目录
[Selenium 是什么?](#Selenium 是什么?)
[Selenium 的主要组件](#Selenium 的主要组件)
[为什么使用 Selenium?主要用途](#为什么使用 Selenium?主要用途)
[一个简单的例子(使用 Python)](#一个简单的例子(使用 Python))
[补充: Selenium 元素定位](#补充: Selenium 元素定位)
[✅ 一、语法与表达能力不同](#✅ 一、语法与表达能力不同)
[✅ 二、性能差异(一般来说)](#✅ 二、性能差异(一般来说))
[✅ 三、功能对比(CSS vs XPath 等)](#✅ 三、功能对比(CSS vs XPath 等))
[✅ 四、适用场景推荐](#✅ 四、适用场景推荐)
[✅ 推荐使用 CSS 选择器 的情况:](#✅ 推荐使用 CSS 选择器 的情况:)
[✅ 推荐使用 XPath 的情况:](#✅ 推荐使用 XPath 的情况:)
[✅ 推荐使用 ID / Name / Class / Tag 的情况:](#✅ 推荐使用 ID / Name / Class / Tag 的情况:)
[✅ 总结对比表](#✅ 总结对比表)
[✅ 结论](#✅ 结论)
美səˈliniəm英səˈliːniəm
"瑟 - 利 - 尼 - 厄姆"(sè - lì - ní - èm)
n.硒(化学元素,用于制造电气设备和有色玻璃,人体缺此元素可致抑郁等病)
网络硒质;含硒;硒元素
Selenium 是什么?
Selenium 是一个用于自动化 Web 浏览器操作 的强大开源工具和框架集合。它的核心使命是让您能够通过编写代码来模拟真实用户与网页的交互行为,从而实现 Web 应用的自动化测试、数据抓取、任务自动化等。
简单来说,Selenium 就是一个机器人程序 ,它可以按照你写的脚本指令,去控制一个真正的网页浏览器(如 Chrome, Firefox, Edge 等)来做各种事情,比如点击按钮、填写表单、跳转页面、抓取信息等。
Selenium 的主要组件
Selenium 项目不仅仅是一个工具,它由几个关键组件组成,以适应不同的需求:
-
Selenium WebDriver Selenium WebDriver | 菜鸟教程
-
核心组件,也是目前最常用、功能最强大的部分。
-
它提供了一套面向各种编程语言(如 Python, Java, C#, JavaScript, Ruby 等)的 API(应用程序接口)。
-
这些 API 允许你直接向浏览器发送命令(如"打开这个网址"、"找到这个输入框"、"输入这段文字"),浏览器执行后返回结果。
-
WebDriver 直接与浏览器原生支持的功能进行通信,控制力强,更接近真实用户操作。
-
-
