先看效果!!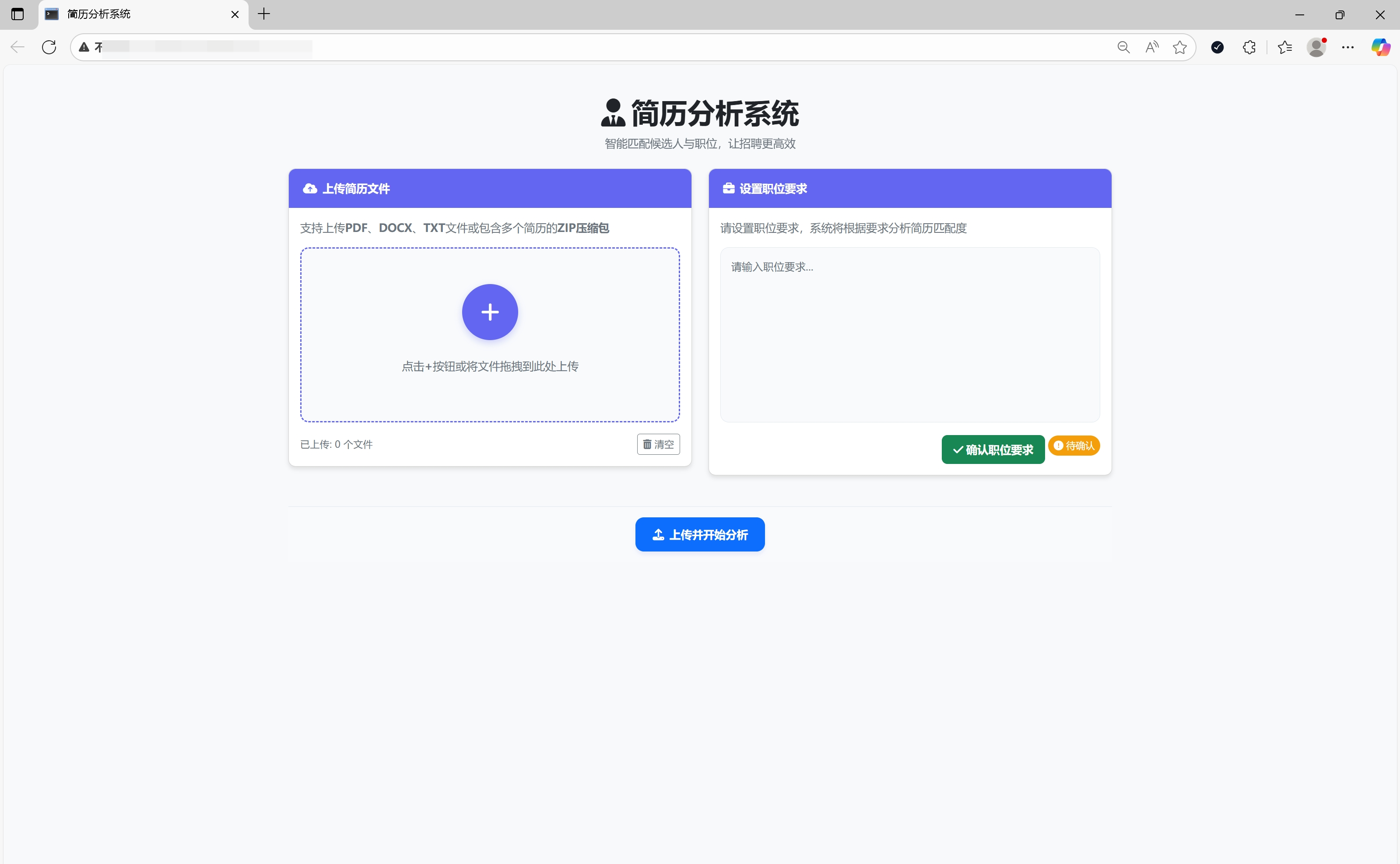
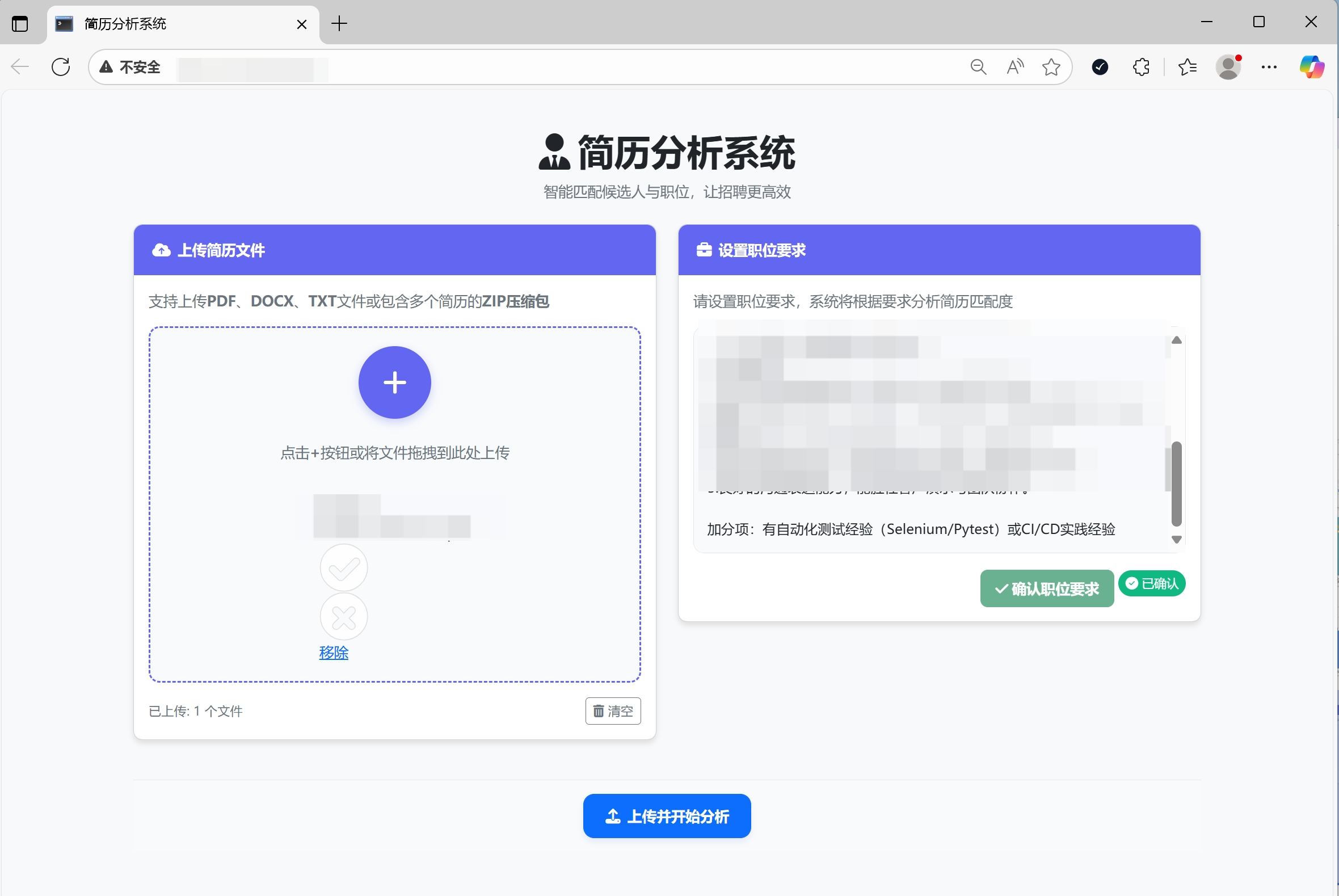
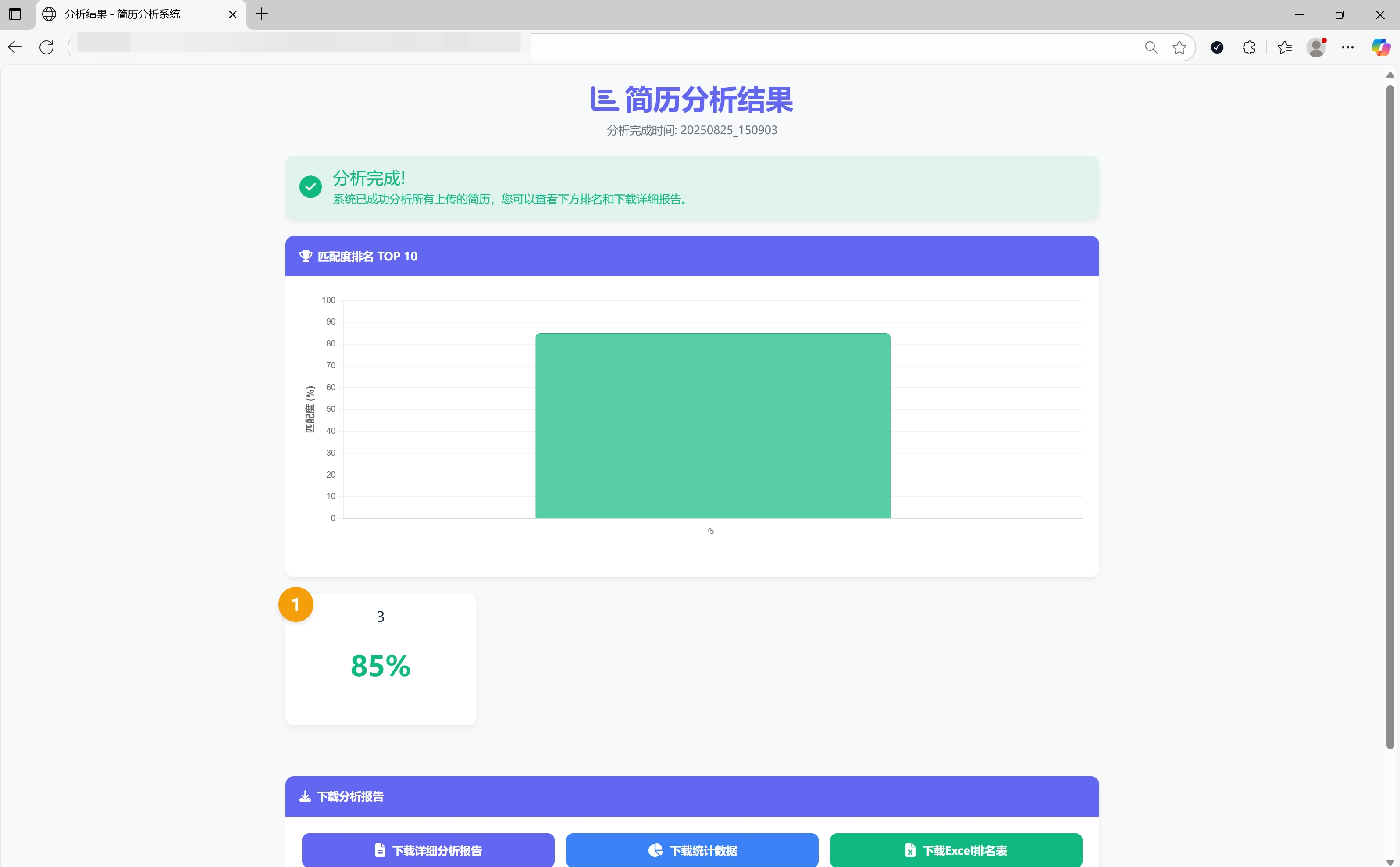
1. 项目简介
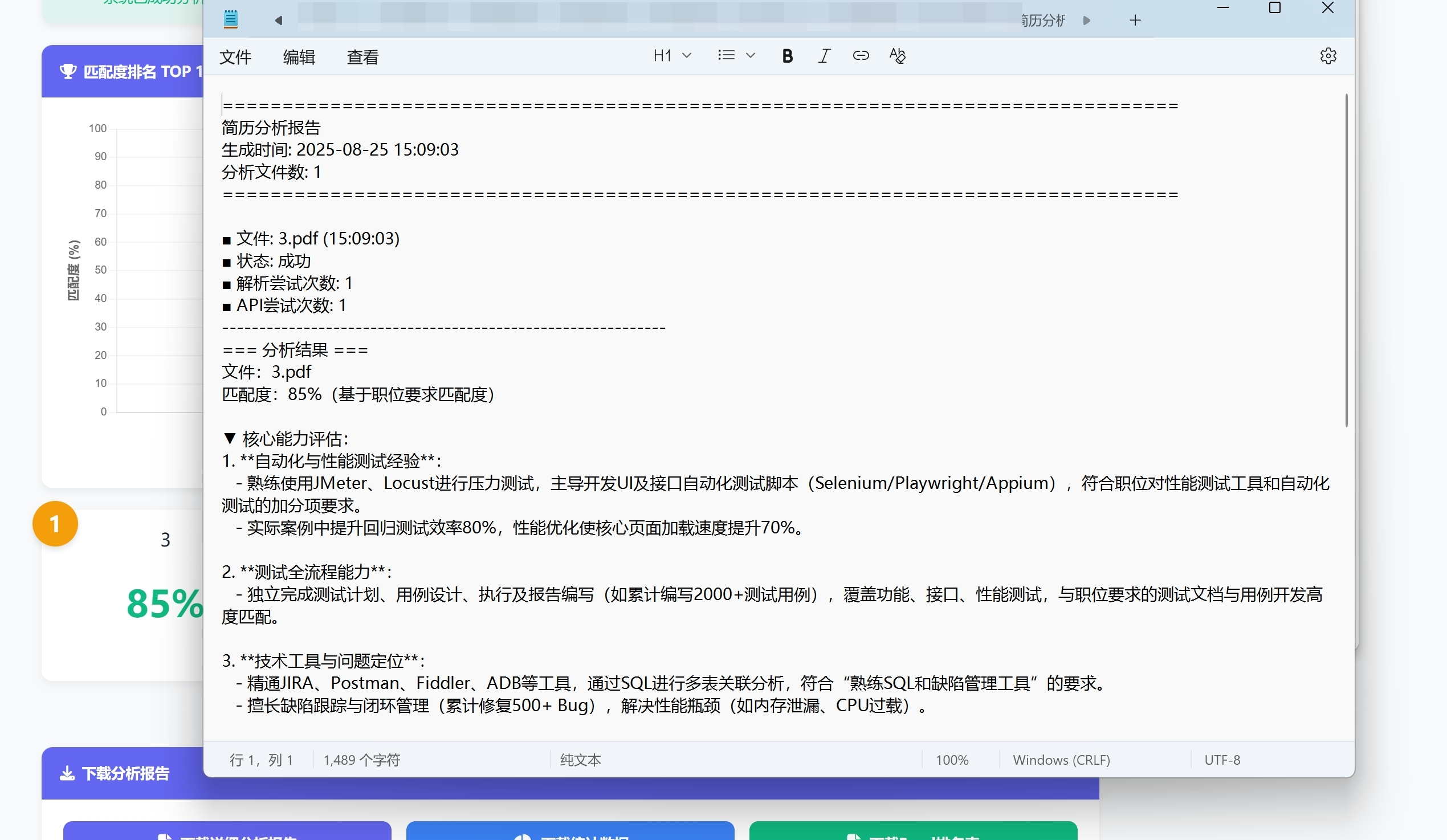
随着企业招聘需求的不断增加,HR每天需要处理大量简历,如何高效筛选匹配度高的候选人成为一大挑战。本文介绍一个基于Flask框架和AI技术的智能简历分析系统,能够自动评估简历与职位要求的匹配度,大幅提高招聘效率。
2. 项目功能
2.1 核心功能
- 简历批量上传:支持PDF、DOCX、TXT格式及ZIP压缩包
- 职位要求设置:可自定义职位描述和要求
- 智能匹配分析:利用AI模型评估简历匹配度
- 可视化结果展示:图表和排名展示候选人匹配情况
- 报告导出:支持导出详细分析报告和Excel排名表
2.2 技术亮点
- 多线程并发处理大量简历
- 智能重试机制保证分析可靠性
- 响应式前端界面适配多种设备
- 完善的错误处理和日志记录
3. 技术架构
3.1 前端技术
html
<!-- 主要前端技术 -->
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.2.3/dist/css/bootstrap.min.css" rel="stylesheet">
<link href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css" rel="stylesheet">
<link href="https://cdnjs.cloudflare.com/ajax/libs/animate.css/4.1.1/animate.min.css">
