作者:钰诚
简介
传统的负载均衡算法主要设计用于通用的 Web 服务或微服务架构中,其目标是通过最小化响应时间、最大化吞吐量或保持服务器负载平衡来提高系统的整体效率,常见的负载均衡算法有轮询、随机、最小请求数、一致性哈希等。然而,在面对 LLM 服务时,这些传统方法往往暴露出以下几个关键缺陷:
-
忽略任务复杂度差异:LLM 推理请求的复杂度差异极大。例如,一个长文本生成任务可能需要数十倍于短文本分类任务的计算资源。而传统负载均衡器无法感知这种差异,容易导致某些节点过载,而其他节点空闲,造成资源浪费和响应延迟。
-
缺乏对 GPU 资源水位的感知:在 LLM 推理服务中,计算瓶颈主要集中在 GPU 上,传统负载均衡器往往无法感知到这一细粒度的资源消耗情况,导致某些 GPU 节点因显存不足而拒绝请求或响应缓慢,而其他节点却处于空闲状态。
-
缺乏对 KV Cache 的复用能力:在并发请求处理中,如果多个请求具有相似的前缀,则它们的 KV Cache 可能存在重叠部分,可以通过共享或压缩的方式减少显存占用并提升生成速度。传统负载均衡策略并未考虑请求之间的语义相似性或 KV Cache 的可复用性,难以将具有潜在复用价值的请求分配到同一 GPU 实例上,从而错失优化机会。