Selenium IDE (Integrated Development Environment)入门 - 《Selenium IDE 中文文档帮助手册教程》 - 极客文档,
-
一个用于录制和回放操作的浏览器插件(主要用于 Chrome 和 Firefox)。
-
它非常适合快速创建简单的测试用例而无需编写代码。你只需要在浏览器中正常操作,IDE 会录下你的所有步骤,之后可以回放。
-
主要用于原型设计、快速调试或学习 Selenium 命令。
-
-
Selenium Grid Selenium Grid | 菜鸟教程
-
用于并行测试的工具。
-
允许你在多台机器上的多个浏览器中同时运行测试用例。这极大地加快了测试速度(特别是大型测试套件),并可以方便地测试不同浏览器和操作系统的组合。
-
通常由一个 Hub (中心节点)和多个 Node (节点)组成。Hub 接收测试指令并将其分发到符合条件的 Node 上执行。
-
为什么使用 Selenium?主要用途
-
自动化测试 (最主要的用途)
-
功能测试 :自动验证网站的功能是否正常工作,如表单提交、登录流程、购物车结算等。
-
回归测试 :当软件开发新功能或修复 Bug 后,运行已有的自动化测试来确保没有破坏旧有的功能。
-
跨浏览器测试:确保你的网站在 Chrome, Firefox, Safari, Edge 等不同浏览器上表现一致。
-
-
网络爬虫 / 数据抓取
-
对于大量依赖 JavaScript 动态加载数据的现代网页(即内容不是直接写在 HTML 源码里,而是通过 JS 脚本异步获取并渲染),传统的简单爬虫(如 requests + BeautifulSoup)无法获取到完整内容。
-
Selenium 可以驱动一个真正的浏览器,等待 JS 执行完毕并完全渲染出页面后再抓取内容,因此能完美解决动态网页的抓取问题。
-
-
重复性任务自动化
- 任何你需要在网页上重复进行的枯燥任务,都可以用 Selenium 来自动化。例如:自动填写在线表格、自动发布内容、自动检查网站状态、自动下载文件等。
一个简单的例子(使用 Python)
以下是一个使用 Selenium WebDriver 和 Python 来自动打开百度并搜索"Selenium"的示例:
python
from selenium import webdriver #自动化控制浏览器模块
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# 0. 先创建 Service 对象,指定 chromedriver 路径
service = Service(r"C:\Program Files\Google\Chrome\Application\chromedriver.exe")
