文章目录
- [1. LLM的网络基础知识](#1. LLM的网络基础知识)
-
- 单个训练节点的架构图
- 集合通信基础知识
-
- [all reduce/broadcast/all gather/reduce scatter](#all reduce/broadcast/all gather/reduce scatter)
- [all reduce == reduce-scatter-gather](#all reduce == reduce-scatter-gather)
- [TPU vs GPUs](#TPU vs GPUs)
- [2. 不同的LLM并行训练形式](#2. 不同的LLM并行训练形式)
-
- 数据并行
- 模型并行
-
- 朴素的想法:按层并行
- [pipeline 并行/流水线并行](#pipeline 并行/流水线并行)
-
- 流水线并行的优点
- [Zero bubble 流水线并行/ DualPipe](#Zero bubble 流水线并行/ DualPipe)
- [tensor 并行/张量并行](#tensor 并行/张量并行)
-
- 何时使用
- [张量并行 vs 流水线并行:优缺点](#张量并行 vs 流水线并行:优缺点)
- 激活并行
-
- 每一层激活值内存如何计算?
- [sequence 并行](#sequence 并行)
- 其他类型的并行策略
- 并行化策略总结
- [3. 缩放+并行化训练LLM](#3. 缩放+并行化训练LLM)
-
- 3D并行:不同维度的并行
-
- [3D 并行的应用:megatron的缩放策略](#3D 并行的应用:megatron的缩放策略)
- 3D并行的效果
- 最近的大语言模型是怎么做的?
学习目标:
- 了解训练大型模型的系统复杂性
- 不同的并行化范例以及人们为什么同时使用多个并行化
- 大规模训练运行通常是什么样的
1. LLM的网络基础知识
训练大模型面临的双重挑战:计算和内存
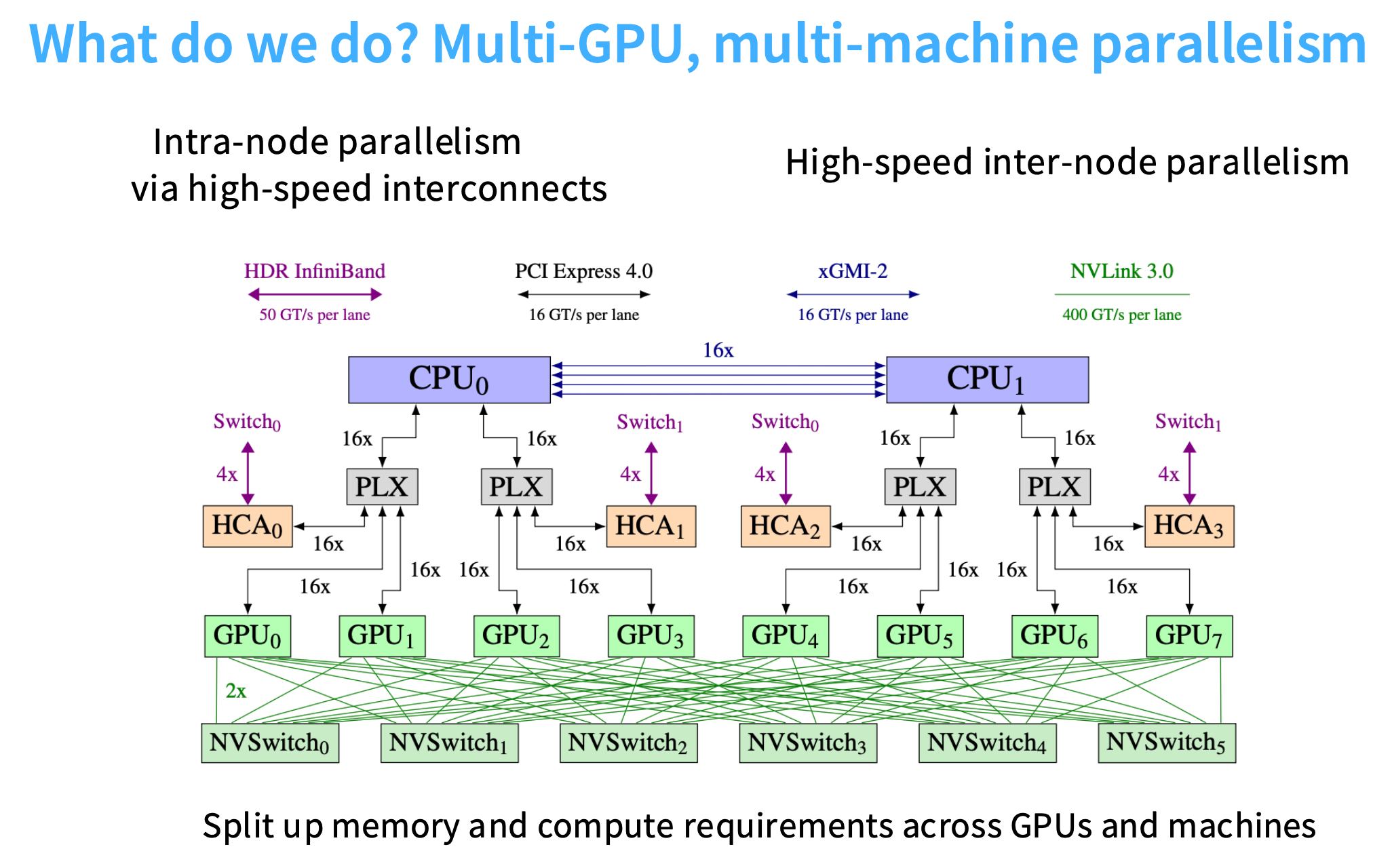
单个训练节点的架构图
- 以GPT-NeoX为例,单台机器(即同一物理机架)内会有多个GPU。
- 如图展示了8个不同的GPU,每个GPU通过NVSwitch进行连接(速度最快, 400GT/s per lane)
- 如果这台机器的GPU要和其他机器的GPU进行通信,需要通过网络交换机switch进行连接(速度是 50GT/s per lane)
- 这种硬件层次结构将, 会对实际如何并行化模型产生重大影响
- 核心思想 :单机内部有非常快速的连接,但跨机器时,速度会变慢。
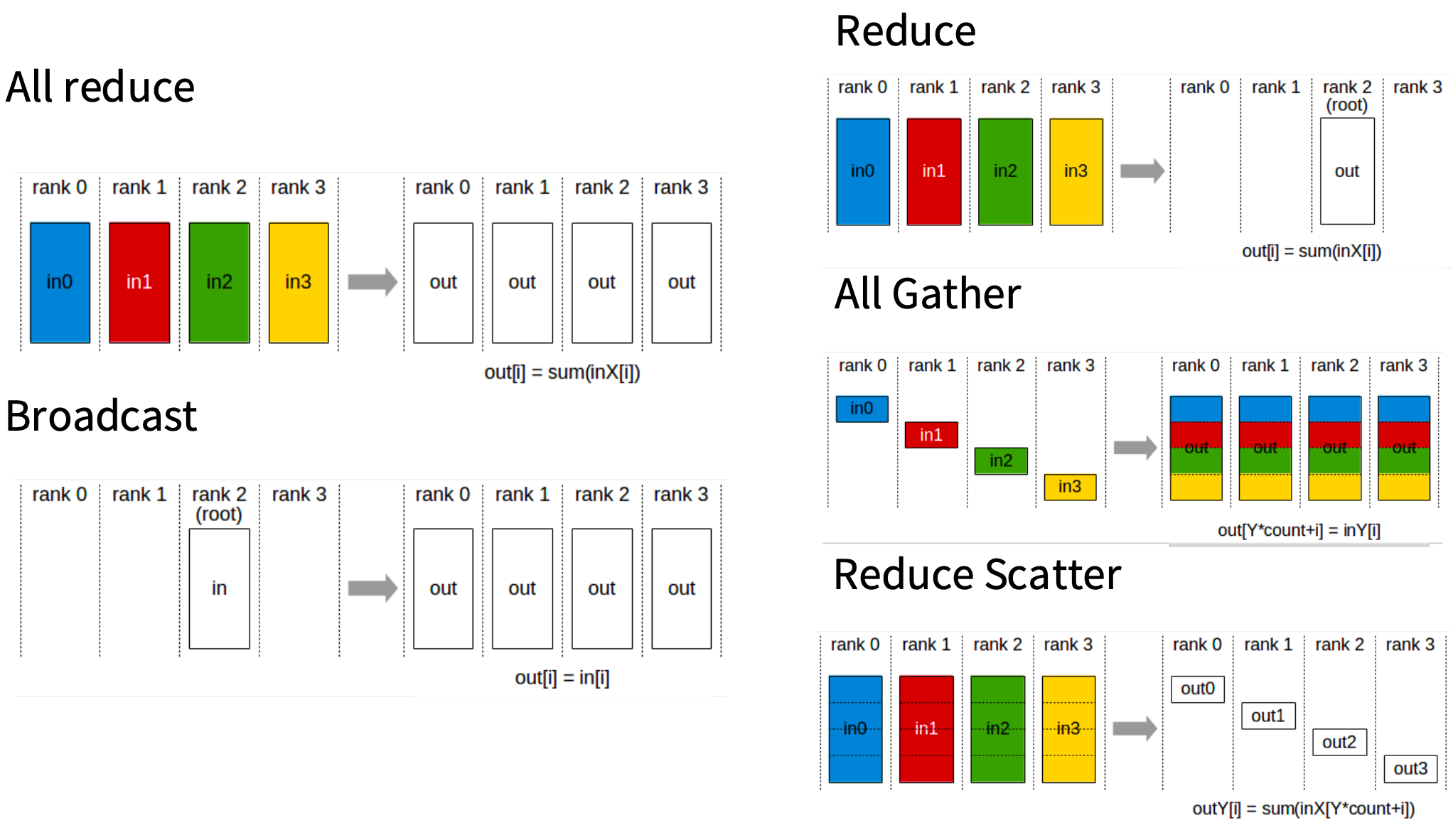
集合通信基础知识
all reduce/broadcast/all gather/reduce scatter
假设你有四台机器,四个rank,每个都有自己的数据片段。
- rank :指参与通信的每个进程(或设备,如 GPU、节点)的唯一标识符,用于在通信过程中标识和区分不同的参与者。
- All reduce:对所有输入求和,然后将结果复制到每台机器。一次all-reduce的通信量是你正在all-reducing的数据量的两倍。
- Broadcast:从 rank 2 获取单个输入, 并复制到所有rank。
- Reduce:对所有数据求和,但结果只发送到一台机器。
- All Gather:从rank 0 获取一个单一的参数子组件,然后复制到所有rank。rank 1、2、3 同理。所以每个rank都在处理参数的不同部分,然后复制到其他所有机器。
- Reduce Scatter:获取每一行,求和后发送到rank 0、1、2、3。注意这里只有每一行的结果。
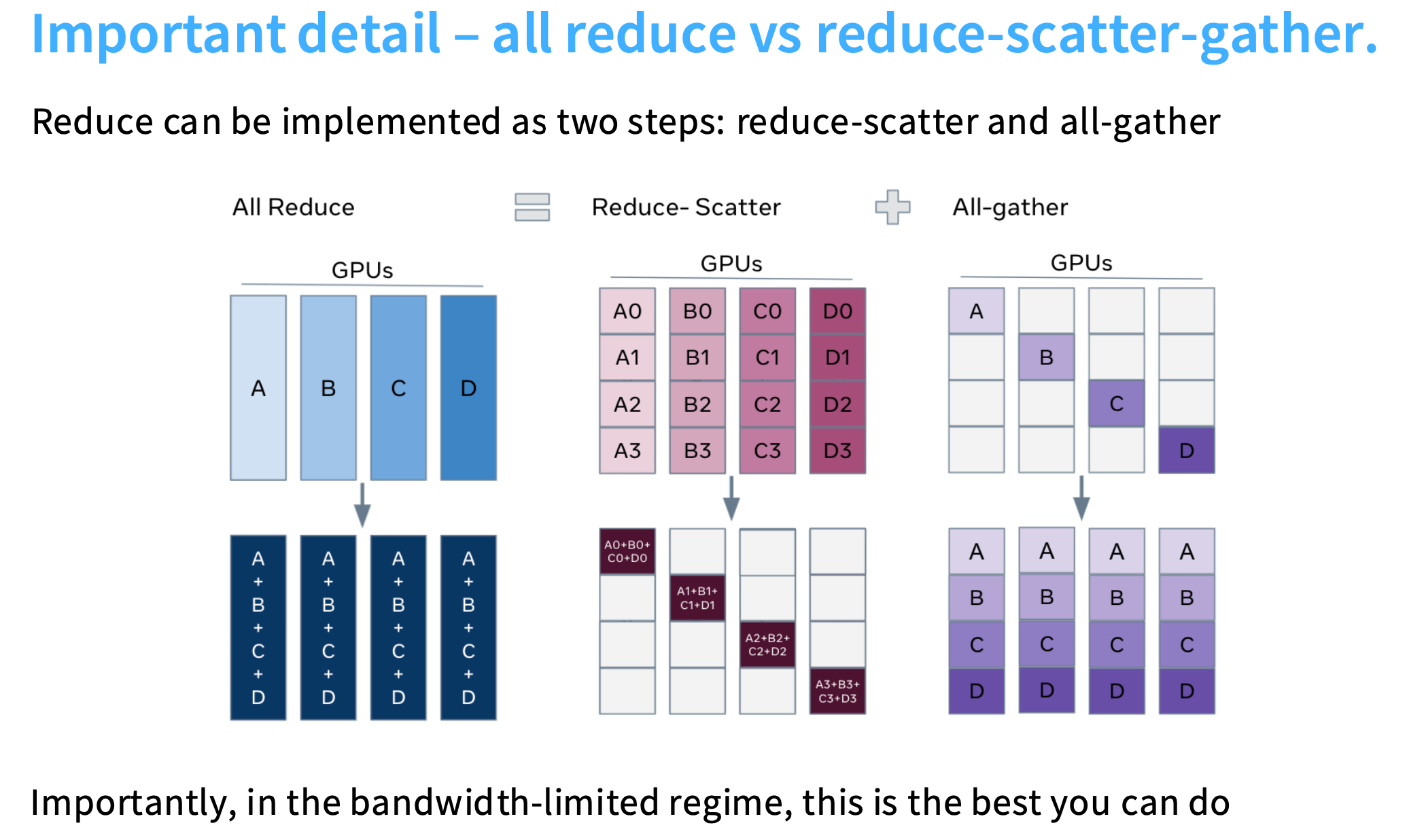
all reduce == reduce-scatter-gather
比如我有不同的GPU,A/B/C/D,每个GPU处理不同的数据点,对于每个数据点都有各自的梯度,现在需要将梯度求和并传回各个GPU。
all reduce 操作可以分解为 reduce-scatter + all-gather。
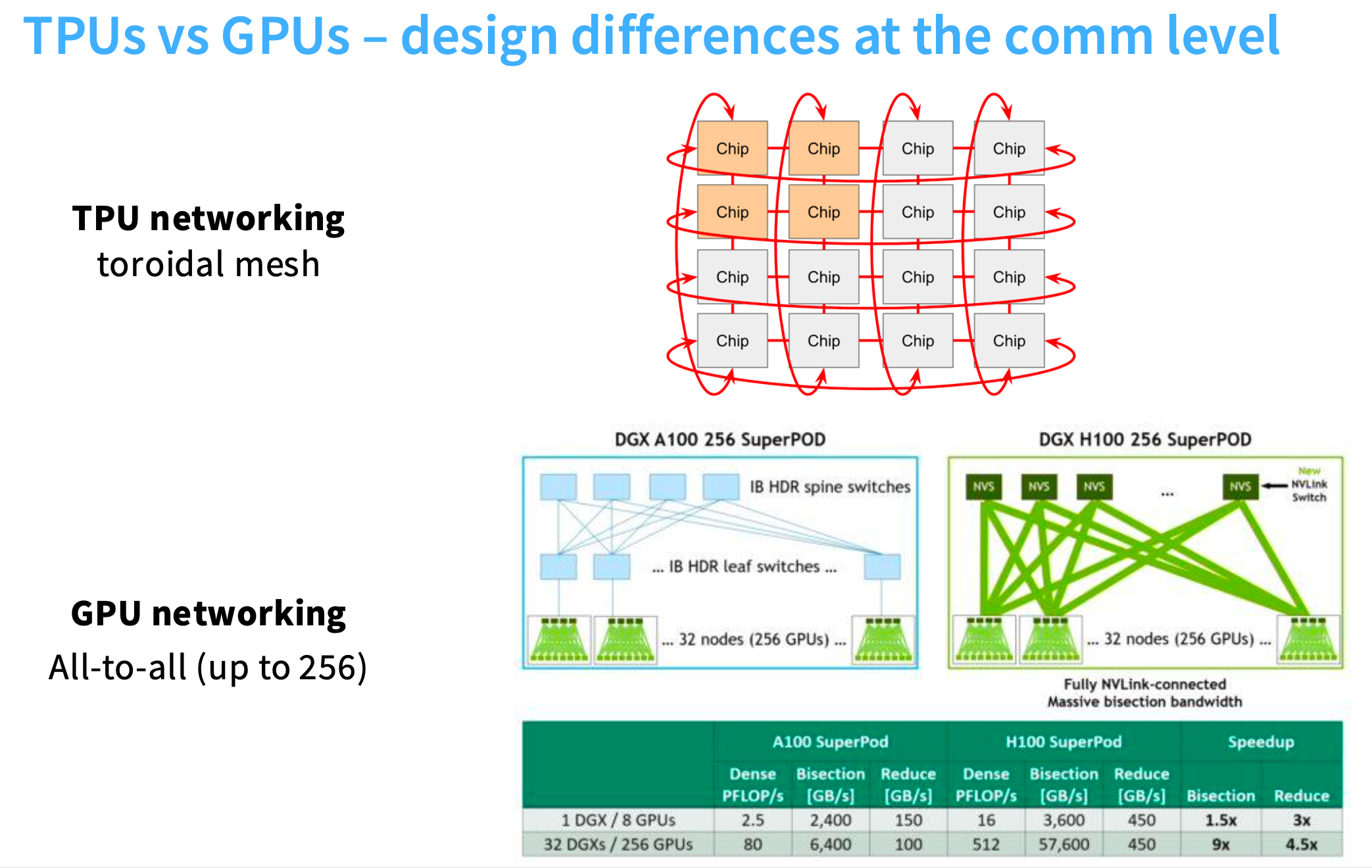
TPU vs GPUs
Q:我们如何将不同的机器或不同类型的GPU连接起来?
