%)和图像检索(在Flickr30k上提高了约19%,在MSCOCO上提高了约15%)方面的显著性能提升。总之,FFF方法通过解决负对分配错误和提升字幕质量与多样性,显著提高了视觉-语言模型的预训练效果,并通过使用sigmoid loss作为训练损失函数,有效地利用了多个正对进行训练。
DreamLIP:带有长字幕的语言图像预训练
文章提出的DreamLIP模型实现了从长标题中动态采样子标题,并与图像的局部区域进行细粒度对齐。
- DreamLIP首先使用预训练的多模态大型语言模型(MLLM)为30M图像重新生成详细的描述性长标题 ,这些长标题比现有的数据集更丰富、更详尽。进而从长标题中动态采样子标题 (subcaptions),以构建多个正对 (positive pairs)。每个子标题可能描述图像的一个部分,例如一个物体或者场景的一个方面。引入分组损失来匹配每个子标题的文本嵌入与相应的局部图像块。这种损失函数在自我监督的方式下工作,意味着它不需要外部标注来指导子标题和图像块之间的对齐。
- 采用多正对对比学习框架 (Multi-Positive Contrastive Learning),将文本嵌入与图像嵌入进行对齐,使得来自同一图像的多个子标题能够与图像的不同部分形成正对。通过分组损失实现细粒度对齐,确保每个子标题的文本特征与图像中相应的局部特征精确匹配,从而提高模型对图像细节的理解。将多正对对比损失和细粒度对齐损失结合起来,形成DreamLIP的整体训练目标函数,通过这个函数来优化模型。
在多种下游任务上进行实验,包括图像-文本检索、语义分割等,证明了DreamLIP模型相较于现有方法在细粒度表示能力上的一致优越性。通过这种方法,DreamLIP能够充分利用长标题中的信息,提高模型对图像内容的理解和表示能力,尤其是在零样本学习的场景下,展现出了强大的性能。
DIVA:扩散反馈帮助 CLIP 看得更清楚
对比语言-图像预训练 (CLIP) 擅长跨领域和模态抽象开放世界表示,已成为各种视觉和多模态任务的基础。然而,最近的研究表明,CLIP存在严重的视觉缺陷,例如几乎无法区分方向、数量、颜色、结构等 。这些视觉缺陷也限制了基于 CLIP 构建的多模态大型语言模型 (MLLM) 的感知能力。主要原因可能是用于训练 CLIP 的图像-文本对具有固有的偏见,因为缺乏文本的独特性和图像的多样性。这项工作提出了一种简单的CLIP模型后训练方法,该方法通过自监督扩散过程在很大程度上克服了其视觉缺陷。 我们介绍了 DIVA,它使用 DIffusion 模型作为 CLIP 的视觉助手。具体来说,DIVA利用来自文本到图像扩散模型的生成反馈来优化CLIP的表征 ,仅使用图像(没有相应的文本),从而实现了自监督学习。
- DIVA使用一个预训练的条件扩散模型 ,该模型能够根据条件生成详细的图像。扩散模型通过一个逐步添加高斯噪声的过程来学习图像的概率分布,这个过程可以逆转,从而从噪声中重建图像。DIVA利用文本到图像扩散模型的生成能力,将CLIP模型编码的视觉特征作为扩散模型的条件输入。这意味着CLIP的视觉特征被用来指导扩散模型生成图像 。通过最大化图像似然度,使用扩散损失来优化CLIP模型的表示。具体来说,扩散模型尝试预测每一步中添加的噪声,并通过这种方式来优化CLIP的权重,使其学习到更丰富的视觉细节。
- DIVA引入了一种视觉密集重述策略(Visual Dense Recap Scheme),通过结合局部区域的视觉特征(patch tokens)和类别标记(class token)来增强条件信息的丰富性,从而提高CLIP模型的优化能力。
- 尽管进行了优化,DIVA框架仍然保持了CLIP模型原有的零样本(zero-shot)能力,在多种图像分类和检索基准测试中表现出色。
通过在MMVP-VLM基准测试上的实验,DIVA显著提升了CLIP模型在细粒度视觉能力上的表现,并在多模态理解和分割任务上提高了MLLMs和视觉模型的性能。总的来说,DIVA模型通过一个简单而有效的自监督框架,使用扩散模型的生成反馈来优化CLIP的视觉表示,使其在视觉细节的感知上有了显著的提升,同时保留了CLIP的原有优势。
CLIP-FSAR:小样本动作识别的原型调制方法
本文的目标是迁移CLIP强大的多模态知识,以解决由于数据稀缺而导致的原型估计不准确的问题,这是少样本动作识别 (Few-shot Action Recognition, FSAR)中一个关键问题。文章提出了一种名为CLIP-FSAR 的原型调制框架,该框架由两个关键组件组成:视频-文本对比物镜(Video-text Contrastive Objective)和原型调制(Prototype Modulation)。
- 视频-文本对比物镜的目的是缩小CLIP和少样本视频任务之间的差异 。通过对比视频特征和对应的类别文本描述,框架能够学习如何将视频内容与文本描述相匹配。使用CLIP的视觉编码器(Visual Encoder)提取视频帧的特征,同时使用文本编码器(Text Encoder)提取文本描述的特征。然后通过全局平均池化(Global Average Pooling, GAP)和余弦相似度函数来计算视频特征和文本特征之间的匹配概率。最后应用交叉熵损失函数来优化视频-文本匹配概率,使得匹配对的相似度最大化,不匹配对的相似度最小化。
- 原型调制是为了解决少样本情况下视觉信息不足导致的原型估计不准确问题,原型调制组件利用CLIP中的文本语义先验来优化视觉原型。 首先在支持集(Support Set)的视觉特征基础上,将文本特征沿时间维度堆叠,并使用时间Transformer来自适应地融合文本和视觉特征。时间Transformer能够处理支持视频和查询视频的特征,使得融合后的特征在共同的特征空间中进行匹配,以计算查询视频与支持视频之间的距离。采用动态时间规整(Dynamic Time Warping, DTW)或其他时间对齐度量来计算查询视频和支持视频之间的距离,并通过少数样本度量目标(Few-shot Metric Objective)来进行分类。
CLIP-FSAR框架通过这两个组件的协同工作,能够充分利用CLIP模型中的丰富语义信息,生成可靠原型,并在少样本分类任务中实现精确分类。通过视频-文本对比物镜,CLIP-FSAR适应于视频任务,并通过原型调制增强了对视频中动作类别的识别能力。
MA-CLIP:CLIP的多模态自适应用于小样本动作识别
将大规模预训练的视觉模型(如 CLIP)应用于小样本动作识别任务可以提高性能和效率。利用"预训练,微调"范式可以避免从头开始训练网络,这可能既耗时又耗费资源。但是,这种方法有两个缺点。首先,用于小样本动作识别的标记样本有限,因此需要尽量减少可调参数的数量以减轻过拟合 ,这也会导致微调不足,从而增加资源消耗并可能破坏模型的广义表示。其次,视频的超时域维度挑战了小样本识别的有效时间建模 ,而预训练的视觉模型通常是图像模型。为了解决这些问题,本文提出了一种名为CLIP多模态适应 (MA-CLIP, Multimodal Adaptation of CLIP)的新方法。
- 轻量级适配器 (Lightweight Adapters)被添加到CLIP模型中,目的是最小化可学习的参数数量,从而减少过拟合的风险,并允许模型快速适应新任务。适配器的设计允许它们结合视频和文本信息,进行面向任务的时空建模。MA-CLIP利用视频的时空信息和文本的语义信息,通过适配器进行有效的多模态信息融合。这种融合方法可以提高模型对动作类别的识别能力,尤其是在小样本学习场景下。
- 模型不仅关注视频帧内的空间特征 ,还关注帧之间的时间关系 ,这对于理解动作的发展和变化至关重要。面向任务的时空建模(Task-oriented Spatiotemporal Modeling)使得MA-CLIP能够捕捉到动作的本质特征,提高识别的准确性。
- 文本引导的原型构建模块(TPCM, Text-guided Prototype Construction Module)基于注意力机制设计,用于增强视频原型的表示。通过利用文本描述,TPCM能够更好地理解视频内容,从而提高类别原型的质量,这对于小样本学习中的类别匹配和识别非常关键。
MA-CLIP设计为可以与任何不同的小样本动作识别时间对齐度量(如视频匹配器)一起使用,这增加了模型的通用性和灵活性。由于适配器的轻量级特性和参数数量的减少,MA-CLIP在训练时更加快速和高效,同时降低了训练成本。总的来说,MA-CLIP通过精心设计的适配器和文本引导的原型构建模块,有效地结合了视觉和语言信息,提高了小样本动作识别的性能,同时保持了模型的快速适应性和低训练成本。
APE:并非所有特征都重要:通过自适应先验优化增强CLIP的少样本泛化能力
现有的CLIP少样本泛化方法要么表现出有限的性能,要么存在过多的可学习参数。本文提出了 APE(Adaptive Prior rEfinement),这是一种为CLIP模型的预训练知识进行适应性细化的方法,旨在提高CLIP在下游任务中的性能,特别是在小样本学习场景下。
- APE通过先验细化模块(Prior Refinement Module) 分析下游数据中的类间差异性,目的是将领域特定的知识与CLIP模型中已经提取的缓存模型进行解耦,从而选择最有意义的特征通道。利用两个标准------类间相似度(inter-class similarity)和方差(variance) ------来选择最具区分性的特征通道,减少冗余信息并降低缓存大小,以减少内存成本。
- APE提供了两种模型变体:(1)无需训练的APE(Training-free APE) :直接利用细化后的缓存模型进行推理,探索测试图像、细化的缓存模型和文本表示之间的三边亲和性,实现无需训练的稳健识别。(2)需要训练的APE-T :在APE的基础上,增加了一个轻量级的类别残差模块(category-residual module),该模块只需对类别残差进行训练,而不需要对整个缓存模型进行昂贵的微调。这个模块进一步更新细化的缓存模型,并在模态之间共享以确保视觉-语言的对应关系。
- APE模型探索了测试图像、先验缓存模型和文本表示之间的三边关系,通过这种关系来增强小样本学习的性能。
APE和APE-T在保持高计算效率的同时,实现了在多个基准测试中的最先进性能,特别是在16次拍摄的ImageNet分类任务中,APE和APE-T分别以少于第二佳方法+1.59%和+1.99%的平均准确率,并且具有×30更少的可学习参数。
.
#SAM2-Adapter
SAM2无法分割一切?首次让SAM2适应一切!
SAM2-Adapter是一种新型适配方法,旨在充分利用Segment Anything 2(SAM2)模型的高级功能,以应对特定的下游分割任务。
2023年,Meta提出了SAM,在图像分割领域取得了突破的进展。但是,研究人员也发现了SAM在医学图像领域、伪装物体等领域效果不佳,因此,我们在SAM发布后两周提出了SAM-Adapter,它成功地将Segment Anything (SAM) 模型应用于特定的复杂任务中,如伪装物体检测、阴影识别和医学图像分割,展现出完美的表现。SAM-Adapter不仅为科研人员提供了强大的工具,还在学术界和工业界产生了深远的影响,成为处理高难度分割任务的首选方案。随着Segment Anything 2 (SAM2) 的出现,这一升级版的模型在架构和数据训练规模上进行了大幅度的增强,为更复杂的图像分割任务提供了新的可能性。SAM2的发布带来了更强大的基础能力,但也提出了新的挑战:如何将这些增强的功能应用于具体的下游任务中。令人振奋的是,我们在新工作中展示了,SAM-Adapter的微调方法在SAM2上再次取得了成功。通过SAM2-Adapter的引入,研究人员将SAM2的潜力充分释放,在各类复杂任务中继续实现最先进(SOTA)的性能。这一成果不仅延续了SAM-Adapter的影响力,还证明了其方法的通用性和强大效能,推动了图像分割技术的进一步发展。论文和代码均已开源。
单位:魔芯科技、浙大等
项目页面:http://tianrun-chen.github.io/SAM-Adaptor
论文:https://arxiv.org/abs/2408.04579
开源代码(已开源):https://github.com/tianrun-chen/SAM-Adapter-PyTorch
- 研究背景
在人工智能(AI)的研究领域,基础模型的引入已经显著地重塑了研究的版图,特别是在这些模型经过大规模数据集训练后。最近,Segment Anything(SAM)模型因其在图像分割领域的杰出成就而受到广泛关注。然而,尽管SAM在图像分割任务中表现出色,但先前的研究也指出了它在处理某些复杂低层次结构分割任务时的性能限制。为了应对这些挑战,研究人员在SAM模型发布不久之后,便开发了SAM-Adapter,目的是通过增强SAM的功能来提升其在这些任务上的表现。SAM-Adapter的设计架构在下图中进行了详细展示。
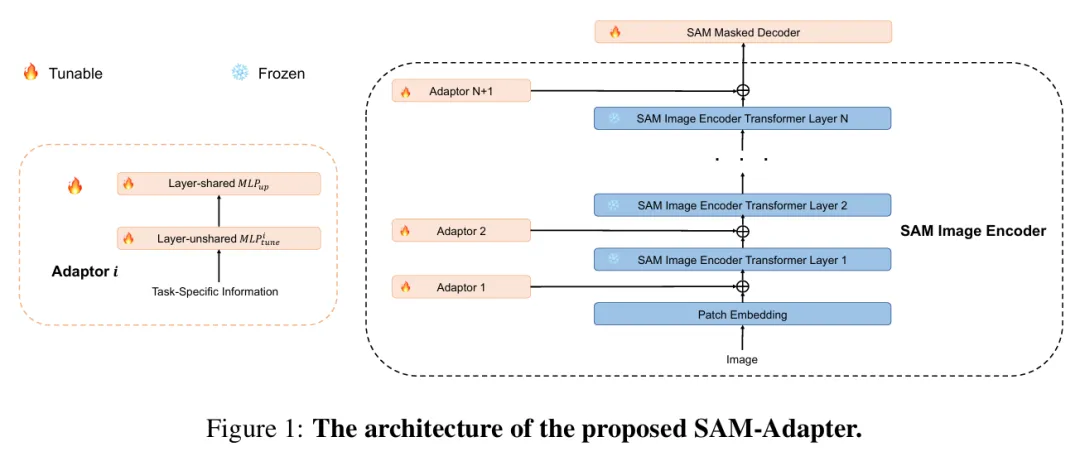
随着技术的发展,一个更为强大和通用的模型------Segment Anything 2 (SAM2)应运而生。SAM2在SAM的基础上对网络架构进行了优化,并在更广泛的视觉数据上进行了训练,引起了科研界的广泛关注。这引发了两个关键问题:
1. SAM在下游任务中遇到的挑战是否同样存在于SAM2?
2. 是否能够借鉴SAM-Adapter的成功经验,利用SAM2的先进预训练编码器和解码器,在这些任务中达到新的最前沿(SOTA)水平?
- SAM2-Adapter
本研究的实验结果对这两个问题都给出了肯定的答案。尽管基础模型的固有局限性仍然存在,例如训练数据无法完全覆盖所有可能的场景,但通过引入SAM2-Adapter,研究者成功地在多个任务中实现了SOTA性能。SAM2-Adapter不仅继承了SAM-Adapter的核心优势,还引入了显著的改进,SAM2-Adapter有效地利用了SAM2的多分辨率和分层特性,实现了更为精确和鲁棒的分割效果。
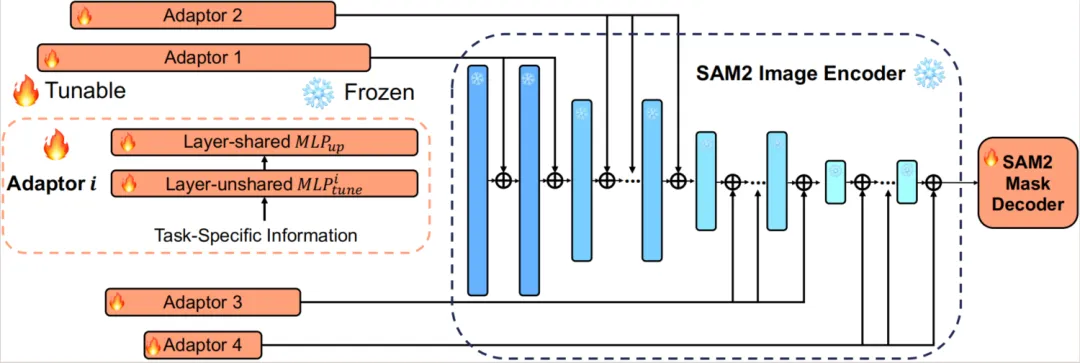
SAM2-Adapter 的核心基于SAM2模型的强大图像编码器和掩码解码器组件。具体来说,利用从 SAM2 中预训练的 MAE Hiera 图像编码器,并冻结其权重以保留从大规模数据集预训练中学到的丰富视觉表示。此外,研究团队使用了原始 SAM2 模型的掩码解码器模块,初始化其权重为预训练的 SAM2 参数,然后在训练适配器过程中进行微调。这个方法没有为原始 SAM2 掩码解码器提供任何额外的提示作为输入。
与 SAM-Adapter 的成功方法类似,通过适配器学习并注入任务特定的知识F^i到网络中。这个方法采用提示的概念,这利用了基础模型(如 SAM2)已在大规模数据集上训练的事实。使用适当的提示来引入任务特定的知识可以增强模型在下游任务上的泛化能力,尤其是在标注数据稀缺的情况下。
这个方法旨在保持适配器设计的简单和高效。因此选择使用一个仅由两个 MLP 和一个激活函数组成的适配器。值得注意的是,与 SAM 不同,SAM2 的图像编码器具有四个层次的分层分辨率。因此,本方法初始化了四个不同的适配器,并将四个适配器插入每个阶段的不同层中。
- 实验验证
在实验中,研究团队选择了两个具有挑战性的低级结构分割任务和一个医学成像任务来评估SAM2-Adapter的性能:伪装物体检测、阴影检测和息肉分割。
3.1 伪目标检测
研究团队首先评估了SAM在伪装物体检测这一具有挑战性的任务中的表现,这项任务的调整在于前景物体通常与视觉上相似的背景图案融合在一起。实验表明,SAM在该任务中表现不佳。如图所示,SAM无法检测到多个隐藏物体。定量结果进一步确认了这一点,表明SAM在所有评估指标上的表现显著低于现有的最先进方法,而SAM2本身的表现最低,无法产生任何有意义的结果。实验结果证明,通过引入SAM2-Adapter,这个方法显著提高了模型的性能。该方法成功识别了隐藏的物体。
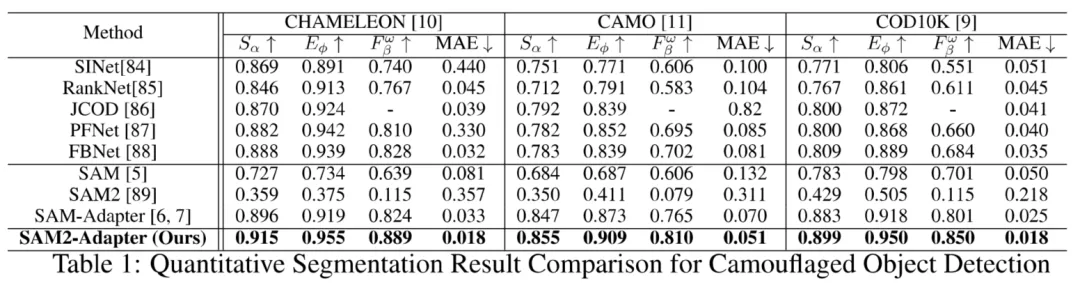

