总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2506.22316#page=6.73
https://www.doubao.com/chat/17588734282537986
文章目录
- 评估作为评判者的大型语言模型(LLM-as-a-Judge)中的评分偏差
-
- 摘要
- [1 引言](#1 引言)
- [2 相关工作](#2 相关工作)
- [6 结论](#6 结论)
评估作为评判者的大型语言模型(LLM-as-a-Judge)中的评分偏差
摘要
大型语言模型(LLMs)的卓越性能催生了"LLM-as-a-Judge"这一应用模式,即利用大型语言模型作为复杂任务的评估者。此外,该模式已在自然语言处理(NLP)、偏好学习以及各类特定领域中得到广泛应用。然而,LLM-as-a-Judge中存在多种偏差,这些偏差会对评估的公平性和可靠性产生不利影响。目前,关于评估或缓解LLM-as-a-Judge中偏差的研究主要集中在基于比较的评估上,而对基于评分的评估中偏差的系统性研究仍较为有限。因此,我们将LLM-as-a-Judge中的评分偏差定义为:当评分评判模型受到与偏差相关的干扰时,其给出的评分产生差异;同时,我们提出了一个设计完善的框架,用于全面评估评分偏差。我们通过数据合成对现有的LLM-as-a-Judge基准数据集进行扩充,构建了我们的评估数据集,并设计了多维度的评估指标。实验结果表明,现有评判模型的评分稳定性会受到评分偏差的干扰。进一步的探索性实验和讨论,为评分提示模板的设计以及从评分标准、评分标识和参考答案选择等方面缓解评分偏差提供了宝贵的见解。
1 引言
大型语言模型(LLMs)凭借卓越的性能,已被广泛应用于自然语言生成(NLG)任务,例如文本摘要(Zhang等人,2024)、问答(Robinson、Rytting和Wingate,2022)以及特定领域对话(Wang等人,2024a;Singhal等人,2025)。在这些任务中,需要对模型生成的响应从质量、真实性、指令遵循度等多个方面进行细粒度评估,从而为模型改进提供有价值的参考。传统的统计型自然语言生成评估指标,如BLEU(Papineni等人,2002)和ROUGE(Lin,2004),通过生成文本与标准答案之间的n元语法重叠度来评估生成文本。上述方法存在两个主要局限性:(1)它们仅关注生成文本与标准答案之间的相似性,无法量化文本本身的内在属性,如写作风格、真实性和教育价值;(2)所得指标缺乏可解释性,难以对模型升级提供指导。目前迫切需要针对自然语言生成任务和大型语言模型应用,设计细粒度、多维度且具有可解释性的评估指标与方法。
