目录
[一、 业务场景与核心挑战深度剖析](#一、 业务场景与核心挑战深度剖析 "#%E4%B8%80%E3%80%81%20%E4%B8%9A%E5%8A%A1%E5%9C%BA%E6%99%AF%E4%B8%8E%E6%A0%B8%E5%BF%83%E6%8C%91%E6%88%98%E6%B7%B1%E5%BA%A6%E5%89%96%E6%9E%90")
[二、 总体架构设计](#二、 总体架构设计 "#%E4%BA%8C%E3%80%81%20%E6%80%BB%E4%BD%93%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1")
[1.1 架构示意图](#1.1 架构示意图 "#1.1%20%E6%9E%B6%E6%9E%84%E7%A4%BA%E6%84%8F%E5%9B%BE")
[1.2 核心组件职责](#1.2 核心组件职责 "#1.2%20%E6%A0%B8%E5%BF%83%E7%BB%84%E4%BB%B6%E8%81%8C%E8%B4%A3")
[三、 核心难题与设计:双写一致性保障](#三、 核心难题与设计:双写一致性保障 "#%E4%B8%89%E3%80%81%20%E6%A0%B8%E5%BF%83%E9%9A%BE%E9%A2%98%E4%B8%8E%E8%AE%BE%E8%AE%A1%EF%BC%9A%E5%8F%8C%E5%86%99%E4%B8%80%E8%87%B4%E6%80%A7%E4%BF%9D%E9%9A%9C")
[3.1 最终一致性方案:通过消费端幂等 + 消息重试](#3.1 最终一致性方案:通过消费端幂等 + 消息重试 "#3.1%20%E6%9C%80%E7%BB%88%E4%B8%80%E8%87%B4%E6%80%A7%E6%96%B9%E6%A1%88%EF%BC%9A%E9%80%9A%E8%BF%87%E6%B6%88%E8%B4%B9%E7%AB%AF%E5%B9%82%E7%AD%89%20%2B%20%E6%B6%88%E6%81%AF%E9%87%8D%E8%AF%95")
[3.2 代码片段示例 (SpringBoot)](#3.2 代码片段示例 (SpringBoot) "#3.2%20%E4%BB%A3%E7%A0%81%E7%89%87%E6%AE%B5%E7%A4%BA%E4%BE%8B%20(SpringBoot)")
[四、 核心难题与设计:百万级数据处理能力](#四、 核心难题与设计:百万级数据处理能力 "#%E5%9B%9B%E3%80%81%20%E6%A0%B8%E5%BF%83%E9%9A%BE%E9%A2%98%E4%B8%8E%E8%AE%BE%E8%AE%A1%EF%BC%9A%E7%99%BE%E4%B8%87%E7%BA%A7%E6%95%B0%E6%8D%AE%E5%A4%84%E7%90%86%E8%83%BD%E5%8A%9B")
[3.1 高性能写入设计](#3.1 高性能写入设计 "#3.1%20%E9%AB%98%E6%80%A7%E8%83%BD%E5%86%99%E5%85%A5%E8%AE%BE%E8%AE%A1")
[3.2 高性能查询设计](#3.2 高性能查询设计 "#3.2%20%E9%AB%98%E6%80%A7%E8%83%BD%E6%9F%A5%E8%AF%A2%E8%AE%BE%E8%AE%A1")
[五、 高可用性设计](#五、 高可用性设计 "#%E4%BA%94%E3%80%81%20%E9%AB%98%E5%8F%AF%E7%94%A8%E6%80%A7%E8%AE%BE%E8%AE%A1")
[processData方法:先DB,后Cache (Pipeline优化)](#processData方法:先DB,后Cache (Pipeline优化) "#processData%E6%96%B9%E6%B3%95%EF%BC%9A%E5%85%88DB%EF%BC%8C%E5%90%8ECache%20(Pipeline%E4%BC%98%E5%8C%96)")
[MongoDB Document设计:](#MongoDB Document设计: "#MongoDB%20Document%E8%AE%BE%E8%AE%A1%EF%BC%9A")
[八(附)、 性能优化策略](#八(附)、 性能优化策略 "#%E5%85%AB(%E9%99%84)%E3%80%81%20%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E7%AD%96%E7%95%A5")
[1. SpringBoot-Ingestion-Service (接入服务)](#1. SpringBoot-Ingestion-Service (接入服务) "#1.%20SpringBoot-Ingestion-Service%20(%E6%8E%A5%E5%85%A5%E6%9C%8D%E5%8A%A1)")
[2. SpringBoot-Process-Service (处理服务)](#2. SpringBoot-Process-Service (处理服务) "#2.%20SpringBoot-Process-Service%20(%E5%A4%84%E7%90%86%E6%9C%8D%E5%8A%A1)")
[3. MongoDB 数据模型与索引](#3. MongoDB 数据模型与索引 "#3.%20MongoDB%20%E6%95%B0%E6%8D%AE%E6%A8%A1%E5%9E%8B%E4%B8%8E%E7%B4%A2%E5%BC%95")
[4. 补偿Job代码 (CompensationJob.java)](#4. 补偿Job代码 (CompensationJob.java) "#4.%20%E8%A1%A5%E5%81%BFJob%E4%BB%A3%E7%A0%81%20(CompensationJob.java)")
[十、SpringBoot + RabbitMQ + MongoDB + Redis 半导体生产数据处理平台核心总结](#十、SpringBoot + RabbitMQ + MongoDB + Redis 半导体生产数据处理平台核心总结 "#%E5%8D%81%E3%80%81SpringBoot%20%2B%20RabbitMQ%20%2B%20MongoDB%20%2B%20Redis%20%E5%8D%8A%E5%AF%BC%E4%BD%93%E7%94%9F%E4%BA%A7%E6%95%B0%E6%8D%AE%E5%A4%84%E7%90%86%E5%B9%B3%E5%8F%B0%E6%A0%B8%E5%BF%83%E6%80%BB%E7%BB%93")
