🔥作者:it毕设实战小研🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
- 1、大数据图书推荐系统-前言介绍
-
- 1.1背景
- 1.2课题功能、技术
- [1.3 意义](#1.3 意义)
- 2、大数据图书推荐系统-研究内容
- 3、大数据图书推荐系统-开发技术与环境
- 4、大数据图书推荐系统-功能介绍
- 5、大数据图书推荐系统-文档展示
- 6、大数据图书推荐系统-成果展示
- 7、代码展示
- 8、结语(文末获取源码)
本次文章主要是介绍基于协同过滤+大数据的图书推荐系统的设计与实现分析平台
1、大数据图书推荐系统-前言介绍
1.1背景
基于大数据技术的快速发展,传统图书推荐方式已经无法满足用户个性化阅读需求,海量图书信息导致用户在选择过程中出现信息过载问题。现有推荐平台普遍存在推荐精度不高、用户画像构建不准确等缺陷,难以为读者提供精准的个性化服务,因此急需构建一套智能化程度更高的图书推荐系统来解决上述问题。
1.2课题功能、技术
本课题设计并实现了基于大数据的图书推荐系统,采用Python语言作为核心开发技术,运用Django框架构建后端服务架构,结合Vue框架完成前端交互界面设计;系统集成了协同过滤推荐算法,通过分析用户历史行为数据挖掘潜在兴趣偏好,同时运用网络爬虫技术获取淘宝平台图书数据,丰富了系统数据源,并通过Echarts技术实现数据可视化分析功能,为管理员提供直观的统计图表展示。
1.3 意义
该系统有效提升了图书推荐的准确性和用户体验满意度,为图书行业数字化转型提供了技术支撑,其大数据处理和算法优化方案对相关推荐系统的设计具有一定的参考价值;通过协同过滤算法的应用验证了深度学习技术在个性化推荐领域的实用性,同时系统的可视化分析功能为运营决策提供了数据支持,推动了传统图书销售模式向智能化方向的发展。
2、大数据图书推荐系统-研究内容
1、数据采集与预处理:系统运用网络爬虫技术从淘宝平台获取图书相关数据,包括图书标题、作者、出版社、价格、销量、用户评分等关键信息。采集完成后,通过Python对原始数据进行清洗处理,剔除无效记录和重复内容,标准化数据格式,构建完整的图书信息数据库,为后续推荐算法提供可靠的数据基础。
2、数据存储与管理:采用MySQL数据库存储清洗后的图书数据及用户行为记录,设计合理的数据表结构来支撑用户信息、图书详情、浏览记录等多维度数据的高效存储与查询操作。
3、推荐算法实现:基于协同过滤算法构建个性化推荐模型,通过分析用户历史浏览、收藏、评分等行为数据,计算用户相似度和物品相似度,生成精准的个性化图书推荐列表,提升推荐系统的智能化水平。
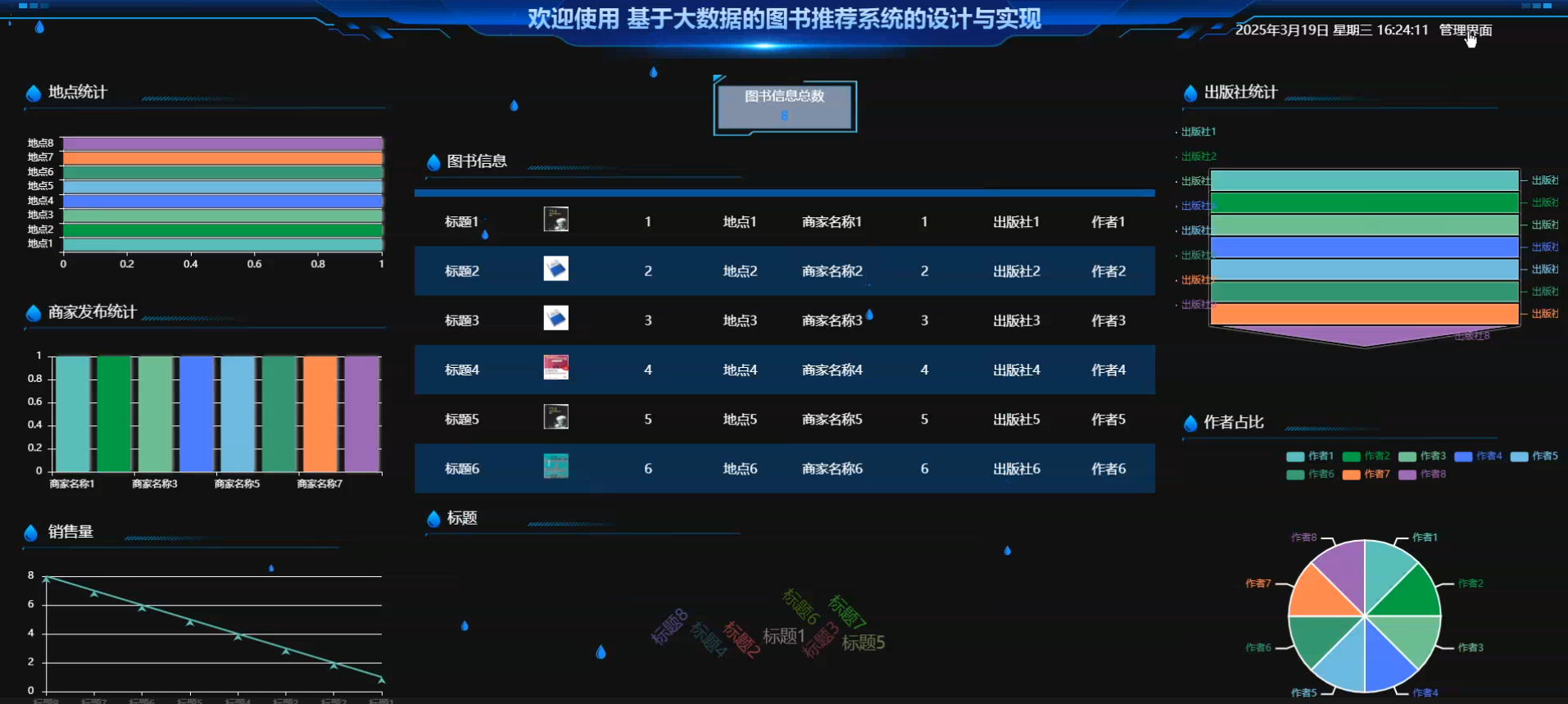
4、数据可视化展示:前端采用Vue框架结合Echarts技术实现数据可视化功能,通过多样化图表形式展示地区分布、销量统计、作者占比、出版社排名等关键指标,为管理员提供直观的数据分析视图。
5、系统集成与测试:后端基于Django框架开发,负责用户认证、数据接口、推荐算法调用等核心功能模块。前端通过API接口与后端交互,实现用户注册登录、图书信息查看、推荐结果展示等功能,完成开发后进行全面的功能测试和性能优化,确保系统运行稳定可靠。
3、大数据图书推荐系统-开发技术与环境
- 开发语言:Python
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:协同过滤模型
- 开发工具:pycharm
4、大数据图书推荐系统-功能介绍
