代码见:登录 - Gitee.com
回顾上一篇顺序表的内容数据结构:顺序表-CSDN博客,我们发现:
1.对于中间/头部的插入删除,时间复杂度为O(N)。
2.增容需要申请新空间,拷贝数据,释放旧空间,会有不小的消耗。
3.增容一般呈2倍增长,会产生空间浪费。
那么如何解决上述问题呢?我们通过对单链表的学习,试试能否解决上述问题。
1.单链表
1.1概念与结构
概念:链表是一种物理存储结构上非连续,非顺序 的存储结构,数据元素的逻辑顺序 是通过链表中的指针链接次序实现的。

1.1.1结点
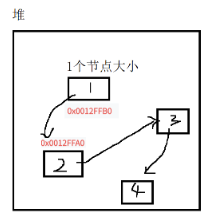
与顺序表不同的是,链表里的每"节"都是独立申请下来的空间,我们称之为"结点"。
结点的组成主要有两个部分:当前结点要保存的数据和保存下一个结点的地址(指针变量)。
图中指针变量plist保存的是第一个结点的地址,我们称plist为"指向"第一个结点,如果我们希望plist"指向"第二个结点时,只需要修改plist保存的内容为下一结点的地址。
链表中每个结点都是独立申请的 (即需要插入数据时才去申请一块结点的空间),我们需要通过指针变量来保存下一个结点位置才能从当前结点找到下一个结点。
1.1.2链表的性质
1.链式机构在逻辑上是连续的,在物理结构上不一定连续(如果地址连续则连续)。
2.结点一般是从堆上申请的。
3.从堆上申请来的空间,是按照一定策略分配出来的,每次申请的空间可能连续,可能不连续。
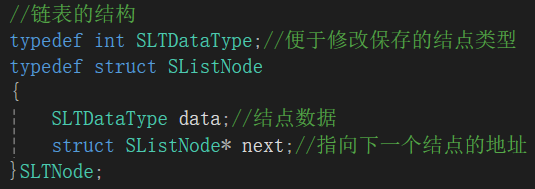
每个结点对应的结构体代码:
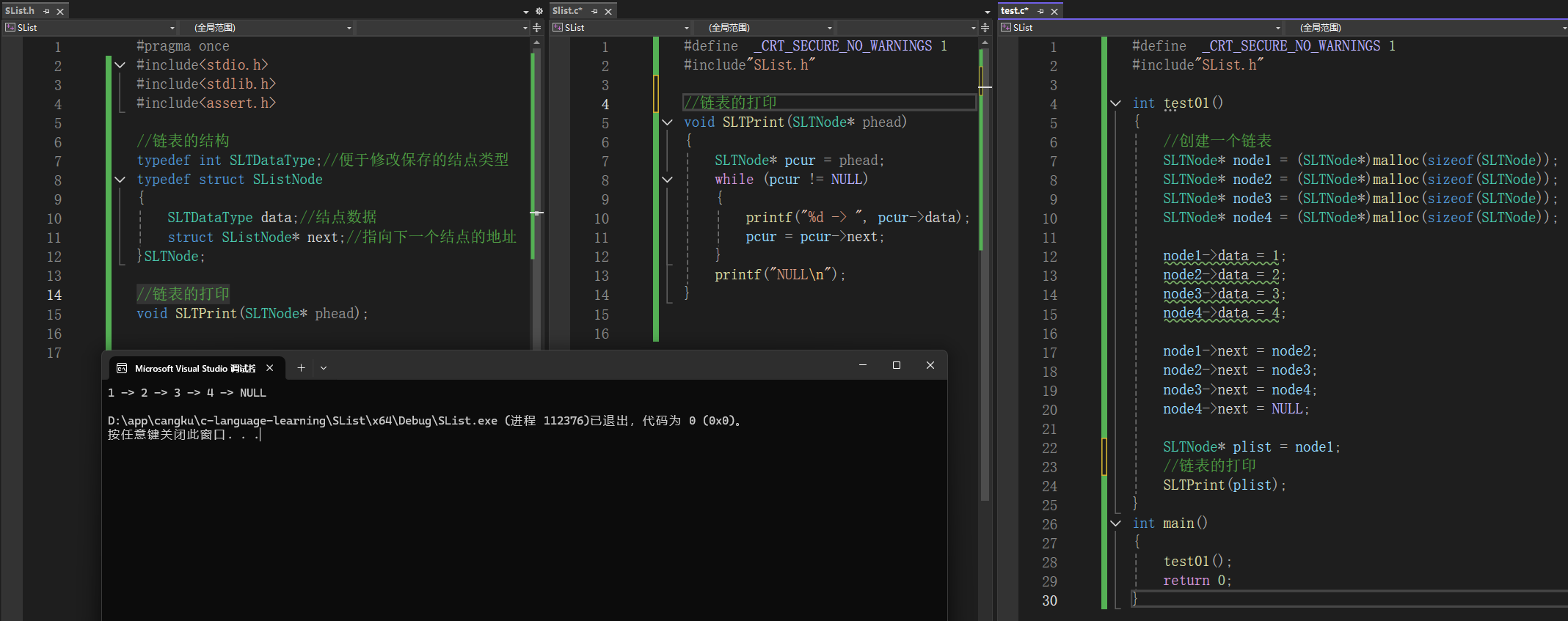
1.1.3链表的打印
在给定的链表结构中,实现结点从头到尾的打印:

1.1.4调试
1.2实现单链表
结构体代码和链表的打印上述已实现。
//链表的结构
typedef int SLTDataType;//便于修改保存的结点类型
typedef struct SListNode
{