3.2 阴影检测
研究团队进一步评估了SAM在阴影检测中的表现。SAM2-Adapter的表现与SAM-Adapter一样出色,提供了可比的结果。

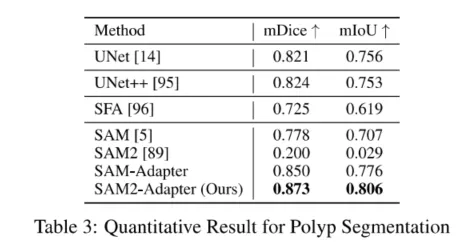
3.2 息肉分割
研究团队还展示了SAM2-Adapter在医学图像分割中的应用,特别是息肉分割。息肉在结肠镜检查过程中被识别并通过息肉切除术移除。准确快速地检测和移除息肉对于预防结直肠癌至关重要。在没有适当提示的情况下,SAM2模型无法产生有意义的结果。SAM2-Adapter解决了这个问题,并且优于原始的SAM-Adapter。根据定量分析和可视化结果,强调了SAM2-Adapter在提高息肉检测准确性和可靠性方面的有效性。
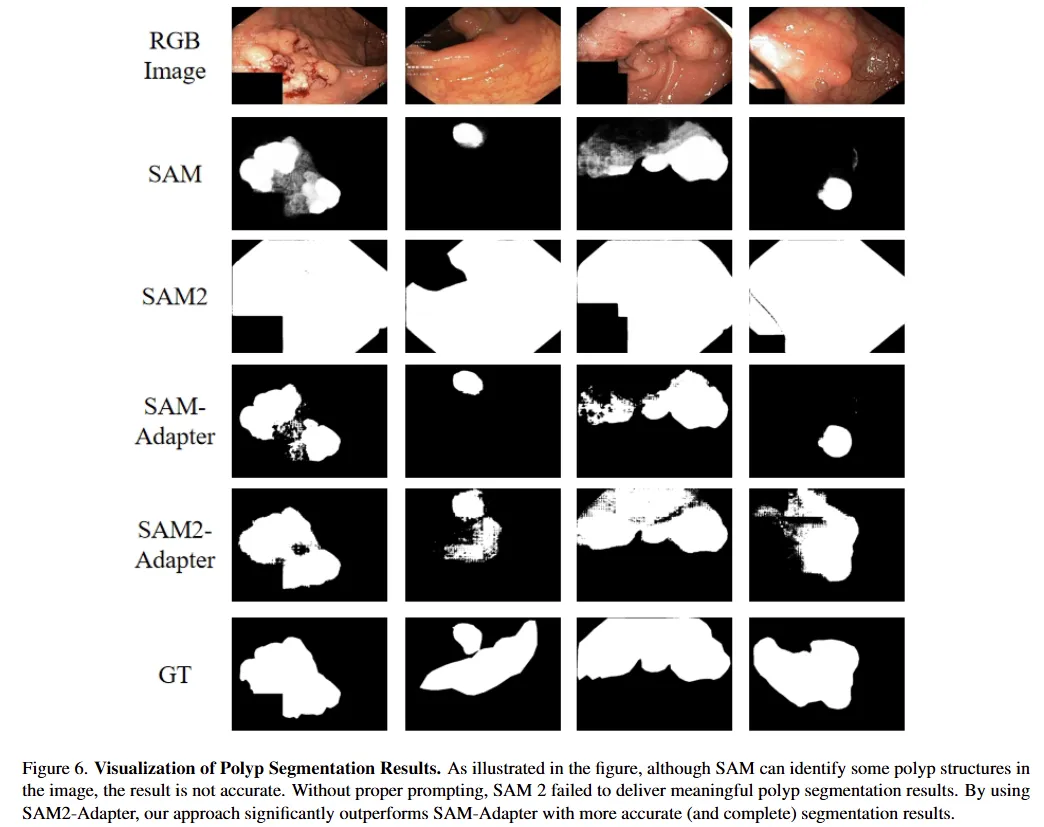
- 总结与展望
SAM2-Adapter是一种新型适配方法,旨在充分利用Segment Anything 2(SAM2)模型的高级功能,以应对特定的下游分割任务。基于SAM-Adapter的成功,SAM2-Adapter针对SAM2的多分辨率分层Transformer架构进行了优化,成功克服了SAM的局限性,在伪装物体检测、阴影检测和息肉分割等挑战性任务中实现了新的最先进(SOTA)性能。实验结果表明,SAM2-Adapter不仅保留了其前身的优势,如泛化性和可组合性,还通过与SAM2的高级架构无缝集成进一步增强了这些能力。这使得SAM2-Adapter在各种数据集和任务中设定了新的基准,超越了之前的方法。从SAM到SAM2的持续挑战反映了基础模型在多样化现实场景中的复杂性。尽管如此,SAM2-Adapter有效解决了这些问题,展示了其作为高质量分割工具的潜力,适用于多种应用领域。研究人员和工程师被鼓励采用SAM2结合SAM2-Adapter,以提升分割任务的性能,推动图像分割领域的发展。这项工作不仅扩展了SAM2的能力,还为未来的大规模预训练模型在专门应用中的创新奠定了基础。
.
#文远知行
文远知行上市基石曝光:博世认购部分,IPO作价50亿美元
50亿美元 ,这就是国产通用型自动驾驶公司,文远知行刚刚曝光的IPO作价。
据文远知行更新的招股书信息,明确了IPO将增发的股票数量,以及每股价格,公司估值随之曝光。
其中超过91%的公开增发股份,将由百年Tier 1巨头博世认购。
博世之前已经参与了文远知行的融资,并且双方还落地了L2+方案的合作,而现在博世更进一步以基石投资者身份,帮文远冲击纳斯达克。
此外,首次公开募股的同时,文远知行还将开启私募,总计将获得折合人民币超31.5亿元的资金。
文远知行的IPO,已经到了最后100米冲刺。
360亿,文远知行估值曝光
文远知行向美监管机构提交的最新文件显示,文远知行此次IPO将发行6452000股ADS(美国存托股),每份ADS价格为15.5-18.5美元 ,1份ADS相当于3份普通股。
即此次增发股份的融资金额为1-1.2亿美元,折合人民币约为7.17-8.56亿元。
此次增发股份后,文件显示文远知行将拥有总共814132531股普通股。
若按最高股价计算,则文远知行的市值将冲上50.2亿美元 ,折合人民币约为359.83亿元。
这个作价,实际与2022年11月D+轮融资后,文远知行投后超50亿美元的估值相比,变化并不大。
或许也是文远知行对于这次上市务实求真的态度,没有追求更高的溢价。
而且此次公开增发的股份,将由Tier 1巨头博世认购绝大部分。
文件显示,博世购买的ADS数量为5882353份,约占增发ADS总数的91.2%。
博世与文远知行渊源颇深,既是文远知行的投资者 ,也是文远知行的高阶智驾合作方。
2022年3月,博世和广汽等参与了文远知行的D轮融资,融资金额为4亿美元,当时折合人民币约为25.2亿元。
也差不多是这一轮融资,文远知行的估值达到了44亿美元。
两个月后,博世与文远知行达成合作,将联合开发L2+级ADAS,自此文远知行搭上了第一Tier 1的快车,走上了一条令供应商艳羡的道路。
△左二为时任博世中国执行副总裁、现任总裁徐大全博士,右二为文远知行联合创始人兼CTO李岩博士
经过18个月的努力,双方合作方案成功落地,上车奇瑞星纪元ES,可实现高速NOA,包括超车变道、避让施工区域、自动上下匝道等。
博世此次认购超91%的发行股份,可视为双方合作关系的进一步深化,也说明文远的实力得到了博世的认可。
如此比例的认购,实际也不算多见,全球第一Tier 1帮文远冲刺通用型自动驾驶第一股。
除了增发股份之外,文远知行还表示完成IPO的同时,还会以私募方式,出售价值3.205亿美元(折合人民币约为23亿元)的A类普通股。
相关投资者有Alliance Ventures 、广汽资本、Beijing Minghong、Kechuangzhixing等。
其中Alliance Venture是雷诺日产三菱联盟旗下的战略风投部门,是文远知行的早期投资者。
曾在2018年领投A轮,后又在2021年参与了C轮融资,此次将认购9700万美元,折合人民币约为6.95亿元的A类普通股。
文远知行和雷诺日产等也有合作关系。
2022年11月,文远知行联合日产在苏州落地了Robotaxi,并亮相当年的进博会。
今年5月,雷诺和文远知行合作的无人小巴在法网提供接驳服务。
广汽也是文远知行过去的投资者,曾在2021年底参与文远知行的战略投资,以及2022年3月的D轮融资,此次将认购2000万美元(折合人民币约为1.43亿元)的A类普通股。
简单计算一下可知,文远知行此次将通过IPO和私募等途径,累计获得约4.4亿美元,折合人民币超31.5亿元的资金。
文远知行在文件对资金的用途做了说明:
- 约35%用于自动驾驶技术、产品和服务的研发。
- 约30%用于自动驾驶车队的商业化和运营,拓展市场的营销活动。
- 约25%用于资本支出,包括购买测试车辆、研发设施和行政支出。
- 剩余10%用于公司一般用途。
所以,文远知行靠什么撑起了50亿美元的估值,能够收获博世等合作伙伴的青睐?
文远知行靠什么值50亿美元
文远知行成立于2017年,目前在7个国家30座城市开展自动驾驶的研发、测试和运营,是唯一同时拥有中国、美国、阿联酋和新加坡四地自动驾驶牌照的科技企业。
提供L2和L4级自动驾驶产品与服务,不久前向美国证监会提交招股书,冲刺纳斯达克。
在招股书中,文远知行披露了最近三年半的财务指标。
其中2021年的营收为1.38亿元 ,2022年暴涨至5.28亿元 ,实现**281.7%**的同比增长。
2023年营收略有下滑,为4亿元。
截止2024年上半年,文远知行营收为1.5亿元,对比2023年同期仍然略有下降。
目前公司尚未实现盈利,三年累计净亏损13.31亿元。
从图中可以看到,文远知行的亏损在扩大,这和研发投入逐年增高有关系。
文远知行共有员工2227名 ,其中约**91%**都是研发人员。
2021年研发投入为4.43亿元,2022年几乎翻了一番,增长至7.59亿元,2023年继续增长至10.58亿元。
今年上半年的研发投入,已达5.17亿元。
研发投入远大于营收,对亏损起到了一定影响。
但目前公司的现金储备还比较充足,截止2024年上半年末,文远知行现金及其等价物约为18.28亿元。
所以,亏损中的文远知行,有什么技术和业务,撑起了50亿美元的估值?
文远知行的核心平台是WeRide One ,基于此打造L2和L4级自动驾驶技术,落地乘用车、Robotaxi、无人小巴和自动驾驶厢货车和无人清扫车。
同时押注两条路线,落地产品范围广,这也是为什么,文远知行被称为通用自动驾驶第一股。
从文远知行的营收组成变化来看,文远知行的业务正在发生转变。
招股书显示,文远的营收来源主要分为产品 和服务两大部分。
2021年的营收中,前者占了大头,带来1.01亿元的营收,占比高达73.5% 。而服务则只有0.37亿元的收入,占比26.5%。
而到了2023年,公司产品收入为0.54亿元,占比降至13.5%,服务收入增长至3.48亿元,占比升至89.9%。
这表明,文远知行的商业化模式,正在经历转折:
从一个运营Robotaxi车队,或给运营商卖车辆硬件的**"重资产"模式** ,走向提供技术、提供后续服务的轻资产模式。
短期内,文远营收会受到博世智驾推广覆盖速度的影响。
但长期来看,博世的方案就是全行业的方案,是可持续产生营收的现金奶牛项目。
文远知行还将坚持L4自动驾驶,其判断2024年和2025年随着Robotaxi的大规模投放,来自服务的收入占比将会进一步提升。
最后,简单介绍一下文远知行的两位主要创始人:
CEO韩旭,伊利诺伊大学香槟分校计算机工程博士,历任密苏里大学的助理教授,密苏里大学博士生导师、终身教授,计算机视觉和机器学习实验室主任。
创业前曾担任百度美研自动驾驶事业部首席科学家。
联合创始人兼CTO李岩,卡内基梅隆大学电气与计算机工程学博士,曾在Facebook和微软担任核心工程师。
相比两位创始人,文远知行也因为脱口秀演员赵晓卉的加盟而出圈。
不过赵晓卉在文远知行,担任的是项目经理,与其演员身份有着明确区隔,也没有对文远做过多的公众宣传。
此前其在综艺节目上曾透露,正在负责无人小巴接驳车的部分功能。
相比赵晓卉之于文远知行,文远知行带给这位"打工人"则价值更大。文远知行不仅给了汽车科班出身赵晓卉业务能力认可,如今也在上市IPO进展中,印证了赵晓卉当初眼光的长远。
毕竟相比李诞的笑果文化和脱口秀行业,自动驾驶确实前途光明多了。
One More Thing
招股书之外,近日文远知行还预告了新动向:10月15日将发布新一代Robotaxi车型。
与马斯克和特斯拉,也就前后脚吧。
实际上,随着自动驾驶技术正在实现的技术和商用运营突破,自动驾驶不论是产品还是资本运作,都来到了新周期。
文远知行IPO,只是浪潮中的浪花一朵,同样在潮尖之上的,还有M公司、P公司...以及刚刚通过港股聆讯的H公司。
一个新的周期,已经来到了公众面前。
.
#RadarPillars
从4D雷达中进行高效目标检测(速度精度均有优势)
原标题:RadarPillars: Efficient Object Detection from 4D Radar Point Clouds
论文链接:https://arxiv.org/pdf/2408.05020
作者单位:曼海姆应用科学大学
论文思路:
汽车雷达(radar)系统已经发展到不仅提供距离、方位角和多普勒速度,还能提供俯仰数据。这一额外的维度使得4D雷达可以表示为3D点云。因此,现有的用于3D目标检测的深度学习方法,最初是为LiDAR数据开发的,经常被应用于这些雷达点云。然而,这忽略了4D雷达数据的特殊特性,例如极端稀疏性和速度信息的最佳利用。为了弥补这些在现有技术中的不足,本文提出了RadarPillars,一种基于柱状结构的目标检测网络。通过分解径向速度数据,引入PillarAttention进行高效特征提取,并研究层缩放以适应雷达稀疏性,RadarPillars在View-of-Delft数据集上的检测结果显著优于现有技术。重要的是,这在显著减少参数量的同时,实现了超越现有方法的效率,并在边缘设备上实现了实时性能。
论文设计:
在自动驾驶和汽车应用的背景下,雷达作为一种关键的感知技术脱颖而出,使车辆能够检测到周围的物体和障碍物。这一能力对于确保各种自动驾驶功能的安全性和效率至关重要,包括碰撞避免、自适应巡航控制和车道保持辅助。雷达技术的最新进展导致了4D雷达的发展,它结合了三个空间维度以及一个额外的多普勒速度维度。与传统雷达系统不同,4D雷达引入了作为第三维度的俯仰信息。这一增强功能使得雷达数据可以表示为3D点云,类似于LiDAR或深度感应相机生成的点云,从而能够应用之前仅限于这些传感器的深度学习方法。
然而,尽管来自LiDAR检测领域的深度学习技术已经被适配到4D雷达数据上,但它们并没有充分探索或适应其独特特性。与LiDAR数据相比,4D雷达数据显著稀疏。尽管存在这种稀疏性,雷达独特地提供了速度作为特征,这在各种场景中有助于移动物体的检测,例如在LiDAR传统上难以应对的远距离场景中1。在View-of-Delft数据集中,平均每次4D雷达扫描仅包含216个点,而相同视野内的LiDAR扫描包含21,344个点2。对此,本文提出了RadarPillars,一种专门为4D雷达数据量身定制的新型3D检测网络。通过RadarPillars,本文填补了当前技术中的空白,并在以下几个方面做出了贡献,大幅提升了性能,同时保持了实时能力:
- 增强速度信息的利用:本文分解径向速度数据,提供额外的特征,从而显著提升网络性能。
- 适应雷达稀疏性:RadarPillars利用柱状表示法3进行高效的实时处理。本文利用4D雷达数据固有的稀疏性,并引入PillarAttention,一种将每个 pillar 作为一个 token 处理的新型自注意层,同时保持效率和实时性能。
- 针对稀疏雷达数据的扩展:本文展示了雷达数据的稀疏性可能导致检测网络中信息量较少的特征。通过均匀网络,本文不仅提升了性能,还显著减少了参数量,从而提高了运行效率。
图1:RadarPillars在4D雷达上的检测结果示例。汽车用红色标记,行人用绿色标记,骑行者用蓝色标记。点的径向速度由箭头指示。
图2:补偿了4D雷达自车运动的绝对径向速度 v_r 。随着物体的移动, v_r 会根据其相对于传感器的航向角发生变化。由于其航向无法确定,汽车的实际速度v仍然未知。然而, v_r 可以分解为其x和y分量,以提供额外的特征。坐标系统和命名法遵循View-of-Delft数据集2。
图3:PillarAttention概述。本文利用雷达点云的稀疏性,通过使用掩码从非空 pillars 中收集特征,将空间大小从H, W减少到p。每个具有C通道的柱状特征被视为计算自注意力的一个 token 。本文的PillarAttention封装在一个Transformer层中,前馈网络(FFN)由层归一化(Layer Norm)和两个中间带有GeLU激活的MLP组成。PillarAttention的隐藏维度E由层前后的MLP控制。最后,具有C通道的柱状特征被散射回其在网格中的原始位置。本文的PillarAttention不使用位置嵌入。
图4:本文提出的方法组合形成RadarPillars,与基准方法PointPillars 3的比较。在View-of-Delft数据集2上,整个雷达区域的一帧目标检测精度结果。帧率是在Nvidia AGX Xavier 32GB上评估的。
图5:权重幅度分析比较不同通道大小的均匀缩放RadarPillars。结果显示,随着网络规模的减小,权重强度增加。本可视化排除了无效权重和异常值。
实验结果:
总结:
本文提出了RadarPillars,利用4D雷达数据进行目标检测的新方法。作为一个仅有 0.27 M 参数和1.99 GFLOPS的轻量级网络,RadarPillars在检测性能方面建立了新的基准,同时实现了实时能力,显著超越了当前的先进技术。本文研究了雷达速度的最佳利用,以为网络提供增强的上下文。此外,本文引入了PillarAttention,这是一种创新的层,将每个 pillar 视为一个 token ,同时确保效率。本文展示了均匀缩放网络在检测性能和实时推理方面的优势。以RadarPillars为基础,本文未来的工作将集中于通过优化主干网络和探索无锚检测头来提升运行时间。另一条研究途径是研究使用仅包含PillarAttention的Transformer层进行端到端的目标检测,或将有前景的LiDAR方法38, 39适用于雷达。此外,本文还提出将RadarPillars扩展到其他传感器数据模态的潜力,如深度传感器或LiDAR。
引用:
@ARTICLE{2024arXiv240805020M,
author = {{Musiat}, Alexander and {Reichardt}, Laurenz and {Schulze}, Michael and {Wasenm{\"u}ller}, Oliver},
title = "{RadarPillars: Efficient Object Detection from 4D Radar Point Clouds}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computer Vision and Pattern Recognition},
year = 2024,
month = aug,
eid = {arXiv:2408.05020},
pages = {arXiv:2408.05020},
doi = {10.48550/arXiv.2408.05020},
archivePrefix = {arXiv},
eprint = {2408.05020},
primaryClass = {cs.CV},
adsurl = {https://ui.adsabs.harvard.edu/abs/2024arXiv240805020M},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}.
#NTU开源嵌入式平台AirSLAM
高效&鲁棒的点线视觉SLAM系统
vslam的光照挑战
现有的vSLAM系统在面对严苛光照条件时仍然面临两类挑战:
- 短期光照挑战:剧烈的光照变化或低光照环境下,特征检测和跟踪经常失败,从而严重影响轨迹估计的质量。它影响了两个时间上相邻帧之间的姿态估计
- 长期光照挑战:当视觉地图用于重定位时,光照的变化可能显著降低成功率。它影响了查询帧与已有地图之间的匹配。
现有方法通常只聚焦于上述挑战中的某一个。例如,各种图像增强和图像归一化算法已经被开发出来,以确保鲁棒的跟踪。这些方法主要集中于保持全局或局部亮度的一致性,但它们通常难以处理所有类型的光照挑战。一些系统通过在包含各种光照条件的大型数据集上训练VO或SLAM网络来解决这一问题。然而,它们很难生成适合长期定位的地图。一些方法可以提供光照鲁棒的重定位,但通常需要在良好光照条件下构建地图。
本文介绍的AirSLAM 1将点和线特征结合起来用于跟踪、建图、优化和重定位。为了在效率和性能之间取得平衡,设计了一个混合系统,采用基于学习的方法进行特征检测和匹配,采用传统的几何方法进行姿态和地图优化。此外,为了提高特征检测的效率,我们开发了一个统一的模型,能够同时检测点和线特征。我们还通过提出一个多阶段的重定位策略来应对长期定位的挑战,该策略能够有效地重用我们的点线地图。
C++源代码链接:https://github.com/sair-lab/AirSLAM
相比前作AirVO2,AirSLAM是扩展版本,其实质性的改进包括:
- 设计了一个统一的CNN来检测点和线特征,增强了特征检测在光照挑战环境中的稳定性。此外,我们使用了更高效的LightGlue进行特征匹配。
- 扩展了系统,使其支持立体数据和立体惯性数据,在提供惯性测量单元(IMU)的情况下提高了系统的可靠性。
- 集成了回环检测和地图优化,形成了一个完整的vSLAM系统。
- 设计了一个基于点和线特征的多阶段重定位模块,使得系统能够有效应对长期光照挑战。
系统概述
一个实用的vSLAM系统应具备以下特性:
- 高效性:系统应在资源受限的平台上具备实时性能。
- 可扩展性:系统应易于扩展,以适应各种需求和实际应用。
- 易于部署:系统应易于在真实机器人上部署,并能够实现稳健的定位。
该系统是一个混合系统,如图1所示,因为需要数据驱动方法的鲁棒性和几何方法的精度。它包括三个主要组件:立体视觉里程计(Stereo VO/VIO)、离线地图优化和轻量级重定位。
- 立体视觉里程计(Stereo VO/VIO):提出了一种基于点线的视觉里程计,能够处理立体视觉数据和立体惯性数据。
- 离线地图优化:实现了几个常用的插件,如回环检测、位姿图优化和全局捆绑调整。系统可以通过添加自定义插件,轻松扩展以实现其他地图处理目的。例如,我们实现了一个插件,用于使用线特征的端点训练场景依赖的交汇点词汇,并在轻量级多阶段重定位中使用。
- 轻量级重定位:提出了一种多阶段的重定位方法,提高了效率的同时保持了效果。在第一阶段,使用提出的PLNet检测关键点和线特征,并使用在大型数据集上训练的关键点词汇检索若干候选。在第二阶段,使用场景依赖的交汇点词汇和结构图快速过滤掉大部分错误的候选。在第三阶段,在查询帧和剩余候选之间进行特征匹配,以找到最佳匹配并估计查询帧的位姿。由于第三阶段的特征匹配通常是耗时的,因此第二阶段的过滤过程提高了系统的效率,相较于其他两阶段的重定位系统。
将一些耗时的过程,如回环检测、位姿图优化和全局捆绑调整,转移到离线阶段。这提高了在线建图模块的效率。在许多实际应用中,例如仓库机器人,通常由一个机器人构建地图,然后由其他机器人重用。设计的系统考虑到了这些应用需求。轻量级的映射和地图重用模块可以轻松部署在资源受限的机器人上,而离线优化模块可以在更强大的计算机上运行,用于各种地图操作,如地图编辑和可视化。映射机器人将初始地图上传到计算机,然后计算机将优化后的地图分发给其他机器人,确保无漂移的重定位。
特征检测
动机
基于学习的特征检测方法在光照挑战环境中展现出了比传统方法更稳定的性能。然而,现有的基于点线的视觉里程计(VO/VIO)和SLAM系统通常分别检测关键点和线特征。对于手工设计的方法,由于其效率较高,可以接受这种做法,但对于基于学习的网络来说,同时应用关键点检测和线检测网络,尤其是在立体配置中,会影响资源受限平台上的实时性能。因此需要设计一个能够同时检测关键点和线特征的高效统一模型。
然而,实现一个同时检测关键点和线特征的统一模型是有挑战性的,因为这些任务通常需要不同的真实图像数据集和训练过程。关键点检测模型通常在包含多种图像的大型数据集上训练,并依赖于提升步骤或图像对的对应关系进行训练。对于线特征检测,我们发现线框解析方法比自监督模型提供了更强的几何线索,因为它们能够检测到更长且更完整的线条。
架构设计
如图2所示,当可视化关键点和线特征检测网络的结果时,有两个发现:
- 大多数由线特征检测模型检测到的线端点(交点)也被关键点检测模型选为关键点
- 关键点检测模型输出的特征图包含了边缘信息。
因此,可以基于预训练的关键点检测模型的骨干网络构建一个线特征检测模型。基于这一假设,设计了PLNet以在一个统一框架中检测关键点和线特征。如图3所示,包括共享的骨干网络、关键点模块和线特征模块。
- 骨干网络:采用了SuperPoint的设计作为骨干网络,因为它具有良好的效率和效果。它使用了8层卷积层和3层最大池化层。输入是尺寸为𝐻 × 𝑊的灰度图像,输出为𝐻 × 𝑊 × 64、𝐻/2 × 𝑊/2 × 64、𝐻/4 × 𝑊/4 × 128、𝐻/8 × 𝑊/8 × 128的特征图。
- 关键点模块 :同样遵循SuperPoint的设计来构建关键点检测头。它有两个分支:得分分支 和描述符分支。输入是骨干网络输出的𝐻/8 × 𝑊/8 × 128特征图。得分分支输出尺寸为𝐻/8 × 𝑊/8 × 65的张量,其中65个通道对应一个8×8的网格区域和一个表示没有关键点的垃圾箱。该张量经过softmax处理后再调整尺寸为𝐻 × 𝑊。描述符分支输出尺寸为𝐻/8 × 𝑊/8 × 256的张量,用于插值计算关键点的描述符。
- 线特征模块:该模块以𝐻/4 × 𝑊/4 × 128的特征图为输入。它由一个类U-Net的CNN和线特征检测头组成。将U-Net进行了修改,使其包含更少的卷积层,从而提高了效率。类U-Net的CNN用于增加感受野,因为检测线条比检测关键点需要更大的感受野。使用EPD LOIAlign处理线特征模块的输出,并最终输出交点和线条。
网络训练
PLNet训练分为两轮。
- 在第一轮中,仅训练骨干网络和关键点检测模块,这意味着我们需要训练一个关键点检测网络。
- 在第二轮中,固定骨干网络和关键点检测模块,仅在Wireframe数据集上训练线特征检测模块。我们跳过了第一轮的详细内容,因为它们与非常相似,而是介绍线特征检测模块的训练过程。
- 线编码:采用吸引区域场来编码线段。对于线段l = (x1, x2),其中x1和x2是l的两个端点,p是l的吸引区域中的一个点,使用p和四个参数来编码l:
其中𝑑是p到l的垂线段,𝜃是l与图像Y轴的夹角,𝜃1是p到x1的夹角,𝜃2是p到x2的夹角。
- 线特征预测:线特征模块输出一个尺寸为𝐻/4 × 𝑊/4 × 4的张量来预测参数,并输出一个热图来预测交点。对于每个通过参数解码的线段,从热图中选择与端点最接近的两个交点,并形成线条提议。然后使用EPD LOIAlign和一个头分类器来决定线条提议是否为真正的线特征。
- 线特征模块训练:使用𝐿1损失来监督参数的预测,并使用二元交叉熵损失来监督交点热图和头分类器的输出。总损失为它们的和。为了提高线特征检测在光照挑战环境中的鲁棒性,对训练图像进行了七种类型的光度数据增强处理。训练使用ADAM优化器,前35个epoch学习率为4𝑒-4,最后5个epoch学习率为4𝑒-5。
立体视觉里程计
概述
基于点线的立体视觉里程计(Stereo Visual Odometry)如图5所示。它是一个混合VO系统,结合了基于学习的前端和传统优化的后端。对于每对立体图像,首先使用所提出的PLNet提取关键点和线特征。然后使用一个图神经网络(LightGlue)来匹配关键点。同时通过关键点匹配结果关联线特征,并进行线特征匹配。接下来执行初始位姿估计并剔除离群值。基于这些结果,对关键帧的2D特征进行三角测量,并将其插入到地图中。最后,执行局部BA以优化点、线和关键帧的位姿。与此同时,如果可以获取惯性测量单元(IMU)的数据,会使用IMU预积分方法处理这些测量数据,并将其添加到初始位姿估计和局部捆绑调整中。
将基于学习的特征检测和匹配方法应用于立体VO是耗时的。因此,为了提高效率,在系统中使用了以下三种技术:
- 对于关键帧,在左右图像上提取特征并执行立体匹配以估计真实尺度。但对于非关键帧,仅处理左图像。此外使用了一些宽松的标准,使得系统中选取的关键帧非常稀疏,因此系统中特征检测和匹配的运行时间和资源消耗接近于单目系统。
- 将CNN和GNN的推理代码从Python转换为C++,并使用ONNX和NVIDIA TensorRT进行部署,其中16位浮点运算替代了32位浮点运算。
- 设计了一个多线程管道。采用生产者-消费者模型,将系统分为前端线程和后端线程两大部分。前端线程负责特征提取和匹配,而后端线程执行初始位姿估计、关键帧插入和局部捆绑调整。
特征匹配
使用LightGlue来匹配关键点。对于线特征,目前大多数VO和SLAM系统使用LBD算法或跟踪采样点来匹配它们。然而,LBD算法从线的局部带状区域提取描述符,因此在光照变化或视点变化的情况下,线特征检测不稳定。跟踪采样点可以匹配在两个帧中检测到不同长度的线,但目前SLAM系统通常使用光流跟踪采样点,这在光照条件快速或剧烈变化时表现较差。一些基于学习的线特征描述符也被提出,但由于时间复杂度的增加,它们很少在现有SLAM系统中使用。
因此,为了解决效率和效果问题,我们设计了一种快速且鲁棒的线特征匹配方法,以应对光照挑战条件。首先,我们通过距离将关键点与线段关联。假设在图像上检测到𝑀个关键点和𝑁个线段,每个关键点表示为 ,每个线段表示为,其中为线段的参数,而()为端点。首先通过以下公式计算与之间的距离:
如果 且在坐标轴上的投影在线段端点的投影范围内,即或,将认为属于。然后,可以基于这两张图像的点匹配结果匹配线段。对于图像𝑘上的线段和图像上的线段,计算一个得分𝑆𝑚𝑛来表示它们是同一线段的置信度:
其中是属于的点特征和属于的点特征之间的匹配数量。和分别是属于和的点特征数量。然后,如果且,我们将认为和是同一线段。这种耦合特征匹配方法使线段匹配能够共享关键点匹配的鲁棒性能,同时由于不需要另一个线段匹配网络,它具有很高的效率。
3D 特征处理
- 3D线段表示:我们使用Plücker坐标【71】来表示三维空间中的线段:
其中v是线段的方向向量,n是由线段和平面确定的法向量。Plücker坐标用于3D线段的三角测量、变换和投影。它是过参数化的,因为它是一个6维向量,而一个3D线段只有四个自由度。在图优化阶段,额外的自由度将增加计算成本并导致系统的数值不稳定。因此,还使用正交表示来表示3D线段:
Plücker坐标和正交表示之间的关系类似于SO(3)和so(3)。通过以下公式可以从Plücker坐标转换为正交表示:
其中Σ3×2是一个对角矩阵,其两个非零项可以通过SO(2)矩阵表示:
在实际操作中,可以通过QR分解简单快速地进行这种转换。
- 三角测量:三角测量是从两个或更多2D线特征初始化一个3D线段。使用两种方法对3D线段进行三角测量。第一种方法3D线段的姿态可以通过两个平面计算。为实现这一点,选择两条在两张图像上的线段l1和l2,它们是一个3D线段的两个观测。注意,这两张图像可以来自同一个关键帧的立体图像对,也可以来自两个不同的关键帧。l1和l2可以反投影并构建两个3D平面π1和π2。然后,3D线段可以视为π1和π2的交线。
然而,三角测量一个3D线段比三角测量一个3D点更困难,因为它更容易受到退化运动的影响。因此,如果上述方法失败,还采用第二种线段三角测量方法,利用点来计算3D线段。为了初始化3D线段,选择两个已三角测量的点X1和X2,它们属于该线段并且在图像平面上与该线段的距离最短。然后,可以通过以下公式获得该线段的Plücker坐标:
该方法只需很少的额外计算,因为所选择的3D点在点三角测量阶段已经被三角测量。它非常高效且鲁棒。
- 重投影:重投影用于计算重投影误差。我们使用Plücker坐标来进行3D线段的变换和重投影。首先,我们将3D线段从世界坐标系转换到相机坐标系:
其中和分别是相机坐标系和世界坐标系中的3D线段的Plücker坐标。是从世界坐标系到相机坐标系的旋转矩阵,是平移向量。表示向量的反对称矩阵,是从世界坐标系到相机坐标系的3D线段变换矩阵。
然后,可以通过线段投影矩阵将3D线段投影到图像平面:
其中 是图像平面上重投影的2D线段。表示向量的前三行。
关键帧选择
系统中使用的基于学习的数据关联方法能够跟踪具有大基线的两帧。因此,不同于其他VO或SLAM系统中使用的逐帧跟踪策略,只将当前帧与最后一个关键帧匹配。我们认为这种策略可以减少累积的跟踪误差。
因此,关键帧选择对系统至关重要。一方面,希望关键帧稀疏以减少计算资源的消耗。另一方面,关键帧越稀疏,发生跟踪失败的可能性就越大。为了平衡效率和跟踪的鲁棒性,如果满足以下任一条件,则选择该帧为关键帧:
- 跟踪到的特征数少于。
- 当前帧与最后一个关键帧之间的跟踪特征的平均视差大于。
- 跟踪到的特征数少于。
其中𝛼1, 𝛼2和𝑁𝑘𝑓均为预设阈值。𝑁𝑠是检测到的特征数。𝑊和𝐻分别表示输入图像的宽度和高度。
局部图优化
为了提高精度,在插入新关键帧时执行局部捆绑调整。选择最近的个相邻关键帧构建一个局部图,其中地图点、3D线段和关键帧作为顶点,位姿约束作为边。我们使用点约束和线约束,以及如果有IMU数据可用,还会使用IMU约束。相关的误差项定义如下:
- 点重投影误差:如果帧𝑖可以观察到3D地图点X𝑝,则重投影误差定义为:
其中, 是帧上的观测值,表示相机投影。
- 线重投影误差:如果帧𝑖可以观察到3D线段,则重投影误差定义为:
- IMU残差:我们首先按照【69】在帧𝑖和帧𝑗之间预积分IMU测量值:
IMU残差定义为:
成本函数定义为:
使用Levenberg-Marquardt优化器来最小化成本函数。如果点和线的残差过大,在优化过程中它们也会被拒绝为离群值。
初始地图
地图在离线阶段进行了优化。因此,当视觉里程计完成后,关键帧、地图点和3D线段将被保存到磁盘,以便后续优化使用。对于每个关键帧,保存其索引、位姿、关键点、关键点描述符、线特征和交点。2D特征与3D特征之间的对应关系也会被记录下来。为了加快地图的保存、加载和在不同设备之间的传输,以上信息以二进制形式存储,这也使得初始地图比原始数据要小得多。例如,在OIVIO数据集上,我们的初始地图大小仅约为原始数据大小的2%。
地图优化与重用
离线地图优化
这一部分旨在处理由我们的视觉里程计(VO)模块生成的初始地图,并输出可以用于无漂移重定位的优化地图。我们的离线地图优化模块包括以下几个地图处理插件。
- 回环检测:与大多数当前的vSLAM系统类似,使用粗到细的流程来检测回环。回环检测依赖于DBoW2来检索候选帧,并使用LightGlue进行特征匹配。在包含35,000张图像的数据库上为PLNet检测到的关键点训练了一个词汇。这些图像从几个大型数据集中选取,包括室内和室外场景。该词汇有4层,每层10个节点,因此包含10,000个词。
- 地图融合 :回环对观察到的3D特征通常被错误地当作两个不同的特征。因此,目标是融合由回环对观察到的重复点和线特征。对于关键点特征,使用上述回环对之间的特征匹配结果。如果两个匹配的关键点分别关联了两个不同的地图点,将它们视为重复特征,并且只保留一个地图点。2D关键点与3D地图点之间的对应关系以及共视图图中的连接也将更新。
对于线特征,首先通过2D-3D特征对应关系和2D点线关联来关联3D线段和地图点。然后,检测与同一地图点关联的3D线段对。如果两个3D线段共享超过3个关联的地图点,它们将被视为重复线段,并且只保留一个3D线段。 - 全局BA :在融合重复特征后执行全局捆绑调整(GBA)。其残差和成本函数类似,不同之处在于该模块中所有关键帧和特征都将被优化。在优化的初始阶段,由于VO漂移误差,融合特征的重投影误差相对较大,因此我们首先迭代50次而不剔除离群值,以便将变量优化到一个较好的初始位置,然后再进行另外40次带有离群值剔除的迭代。
我们发现当地图较大时,初始的50次迭代无法将变量优化到令人满意的位置。为了解决这一问题,如果地图包含超过80,000个地图点,将在全局BA之前首先执行位姿图优化(PGO)。在PGO中,仅调整关键帧的位姿,成本函数定义如下:
在线回环检测系统通常在检测到一个新的回环后执行全局捆绑调整,因此当一个场景中包含许多回环时,它们会经历多次重复的全局捆绑调整。相比之下,离线地图优化模块仅在检测到所有回环后才执行全局捆绑调整,这使得与这些系统相比,可以显著减少优化迭代次数。
- 场景依赖词汇:训练了一个用于重定位的交点词汇。该词汇建立在地图中的关键帧交点之上,因此具有场景依赖性。与关键点词汇相比,用于训练交点词汇的数据库通常要小得多,因此我们将层数设置为3,每层10个节点。这个交点词汇非常小,只有大约1MB,因为它只包含1,000个词。
- 优化地图:保存优化后的地图以供后续地图重用,保存了更多的信息,例如每个关键帧的词袋、全局共视图图以及场景依赖的交点词汇。同时,由于重复地图点和3D线段的融合,3D特征的数量有所减少。因此,优化后的地图占用的内存与初始地图相当。
地图重用
在大多数vSLAM系统中,识别已访问的地方通常需要两个步骤:
- 检索𝑁𝑘𝑐个与查询帧相似的关键帧候选
- 执行特征匹配并估计相对位姿。
第二步通常是耗时的,因此选择合适的𝑁𝑘𝑐非常重要。较大的𝑁𝑘𝑐会降低系统的效率,而较小的𝑁𝑘𝑐可能会使正确的候选无法被召回。例如,在ORB-SLAM3的回环关闭模块中,只使用DBoW2检索到的最相似的三个关键帧来提高效率。这在两帧之间时间间隔较短且光照条件相对相似的回环对中表现良好。然而,对于具有挑战性的任务,如日/夜重定位问题,检索如此少的候选通常会导致较低的召回率。然而,检索更多候选需要对每个查询帧进行更多次特征匹配和位姿估计,这使得在实时应用中很难实现。
为了解决这个问题,提出了一种高效的多阶段重定位方法,使优化地图可以在不同的光照条件下使用。我们的见解是,如果能够快速过滤掉大多数错误的候选,那么在保持或甚至提高重定位召回率的同时,也可以提高效率。因此,在上述两步流程中添加了另一个步骤。接下来,将详细介绍所提出的多阶段流程。
- 第一步:这一步是从地图中检索与查询帧相似的关键帧。对于每个输入的单目图像,使用PLNet检测关键点、交点和线特征。然后,执行一个"粗略候选选择"的流程,但有两个不同之处。第一个不同点是不使用共视图图过滤候选,因为查询帧不在图中。第二个不同点是保留所有候选用于下一步,而不仅仅是三个候选。
- 第二步:这一步使用交点和线特征过滤掉大多数在第一步中选定的候选。对于查询帧K𝑞和每个候选帧K𝑏,首先通过交点词汇过滤掉大多数候选。在前面的步骤中,已经检测了K𝑞的交点。接下来,使用DBoW2词袋将这些交点量化为单词,并通过计算直方图的𝜒2距离来选择与K𝑞相似的候选帧。如果𝜒2距离大于0.3 · 𝑆𝑚𝑎𝑥,K𝑏将被过滤掉。在剩余的候选中,如果K𝑞和K𝑏之间共享超过4条线特征,并且这些线特征的端点足够接近,它们将保留。否则,K𝑏将被过滤掉。这一步使得通过接下来耗时的特征匹配和位姿估计进行处理的候选数量大大减少。
- 第三步:这一步对第二步中剩余的候选执行特征匹配并估计位姿。首先通过LightGlue将K𝑞和K𝑏的关键点和交点进行匹配。然后,基于上述点匹配结果匹配线特征。最后,通过五点法估计初始相对位姿,并通过迭代最近点算法(ICP)优化它。
通过这种多阶段流程,我们能够提高重定位的召回率和精度,同时保持实时性能。开发板商城 天皓智联 TB上有视觉设备哦 支持AI相关~ 大模型相关也可用 whaosoft aiot自动驾驶也可以哦
实验效果
总结一下
AirSLAM系统是一种高效且光照鲁棒的点线视觉SLAM系统。设计了一个统一的CNN模型来同时检测点和线特征,并提出了一种基于点线特征的多阶段重定位方法。这些创新使得系统能够在短期和长期光照挑战中表现出色,同时保持足够的效率以部署在嵌入式平台上。最终将AirSLAM部署在实际机器人中,显示出其在各种真实场景下的广泛适用性。
#WHALES
支持多智能体调度的大规模协同感知数据集
自动驾驶技术在预防交通事故、提升交通效率与安全性方面展现出巨大潜力。然而,现有单车自动驾驶系统存在固有的感知局限性,特别是在处理非视距 (NLOS) 区域信息时,由于遮挡导致的感知盲区会带来潜在的安全风险。
为克服这一挑战,研究人员提出了协同式驾驶 (Cooperative Autonomous Driving) 方案,通过车辆间无线通信实现信息共享,显著增强了系统在复杂场景下的安全性。尽管协同式感知为自动驾驶提供了广阔前景,但现有研究仍受限于数据集智能体数量的不足,无法充分探索智能体调度这一关键任务,从而制约了协同感知的实际落地应用。
为弥合此研究鸿沟,作者团队正式发布 WHALES (Wireless enHanced Autonomous vehicles with Large number of Engaged agentS),首个专门设计用于评估通信感知智能体调度与可扩展协同感知的大规模车联网数据集 。数据集整合了详细的通信元数据,模拟真实场景中的通信瓶颈,为调度策略评估提供严格标准。为推动领域发展,作者团队提出覆盖范围自适应的历史调度算法 (Coverage-Aware Historical Scheduler, CAHS),这种新型调度基准通过基于历史视角覆盖度的智能选择机制,在感知性能上超越现有方法。WHALES成功弥合了仿真与真实车联网挑战之间的鸿沟,为探索感知-调度协同设计、跨数据泛化及扩展性极限提供了坚实框架。作者团队使用 MMDetection3D 实现了数据集,并提供了基线模型以及相应的性能指标。预处理流程集成了现有的智能体调度方法,使研究人员能够轻松地提出和评估新的调度策略。
- 论文标题:WHALES: A Multi-agent Scheduling Dataset for Enhanced Cooperation in Autonomous Driving
- 论文链接:https://arxiv.org/pdf/2411.13340
- 代码仓库:https://github.com/chensiweiTHU/WHALES
,时长02:05
WHALES:支持多智能体调度的大规模数据集