亮点:(爬虫【淘宝】、协同过滤推荐算法、Echarts可视化)
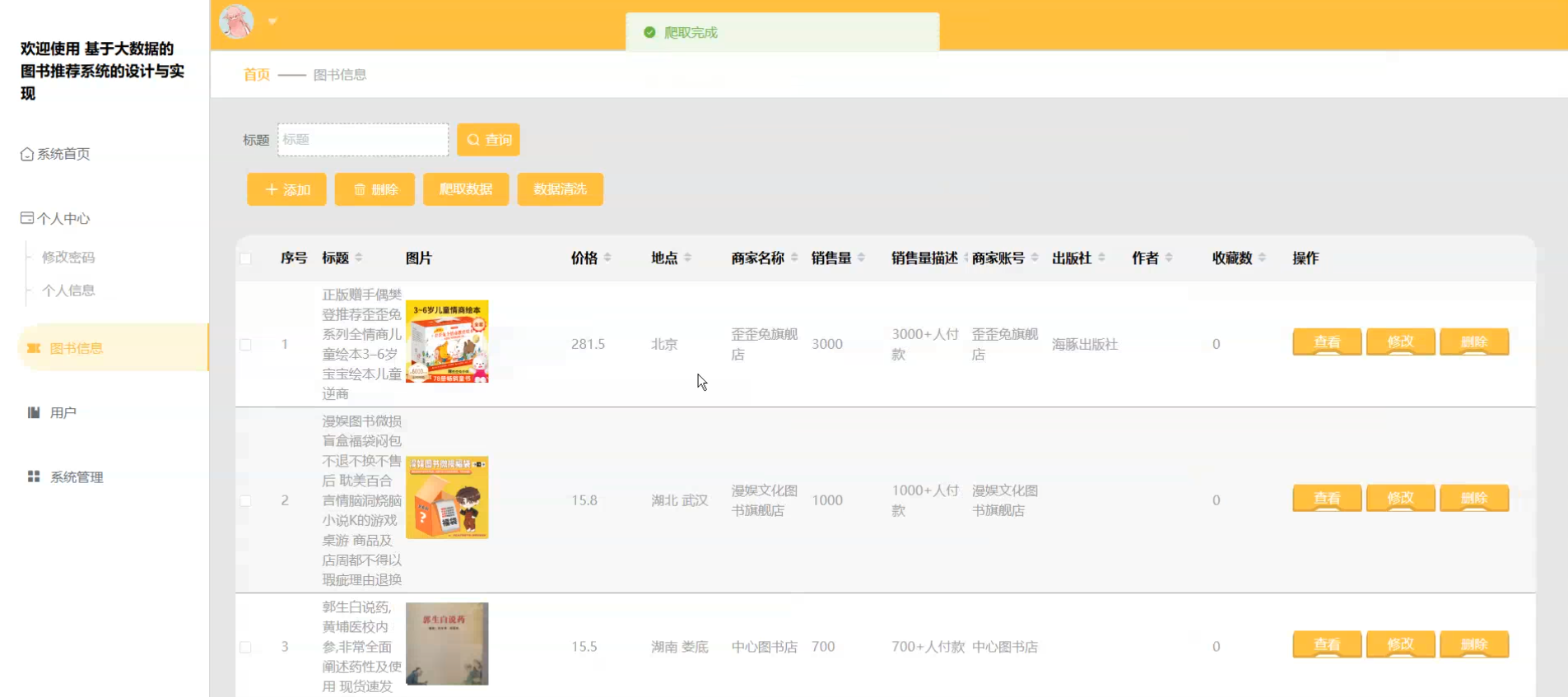
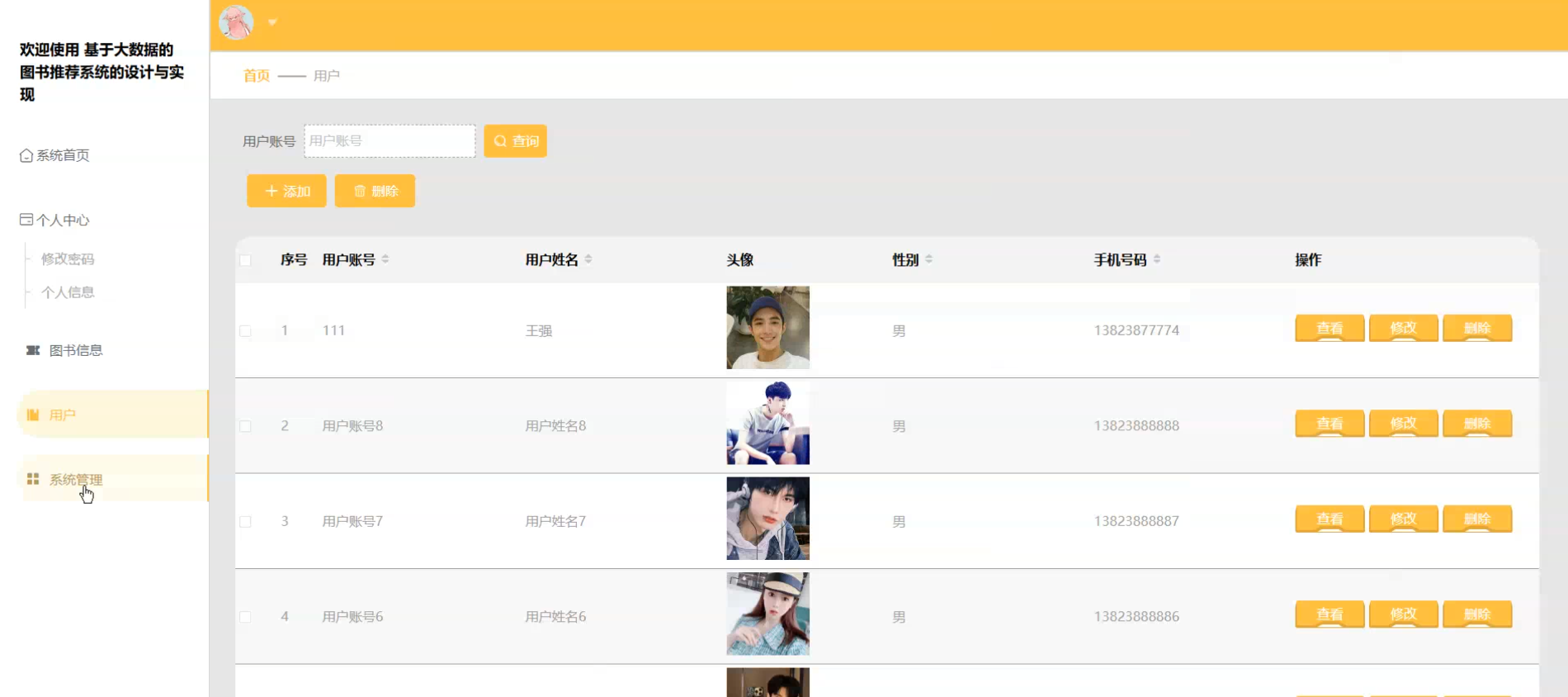
1、功能:登录注册、查看图书信息、查看图书资讯 、用户管理、图书资讯管理、图书信息管理、用户管理、个人中心。。
2、大屏可视化分析:地点统计、商家发布统计、销售量、图书信息、标题、出版社统计、作者占比。
3、算法:预测年龄、预测青少年浏览内容类型(线性回归预测模型)。
5、大数据图书推荐系统-文档展示
6、大数据图书推荐系统-成果展示
6.1演示视频
2026届大数据机器学习选题推荐-基于大数据的图书推荐系统的设计与实现 智能图书馆系统
6.2演示图片
☀️可视化大屏☀️
☀️登录注册☀️

☀️图书信息管理☀️
☀️查看图书信息☀️
☀️用户管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
bash
class BookDataCleaner:
def __init__(self, raw_data_path):
"""
初始化数据清洗器
:param raw_data_path: 原始数据文件路径
"""
self.raw_data = pd.read_csv(raw_data_path, encoding='utf-8')
self.cleaned_data = None
def remove_duplicates(self):
"""去除重复数据"""
print(f"原始数据量: {len(self.raw_data)}")
# 基于图书标题和作者去重
self.raw_data = self.raw_data.drop_duplicates(subset=['title', 'author'], keep='first')
print(f"去重后数据量: {len(self.raw_data)}")
return self
def clean_price(self):
"""清洗价格数据"""
def extract_price(price_str):
if pd.isna(price_str):
return None
# 提取数字部分
price_match = re.search(r'(\d+\.?\d*)', str(price_str))
if price_match:
return float(price_match.group(1))
return None
self.raw_data['price'] = self.raw_data['price'].apply(extract_price)
# 处理异常价格值(小于0或大于1000的价格)
self.raw_data.loc[(self.raw_data['price'] < 0) | (self.raw_data['price'] > 1000), 'price'] = np.nan
return self
def clean_sales_volume(self):
"""清洗销量数据"""
def extract_sales(sales_str):
if pd.isna(sales_str):
return 0
sales_str = str(sales_str)
# 处理"万+"格式
if '万' in sales_str:
num_match = re.search(r'(\d+\.?\d*)', sales_str)
