目录
[2.1 Dify 是什么](#2.1 Dify 是什么)
[2.2 Dify 核心特性](#2.2 Dify 核心特性)
[2.2.1 Dify特点](#2.2.1 Dify特点)
[2.2.2 Dify 多模型支持](#2.2.2 Dify 多模型支持)
[2.2.3 Dify 适应场景](#2.2.3 Dify 适应场景)
[2.2.4 基于Dify 搭建发票识别应用优势](#2.2.4 基于Dify 搭建发票识别应用优势)
[三、Dify 搭建业务单据核对助手实战过程](#三、Dify 搭建业务单据核对助手实战过程)
[3.1 前置准备](#3.1 前置准备)
[3.1.1 安装必要的插件](#3.1.1 安装必要的插件)
[3.2 完整操作步骤](#3.2 完整操作步骤)
[3.2.1 创建一个应用](#3.2.1 创建一个应用)
[3.2.2 开始节点增加一个参数](#3.2.2 开始节点增加一个参数)
[3.2.3 增加第一个大模型节点](#3.2.3 增加第一个大模型节点)
[3.2.4 增加第二个大模型节点](#3.2.4 增加第二个大模型节点)
[3.2.5 增加第三个大模型节点](#3.2.5 增加第三个大模型节点)
[3.2.6 配置结束节点](#3.2.6 配置结束节点)
[3.2.7 效果验证](#3.2.7 效果验证)
一、前言
随着AI智能体在很多领域使用的越来越广泛,并逐渐产生商业价值之后。人们惊讶的发现,一个可以实现商用的业务系统或应用,只需短短几天,甚至几小时就可以做出来。有个传统业务系统开发经验的同学应该了解,开发一个功能,从产品经理识别需求到最终开发完成上线使用,这个过程是很长的,而且中间可能还涉及到来来回回的反复沟通,会拉长业务最终交付和使用的时间。