A:在《单个训练节点的架构图》一节中可以看到,不同的GPU通过switch连接,最多能实现256个GPU的连接。
TPU的连接:采用TPU chip,可以和邻居连接得非常快,但只能与邻居连接。这种结构被称为环形网格,非常容易扩展。
在做reduce操作时,TPU的chip也很容易做到。
2. 不同的LLM并行训练形式
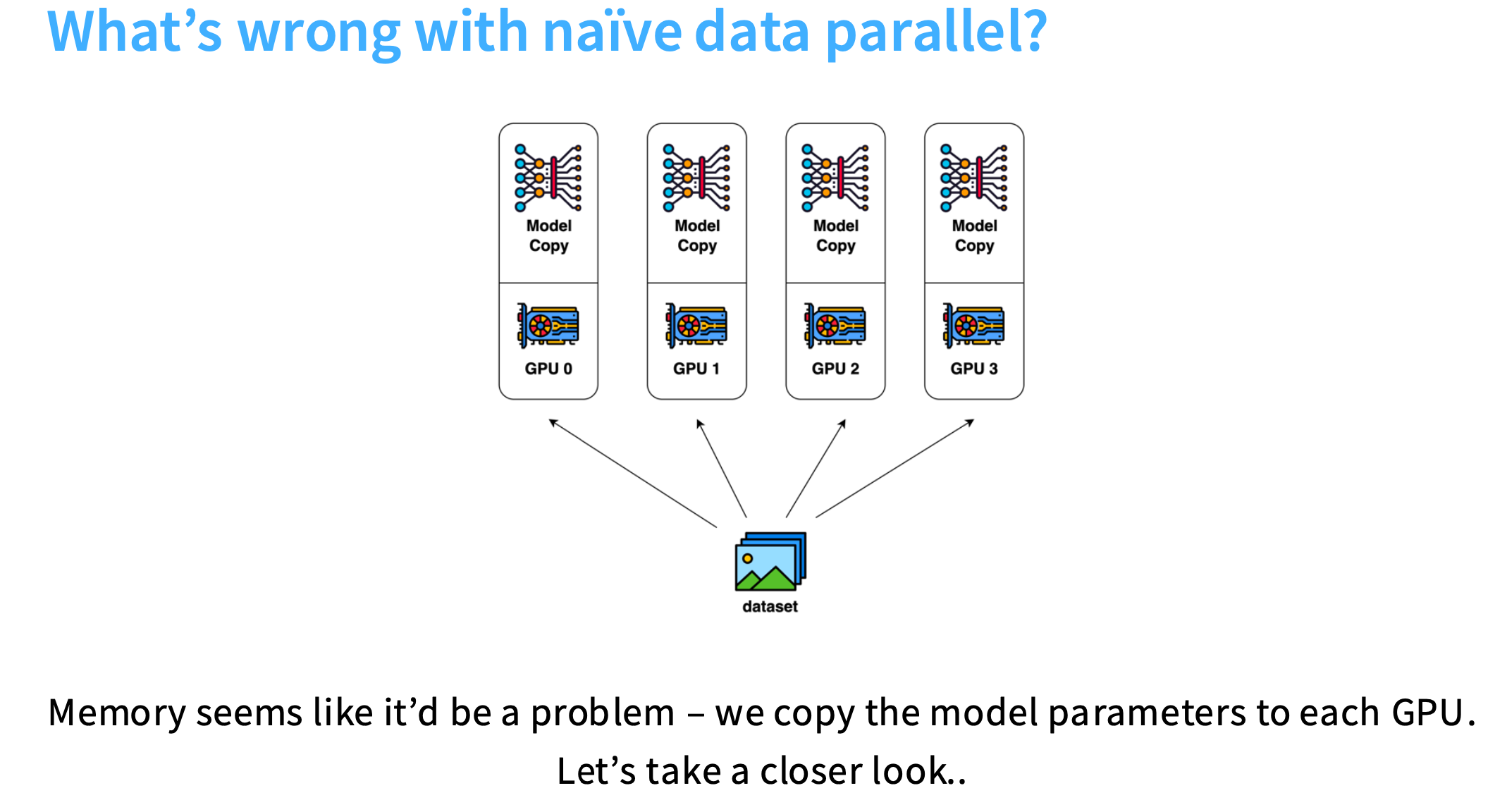
数据并行
核心思想:不同GPU处理数据的不同部分。
朴素的数据并行
以SGD为例,B代表当前batch,在计算梯度时,需要将这一个batch内的梯度求和,再更新 θ \theta θ。
朴素的数据并行,核心思想是,将数据按 batch_size 大小分割后,发送到不同机器,每个机器计算总和的一部分,再在每次gradient step前,交换所有的梯度进行同步,最后进行更新。
每个GPU分到B个样本,如果B足够大,GPU能获得相当不错的batch大小,并能饱和其计算能力。
通信开销:每个批次,都要传输参数量两倍的数据。

缺点-内存占用多
因为每个GPU需要复制参数数量, 还需要复制优化器状态
- 每个参数要存储16字节
- 梯度计算采用BF16,需要2字节
- 优化器状态
- 对于SGD:采用FP32,需要4字节
- 对于Adam:第一个矩估计(因为adam会跟踪历史梯度)需要4或2字节;第二个矩估计(过去梯度的方差)也需要4或2字节

如果绘制到图形中,会发现,大部分内存使用都在优化器状态的存储上。
- K代表优化器状态的字节数
- ϕ \phi ϕ=7.5B,表示75B参数量的模型
- N d N_d Nd表示分布在64个加速器上


ZeRO levels 1-3
ZeRO
ZeRO 是 Zero Redundancy Optimizer(零冗余优化器)的缩写。
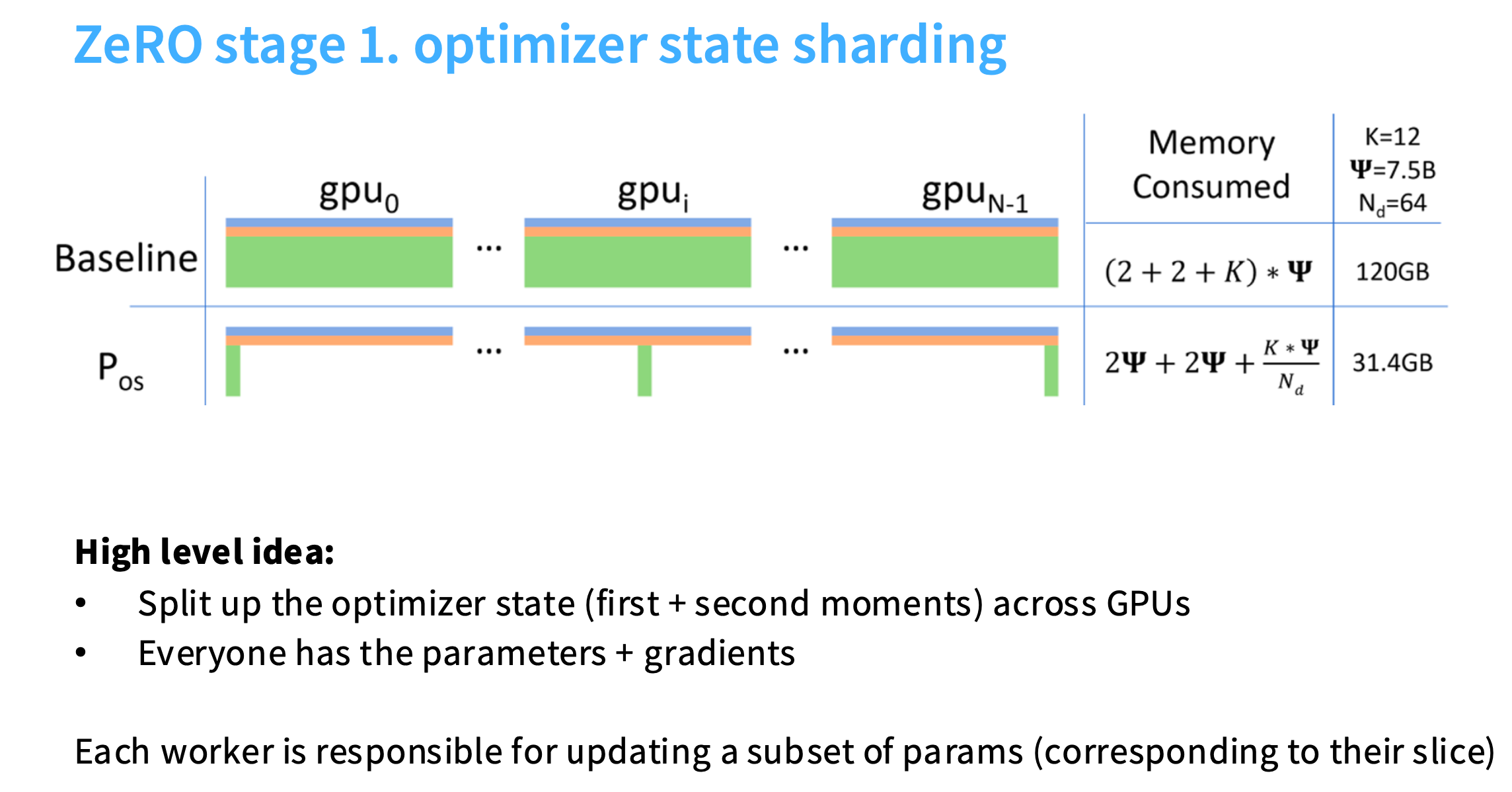
- P o s P_{os} Pos:对优化器状态分片,内存量下降到31.4GB
- P o s + g P_{os+g} Pos+g:对优化器状态+梯度分片,内存量下降到16.6GB
- P o s + g + p P_{os+g+p} Pos+g+p:对优化器状态+梯度+参数分片,内存量下降到1.9GB

ZeRO stage 1
假设现在,adam的优化器状态(一阶矩和二阶矩)分布在所有GPU上,且每个GPU都有完整的参数和梯度,但是无法用梯度去更新参数,除非看到所有的优化器状态。
解决方案是,GPU 0将计算所有梯度,但只负责更新它所拥有的分片的参数,最后再同步回去。
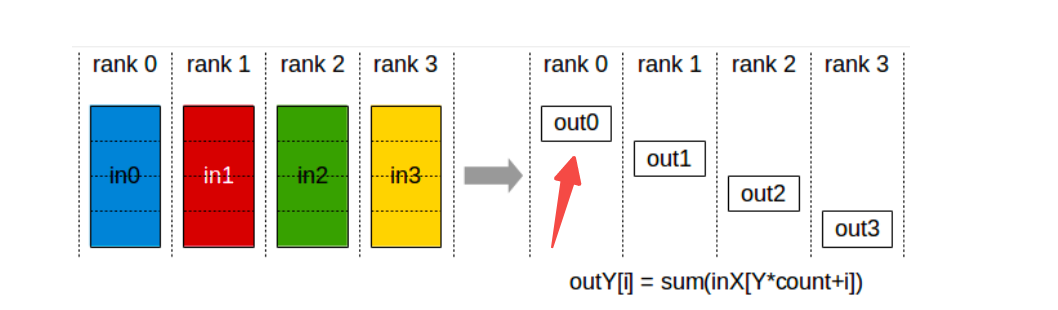
具体步骤
step1. 每个GPU在当前 batch 数据上,计算完整梯度
step2. 对梯度进行reduce scatter,也就是发送梯度,这样会收集每个GPU拥有的梯度。GPU 0负责这部分参数的第一个四分之一,做完reduce scatter,GPU 0能获得针对指定参数的全部梯度信息。
step3. 现在GPU 0 拥有自身参数所需的所有信息,所以可以进行参数更新。
step4. all gather 将更新后的参数发送到所有rank中。
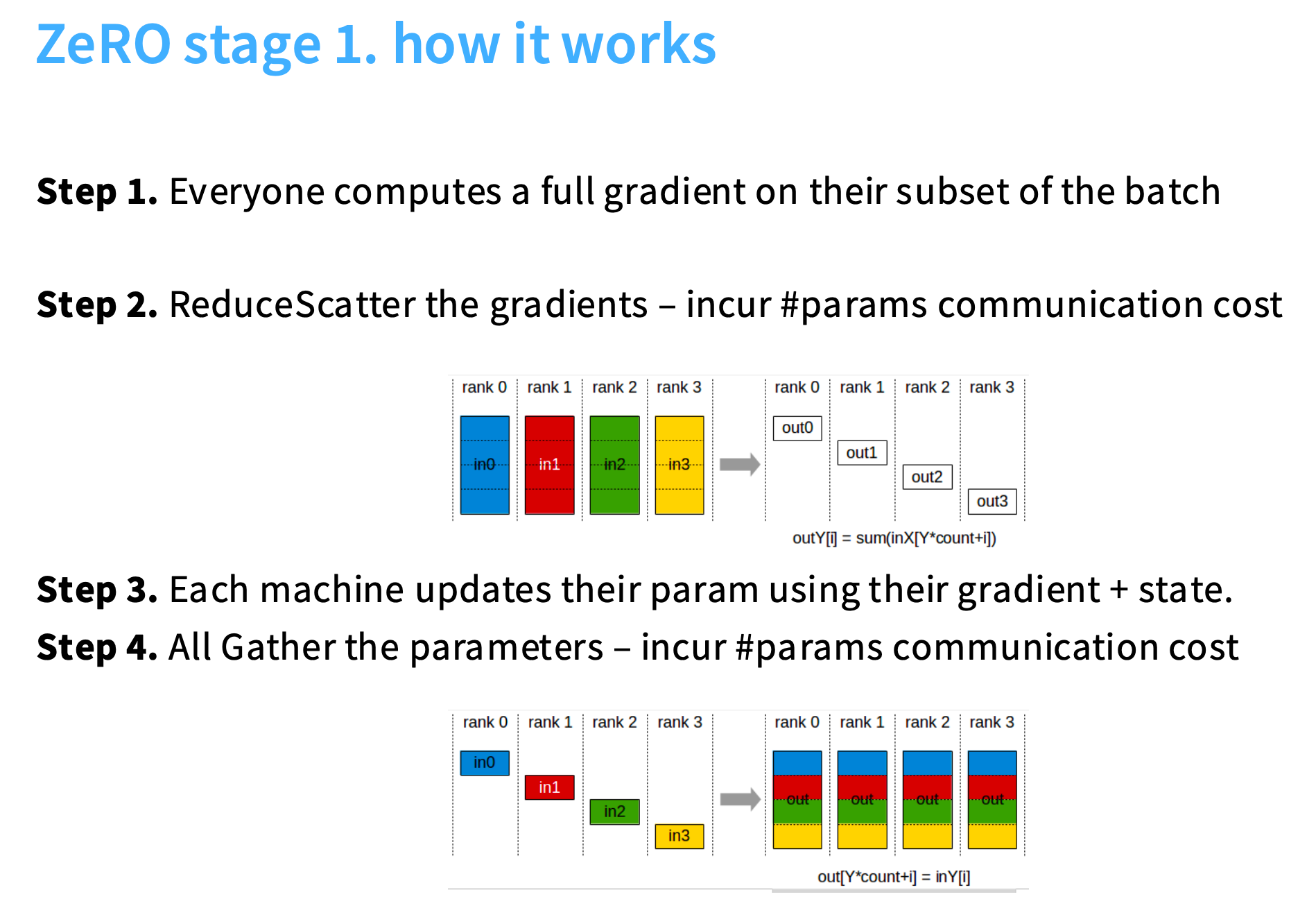
结论 :在内存上,ZeRO stage1可以缩减很多。
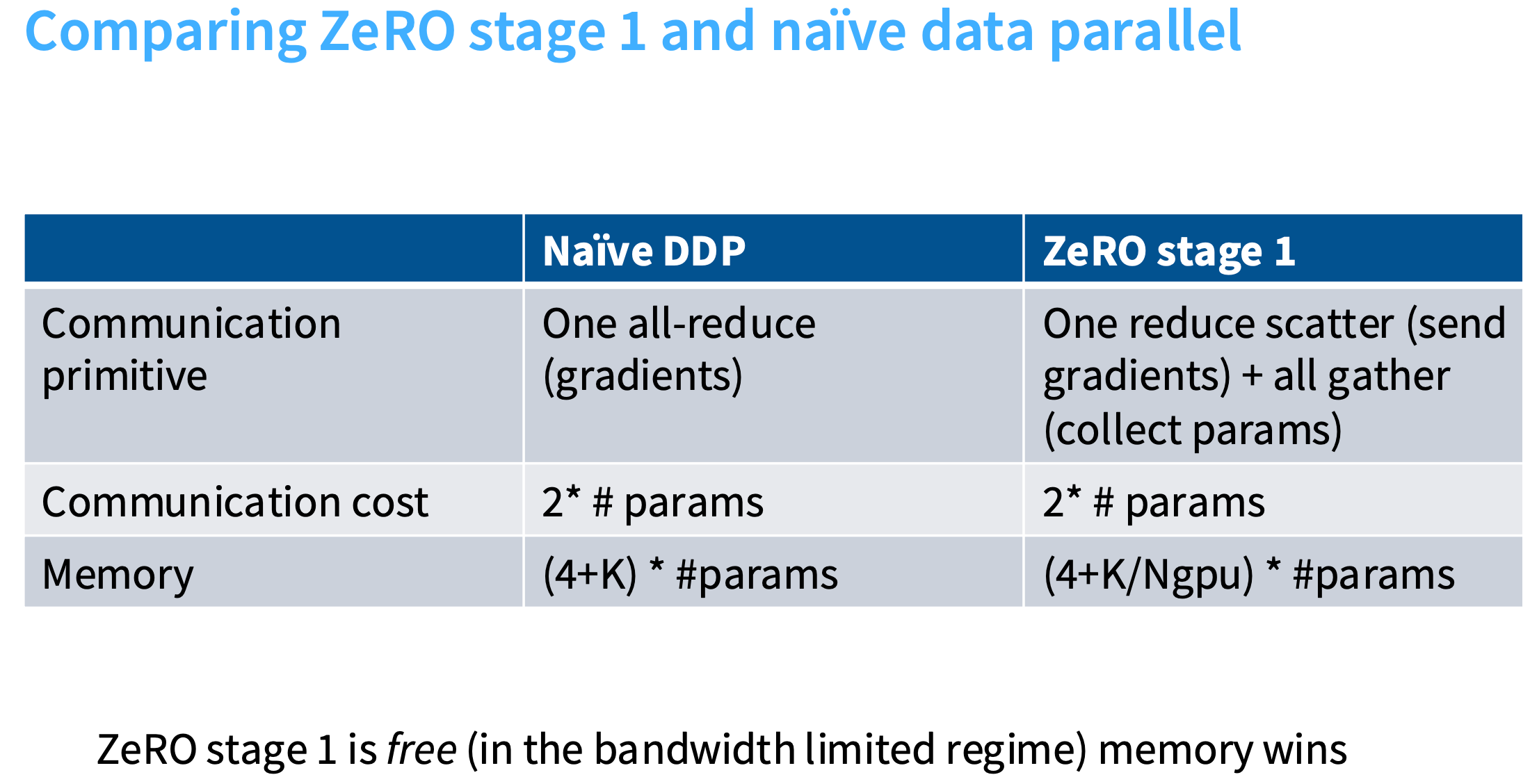
ZeRO stage 2
核心思想:把梯度也分片到每个机器上。
挑战:不能在内存中完整地实例化整个梯度向量。如果执行完整的反向传播过程,并尝试计算并存储完整的梯度向量,就可能内存不足(OOM)。