# 1. 再用 Service 对象去初始化 Chrome
driver = webdriver.Chrome(service=service)
# 2. 打开百度首页
driver.get("https://www.baidu.com")
# 3. 找到搜索输入框(通过它的HTML ID属性)
# <div id="chat-input-area"><textarea id="chat-textarea" class="chat-input-textarea chat-input-scroll-style" data-ai-placeholder="让大脑慢慢变笨的9种行为" rows="1" autocomplete="off" data-normal-placeholder="合肥22岁男子赴广州后失联" placeholder="合肥22岁男子赴广州后失联"></textarea></div>
search_box = driver.find_element(By.ID, "chat-textarea")
# 4. 在输入框中输入搜索词 "Selenium"
search_box.send_keys("Selenium")
# 5. 模拟按下键盘的 "回车" 键来执行搜索
search_box.send_keys(Keys.RETURN)
# 6. 等待一会儿(或者在这里可以添加代码来等待页面加载完成并处理结果)
# 7. 关闭浏览器
# driver.quit()优点与缺点
优点:
-
高度模拟真实用户:操控真实浏览器,行为与人类用户几乎无异。
-
强大的功能:能处理复杂的交互、JavaScript 渲染、弹出框、iframe 等。
-
跨浏览器和平台:支持所有主流浏览器和操作系统。
-
多语言支持:可以用你熟悉的编程语言来编写脚本。
-
庞大的社区:遇到问题很容易找到解决方案和资料。
缺点:
-
速度慢 :相比于直接发送 HTTP 请求的爬虫(如
requests库),启动浏览器和渲染页面需要更多时间和资源(内存、CPU)。 -
资源消耗大:同时运行多个浏览器实例对计算机性能要求较高。
-
容易被反爬虫机制检测 :虽然像真人,但一些高级的反爬虫技术可以通过浏览器指纹等方式检测出自动化浏览器。不过也有一些方法可以规避。
总结
Selenium 是一个行业标准级的 Web 浏览器自动化工具。 它的主要舞台是自动化测试 ,但在需要与 JavaScript heavy(重度使用JavaScript)的网页进行交互的网络爬虫 领域,它同样是不可或缺的利器。如果你需要让程序像人一样操作网页,Selenium 几乎是最佳选择。
实战!!!!!
查看自己的Google Chrome版本:
|------------------------------|
| 139.0.7258.139 (正式版本) (64 位) |