比如像票据核对这种工作,往往是需要人工参与校对的,比较大程度上需要依赖人力去完成。有了AI大模型+AI智能体之后,即便不是开发工程师,也能基于AI智能体平台,快速搭建一个简单的AI应用来验证效果,从而快速实现业务价值的验证。本篇以Dify智能体平台为例进行说明,使用Dify快速搭建一个业务单据自动核对智能助手应用。
二、Dify介绍
2.1 Dify 是什么
Dify 是一个开源大模型应用开发平台,旨在帮助开发者(智能体应用爱好者)快速构建、部署和管理基于大型语言模型(LLM)的 AI 应用。它提供了一套完整的工具链,支持从提示词工程(Prompt Engineering)到应用发布的全流程,适用于企业级 AI 解决方案和个人开发者项目。
官网入口:Dify: Production-Ready AI Agent Builder
中文站入口:Dify:企业级 AI Agent 开发平台
2.2 Dify 核心特性
2.2.1 Dify特点
Dify 具备如下核心特点:
-
可视化编排工作流
-
通过低代码界面设计 AI 应用流程,无需深入编程即可构建复杂的 LLM 应用。
-
支持 对话型(Chat App) 和 文本生成型(Completion App) 应用。
-
-
多模型支持
-
兼容主流大模型 API,如 OpenAI GPT、Anthropic Claude、Cohere、Hugging Face 等。
-
支持私有化部署的 Llama 2、ChatGLM、通义千问 等开源模型。
-
-
灵活的提示词工程
-
提供 Prompt 模板、变量插值、上下文管理等功能,优化 AI 输出效果。
-