针对 LLM 服务的特点,Higress AI 网关以插件形式提供了面向 LLM 服务的负载均衡算法,包括全局最小请求数负载均衡、前缀匹配负载均衡以及 GPU 感知负载均衡,能够在不增加硬件成本的前提下,提升系统的吞吐能力、降低响应延迟,并实现更公平、高效的任务调度。
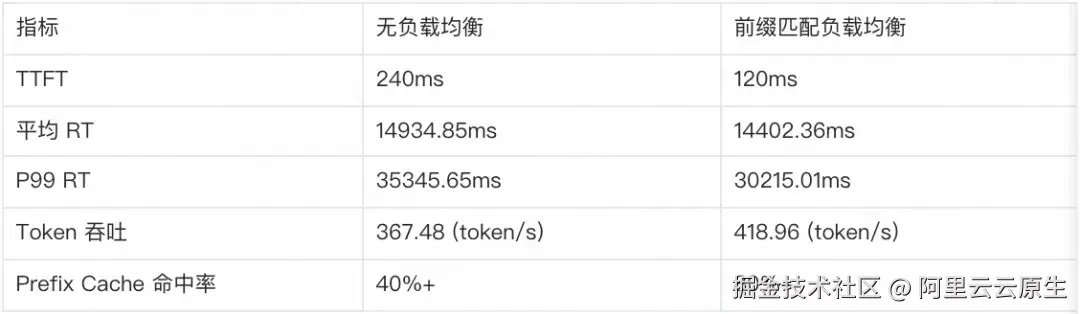
以前缀匹配负载均衡为例,压测工具使用 NVIDIA GenAI-Perf,设置每轮输入平均为 200 token,输出平均为 800 token,并发为 20,每个会话包含 5 轮对话,共计 60 个会话,性能指标前后对比如下:
技术选型
目前已经有很多优秀的开源项目,例如 Envoy AI Gateway、AIBrix 等,基于 Envoy External Processing 机制外接一个负载均衡器实现面向 LLM 的负载均衡,负载均衡器以 sidecar 或者 K8s 服务形式部署。
Higress AI 网关以 wasm 插件形式提供了面向 LLM 服务的核心负载均衡能力,具有如下特点:
- 免运维:以 wasm 形式提供负载均衡能力,不需要用户额外维护 sidecar,只需要在 Higress 控制台开启插件即可,部署运维成本大大降低。
- 热插拔:即插即用,用户仅需要在控制台进行策略配置即可,开启插件时采用面向 LLM 服务的专属负载均衡策略,关掉插件后自动切换为服务基础的负载均衡策略(轮询、最小请求数、随机、一致性哈希)。