解决方案:在反向传播过程中,一旦计算出某一层的梯度,就必须把它发送到对应的GPU上。

具体步骤
现在每个进程都有自己的batch数据,每个进程在计算图上逐步反向计算,假设我们要逐层进行操作,所以层会被分片。
step1. 当我们在计算图上反向计算时,计算出一个层的梯度后,立即调用reduce操作,并发送到正确的work节点上。一旦梯度在反向计算图中不再需要,就立即释放内存。如图,计算出梯度后进行reduce,并发送到 rank 2 上,其他 rank 就不再保存梯度。
step2. 每个GPU根据梯度和优化器状态更新参数。
step3. all gather所有的参数。
相比于stage 1,多了逐层同步的开销。

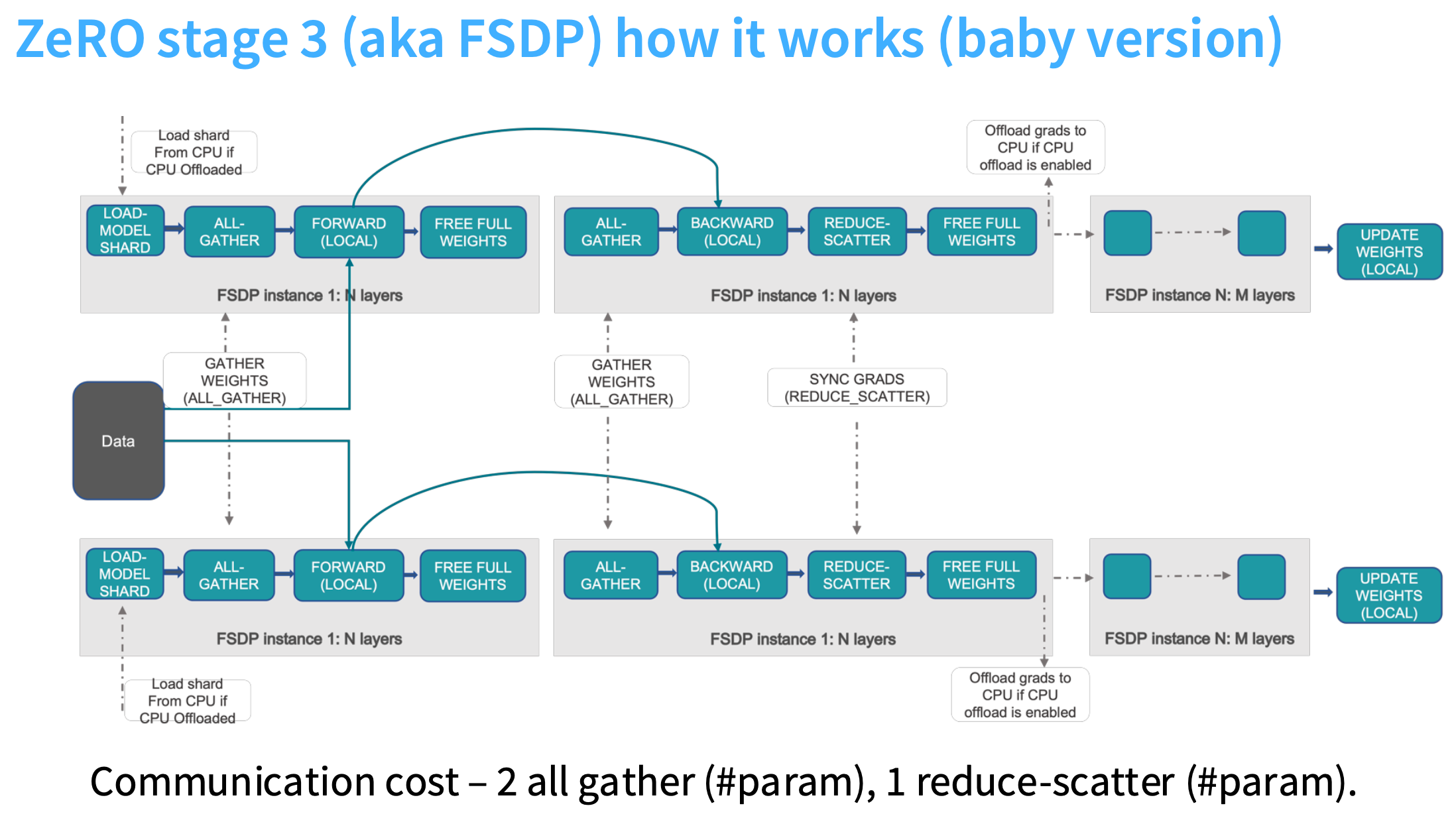
ZeRO stage 3

具体步骤
从左上角开始,先加载模型权重分片(即,参数),这意味着,没有一个GPU会拥有完整权重,也就是无法做到让 GPU 0 跑一个前向计算。此时,GPU 0只拥有最底层 layer 的权重,所以它完成计算,停下来,向其他工作节点请求所有参数。
然后进行all-gather,这样会获得所有参数。
接着进行FORWARD,前向计算完,再释放所有权重。
然后再进行下一层 layer 的计算,以此类推。
注意:激活值需要存储
一旦运行到最后,就开始反向传播,首先对需要的参数进行all-gather,执行完 BACKFORWARD 后,进行reduce-scatter操作来更新模型。最后释放不再需要的梯度和参数。
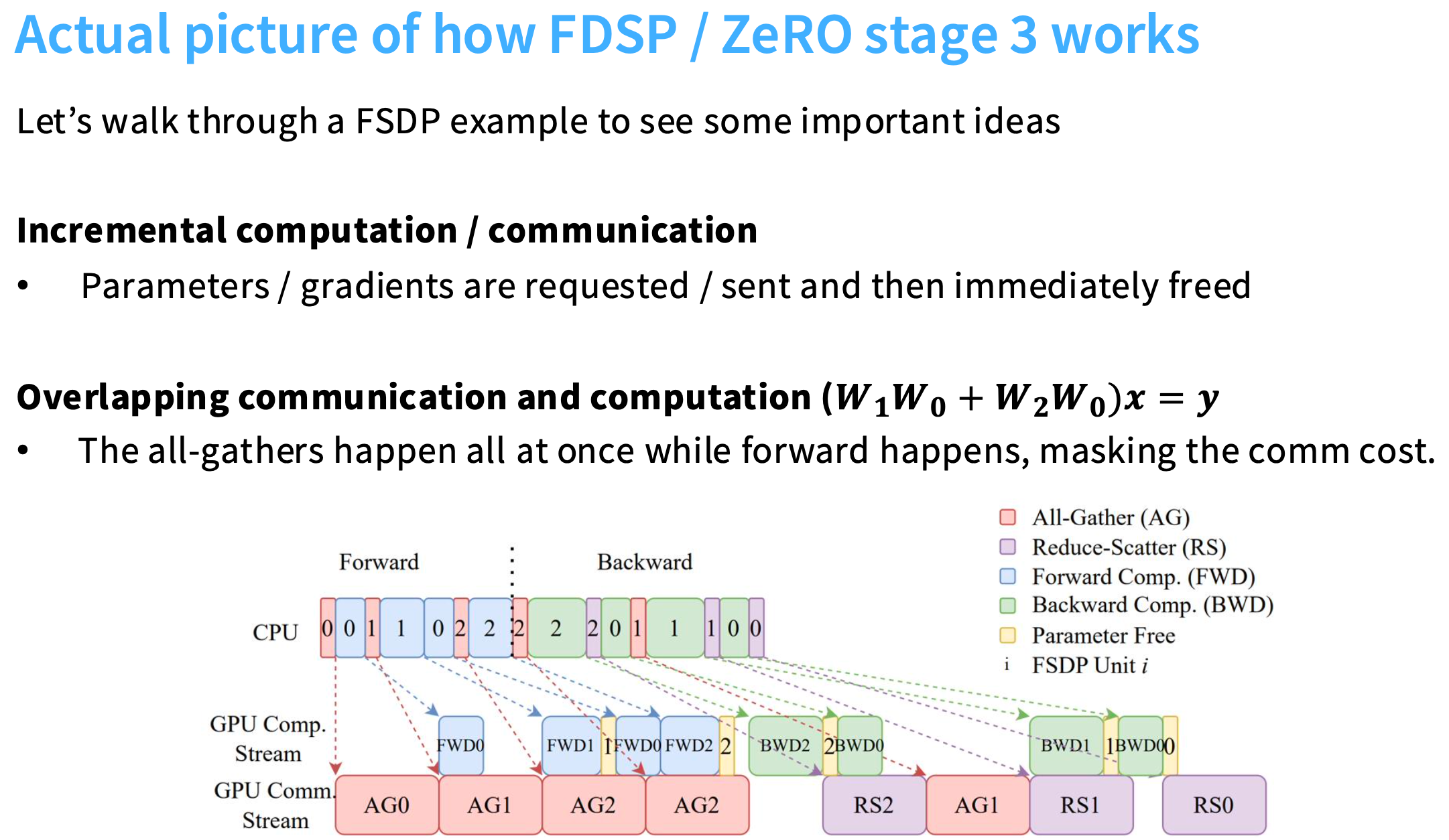
FDSP(FullyShardDataParallel)效率高的关键:让通信和计算同时进行。
CPU会分派一些命令,要求GPU的通信部分去获取一些参数、让GPU去执行一些矩阵乘法。
在最开始,先确保每个节点都有第0层( W 0 W_0 W0)的权重,然后执行AG0(All-Gather 0)并等待它完成。接着,在 W 0 W_0 W0上执行 FWD0(Forward 0,正向传播)------计算 x 乘以 W 0 W_0 W0。
AG1在AG0结束时就启动了,在进行矩阵乘法时,GPU开始加载所需的下一个参数。AG1执行完,FWD1和AG2都开始执行。黄色区域1 释放的是,与FWD 1相关的参数。
另外,由于重复计算 W 0 W_0 W0,无需再次通信,所以在黄色区域1 后紧跟着FWD 0。
由于已经加载了FWD2的参数(AG2在FWD2之前),所以在执行FWD2时不需要等待。然后就可以释放与FWD 2相关的参数了。
反向传播时,进行RS和AG。
核心思想:在实际需要权重之前,就将权重请求进行排队,就可以避免很多与通信相关的开销。
-
ZeRO stage 1:基本是零成本的,采用的通信模型与朴素数据并行相同,但可以分片优化器状态。
-
ZeRO stage 2:通信量是参数量的两倍,所以总带宽消耗是相同的。但在反向传播时,必须逐步释放梯度,这会产生额外的开销。
ZeRO-2 中 "通信量是参数量的两倍",是因为梯度和优化器状态的分片存储需要两次独立的通信(各 1 倍参数量);而 "总带宽消耗相同",是因为虽然通信次数增加,但每次通信的数据量按并行度分摊,总数据传输量与朴素数据并行等方案相当,因此整体带宽需求并未增加。
-
ZeRO stage 3: 通信量是参数量的三倍。
数据并行的优点 :不依赖于模型架构

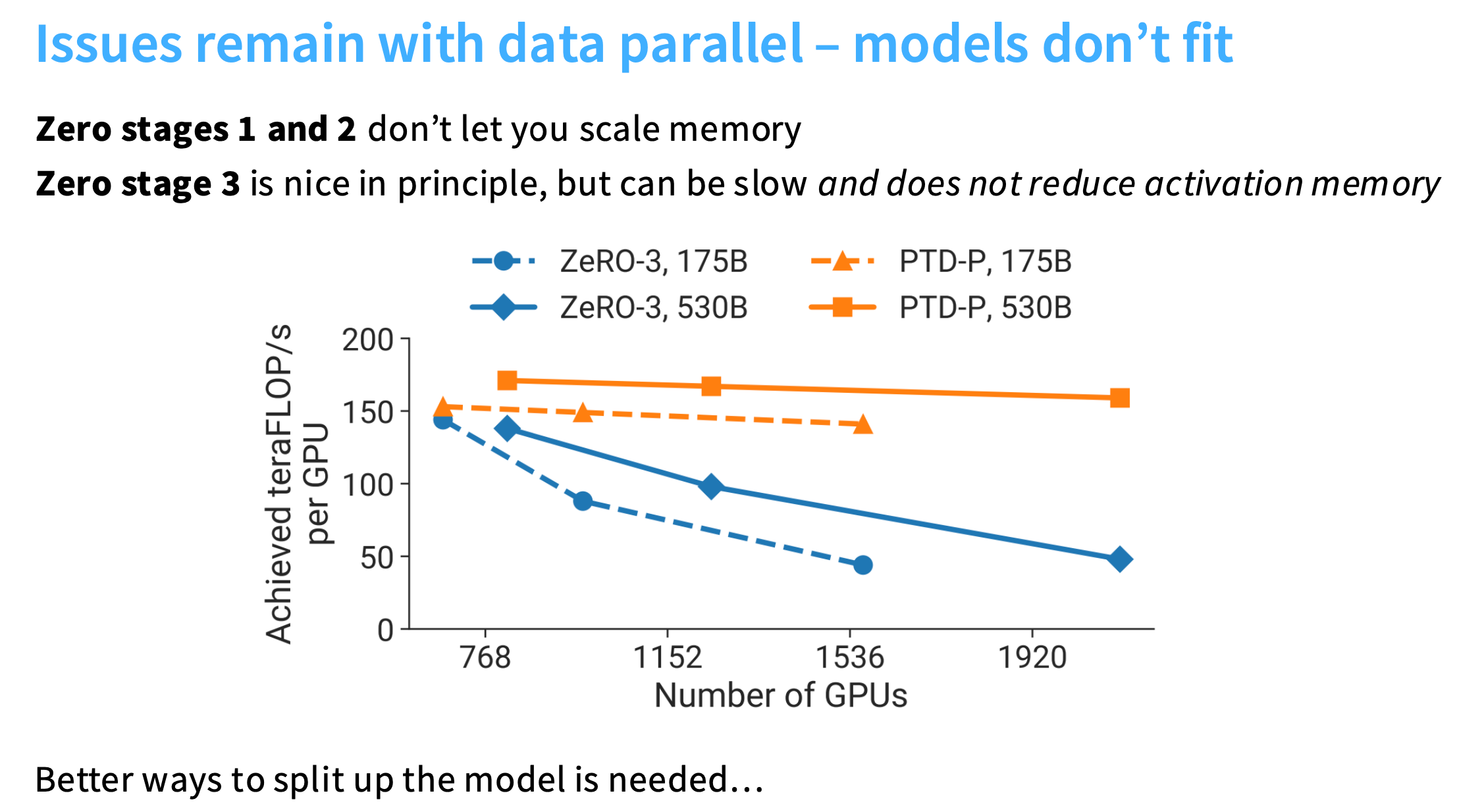
可以看到Baseline只能运行60亿参数的模型,但是Zero stage 3可以运行530亿参数的模型!