图1 WHALES数据集的总览。(a) 数据集中单帧的BEV视图。(b) 点云与边界框的可视化呈现。(c) 智能体在该帧中的前向相机图像。
核心特点与主要贡献
- 大规模多智能体协同环境 :WHALES支持V2V和V2I感知,通过优化CARLA模拟器的速度和计算成本 ,实现了平均每个驾驶场景有8.4个协同智能体 ,包含17k帧LiDAR点云, 70k张图像和2.01M个有效3D标注框的大规模模拟。该数据集包含了超过2.01M个3D标注框,以及物体索引和智能体行为信息,使其具有很强的可扩展性。
- 创新性引入多智能体调度任务 :WHALES支持3D目标检测 和智能体调度 等协同式驾驶任务。**WHALES 是第一个将调度问题纳入协同感知的数据集。**作者团队为这两个任务都提供了详细的基准,并分析了各种现有的单智能体和多智能体调度算法。
- 较低的时间成本 :平均而言,每增加一个智能体只需要160ms,有效地将时间成本降至线性函数,使得数据集生成的时间和计算成本可以接受。

表1 WHALES和现有自动驾驶数据集的比较
传感器和智能体配置
每个智能体都配备了传感器,包括一个64通道的LiDAR ,四个1920×1080的相机以及V2X通信设备。通过这种设置,它们可以执行感知和通信任务。
数据集中有四种类型的智能体:
- 非受控网联自动驾驶车辆:使用CARLA自动驾驶系统进行规划和控制。
- 受控网联自动驾驶车辆:可通过强化学习专家模型进行控制。
- **路侧单元 (RSU):**安装在路边,配备LiDAR和摄像头,并能进行感知和规划。
- 普通智能体:没有传感器,轨迹非受控。
通过这种设置,能够评估协同对自动驾驶安全性和其他基准的增强作用。
强化学习专家模型进行规控
轨迹真值对自动驾驶模型至关重要,但是基于规则的CARLA pilot过于保守,无法探索智能体行为的多样性。为了更好地生成轨迹,作者团队继承了Roach的强化学习环境,利用强化学习专家模型生成更高质量的轨迹。该强化学习模型以自身BEV的真实值作为输入,并输出控制信号(油门、刹车和转向)给车辆。然后,另一个深度学习模型通过模仿学习训练,以近似在理想观测条件下的真实车辆行为。为了在后续任务中进行扩展,本车的行为和奖励函数存储在标签中。
数据分析
自车周围的边界框分布在各种方向上,由于道路方向的限制,许多物体与自车方向平行或垂直对齐。大多数车辆彼此靠近,提供互补的视野,而一些车辆则相距较远,以提供长距离信息。WHALES的数据存储格式遵循nuScenes数据集,除了现有的nuScenes标签外,还包括了用于协同感知任务的新标签,例如智能体之间的距离和遮挡关系图。
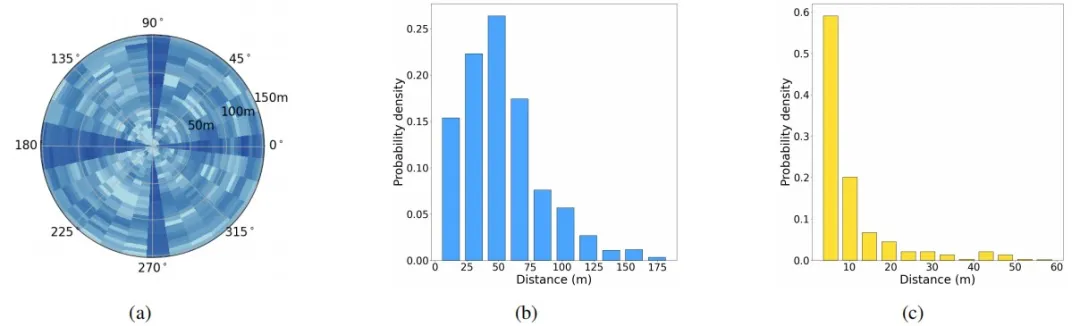
图2 (a) 在对数刻度的极坐标密度图中标注框的分布。受限于道路朝向,多数物体与本车方向平行或垂直。(b) 不同协同智能体之间的距离分布。大多智能体彼此靠近,提供互补视角,少数距离较远,以获取远程信息。(c) 物体的邻近性的量化。88%的物体位于本车的20米范围内,突显了密集城市环境中遮挡现象的频繁性。
WHALES支持的调度算法
WHALES支持的调度算法包括全通信 (Full Communication)、最临近调度 (Closest Agent)、随机调度 (Single/Multiple Random)、移动条件下协作车辆选择算法 (Mobility-Aware Sensor Scheduling, MASS) 以及作者团队提出的CAHS算法。CAHS调度算法 是一种新型调度方法,根据本车感知范围内的历史视角覆盖率对智能体进行优先级排序。通过握手机制,CAHS能够动态选择具有最大空间相关性的候选对象。
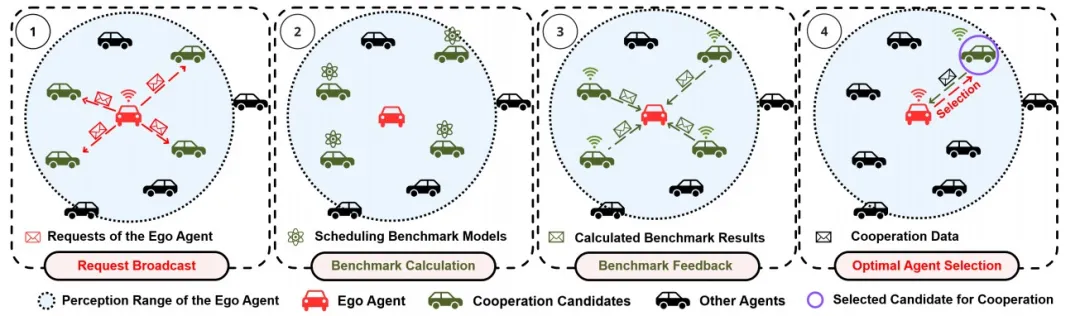
图3 智能体调度的四个阶段。(1) 本车将自身需求广播给所有候选智能体。(2) 候选智能体根据本车需求计算调度基准。(3) 候选智能体将结果反馈给本车。(4) 本车选择基准值最高的候选智能体进行协同。
- 全通信算法允许本车从所有其他智能体获取数据,这种理想化场景可视为感知性能的上限,而No Fusion则对应下限。
- 最临近调度算法采用更直接的方式,仅通过距离不依赖历史信息来选择最近智能体。
- 随机调度算法从环境中随机选取一个智能体作为通信对象。
- MASS算法通过结合车辆动态特性与Upper置信边界 (UCB) ,能够实现去中心化调度并最大化感知增益。
- **CAHS算法(本文提出)**会选择候选车辆中,在上一帧范围内为其本车提供最多边界框数量的车辆,该机制可通过握手协议实现。具体而言,对于候选智能体,定义其奖励定义为先前检测结果与本车过去感知范围相交的数量:
最后本车选择相交数量最多的智能体进行通信:
实验结果
作者团队在WHALES数据集上进行了三种类型的实验,所有模型都在8个NVIDIA GeForce RTX 3090 GPU上训练,对于每个任务以8:2的比例分为训练集和测试集。所有模型都训练了24个epoch,基础学习率为0.001。实验在50米和100米的检测范围内训练和测试。每次传输的数据量限制为每帧2MB。
- **独立 3D 目标检测 (Stand-alone 3D Object Detection):**使用Pointpillars、RegNet和SECOND等主流模型进行实验。结果表明,在100米的检测范围内,性能显著下降,这强调了协同在增强长距离感知方面的重要性。