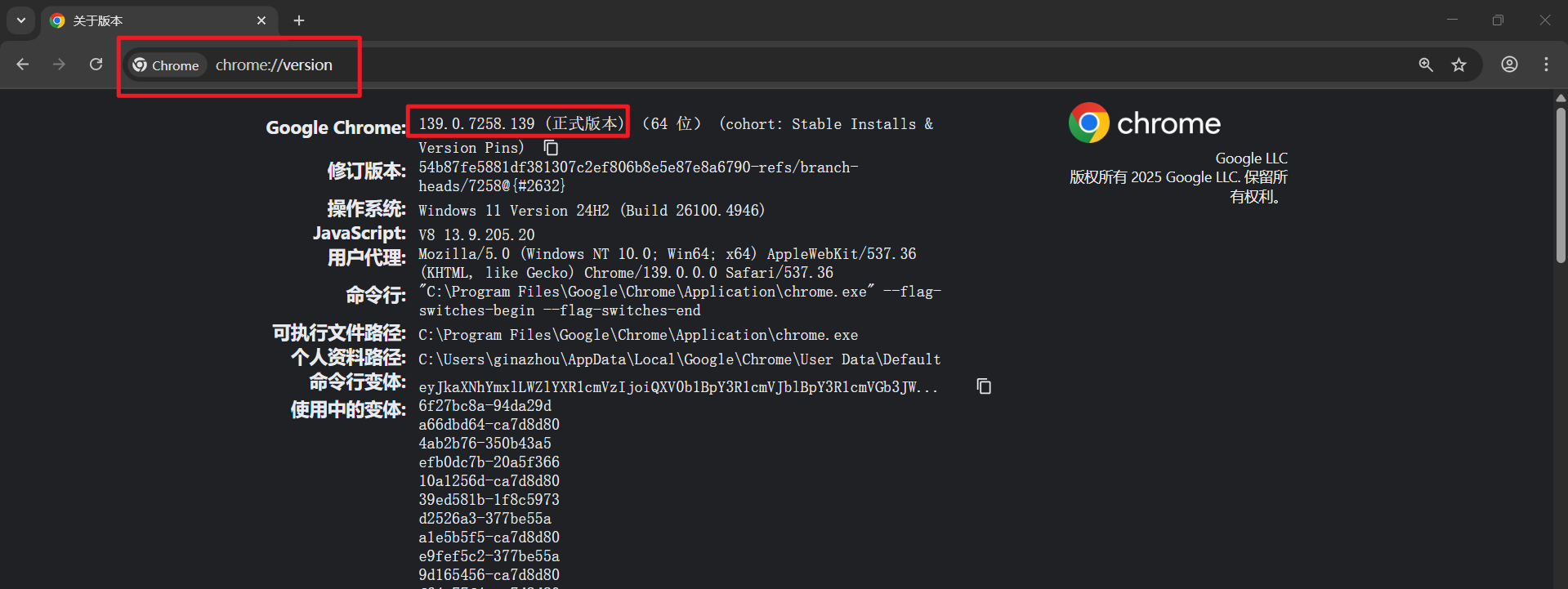
驱动下载地址:
Index of chromedriver-local/139.0.7258.138
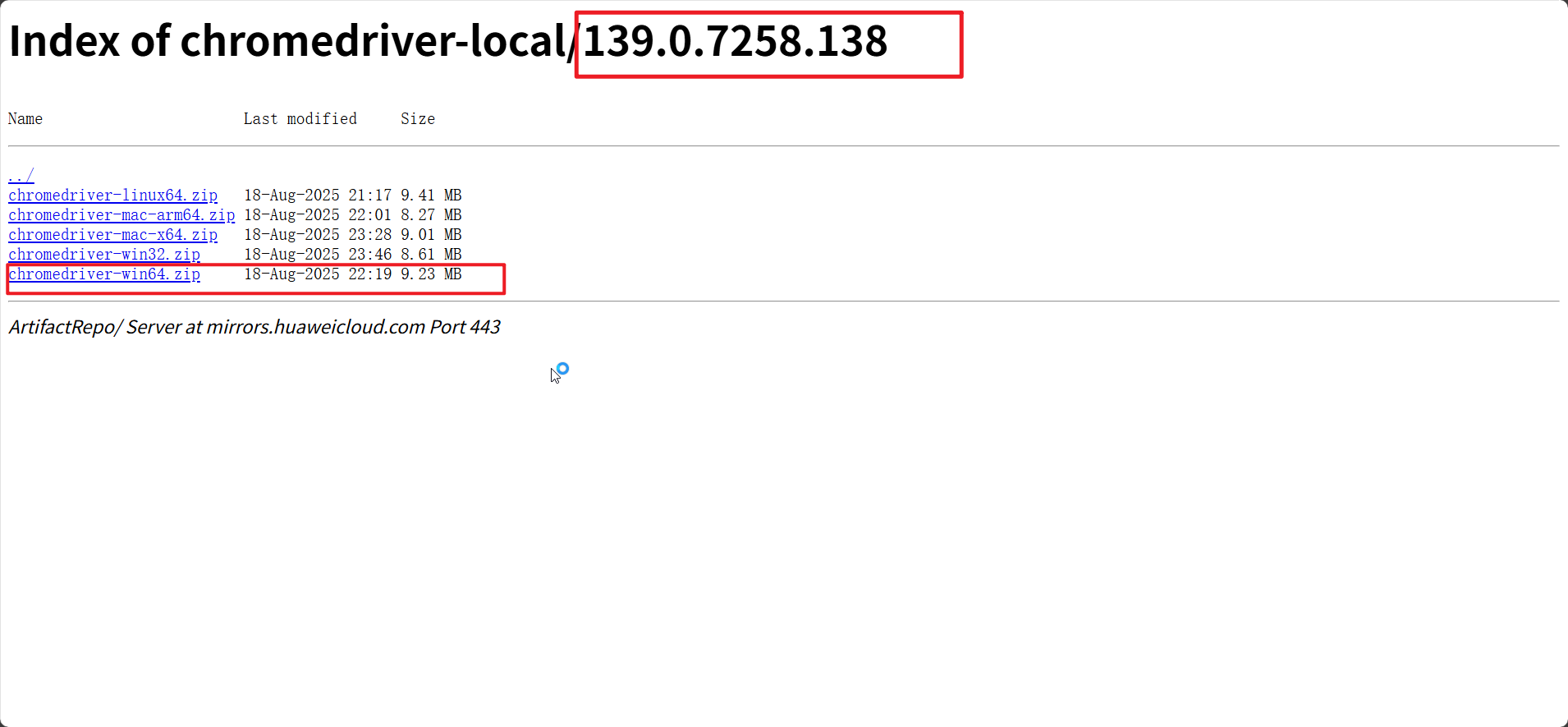
解压
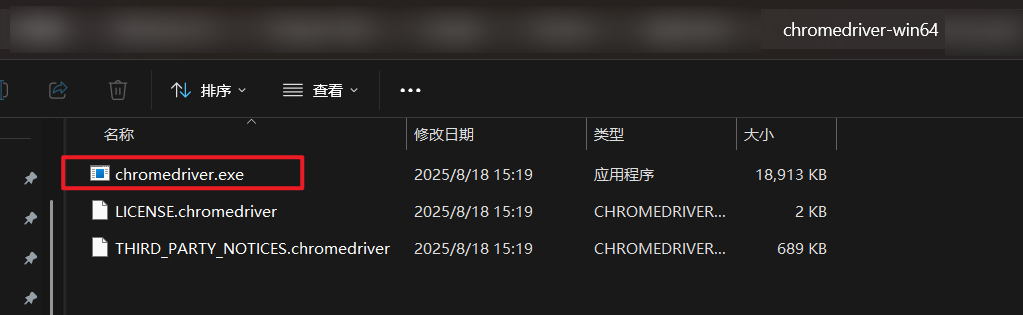
首先复制到:C:\Program Files\Google\Chrome\Application
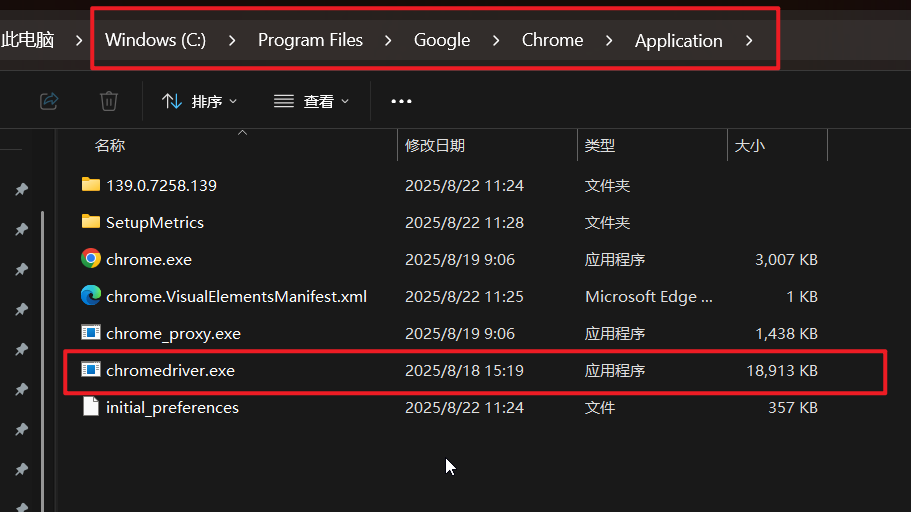
再复制到:D:\Program2\Anaconda
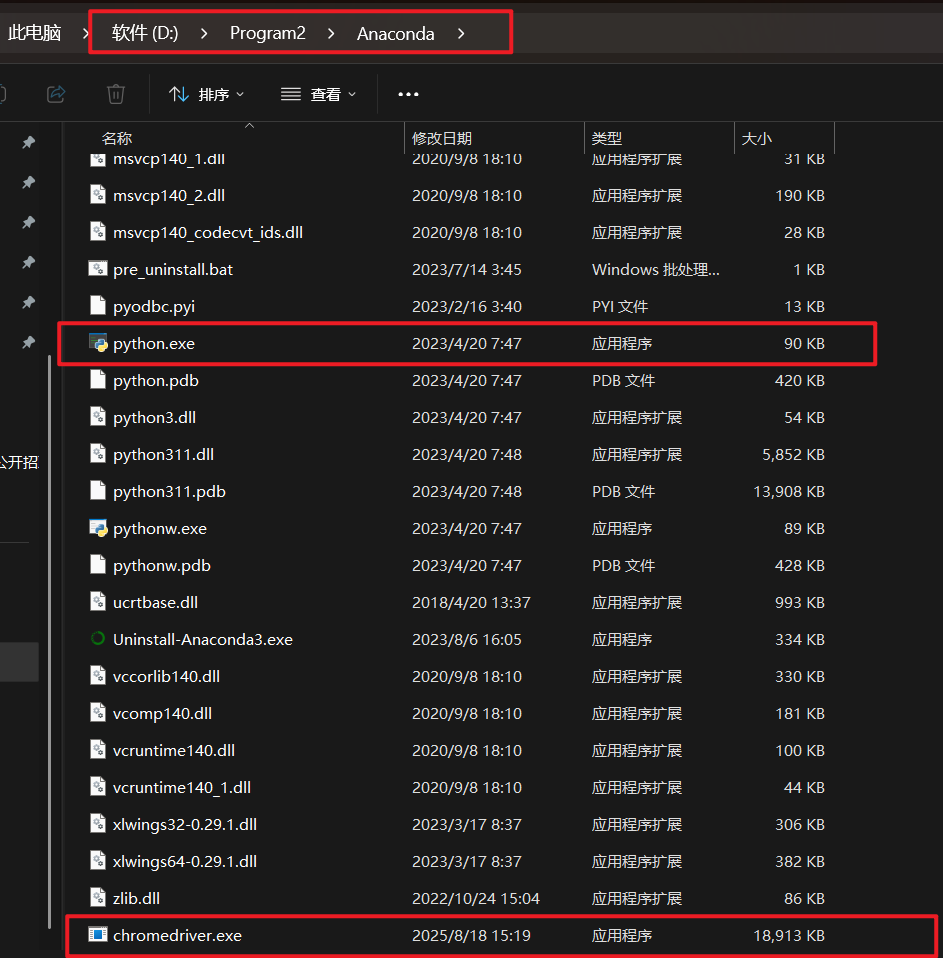
配置环境变量
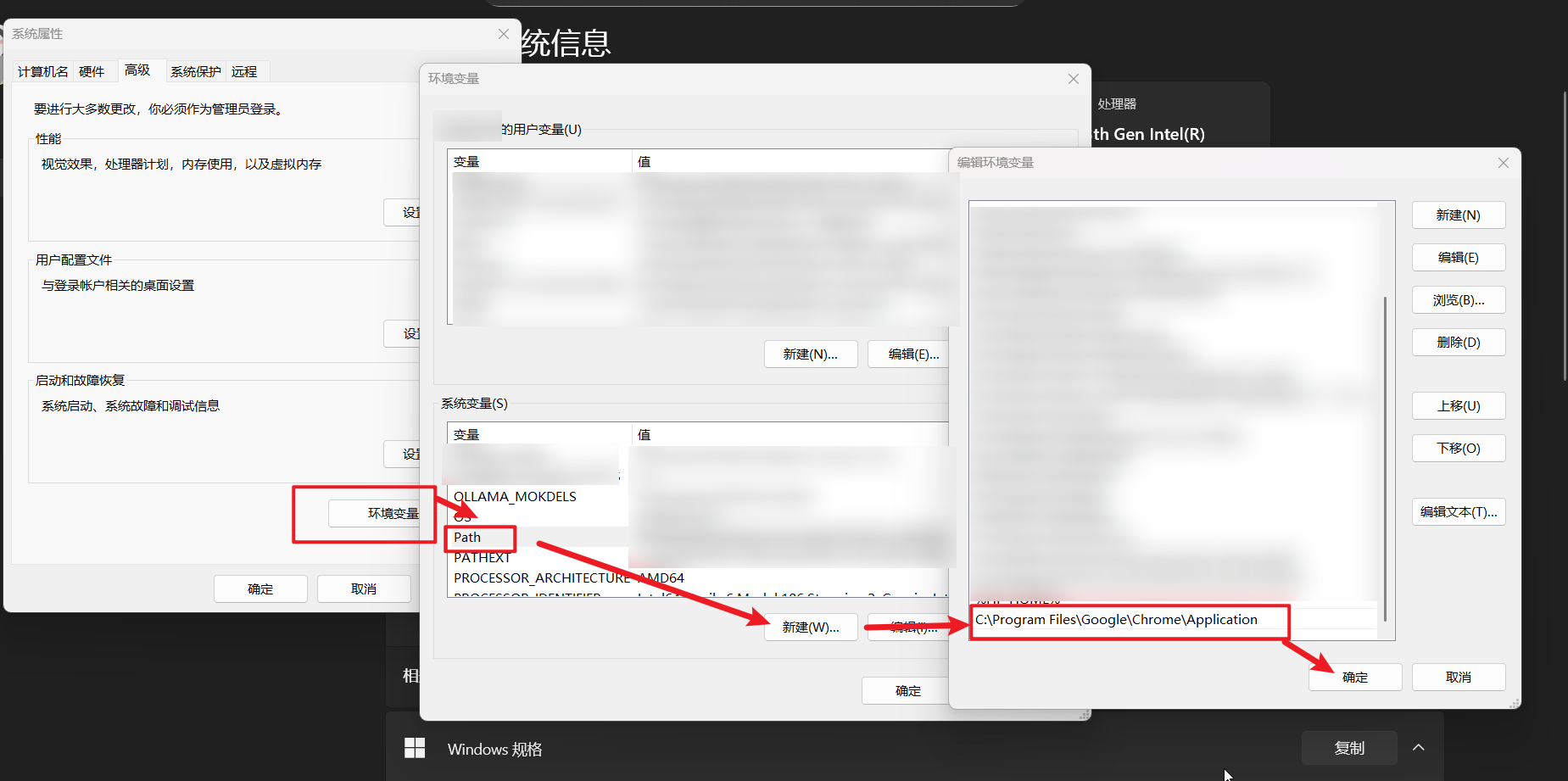
测试
python
from selenium import webdriver #自动化控制浏览器模块
from selenium.webdriver.chrome.service import Service
# 1. 先创建 Service 对象,指定 chromedriver 路径
service = Service(r"C:\Program Files\Google\Chrome\Application\chromedriver.exe")
# 2. 再用 Service 对象去初始化 Chrome
driver = webdriver.Chrome(service=service)
# 后续操作...
driver.get("https://baidu.com/")from selenium import webdriver
这行代码导入了 Selenium 库中的 webdriver 模块。webdriver 是 Selenium 的核心模块,用于控制不同类型的浏览器(如 Chrome、Firefox、Edge 等)。
用途:通过 webdriver,你可以创建一个浏览器实例,并通过编程方式控制浏览器的行为,如打开网页、填写表单、点击按钮等。
支持的浏览器类型:
python
__all__ = [
"ActionChains",
"Chrome",#√
"ChromeOptions",
"ChromeService",
"ChromiumEdge",
"DesiredCapabilities",
"Edge", #√
"EdgeOptions",
"EdgeService",
"Firefox", #√
"FirefoxOptions",
"FirefoxProfile",
"FirefoxService",
"Ie",
"IeOptions",
"IeService",
"Keys",
"Proxy",