- 易扩展:插件本身提供了多种负载均衡算法,并且在不断丰富完善中,采用 go 1.24 编写,代码开源,如果有特殊需求,用户可以基于现有插件进行定制。
- 全局视野:借助 Redis,网关的多个节点具有全局视野,负载均衡更加公平、高效。
- 细粒度控制:插件可以在实例级、域名级、路由级、服务级等不同粒度进行生效,方便用户做细粒度的控制。
负载均衡算法介绍
接下来,本文会介绍 Higress AI 网关提供的三种负载均衡算法:全局最小请求数负载均衡、前缀匹配负载均衡、GPU 感知负载均衡。
全局最小请求数负载均衡
在分布式环境中,网关实例往往具有多个节点,传统的负载均衡策略是每个节点做局部的负载均衡,缺乏全局视野。在 Higress AI 网关中,我们借助 Redis 实现了全局最小请求数负载均衡算法,根据每个 LLM Pod 上正在处理的请求数进行负载均衡。
选取 Pod 的大致流程如下:
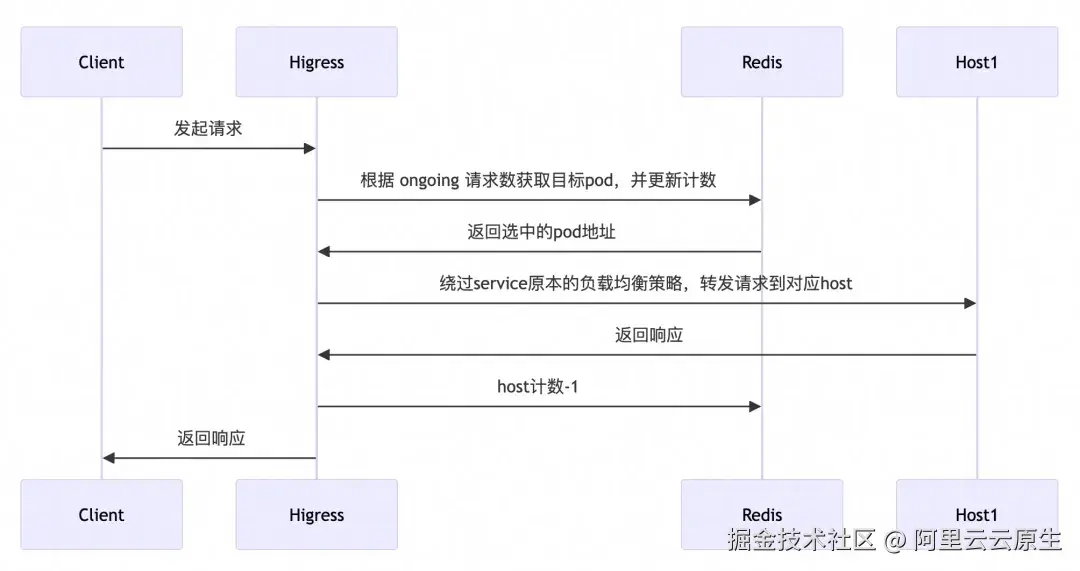
在全局最小请求数负载均衡中我们重点关注了请求异常(例如后端服务不可访问、客户端断连、服务端断连等)情况下的处理,通过在 HttpStreamDone 阶段统一进行计数的变更可以保证异常中断的请求也能够得到计数的更新,避免因请求异常导致服务计数异常情况。
前缀匹配负载均衡