表2 单车三维物体检测 (50m/100m)
- **协同 3D 目标检测 (Cooperative 3D Object Detection):**通过使用不同的融合方法(如原始数据级融合和特征级融合),协同模型在检测性能上显著优于单车独立模型。与基线相比,F-Cooper在50米和100米下mAP分别提高了19.5%和38.4%,而VoxelNeXt则分别提高了25.7%和81.3%。

表3 协同三维物体检测 (50m/100m)
- **智能体调度 (Agent Scheduling):**这是WHALES数据集引入的一项新任务。单智能体调度部分展示了当本车选择单一协同对象时各策略的性能表现,而多智能体调度部分则涉及在协同场景中协调两个及以上智能体的调度算法。
研究发现,Historical Best和MASS算法在单智能体调度中表现最好。同时,使用随机训练策略的模型比确定性训练策略的模型表现更好,因为它能生成更多样化的输入,从而在有限的训练周期内更好地泛化。
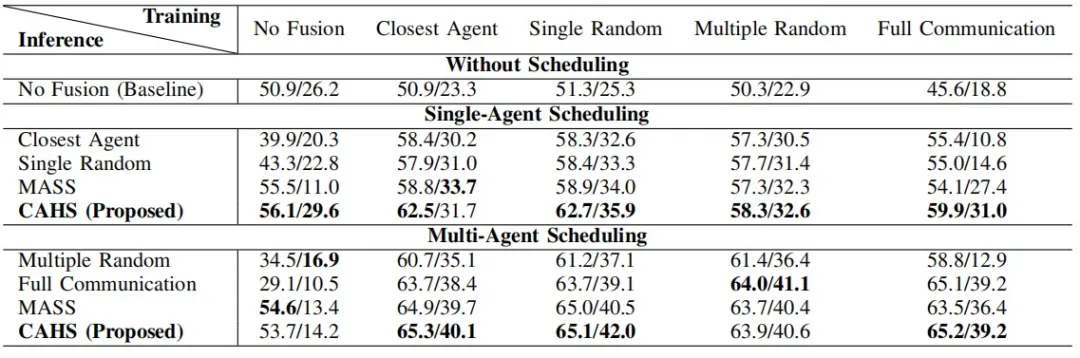
表4 使用不同调度算法的3D物体检测mAP评分 (50m/100m)
结论
作者团队提出了WHALES数据集,包含1.7万帧激光雷达数据、7万张RGB图像及总计201万个三维标注数据,旨在推动自动驾驶领域中协同式感知和调度研究的进展。通过深度学习模型同步智能体进程,显著提升了CARLA仿真系统的数据生成速度。作者团队还建立了三维目标检测与智能体调度的基准测试体系,充分展现数据集的优势。此外,WHALES还支持智能体行为的可控性,为智能体交互与控制策略研究提供可能。未来将基于该数据集构建模块化、端到端的自动驾驶系统,进一步拓展感知协同之外的协同应用,并评估协同带来的安全性能提升。
#CBDES MoE
能暴涨4%!MoE焕发BEV第二春,性能直接SOTA(清华&帝国理工)基于多传感器的BEV感知已经成为端到端自动驾驶的的核心,然而现有方法仍然面临输入适应性有限、建模能力受限以及泛化不佳等问题。针对这些挑战,清华大学、伦敦帝国理工学院和武汉理工的团队提出了CBDES MoE,一种在功能模块层面实现分层解耦的专家混合结构。也是首个在自动驾驶领域内以功能模块粒度构建的模块化专家混合框架。
CBDES MoE集成了多个结构异构的专家网络,并采用轻量级的自注意力路由器(Self-Attention Router, SAR)门控机制,从而实现动态专家路径选择以及稀疏、感知输入的高效推理。具体来说,是针对视觉backbone的MoE,集成四种backbone------Swin Transformer、ResNet、ConvNeXt和PVT,有点类似于模型集成,但通过MoE一次性解决。
最终的实验结果很不错,在nuScenes的3D目标检测任务上,相较于最强的单专家模型,mAP提升了1.6个百分点,NDS提升了4.1个百分点,验证了所提方法的有效性和实际优势。
和大模型中的MoE不同,由于是backbone层级的MoE,车端部署难度可能较大,但在云端模型中还是值得尝试的。未来可以进一步探索多任务、多模态的MoE,同时针对部署做一些专门的优化。
引言
随着自动驾驶技术的快速发展,三维感知已成为构建安全、智能和可靠驾驶系统的基础。在主流解决方案中,基于鸟瞰图的多模态融合框架(如BEVFusion)展现出巨大潜力,通过将来自相机和激光雷达(LiDAR)的原始传感器输入投影到统一的空间表示中,实现了高效的三维感知。这些结构化的BEV特征能够实现精确的三维目标检测,并支持一系列下游驾驶任务。尽管取得了成功,但大多数现有方法为每种模态采用固定的单backbone特征提取器。虽然这种设计简化了训练流程,但严重限制了模型对多样化和动态变化驾驶环境(如不同光照、天气和相机视角)的适应能力。此外,单backbone架构有限的建模能力削弱了其捕捉语义丰富且复杂的场景信息的能力,最终导致在领域迁移或任务转换时性能下降。
为应对这些挑战,先前的研究探索了自适应模块,例如动态卷积和可变形注意力。尽管这些技术提高了局部灵活性,但仍局限于刚性的单一网络结构。由于缺乏粗粒度的架构适应性,此类模型难以根据输入变化动态重新分配计算资源,从而阻碍了其在安全关键型自动驾驶系统中的大规模部署。专家混合(Mixture-of-Experts, MoE)范式提供了一种新的的解决方案。通过基于学习到的路由机制实现动态专家选择,MoE模型能够在计算效率和表示丰富性之间灵活平衡。尽管MoE在自然语言处理和视觉-语言任务中取得了显著成功,但其在基于BEV的三维感知中的潜力尚未得到充分挖掘。特别是,设计适用于多模态融合的异构专家backbone和路由策略,仍面临独特挑战,尚未得到充分解决。
在本研究中,我们提出了CBDES MoE,一种专为BEV感知任务设计的分层解耦专家混合架构。我们的方法引入了多样化的backbone专家池、轻量级门控路由网络和稀疏激活机制,以实现高效、自适应和可扩展的3D感知。在nuScenes基准上的综合实验表明,我们的方法在复杂和多样的驾驶场景下持续超越强大的单backbone基线模型。我们的主要贡献总结如下:
- CBDES MoE 引入了一种全新的基于专家的架构,包含一个多阶段异构backbone设计池。通过支持分层解耦和动态专家选择,该模型增强了场景适应性和特征表示能力。
- 开发了一种轻量级、分层的路由机制,集成了卷积操作、自注意力和多层感知机(MLP)。该模块实现了从输入到专家的端到端学习映射,支持稀疏激活和高效的动态推理。
- 在nuScenes数据集上进行了大量实验,结果表明CBDES MoE在多样且具有挑战性的环境条件下持续超越强大的单backbone基线模型。
相关工作回顾
多模态BEV感知
随着自动驾驶系统的发展,多传感器信息融合已成为提升感知精度与鲁棒性的关键技术。早期方法通常依赖于独立的流水线阶段或基于点云的融合方法(例如PointPillars、VoxelNet),但这些方法难以充分利用图像丰富的纹理与语义信息。近年来,由于其统一的空间投影特性,鸟瞰图(BEV)表示方法日益受到关注。BEVDet、BEVDepth、BEVFormer等方法通过将多视角相机图像投影到BEV空间,在三维目标检测和地图分割任务中展现出显著的性能提升。
进一步地,BEVFusion等研究提出了特征级多模态融合框架,通过在BEV空间内对齐并联合建模相机与激光雷达(LiDAR)信息。然而,这些方法通常采用固定的单主干架构(如ResNet、Swin Transformer),缺乏对多样化和动态变化输入条件的适应能力。
动态设计范式
自动驾驶场景具有高度的变异性------包括光照、天气、视角和道路布局------要求感知系统具备灵活且强大的建模能力。单一的固定架构在受控条件下表现可靠,但在领域迁移或任务转换时性能往往下降。
近期研究引入了动态卷积和可变形注意力机制,以实现基于输入特征的自适应参数调整,从而提升模型鲁棒性。然而,这些工作主要在单一架构内的细粒度模块层面进行操作,未能提供宏观层面的架构多样性或动态路径调度能力。在自动驾驶感知研究中,仍迫切需要一种机制,既能实现结构多样性与动态选择,又能保持推理效率。
MoE架构
Jacobs等人最初提出的专家混合(MoE)架构,通过基于输入依赖的门控机制实现动态专家选择,从而在增强表示能力的同时控制计算成本。在自然语言处理(NLP)领域,GShard和Switch Transformers等模型已证明,稀疏激活的专家结构可以在不带来沉重推理开销的情况下线性扩展模型容量。最近,DeepSeekMoE进一步推动了这一边界,通过专家稀疏性和优化路由,将MoE模型扩展至超过千亿参数,同时保持高效性。在视觉领域,Vision MoE通过引入专家模块,在分类和检测等任务中表现出色。
然而,系统性地将MoE集成到自动驾驶的多模态BEV感知中仍处于探索阶段。挑战包括设计合适的专家组合、高效的门控机制,以及在BEV投影空间中保持跨模态一致性。
自动驾驶中的MoE研究
在自动驾驶领域,已有先驱性工作开始将MoE引入端到端任务学习。例如,ARTEMIS将MoE引入轨迹规划,利用动态路由解决在模糊引导条件下的性能退化问题,实现了跨场景的鲁棒规划。DriveMoE则提出了一种基于视觉的MoE用于感知,以及一种基于行为的MoE用于决策,实现了多视角处理的解耦和多样化驾驶技能,并在Bench2Drive基准上取得了最先进的结果。
这些工作证实了MoE能够增强端到端规划和决策模块的多样性与适应性。然而,上述研究主要聚焦于端到端的规划和决策层。目前,尚缺乏在多模态BEV感知系统中实现分层、解耦的动态专家选择的系统性解决方案。
CBDES MoE算法详解
在本节中,我们介绍了所提出的CBDES MoE的架构与设计细节,这是一种专为自动驾驶中多模态BEV感知任务设计的新型多专家模型。CBDES MoE模块被设计为一种即插即用的主干网络,通过利用架构多样性与输入自适应路由机制来增强特征表示能力。
我们的设计通过引入异构专家组合、输入依赖的动态路由以及BEV空间中的特征级聚合,有效解决了单主干融合网络的局限性。
整体框架
CBDES MoE模块集成于类似BEVFusion的框架中,其中多视角相机图像被投影到BEV空间,并与激光雷达(LiDAR)/雷达模态融合,以执行三维目标检测和地图分割等3D感知任务。我们将传统的静态图像主干替换为一个异构的专家混合(Mixture-of-Experts)模块,用于在BEV投影前提取图像特征。每个专家独立处理输入图像,然后利用相机到BEV的视图变换层将特征投影至BEV空间。所有后续操作,如模态融合和任务头,均与BEVFusion等标准流水线保持兼容。
如图1所示,CBDES MoE由四个结构各异的专家网络、一个轻量级可学习的路由模块以及一个专家输出的软特征融合机制组成。每个组件的设计均以效率、多样性与输入适应性为核心,使模型能够在不同视觉条件和任务需求下选择性地激活专家路径。
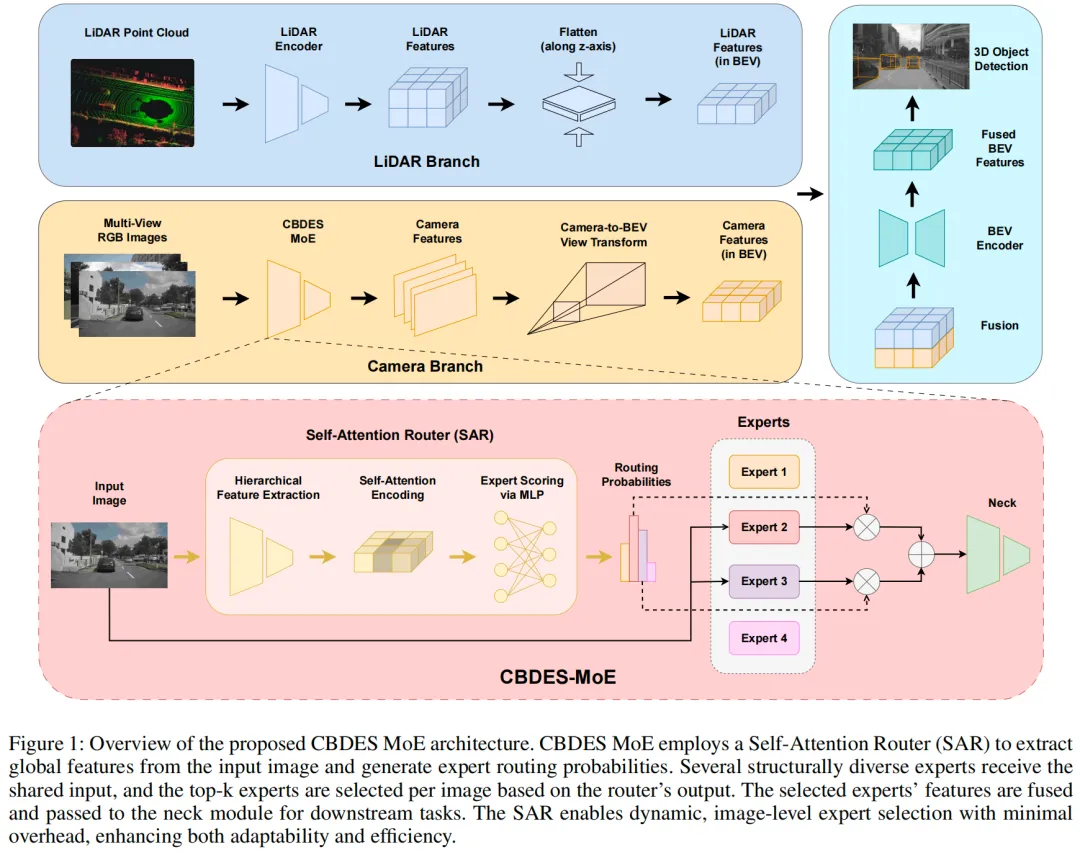
异构专家集设计
CBDES MoE的一项主要创新在于专家主干网络之间的显式架构异构性。与使用相同架构的专家不同,我们设计了一个由四种不同的视觉主干组成的专家池,每种主干代表深度视觉表示学习中的不同范式:
- Swin Transformer:一种采用基于窗口的自注意力与移位窗口机制的分层Transformer,特别擅长捕捉大视野场景中的全局空间结构。
- ResNet:一种使用残差连接的经典卷积主干。尽管结构简单,但其为局部结构编码和边缘检测提供了强大的归纳偏置,尤其在光照不足或纹理缺失的条件下表现优异。
- ConvNeXt:一种受Transformer启发但保持全卷积设计的现代化卷积网络架构,在局部性与可扩展性之间取得平衡,以较少的手工先验提供强大的表示能力。
- yramid Vision Transformer(PVT):一种专为密集预测任务设计的分层Transformer,通过引入空间缩减注意力机制,在全局上下文建模与计算成本之间实现平衡,适用于多尺度目标建模。
通过集成四种结构差异显著的专家主干,模型能够受益于多样化的归纳偏置与表示能力。这些专家不仅在架构上不同,其感受野特性、参数化模式和计算开销也各不相同。这种异构性对于建模真实世界自动驾驶场景中巨大的变异性至关重要(例如城市与乡村、白天与夜晚、晴朗与雾天)。每个专家在捕捉特定图像模式方面表现出色,从而使系统对动态多变的道路场景更具鲁棒性。
自注意力路由器SAR
为动态地为每张输入图像分配最合适的专家,我们提出了一种自注意力路由器(SAR),该路由器结合了卷积特征提取、轻量级自注意力机制和MLP分类器。
SAR接收一个特征图 作为输入,其中 为批量大小, 为输入通道数, 为空间分辨率。该模块随后经历三个主要阶段:分层特征提取、自注意力编码和通过MLP进行专家评分。
分层特征提取。我们首先使用一系列卷积和池化层逐步降低空间分辨率,同时增加通道维度:
其中 为注意力嵌入维度(例如128)。每个ConvModule包含一个卷积层,后接批归一化(Batch Normalization)和PReLU激活函数。池化操作采用步长为2的最大池化。
自注意力编码。上一阶段的结果 被重塑为一个token序列:
为建模空间token之间的全局交互,我们应用一个多头自注意力(MHA)层:
该操作使路由器能够整合空间依赖关系,并学习更丰富的全局场景上下文表示。
随后,将输出序列 在token维度上取平均,生成图像级嵌入:
通过MLP进行专家评分。将上一阶段的全局描述符 输入一个包含PReLU激活的三层MLP,以生成专家logits:
其中 为专家数量。最后,路由器应用softmax函数得到路由概率:
每一行 表示对 个可用专家的图像级软分配。
这种图像级路由机制使模型能够根据输入语义调整其计算路径。例如,雨天场景可能被路由至以Transformer为主的专家,而纹理丰富的城市场景则可能受益于卷积网络。这种适应性提升了模型对域偏移以及罕见或复杂场景的鲁棒性,解决了静态模型的常见缺陷。
路由器本身结构轻量,仅包含少量卷积层、一个单层多头自注意力机制和一个紧凑的MLP。尽管结构简单,它仍能有效汇总全局场景级信息并生成语义上有意义的路由分数。它使系统能够为每张输入图像动态地为每个专家分配不同的权重。这种路由灵活性使模型能够自动为不同类型的场景、光照条件或空间布局专门化每个专家,而无需人工干预。
专家特征提取
每个专家接收图像作为输入,并生成各自的处理后特征:
其中 表示第 个专家网络。
值得注意的是,所有专家输出均保持相同的空间分辨率和通道维度(必要时通过适配器层实现),以确保在融合过程中的兼容性。架构差异导致每个专家在不同的视觉模式上实现专业化------某些专家可能在检测长距离车辆方面表现出色,而其他专家可能更擅长分割道路边界。
软加权特征融合
在获得路由分数和专家输出后,我们使用路由图在专家间进行加权软融合。最终的融合特征图 计算如下:
该机制实现了专家间的平滑过渡,避免了硬路由带来的不稳定性,同时由于训练过程中softmax的锐化作用,仍能保持稀疏的激活模式。
基于稀疏专家激活的高效推理
在推理阶段,我们根据路由器的输出仅激活每个图像的top-1专家。这种稀疏专家激活策略相比评估所有专家,极大地降低了计算成本,同时由于路由器的判别能力,仍能保持具有竞争力的精度。
形式上,对于批量大小为 的输入,仅需 次专家主干的前向传播,而非 次( 为专家数量)。这使得计算成本随批量大小线性扩展,使系统在边缘硬件上具备实时应用的可行性。
负载均衡正则化
MoE模型的一个常见问题是专家坍塌(expert collapse),即路由器持续选择专家子集,导致其他专家利用率不足。这种不平衡不仅浪费模型容量,还削弱了专家多样性的优势。为解决此问题,我们引入了一个负载均衡正则化项,以鼓励在整个数据集上均匀使用所有专家。
设 为路由概率矩阵,其中 为样本数(如批次中的图像数), 为专家数量。每一行 表示第 个样本分配给 个专家的软路由概率,满足 。
专家的平均激活定义为:
每个专家的总路由负载为:
则负载均衡损失定义为:
该公式惩罚了专家使用频率()与累积负载()之间的联合偏差。当所有专家在批次中被均匀分配时,该损失达到最小值,从而促进所有专家的公平参与。
该正则化项被集成到整体训练目标中:
其中 是控制任务性能与路由多样性之间权衡的超参数。实践中,较小的 (如0.01)足以促进负载均衡,而不会干扰任务收敛。
该负载均衡正则化确保了所有专家在训练期间均被激活,从而实现更丰富的专业化,并避免专家利用不足。
与BEVFusion的集成
融合后的特征图 被传递至BEVFusion中标准的camera-to-BEV投影。该模块利用相机内参和外参矩阵将2D特征反投影到一个共享的BEV网格中。生成的BEV特征随后与其他模态(如LiDAR、雷达)融合,并传递至特定任务的head,以实现3D目标检测、语义分割或实例分割。
由于我们设计的即插即用特性,CBDES MoE可以无缝集成到各种基于BEV的感知框架中,而无需修改投影逻辑或下游头网络。
训练策略
我们使用与标准BEVFusion流水线相同的损失函数(如检测的focal loss)对CBDES MoE进行端到端训练,并额外加入专家负载均衡损失以均衡专家使用并促进专业化。
自注意力路由器与模型其余部分联合训练。在训练期间,我们使用软门控(即所有专家输出的加权和)以确保可微性。在推理时,我们切换为每张图像激活top-1专家,以降低计算开销。除非另有说明,所有结果均在此推理模式下报告。
我们采用混合精度训练以减少训练时间和GPU内存消耗。所有专家联合优化,路由参数通过标准反向传播进行训练。
实验结果
为评估所提出的CBDES MoE框架的有效性,我们进行了全面的实验,重点研究自动驾驶场景中的三维目标检测任务。目标是评估动态异构专家选择带来的性能提升以及负载均衡正则化带来的益处。我们将CBDES MoE与多个强单专家基线模型进行比较,并进行消融研究以分离每个组件的贡献。
实验设置
我们将CBDES MoE集成到官方的BEVFusion代码库中进行性能评估。四个专家------Swin Transformer、ResNet、ConvNeXt和PVT------均在ImageNet-1K上进行了预训练,并被适配以匹配BEVFusion相机分支的输入-输出接口。
实验在nuScenes上展开,具体的评测、计算资源和超参数可以参考原文。
与单专家模型的比较
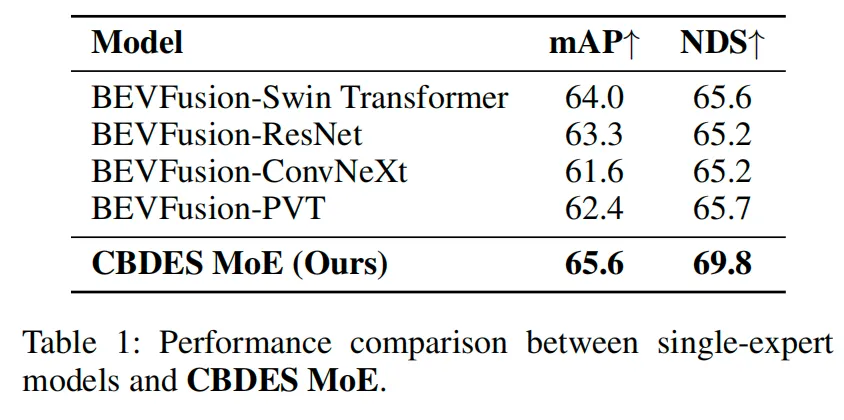
为评估专家多样性和动态路由的贡献,我们将CBDES MoE与四个基线模型进行比较,每个基线使用单一的专家主干:Swin Transformer、ResNet、ConvNeXt和PVT。所有模型共享相同的BEV融合、检测头和训练配置,以确保公平比较。单专家变体省略了MoE结构和路由机制。
如表1所示,CBDES MoE在mAP和NDS上均持续优于所有四个单专家基线。这验证了专家多样性和自适应路由机制在提升三维检测性能方面的有效性。
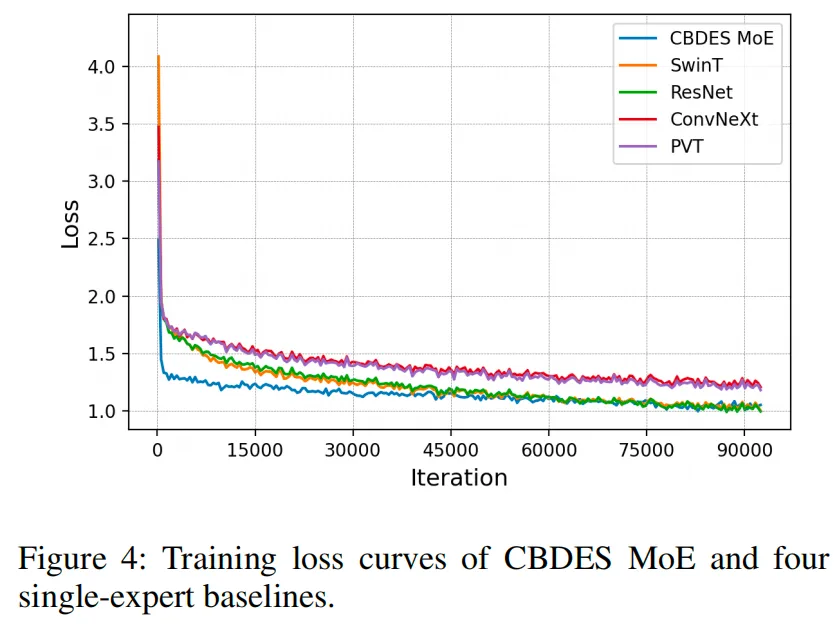
除了精度指标外,我们还在图4中比较了训练过程。CBDES MoE表现出更快的收敛速度,并在整个训练过程中保持更低的损失,表明其优化稳定性更高,学习效率更优。
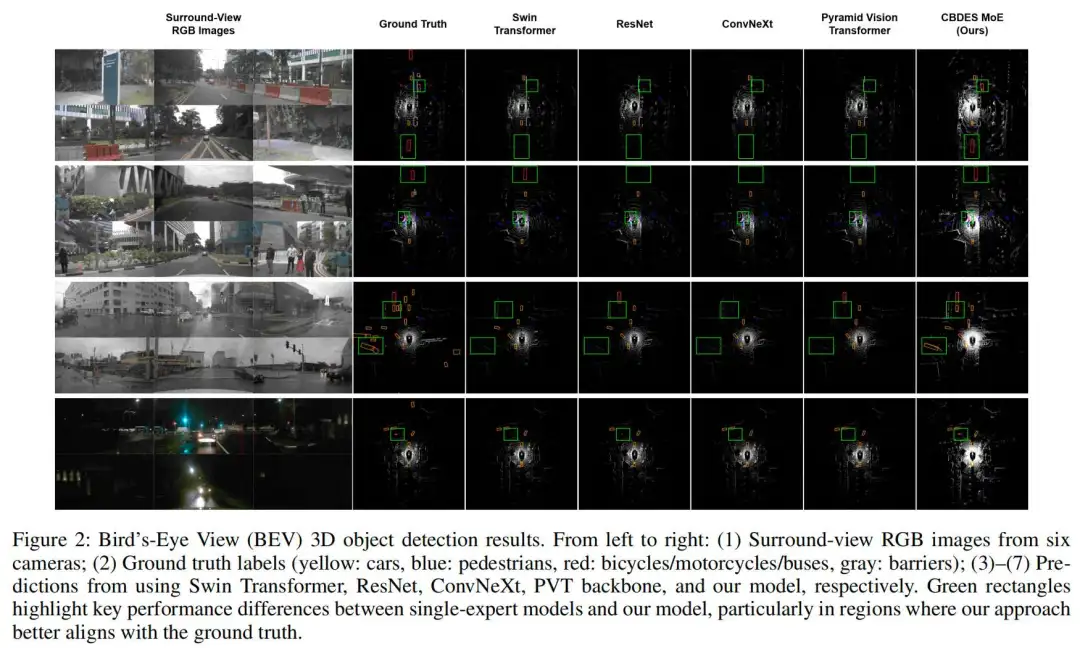
为进一步说明这些定量提升,图2展示了在四种不同环境条件下代表性场景的BEV 3D目标检测结果的定性比较。前两行描绘了能见度良好的正常白天场景,而第三和第四行展示了更具挑战性的条件:第三行包含雨雾,第四行为夜间拍摄。在所有场景中,CBDES MoE产生的结果与GT更为接近,尤其是在绿色框标出的区域。
在晴朗的白天场景中,CBDES MoE相比单专家模型表现出更强的一致性和更少的漏检。在恶劣条件下------例如因雾导致能见度低或夜间光照有限------我们的模型通过在基线模型出现误检或完全无法定位目标时仍能保持稳健的检测而优于基线。这些结果凸显了动态专家路由的优势:通过为每个输入选择最合适的专家,CBDES MoE能够更好地适应环境变化,并在多样化的真实世界条件下展现出卓越的泛化能力。
负载均衡正则化的影响
我们进一步分析了负载均衡正则化对检测性能的影响。比较了CBDES MoE的两个变体:一个在训练中加入了负载均衡损失,另一个没有。
如表2所示,使用负载均衡正则化的CBDES MoE在mAP和NDS上均显著优于未使用该正则化的版本。