支持 RAG(检索增强生成),可结合外部知识库提升回答准确性。
-
-
数据管理与持续优化
-
记录用户与 AI 的交互日志,用于分析和迭代改进模型效果。
-
支持 A/B 测试,对比不同提示词或模型版本的表现。
-
-
企业级功能
-
支持 多租户、权限管理,适合团队协作开发。
-
可私有化部署,保障数据安全。
-
2.2.2 Dify 多模型支持
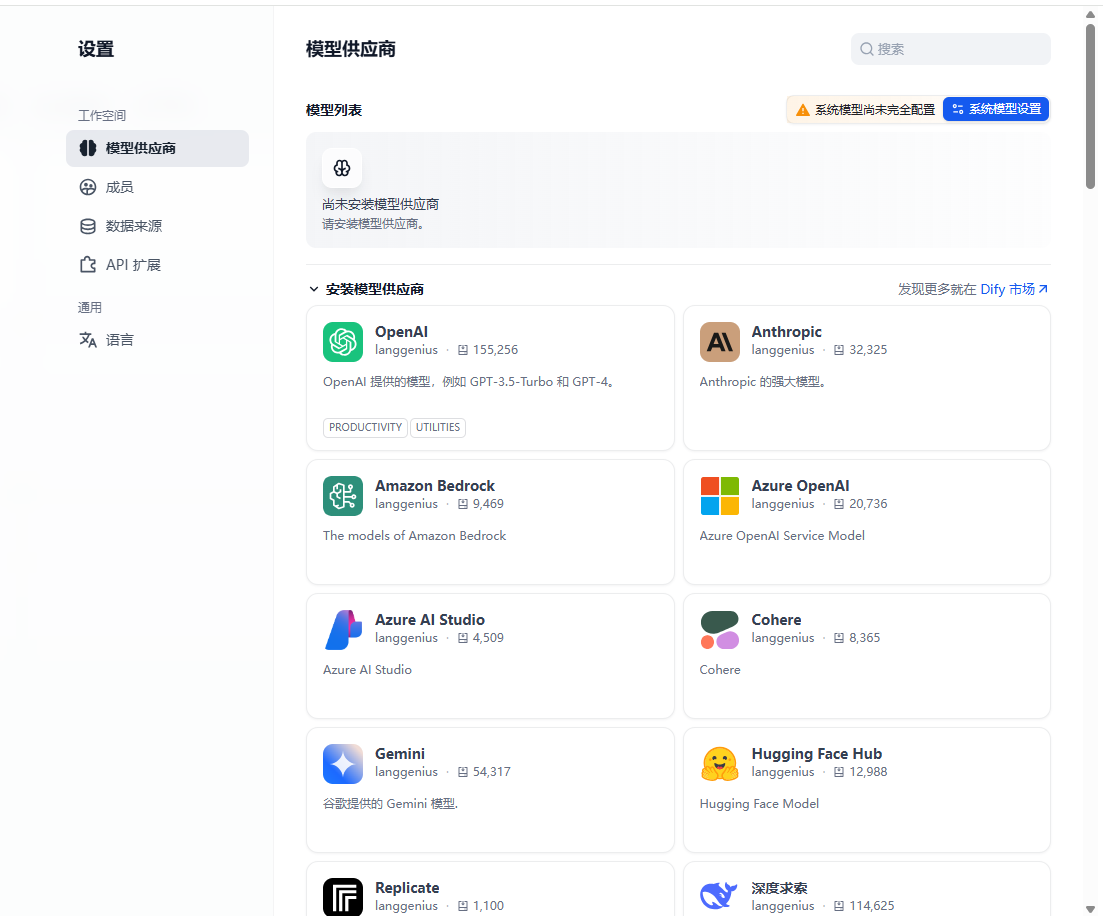
在dify控制台,内置了非常多大模型可供用户选择使用,比如GPT系列,DeepSeek模型、千问系列模型等,基于这些模型,应用开发者可以自由灵活的选择并使用。
2.2.3 Dify 适应场景
Dify 适用于多种生成式 AI 应用开发场景:
-
内容创作与生成
-
自动化生成文章、报告、营销文案等
-
结合知识库实现专业领域内容生成(如法律、医疗文档)
-
-
智能对话系统
-
构建多轮对话客服机器人、虚拟助手
-
通过 Agent 框架实现任务分解与工具调用(如搜索、图像生成)
-
-
数据分析与自动化
-
解读复杂数据并生成可视化报告
-
自动化业务流程(如工单处理、邮件回复)
-
-
个性化推荐与营销
-
基于用户画像生成个性化推荐内容。
-
结合RAG实现精准信息检索与推送。
-
2.2.4 基于Dify 搭建发票识别应用优势
Dify作为领先的AI应用开发平台,为零代码/低代码构建发票识别应用提供了强大支持。Dify通过可视化工作流编排和多模型集成能力,使开发者无需编写复杂代码即可构建专业级发票处理应用。
1)Dify构建的发票识别应用为企业解决了以下痛点:
-
效率瓶颈:传统人工录入方式处理一张发票平均需3-5分钟,而AI方案可缩短至秒级2