<script src="https://unpkg.com/dropzone@5/dist/min/dropzone.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>- Bootstrap 5:构建响应式界面
- Font Awesome:图标库
- Animate.css:动画效果
- Dropzone.js:文件上传组件
- Chart.js:数据可视化
3.2 后端技术
python
# 主要后端技术栈
from flask import Flask, render_template, request, jsonify, send_file
from flask_dropzone import Dropzone
import pdfplumber
from docx import Document
from concurrent.futures import ThreadPoolExecutor
import requests- Flask:轻量级Web框架
- pdfplumber:PDF解析库
- python-docx:Word文档处理
- ThreadPoolExecutor:多线程处理
- Requests:HTTP请求库
4. 核心代码解析
4.1 简历解析模块
python
def parse_resume(file_path):
"""解析多种格式的简历文件"""
try:
if file_path.endswith('.pdf'):
with pdfplumber.open(file_path) as pdf:
text = "\n".join([page.extract_text() or "" for page in pdf.pages])
elif file_path.endswith('.docx'):
doc = Document(file_path)
text = "\n".join([para.text for para in doc.paragraphs])
elif file_path.endswith('.txt'):
encodings = ['utf-8', 'gbk', 'gb2312', 'iso-8859-1']
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
text = f.read()
break
except UnicodeDecodeError:
continue
# 文本清洗处理
text = re.sub(r'\s+', ' ', text)
return text.strip()
except Exception as e:
logger.error(f"解析失败 [{os.path.basename(file_path)}]: {str(e)}")
return None4.2 AI分析模块
python
def call_gpt_api(prompt, attempt=1):
"""调用AI分析API,带重试机制"""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "deepseek-v3-250324",
"messages": [
{"role": "system", "content": "简历分析专家,专注评估候选人与职位要求的匹配度"},
{"role": "user", "content": prompt}
],
"temperature": 0.2
}
try:
response = requests.post(API_URL, headers=headers, json=data, timeout=REQUEST_TIMEOUT)
response.raise_for_status()
return {
"status": "success",