if num_match:
return int(float(num_match.group(1)) * 10000)
# 提取纯数字
num_match = re.search(r'(\d+)', sales_str)
if num_match:
return int(num_match.group(1))
return 0
self.raw_data['sales_volume'] = self.raw_data['sales_volume'].apply(extract_sales)
return self
def clean_rating(self):
"""清洗评分数据"""
def extract_rating(rating_str):
if pd.isna(rating_str):
return None
rating_match = re.search(r'(\d+\.?\d*)', str(rating_str))
if rating_match:
rating = float(rating_match.group(1))
# 评分范围应在0-5之间
if 0 <= rating <= 5:
return rating
return None
self.raw_data['rating'] = self.raw_data['rating'].apply(extract_rating)
return self
def clean_text_fields(self):
"""清洗文本字段"""
text_columns = ['title', 'author', 'publisher', 'category']
for col in text_columns:
if col in self.raw_data.columns:
# 去除多余空白字符
self.raw_data[col] = self.raw_data[col].astype(str).str.strip()
# 去除特殊字符
self.raw_data[col] = self.raw_data[col].str.replace(r'[^\w\s\u4e00-\u9fff]', '', regex=True)
# 处理空值
self.raw_data[col] = self.raw_data[col].replace(['nan', '', 'None'], np.nan)
return self
def handle_missing_values(self):
"""处理缺失值"""
# 关键字段不能为空,删除这些记录
essential_cols = ['title', 'author']
for col in essential_cols:
if col in self.raw_data.columns:
self.raw_data = self.raw_data.dropna(subset=[col])
# 用众数填充分类信息
if 'category' in self.raw_data.columns:
mode_category = self.raw_data['category'].mode()
if len(mode_category) > 0:
self.raw_data['category'].fillna(mode_category[0], inplace=True)
# 用中位数填充价格
if 'price' in self.raw_data.columns:
median_price = self.raw_data['price'].median()
self.raw_data['price'].fillna(median_price, inplace=True)
# 用平均值填充评分
if 'rating' in self.raw_data.columns:
mean_rating = self.raw_data['rating'].mean()
self.raw_data['rating'].fillna(mean_rating, inplace=True)
return self
def standardize_format(self):
"""标准化数据格式"""
# 标准化价格格式(保留两位小数)
if 'price' in self.raw_data.columns:
self.raw_data['price'] = self.raw_data['price'].round(2)
# 标准化评分格式
if 'rating' in self.raw_data.columns:
self.raw_data['rating'] = self.raw_data['rating'].round(1)
# 添加数据清洗时间戳
self.raw_data['cleaned_at'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
return self
def validate_data(self):
"""数据验证"""
validation_results = {}
# 检查必要字段完整性
essential_fields = ['title', 'author', 'price']
for field in essential_fields:
if field in self.raw_data.columns:
null_count = self.raw_data[field].isnull().sum()
validation_results[f'{field}_null_count'] = null_count
# 检查数据范围合理性
if 'price' in self.raw_data.columns:
price_stats = {
'min_price': self.raw_data['price'].min(),
'max_price': self.raw_data['price'].max(),
'avg_price': self.raw_data['price'].mean()
}2.大屏可视化【代码如下(示例):】
bash
class DashboardDataView(View):
"""大屏可视化数据接口"""
def get(self, request):
"""获取大屏展示所需的统计数据"""
try:
# 地区销量统计
location_stats = self.get_location_statistics()
# 商家发布统计
publisher_stats = self.get_publisher_statistics()
# 销量统计
sales_stats = self.get_sales_statistics()
# 图书信息统计
book_info_stats = self.get_book_info_statistics()
# 出版社统计
publisher_ranking = self.get_publisher_ranking()