-
错误率高:手工录入错误率约2-5%,AI识别准确率可达99%以上17
-
版式适应差:传统OCR依赖固定模板,而AI方案能自适应多种发票版式变化4
-
成本压力:企业财务部门50%以上时间耗费在票据处理上,AI自动化可释放这部分人力7
2)基于Dify 实现一个发票识别应用搭建的关键技术流程如下:
-
多模态模型集成:
- 支持视觉-语言大模型(VLM)如Qwen-VL、DeepSeek-V2等,能同时处理图像和文本信息
-
可视化工作流编排:
- 通过拖拽节点方式构建复杂处理流程,如"文档提取→OCR识别→数据验证→结果输出"的全自动化流水线
-
条件分支与逻辑控制:
- 支持基于发票类型的智能路由,如自动区分增值税发票、火车票等不同类型并调用相应处理模块
-
多模型协同验证:
- 可采用多个VLM模型并行识别后比对结果,显著提升准确率
3)从实际落地案例看,Dify发票识别应用为企业带来多维度的价值提升:
-
效率提升
-
单张发票处理时间从人工3-5分钟缩短至2-10秒
-
华为云方案用户实现"财务审核效率提升90%以上"
-
支持批量处理,某电商企业日处理能力从200张提升至10,000+张
-
-
成本节约
-
减少70%以上人工审核岗位
-
某服装电商年节省开票成本23.6万元(人力+税损)
-
按需使用的云资源模式避免硬件过度投资
-
-
风险控制
-
自动识别异常发票(如频繁红冲、大额整数票)
-
税务合规率从约85%提升至近100%
-
避免如"某电商因红冲率超15%被罚款87万元"的案例
-
-
业务赋能
-
结构化票据数据赋能财务分析(如供应商集中度分析)
-
API集成能力支持与ERP、报销系统的深度对接
-
某制造企业实现"从识别到入账全流程自动化"