为更好地理解负载均衡损失对专家利用率的影响,我们在图3中可视化了路由器的行为。两个热图分别展示了在有和没有负载均衡正则化项的情况下,分配给每个专家的软路由概率。
在没有负载均衡损失(图3b)的情况下,路由概率严重偏向一个主导专家,导致严重的专家不平衡和其余专家的利用不足。相比之下,当应用负载均衡损失(图3a)时,路由概率在所有四个专家之间分布得更加均匀,最终的选择表现出更大的多样性。这证实了正则化项促使路由器探索完整的专家空间,并防止陷入退化的路由模式。
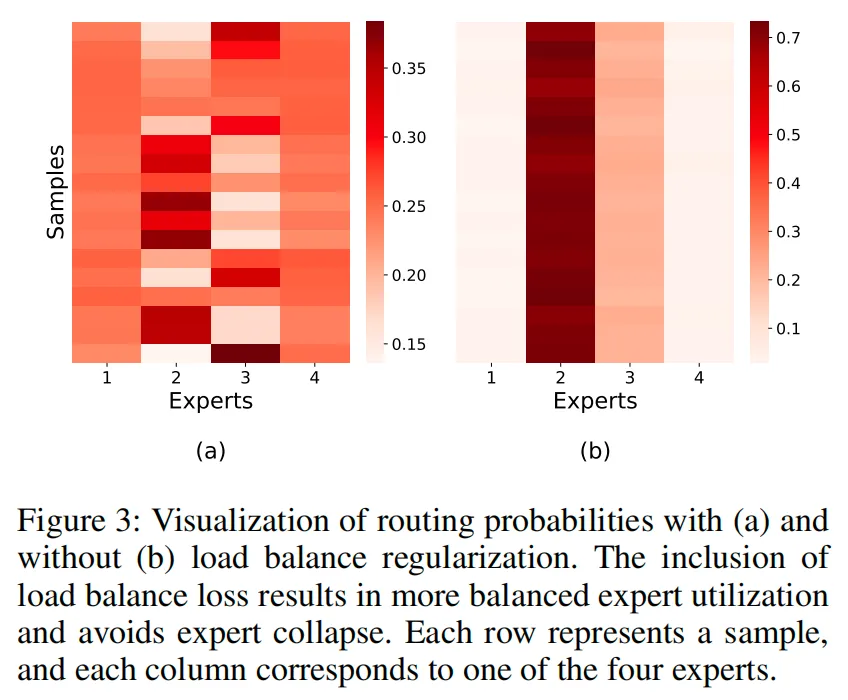
改进的专家多样性直接促成了更好的性能,如表2所示,在专家使用均衡的情况下,mAP和NDS均更高。这些结果凸显了在基于MoE的感知系统中引入负载均衡以充分利用其建模能力的必要性。
结论
本文提出了CBDES MoE,一种专为自动驾驶功能模块设计的新型分层解耦MoE框架。通过集成四种结构异构的专家主干------Swin Transformer、ResNet、ConvNeXt和PVT,并引入轻量级的自注意力路由器(SAR)实现图像级的动态专家选择,我们的模型能够为每个输入自适应地激活最合适的专家。此外,我们还引入了负载均衡正则化项,以防止专家坍塌并确保训练稳定。在nuScenes数据集上的实验结果表明,CBDES MoE在mAP和NDS指标上持续优于单专家基线,验证了所提框架的有效性。
局限性与未来工作 :尽管CBDES MoE性能强劲,但仍存在一些局限性。目前,专家路由仅在图像级别进行;未来的工作可以探索基于图像块(patch-wise)或区域感知(region-aware)的路由,以实现更细粒度的适应。未来可以将方法扩展到多任务(例如分割和跟踪)或引入来自激光雷达的跨模态路由信号,可进一步增强泛化能力。我们还计划研究自动化的专家架构搜索和面向硬件的模型压缩,以优化模型的可扩展性和部署效率。
致谢
本工作得到了国家重点研发计划项目"自动驾驶数据闭环大模型技术与场景库构建"(项目编号:2024YFB2505501)和广西重点科技项目"高性能低成本城市试点驾驶技术研究与产业化"(项目编号:桂科AA24206054)的支持。
#LMAD
复旦最新:迈向可解释端到端VLM~
概述
随着自动驾驶技术的快速发展,场景理解与行为可解释性成为核心研究方向。大型视觉语言模型(VLMs)在连接视觉与语言信息、解释驾驶行为方面展现出潜力,但现有方法多通过微调VLMs处理车载多视图图像和场景推理文本,存在整体场景识别不足、空间感知薄弱等问题,难以应对复杂驾驶场景。
为此,本文提出LMAD框架一种专为自动驾驶设计的视觉语言框架。其借鉴现代端到端驾驶范式,通过引入初步场景交互(Preliminary Interaction,PI)机制和任务专用专家适配器,增强VLMs与自动驾驶场景的对齐性,同时兼容现有VLMs并无缝集成规划导向的驾驶系统。在DriveLM和nuScenes-QA数据集上的实验表明,LMAD显著提升了现有VLMs在驾驶推理任务中的性能,树立了可解释自动驾驶的新标准。
核心挑战与创新
现有方法的局限性
现有基于VLMs的自动驾驶方法存在两点关键缺陷:
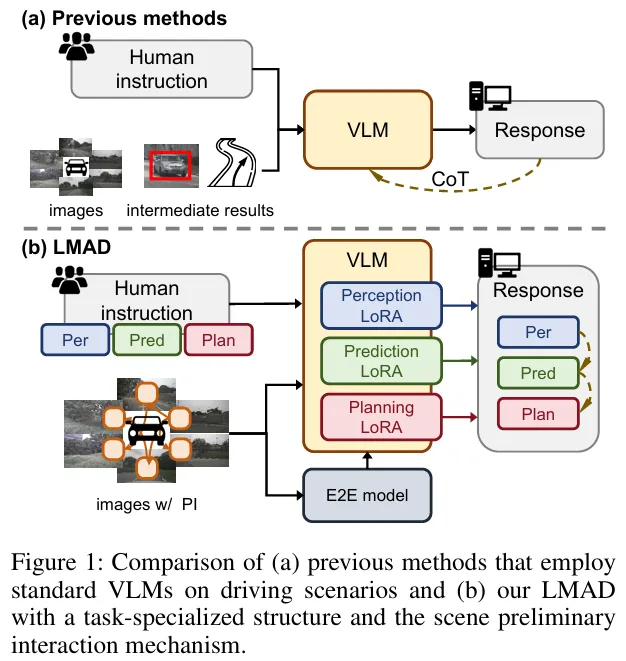
- 场景理解碎片化:依赖驾驶系统的中间结果或简单视觉表征,难以捕捉交通元素间的关系,无法形成整体场景认知(figure 1a)。
- 空间与运动感知薄弱:在定位和运动估计上表现不足,推理过程中易积累误差,导致驾驶任务性能不佳。
LMAD的创新设计
针对上述问题,LMAD的核心创新包括:
- 初步场景交互(PI)机制:建模交通参与者的初步关系,降低VLMs的学习复杂度。
- 任务专用专家结构:通过并行LoRA(P-LoRA)模块,使VLMs专注于感知、预测、规划等特定任务,获取任务专属知识。
- 端到端系统集成:融合端到端驾驶系统的先验知识,补充VLMs的空间和运动信息,增强推理能力(figure 1b)。
方法细节
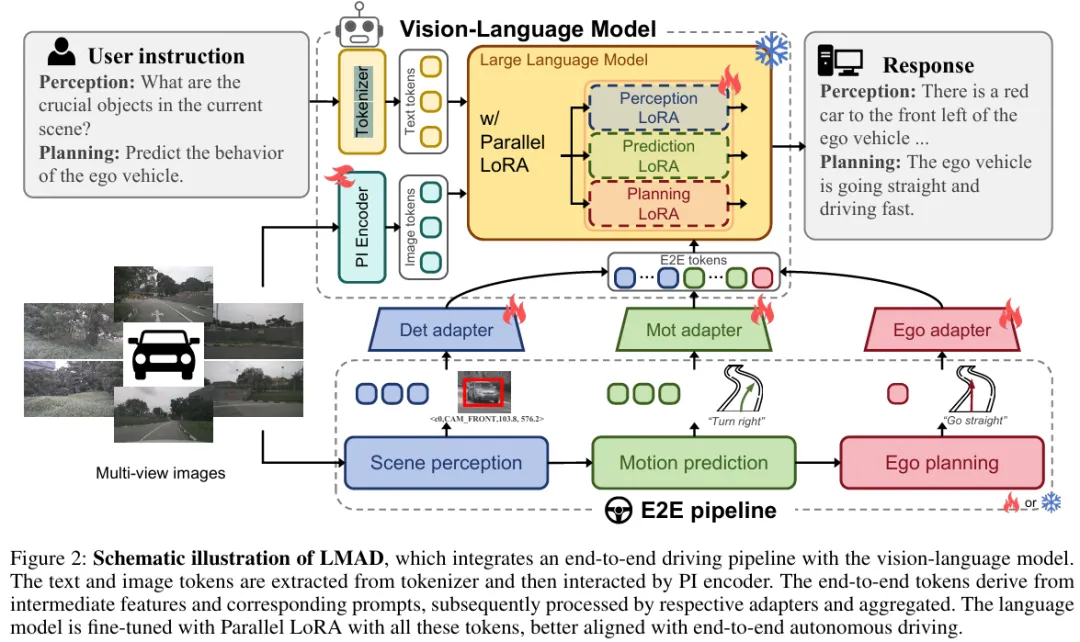
整体框架
LMAD整合端到端驾驶流水线与视觉语言模型,由三部分构成:
- 视觉语言模型:含视觉编码器(提取图像tokens)、分词器(编码文本tokens)、语言解码器(生成响应)。
- PI编码器:处理多视图图像,建模场景关系。
- 并行LoRA模块:整合任务专用知识,适配不同驾驶任务(figure 2)。
关键模块设计
- 初步场景交互(PI)编码器
多视图图像独立处理易产生冗余跨视图tokens,增加空间关系学习负担。PI编码器通过解耦查询和交替注意力机制解决这一问题(figure 3a):
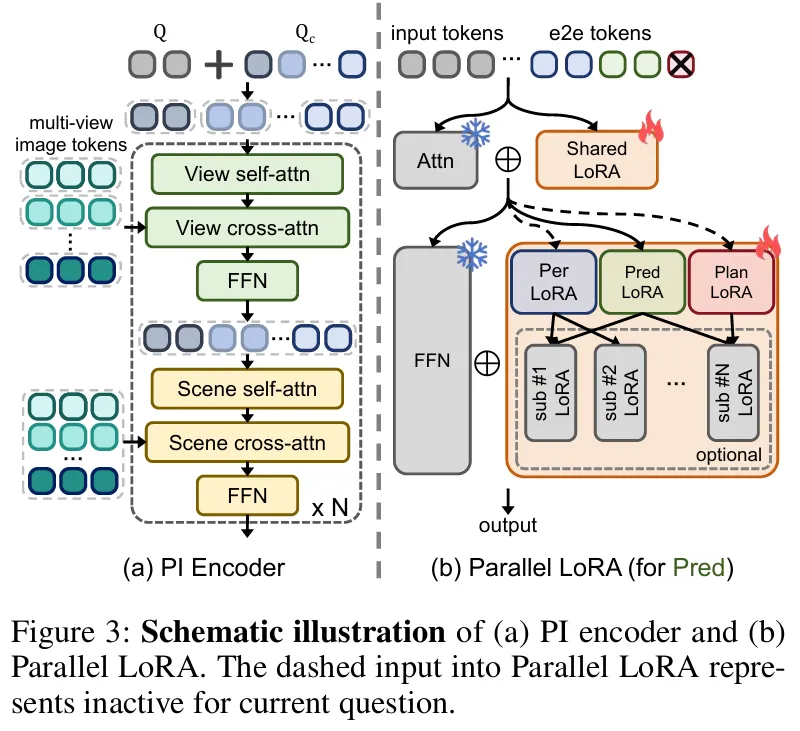
- 解耦查询:包含个通用视觉查询(捕捉图像上下文)和个相机查询(标识相机视角,辅助空间关系构建)。
- 交替注意力:奇数块中,查询按相机分组,仅组内及与对应图像特征交互,保留单视图信息;偶数块中,所有查询联合进行场景级自注意力和交叉注意力,整合多视图信息。
- 并行LoRA(P-LoRA)微调
为使VLMs适配多样化驾驶任务,P-LoRA在FFN块中替换传统LoRA为多个并行分支,每个分支对应感知、预测或规划任务(figure 3b):
- 注意力块中的LoRA保持共享,保留通用驾驶知识。
- 推理时结合Chain-of-Thought(CoT)技术,按端到端方法逐步输出结果。
与端到端驾驶系统的集成
端到端驾驶系统的感知、预测、规划特征可为VLMs提供丰富的位置和运动先验,具体集成方式如下:
-
特征提取:收集感知()、预测()、规划()的输出特征,结合数值和文本提示增强可理解性。
其中表示或,为语言模型输入嵌入编码的原始文本特征,为用于聚合文本信息的可学习查询。
- 数值提示:通过MLP将预测轨迹和 ego 规划轨迹投影为高维特征和。
- 文本提示:基于转向和速度变化生成描述(如"直行,加速"),经多头注意力(MHA)生成文本特征和。 公式表示为:
-
特征整合:通过适配器处理三类特征并对齐语言上下文,拼接为端到端tokens :
其中为语言模型特征维度,(为选定目标数量)。
训练策略
- 单分支微调:冻结端到端驾驶分支,仅微调语言分支,采用自回归交叉熵损失。
- 联合训练:激活语言分支到端到端分支的梯度流,同时优化文本生成和端到端任务,损失函数为:
其中为平衡因子,包含检测、运动预测和规划损失(按端到端模型默认权重聚合)。
实验验证实验设置
- 数据集:采用DriveLM(377,956个QA对,涵盖感知到规划的渐进式任务)和nuScenes-QA(约460k个QA对,聚焦感知任务)。
- 基线模型:LLaMA-Adapter、LLaVA-1.5、InternVL2,端到端框架采用VAD-base。
- 训练细节:使用AdamW优化器(权重衰减0.01),余弦学习率调度(预热比0.03),8张A6000 GPU上以 batch size 16训练2个epoch。
主要结果
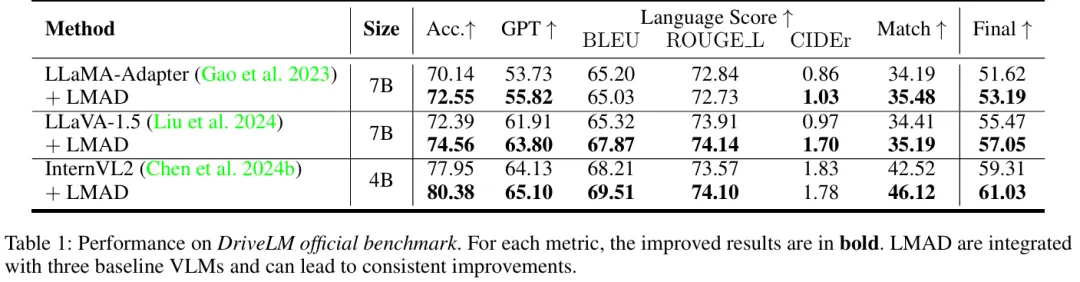
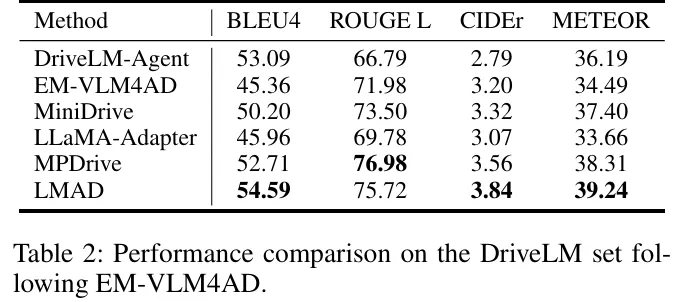
- DriveLM基准测试:LMAD显著提升所有基线VLMs的性能。例如,LLaMA-Adapter的准确率提升3.44%,GPT得分提升3.89%;即使是强基线InternVL2,整体指标仍有改善(table 1)。与现有方法相比,LMAD在BLEU4、ROUGE L等指标上表现最优(table 2)。
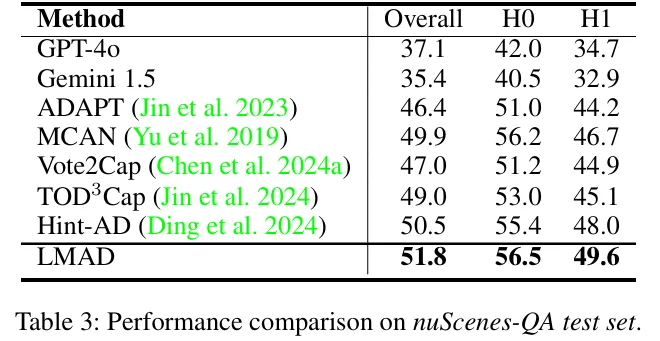
- nuScenes-QA测试:在相同基线(LLaMA-Adapter)下,LMAD的整体准确率提升2.57%,H0(零跳推理)和H1(单跳推理)指标分别提升1.99%和3.75%(table 3)。
消融研究
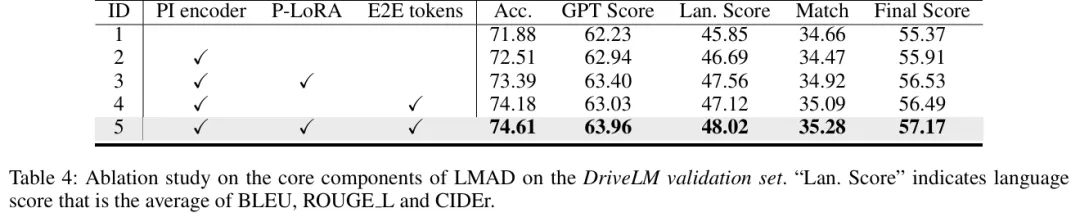
- 组件有效性:PI编码器、P-LoRA和端到端tokens的协同作用显著提升性能,全组件配置(ID5)的最终得分最高(57.17)(table 4)。
- P-LoRA设计:任务导向的P-LoRA(感知、预测、规划分支)在各项指标上表现均衡,优于问题导向和分层模式(table 5)。
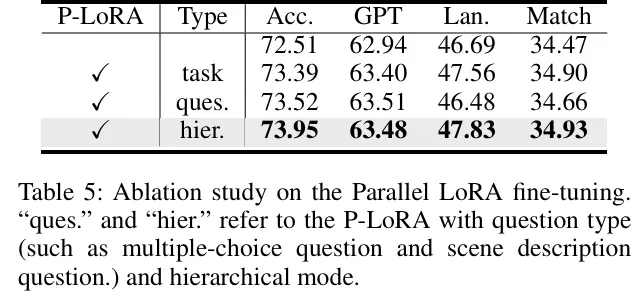
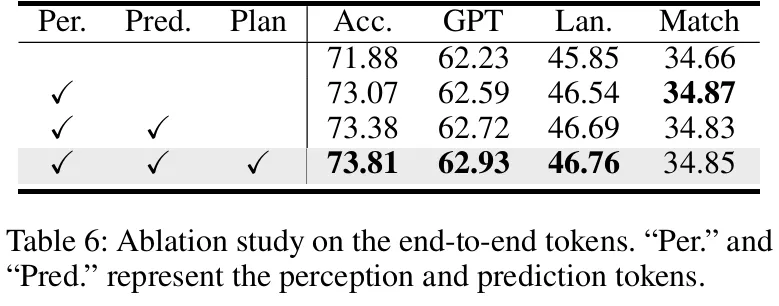
- 端到端tokens作用:感知tokens对行为解释最关键,加入预测和规划tokens后,准确性和交互关系建模进一步提升(table 6)。
定性分析
- 感知任务:借助规划结果中的位置先验,LMAD能准确识别多数关键目标,但对"禁止进入"等不明显标识仍有困难。
- 预测任务:聚焦对ego行为影响大的目标(如交通标志),即使预测目标与真值不同,仍能合理影响后续规划。
- 规划任务:结合历史上下文和端到端结果,输出符合当前环境的驾驶行为(figure 4)。