[一、 核心架构思想:分层解耦,各司其职](#一、 核心架构思想:分层解耦,各司其职 "#%E4%B8%80%E3%80%81%20%E6%A0%B8%E5%BF%83%E6%9E%B6%E6%9E%84%E6%80%9D%E6%83%B3%EF%BC%9A%E5%88%86%E5%B1%82%E8%A7%A3%E8%80%A6%EF%BC%8C%E5%90%84%E5%8F%B8%E5%85%B6%E8%81%8C")
[二、 核心难题解决方案:双写一致性保障](#二、 核心难题解决方案:双写一致性保障 "#%E4%BA%8C%E3%80%81%20%E6%A0%B8%E5%BF%83%E9%9A%BE%E9%A2%98%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88%EF%BC%9A%E5%8F%8C%E5%86%99%E4%B8%80%E8%87%B4%E6%80%A7%E4%BF%9D%E9%9A%9C")
[三、 百万级性能优化关键点](#三、 百万级性能优化关键点 "#%E4%B8%89%E3%80%81%20%E7%99%BE%E4%B8%87%E7%BA%A7%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E5%85%B3%E9%94%AE%E7%82%B9")
引言:半导体生产的数字化挑战
在现代半导体制造中,晶圆经过数百道工序,每台设备每秒都可能产生数以千计的数据点(温度、压力、良率等)。这些数据不仅是生产监控的依据,更是工艺优化、良率分析和故障预测的宝贵资产。构建一个能实时处理海量数据、保证数据一致性、并支持高并发查询的系统,是数字化工厂的核心基础。
本实践将深入探讨如何利用SpringBoot 作为快速开发框架,RabbitMQ 进行异步解耦与流量削峰,MongoDB 存储海量非结构化时序数据,并结合Redis 提供高速缓存与实时状态查询,最终打造一个稳定、高效的数据处理平台。
一、 业务场景与核心挑战深度剖析
1.1 半导体生产数据特性:
- 海量性 (Volume) :一台蚀刻机每秒可产生数KB到数MB的数据,全厂日数据量可达TB级。
- 高速性 (Velocity) :数据上报频率极高,要求接入层有百万级TPS的处理能力。
- 多样性 (Variety) :数据格式复杂,包括时序数据(传感器读数)、事件数据(报警、状态变更)、图片(AOI检测)等。
- 价值性 (Value) :数据是良率分析和工艺优化的核心,要求数据不丢失、不错乱 ,查询高效、准确。
1.2 核心挑战:
- 高并发写入:如何承接数据洪流,避免数据丢失或服务雪崩?
- 双写一致性 :如何保证MongoDB(权威数据源)和Redis(缓存)之间的数据最终一致?这是系统设计的重中之重。
- 海量数据存储与查询:如何设计MongoDB分片以支持水平扩展?如何设计Redis数据结构以支持复杂实时查询?
- 系统高可用:任何中间件或服务都不能成为单点故障。
二、 总体架构设计
我们的核心目标是:可靠地接收、处理和存储每秒可能产生的数十万条数据,并保证应用层在查询最新状态和历史数据时的绝对一致性。
1.1 架构示意图
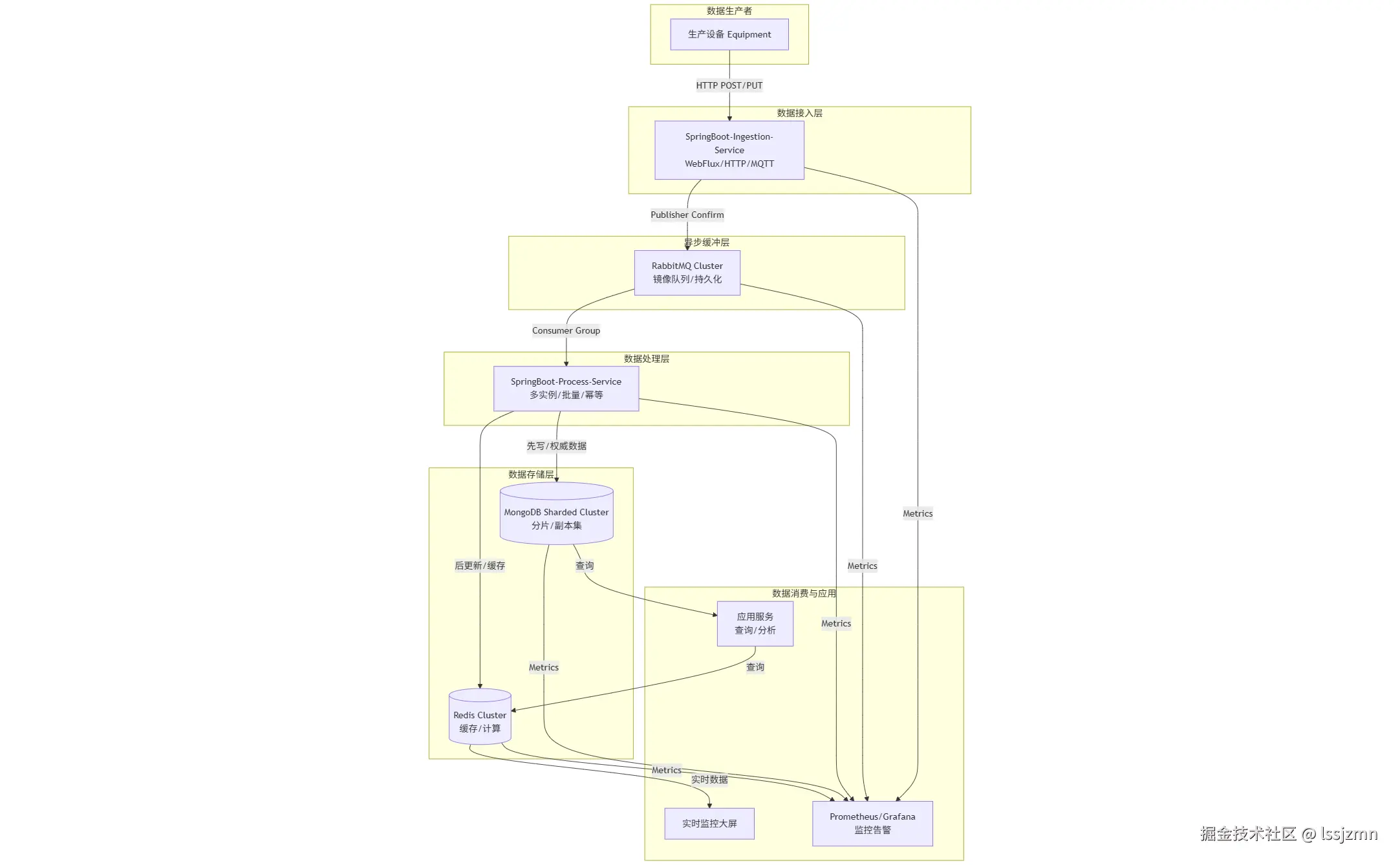 编辑
编辑
1.2 核心组件职责
-
SpringBoot接入服务 (Data-Ingestion-Service) :
- 提供高性能HTTP接口或MQTT客户端,接收生产设备上报的数据。
- 完成数据清洗、格式校验、基础格式化。
- 将合法消息异步发送至RabbitMQ,立即响应设备,确保高吞吐量。
-
RabbitMQ集群:
- 作为系统的异步缓冲与削峰填谷的核心组件。设置持久化、镜像队列,确保消息不丢失。
- 将数据生产与消费解耦,允许消费者动态扩展。
-
数据消费服务 (Data-Process-Service) :
- 核心中的核心,负责从RabbitMQ消费消息。
- 肩负双写重任:将数据持久化至MongoDB,同时更新Redis中的最新状态或聚合数据。
- 实现消费者组模式,多实例并行消费,提升处理能力。
-
MongoDB分片集群:
- 存储全量历史生产数据。利用其灵活的文档模型,轻松存储不同设备类型的异构数据。
- 通过分片(Sharding)机制,按设备ID或时间戳进行分片,实现容量的水平扩展和高并发写入。
-
Redis集群:
- 存储设备最新状态 、常用统计结果 、生产计数器等。
- 提供极低的查询延迟,支撑实时监控大屏、设备实时状态查询等场景。
- 使用Redis的原子操作和复杂数据结构,实现高效计算。
三、 核心难题与设计:双写一致性保障
双写(MongoDB和Redis)最关键的挑战是如何保证原子性:即两者要么都成功,要么都失败。在网络抖动或服务重启时,避免数据不一致。
3.1 最终一致性方案:通过消费端幂等 + 消息重试
我们不采用强一致性分布式事务(如2PC,性能低下),而是依靠消息队列的可靠性投递 和消费者的幂等设计来实现最终一致性。
步骤详解:
-
可靠消息生产 :接入服务发送消息到RabbitMQ时,开启
publisher-confirm机制,确保消息已持久化到Broker。 -
消费端幂等处理:
- 每条消息携带一个唯一业务ID(如
deviceId_timestamp或全局唯一ID)。 - 在处理消息前,消费者先检查Redis中是否存在该ID的处理记录(例如:
SETNX id_12345 "processing")。 - 如果已存在,说明是重复消息,直接确认消息并跳过处理。
- 每条消息携带一个唯一业务ID(如
-
双写执行顺序:
-
先写Redis?先写MongoDB? 这是一个关键选择。
-
我们的选择:先写MongoDB,再更新Redis。
- 原因:MongoDB是数据的权威来源(Source of Truth)。如果先写Redis成功但写MongoDB失败,会导致脏数据永久存在于缓存中,难以清理。反之,如果先写MongoDB成功但更新Redis失败,我们可以通过消息重试机制再次更新Redis,或者通过其他补偿机制(如从MongoDB回填Redis)来最终达到一致。
-
-
异常处理与重试:
- 将双写操作放在一个本地事务中(例如使用
@Transactional),但这只能保证数据库操作,无法保证Redis。 - 更佳实践:将"写MongoDB"和"更新Redis"视为一个整体业务逻辑。任何一步失败,则抛出异常。
- RabbitMQ消费者默认采用自动确认 模式。我们应改为手动确认 。只有业务处理成功,才
basicAck确认消息。如果抛出异常,则basicNack并让消息重新入队(或进入死信队列),等待重试。