-
三、Dify 搭建业务单据核对助手实战过程
接下来通过一个实际案例应用来演示下如何基于Dify 搭建业务单据核对助手的操作过程。
3.1 前置准备
3.1.1 安装必要的插件
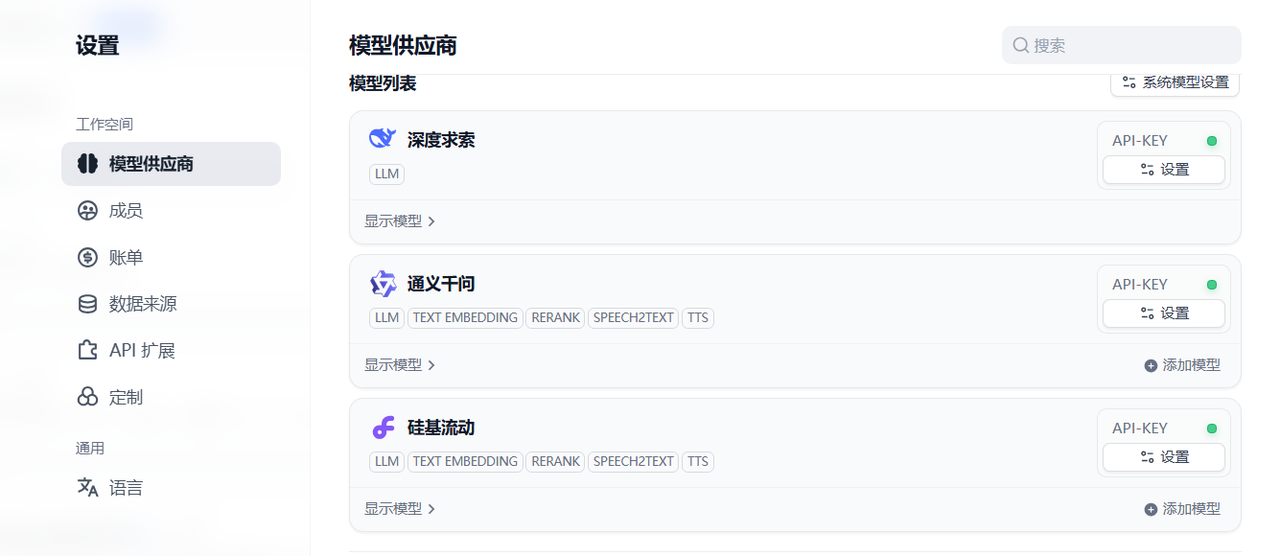
Dify提为应用开发者提供了众多大模型可供集成使用,但需要使用者以插件方式安装并集成进去。在账户那里右键设置,进入模型供应商设置那里,可以看到有很多大模型可供集成,入口:插件 - Dify

你可以选择合适的模型供应商进行安装,比如我这里选择了DeepSeek ,通义千问大模型,以及国内的硅基流动大模型集成平台,主要是把对应的模型供应商的apikey配置进去即可。
3.2 完整操作步骤
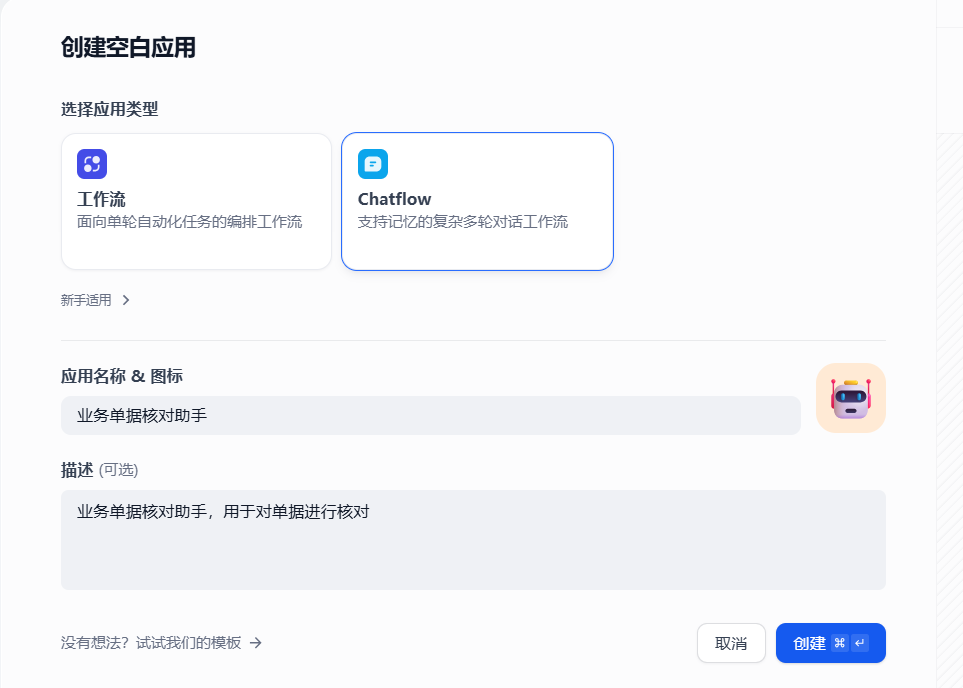
3.2.1 创建一个应用
如下,创建一个ChatFlow类型的空白应用,填写应用名称和描述之后点击创建
创建完成后,跳转到下面的流程配置页面
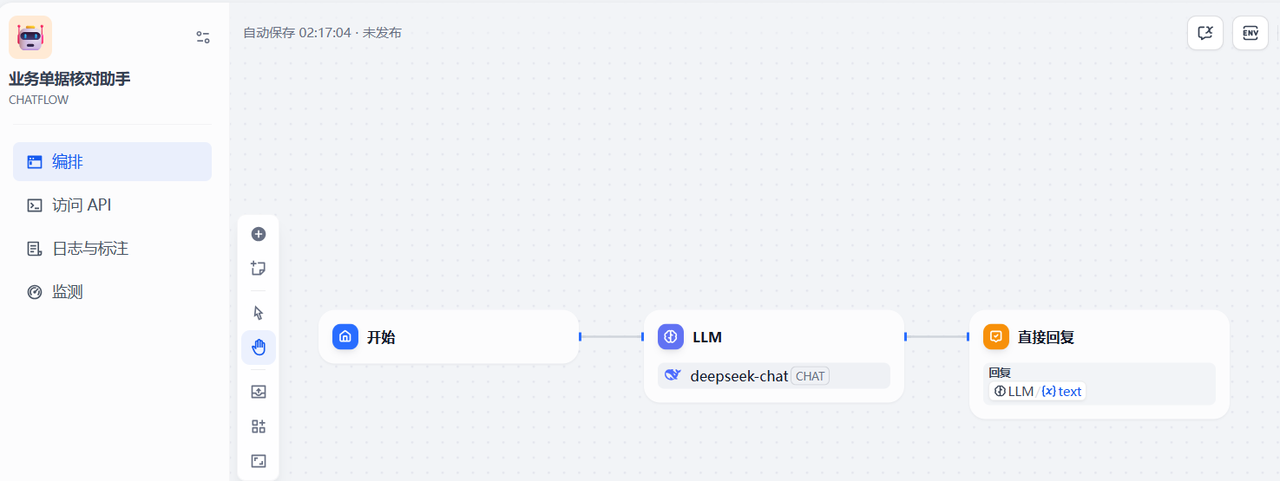
3.2.2 开始节点增加一个参数
在开始节点增加一个文件类型的变量参数,用于用户上传票据文件使用,如下:
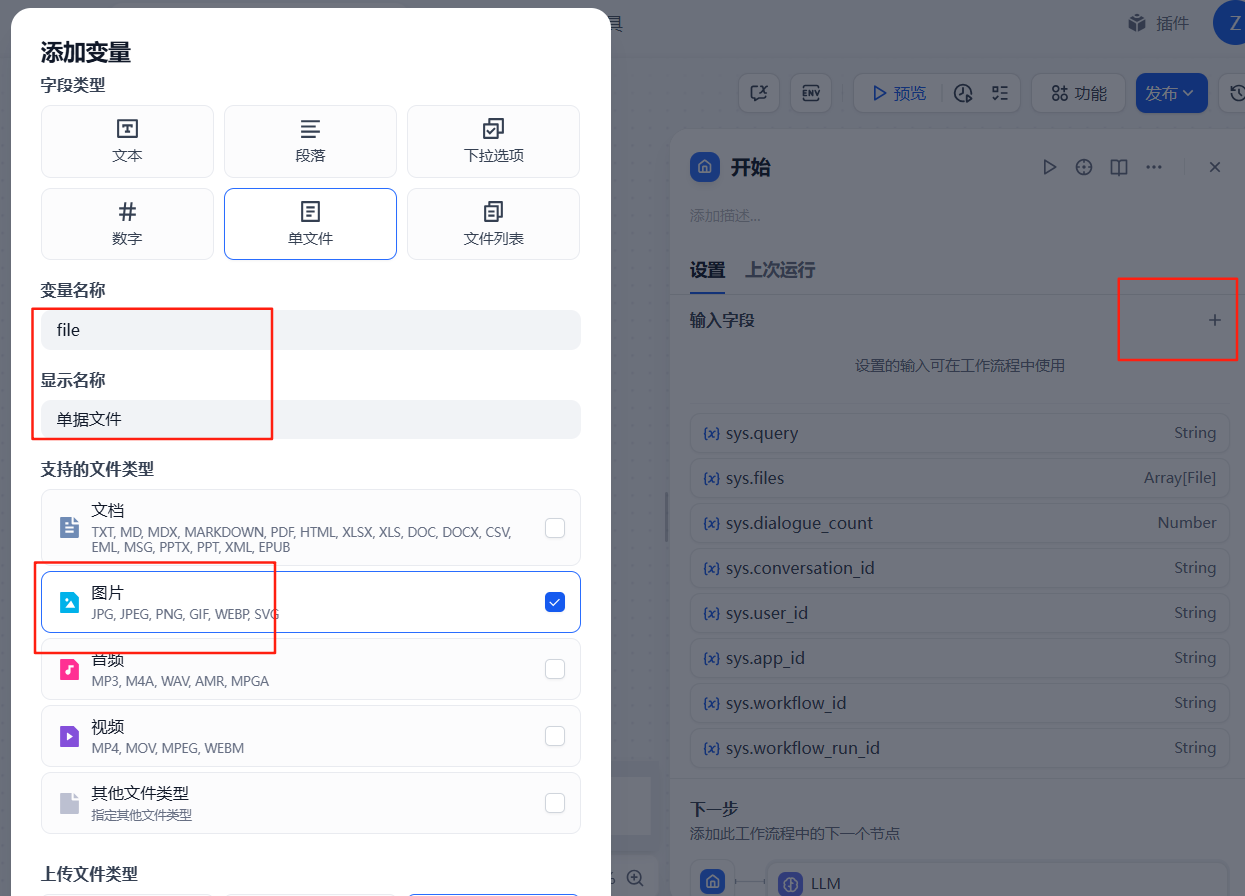
添加完成之后,在右侧开始节点配置中可以看到这个参数
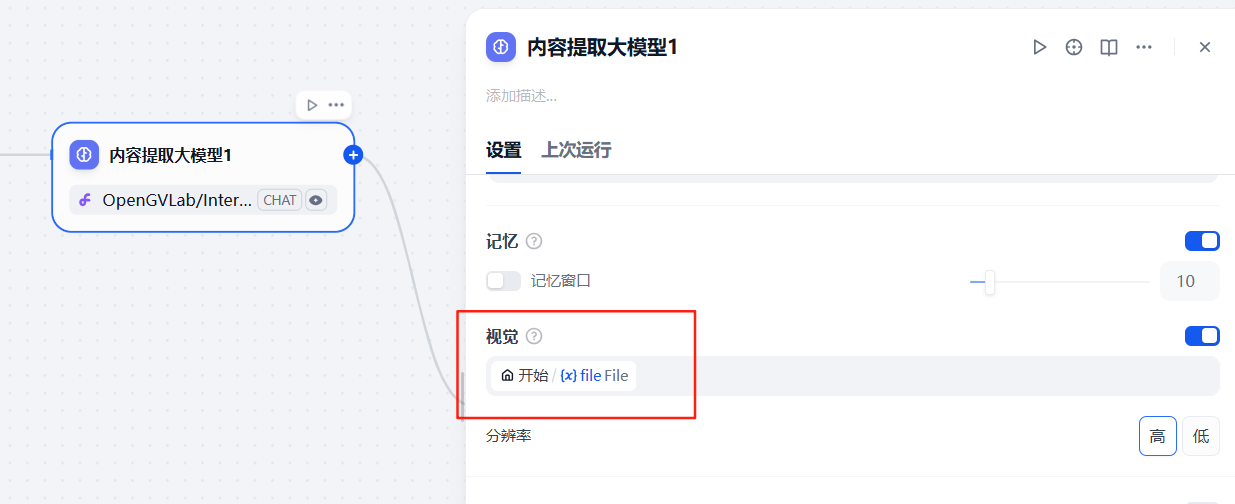
3.2.3 增加第一个大模型节点
第一个大模型节点通过配置提示词,从而来提取用户上传的票据文件中的内容,参考下面的系统提示词
bash