"result": response.json()['choices'][0]['message']['content'],
"attempt": attempt
}
except Exception as e:
logger.error(f"API请求错误 (尝试 {attempt}/{MAX_RETRIES}): {str(e)}")
return {"status": "retry", "error": str(e), "attempt": attempt}4.3 多线程处理
python
def process_resumes(resume_files, position_requirements):
"""多线程处理简历分析"""
results = []
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
futures = {executor.submit(analyze_resume, path, position_requirements): path
for path in resume_files}
for future in as_completed(futures):
path = futures[future]
try:
result = future.result()
with FILE_LOCK: # 线程锁保证数据安全
results.append(result)
except Exception as e:
logger.error(f"分析过程出错: {str(e)}")
return results5. 前端交互设计
系统采用现代化UI设计,关键界面包括:
html
<div class="upload-area">
<div id="upload-button" class="upload-btn">
<i class="fas fa-plus"></i>
</div>
<p class="upload-text">
点击<b>+</b>按钮或将文件拖拽到此处上传
</p>
</div>
html
<div class="chart-container">
<canvas id="matchChart"></canvas>
</div>
<!-- 排名卡片 -->
<div class="row g-4 mb-5">
{% for resume in top_resumes %}
<div class="col-md-4 col-lg-3">
<div class="position-relative">
<div class="rank-badge top-3-badge rank-{{ loop.index }}">
{{ loop.index }}
</div>
<div class="card result-card h-100">
<!-- 卡片内容 -->
</div>
</div>
</div>
{% endfor %}
</div>6. 部署与配置
系统使用Flask内置的配置管理系统:
python
class Config:
SECRET_KEY = os.environ.get('SECRET_KEY')
DEBUG = False
UPLOADED_PATH = os.path.join(os.path.dirname(__file__), 'uploads')
MAX_CONTENT_LENGTH = 50 * 1024 * 1024 # 50MB
# API配置
API_URL = "ht"
API_KEY = os.environ.get('API_KEY')7. 项目收获与改进方向
通过开发这个项目
- Flask框架的深入理解
- 文件处理的多格式兼容经验
- 多线程编程实践
- API集成与错误处理技巧
未来改进方向:
- 增加更详细的候选人技能标签
- 实现自动生成面试问题功能
- 添加多用户和权限管理系统
- 优化AI提示词提高分析准确率