- 将双写操作放在一个本地事务中(例如使用
-
补偿机制:
- 对于重试多次仍失败的消息,会进入死信队列。
- 启动一个后台任务监控死信队列,进行告警和人工干预。或者尝试解析失败原因,进行特定逻辑的补偿。
3.2 代码片段示例 (SpringBoot)
less
@Service
@Slf4j
public class DataProcessService {
@Autowired
private MongoTemplate mongoTemplate;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@RabbitListener(queues = "fab.data.queue")
@Transactional(rollbackFor = Exception.class) // 保证Mongo操作的事务性(需MongoDB 4.0+)
public void handleMessage(DeviceDataMessage message, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) {
String messageId = message.getMessageId();
// 1. 幂等检查
Boolean isAbsent = redisTemplate.opsForValue().setIfAbsent("MSG_ID:" + messageId, "PROCESSED", Duration.ofMinutes(10));
if (Boolean.FALSE.equals(isAbsent)) {
log.warn("Duplicate message received, id: {}", messageId);
channel.basicAck(tag, false); // 确认消息
return;
}
try {
// 2. 先写MongoDB
DeviceDataDocument doc = convertToDocument(message);
mongoTemplate.insert(doc);
// 3. 再更新Redis状态 (例如:更新设备最新读数)
String redisKey = "device:status:" + message.getDeviceId();
redisTemplate.opsForHash().put(redisKey, "latest_temperature", message.getTemperature());
redisTemplate.opsForHash().put(redisKey, "latest_timestamp", message.getTimestamp());
// ... 其他状态更新
// 4. 一切成功,确认消息
channel.basicAck(tag, false);
} catch (Exception e) {
log.error("Error processing message: " + messageId, e);
// 删除幂等键,允许重试(可选,取决于业务)
redisTemplate.delete("MSG_ID:" + messageId);
// 否认消息,并要求重新入队
channel.basicNack(tag, false, true);
// 抛出异常,让@Transactional回滚MongoDB操作
throw new RuntimeException(e);
}
}
}四、 核心难题与设计:百万级数据处理能力
3.1 高性能写入设计
-
RabbitMQ优化:
- 使用镜像队列,保证高可用。
- 发送端开启批量确认 和异步发送,提升吞吐量。
- 根据业务规划多个Exchange和Queue,实现业务隔离,避免相互影响。
-
消费者并行性:
- 在
@RabbitListener注解中配置concurrency参数,启动多个消费者线程。@RabbitListener(queues = "fab.data.queue", concurrency = "10-20") - 部署多个Data-Process-Service实例,形成消费者组,水平扩展消费能力。
- 在
-
MongoDB批量写入:
- 消费者在处理时,可以积累一批消息(如1000条或攒够5ms)后,使用
insertMany进行批量写入,大幅减少网络IO和数据库开销。
- 消费者在处理时,可以积累一批消息(如1000条或攒够5ms)后,使用
-
Redis管道(Pipeline) :
- 在更新Redis时,同样可以采用Pipeline技术,将多个命令一次性发送,减少RTT次数。
3.2 高性能查询设计
-
MongoDB查询优化:
- 为查询条件建立复合索引(如
{deviceId: 1, timestamp: -1})。 - 使用分片键作为常用查询条件,避免 scatter-gather 查询。
- 使用 Projection 只返回必要的字段。
- 对历史数据集合使用TTL索引,自动过期旧数据(如果需要)。
- 为查询条件建立复合索引(如
-
Redis物化视图:
- 不要只是简单缓存原始数据。利用Redis强大的数据结构预计算常用查询。
- 示例 :使用Sorted Set (ZSET) 维护设备产量日排行。每次处理完一条良品数据后,执行
ZINCRBY day:20231030:output 1 deviceId。 - 示例 :使用HyperLogLog (PFADD) 统计每日活跃设备数,占用极小空间。
- 示例 :使用Hash (HASH) 存储设备完整实时状态,一次查询即可获取所有属性。
五、 高可用性设计
-
无单点故障:
- 所有中间件均采用集群模式部署:RabbitMQ镜像集群、MongoDB分片副本集、Redis Cluster模式。任何单个节点宕机都不会影响整体服务。
-
服务本身无状态化:
- Data-Ingestion-Service 和Data-Process-Service本身不持有状态,可以轻松水平扩展和重启。通过Nginx等负载均衡器对外提供服务。
-
优雅降级与熔断:
- 使用 Resilience4j 或 Sentinel 实现熔断。如果MongoDB或Redis响应缓慢或不可用,消费者服务可以快速失败,并让消息重新排队,避免线程池被拖垮。同时,可以降级为只写MongoDB,后续再通过日志补偿Redis。
-
监控与告警:
- 全面监控:SpringBoot Actuator + Micrometer + Prometheus + Grafana。
- 监控关键指标:RabbitMQ队列堆积情况、MongoDB操作延迟、Redis内存使用率和命中率、JVM状态、服务实例健康度。一旦异常,立即告警。