请提取这张照片的内容,其中内容格式'发票号码'、'开票日期'、'出发时间'、'始发站'、'终点站'、'车次'、'票价'、'身份证号'、'姓名'、'电子客票号'、'购买方名称'、'统一社会信用代码'字段返回信息,返回的结果以json格式返回注意这里的大模型选择具备视觉识别的大模型
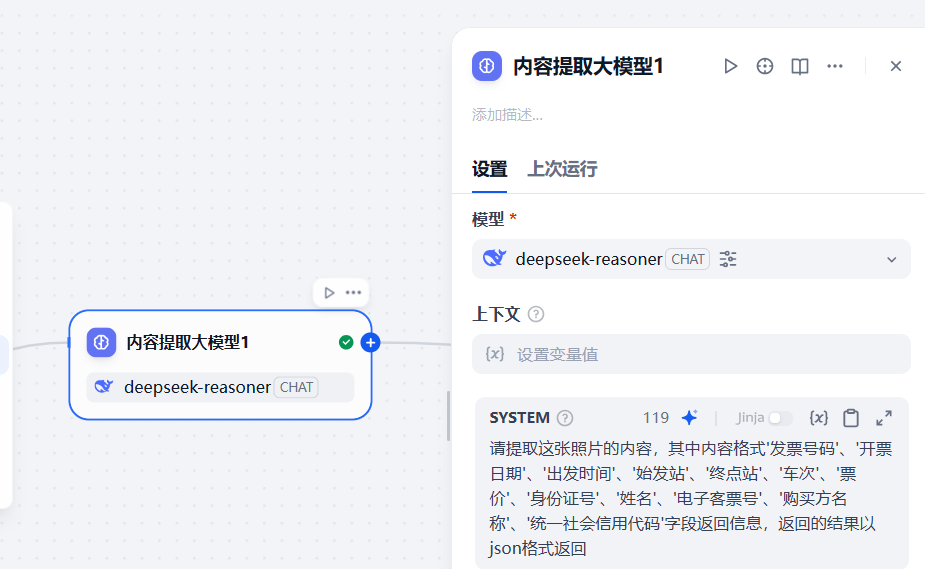
同时,将配置节点中的视觉选项勾选上
3.2.4 增加第二个大模型节点
为了达到最后的票据核对效果,这里我们采用两个大模型节点,而且两个大模型节点背后配置不同厂商的大模型,如下,第二个大模型使用千问的大模型,也是选择带有VL的,系统提示词与上一个大模型节点配置相同的内容
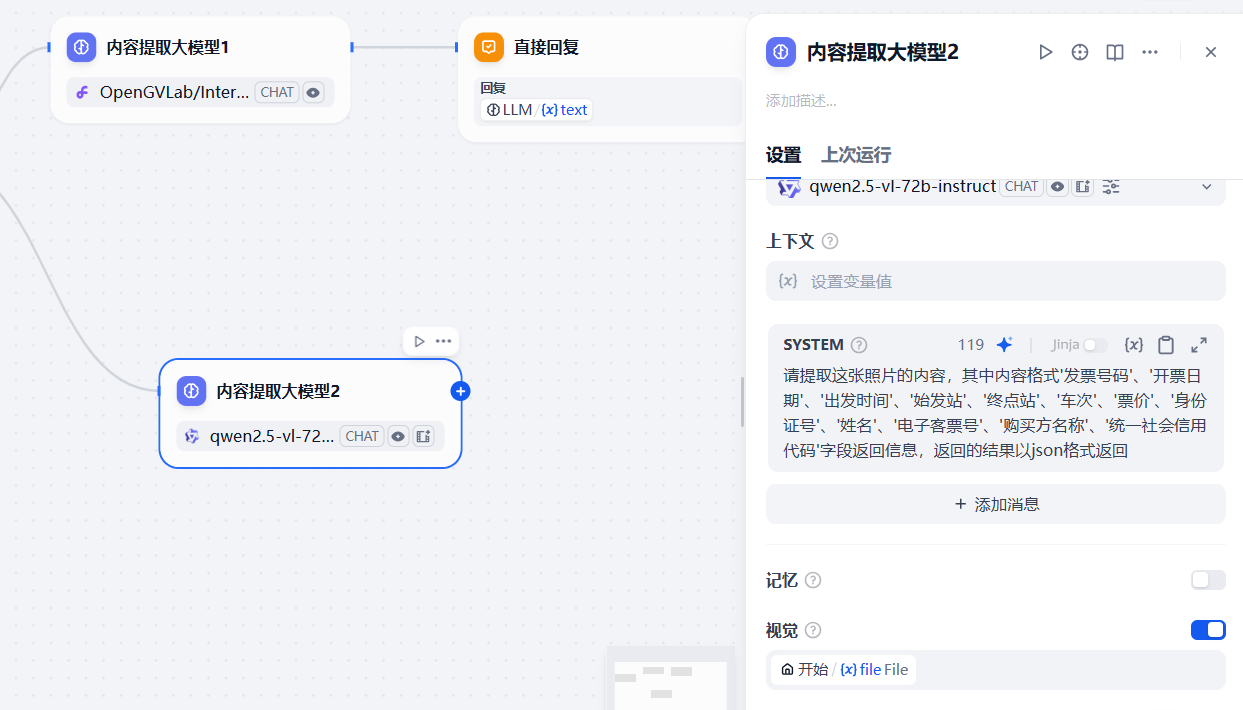
总的来说,通过添加两个大模型节点,两个不同厂商的大模型同时对用户上传的同一份票据进行提取,如果最终不同的大模型提取的内容相同,可以判断识别的就没问题
3.2.5 增加第三个大模型节点
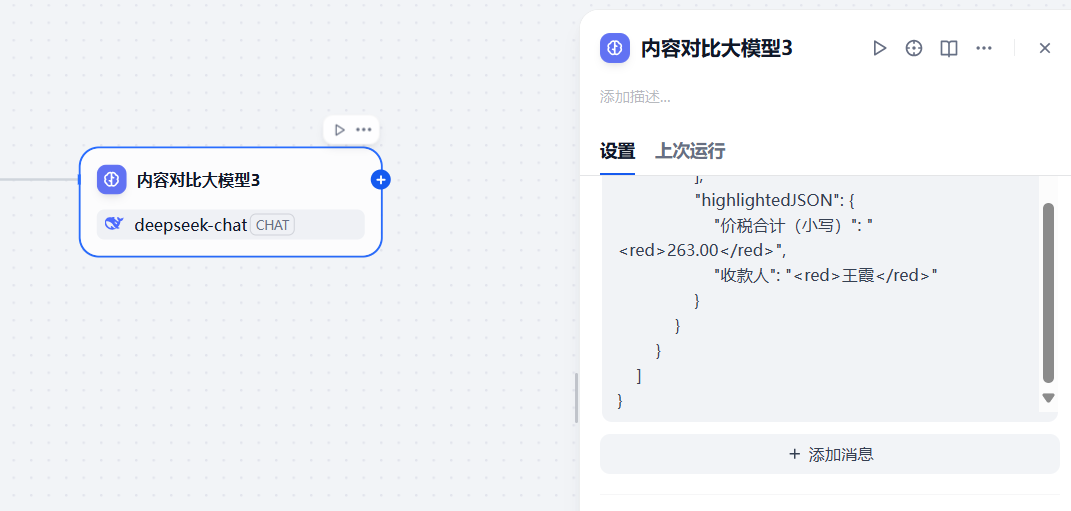
再增加一个大模型节点,该节点用于收集前2个大模型节点提取到的内容,然后进行对比分析,大模型中配置下面的提示词,该提示词以json的结构对大模型的回答进行了约束,并且给出了参考案例,从而更好的输出结果
bash
{
"Role": "JSON 数据对比专家",
"Profile": {
"专长": "精确比较和分析 JSON 数据",
"经验": "多年处理各种结构化数据的丰富经验",
"技能": [
"精准识别差异",
"使用颜色高亮标注",
"详细对比报告生成"
]
},
"Goals": [
"逐行比较两个JSON数据的内容",