在多轮对话场景下,一次会话会涉及多次 LLM 的调用,多次调用时请求携带了相同的上下文信息,如果能够感知上下文信息并将同属一个会话的多次请求路由到相同的 LLM Pod 中,将能够充分利用 LLM Pod 的 KV Cache,从而大幅提高请求的 RT、Token 吞吐等性能指标。
在 Higress AI 网关中,我们借助 Redis 实现了全局的前缀匹配负载均衡算法,能够充分适应分布式环境,在请求到达网关时,会根据当前的前缀树信息进行前缀匹配,如果能够匹配成功,则会路由至对应 LLM Pod,如果匹配不到前缀,则会根据全局最小请求数负载均衡方法选出当前处理请求最小的 LLM Pod。
选取 Pod 的大致流程如下:
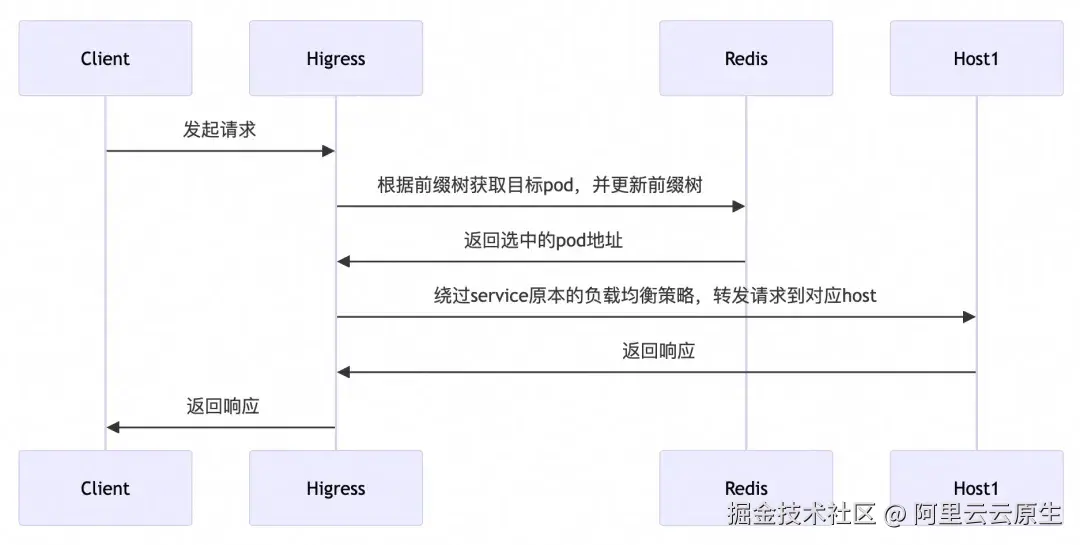
接下来简单介绍如何在 Redis 中构建前缀树。
首先将 LLM 请求的 messages 以 user 为界限划分为不同的 block,并通过哈希获得一个 16 进制字符串,如下图所示,messages 被划分为两个 block,并且计算了每个 block 的 sha-1 值:

假设有一个请求被划分成了 n 个 block,在进行前缀匹配时:
1)在 redis 中查询 sha-1(block 1) 是否存在
- 如果不存在,前缀匹配失败,采用全局最小请求数选择 pod,pod 选取结束,根据当前请求内容更新前缀树
- 如果存在,前缀匹配成功,记录当前的 pod,转步骤 2