参考
1LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving
#VisionTrap
VLM+LLM教会模型利用视觉特征更好实现轨迹预测VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions开源数据集
https://moonseokha.github.io/VisionTrapmoonseokha.github.io/VisionTrap
摘要
预测其他道路代理的未来轨迹是自动驾驶汽车的一项重要任务。已建立的轨迹预测方法主要使用检测和跟踪系统生成的代理轨迹和HD地图作为输入。
在这项工作中,我们提出了一种新方法,该方法还结合了来自环视摄像头的视觉输入,使模型能够利用视觉线索,如人类的凝视和手势、道路状况、车辆转向信号等,这些线索在现有方法中通常对模型隐藏。此外,我们使用视觉语言模型(VLM)生成并由大型语言模型(LLM)细化的文本描述作为训练期间的监督,以指导模型从输入数据中学习特征。尽管使用了这些额外的输入,但我们的方法实现了53毫秒的延迟,使其可用于实时处理,这比之前具有类似性能的单代理预测方法快得多。
我们的实验表明,视觉输入和文本描述都有助于提高轨迹预测性能,我们的定性分析突出了模型如何利用这些额外的输入。最后,在这项工作中,我们创建并发布了nuScenes文本数据集,该数据集为每个场景添加了丰富的文本注释,从而增强了已建立的nuScenes数据集,展示了利用VLM对轨迹预测的积极影响
问题
目前的轨迹预测方法依赖于检测跟踪系统的输出以及 HD 地图,传统方法中模型利用视觉线索,如人类的凝视和手势、道路状况、车辆转向信号等,这些线索在现有方法中并没有很好利用
方法
本文在传统轨迹预测方法的输入基础上引入了环视摄像头的视觉输入,使用视觉语言模型(VLM)生成并由大型语言模型(LLM)细化的文本描述作为训练期间的监督,以指导模型从输入数据中学习什么
Introduction
传统轨迹预测的输入的缺陷------信息不足
传统轨迹预测方法中只使用检测跟踪结果+HD地图,其存在以下缺点
- HD高清地图是静态的,只能提供预先定义好的信息,限制了他们对于变化环境的适应性,如施工区域以及天气条件。同时HD地图不能提供理解agent行为的视觉数据
传统的轨迹预测中输入只有HD地图和agent的历史轨迹,这些信息是不足的;周围环境中agent的转向灯、行人的朝向、天气情况等信息都是丢失的;而且HD地图成本很高且是静态的,假设场景中存在施工区域,这都是无法在HD地图中体现的。
而视觉图像中包含了周围环境中绝大多数信息,将图像引入轨迹预测中辅助预测自然可以提高轨迹预测的精度。这一点之前的很多工作也都进行了考虑,并提出了自己的方法。
以往引入视觉的轨迹预测方法的不足------图像处理方式不好 & 仅使用正面图像
有些工作使用了视觉信息,但同时也存在以下问题
- 现有的利用视觉语义信息的的轨迹预测方法中要么使用agent所在区域的图像,要么整个图像 ,同时没有显式的指示要提取什么信息。导致这些方法只能关注于最显式的特征,导致了次优;
- 此外这些方法只使用正面图像,导致充分认识周围的驾驶环境变得具有挑战性。
针对上面提到的两个问题,本文提出了自己的解决方案。首先肯定要引入图像信息参与到轨迹预测中,第一个问题得到了解决;
其次,第二个问题的本质就在于如何更好地利用图像信息,从图像中提取出有效地信息进行轨迹预测。第二个问题实际上是由于图像中的信息是稠密的,模型不知道提取哪些有用的信息
本文针对第二个问题,对每个图像进行文本描述,将每个视觉特征同文本描述对齐,利用文本引导Text-driven作为监督,让模型能够更好地利用丰富的视觉语义信息。
在这个过程中,本文顺势提出了nuScenee-Text数据集,包含了nuScenes数据集中每个场景中每个agent的文本描述的数据集。在创建该数据集的过程中,使用了VLM和LLM进行标注
文章中此处描述
"Automating this annotation process, we utilize both a Vision-Language Model (VLM) and a Large-Language Model (LLM)" (Moon 等, 2024, p. 3)
上述描述中提到,为了自动化标注过程,使用VLM。按照此描述,VLM实际上没有参与到训练和推理过程,只是在数据集的标注过程中应用了VLM
Related work
本文在描述相关工作时并没有介绍到近期一些将LLM同轨迹预测结合起来的工作,有些不足
Method
接下来介绍本文提出方法的具体做法。本文提出的模型中包含四个重要部分,Per-agent State Encoder,Visual Semantic Encoder, Text-driven Guidance Module, Trajectory Decoder
下图为模型的主要结构图
下面详细介绍agent的状态编码器
提取agent时间特征和agent之间的空间交互特征------Per-agent State Encoder
状态编码器的结构如下所示
场景中的agent中的坐标均在自车坐标系(以自车位置及方向为坐标轴)下,使用相对位移,agent i的特征通过以下表达式获得
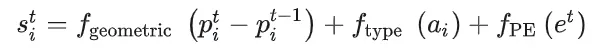
是可学习位置嵌入,用于学习并利用到时间信息的顺序
- 时间维度自注意力+时间维度可学习token编码时间信息

- 空间维度自注意力------建模agent之间的空间交互
为了让得到的每个agent的特征中具有spatially aware,将时间特征同位置特征相加,如下所示
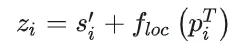
其中是agent i在自车坐标系下的坐标,并没有使用相对坐标来计算
通过上式得到各个agent的特征,然后在作为query,同当前agent周围的其他agent的特征进行cross attn
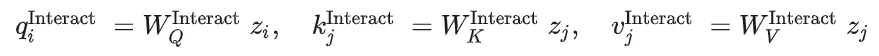
每个agent的状态编码器中使用了常见了空间和时间维度的注意力操作来提取特征,值得一提的是此处在时间维度自注意力操作之后,对最新时间的位置进行编码后叠加到特征上,此处的思想依旧是在What-if一文中说到的"残差连接"的思想。
基于Bev特征和初步预测轨迹,利用Deformable attn实现Scene-Agent交互------Visual Semantic Encoder
视觉语义编码器的主要结构如下
视觉语义编码器的作用就是提取自车周围环境的图像特征。
- bev特征的获取------BevDepth+rasterized BEV map

接下来的问题是,如何将代表环境信息的bev特征同上一步得到的agent特征结合,从而让每个agent的特征能够包含环境信息。本文利用deformable attn机制来实现此目标
- 初步轨迹的获取------Recurrent Trajectory Prediction
agent状态编码器得到的agent特征,通过Recurrent Trajectory Prediciton后得到初步的agent未来轨迹,该未来轨迹用于后续步骤中scene-agent的交互建模中,作为deformable attn的参考点
★
备注:此处Recurrent Trajectory Prediciton具体做法笔者尚不清楚,论文中阐述道,此处的解码器结构同Section 3.4中描述的解码器结构相同"utilizes the same architecture as the main trajectory decoder(explained in Sec. 3.4)" (Moon 等, 2024, p. 7)
- deformable attn机制实现scene-agent交互
将agent的未来初步轨迹作为deformable attn的参考点,将agent特征同reference point + offset处的bev特征进行交互,将环境信息注入此特征中,计算公式如下
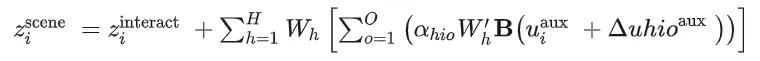
★
笔者注:这种方式降低的计算的复杂度,只需要关注初步未来轨迹附近一定范围内的bev 特征,避免了同全局bev特征之间进行注意力计算,是一种可取的思想。同时,笔者也注意到一些工作着力于此处,见后文中的联系一节中
通过多模态对比学习让agent的state embedding关注更加细节的语义细节------Text-driven Guidance Module
通过前文的描述可知,本文希望通过文本描述使模型能够更好地提取来自图像中的特征 ,从而提高轨迹预测的精度。现在的问题是如何利用文本描述来增强特征学习?
下图为此部分结构图
本文利用多模态对比学习,文本描述编码得到的特征 和通过时空间注意力得到的agent特征嵌入并不在一个特征空间中,因此使用对比学习。对比学习的理解可见以下链接
https://blog.csdn.net/qq_42018521/article/details/128867539
https://blog.csdn.net/jcfszxc/article/details/135381129
对于来自于同一个agent的文本特征和编码特征 ,此两个特征的组合称之为正对。我们希望正对中两个特征的相似度高,追求的训练目标是正对中的特征相似度高。这就相当于通过文本特征引导(guide) 编码特征 捕获到更加丰富的视觉语义特征以区别不同的agent行为。
同时我们还希望负对之间的特征相似度低,负对就是不同agent之间的文本特征和编码特征组成的特征对,例如agent i 的文本特征和agent j 的编码特征,即可称之为负对。追求负对相似度低的原因在于,希望模型能够学习到不同agent特有的视觉语义特征,区分不同的situation。
论文中提到,为了能够在一个batch中稳定优化,因此需要限制每个batch中负对的数量。
那么此时引发一个新问题,如何确定需要考虑的负对特征?/如何找到最需要被"关注"的负对?
此外,由于文本的描述是多样的,因此各个agent的文本特征也是多样的,这也给如何确定负对带来了困难。
本文的具体做法,通过BERT对agent的文本描述进行编码,得到word-level的embedding,然后在word-level embedding之间进行注意力操作,得到sentence-level embedding,然后求解此embedding之间的cosine相似度,筛选出小于阈值()<的嵌入,其中代表阈值,本文取0.8。
按照升序进行排序,从前往后依次得到相似度逐渐递增的嵌入列表。选择前k个相似度最低的嵌入{}代表的agent,取出这些agent的编码特征,组成负对
此部分的训练目标------正对足够接近,负对足够远离
将agent 的状态嵌入 和对应的文本描述嵌入 作为正对,agent 的状态嵌入和 top-k 的其他agent的嵌入 作为负对,使用 InfoNCE 损失来指导agent的状态嵌入和文本描述。
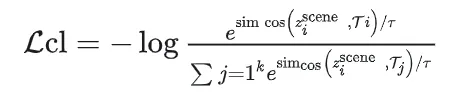
下图为具体的对比学习过程
由上图可以看到,每张图片中的agent都对应一个句子描述,首先使用BERT对sentence中的word进行编码,即上图中的Text Encoder,得到word-level的embedding,然后使用attention,得到上图中灰黑色方框的sentence-level的embedding。计算各个sentence-level embedding之间的cos相似度,由相似度确定负对。
★
笔者注:笔者先前也未了解对比学习,如有概念或理解上有偏差,请务必指出
此外,值得注意的是,此对比学习过程只会在训练的时候存在 ,该模块的作用就是为了让视觉语义特征编码器能够关注到更多有用的细节 ,故在推理阶段时,该对比学习过程是不存在的。
考虑旋转不变性的GMM参数学习网络------Trajectory Decoder
- 为什么需要Transformation Module?
根据HiVT等众多研究发现,场景元素之间的平移和旋转不变性对于轨迹预测网络的性能非常重要。
由于本文使用的是过去历史轨迹的相对位移,平移不变性得到了保证。但由于本文中agent坐标都是在自车坐标系下的,旋转不变性并没有得到保证。
在以往的工作HiVT中,平移不变形和旋转不变性是直接通过数据预处理实现的 ,在将数据输入进神经网络之前,处理原始历史轨迹时,转换为相对位移 ,以及按照各个local region的中心agent的坐标系进行旋转,从输入数据上保证了平移不变性和旋转不变性。
但现在输入的数据都是自车坐标系下的,自车的环视摄像头以及自车周围其他agent的位置及方向
★
笔者注:理论上,此处其他agent的坐标完全可以表示为各自坐标系下的形式,类似于Hivt中的做法。笔者推测,由于本文使用自车上的环视摄像头图像,为了和图像特征对齐,就只能使用自车坐标系下的其他agent的坐标和方向。
既然没办法从输入数据入手解决旋转不变性,那就只能让模型学习到隐含在数据中的旋转不变性。因此本文提出了一个Transformation模块,该模块就是为了降低与学习旋转不变性的复杂度。
★
笔者注:端到端自动驾驶的轨迹预测中的对称性是一个需要解决的问题,目前尚未看到较好的解决方案。受制于感知环节中的特征都是基于自车坐标系下的,轨迹预测无法很好地利用对称性。本文虽然提出用学习的方式学习旋转不变性缓解此问题,但是在端到端的过程中,agent的旋转方向该如何获得呢?只能通过接head输出吗?
- 基于前馈神经网络 和门控单元的Transformation Module
通过简单的前馈神经网络将此agent的方向信息编码为特征,通过Gate单元将信息注入前述步骤中得到的agent特征中,希望模型能够学习到旋转不变性。
★
笔者注:遗憾的是后文实验中并没有单独对此模块进行消融实验,尚不知此模块的真实效果如何
注入了agent方向信息的特征一方面输入至解码器中产生未来轨迹;另一方面输入至Text-driven Guidance Module中进行对比学习
- 将未来轨迹点分布建模为高斯混合模型------Trajectory Decoder