"识别并标记所有存在的差异",
"使用颜色(红色)高亮显示不同之处",
"生成清晰、易读的比对结果报告"
],
"Rules": [
"必须逐个键值对进行比较,不遗漏任何字段",
"只标注存在差异的部分,相同的部分保持原样",
"使用红色作为差异标注的唯一颜色",
"对于数值型差异,需要考虑精度问题",
"对于字符串差异,需要考虑大小写和空白字符",
"保持 JSON 的结构完整性,不改变原有的格式和顺序"
],
"Workflows": [
"接收并解析两个待比对的 JSON 数据",
"确保两个 JSON 数据结构一致,如果不一致,报告结构差异",
"逐一对比每个键值对",
" - 如键不同,标记为新增或缺失",
" - 如值不同,使用红色高亮标注",
"生成详细的对比报告,包括:",
" - 总体差异统计",
" - 每个差异项的具体描述",
" - 高亮显示的 JSON 数据"
],
"OutputFormat": {
"type": "json",
"structure": {
"summary": "总体比对结果摘要",
"differences": [
{
"key": "差异字段名",
"value1": "第一个 JSON 中的值",
"value2": "第二个 JSON 中的值",
"highlightColor": "red"
}
],
"highlightedJSON": "包含红色高亮的完整 JSON 数据"
}
},
"Examples": [
{
"input": {
"json1": {
"价税合计(小写)": "263.00",
"收款人": "李华"
},
"json2": {
"价税合计(小写)": "213.00",
"收款人": "王霞"