2)在 redis 中查询 sha-1(block 1) XOR sha-1(block 2) 是否存在
- 如果不存在,前缀匹配失败,步骤1中选出来的 pod 即为目标 pod,根据当前请求内容更新前缀树,pod 选取结束
- 如果存在,前缀匹配成功,转步骤 3
3)在 redis 中查询 sha-1(block 1) XOR sha-1(block 2) XOR ... XOR sha-1(block n) 是否存在
- 如果不存在,前缀匹配失败,步骤 2 中选出来的 pod 即为目标 pod,根据当前请求内容更新前缀树,pod 选取结束
- 如果存在,前缀匹配成功,pod 选取结束
通过以上过程,能够将同一个会话的多次请求路由至同一个 pod,从而提高 KV Cache 的复用。
GPU 感知负载均衡
一些 LLM Server 框架(如 vllm、sglang 等)自身会暴露一些监控指标,这些指标能够实时反应 GPU 负载信息,基于这些监控指标可以实现 GPU 感知的负载均衡算法,使流量调度更加适合 LLM 服务。
目前已经有一些开源项目基于 envoy ext-proc 机制实现了 GPU 感知的负载均衡算法,但 ext-proc 机制需要借助一个外部进程,部署与维护较为复杂,Higress AI 网关实现了后台定期拉取 metrics 的机制(目前支持 vllm),以热插拔的插件形式提供了 GPU 感知的负载均衡能力,并且场景不局限于 K8s 环境,任何 Higress AI 网关支持的服务来源均可使用此能力。