"Remote",
"Safari",
"SafariOptions",
"SafariService",
"WPEWebKit",
"WPEWebKitOptions",
"WPEWebKitService",
"WebKitGTK",
"WebKitGTKOptions",
"WebKitGTKService",
]from selenium.webdriver.chrome.service import Service
这行代码导入了 Service 类,该类用于配置 Chrome 浏览器的启动服务。
用途:Service 类可以帮助你更灵活地配置 Chrome 浏览器的启动参数,例如指定 ChromeDriver 的路径、设置环境变量等。
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# ---------------------------
# 1. 配置 chromedriver 路径并初始化浏览器
# ---------------------------
# 替换为你本地 chromedriver 的实际路径
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(chromedriver_path)
# 初始化 Chrome 浏览器(可以加一些启动参数,比如无头模式、禁用图片等,按需添加)
options = webdriver.ChromeOptions()
# options.add_argument('--headless') # 无头模式,不弹出浏览器窗口(调试用的话可以先注释掉)
# options.add_argument('--disable-gpu') # 禁用 GPU 加速(某些环境下需要)
# options.add_argument('--no-sandbox') # 可选,解决一些权限问题
driver = webdriver.Chrome(service=service, options=options)
# ---------------------------
# 2. 访问豆瓣电影 Top250 首页
# ---------------------------
url = "https://movie.douban.com/top250"
driver.get(url)
# 可以加个等待,确保页面加载完成(也可以用显式等待,下面示例会演示)
time.sleep(3)
# ---------------------------
# 3. 定位并提取单页中的电影信息(名称、评分、简介链接等)
# ---------------------------
# 先定义一个列表,用来存储所有电影信息
movies = []