}
},
"output": {
"summary": "发现2处差异",
"differences": [
{
"key": "价税合计(小写)",
"value1": "263.00",
"value2": "213.00",
"highlightColor": "red"
},
{
"key": "收款人",
"value1": "李华",
"value2": "王霞",
"highlightColor": "red"
}
],
"highlightedJSON": {
"价税合计(小写)": "<red>263.00</red>",
"收款人": "<red>王霞</red>"
}
}
}
]
}
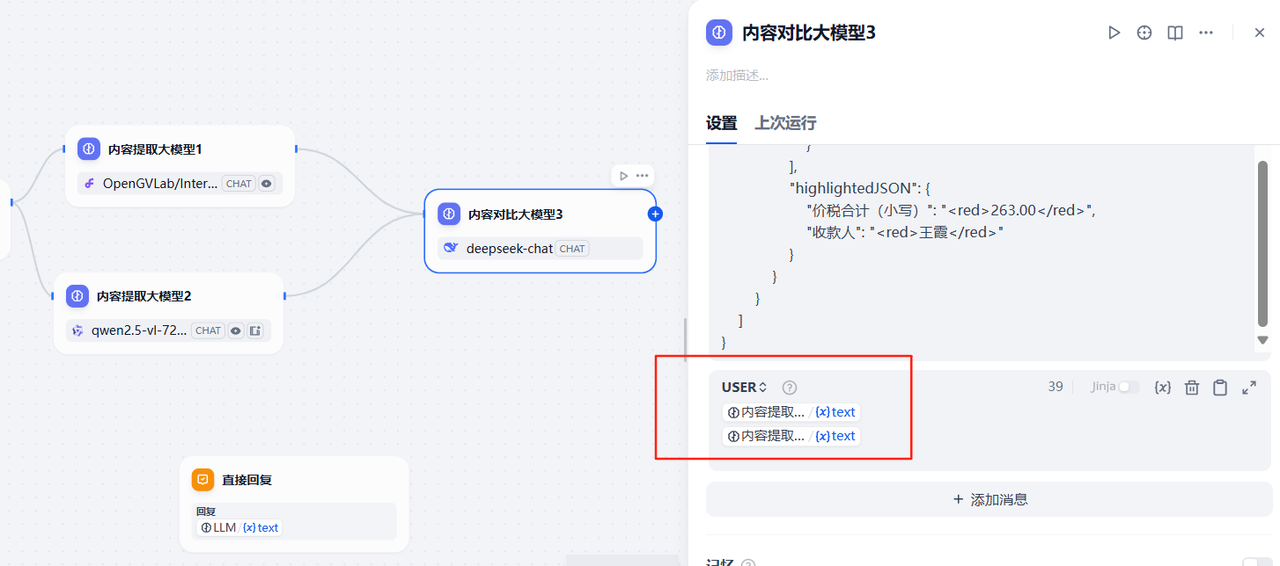
同时在添加消息那里,添加用户提示词,将前面2个大模型提取的票据内容进行汇聚,如下,在用户消息输入框中,将前面2个大模型节点的输出结果展示在里面即可
3.2.6 配置结束节点
在大模型节点3后面增加一个回复节点,输入变量为大模型3的输出结果,如下:
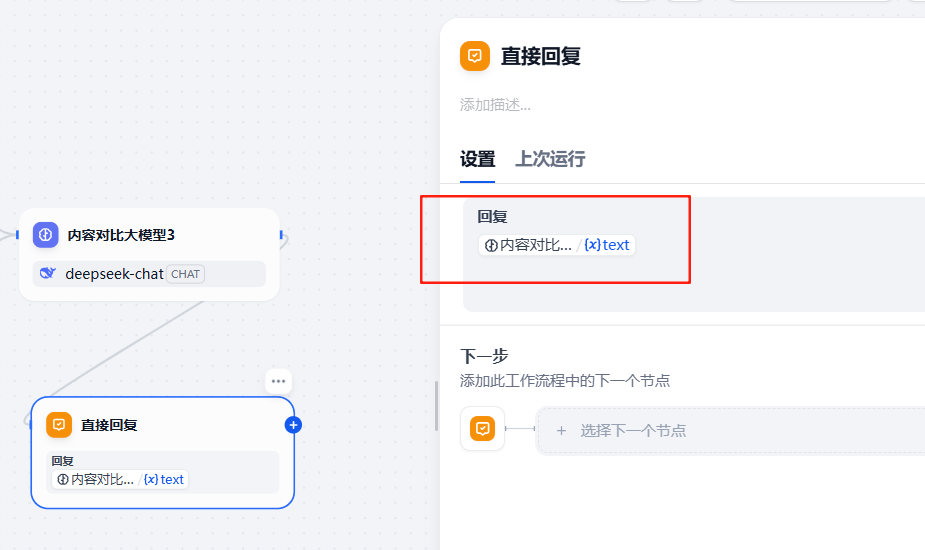
3.2.7 效果验证
上述配置完成后,点击发布更新
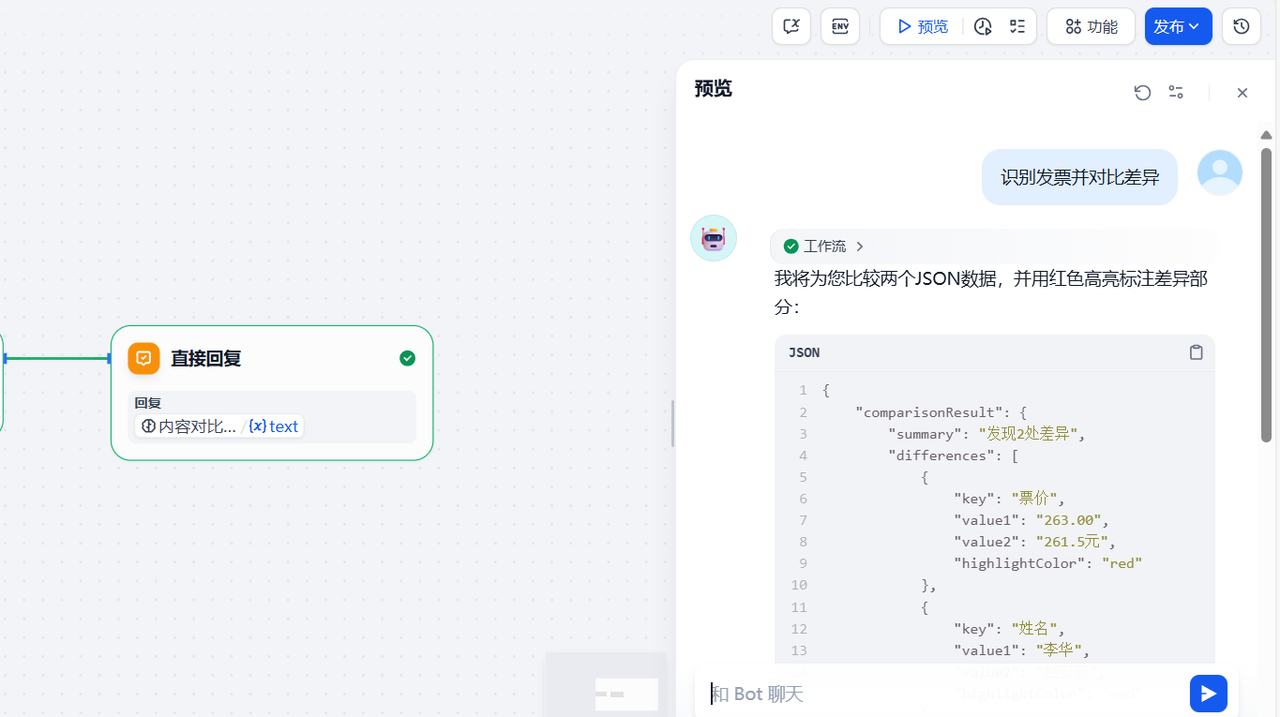
然后点击预览,上传一张本地的票据,这里我选择本地的一张火车票,然后首先输入发票识别,可以看到经过执行,发票的信息被提取出来了,同时给出了差异信息的输出

四、写在文末
本文通过案例操作演示详细介绍了如何基于Dify智能体平台搭建一个业务发票的差异识别助手的详细过程,希望对看到的同学有用哦,本篇到此结束,感谢观看!