本文的解码器优化一个GMM,概率密度函数如下
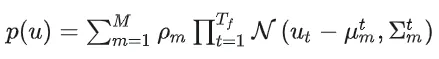

损失函数
损失函数为负对数似然概率
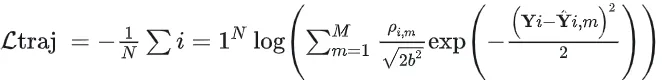
笔者注:形式上确实同GMM的负对数似然概率计算公式差不多,但是细节上对不上啊 。原文中提到b为scale parameter,应该指的是标准差。**系数的分母中的为何没有?指数系数分母中的为何没有?**下面是一个一维GMM的负对数似然概率公式。
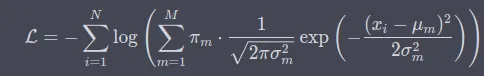
同时还优化一个辅助损失,该损失也是类似于上式中的负对数似然概率,是基于Recurrent Trajectory Prediction模块预测的初步轨迹计算的负对数似然概率,表示为。此外,损失中还包含对比学习的损失infoNCE。
最终损失的计算公式如下
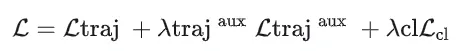
利用Fine-tuned VLM和LLM refine生成轨迹预测文本数据集------nuScenes-Text Dataset
- DRAMA数据集不适用于预测任务------该数据集对每个场景中只有一个agent的描述,不符合预测任务
DRAMA数据集中只提供了不充分的文本描述,针对每个场景中每个agent只有一个单独的标题。这种文本描述适合检测任务,但是不适合预测任务
- 基于DRAMA对VLM进行fine-tuned+GPT细化文本描述
最初,论文采用预训练之后的VLM产生每个图片中的文本描述,但是发现效果不佳;后使用DRAMA数据集对VLM进行微调;将感兴趣agent的边界框区域同原始图像concat。然后利用微调之后的VLM为场景中每个agent单独生成一个标题caption
但是生成的描述通常缺乏正确的动作相关的细节,以及提供很多不必要信息。为了解决此问题,本文采用GPT细化VLM产生的文本
将产生的文本,agent类型以及机动作为输入,其中agent的机动是通过规则的方式判断的;使用提示词来纠正不合理的描述,希望经过GPT产生的文本能够提供预测相关的信息,包括agent类型,动作以及逻辑依据。下图为产生nuScenes-Text数据集的流程。
★
笔者注:本文是通过规则的方式判断agent的机动类型,规则算法的具体描述详见本文后的补充材料中Fig3
- nuScenes-Text数据集中样例分析及分析
本文在此处展示了该数据集中典型场景下的文本描述,以及分析数据集,用于说明本文提出的数据集的优势
下图展示了agent的行为随时间变化时,文本描述的变化
下图展示了生成的文本描述的多样性以及LLM对文本的细化
实验
下图展示了本文提出的轨迹预测方法在不同场景下的表现
上图展示了视觉语义编码器+文本驱动模块对轨迹预测的帮助
★
笔者注:遗憾的是没有展示视觉语义编码器和文本驱动模块单独分别生效时的可视化表现,但后文的消融实验中包含了两者的消融实验结果
下面列举本文对上述实验结果的一些定性分析
- 视觉信息对轨迹预测有帮助;通过视觉信息输入,(a)图中由于红灯和相互交谈的行人未来的轨迹被预测为保持静止
- 行人的注视和身体朝向可以帮助预测行人穿越人行横道时的意图;
- 视觉信息可以提高现有预测的精度;(d)图中所示
- 视觉信息可以利用转向灯的信息;如(e)图所示
下表为实验指标的量化结果
上表中可以发现视觉语义编码器和文本引导模块对于轨迹预测的精度提升是巨大的,两者对于结果的提升都是在20%以上,尤其是文本引导模块。
此外,本文还在整个nuScenes数据集上进行了测试,验证所提出的各个组件的有效性
为了验证视觉信息引入和文本描述引导模块的作用,本文使用UMAP可视化了每个agent的状态嵌入,可视结果如下所示。可视结果证明了视觉信息和文本语义信息的引入改变了每个agent的状态嵌入。
当使用视觉和文本语义时,从UMAP图上可以看到agent状态嵌入之间的聚合程度得到了提升。在相同cluster中的agent具有相似的文本描述。
★
笔者注:text-driven模块的作用之一就在于让处于类似情况的agent状态嵌入聚合在一起?
补充 下图为用于判断未来机动类型的规则算法
下图为LLM提示词样例
总结
本文提出的方法的关键创新点在于,利用文本描述"引导"模型学习图像语义特征,提高轨迹预测精度。本文的主要内容主要为以下几个方面:
- 图像信息对于轨迹预测很重要;利用BEV编码器提取bev特征,通过scene-agent交互向agent嵌入中注入来自图像特征的信息。
- 基于多模态对比学习,利用文本描述"引导"轨迹预测模型更好地利用图像信息,提高轨迹预测精度
- 基于fine-tuned的VLM和LLM创建适用于本文所提方法的text-nuScenes数据集
联系
近期涌现了很多将LLM同自动驾驶或轨迹预测相结合的工作
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving------Arxiv 2023
Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models------IEEE TIV 2024
iMotion-LLM: Motion Prediction Instruction Tuning------Arxiv 2024
.
#VLM还是VLA?
从现有工作看自动驾驶多模态大模型的发展趋势~
基于LLM的方法
基于LLM的方法主要是利用大模型的推理能力描述自动驾驶,输入自动驾驶和大模型结合的早期阶段,但仍然值得学习~
Distilling Multi-modal Large Language Models for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2501.09757
- 会议名称:arXiv
LearningFlow: Automated Policy Learning Workflow for Urban Driving with Large Language Models
- 论文链接:https://arxiv.org/pdf/2501.05057
- 会议名称:arXiv
CoT-Drive: Efficient Motion Forecasting for Autonomous Driving with LLMs and Chain-of-Thought Prompting
- 论文链接:https://arxiv.org/2503.07234
- 会议名称:arXiv
PADriver: Towards Personalized Autonomous Driving
- 论文链接:https://arxiv.org/pdf/2505.05240
- 会议名称:arXiv
Towards Human-Centric Autonomous Driving: AFast-Slow Architecture Integrating Large LanguageModel Guidance with Reinforcement Learning
- 论文链接:https://arxiv.org/pdf/2505.06875
- 项目主页:https://drive.google.com/drive/folders/1K0WgRw1SdJL-JufvJNaTO1ES5SOuSj6p
- 会议名称:arXiv
Driving with Regulation: Interpretable Decision-Making for Autonomous Vehicles with Retrieval-Augmented Reasoning via LLM
- 论文链接:https://arxiv.org/abs/2410.04759
- 会议名称:arXiv
Empowering autonomous driving with large language models: A safety perspective
- 论文链接:https://arxiv.org/abs/2312.00812
- 会议名称:ICLR 2024
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models
- 论文链接:https://arxiv.org/pdf/2307.07162.pdf
- 代码:https://github.com/PJLab-ADG/DriveLikeAHuman
- 会议名称:arXiv
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
- 论文链接:https://arxiv.org/abs/2310.01957
- 代码:https://github.com/wayveai/Driving-with-LLMs
- 会议名称:LCRA 2024
A Language Agent for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2311.10813
- 项目主页:https://usc-gvl.github.io/Agent-Driver/
- 会议名称:arXiv
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2310.03026
- 项目主页:https://sites.google.com/view/llm-mpc
- 会议名称:arXiv
Receive, Reason, and React: Drive as You Say with Large Language Models in Autonomous Vehicles
- 论文链接:https://arxiv.org/2310.08034v1
- 会议名称:MITS 2024
Dilu: A knowledge-driven approach to autonomous driving with large language models
- 论文链接:https://arxiv.org/abs/2309.16292
- 项目主页:https://pjlab-adg.github.io/DiLu/
- 代码:https://github.com/PJLab-ADG/DiLu
- 会议名称:LCLR 2024
DSDrive: Distilling Large Language Model for Lightweight End-to-End Autonomous Driving with Unified Reasoning and Planning
- 论文链接:https://arxiv.org/pdf/2505.05360
- 会议名称:arXiv
TeLL-Drive: Enhancing Autonomous Driving with Teacher LLM-Guided Deep Reinforcement Learning
- 论文链接:https://arxiv.org/abs/2502.01387
- 项目主页:https://perfectxu88.github.io/TeLL-Drive.github.io/
- 会议名称:arXiv
基于VLM的方法
基于VLM和VLA的算法是当前的主流范式,因为视觉是自动驾驶依赖最多的传感器,在这个部分我们汇总了当前最新的工作供大家参考和学习~
Drive-R1: Bridging Reasoning and Planning in VLMs for Autonomous Driving with Reinforcement Learning
- 论文链接:https://arxiv.org/abs/2506.18234
- 会议名称:arXiv
FutureSightDrive: Visualizing Trajectory Planning with Spatio-Temporal CoT for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.17685
- 代码:https://github.com/MIV-XJTU/FSDrive
- 会议名称:arXiv
Generative Planning with 3D-vision Language Pre-training for End-to-End Autonomous Driving
- 论文链接:https://arxiv.org/abs/2501.08861
- 会议名称:arXiv
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
- 论文链接:https://arxiv.org/abs/2503.19755
- 代码:https://github.com/xiaomi-mlab/Orion
- 会议名称:arXiv
Training-Free Open-Ended Object Detection and Segmentation via Attention as Prompts
- 论文链接:https://arxiv.org/abs/2410.05963
- 会议名称:NeurIPS 2024
LingoQA: Visual Question Answering for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2312.14115
- 代码:https://github.com/wayveai/LingoQA/
- 会议名称:ECCV 2024
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
- 论文链接:https://arxiv.org/abs/2402.12289
- 项目主页:https://tsinghua-mars-lab.github.io/DriveVLM/
- 会议名称:arXiv
Continuously Learning, Adapting, and Improving: A Dual-Process Approach to Autonomous Driving
- 论文链接:https://arxiv.org/abs/2405.15324
- 代码:https://github.com/PJLab-ADG/LeapAD
- 会议名称:NeurIPS 2024
ADAPT: Action-aware Driving Caption Transformer
- 论文链接:https://arxiv.org/abs/2302.00673
- 代码:https://github.com/jxbbb/ADAPT
- 会议名称:ICRA 2023
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
- 论文链接:https://arxiv.org/abs/2310.01412
- 项目主页:https://tonyxuqaq.github.io/projects/DriveGPT4/
- 会议名称:RAL 2024
LightEMMA: Lightweight End-to-End Multimodal Model for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.00284
- 代码:https://github.com/michigan-traffic-lab/LightEMMA
- 会议名称:arXiv
TS-VLM: Text-Guided SoftSort Pooling for Vision-Language Models in Multi-View Driving Reasoning
- 论文链接:https://arxiv.org/abs/2505.12670
- 会议名称:arXiv
VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
- 论文链接:https://arxiv.org/pdf/2412.14446
- 会议名称:arXiv
OpenEMMA: Open-Source Multimodal Model for End-to-End Autonomous Driving
- 论文链接:https://arxiv.org/pdf/2412.15208
- 代码:https://github.com/taco-group/OpenEMMA
- 会议名称:WACV 2025
CALMM-Drive: Confidence-Aware Autonomous Driving with Large Multi modal Model
- 论文链接:https://arxiv.org/pdf/2412.04209
- 会议名称:arXiv
WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model
- 论文链接:https://arxiv.org/2412.09951
- 项目主页:https://wyddmw.github.io/WiseAD_demo/
- 代码:https://github.com/wyddmw/WiseAD
- 会议名称:arXiv
VLM-Assisted Continual learning for Visual Question Answering in Self-Driving
- 论文链接:https://arxiv.org/2502.00843
- 会议名称:arXiv
VLM-E2E: Enhancing End-to-End Autonomous Driving with Multi modal Driver Attention Fusion
- 论文链接:https://arxiv.org/2502.18042
- 会议名称:arXiv
VLM-MPC: Vision Language Foundation Model (VLM)-Guided Model Predictive Controller (MPC) for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2408.04821
- 会议名称:ICML 2025
Sce2DriveX: A Generalized MLLM Framework for Scene-to-Drive Learning
- 论文链接:https://arxiv.org/2502.14917
- 会议名称:arXiv
AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
- 论文链接:https://arxiv.org/pdf/2503.07608
- 代码:https://github.com/hustvl/AlphaDrive
- 会议名称:arXiv
X-Driver: Explainable Autonomous Driving with Vision-Language Models
- 论文链接:https://arxiv.org/pdf/2505.05098
- 会议名称:arXiv
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
- 论文链接:https://arxiv.org/pdf/2505.08725
- 代码:https://arxiv.org/pdf/2505.08725
- 会议名称:arXiv
LightEMMA: Lightweight End-to-End Multimodal Model for Autonomous Driving
- 论文链接:https://arxiv.org/pdf/2505.00284
- 代码:https://github.com/michigan-traffic-lab/LightEMMA
- 会议名称:arXiv
基于VLA的方法
AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
- 论文链接:https://arxiv.org/abs/2506.13757
- 项目主页:https://autovla.github.io/
- 代码:https://github.com/ucla-mobility/AutoVLA
- 会议名称:arXiv
DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.19381
- 会议名称:arXiv
Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models
- 论文链接:https://arxiv.org/abs/2505.23757
- 项目主页:http://impromptu-vla.c7w.tech/
- 代码:https://github.com/ahydchh/Impromptu-VLA
- 会议名称:arXiv
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.16278
- 项目主页:https://thinklab-sjtu.github.io/DriveMoE/
- 会议名称:arXiv
OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
- 论文链接:https://arxiv.org/pdf/2503.23463
- 代码:https://github.com/DriveVLA/OpenDriveVLA
- 会议名称:arXiv
#理想VLA到底是不是真的VLA?
以下为原文:写一点 #理想mindvla让每个人都有专职司机# 到底是不是 真的VLA❓
或者更加收敛一点:
是不是机器人领域 基于一个大语言模型LLM作为主干网络,串行的神经网络实现:多模态信息整合编码【包含但不限于视觉、激光雷达、语言、地图、定位】后,基于大语言模型整合后输出决策并将决策转换成轨迹后再转换成控制细节❓
这类狭义的VLA
根据目前短暂本地体验,并对比了和E2E+VLM的差异
我认为是狭义的VLA
这里用几个场景差异来作证这个观点【如果觉得不对,那就是我错了~】
①:VLA后具备了非常好【比较少漏报或者虚惊】情况下的防御性驾驶,即在无遮挡的十字路口会开的比较快且稳健;在有遮挡的、视野不佳的路口会出现明显的基于可行驶剩余距离丝滑减速的防御性驾驶。
而过去E2E模型很难学会这种丝滑的减速,加上了VLM模块是可以实现特定场景,例如丁字路口的强制减速,但是体感上能感受到是一脚略微比较急的刹车。
而在VLA里面,这个减速的G值是根据剩余距离的长短进行调整,而且在这个短暂体验中没有出现过漏检/虚惊的情况。
这种场景变相证明了:
基于前向感知为主的信息输入,只要有比较好的LLM模型,能实现相当不错的场景理解能力。
②:在高架场景中,遇到严重的拥堵情况。本车已经处于静止状态,且右后到右前方一直有车辆强行Cut in进来。
VLA 在思考了一下【让了2辆Cut in 车辆后】,偶发顿悟。直接选择直接向左变道,并且触发变道后等了一下左后车辆,然后变道过去。避免了持续右边加塞的车辆。
而过去的E2E+VLM,在这类场景中一般会触发的都是绕行逻辑。本质上是基于模仿学习的端到端模型很难有真的场景理解能力【假定场景数据足够多,一定也能学会,只是现在OrinX跑不好,提前叠甲】。
在这个场景:其背后的推理思维,大概是。堵车、右前一直有Cut in ,且左前还有不错的空间似乎不堵车,离下高架还有好几百米。等会再变回去。所以现在先往左变道效率更高。【实际思考不一定是这样,大概率没有这个深度】
再次证明:VLA具备一定深度的场景理解能力。
③:高架A-高架B 中间那些 1.5倍标准车道宽度~2.5倍标准车道宽度的闸道行驶。
VLA 的驾驶策略是轻微松开电门减速,然后判断车道宽度不足是2个车道场景下,直接选择1.5 车道的居中行驶。且从A-B 衔接点的宽车道,再也不会出现画龙的场景。
而过去E2E+VLM 在这个场景100%会出现轻微画龙的轨迹。
在这个场景:1. 是因为VLA先通过场景理解知道这个是非标车道,需要居中行驶。第二个是在决策通过扩散模型生成轨迹,这个轨迹会比 E2E直接出的 轨迹先天会更加的收敛一些【具备更加稳定的中短时序的轨迹生成能力】
因此在A-B区域的画龙现象几乎没有,车道居中能力也大幅度提升。
④:再路口右转后,经过不到50米就马上要左转。且路口右转是进入下个路口的左三车道,车辆需要连续变3个车道才能进入左转车道【不到10米】。
VLA会直接选择直行,而并非直接进入左转车道【大概率会触发导航重新规划】,而且这个直行的决策非常的坚决。
E2E+VLM 大概率会触发直接变三道,放飞自我;小概率会出现直行触发强制导航重新规划。
这个也是证明 因为 VLA是全局串行存在,因此进LLM 后客观存在时延,轨迹的更加稳定,必然就不会像以前端到端这样放飞自我。
基于这个几个场景的解释,大家可以稍微重构一下场景,再来思考MindVLA是不是机器人领域中的狭义的VLA大模型?
几个问题顺带回答了?
Q1:语音有没有?有,还行语音本质上是LLM带来的添头,甜点区。泛化再进一步做,基础语音有了,记忆也有了~
Q2:选路能力是不是大幅度提升? 高维度抽象的选路能力有质的飞跃【场景理解】,底层能力会更加稳健【来源于扩散】
Q3:是不是自动驾驶? 不是,只是辅助驾驶,需要随时接管。请大家小心
Q4:是一个完整的技术栈么?行车是一个完整的技术栈,包含地面/高架/高速。是完整的技术栈
Q5:关键信息提取 COT 来得及么?基于防御性驾驶的Cot关键节点显示,在路口15-20米左右【目测】,已经触发防御性减速,延迟完全可以接受
Q6:迭代会快么?迭代会快很多,VLA 因为有Moe 还有其他很多工程巧思,相较于以前的端到端更不容易出现跷跷板的情况。可以分场景、分能力、分细节并行优化。
Q7:和FSD有没有差距?控车细节我觉得大部分场景仍然是FSD更好,但是选路能力在杭州是要好于FSD。部分场景释放的比FSD多【三点式掉头、语义理解】。我推测FSD的E2E 参量非常大和直接出控制细节相关。这个仍然需要调
Q8:有没有不好地方:遇到一次绿灯不走,在辅路估计看成了主路的红绿灯。【辅路么有右转绿灯,且主路右转是红灯场景。】这个场景思考估计还没打通?遇到一次跟着前车一起绕行的场景,我主动接管了。
Q9:现在要注意的事项?能力边界和E2E+VLM完全不一样,辅助驾驶请及时接管。
以上均来自于一台2022年的 双OrinX 计算芯片搭载的 VLA 模型体验反馈~
#VeteranAD
端到端全新范式!复旦VeteranAD:"感知即规划"刷新开闭环SOTA,超越DiffusionDrive~
端到端自动驾驶在近几年取得了显著进展,它将多个任务统一到一个框架中,为了避免多个阶段造成的信息损失。通过这种方式,端到端驾驶框架也构建了一个完全可微分的学习系统,能够实现面向规划的优化。这种设计使得其在 open-loop(开环) 和 closed-loop(闭环) 规划任务中都展现出了不错的表现。
主流的端到端自动驾驶方法通常采用顺序式范式:先执行感知,再执行规划,如图1(a)所示。常见的做法是引入 Transformer 架构,使整个流程保持可微分。然而,仅仅依靠可微分性并不足以充分发挥端到端规划优化的优势。毕竟,端到端自动驾驶的目标是让所有前置模块都能更好地为规划服务。
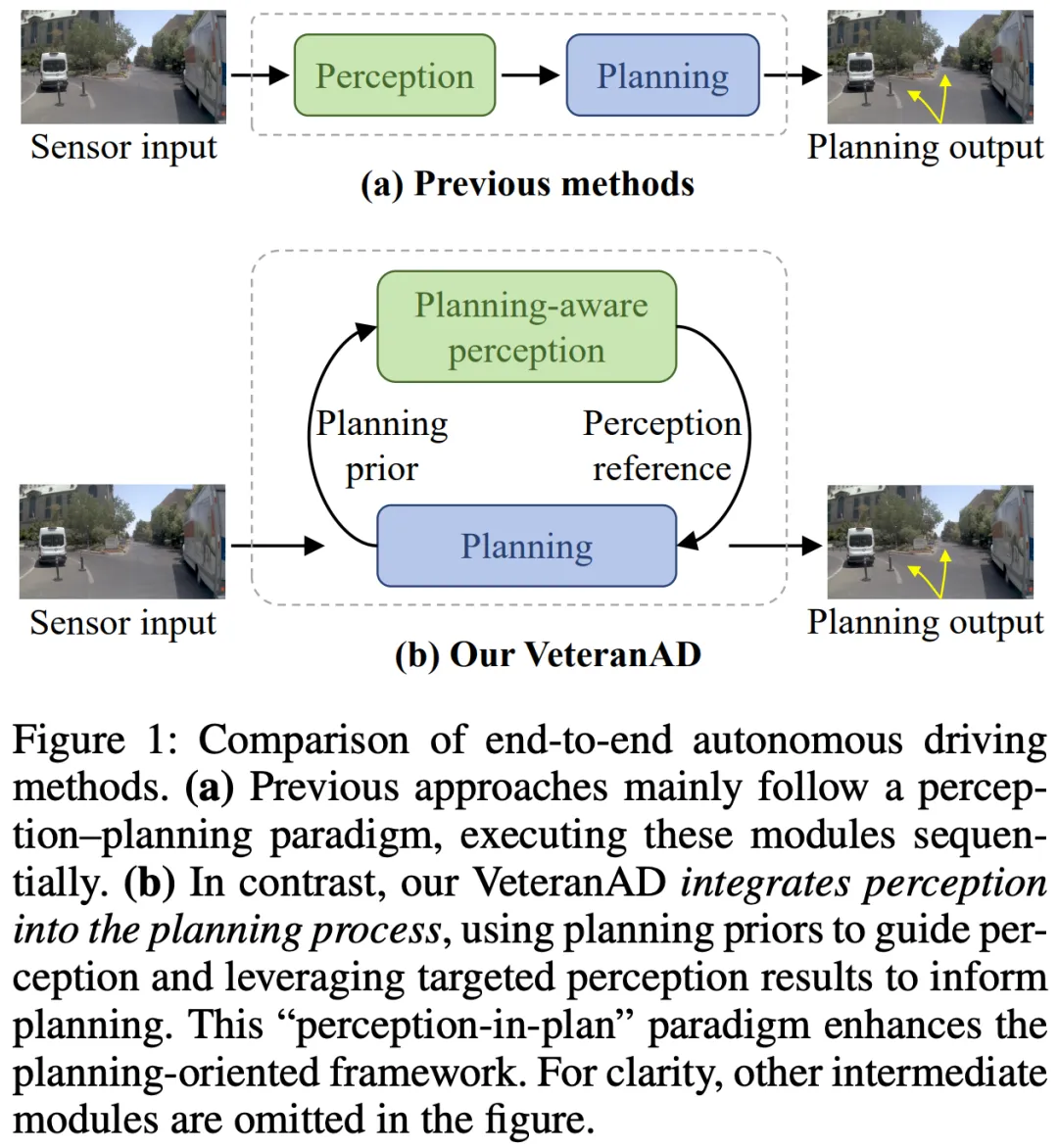
为了解决上述局限性,我们提出了一种 "perception-in-plan(感知融入规划)" 的新范式,它将感知过程直接嵌入到规划之中。这样,感知模块就能以更具针对性的方式运作,与规划需求保持一致。基于这一思路,我们设计了 VeteranAD 框架,如图1(b)所示。在该框架中,感知与规划紧密耦合。我们采用 多模态锚定轨迹(multi-mode anchored trajectories) 作为规划先验,用来引导感知模块在预测轨迹上感知关键交通元素,从而实现更全面、更有针对性的感知。
为了让感知能够真正服务于规划,我们进一步引入了一种自回归(autoregressive)策略:逐步生成未来轨迹。在每一个时间步,模型都会在规划先验的指引下,聚焦于相关区域进行针对性感知,并输出该时间步对应的规划结果。基于这一范式,我们设计了两个核心模块:
- 规划感知耦合的整体感知模块(Planning-Aware Holistic Perception):在图像特征、鸟瞰图(BEV)特征以及周围交通体特征三个维度上进行交互,从而实现对车辆、车道和障碍物等交通元素的全面理解。
- 局部自回归轨迹规划模块(Localized Autoregressive Trajectory Planning):以自回归的方式解码未来轨迹:从近到远逐步调整锚定轨迹,并结合感知结果不断优化,确保规划既具备上下文感知能力,又能逐步细化。
通过以上设计,VeteranAD 利用轨迹先验来实现聚焦式感知和渐进式规划,从而在端到端规划任务中表现出强大的性能。
总结来说,本文的主要贡献如下:
- 提出了 VeteranAD 框架,首次将 "perception-in-plan" 范式应用于端到端自动驾驶,将感知深度融入到规划过程中;
- 设计了两个关键模块:Planning-Aware Holistic Perception 和 Localized Autoregressive Trajectory Planning,实现感知与规划的紧密耦合,最大化发挥端到端优化的优势;
- 在 NAVSIM 和 Bench2Drive 两个数据集上的大量实验表明,VeteranAD 均取得了当前最优的性能表现。
相关工作回顾
端到端自动驾驶
在自动驾驶的早期阶段,基于规则的方法采用了模块化设计,将系统划分为独立的组件------感知、预测、规划和控制------并通过预定义规则相互连接。虽然这种架构具有可解释性,但它会受到误差传播和有限场景覆盖范围的影响。端到端规划方法逐渐用基于深度学习的子网络替代了诸如感知和规划等单独模块,同时保留必要的基于规则的约束。这种范式因其能够将感知、预测和规划统一到一个框架中,从而去掉手工设计的中间表示而受到关注。早期的工作通常会绕过感知和运动预测等中间任务。ST-P3 是第一个在基于环视相机的框架中引入显式中间表示的工作。UniAD 进一步通过基于 transformer 的 query 交互统一了感知、预测和规划,并在 nuScenes 基准上取得了很强的性能。最近的进展探索了多样化的表示方式和学习范式。VAD 提出了向量化场景表示,而 VADv2 引入了带有 4K 轨迹词表和冲突感知损失的概率化规划,在 CARLA Town05 上实现了最先进的闭环性能。SparseDrive 通过稀疏场景表示和并行运动规划器提升了效率。GenAD 采用生成式框架,将运动预测和规划统一起来,使用基于实例的场景表示和通过变分自编码器进行的结构化潜变量建模。最近,随着更具挑战性的真实世界基准和基于 CARLA 的闭环仿真基准的引入,越来越多的研究探索了端到端自动驾驶的不同方法,例如扩散策略、视觉语言模型、纯 transformer 架构、强化学习、闭环仿真、视觉-语言-动作模型、双系统、专家混合、流匹配、测试时训练、弥合开环训练与闭环部署之间的差距、轨迹选择、迭代规划和世界模型。这些现有方法主要遵循 "感知--规划" 范式,旨在通过分别增强感知和规划能力来提升性能。相比之下,我们提出的 VeteranAD 采用了 perception-in-plan" 范式,将感知直接整合到规划过程中,从而实现更有效的、面向规划的优化。
闭环与开环基准
闭环和开环基准是两种用于评估自动驾驶系统的方式。闭环评估会模拟完整的反馈回路------从传感器输入到控制执行------使用的工具包括 nuPlan、Waymax、CARLA、Bench2Drive 和 MetaDrive。这些模拟器可以用于衡量驾驶指标,例如碰撞率和乘坐舒适度。然而,模拟逼真的交通行为和传感器数据仍然是一个挑战。基于图形的渲染会引入域间差距,而基于数据驱动的传感器模拟则存在视觉质量有限的问题。开环评估则是在离线数据集(如 nuScenes)上测试轨迹预测,不与环境进行交互。
VeteranAD算法详解
一些先验知识
任务表述
端到端自动驾驶以传感器数据(如视觉和激光雷达)作为输入,并生成未来的规划轨迹作为输出。规划任务通常涉及生成多模态轨迹,以表示多种可能的未来行驶方案。辅助任务,例如检测、地图分割,以及对周围交通参与者的运动预测,也会被整合到端到端模型中,以帮助模型更好地学习场景特征,从而获得安全的规划结果。
框架概览
VeteranAD 框架如图2所示。它由三个主要部分组成:图像编码器(image encoder) 、规划感知整体感知模块(Planning-Aware Holistic Perception) 和 局部自回归轨迹规划模块(Localized Autoregressive Trajectory Planning) 。
首先,图像编码器从多视角图像中提取特征,生成图像特征、BEV 特征以及周围交通体特征。接着,多模态轨迹查询由锚定轨迹(anchored trajectories)初始化。规划感知整体感知模块会在轨迹查询与图像特征、BEV 特征和交通体特征之间进行位置引导的交互。随后,局部自回归轨迹规划模块以自回归的方式运作,在每个时间步执行感知并调整锚定轨迹点,最终生成完整的规划输出。
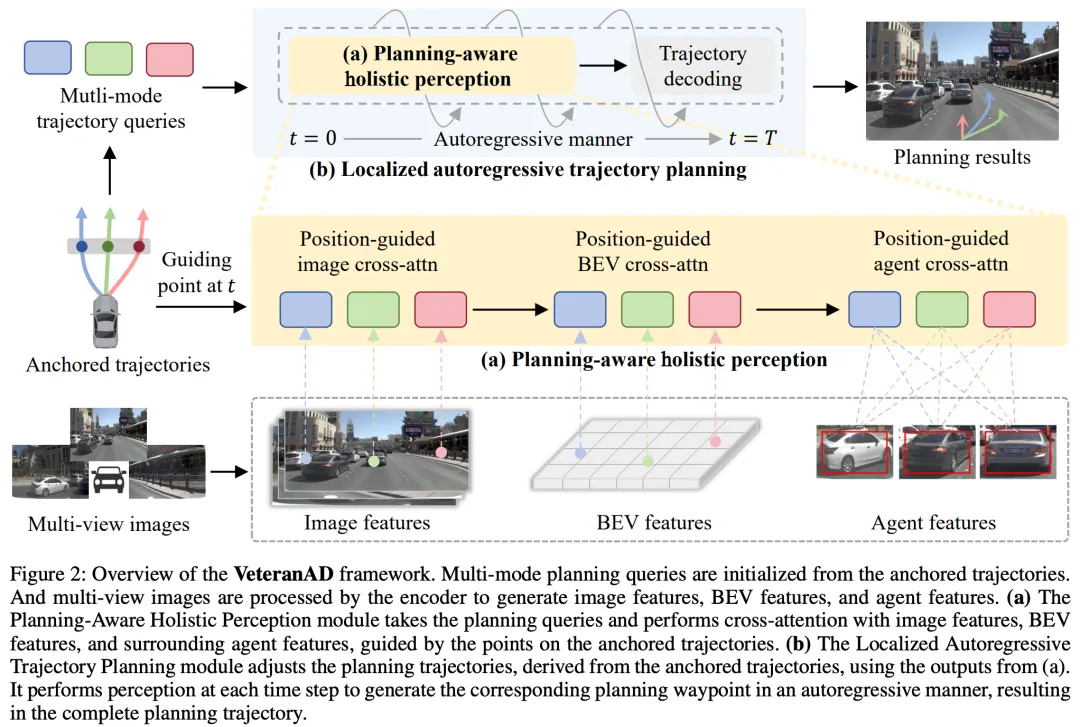
图像编码
给定多视角图像 ,其中 表示视觉视角数量,图像编码器首先提取多视角图像特征,记为 。然后,使用 LSS 方法从图像特征中生成鸟瞰图特征 。接着,通过一个简单的多层感知机 (MLP) 解码器将 BEV 特征解码为 BEV 分割图,并使用真实标签分割图进行监督。周围交通体特征 被初始化后,会通过 Transformer 块与 BEV 特征交互。最后,一个简单的 MLP 解码器将交通体特征解码为 bounding box,并通过真实的交通体 bounding box 进行监督。过程如下:
在得到这些特征之后,多模态轨迹查询 由锚定轨迹初始化,其中 表示规划模式的数量, 表示特征通道数。锚定轨迹是从真实规划轨迹中聚类得到的。
规划感知整体感知
感知模块使得轨迹查询能够全面捕获场景和交通元素,例如车道、车辆、行人和障碍物,从而确保规划的准确性和安全性。给定轨迹查询 ,我们采用三类交叉注意力机制与图像特征、BEV 特征和交通体特征进行交互。
位置引导的图像交叉注意力和 BEV 交叉注意力 用于在潜在规划轨迹上选择性地收集特征。首先,从锚定轨迹中提取时间 的引导点 ,作为规划先验。这些引导点随后被投影到图像和 BEV 坐标上。它们被作为轨迹查询与图像和 BEV 特征之间交叉注意力的参考点。过程如下:
位置引导的交通体交叉注意力 则用于基于距离有效地区分周围交通体的重要性。如在图像编码部分介绍的那样, bounding box 被解码出来,从而可以得到交通体的位置。然后,计算周围交通体与自车之间的两两相对距离,基于引导点和解码的交通体位置。
相对距离首先通过一个 MLP 编码为相对距离特征 。该特征与交通体特征和轨迹查询拼接后,形成距离感知的交通体特征 。随后应用交叉注意力机制,在维度对齐后,使轨迹查询与距离感知交通体特征进行交互。整体过程如下:
局部自回归轨迹规划
轨迹规划模块的目标是利用锚定轨迹作为粗略的规划轨迹,并结合场景特征生成最终的规划轨迹。对于未来 步的锚定多模态轨迹,我们得到轨迹点集 ,其中 ,与前文所述相同。这些轨迹点作为轨迹规划的引导点。该过程以自回归方式运作。在每个时间步 ,模块将轨迹查询 和引导点 作为输入,同时规划感知整体感知模块与轨迹查询和场景特征交互。随后,一个 MLP 轨迹解码器被用来预测时间步 的未来轨迹点。模型估计偏移量 来修正引导点,从而生成最终的规划轨迹点 ,如下所示:
最终,我们得到规划轨迹点集 ,形成最终的规划轨迹 。在最后一个时间步 ,模块会解码出多模态轨迹的分类分数 。为了对轨迹点的运动建模,我们采用 Motion-Aware Layer Normalization,根据时间 的引导点将轨迹查询从 转换为 。
端到端学习
损失函数由四个部分组成:
- BEV 分割图损失
- 交通体 bounding box损失
- 规划回归损失
- 规划分类损失
BEV 分割图损失使用交叉熵损失计算。交通体 bounding box损失分为位置回归的 L1 损失和类别分类的二元交叉熵损失。规划回归损失为 L1 损失,规划分类损失则使用 Focal Loss 计算。端到端训练的整体损失函数如下:
λλλλ
其中,λλλλ 为平衡因子。
实验及结论
实验设置
数据集
我们在 NAVSIM 和 Bench2Drive 数据集上进行训练和验证。
评测指标
对于 NAVSIM 数据集,我们使用官方基准中定义的 PDM Score (PDMS) 来评估方法。PDMS 由多个子指标组成:
- NC (No At-Fault Collisions,无责任碰撞)
- DAC (Drivable Area Compliance,可行驶区域符合度)
- TTC (Time-to-Collision,碰撞时间)
- Comf. (Comfort,舒适度)
- EP (Ego Progress,自车行驶进度)
对于 Bench2Drive 数据集,遵循官方评测协议:
- 在 开环评测 中,我们使用 **平均 L2 误差 (Average L2 Error)**;
- 在 闭环评测 中,我们采用 Driving Score 和 Success Rate 两个指标。
实现细节
模型在 8 张 NVIDIA GeForce RTX 3090 GPU 上训练,总 batch size 为 32,训练 16 个 epoch。学习率和权重衰减分别设为 和 ,优化器使用 AdamW。图像 backbone 与以往工作保持一致,采用 ResNet-34。输入由三张图像组成:前右、前方和前左,图像大小调整为 。规划模式的数量设为 20。损失计算中的平衡因子 λλλλ 在 NAVSIM 上都设为 10,在 Bench2Drive 上都设为 1。锚定轨迹使用 K-Means 聚类得到。
与 SOTA 的比较
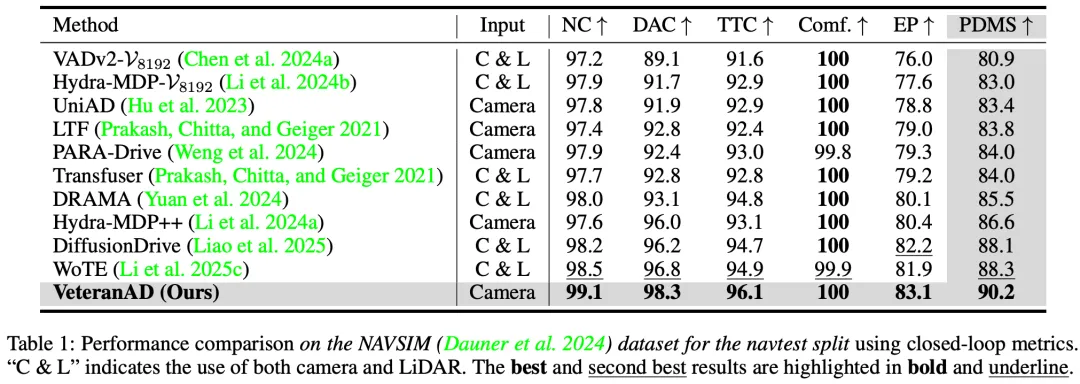
如表 1 所示,VeteranAD在 NAVSIM navtest 数据集上与 SOTA 进行了比较。在相同的 ResNet-34 backbone 下,VeteranAD 的 PDM Score (PDMS) 达到 90.2 ,显著优于之前的学习方法。仅使用视觉输入时,VeteranAD 比 UniAD 高出 6.8 PDMS,展现出其卓越性能。即使与 SOTA,如 DiffusionDrive 和 WoTE 相比,VeteranAD 在所有评测指标上也取得了更高的分数。这些结果突出了我们提出的 "perception-in-plan" 设计在端到端规划中的有效性。
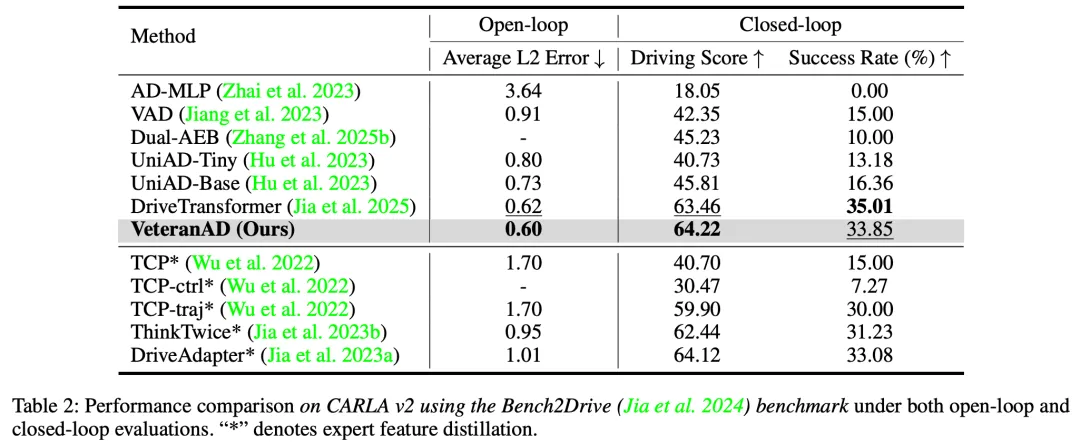
我们还在 CARLA v2 的 Bench2Drive 基准上进行了开环和闭环评测。如表 2 所示,在开环评测中,VeteranAD 的平均 L2 误差为 0.60,优于所有基线方法。在闭环评测中,VeteranAD 的性能具有竞争力,可与 SOTA 方法如 DriveTransformer 和 DriveAdapter 相媲美。这些强有力的结果展示了我们方法的有效性和泛化能力。
消融实验模块效果
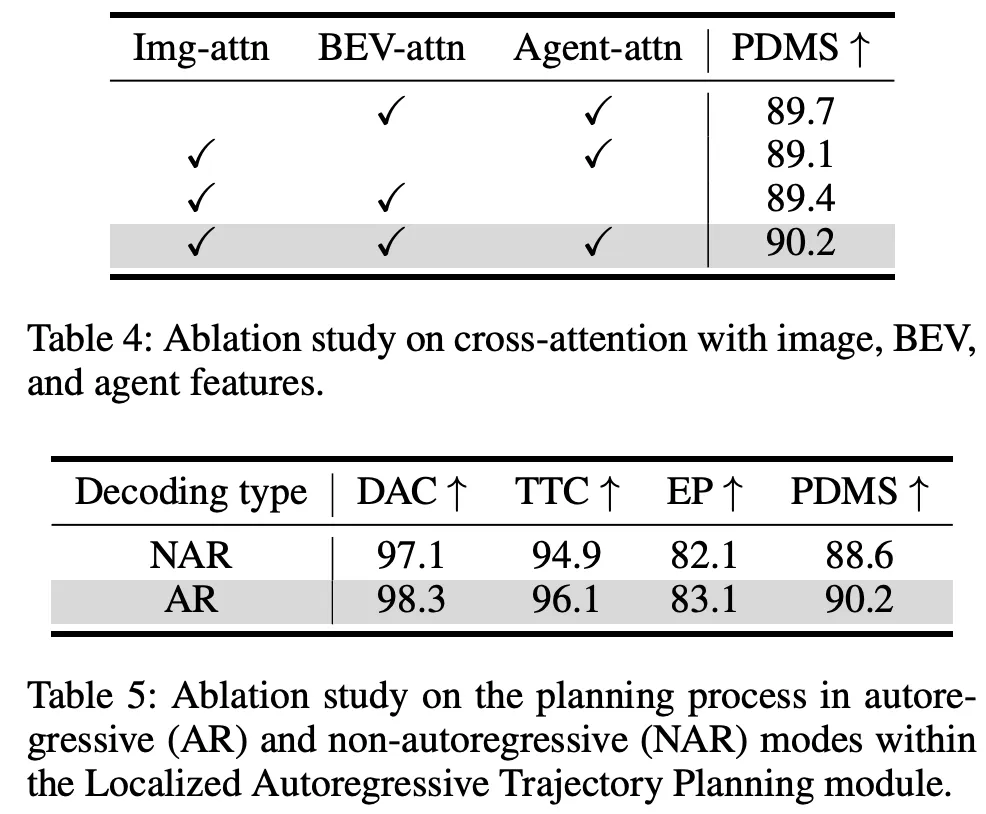
表 3 展示了对两个核心模块的消融实验结果:规划感知整体感知模块 和 局部自回归轨迹规划模块 。结果包括完整模型的性能以及单独使用各模块的效果。第一行中,将感知模块中的位置引导注意力替换为普通注意力,会导致 PDMS 下降,说明使用来自锚定轨迹的引导点作为规划先验的重要性。第二行显示,若去掉引导点,直接输出规划轨迹而非预测偏移,也会造成显著的性能下降。这些结果表明,锚定轨迹提供的引导点在准确规划中起到关键作用。当两个模块同时应用时,PDMS 达到 90.2,展示了它们的互补性和整体有效性。