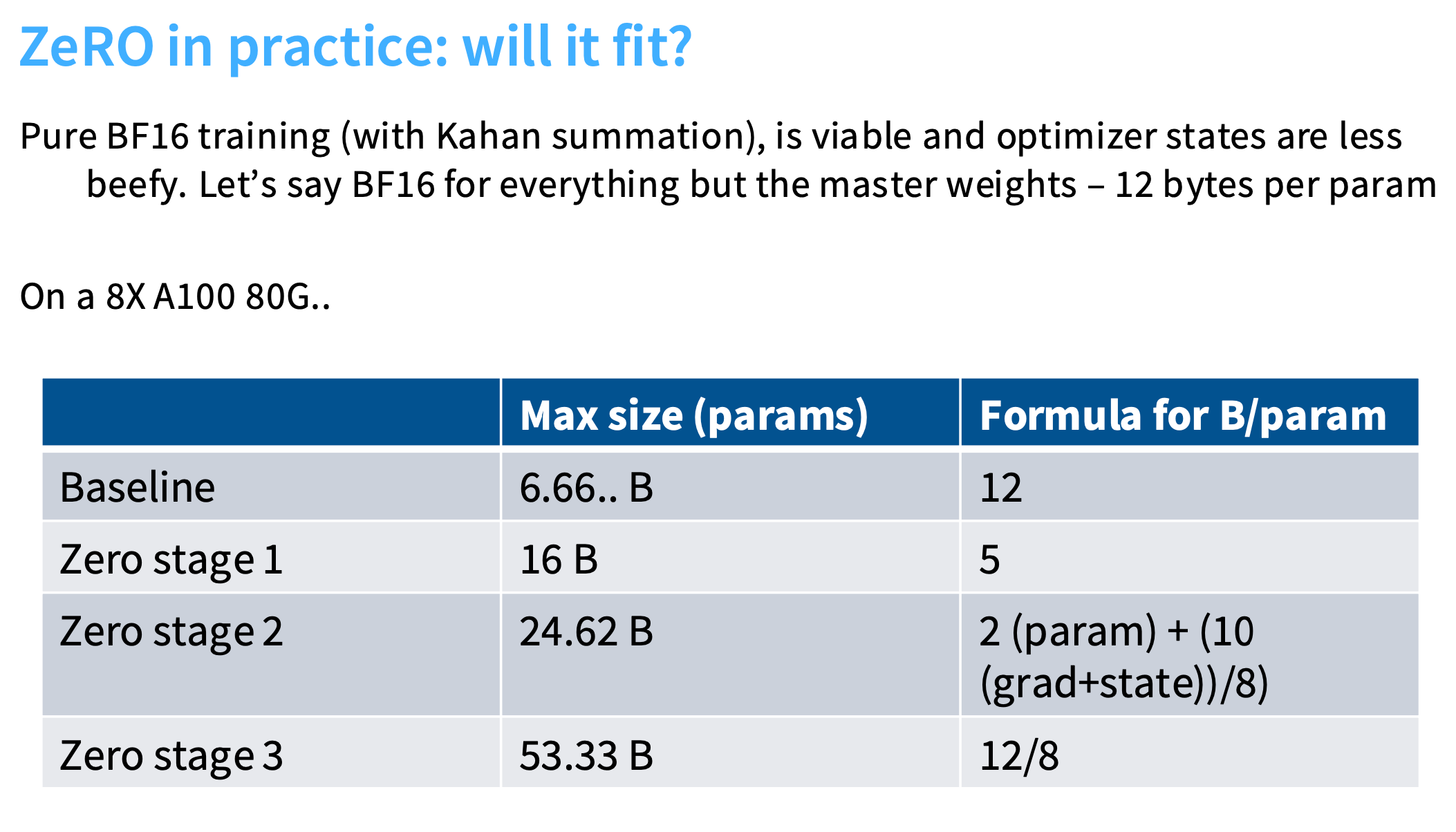
对于数据并行,batch size是一个非常关键的资源,当超过一定阈值,收益就会递减。
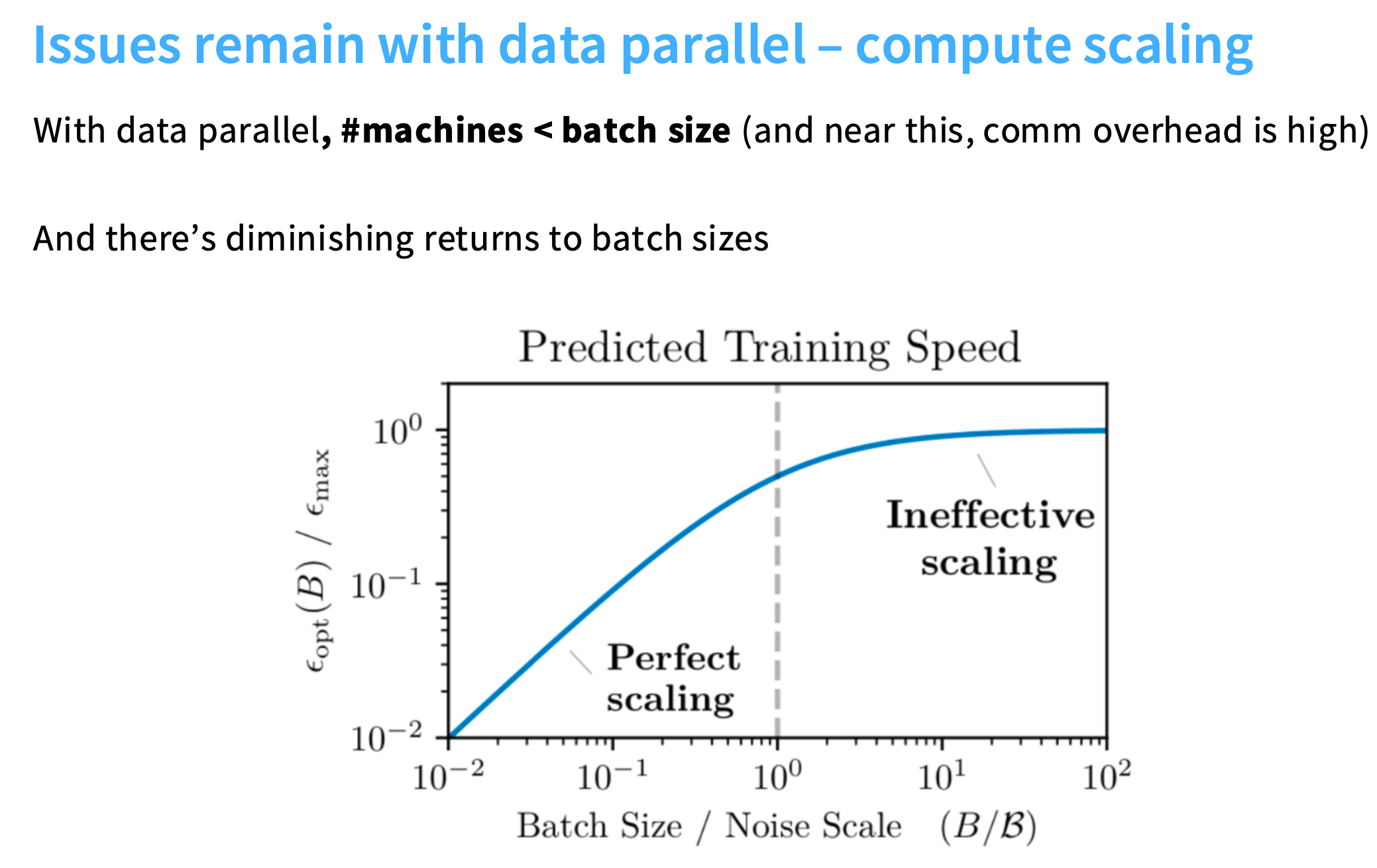
数据并行的缺点
- ZeRO-1和ZeRO-2不允许扩展内存
- ZeRO-3可能会很慢,因为不减少激活内存
模型并行
核心思想:不同GPU处理模型的不同部分。
目标:在不改变batch size大小的情况下扩展内存。
实现:将参数分割到各个GPU上,但不再传递参数,而是传递激活值。

朴素的想法:按层并行
每个GPU处理一层layer,GPU之间相互传递激活值。反向传播时,反向梯度会从GPU3传递到GPU0。
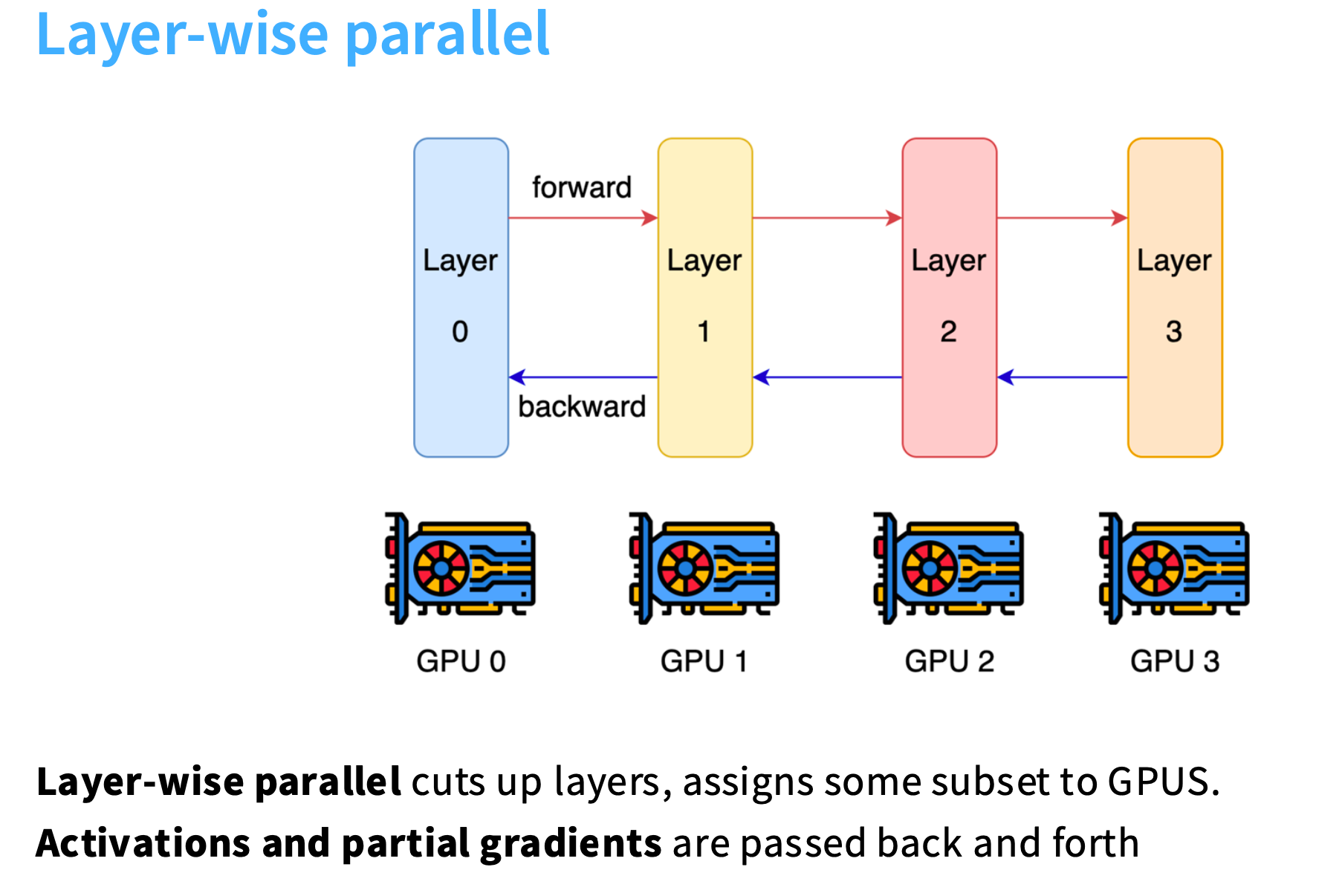
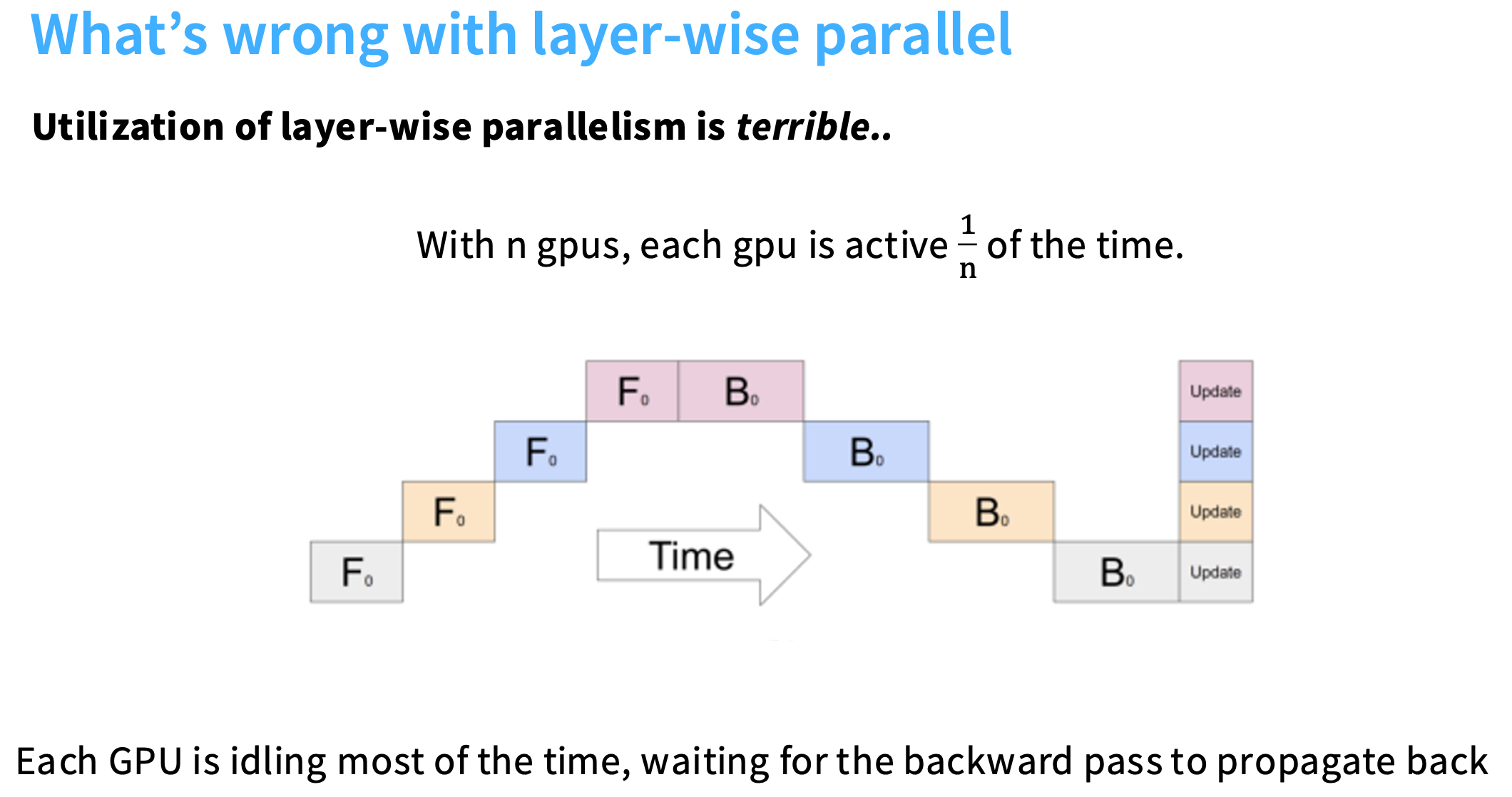
缺点: 大部分时间里,GPU都是空闲的,利用率很低。
下图中不同行代表不同的层,也代表不同的GPU。横轴表示时间,从做向右推进。执行 F 0 F_0 F0的GPU要等到最后才能执行 B 0 B_0 B0。
虽然有四个GPU,但吞吐量只有一个GPU的水平。
pipeline 并行/流水线并行
假设我有一个mini batch,也就是4个样本。首先执行第一个样本的 F 0 , 0 F_{0,0} F0,0,然后把它的激活值发送到 F 1 , 0 F_{1,0} F1,0(第二个GPU),同时第一个GPU在处理第二个样本的 F 0 , 1 F_{0,1} F0,1。
这样通信和计算就重叠了。如果你有很大的batch size,流水线并行可能会很有效。但是batch_size是有限的。
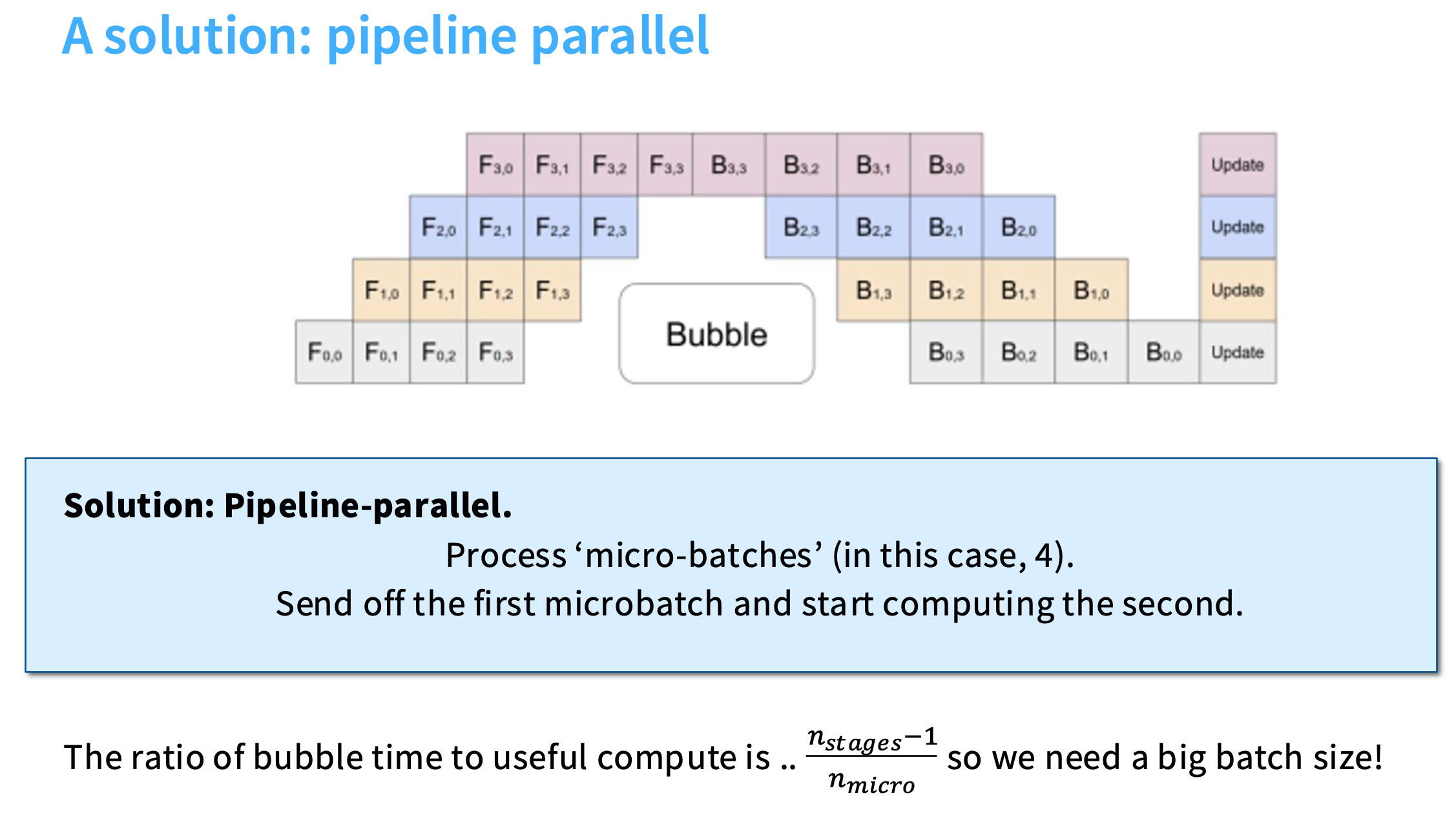
流水线并行的优点
- 和数据并行相比,可以节约内存。ZeRO-3和流水线都会对参数分片,但是流水线并行还能对激活值分片。
- 流水线并行的通信性能很好,通常会用在较慢的网络链路上,比如节点间、跨越不同的数据中心
- TPU的一个巨大优势在于,不必过多地使用流水线并行,因为所有连接的带宽都大得多。

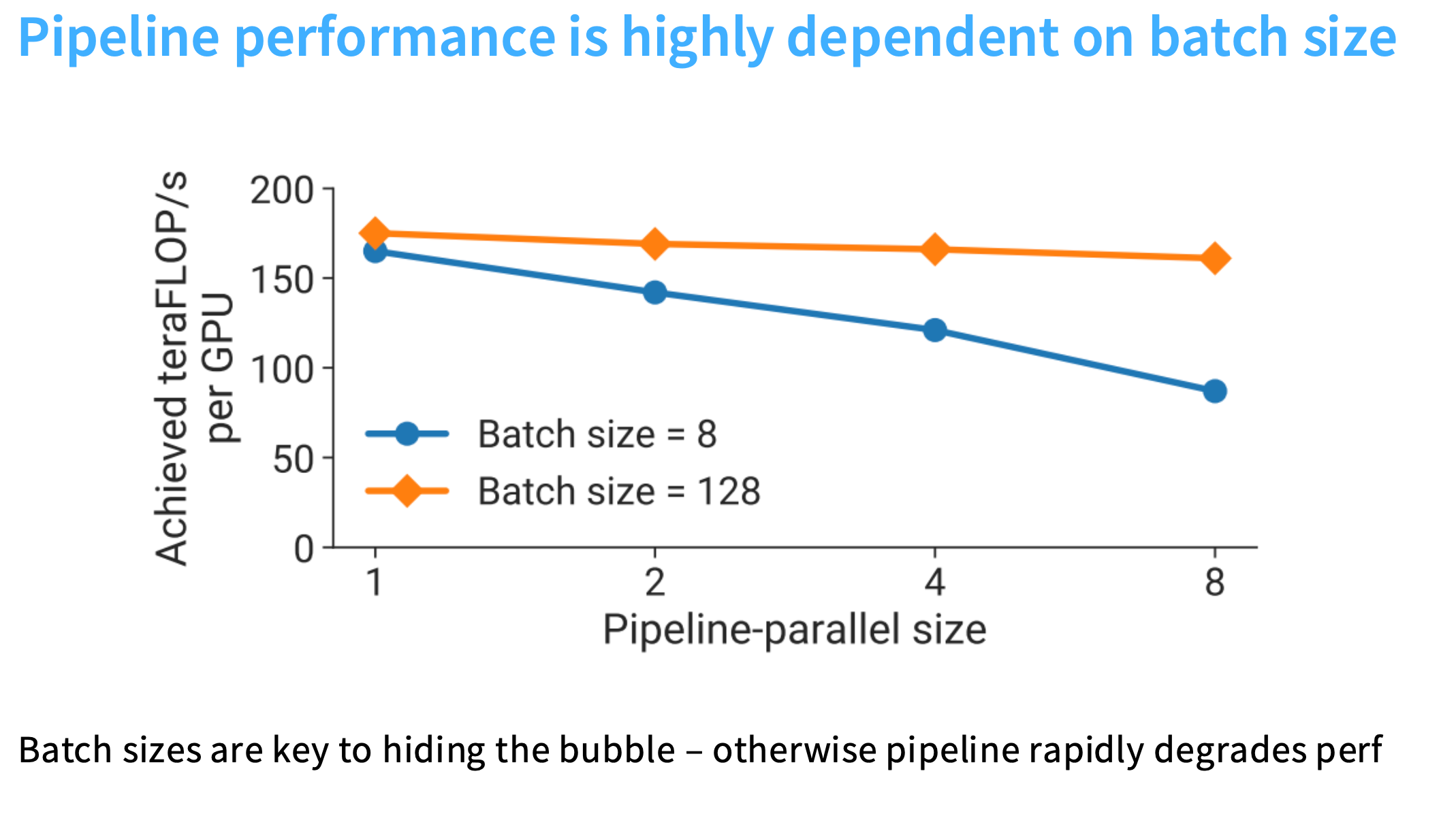
当batch_size为8时,随着增加流水线并行的大小,即增加GPU数量,GPU的利用率开始大幅下降。