# 找到当前页面所有的"电影条目"(每个条目是 <div class="item">...)
movie_items = driver.find_elements(By.CSS_SELECTOR, ".item")
for item in movie_items:
# 电影名称:一般在 <span class="title"> 标签里
title_elem = item.find_element(By.CSS_SELECTOR, ".title")
title = title_elem.text
# 电影评分:一般在 <span class="rating_num"> 标签里
rating_elem = item.find_element(By.CSS_SELECTOR, ".rating_num")
rating = rating_elem.text
# 电影简介链接:一般在 <a> 标签里(也可以拿到 href 属性跳转到详情页)
link_elem = item.find_element(By.CSS_SELECTOR, "a")
link = link_elem.get_attribute("href")
# 把这一条电影信息存到字典里,再 append 到列表
movie_info = {
"title": title,
"rating": rating,
"link": link
}
movies.append(movie_info)
# ---------------------------
# 4. 翻页,继续爬取下一页(直到没有下一页为止)
# ---------------------------
while True:
try:
# 找到"下一页"按钮(一般是 <span class="next"> 里的 <a> 标签)
next_page_elem = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".next a"))
)
# 点击"下一页"
next_page_elem.click()
# 等待新页面加载(可以酌情调整等待时间,或者用显式等待特定元素)
time.sleep(3)
# 再次定位当前页面所有的电影条目
movie_items = driver.find_elements(By.CSS_SELECTOR, ".item")
for item in movie_items:
title_elem = item.find_element(By.CSS_SELECTOR, ".title")
title = title_elem.text
rating_elem = item.find_element(By.CSS_SELECTOR, ".rating_num")
rating = rating_elem.text
link_elem = item.find_element(By.CSS_SELECTOR, "a")
link = link_elem.get_attribute("href")
movie_info = {
"title": title,
"rating": rating,
"link": link
}
movies.append(movie_info)
except Exception as e:
# 如果找不到"下一页"按钮,或者点击失败,说明已经到最后一页了
print("已经爬取完所有页面,或者发生异常:", e)
break
# ---------------------------
# 5. 关闭浏览器,并打印/保存结果
# ---------------------------
driver.quit()
# 打印爬到的电影信息(前几条示例)
for idx, movie in enumerate(movies[:10], 1):
print(f"{idx}. {movie['title']} 评分: {movie['rating']} 链接: {movie['link']}")
# 如果想保存到文件,可以用 CSV、JSON 等方式,示例如下(保存为 movies_top250.json):
import json
with open("movies_top250.json", "w", encoding="utf-8") as f:
json.dump(movies, f, ensure_ascii=False, indent=4)
print("已将电影信息保存到 movies_top250.json")
movies
python
[{'title': '肖申克的救赎',
'rating': '9.7',
'link': 'https://movie.douban.com/subject/1292052/'},
{'title': '霸王别姬',
'rating': '9.6',
'link': 'https://movie.douban.com/subject/1291546/'},
{'title': '泰坦尼克号',
'rating': '9.5',
'link': 'https://movie.douban.com/subject/1292722/'},
{'title': '阿甘正传',
'rating': '9.5',
'link': 'https://movie.douban.com/subject/1292720/'},
{'title': '千与千寻',
'rating': '9.4',
'link': 'https://movie.douban.com/subject/1291561/'},
{'title': '美丽人生',
'rating': '9.5',
'link': 'https://movie.douban.com/subject/1292063/'},
{'title': '这个杀手不太冷',
'rating': '9.4',
'link': 'https://movie.douban.com/subject/1295644/'},
{'title': '星际穿越',
'rating': '9.4',
'link': 'https://movie.douban.com/subject/1889243/'},
{'title': '盗梦空间',
'rating': '9.4',
'link': 'https://movie.douban.com/subject/3541415/'},