大型语言模型在指令理解和响应生成方面具备出色能力,能够提供多种形式的评估结果,如评分、比较和排序。此外,它们还可以沿着指定维度进行评估,并为评估结果生成评论,从而提高评估的可解释性。这类被称为"LLM-as-a-Judge"的研究方向(Gu等人,2024;Li等人,2024a),近年来已成为研究热点。
鲁棒性是确保LLM评估公平性和可靠性的关键因素,这要求在相同的评估标准下,LLM评判者对同一评估对象应给出一致的评估结果。然而,近期研究(Park等人,2024)表明,LLM评判者会受到多种偏差的影响,这些偏差会破坏其评估的自一致性。已有多项研究致力于识别导致评估结果偏移的偏差类型。(Wang等人,2024b)发现,通过改变候选响应在上下文当中的位置,很容易干扰对该响应的评估结果。(Wataoka、Takahashi和Ri,2024)对LLM-as-a-Judge中的自我偏好偏差进行了测量,这种偏差指的是LLM评判者倾向于高估自身生成结果的质量。(Wei等人,2024)将长度偏差视为LLM评判者对较长响应或较短响应存在偏好的现象。
尽管现有研究已对LLM-as-a-Judge中的多种偏差进行了系统性探究,但仍有一些亟待解决的紧迫问题。首先,尽管部分研究(Wang等人,2024b;Ye等人,2024a)已针对基于评分的LLM评判者中的位置偏差、优化感知偏差等偏差类型展开研究,但现有多数研究仍聚焦于基于比较的LLM评判者中的偏差。现有研究(Ye等人,2024a)试图探究评分任务中的特定偏差,如自我提升偏差和优化感知偏差,然而,针对基于评分的LLM-as-a-Judge中偏差的全面研究仍较为缺乏。其次,现有研究中定义的偏差主要与评估对象的属性或呈现形式相关,如位置、长度和响应模型。但基于LLM的评判者自身提示中固有的变化,也可能影响评估的自一致性,而当前研究对此缺乏系统性探究。
为解决上述问题,我们提出了评分偏差的概念,将其定义为:在评分提示受到干扰的情况下,LLM-as-a-Judge给出的评分发生偏移。在本研究中,我们提出了三种类型的评分偏差:评分标准顺序偏差、评分标识偏差和参考答案评分偏差,并设计了一个框架来系统性评估这些偏差。我们选取了四个现有的LLM-as-a-Judge基准数据集作为评估数据集,并制定了一系列指标来量化LLM评判者对评分偏差的鲁棒性。我们的主要贡献可总结如下:
- 我们首次对基于评分的LLM-as-a-Judge中的偏差进行系统性评估,定义了三种评分偏差类型和五种干扰方法。
- 通过自动数据合成,我们在无需人工成本的情况下,将现有的LLM-as-a-Judge基准数据集扩充为我们的评估数据集。此外,我们通过全面设计评估指标,从多个角度对评分偏差进行评估。
- 全面的实验和深入的分析表明,评分偏差会影响现有各类评判模型的鲁棒性和可靠性。我们还为评分提示的设计以及评分偏差的缓解提供了有价值的建议。
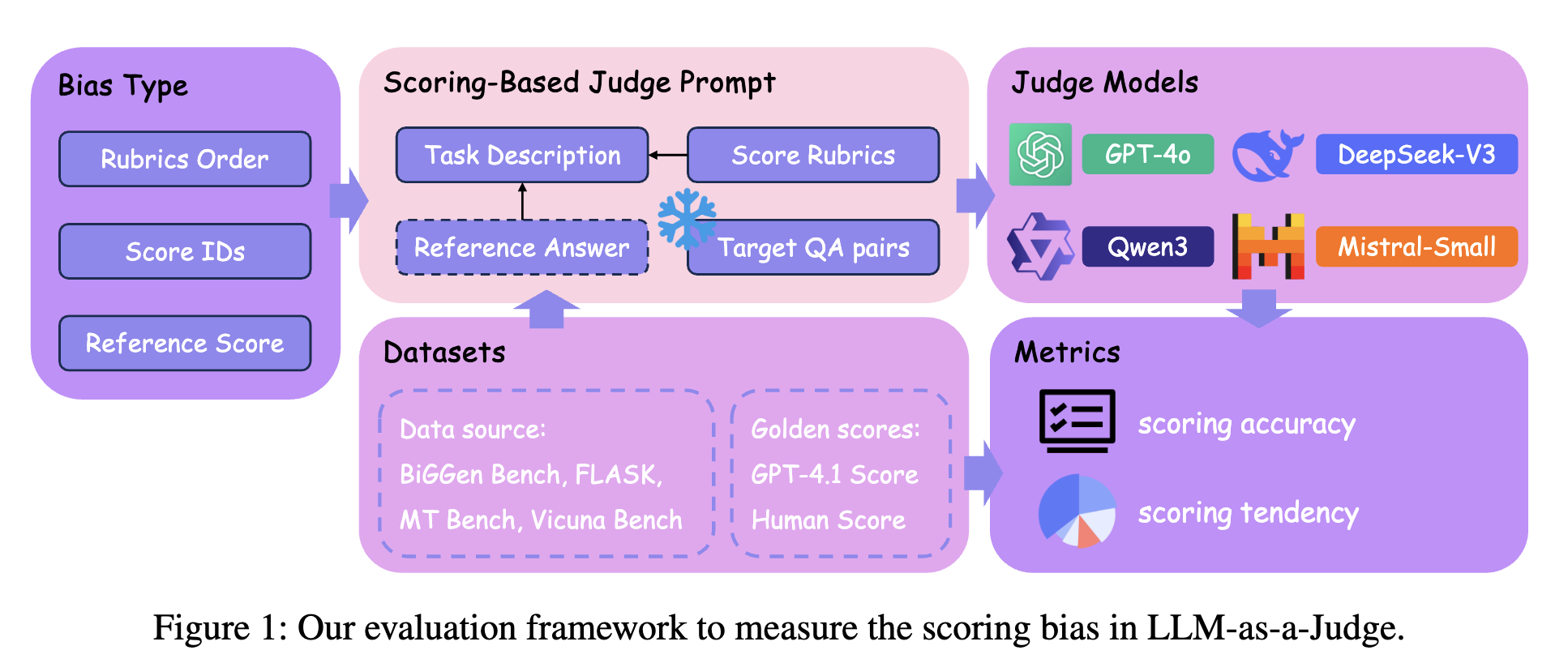
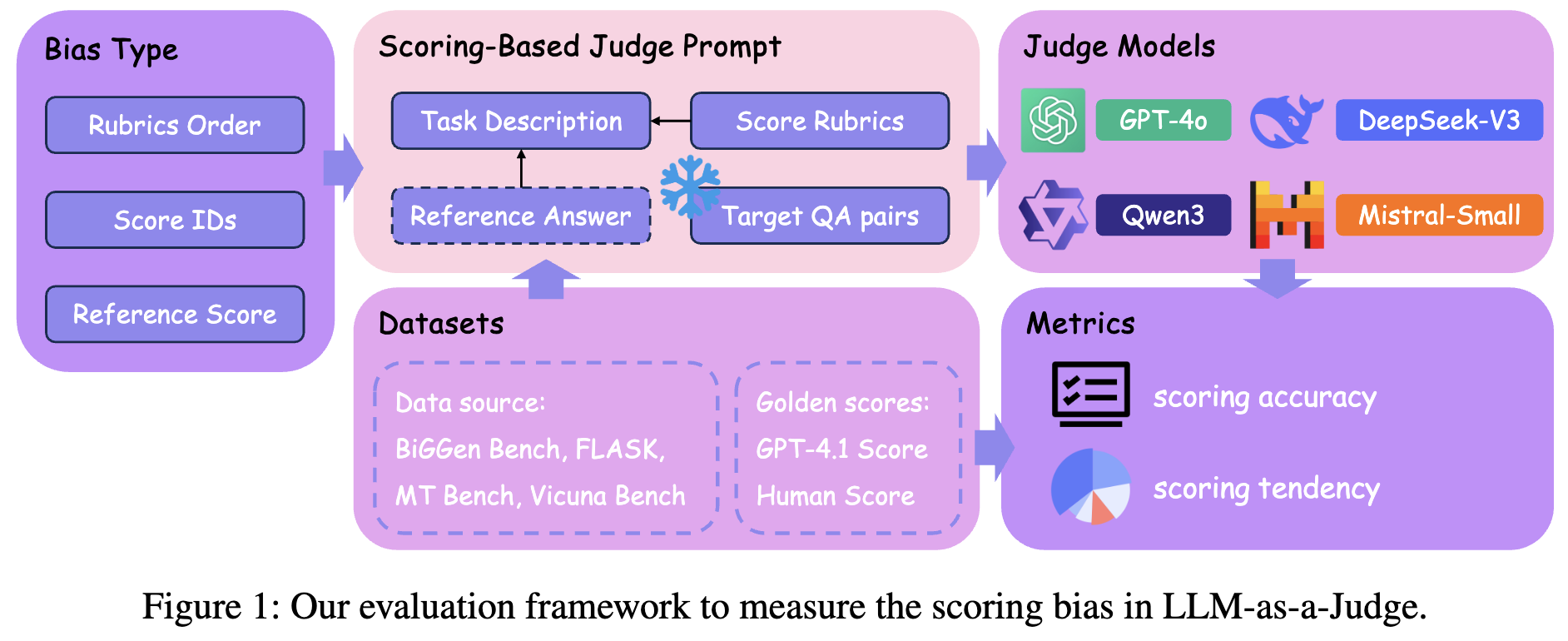
图1:用于衡量LLM-as-a-Judge中评分偏差的评估框架。

图2:源自(Kim等人,2024c)的包含四个组成部分的评分提示模板。红色文本代表可能受到干扰的组成部分。
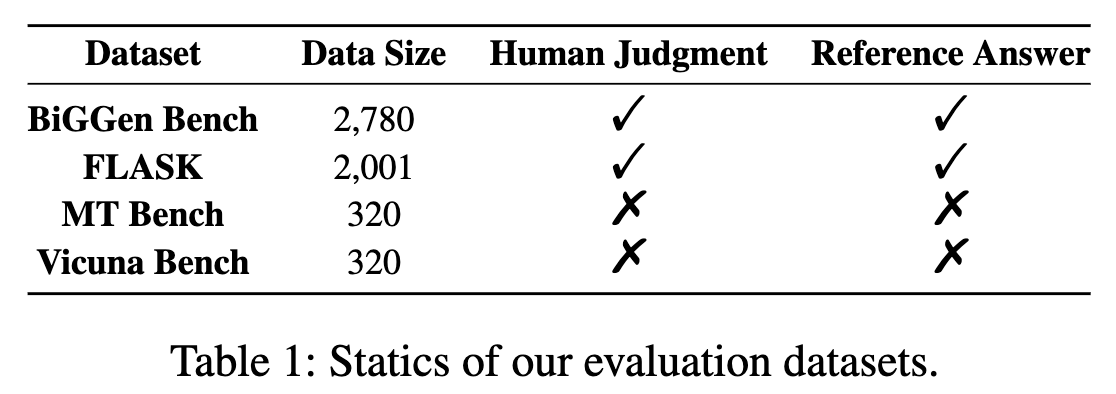
表1:我们评估数据集的统计信息。
2 相关工作
LLM-as-a-Judge(Gu等人,2024)将LLM-as-a-Judge定义为:在给定输入数据和上下文的情况下,大型语言模型(LLM)以任意形式生成评估结果的任务。LLM评估的常见形式包括分数生成(Gao等人,2023)、成对比较(Qin等人,2024)、排序(Li、Patel和Du,2023)、多项选择(Li等人,2024b)以及评论生成(Ke等人,2024)。
LLM-as-a-Judge的改进策略包括:精心设计评估提示(Liu等人,2023)、提升LLM的能力(如微调,Wang等人,2024c)、构建多LLM协作流程(如反馈机制,Xu等人,2023),以及优化输出策略(如多输出集成,Sottana等人,2023)。LLM-as-a-Judge的性能通常通过衡量其与人工标注者或高级LLM评估结果一致性的指标来评估,例如一致性(Thakur等人,2024)、科恩卡帕系数(Cohen's Kappa)和斯皮尔曼相关系数(Spearman's correlation,Bai等人,2023)。
LLM-as-a-Judge已广泛应用于评估(Lin和Chen,2023)、对齐(Bai等人,2022)、检索(Sun等人,2023)、推理(Gao等人,2024a)以及其他特定领域(Ryu等人,2023;Babaei和Giudici,2024)。然而,LLM-as-a-Judge面临偏差和脆弱性方面的挑战,这些挑战会严重影响LLM评判者的公平性和可靠性(Li等人,2024a)。