SLTDataType data;//结点数据
struct SListNode* next;//指向下一个结点的地址
}SLTNode;
//链表的打印
void SLTPrint(SLTNode* phead);
//创建新链表
SLTNode* SLTBuyNode(SLTDataType x);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾删
void SLTPopBack(SLTNode** pphead);
//头删
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SListDestroy(SLTNode** pphead);1.2.1创建新链表
使用malloc见这篇文章:C语言:动态内存管理-CSDN博客 并判断newnode是否为空,随后创建新链表。
//创建新链表
SLTNode* SLTBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail!");
exit(1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}1.2.2尾插
需要先从创建新链表中申请新节点,并且在尾插时判断链表是否为空。
其中,phead为头节点,ptail遍历寻找尾节点。
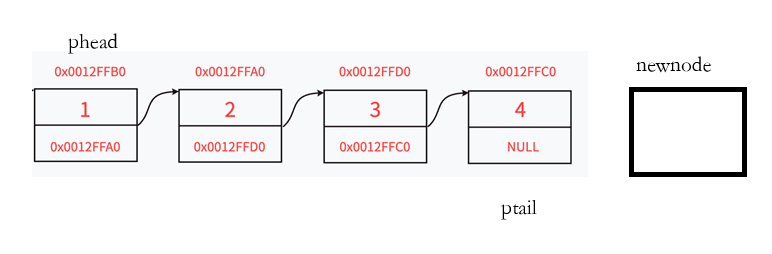
此时写好尾插的代码:
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
//创建新链表
SLTNode* newnode = SLTBuyNode(x);
//判空
if (*pphead == NULL)
{
*pphead = newnode;
}
else {
SLTNode* ptail = *pphead;
while (ptail->next != NULL)
{
ptail = ptail->next;