选取 Pod 的大致流程如下:
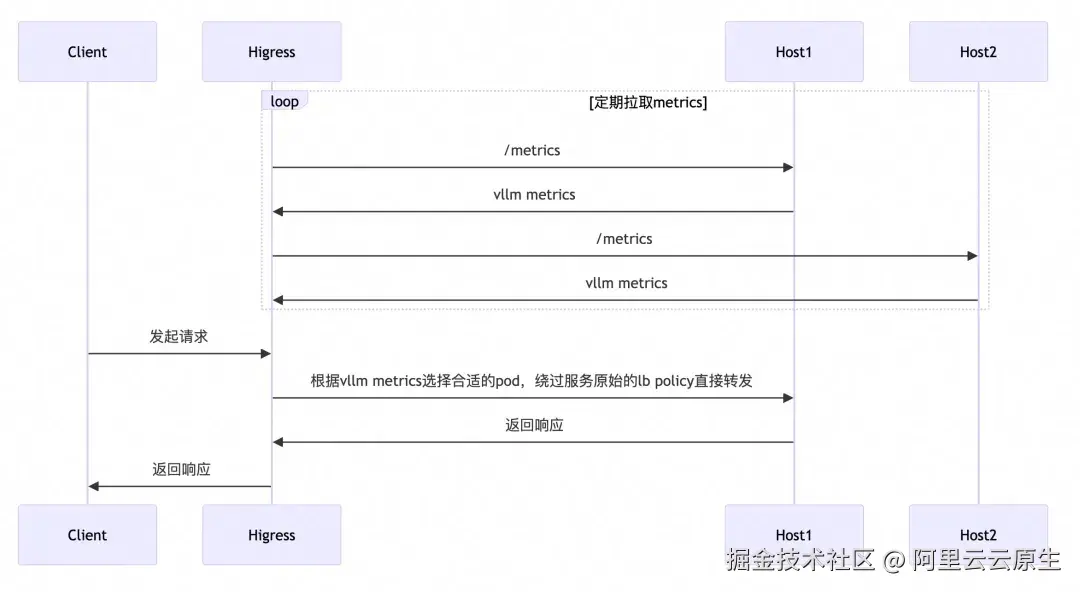
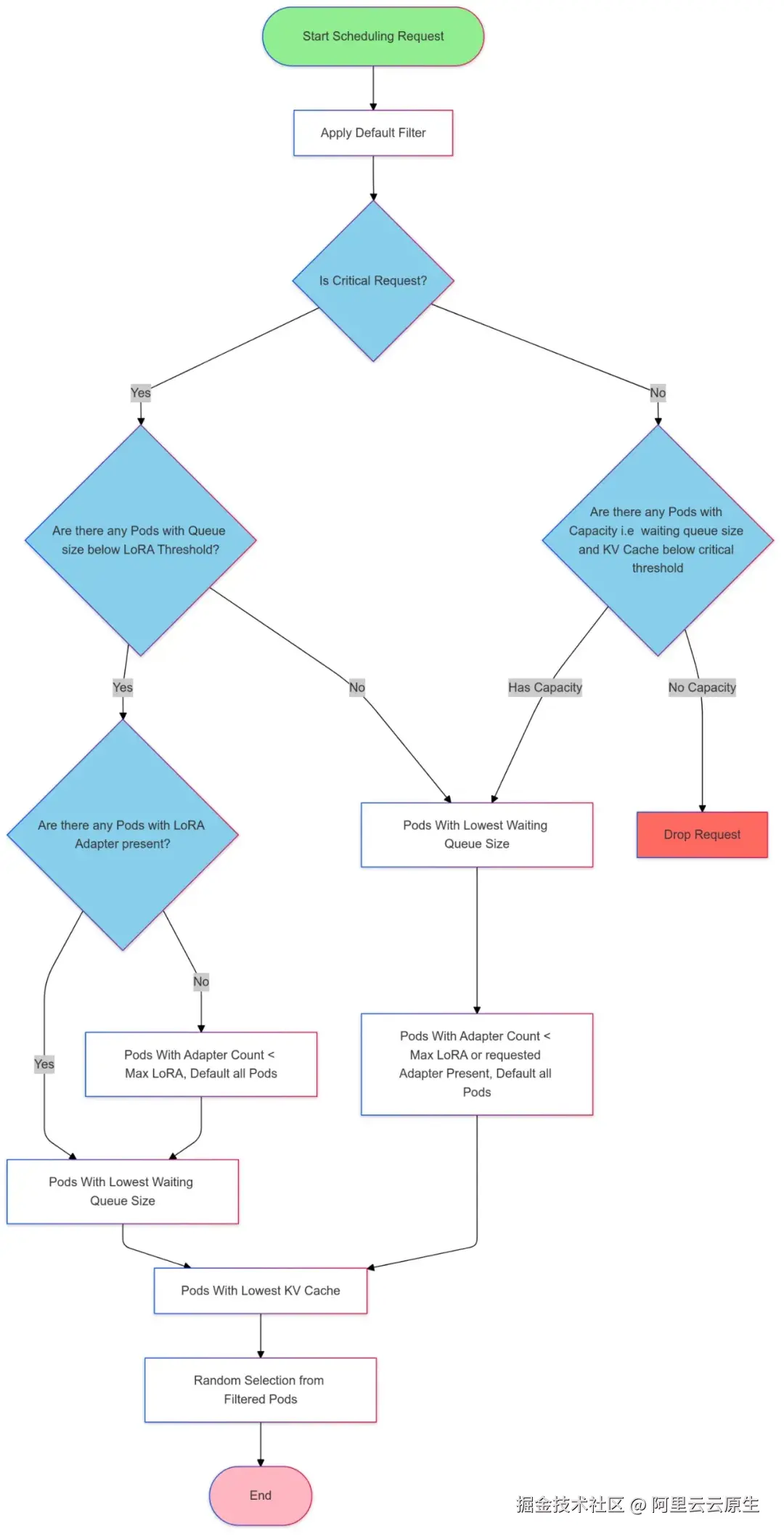
目前基于 metrics 的负载均衡策略遵循了 gateway-api-inference-extension【1】 的 pod 选取算法,根据 LoRA Adaotor 亲和、队列长度、KV Cache 使用率进行负载均衡,选取过程如下图所示:
使用方法
以前缀匹配负载均衡为例:
- 准备 Redis 资源:登录阿里云 Redis 控制台【2】,创建Redis实例,并设置连接密码。具体操作,请参见 Redis 快速入门概览【3】。
- 准备 LLM 服务:以 ECS 形式基于 vllm 框架部署 llama3 模型,共 3 个节点。
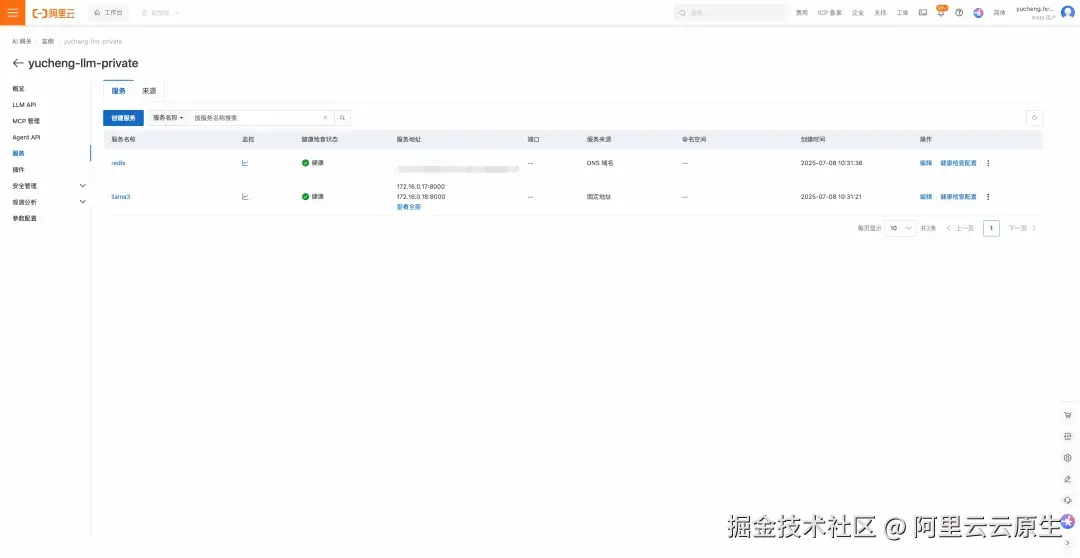
- 在网关配置服务:在网关实例中导入 Redis 服务以及 LLM 服务,其中 redis 为DNS类型服务,llama3 为固定地址类型服务。
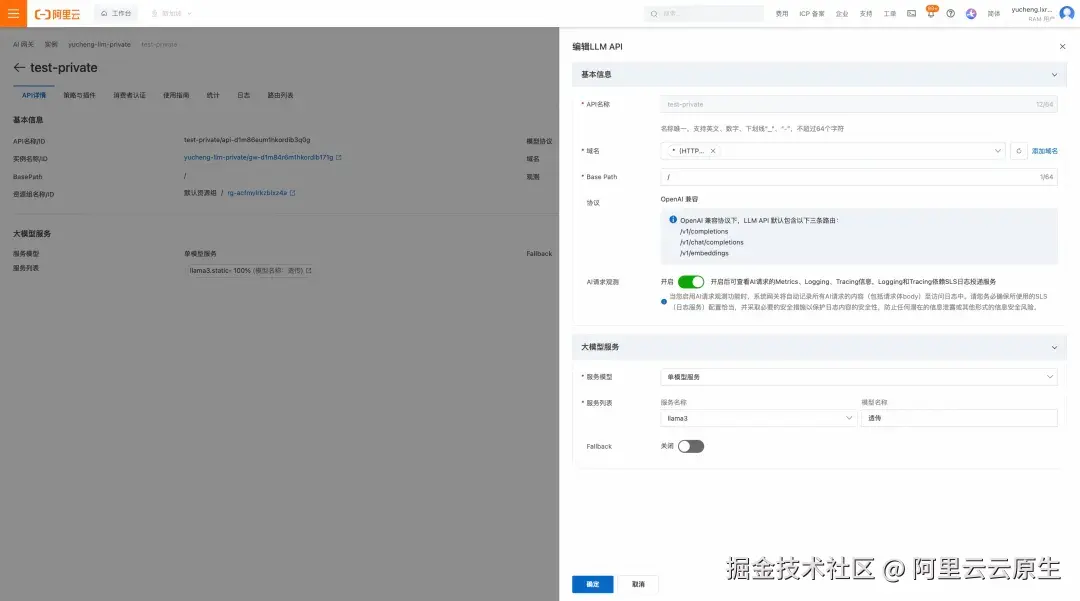
- 在网关配置 API:在网关中创建一个 LLM API,后端服务指向 llama3.