{'title': '楚门的世界',
'rating': '9.4',
'link': 'https://movie.douban.com/subject/1292064/'},
{'title': '辛德勒的名单',
'rating': '9.5',
'link': 'https://movie.douban.com/subject/1295124/'},
{'title': '忠犬八公的故事',
'rating': '9.4',
'link': 'https://movie.douban.com/subject/3011091/'},
{'title': '海上钢琴师',
'rating': '9.3',
'link': 'https://movie.douban.com/subject/1292001/'},
{'title': '三傻大闹宝莱坞',
'rating': '9.2',
'link': 'https://movie.douban.com/subject/3793023/'},
{'title': '疯狂动物城',
'rating': '9.2',
'link': 'https://movie.douban.com/subject/25662329/'},
{'title': '放牛班的春天',
'rating': '9.3',
'link': 'https://movie.douban.com/subject/1291549/'},
{'title': '机器人总动员',
'rating': '9.3',
'link': 'https://movie.douban.com/subject/2131459/'},
{'title': '无间道',
'rating': '9.3',
'link': 'https://movie.douban.com/subject/1307914/'},
{'title': '控方证人',
'rating': '9.6',
'link': 'https://movie.douban.com/subject/1296141/'},
{'title': '大话西游之大圣娶亲',
'rating': '9.2',
'link': 'https://movie.douban.com/subject/1292213/'},
{'title': '熔炉',
'rating': '9.3',
'link': 'https://movie.douban.com/subject/5912992/'},
{'title': '触不可及',
'rating': '9.3',
'link': 'https://movie.douban.com/subject/6786002/'},
{'title': '寻梦环游记',
'rating': '9.1',
'link': 'https://movie.douban.com/subject/20495023/'},
{'title': '教父',
'rating': '9.3',
'link': 'https://movie.douban.com/subject/1291841/'},
{'title': '当幸福来敲门',
'rating': '9.1',
'link': 'https://movie.douban.com/subject/1849031/'}]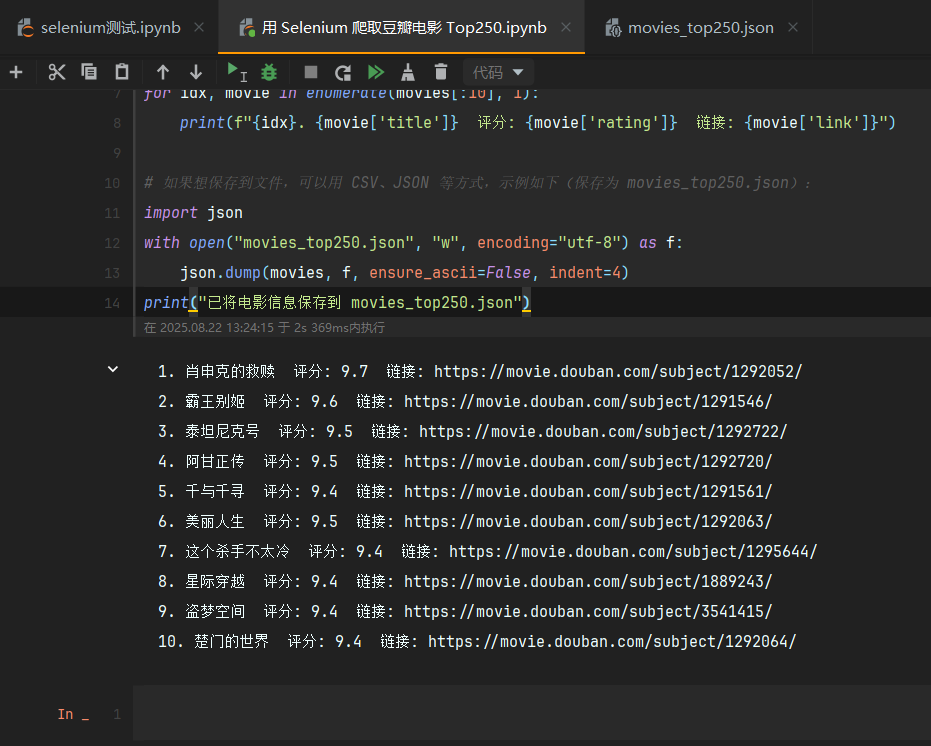
补充: Selenium 元素定位
通过 CSS 选择器定位 (find_element(By.CSS_SELECTOR, "css_selector"))与其他定位方式(如 By.ID、By.NAME、By.CLASS_NAME、By.XPATH 等)的主要区别在于:
✅ 一、语法与表达能力不同
| 定位方式 | 方法 | 语法示例 | 特点 |
|---|---|---|---|
| CSS 选择器 | find_element(By.CSS_SELECTOR, "css_selector") |
input#username, .btn-submit, div.container > input |
使用 CSS 语法,支持元素标签、ID、类、属性、伪类、层级关系等,语法简洁且功能强大,适合复杂选择。 |
| ID 定位 | find_element(By.ID, "id_value") |
username |
直接通过元素的 id 属性定位,最快速、最准确 ,但要求 id 必须唯一。语法:#id(对应 CSS 中的写法)。 |
| Name 定位 | find_element(By.NAME, "name_value") |
password |
通过 name 属性定位,常用于表单元素,但不一定唯一。Selenium 没有直接的 CSS 对应简写,但 CSS 中可通过 [name='value'] 实现。 |
| Class 定位 | find_element(By.CLASS_NAME, "class_value") |
submit-btn |
通过 class 属性定位,但 class 可能被多个元素共用,不唯一 。CSS 中对应 .class_value。 |
| Tag 名定位 | find_element(By.TAG_NAME, "tag_name") |
input |
通过 HTML 标签名定位,如 <input>、<div>,但页面中往往存在多个相同标签,不唯一,慎用。 |
| XPath 定位 | find_element(By.XPATH, "xpath_expression") |
//input[@id='username'] |
使用 XML 路径语言定位,功能最强大且复杂,支持逻辑运算、轴操作等,但 语法较繁琐,性能通常略低于 CSS。 |
✅ 二、性能差异(一般来说)
- CSS 选择器 和 ID 定位 通常具有 更快的查找速度,浏览器对它们的实现做了较多优化。
- XPath 虽然功能更强大(比如可以向上查找父节点、支持文本内容定位等),但在大多数浏览器中 执行速度稍慢于 CSS。
- Class Name 和 Tag Name 定位速度快,但精准度低,适合简单场景。
✅ 三、功能对比(CSS vs XPath 等)
| 功能 | CSS 选择器 | XPath | ID / Name / Class / Tag |
|---|---|---|---|
