一、介绍
广义:多个机器构成分布式系统。
狭义:Redis 提供的集群模式,用于解决存储空间不够。

数据全集会被平均分成若干份存储在一组主从节点,叫做分片中,这样就能解决存储容量的问题。
但是新来一个数据,我们应该把数据放在哪个分片中呢?
二、数据分片算法
1、哈希求余
根据 key 值通过 md5 等哈希算法求出后取余就能得到下标,进行存入。
md5 生成的是一个定长的十六进制数,且计算分散(即便是非常相似的字符串经过 md5 之后一定差别很大),计算结果也是不可逆的。
但是哈希求余是纯随机的,当面临扩容的时候需要把原先所有的数据再次进行求余,非常麻烦。
2、一致性哈希算法
为了解决上述问题,引入一致性哈希算法。
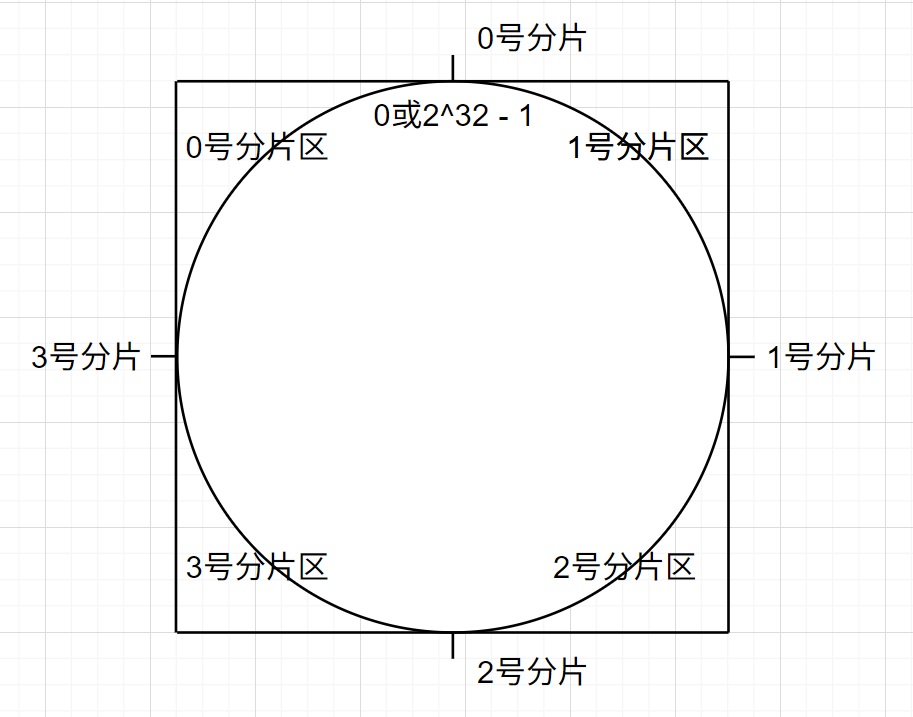
一个圆被分成 2^32 份,计算到的哈希值对应一份放入到对应的分片,由于不再是求余的结果交替式,这种方式分出来的数据是连续的,此时第五个分片来了,进行扩容:
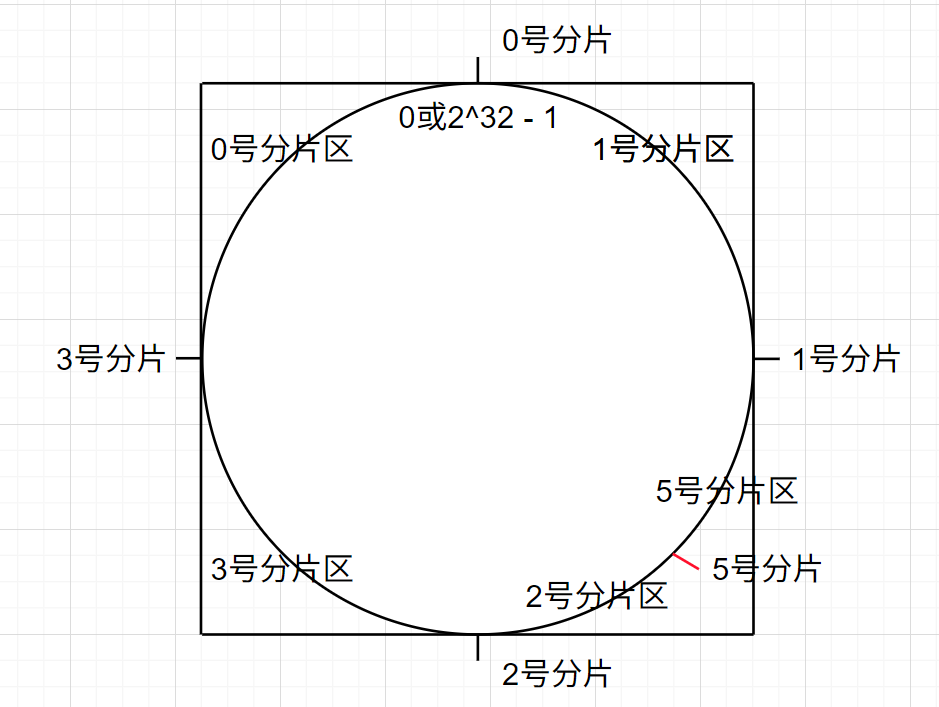
把原本的2号分片区拆成了2号和5号,这样数据只要移动2号的一部分即可。
但是问题是这样做数据就不再平均,数据倾斜了。
3、哈希槽分区算法
Redis 采用此方法,解决上面两个问题。
hash_slot = crc16(key) % 16384
用类似于 md5 的算法 crc16 计算出哈希值之后模 16384(2KB)计算出对应的哈希槽。
进一步把多个哈希槽分配给对应分片,这里举例三个分片:0号获得 0, 5461 的哈希槽,1号获得 5462, 10923,2号获得 10924, 16383
其实就是把前两个方法结合
这样在扩容的时候有4个分片,但是一开始只有3个有数据有哈希槽,那么每个有数据的分片拿一点哈希槽给新来的分片,这样就能做到平均分配,移动的数据也只有四分之一。
为了记录,每个分片都会有一个16位的位图用0 1表示拥有的哈希槽号。
细节:
(1)官方建议分片不超过1000,由于 key 纯随机映射到槽号,再通过槽号映射到分片,只要在每个分片拥有足够的槽时,数据的分配才是相对平均的。
(2)为什么时 16384?够用,而且发送心跳包的时候要带上16位位图也就是2KB,如果过大会占用网络带宽。
三、集群的故障转移
1、故障判定
用心跳包检测节点挂没挂。每个节点每秒随机挑选一个节点进行 ping,如果在规定时间内没有收到 pong 就会主观下线,询问其他节点对应节点有没有下线,如果超过一半认为下线了,那就确认对应节点已经下线,进行故障转移。
2、故障迁移
如果是从节点没有关系,修好连上就行。
如果是主节点挂了,就要在对应的分片中挑选从节点作为主节点,并且同步给其他分片。
四、集群扩容流程
1、加入新主节点
2、重新分配哈希槽
3、添加从节点