当batch_size为128时,GPU的利用率很不错。
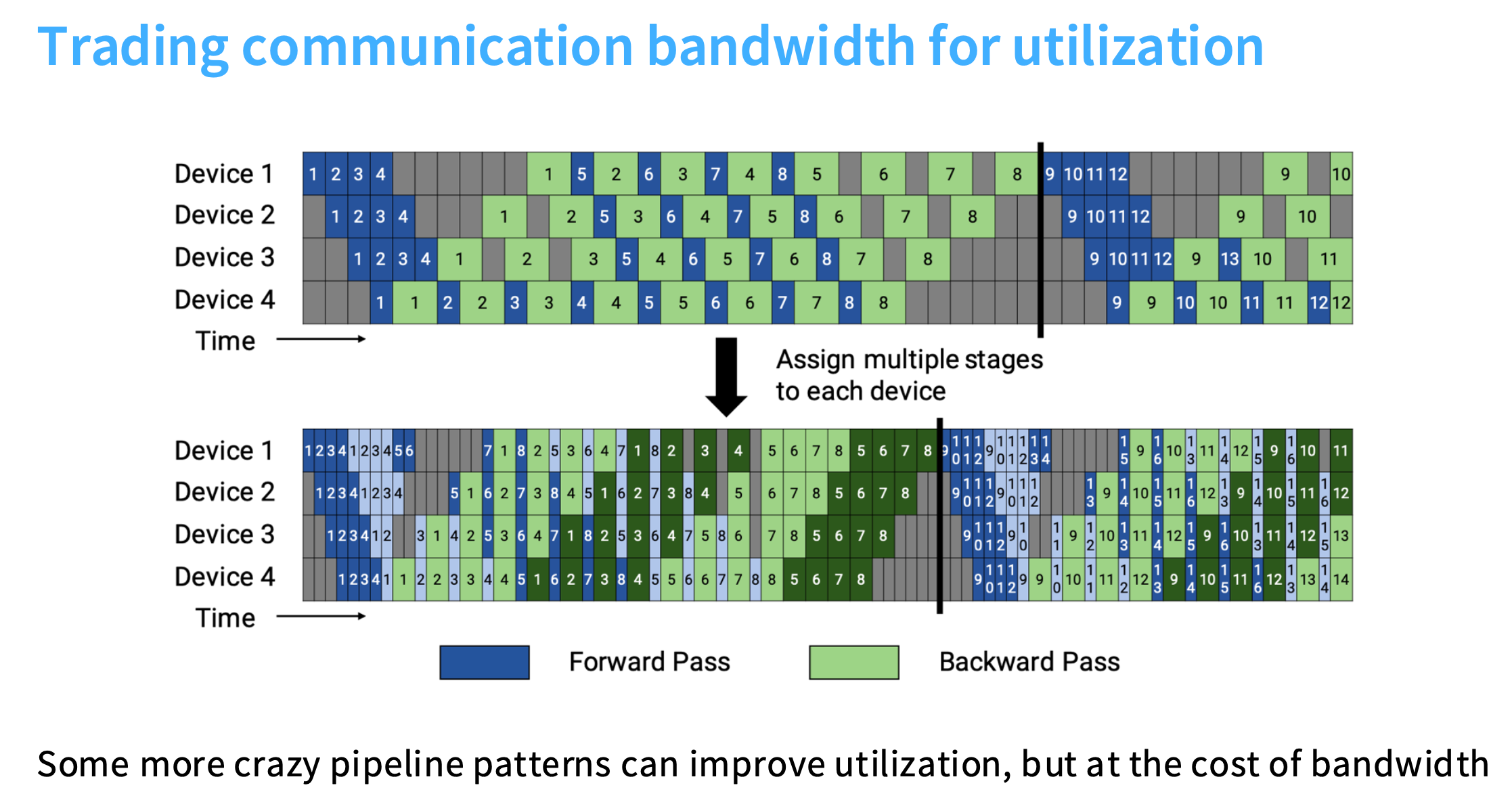
实际使用时,可以采取不同类型的流水线策略。上半部分展示的是标准大小的划分。下半部分展示的是,将任务切成更细的块,在不同的阶段、不同的子层,分配给不同的设备,并在不同的部分执行不同的计算。
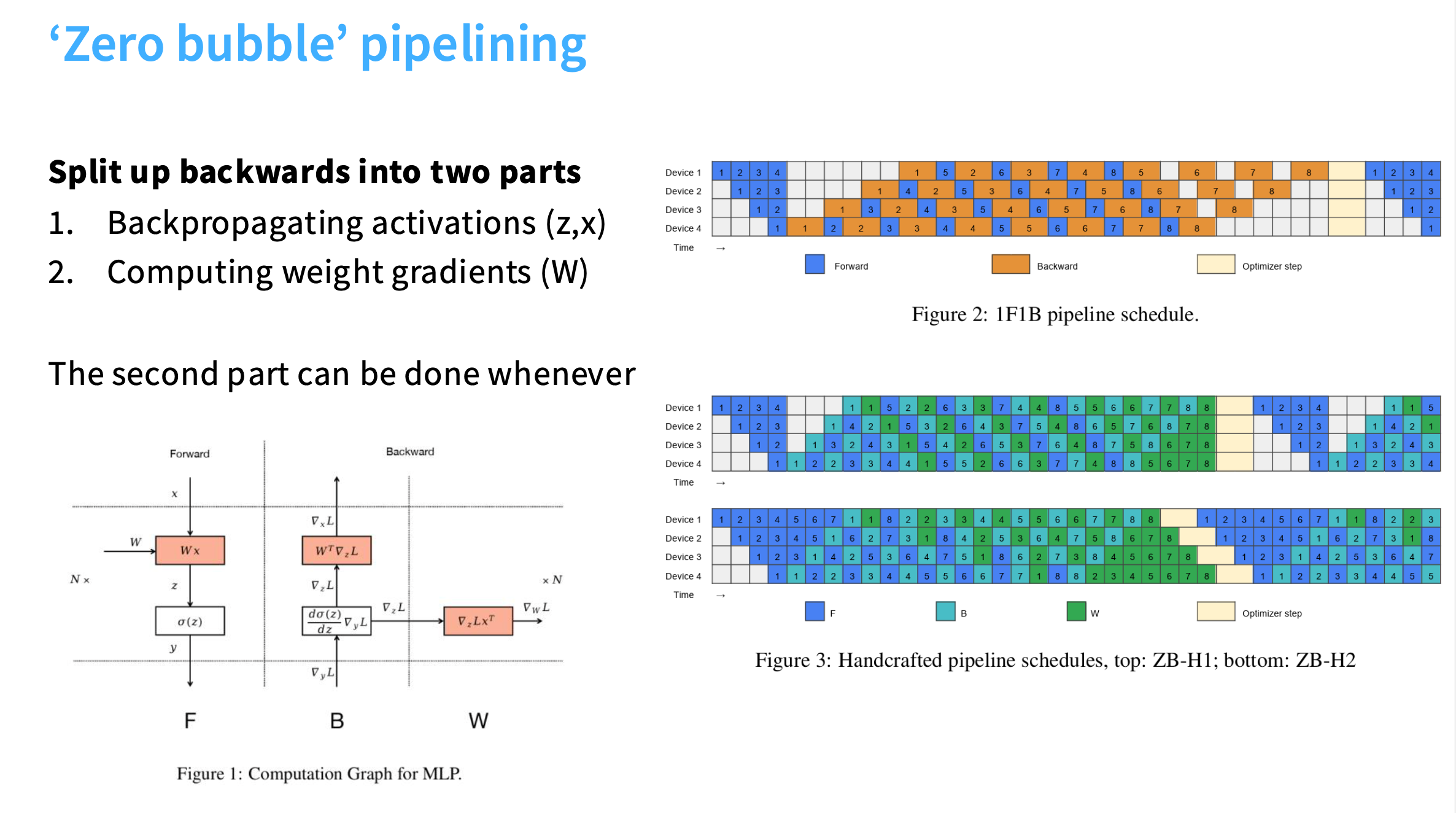
Zero bubble 流水线并行/ DualPipe
Zero bubble 是指中间的等待时间为0。
假设正在进行反向传播,包含两部分:
- 反向传播激活值(z,x):当沿着残差连接向下传递时,需要计算关于激活值的导数。图中左下角 B 列
- 计算权重梯度:当到达参数时,计算参数的梯度,也就是计算如何更新参数,而不仅仅是激活值如何随前一层变化。图中左下角 W 列。特点是没有依赖性,所以可以将这个计算的调度安排在计算图的任何部分。
对有串行依赖的部分可以用标准的流水线,但计算权重梯度这类只是为了更新参数的计算,可以安排到任何地方。
相比于 Figure 1的标准流水线并行调度,Figure 3将B的部分拆解成B和W。
流水线并行是沿着深度维度(比如layer)进行切分,而张量并行是沿着矩阵乘法的宽度维度进行切分。
tensor 并行/张量并行
将一个大的矩阵乘法,分解成一组可以相乘的子矩阵。
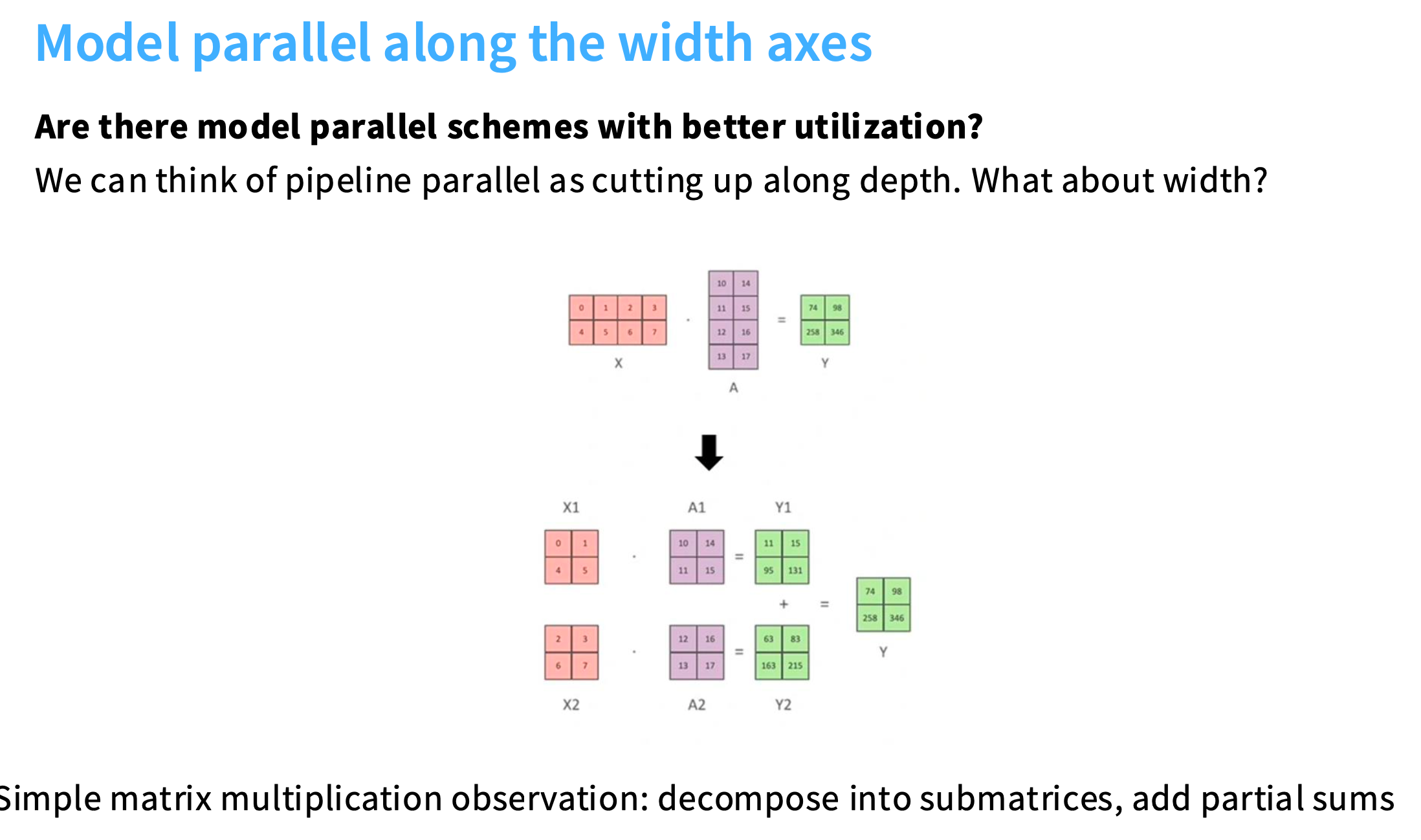
每个GPU处理不同的子矩阵。比如大型MLP矩阵乘法中的子矩阵,计算完,进行集体通信(reduce、gather等)来同步激活。
在下图的例子中,A被切成了A1、A2,B被切成了B1、B2。前向传播时,把X复制两次,分别和A1、A2进行操作,它们的行维度是相同的。接着分别得到激活值Y1、Y2,和B1、B2分别相乘,得到Z1、Z2,最后经过all-reduce将它们加起来。
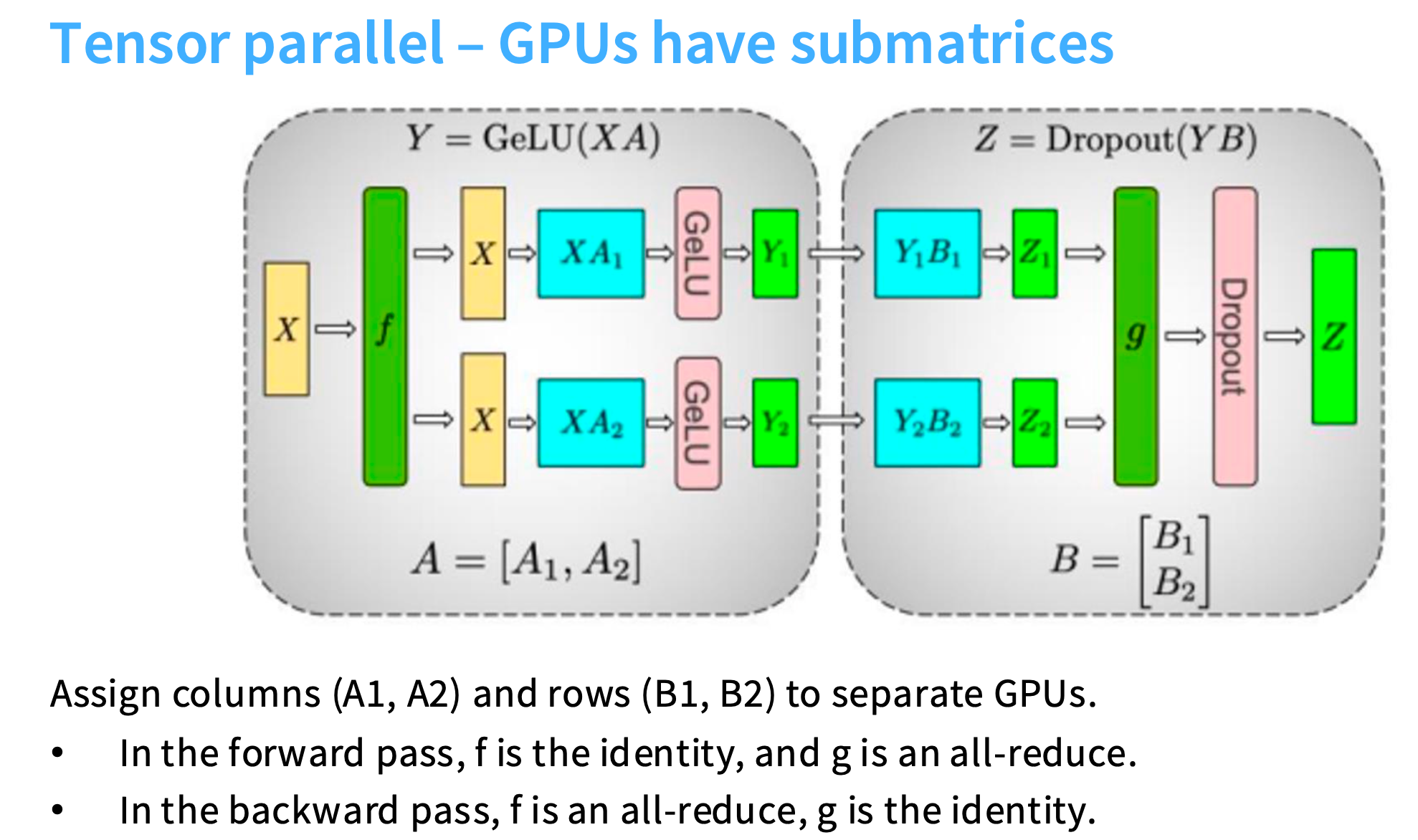
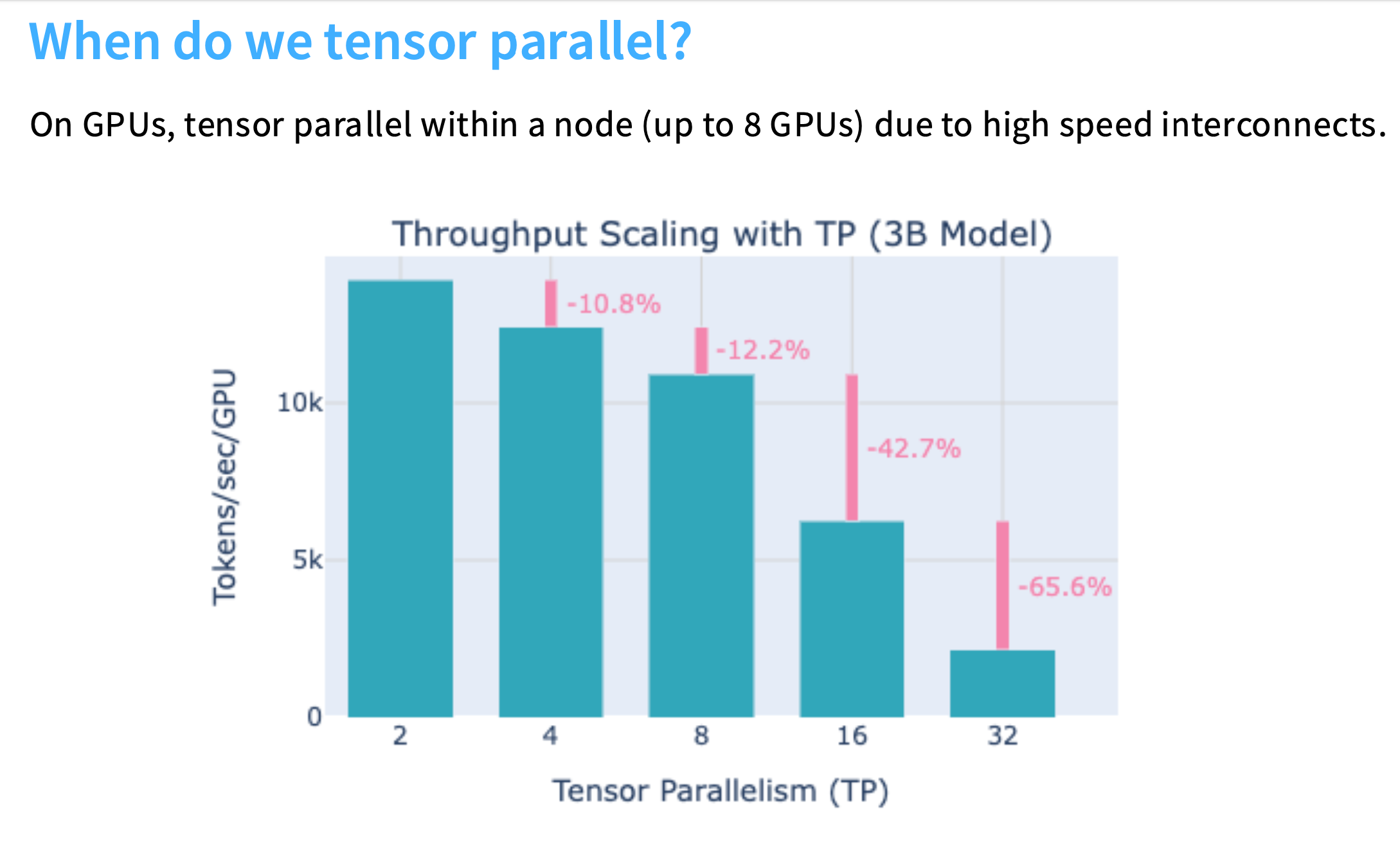
何时使用
张量并行需要非常高速的互联。有一个经验法则是,张量并行时被应用到最多8个GPU,这8个GPU在同一台机器中。
因为张量并行是在设备内部或单个节点内部应用的,比如一台机器内有8个GPU,GPU之间通过NVSwitch可以快速的连接。
张量并行 vs 流水线并行:优缺点
优点:
- 不必处理气泡问题,不需要增大batch_size来减少气泡问题。
- 低复杂度。只需要知道大的矩阵乘法在哪里,能否拆分它们并运行在不同设备上,前向和后向操作不变。
- 不需要很大的batch_size,也能工作得很好
缺点:
- 比流水线并行需要更大的通信开销
- 流水线并行的通信量:batch_size * seq_len * 残差维度,是点对点通信
- 数据并行的通信量:每层通信是流水线并行的8倍,而且还要进行 all-reduce 通信

激活并行
核心思想:管理激活的内存占用
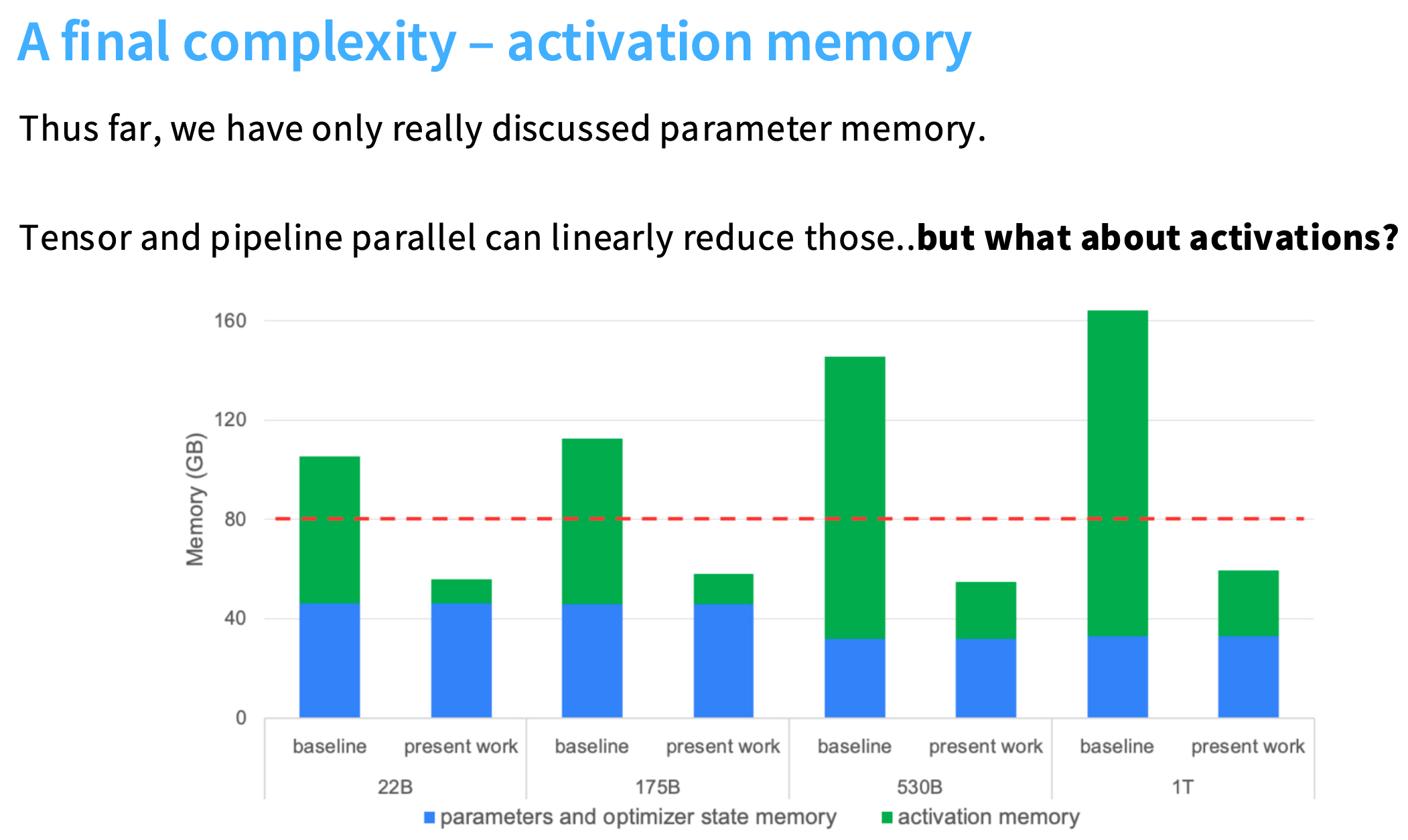
张量并行和流水线并行可以减少内存占用,但是无法减少所有激活值的内存使用量。
如下图,当模型越来越大时,参数和优化器内存占用基本不变,但是激活值的内存却持续增长(只看baseline或present work)。
如果采用重计算,可以保持激活值的内存占用较低。
每一层激活值内存如何计算?
左边的项: s b h ∗ 34 sbh*34 sbh∗34,sbh来自mlp和其他点乘操作。
右边的项: s b h ∗ 5 a s h = 5 a b s 2 sbh * 5\frac{as}{h} = 5abs^{2} sbh∗5has=5abs2,这是softmax所需的内存以及注意力机制中的其他二次项。
计算公式可见 详解 Transformer 激活值的内存占用公式
如果使用flash attention,可以大幅减少,并利用重计算也可以大幅减少第二项。

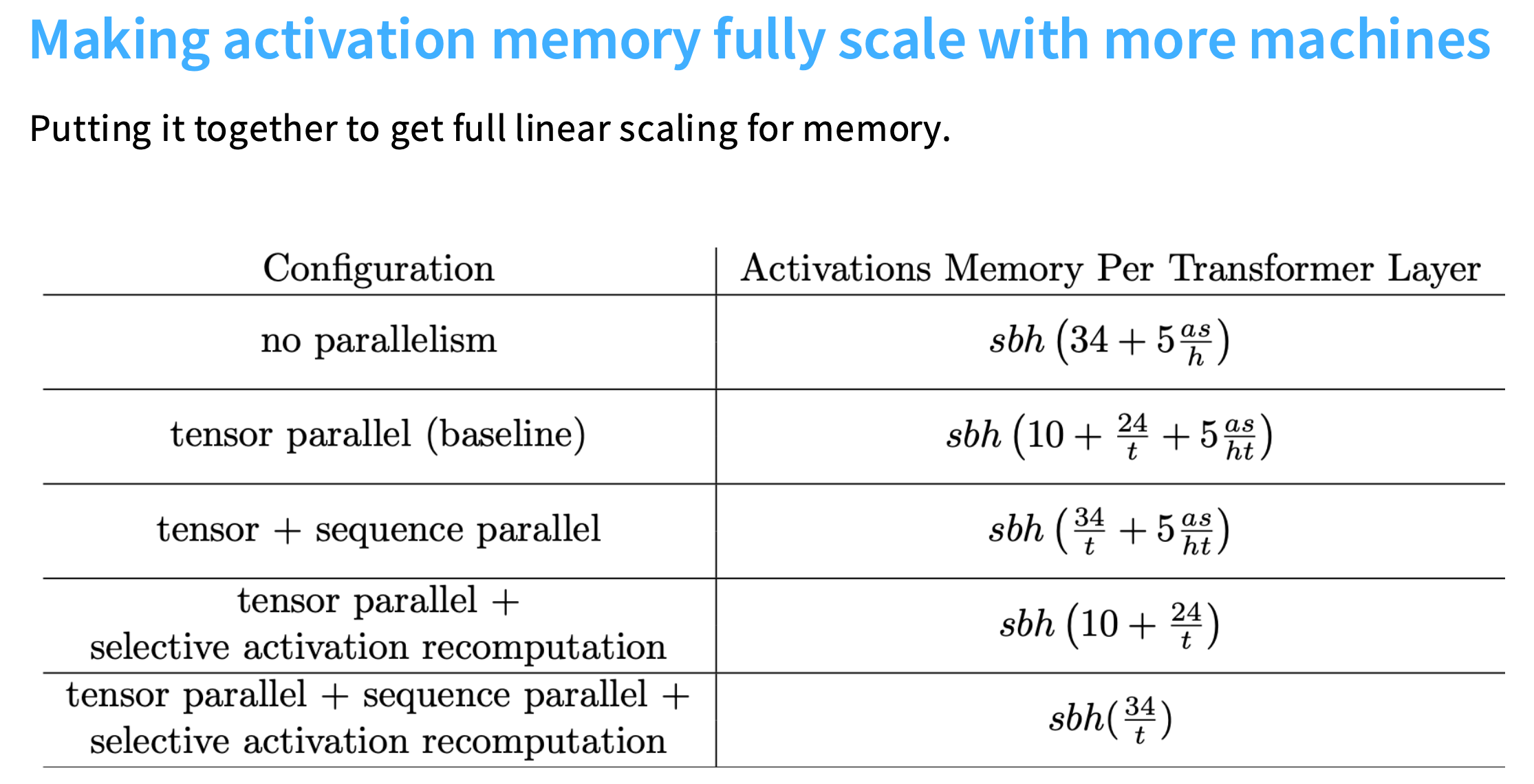
如果用张量并行(在mlp、KQ、attention计算中使用),激活值内存的公式如下:后面两项都会被 t t t 进一步减小,但是前面的10无法消除。
10代表的是非矩阵乘法的部分:层归一化、dropout、注意力机制和MLP的输入。这些项会随着模型规模继续增长,而且无法并行化。

sequence 并行
对于上述的非矩阵乘法,利用序列并行的思想。
比如正在做层归一化,序列中不同位置的层归一化之间是不相关的。假设有一个1024长度的序列,将它切开,然后每个GPU处理层归一化的不同部分。
由于拆分了序列,所以要做一些操作保证并行计算时能再次被聚合。
图中绿色的 g g g 代表 all-gather, g ˉ \bar{g} gˉ 代表 reduce-scatter。也就是经过 LayerNorm 后数据是分散开的,需要将数据聚合。Linear输出的结果仍然是聚合状态,所以经过 g ˉ \bar{g} gˉ 分散开,然后传入Dropout。