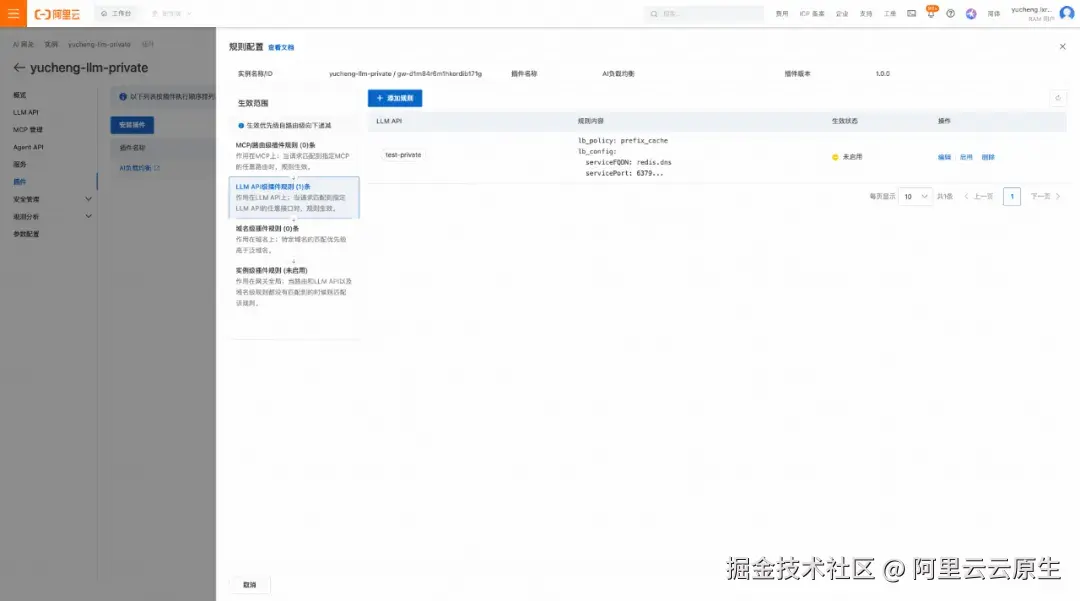
- 在网关配置插件:在插件市场找到 ai-load-balancer 插件进行安装,然后在 LLM API 粒度下给刚才创建的 LLM API 配置负载均衡策略。
插件配置示例如下:
yaml
lb_policy: prefix_cache
lb_config:
serviceFQDN: redis.dns
servicePort: 6379
username: default
password: xxxxxxxxxxxx
redisKeyTTL: 60附录:压测结果与 vllm 监控大盘
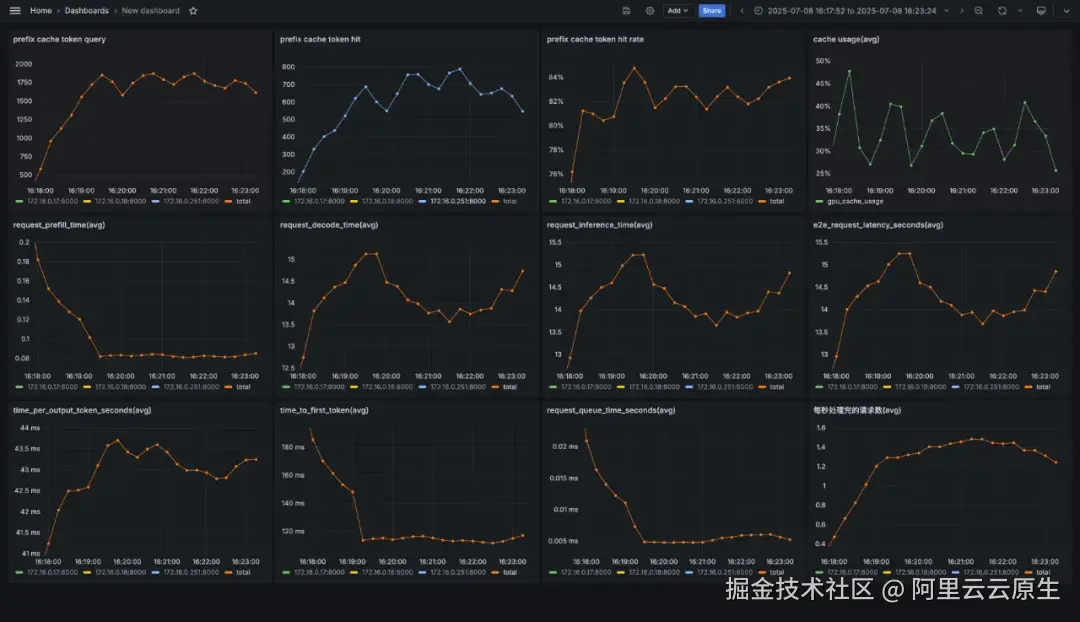
无负载均衡
GenAI-Perf 统计结果如下:

vllm 监控如下:
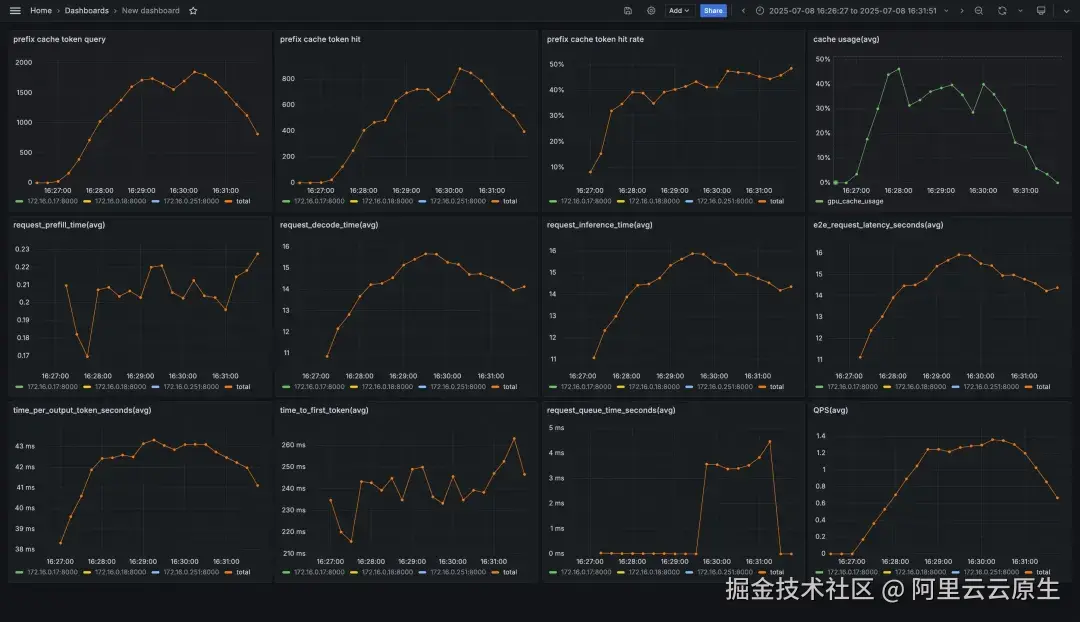
前缀匹配负载均衡
GenAI-Perf 统计结果如下:

vllm 监控如下:
相关链接:
【1】gateway-api-inference-extension
【2】阿里云 Redis 控制台
kvstore.console.aliyun.com/Redis/insta...
【3】Redis 快速入门概览
help.aliyun.com/zh/redis/ge...
🔥🔥拥抱 AI 原生!
8月29日深圳,企业实践工作坊火热报名中!
阿里云诚挚邀请您参加【AI 原生,智构未来------AI 原生架构与企业实践】工作坊,从开发范式到工程化实践,全链路解析AI原生架构奥秘,与AI先行者共探增长新机遇。
⬇️ 点击此处,立即了解完整议程!