| 通过 id 定位 | ✅ (#id) |
✅ (//*[@id='id']) |
✅ (By.ID) 更简单直接 |
| 通过 class 定位 | ✅ (.class) |
✅ (//*[contains(@class, 'class')]) |
✅ (By.CLASS_NAME),但只支持单一 class |
| 通过属性定位 | ✅ ([attr=value]) |
✅ (//*[@attr='value']) |
❌ 仅限特定属性(如 id/name) |
| 组合条件(标签+属性) | ✅ (input#id.class) |
✅ (//input[@id='id' and @class='class']) |
❌ 不支持组合 |
| 层级关系(父子、兄弟) | ✅ (div > input, input + button) |
✅ (//div/input, //input/following-sibling::button) |
❌ 不支持 |
| 文本内容定位 | ❌ 不支持 | ✅ (//button[text()='Submit']) |
❌ 不支持 |
| 灵活性 / 强大程度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐(功能最全) | ⭐⭐(基本定位) |
✅ 表示支持,❌ 表示不支持或功能有限
✅ 四、适用场景推荐
✅ 推荐使用 CSS 选择器 的情况:
- 你需要 快速、简洁地定位元素 ,尤其是基于 id、class、标签和属性组合。
- 你希望 定位性能高,CSS 选择器通常比 XPath 快一点。
- 你要定位的元素有 明确的 class、id 或属性,并且结构不复杂。
🔹 示例:
# 通过 id 定位
driver.find_element(By.CSS_SELECTOR, "#username")
# 通过 class 定位
driver.find_element(By.CSS_SELECTOR, ".submit-btn")
# 通过属性定位
driver.find_element(By.CSS_SELECTOR, "input[type='text']")
# 组合定位:某个 div 下的 input
driver.find_element(By.CSS_SELECTOR, "div.form-group > input#username")✅ 推荐使用 XPath 的情况:
- 你需要根据 元素的文本内容 定位(如:
//button[text()='Submit']),CSS 不支持。 - 你需要 向上查找父节点 或使用 复杂的层级与轴操作。
- 元素的属性是 动态生成 ,但你可以用 相对路径和部分匹配 来定位。
🔹 示例:
# 通过文本内容定位按钮
driver.find_element(By.XPATH, "//button[text()='Submit']")
# 通过部分属性值定位
driver.find_element(By.XPATH, "//input[contains(@id, 'user')]")
# 向上或兄弟节点查找
driver.find_element(By.XPATH, "//input[@id='username']/following-sibling::button")✅ 推荐使用 ID / Name / Class / Tag 的情况:
- 定位非常简单,比如页面元素有 唯一 id ,那直接用
By.ID是最快最清晰的。 - 初学者可以从这些简单方式入手,之后再逐步学习 CSS/XPath。
🔹 示例:
driver.find_element(By.ID, "username") # 最推荐,唯一且快
driver.find_element(By.NAME, "password") # 表单常用
driver.find_element(By.CLASS_NAME, "btn") # 注意可能不唯一
driver.find_element(By.TAG_NAME, "input") # 一般不单独使用,因为不唯一✅ 总结对比表
| 方式 | 语法示例 | 是否唯一 | 速度 | 灵活性 | 支持文本定位 | 推荐度 |
|---|---|---|---|---|---|---|
| CSS 选择器 | find_element(By.CSS_SELECTOR, "#id") |
✅(视属性而定) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ❌ | ⭐⭐⭐⭐⭐ |
| XPath | find_element(By.XPATH, "//input[@id='id']") |
✅(视表达式而定) | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ | ⭐⭐⭐⭐ |
| ID | find_element(By.ID, "username") |
✅ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ❌ | ⭐⭐⭐⭐⭐ |
| Name | find_element(By.NAME, "password") |
❌ | ⭐⭐⭐ | ⭐⭐ | ❌ | ⭐⭐⭐ |
| Class Name | find_element(By.CLASS_NAME, "btn") |
❌ | ⭐⭐⭐ | ⭐⭐ | ❌ | ⭐⭐ |
| Tag Name | find_element(By.TAG_NAME, "input") |
❌ | ⭐⭐ | ⭐⭐ | ❌ | ⭐ |
✅ 结论
- 如果你追求速度和简洁,优先使用 ID 定位;其次是 CSS 选择器。
- CSS 选择器比 XPath 在大多数现代浏览器中更快,且语法更直观,适合大多数定位场景。
- XPath 更强大,尤其适合复杂逻辑、动态元素和文本定位,但性能稍逊,语法也相对复杂。
- Class、Name、Tag 等方式适合简单场景,但通常不够精准,建议结合其他属性使用。
🔧 最佳实践建议:
- 优先使用 ID 定位(最可靠、最快速)。
- 其次考虑 CSS 选择器(语法简洁,功能强大,性能好)。
- 需要文本定位或复杂 DOM 操作时,再使用 XPath。
- 避免依赖动态生成的 class/id,尽量用稳定的属性或相对路径。
- 结合显式等待(WebDriverWait)确保元素加载完成后再定位。