不同注意力类型的影响
我们研究了图像特征、BEV 特征和交通体特征上的不同注意力机制的影响,结果如表 4 所示。去掉任意一种注意力都会导致性能下降,其中移除 BEV 注意力的影响最大,说明道路信息在规划中的关键作用。每种注意力机制都能捕获与特定交通元素(如车道、周围车辆和静态障碍物)的交互。三种注意力机制结合时,模型取得最佳性能。
AR 与 NAR 的比较
自回归(AR)解码过程是 "perception-in-plan" 框架的核心,它通过逐步预测未来轨迹,同时在每个时间步进行针对性感知。我们进行了消融实验,将轨迹规划模块中的 AR 方法替换为非自回归(NAR)方法,结果如表 5 所示。在 NAR 设置下,轨迹查询与场景特征同时进行一次性交互,使用所有锚定轨迹点作为引导,这相当于传统的 "感知--规划" 范式。结果显示,AR 方法始终优于 NAR 方法。这是因为在 AR 设置下,轨迹查询每次只关注一个轨迹点,使得逐步调整更加精细,感知与规划之间耦合更紧密。而 NAR 方法同时处理所有点,使得感知对规划意图的响应较弱,导致性能不佳。这一显著改进突出了我们基于 AR 的、面向规划设计的有效性。
在 nuScenes 数据集上的比较
为了进一步验证 VeteranAD 的有效性和泛化能力,我们在 nuScenes 数据集上进行了开环规划实验,结果如表 6 所示。我们在 VAD 的基础上集成了我们的设计,并遵循其训练和推理流程。结果表明,我们的方法将平均 L2 位移误差降低了 0.10 m,并将平均碰撞率减少了 27.2%,相比于 VAD 具有显著提升。

效率分析
我们将 VeteranAD 与 SOTA 方法 DiffusionDrive 进行比较,遵循其官方训练和推理协议。我们的模型训练约需 8 小时,而 DiffusionDrive 需 9 小时。在推理阶段,VeteranAD 的平均延迟为 22.3 ms ,而 DiffusionDrive 为 18.4 ms。尽管在训练和推理效率上相当,VeteranAD 的性能却显著更优。
定性结果
如图 3 所示,在 NAVSIM 数据集上,我们的模型能够准确规划复杂操作,如左转和变道。
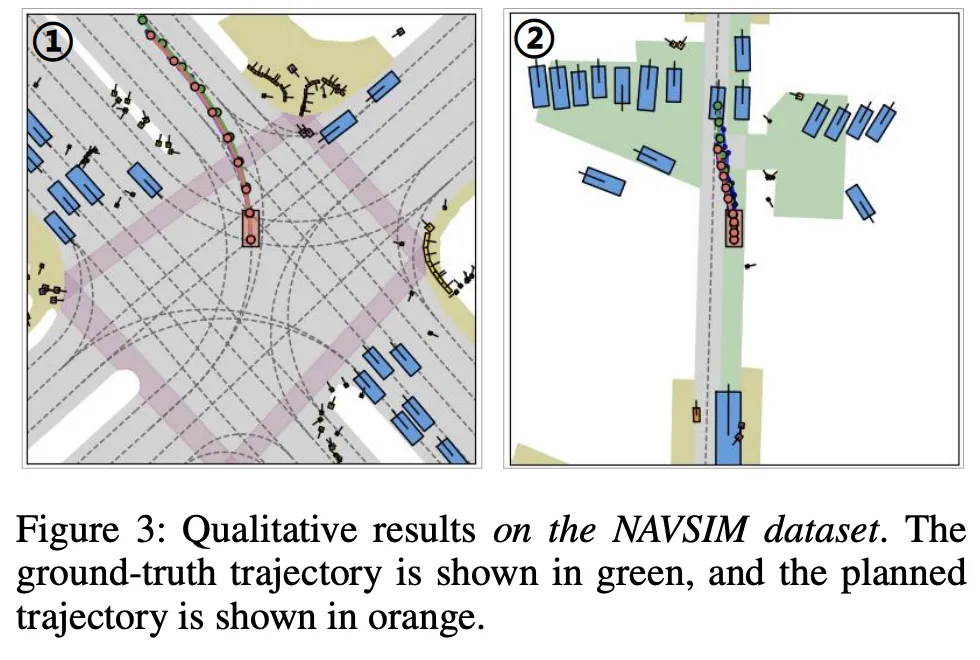
如图 4 所示,在 Bench2Drive 数据集的闭环仿真中,当一辆原本停放的车辆开始并入道路时,我们的模型能够减速避让,避免碰撞。

总结
在本文中,我们提出了一种新颖的 "perception-in-plan(感知融入规划)" 范式用于端到端自动驾驶,并基于此设计了 VeteranAD 框架。与以往普遍遵循的 "感知--规划" 范式不同,我们的方法将感知直接嵌入规划过程中,使得感知能够更好地服务于规划目标。具体而言,我们引入了 规划感知整体感知模块(Planning-Aware Holistic Perception),它利用规划先验轨迹来引导感知过程;同时,我们设计了 局部自回归轨迹规划模块(Localized Autoregressive Trajectory Planning),能够逐步生成未来轨迹,并在每个时间步结合针对性的感知结果进行优化。
通过这一新范式,VeteranAD 在 NAVSIM 和 Bench2Drive 两个具有挑战性的基准上均实现了最先进的性能。实验结果表明,感知与规划的紧密耦合能够显著提升端到端规划的准确性和安全性。我们希望这项工作能够为未来的研究提供启发,推动端到端自动驾驶系统向更高效、更安全和更可靠的方向发展。