六、核心组件选型与配置深度解析
1. SpringBoot-Ingestion-Service (接入服务)
-
职责:高可用、高性能的数据接收端。
-
关键配置与代码:
-
使用WebFlux替代传统MVC:基于Netty,应对高并发连接。
less// @PostMapping("/api/v1/data") 传统注解 @RestController @RequiredArgsConstructor public class DataIngestionController { private final RabbitTemplate rabbitTemplate; @PostMapping(value = "/api/v2/data", consumes = MediaType.APPLICATION_JSON_VALUE) public Mono<ResponseEntity<String>> ingestData(@RequestBody @Valid DeviceData data) { // 1. 基础校验 (使用JSR-303) // 2. 生成唯一消息ID,用于幂等 String messageId = generateMessageId(data.getDeviceId(), data.getTimestamp()); data.setMessageId(messageId); // 3. 异步发送至RabbitMQ,并配置publisher-confirm CorrelationData correlationData = new CorrelationData(messageId); return Mono.fromCallable(() -> { rabbitTemplate.convertAndSend("data.exchange", "data.routingkey", data, correlationData); return ResponseEntity.accepted().body("Accepted"); }).subscribeOn(Schedulers.boundedElastic()); // 防止阻塞Netty工作线程 } } -
RabbitTemplate配置:
yamlspring: rabbitmq: publisher-confirm-type: correlated # 开启publisher confirm publisher-returns: true template: mandatory: true
-
2. RabbitMQ集群
-
设计:采用镜像队列,保证队列高可用。
-
关键配置:
- 交换机:
data.exchange(Topic类型) - 队列:
data.persistence.queue(持久化) - 绑定:
data.exchange->data.persistence.queuewithdata.routingkey - 队列策略:
ha-mode: all,ha-sync-mode: automatic
- 交换机:
3. SpringBoot-Process-Service (处理服务) - 核心中的核心
-
职责:可靠消费,双写一致性保障。
-
关键设计:
-
多实例并行消费 :通过
concurrency配置。yamlspring: rabbitmq: listener: simple: acknowledge-mode: manual # 手动ACK concurrency: 10 # 最小消费者数 max-concurrency: 20 # 最大消费者数 prefetch: 50 # 每个消费者预取数量,平衡吞吐和公平 -
批量消费:进一步提升吞吐量(需生产者支持批量发送或消费者攒批)。
typescript@Bean public BatchRabbitListenerContainerFactory batchFactory() { BatchRabbitListenerContainerFactory factory = new BatchRabbitListenerContainerFactory(); factory.setBatchListener(true); factory.setBatchSize(1000); // 一批的数量 factory.setReceiveTimeout(3000L); // 等待超时时间 return factory; } @RabbitListener(queues = "data.persistence.queue", containerFactory = "batchFactory") public void handleBatch(List<Message> messages, Channel channel) { // 批量处理逻辑 }
-
七、双写一致性保障:终极解决方案与实践
我们采用 "先写库,再删缓存" 结合 "消息队列重试" 和 "最终一致性补偿" 的综合方案。
步骤详解与代码:
死信队列监控将重试多次失败的消息转入DLQ,并触发告警。定时补偿Job:针对Redis可能存在的脏数据,定时从MongoDB中拉取最新数据刷新Redis。
typescript
@Scheduled(cron = "0 0/5 * * * ?") // 每5分钟执行一次
public void compensativeRefreshRedis() {
// 1. 扫描MongoDB中最近更新的设备
// 2. 与Redis中的数据进行对比
// 3. 如果不一致,则以MongoDB为准,覆盖Redis
}幂等消费:
typescript
public void handleMessage(DeviceData message, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) {
String messageId = message.getMessageId();
// 使用Redis原子操作SETNX+NX+EX做幂等
String redisKey = "msg:id:" + messageId;
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(redisKey, "processing", Duration.ofMinutes(10));
if (Boolean.FALSE.equals(isNew)) {
log.info("Duplicate message, skipped: {}", messageId);
channel.basicAck(tag, false);
return;
}
try {