LLM-as-a-Judge中的偏差
(Ye等人,2024a)将LLM评判者的提示定义为三个组成部分:系统指令、问题和响应。基于此,他们将LLM-as-a-Judge中的偏差定义为:当系统指令或响应受到与偏差相关的修改时,评估结果产生差异。
LLM-as-a-Judge中常见的偏差类型包括位置偏差、长度偏差、自我提升偏差等。这些偏差通常被纳入现有LLM-as-a-Judge基准数据集的评估范围(Zheng等人,2023;Wei等人,2024)。目前,偏差类型仍是研究的焦点,已有多个基准数据集被提出用于评估LLM-as-a-Judge中的偏差。
OffsetBias(Park等人,2024)指出了LLM-as-a-Judge中的六种偏差类型,包括长度偏差、具体性偏差、空参考偏差等。CALM(Ye等人,2024a)对LLM评判者中的12种偏差进行了量化和分析。然而,现有研究中定义的偏差主要集中在比较型评估任务,缺乏针对基于评分的评估任务中偏差的系统性研究和定义。
与对抗性攻击研究类似,LLM-as-a-Judge中偏差的评估指标通常基于:受偏差相关修改后的评估结果与原始评估结果的一致性,或与标准答案的对齐程度。部分研究致力于缓解LLM-as-a-Judge中的偏差,旨在开发更具鲁棒性的LLM评判者。(Liu等人,2024c)提出了成对偏好搜索(Pairwise-Preference Search,PAIRS)以缓解LLM评估者中的偏差。(Wang等人,2024b)提出了三种校准LLM-as-a-Judge中位置偏差的方法,包括多证据校准、平衡位置校准和人机协同校准。我们关于评分偏差的评估结果,将为未来缓解评判模型中的评分偏差、提升基于评分的评估鲁棒性的研究提供参考。
6 结论
在本研究中,我们提出了LLM-as-a-Judge中的评分偏差概念,将其定义为:当评判模型受到干扰时,评分结果发生偏移。我们设计了一个评估框架,其中包含三种评分偏差类型:评分标准顺序偏差、评分标识偏差和参考答案评分偏差。
我们选取了四个LLM-as-a-Judge基准数据集,并通过数据合成对其进行扩充,构建了我们的评估数据集。我们的评估指标能够量化评分偏差对评判模型评分准确性和评分倾向的影响。实验结果清晰表明,评分偏差会影响现有基于评分的评判模型的鲁棒性和可靠性。具有不同能力、规模和架构的评判模型,对各类评分偏差的敏感度存在差异。
进一步的探索性实验和讨论揭示了若干值得关注的现象。总而言之,我们的研究为评估和提升LLM-as-a-Judge的评分可靠性提供了详细依据和有价值的建议。