}
//找到尾结点,将newnode添加
ptail->next = newnode;
}
}注意:需要SLTNode** pphead,通过二级指针进行函数传参时的"地址传参"而不是"值传递",并且可以在函数内部修改外部指针的值,再进行调用调试:
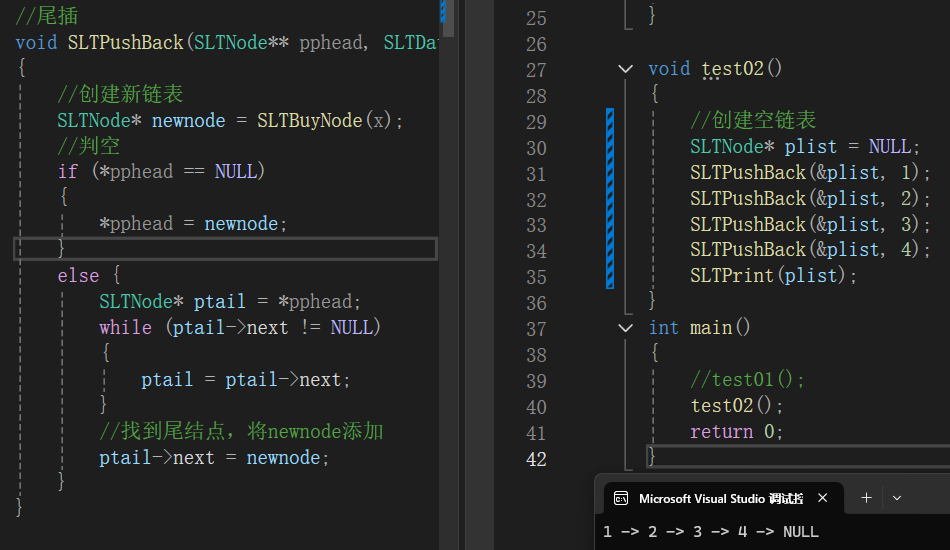
void test02()
{
//创建空链表
SLTNode* plist = NULL;
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPrint(plist);
}注意:需要使用&,否则只是"值传递",不能修改外部的phead。
关于二级指针相关文章:c语言基础:指针(3)-CSDN博客
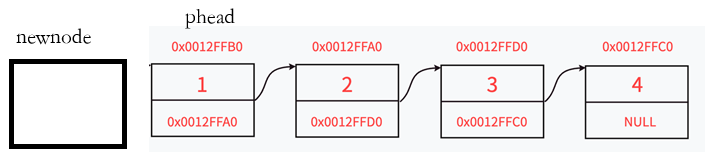
最终结果正确:
1.2.3头插
注意:*pphead :是对 pphead 解引用,得到的是 外部头指针 phead 的值 (即 phead 本身,存储链表第一个节点的地址)
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
//申请新节点
SLTNode* newnode = SLTBuyNode(x);
newnode->next = *pphead;
*pphead = newnode;
}此处断言为pphead,原因:确保二级指针本身有效不是NULL,*pphead可以为NULL。
调用调试:
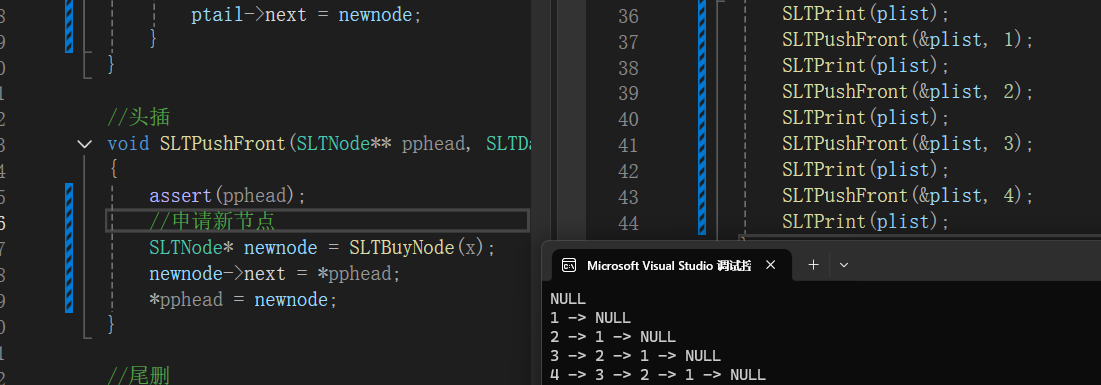
1.2.4尾删
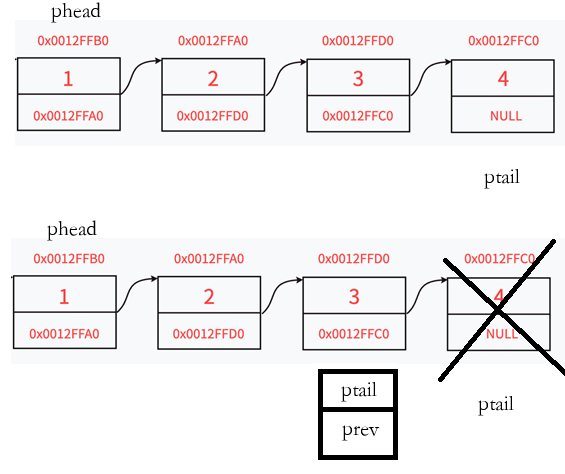
首先要先确保链表不为空,并且对链表是否只有一个结点做出区分,同时也要考虑优先级。优先级相关文章:c语言:操作符详解-CSDN博客。
尾删代码:
//尾删
void SLTPopBack(SLTNode** pphead)
{
//链表为空不能删