// 2. 执行业务逻辑(写MongoDB,更新Redis)
processData(message);
// 3. 成功,确认消息
channel.basicAck(tag, false);
// 可选:成功后可以删除或保留幂等键一段时间
// redisTemplate.delete(redisKey);
} catch (Exception e) {
log.error("Process failed, message will be retried: {}", messageId, e);
// 4. 失败,删除幂等键,允许下次重试
redisTemplate.delete(redisKey);
channel.basicNack(tag, false, true); // 重试
}
}processData方法:先DB,后Cache (Pipeline优化)
less
@Transactional(rollbackFor = Exception.class) // 开启MongoDB事务(4.0+)
public void processData(DeviceData message) {
// 1. 转换并插入MongoDB
DeviceDataDocument doc = convertToDocument(message);
mongoTemplate.insert(doc);
// 2. 更新Redis状态 (使用Pipeline减少RTT)
String statusKey = "device:status:" + message.getDeviceId();
String statsKey = "device:stats:" + message.getDeviceId();
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
// 更新Hash结构的状态
connection.hashCommands().hSet(statusKey.getBytes(), "temp".getBytes(), String.valueOf(message.getTemp()).getBytes());
connection.hashCommands().hSet(statusKey.getBytes(), "timestamp".getBytes(), String.valueOf(message.getTimestamp()).getBytes());
// 更新Sorted Set用于排行榜查询
connection.zSetCommands().zAdd("device:output:rank".getBytes(), message.getOutput(), message.getDeviceId().getBytes());
return null;
});
}最终补偿机制
八、MongoDB与Redis数据结构设计示例
MongoDB Document设计:
css
// collection: device_data_${deviceId_shard}
{
"_id": ObjectId("..."),
"messageId": "EQP001_1621234567890", // 唯一标识,可建唯一索引
"deviceId": "EQP001",
"timestamp": ISODate("2021-05-17T08:16:07.890Z"),
"metrics": {
"temperature": 23.4,
"pressure": 101.3,
"voltage": 12.5
},
"status": "RUNNING",
"recipe": "BKM-001",
"lotId": "LOT123456"
}
// 索引:{deviceId: 1, timestamp: -1}Redis数据结构设计:
- 实时状态 (String/Hash) :
HSET device:status:EQP001 temperature 23.4 pressure 101.3 timestamp 1621234567890 status "RUNNING" - 当日产量排行 (Sorted Set) :
ZINCRBY rank:output:20240517 1 EQP001 - 设备最新报警 (List) :
LPUSH device:alarm:EQP001 "Over Temperature at 1621234567890"<RIM device:alarm:EQP001 0 9// 只保留10条
八(附)、 性能优化策略
-
MongoDB:
- 分片策略 :以
deviceId作为分片键,保证同一设备的数据落在同一分片上,利于查询。 - 写入优化 :启用
writeConcern: majority和readConcern: majority保证读写一致性,但可根据业务调整(如writeConcern: w1)以提升写入速度。 - 读优化:使用覆盖索引,减少内存交换。
- 分片策略 :以
-
Redis:
- 内存优化:使用Hash等紧凑数据结构,避免使用大量Key。
- Pipeline:在所有需要连续执行多个命令的场景(如初始化缓存)中大量使用。
- 集群模式:必须使用Redis Cluster,数据分片存储,实现容量和性能的线性扩展。
-
JVM与GC调优:
- 针对高并发服务,建议使用G1GC或ZGC。
- 关键参数:
-Xms4g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=200
九、详细代码放出
1. SpringBoot-Ingestion-Service (接入服务)
application.yml 关键配置
yaml
server:
port: 8080
spring:
rabbitmq:
host: rabbitmq-cluster
port: 5672
username: admin
password: strongpassword
publisher-confirm-type: correlated # 开启publisher confirm
publisher-returns: true
template:
mandatory: true
data:
mongodb:
uri: mongodb://user:pass@mongos-router:27017/fab-database?replicaSet=rs0
redis:
cluster:
nodes:
- redis-node-1:6379
- redis-node-2:6379
- redis-node-3:6379
max-redirects: 3
lettuce:
pool:
max-active: 16
max-wait: -1
logging:
level:
org.springframework.web: DEBUG
com.example.ingestion: DEBUG核心Java代码 (DataIngestionController.java)
less
@RestController
@RequiredArgsConstructor
public class DataIngestionController {
private final RabbitTemplate rabbitTemplate;
@PostMapping(value = "/api/v1/data", consumes = MediaType.APPLICATION_JSON_VALUE)
public Mono<ResponseEntity<String>> ingestData(@RequestBody @Valid DeviceData data, ServerWebExchange exchange) {
// 1. 生成唯一消息ID (设备ID+时间戳+随机数)
String messageId = generateMessageId(data.getDeviceId(), data.getTimestamp());
data.setMessageId(messageId);
// 2. 异步发送到RabbitMQ,避免阻塞Netty工作线程
return Mono.fromCallable(() -> {
// 设置消息的correlationData,用于confirm回调
CorrelationData correlationData = new CorrelationData(messageId);
rabbitTemplate.convertAndSend("data.exchange", "data.routing.key", data, correlationData);
return ResponseEntity.accepted().body("{"status": "accepted", "messageId": "" + messageId + ""}");
}).subscribeOn(Schedulers.boundedElastic());
}
// RabbitTemplate的ConfirmCallback配置 (在@Configuration类中)
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate template = new RabbitTemplate(connectionFactory);
template.setMandatory(true);
template.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
log.info("Message with ID {} confirmed by broker.", correlationData.getId());
} else {
log.error("Message with ID {} failed to reach broker. Cause: {}", correlationData.getId(), cause);
// 此处可加入重发或告警逻辑
}
});
return template;
}
}2. SpringBoot-Process-Service (处理服务)
application.yml 关键配置
yaml
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual # 手动ACK
concurrency: 10
max-concurrency: 20
prefetch: 100
direct:
retry:
enabled: true
max-attempts: 3
initial-interval: 2000ms
data:
mongodb:
uri: mongodb://user:pass@mongos-router:27017/fab-database?replicaSet=rs0&w=majority&readPreference=secondaryPreferred # 读写分离配置
auto-index-creation: true
redis:
cluster:
nodes:
- redis-node-1:6379
- redis-node-2:6379
- redis-node-3:6379
max-redirects: 3
# 批量消费配置
batch:
rabbit:
listener:
enabled: true
batch-size: 500
receive-timeout: 5000核心Java代码 (RabbitMQConsumer.java)
java
@Component
@Slf4j
@RequiredArgsConstructor
public class RabbitMQConsumer {
private final MongoTemplate mongoTemplate;
private final RedisTemplate<String, Object> redisTemplate;
@RabbitListener(queues = "data.persistence.queue", containerFactory = "batchContainerFactory")
public void handleBatch(List<Message> messages, Channel channel) throws IOException {
for (int i = 0; i < messages.size(); i++) {
Message message = messages.get(i);
DeviceData data = convertMessage(message);
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
processMessage(data, channel, deliveryTag);
// 批量处理中,对最后一条消息进行批量ACK
if (i == messages.size() - 1) {
channel.basicAck(deliveryTag, true); // multiple=true,确认所有直到该deliveryTag的消息
}
} catch (Exception e) {
log.error("Process failed for messageId: {}", data.getMessageId(), e);