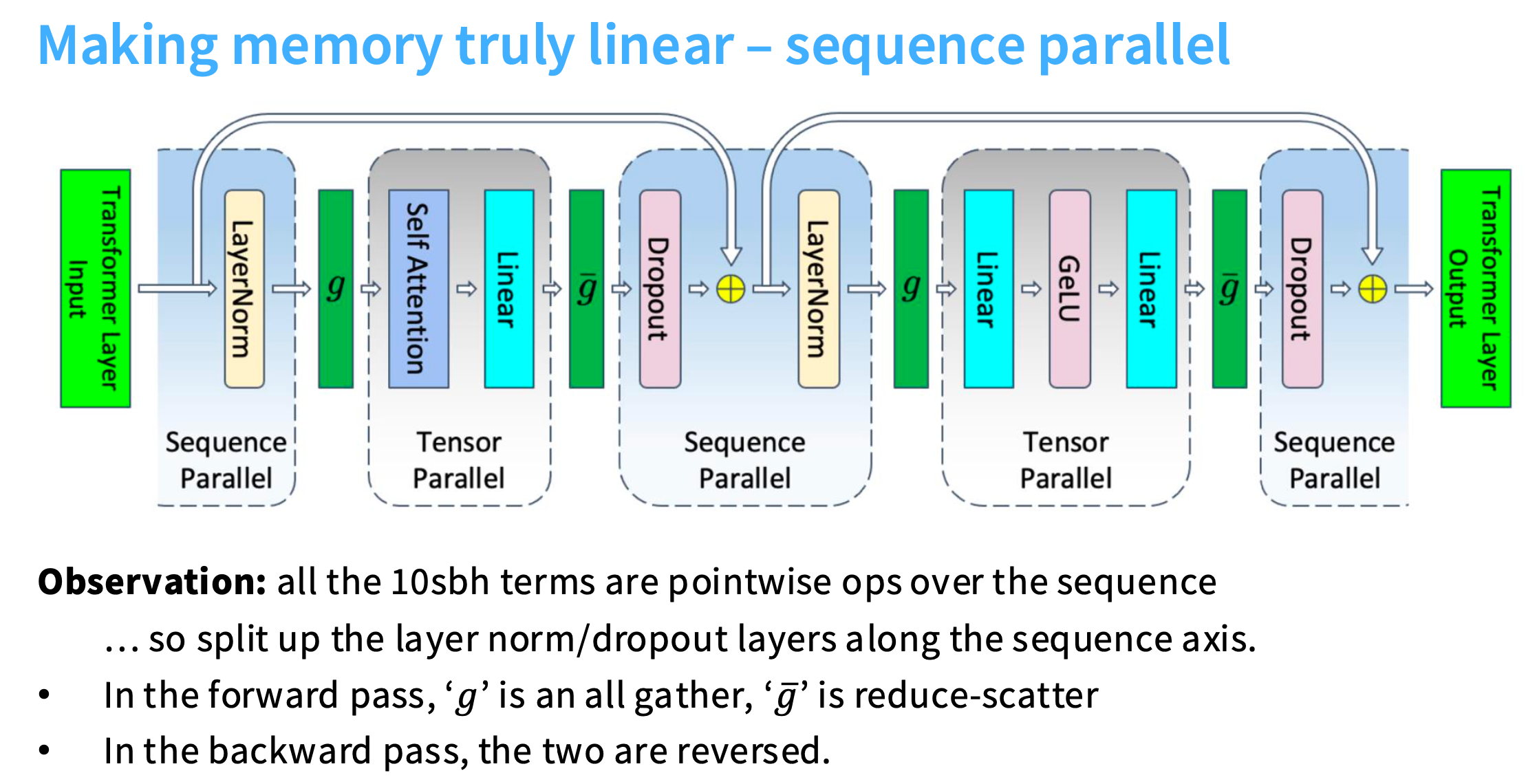
无并行化 -> 张量并行 -> 张量并行+序列并行 -> 张量并行+重计算 -> 张量并行+序列并行+重计算。
最终,将内存优化到 s b h ( 34 t ) sbh(\frac{34}{t}) sbh(t34)
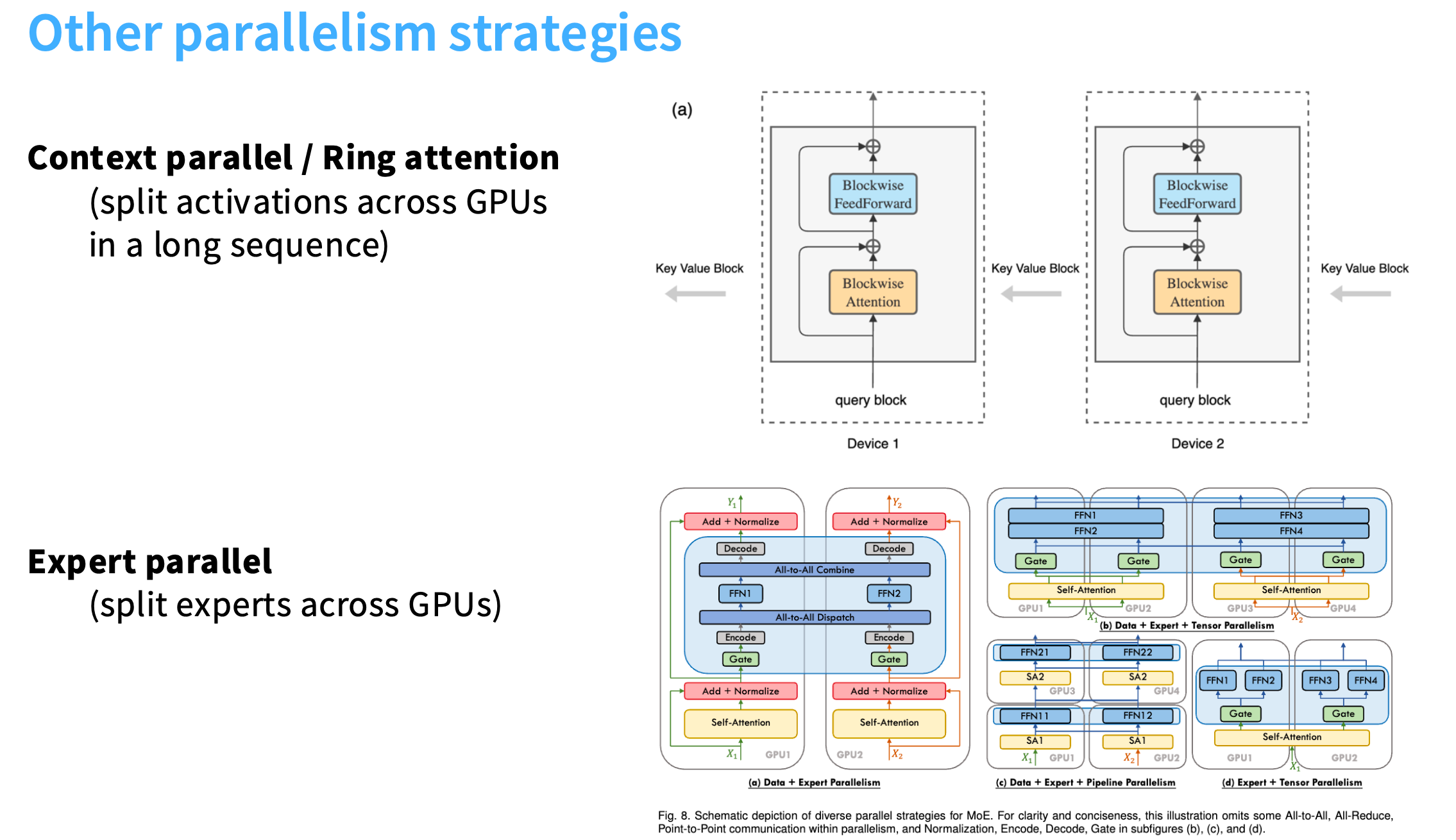
其他类型的并行策略
- 上下文并行,也称环形注意力
将计算和激活的成本都分摊开,用来计算非常大的注意力。本质是将 键 Key 和 值 Value 在不同的机器之间传递,每台机器负责不同的查询 Query。以环形的方式,计算K、Q、V的内积。
- 专家并行
几乎就像张量并行,从某种意义上说,是把大型MLP分割成更小的专家MLP,然后把他们分散到不同的机器上。关键在于,专家们是稀疏激活的,所以要考虑路由问题。
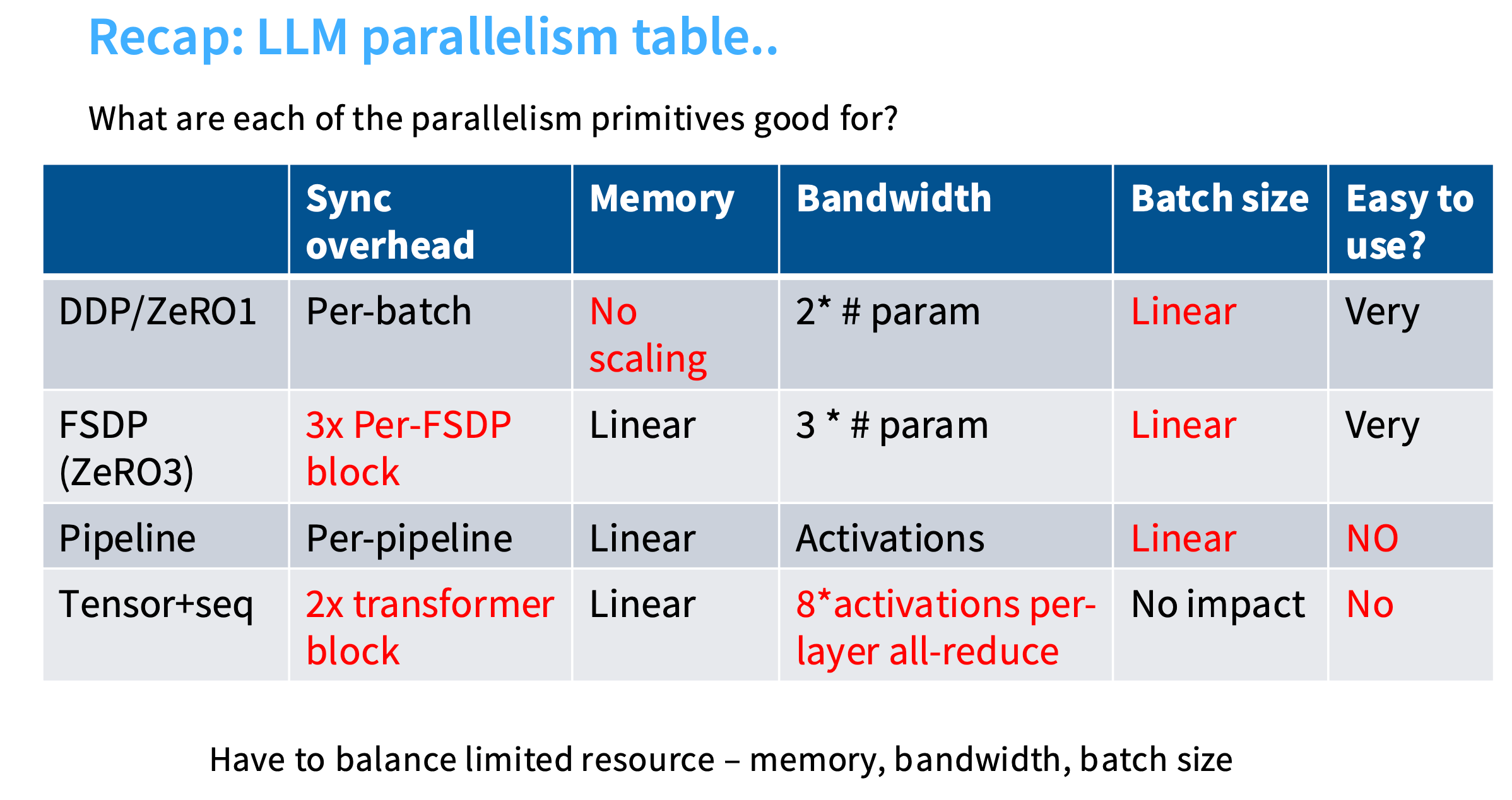
并行化策略总结
- DDP/ZeRO-1:朴素的数据并行方式,每个batch有一些开销,没有内存扩展能力,带宽属性尚可(需要消耗batch size才能做到,需要用更大的batch size实现大规模数据并行)
- FSDP:ZeRO-1的更优版本,可以获得内存扩展能力,但会在不同层级上付出开销。通信成本更高,而且可能存在同步障碍,导致GPU利用率收到影响。
- Pipeline:流水线并行,不再依赖与 batch size 相关的内容,可以获得线性扩展能力。但是消耗batch size,而且设置和使用困难。
- Tensor+seq:在带宽方面成本非常高,需要进行的同步操作量也很高。优点是对batch size没有影响。
3. 缩放+并行化训练LLM
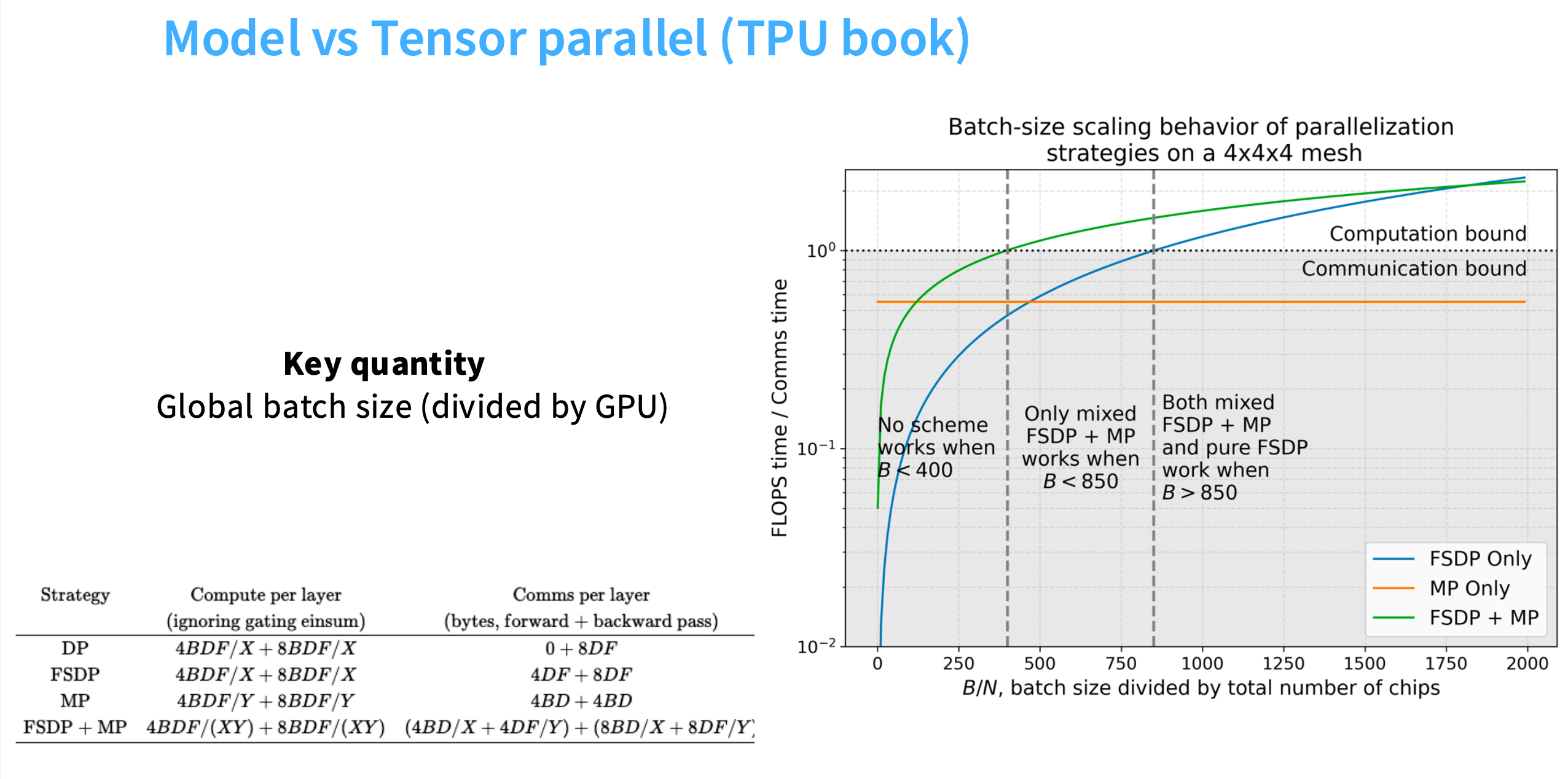
左边的简化公式计算得到右边的图。
- 如果batch size太小,即便有很多GPU,效率也会很低,因为总是受限于通信。(横坐标0~400)
- 随着batch size越来越大,如果同时使用FSDP+MP(张量并行),基本能达到计算受限的状态。(横坐标400~900)
- 如果batch size很大,就可以只用纯数据并行,比如纯FSDP。此时计算时间高于通信时间。(横坐标900+)