assert(pphead && *pphead);
//链表只有一个节点
if ((*pphead)->next == NULL)//注意优先级
{
free(*pphead);
*pphead = NULL;
}
else {
SLTNode* prev = NULL;
SLTNode* ptail = *pphead;
while (ptail->next)
{
prev = ptail;
ptail = ptail->next;
}
prev->next = NULL;
free(ptail);
ptail = NULL;
}
}调用调试:
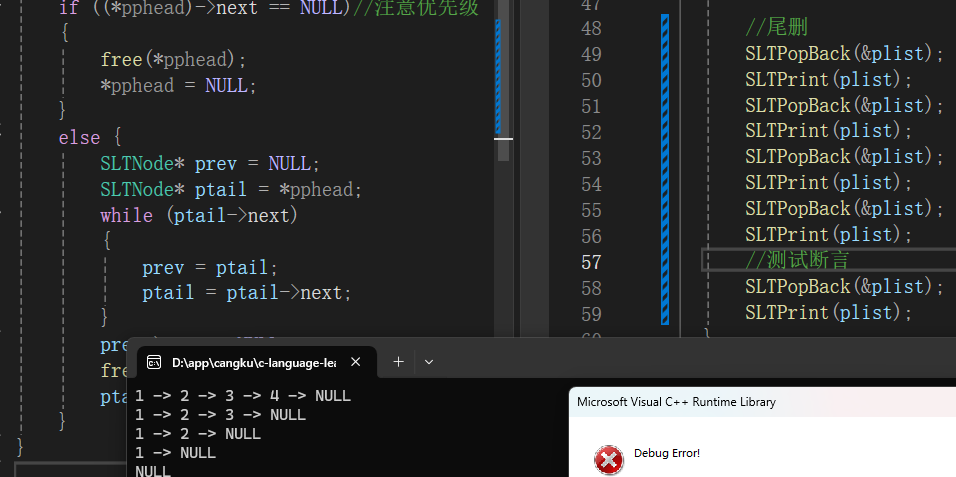
1.2.5头删
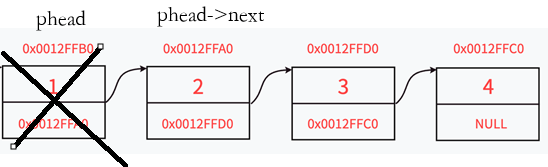
//头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead && *pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}调用测试:
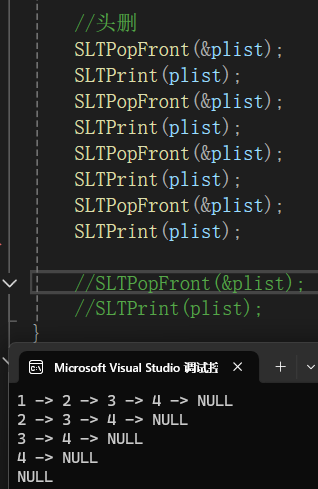
1.2.6查找
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* pcur = phead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
//未找到
return NULL;
}调用调试:
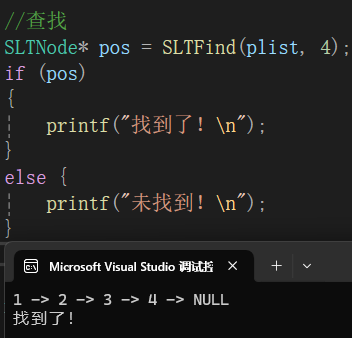
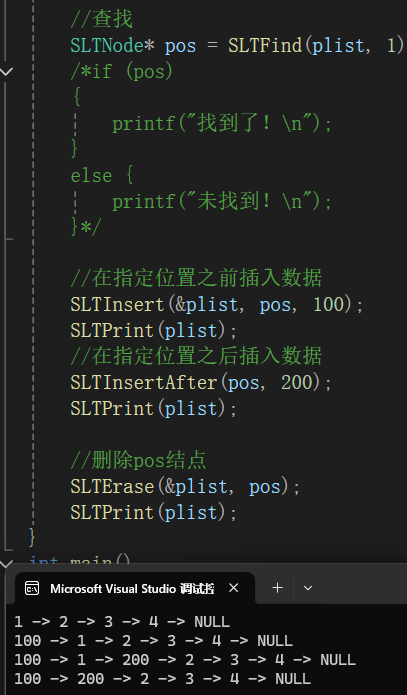
1.2.7在指定位置之前插⼊数据
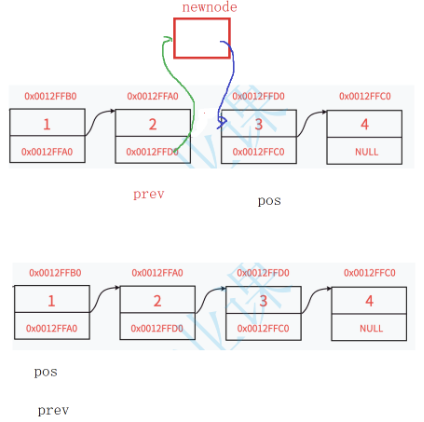
注意考虑pos是头节点时,需要头插,以及断言问题。