channel.basicNack(deliveryTag, true, true); // 重试本批所有消息(需谨慎)或记录失败位置
break;
}
}
}
private void processMessage(DeviceData data, Channel channel, long deliveryTag) throws Exception {
String messageId = data.getMessageId();
String redisLockKey = "msg:id:" + messageId;
// 1. 幂等检查 - Redis原子操作
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(redisLockKey, "processing", Duration.ofMinutes(10));
if (Boolean.FALSE.equals(isNew)) {
log.info("Duplicate message detected, skipped: {}", messageId);
return; // 直接跳过,等待批量ACK
}
try {
// 2. 核心业务处理
processData(data);
// 3. 处理成功,可删除或保留幂等键
// redisTemplate.delete(redisLockKey);
} catch (Exception e) {
// 4. 处理失败,删除幂等键,允许重试
redisTemplate.delete(redisLockKey);
throw e;
}
}
@Transactional(rollbackFor = Exception.class) // 开启MongoDB事务
public void processData(DeviceData data) {
// 1. 转换并插入MongoDB
DeviceDataDocument doc = convertToDocument(data);
mongoTemplate.insert(doc);
// 2. 使用Pipeline批量更新Redis
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
String statusKey = "device:status:" + data.getDeviceId();
// 更新设备状态Hash
connection.hashCommands().hSet(
statusKey.getBytes(StandardCharsets.UTF_8),
"lastUpdate".getBytes(StandardCharsets.UTF_8),
String.valueOf(System.currentTimeMillis()).getBytes(StandardCharsets.UTF_8)
);
connection.hashCommands().hSet(
statusKey.getBytes(StandardCharsets.UTF_8),
"temperature".getBytes(StandardCharsets.UTF_8),
String.valueOf(data.getTemperature()).getBytes(StandardCharsets.UTF_8)
);
// 更新全局设备最新数据Sorted Set (按时间戳排序)
connection.zSetCommands().zAdd(
"global:device:updates".getBytes(StandardCharsets.UTF_8),
data.getTimestamp(),
data.getDeviceId().getBytes(StandardCharsets.UTF_8)
);
return null;
});
}
}3. MongoDB 数据模型与索引
Document 类 (DeviceDataDocument.java)
less
@Document(collection = "device_data")
@CompoundIndex(name = "device_timestamp_idx", def = "{'deviceId': 1, 'timestamp': -1}")
@Sharded(shardKey = {"deviceId", "timestamp"}) // 分片键注解(具体分片需在MongoDB中配置)
@Data
public class DeviceDataDocument {
@Id
private String id;
private String messageId; // 业务唯一ID,可单独建唯一索引
private String deviceId;
private Instant timestamp;
private Map<String, Object> metrics; // 灵活存储各种指标
private String status;
private String recipeId;
private String lotId;
// TTL索引,自动过期旧数据(如果需要)
@Indexed(expireAfterSeconds = 2592000) // 30天后过期
private Instant createdAt;
}4. 补偿Job代码 (CompensationJob.java)
less
@Component
@Slf4j
@RequiredArgsConstructor
public class CompensationJob {
private final MongoTemplate mongoTemplate;
private final RedisTemplate<String, Object> redisTemplate;
@Scheduled(cron = "0 0 2 * * ?") // 每天凌晨2点执行
public void refreshRedisFromMongo() {
log.info("Starting compensation job: Refreshing Redis from MongoDB");
// 查找过去一小时内所有活跃设备
Instant oneHourAgo = Instant.now().minus(1, ChronoUnit.HOURS);
Query query = new Query(Criteria.where("timestamp").gte(oneHourAgo));