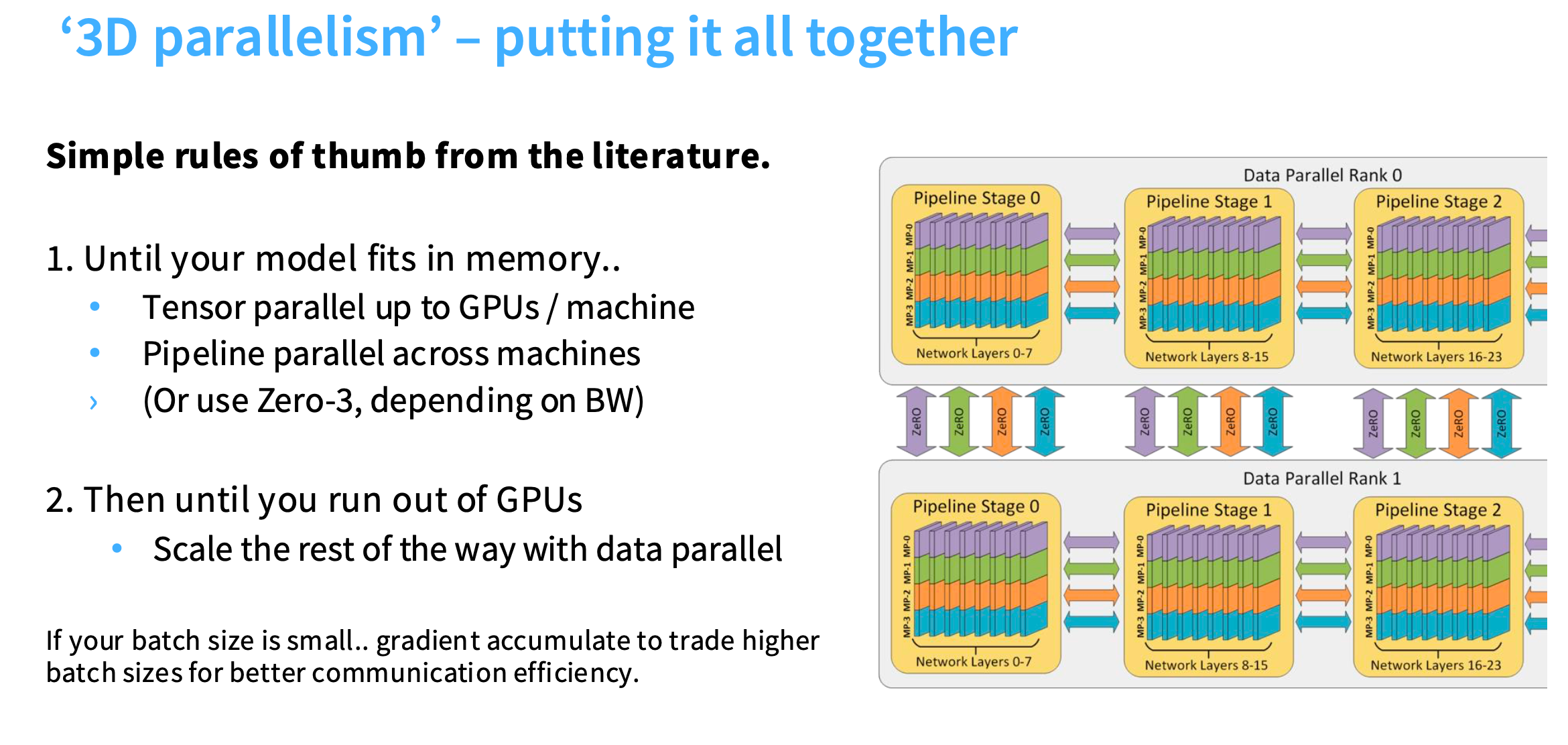
3D并行:不同维度的并行
- 第一步,也是强制条件,模型和激活值能装入内存
- 第二步,当模型能装入内存,就拆分模型,此时用张量并行。因为在每台机器GPU数量范围内,张量并行非常高效。
- 第三步,取决于你是否想处理流水线并行,以及带宽限制等因素,使用ZeRO-3或者在机器间使用流水线并行。
- 剩下的部分使用数据并行,因为数据并行在低带宽的通信通道上效果很好,而且简单。
如果batch size很小,有一种方法可以牺牲batch size大小来换取更好的通信效率,就是进行梯度累积。
总的目标是增加FLOPs的数量。
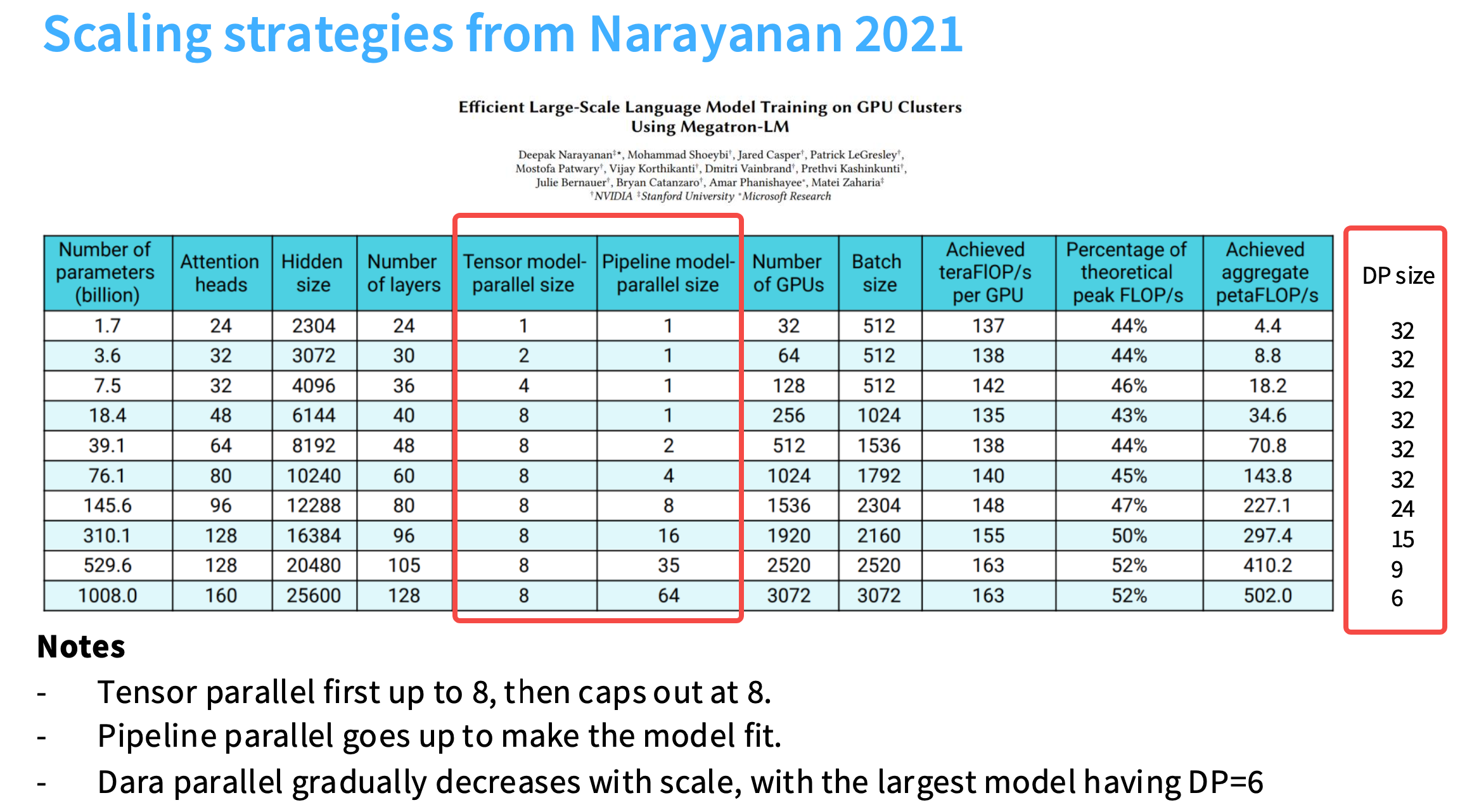
3D 并行的应用:megatron的缩放策略
首先使用张量并行,然后流水线并行。张量并行的GPU数量增加到8以后,流水线并行的大小开始增加,DP(数据并行)的size一开始尽可能大,然后慢慢地降低。因为随着流水线并行增大,某种程度上占用了batch size,所以DP无法有效地拥有很大的batch size。
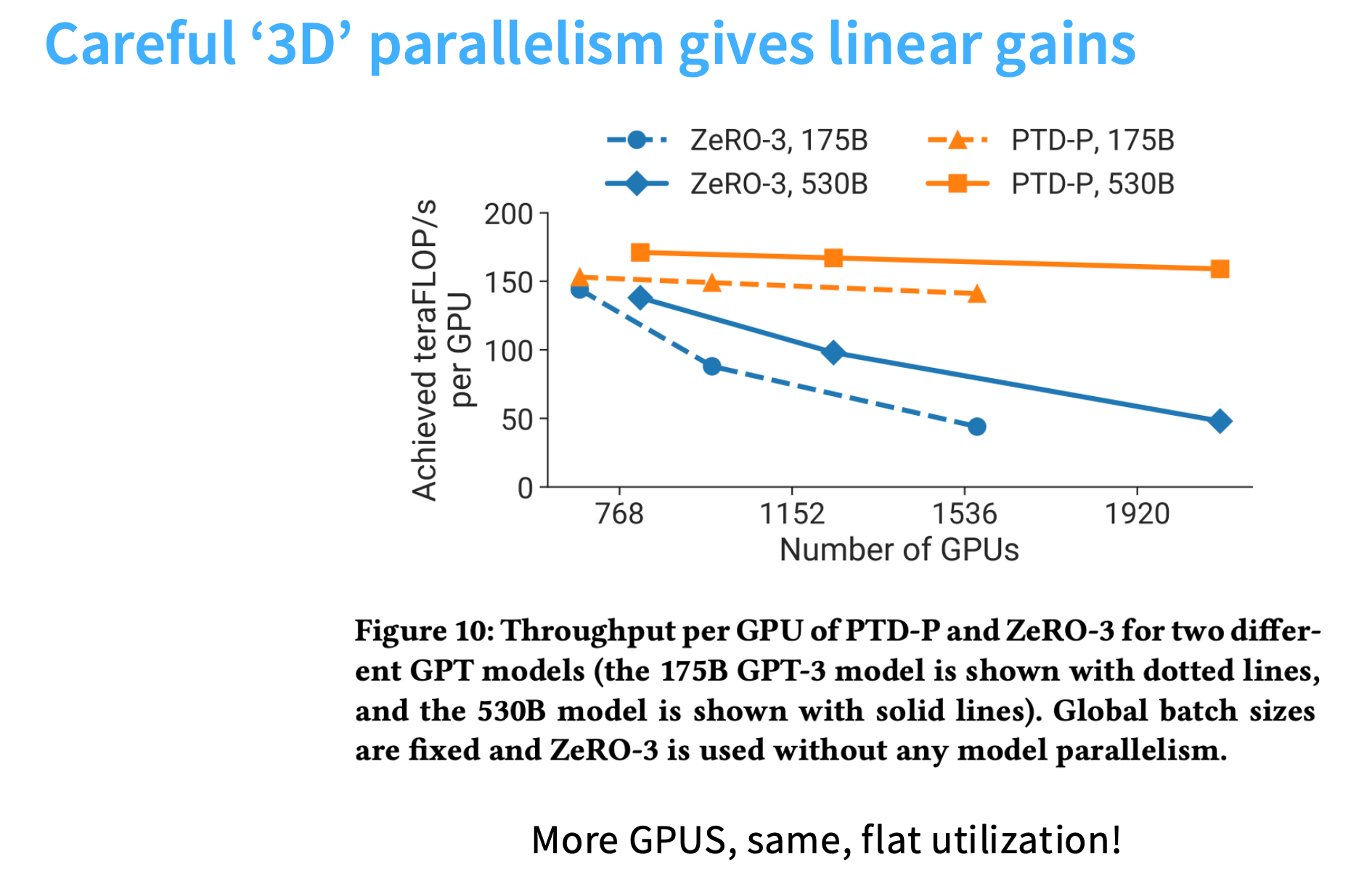
3D并行的效果
在总 FLOP 上带来近似线性的提升(对应图中的橙色方格线),如果增加更多GPU,FLOP 会实现线性扩展。
张量并行的GPU数量设成8,总是最好的!
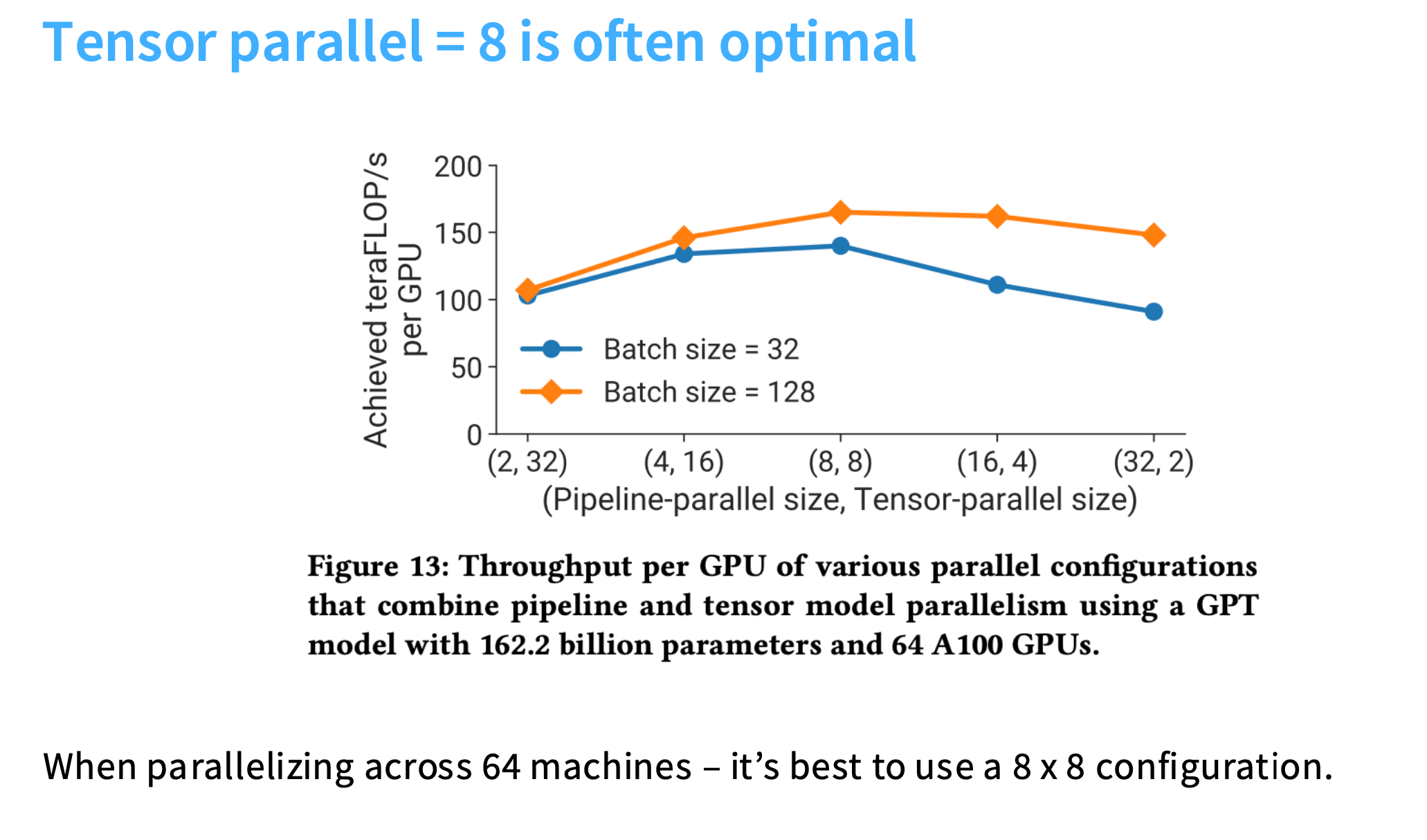
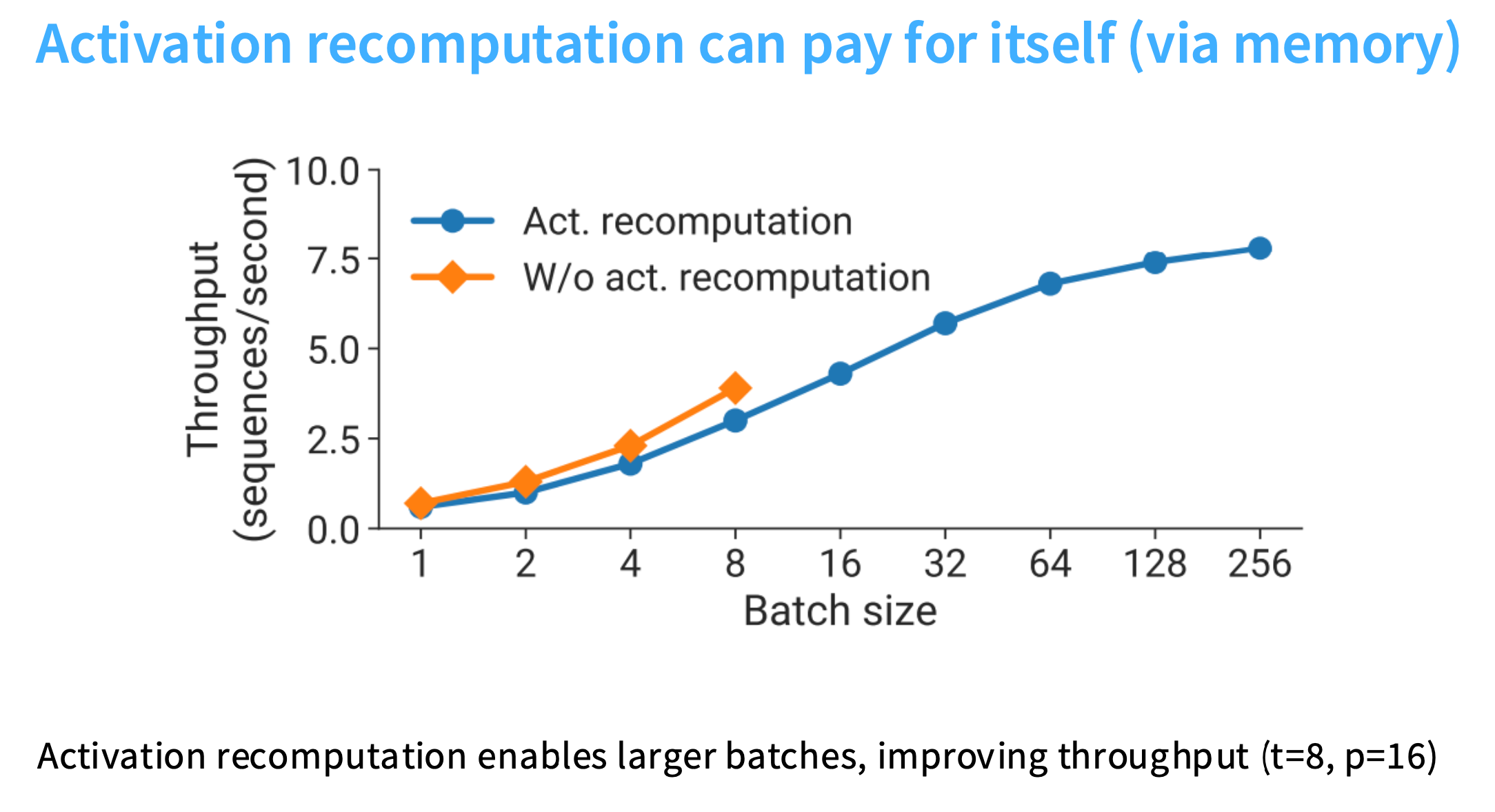
激活重计算可以实现更大的batch size,而更大的batch size反过来可以帮助掩盖流水线并行的开销。所以激活重计算,即使会增加浮点运算率,也是值得的。
最近的大语言模型是怎么做的?
- DOMA:对70亿参数的模型采用了FSDP
- DeepSeek:
- 第一篇论文,采用ZeRO stage 1,结合张量并行、序列并行和流水线并行
- deepseek-V3, 采用16路流水线并行,64路专家并行(类似于张量并行),数据并行采用ZeRO stage 1
- Yi:ZeRO stage 1,结合张量并行和流水线并行
- Yi lighting:采用MOE架构,用专家并行替代张量并行
- Gemma 2:ZeRO-3,大致等于FSDP,以及模型并行和数据并行