//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead && pos);
SLTNode* newnode = SLTBuyNode(x);
//pos指向头结点
if (pos == *pphead)
{
//头插
SLTPushFront(pphead, x);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
}调用调试:
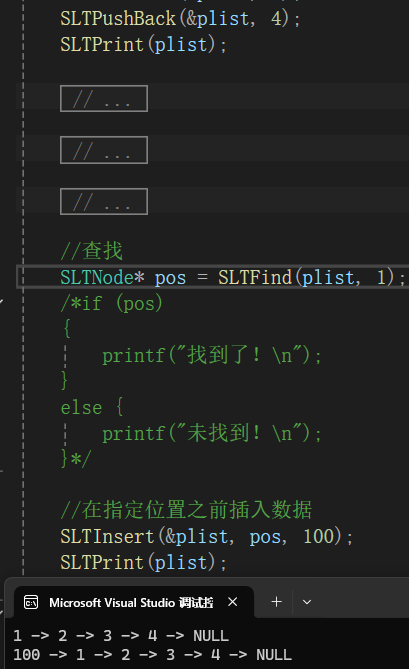
1.2.8在指定位置之后插入数据
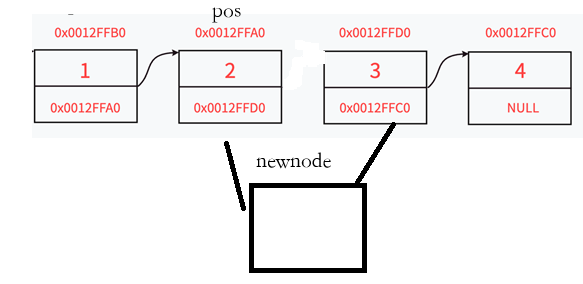
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}调用调试:
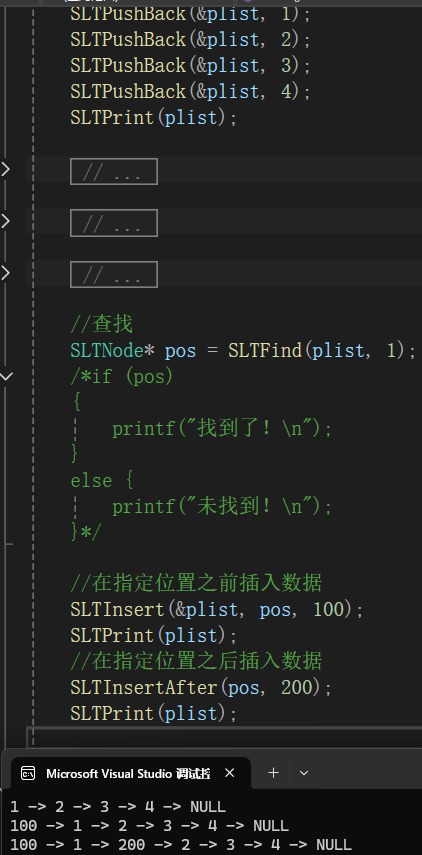
1.2.9删除pos结点
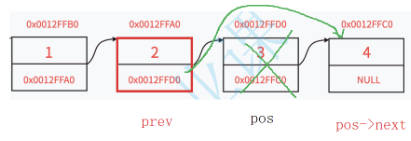
注意:若刚好要删除第一个结点,需添加头删。
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead && pos);
//pos刚好为头节点
if (pos == *pphead)
{
//头删
SLTPopFront(pphead);
}
else {
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}调用调试:
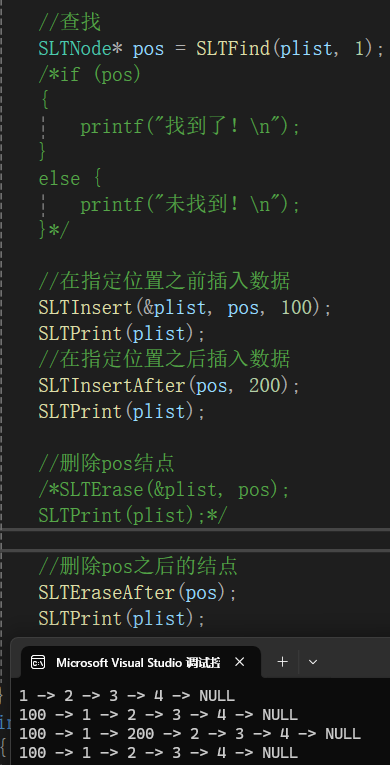
1.2.10删除pos之后的结点
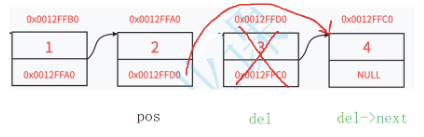
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{
assert(pos && pos->next);
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}调用调试:
1.2.11销毁链表
遍历链表后对其依次销毁。
//销毁链表
void SListDestroy(SLTNode** pphead)
{
assert(pphead);
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}对于不需要对pcur置空的解释:
这段代码中 **不需要** 对 `pcur = NULL;`,原因如下:
### 1. **`pcur` 的作用域和生命周期**
`pcur` 是函数内部的**局部变量**(存储在栈上),其作用域仅限于 `SListDestroy` 函数内部。当函数执行完毕后,`pcur` 会随着栈帧销毁而消失,外部代码无法访问它。
### 2. **循环逻辑的自然结果**
在循环中:
```c
while (pcur) {
SLTNode* next = pcur->next;
free(pcur);
pcur = next; // 每次将 pcur 更新为下一个节点,最终会走到 NULL
}
```
- 当链表最后一个节点被释放后,`next` 会是 `NULL`(链表尾节点的 `next` 本就是 `NULL`),因此循环结束时,`pcur` 已经被赋值为 `NULL`(最后一步 `pcur = next` 会把 `pcur` 设为 `NULL`)。
### 3. **为什么要设置 `*pphead = NULL`?**
`*pphead` 是**外部传入的头指针的别名**(通过二级指针修改一级指针)。链表销毁后,原来的头指针已经指向被释放的内存(野指针),必须将其置为 `NULL`,避免外部代码误用野指针。
而 `pcur` 是内部临时变量,即使不主动置 `NULL`,函数结束后也会自动销毁,不会对外部产生影响。
综上,`pcur` 作为函数内的局部变量,循环结束后已经自然变为 `NULL`,且函数结束后会被销毁,因此**无需额外对 `pcur` 赋值 `NULL`**。调用调试:
本章完。