query.fields().include("deviceId").include("metrics").include("timestamp");
try (MongoCursor<DeviceDataDocument> cursor = mongoTemplate.stream(query, DeviceDataDocument.class)) {
cursor.forEachRemaining(doc -> {
String deviceId = doc.getDeviceId();
String statusKey = "device:status:" + deviceId;
// 获取Redis中该设备的最新时间戳
Object redisTimestamp = redisTemplate.opsForHash().get(statusKey, "lastUpdate");
long redisTime = redisTimestamp != null ? Long.parseLong(redisTimestamp.toString()) : 0L;
// 如果MongoDB的数据更新,则以MongoDB为准
if (doc.getTimestamp().toEpochMilli() > redisTime) {
log.debug("Refreshing data for device: {}", deviceId);
redisTemplate.opsForHash().putAll(statusKey, Map.of(
"temperature", String.valueOf(doc.getMetrics().get("temperature")),
"lastUpdate", String.valueOf(doc.getTimestamp().toEpochMilli())
));
}
});
}
log.info("Compensation job finished.");
}
}九(附)、核心总结
- 架构清晰:通过五大层次(接入、缓冲、处理、存储、应用)实现职责分离与水平扩展。
- 一致性保障 :通过 "幂等键 + 先DB后Cache + 重试 + 定时补偿" 四位一体的组合拳,稳健地保障最终一致性。
- 性能极致:在每一层采用最佳实践(WebFlux、批量、Pipeline、分片、索引)确保百万级数据处理能力。
- 高可用:所有组件均以集群模式部署,无单点故障,并通过监控告警体系实时感知系统状态。
十、SpringBoot + RabbitMQ + MongoDB + Redis 半导体生产数据处理平台核心总结
一、 核心架构思想:分层解耦,各司其职
-
SpringBoot-Ingestion-Service (接入层) :
- 职责 :利用WebFlux实现高性能非阻塞接入,快速接收设备数据,完成基本校验。
- 关键动作 :立即异步化,将消息送入RabbitMQ 集群,并通过
publisher-confirm机制确保消息可靠抵达消息队列,实现流量削峰,响应设备。
-
RabbitMQ (异步缓冲层) :
- 职责 :系统的稳定器 和解耦器 。采用镜像队列确保高可用,承载流量洪峰,为下游处理提供缓冲。
-
SpringBoot-Process-Service (处理层) :
- 职责 :系统的核心大脑 。从RabbitMQ并行消费消息,肩负保障MongoDB 与Redis双写一致性的重任。
- 关键设计 :多实例部署,配置
concurrency实现并发消费,支持批量处理以提升吞吐量。
-
MongoDB (权威数据源) :
- 职责 :存储全量历史数据。采用分片集群 架构,以
deviceId等作为分片键,实现容量的水平扩展,应对海量数据存储。
- 职责 :存储全量历史数据。采用分片集群 架构,以
-
Redis (高速缓存与计算层) :
- 职责 :存储热数据(如设备最新状态、排行榜、计数器)。提供微秒级查询,支撑实时监控大屏等场景。采用Cluster模式实现高可用与扩展性。
二、 核心难题解决方案:双写一致性保障
方案:幂等性 + 可靠消息 + 最终一致性补偿
-
幂等消费:
- 每条消息携带唯一
messageId。 - 处理前,使用Redis的
SETNX key value NX EX指令设置锁,Key为msg:id:{messageId}。若已存在,视为重复消息,直接ACK跳过。这是整个一致性流程的基石。
- 每条消息携带唯一
-
严谨的双写顺序:
- 坚决采用"先写MongoDB,再更新Redis" 。
- 原因:MongoDB是真相之源。若先写Redis成功但写MongoDB失败,会导致难以清理的脏缓存。反之,若写MongoDB成功但更新Redis失败,可以通过消息重试机制最终保证缓存更新。
-
异常处理与重试:
- 消费者采用手动ACK模式。
- 只有业务处理完全成功(Mongo和Redis都写完),才
basicAck确认消息。 - 若过程中任何一步失败,则抛出异常,执行
basicNack并要求消息重新入队重试。在捕获异常后,必须删除之前设置的幂等键,允许下一次重试能再次执行。
-
最终补偿机制:
- 对于重试多次失败进入死信队列的消息,进行监控告警。
- 设立定时补偿任务,定期从MongoDB中拉取最新数据,与Redis中的数据进行比对并刷新,确保最终一致。
三、 百万级性能优化关键点
-
写入优化:
- RabbitMQ :生产者开启
publisher-confirm,消费者开启批量模式 (BatchListener)。 - MongoDB :使用
insertMany进行批量插入。 - Redis :使用
Pipeline一次性发送多个命令,极大减少网络往返开销。
- RabbitMQ :生产者开启
-
查询优化:
- MongoDB :精心设计复合索引(如
{deviceId: 1, timestamp: -1}),使用投影减少返回数据量。 - Redis :充分利用丰富数据结构(如ZSET 做排行榜、HASH 存对象、HyperLogLog做基数统计),进行数据预计算和物化视图存储,避免实时查询数据库。
- MongoDB :精心设计复合索引(如
-
资源与部署:
- 所有中间件(RabbitMQ, MongoDB, Redis)均以集群模式部署,消除单点故障。
- 应用服务(Ingestion, Process)无状态化,便于水平扩展。
- JVM层面针对高并发场景进行GC调优(如使用G1GC并设定目标暂停时间)。
最后,本架构成功的关键在于:通过消息队列解耦并削峰,通过幂等性设计保障消息处理可靠性,通过"先库后缓"的顺序和补偿机制捍卫最终一致性,再通过批量、Pipeline、分片、索引等技术手段在每一个环节极致优化性能。这是一个经过实践检验的、可支撑半导体工厂海量数据场景的高性能、高可用、高并发解决方案。