# 作者占比统计
author_distribution = self.get_author_distribution()
# 实时数据统计
realtime_stats = self.get_realtime_statistics()
response_data = {
'code': 200,
'message': '数据获取成功',
'data': {
'locationStats': location_stats,
'publisherStats': publisher_stats,
'salesStats': sales_stats,
'bookInfoStats': book_info_stats,
'publisherRanking': publisher_ranking,
'authorDistribution': author_distribution,
'realtimeStats': realtime_stats
}
}
return JsonResponse(response_data, safe=False, json_dumps_params={'ensure_ascii': False})
except Exception as e:
return JsonResponse({
'code': 500,
'message': f'数据获取失败: {str(e)}',
'data': None
})
def get_location_statistics(self):
"""获取地区统计数据"""
location_data = Book.objects.values('location').annotate(
count=Count('id'),
total_sales=Sum('sales_volume')
).order_by('-total_sales')[:10]
return {
'regions': [item['location'] for item in location_data],
'sales': [item['total_sales'] or 0 for item in location_data],
'counts': [item['count'] for item in location_data]
}
def get_publisher_statistics(self):
"""获取出版社发布统计"""
publisher_data = Publisher.objects.annotate(
book_count=Count('book')
).order_by('-book_count')[:15]
return {
'publishers': [p.name for p in publisher_data],
'counts': [p.book_count for p in publisher_data]
}
def get_sales_statistics(self):
"""获取销量趋势统计"""
# 按月份统计销量
from django.db.models import Extract
monthly_sales = Book.objects.annotate(
month=Extract('created_at', 'month')
).values('month').annotate(
total_sales=Sum('sales_volume'),
book_count=Count('id')
).order_by('month')
return {
'months': [f'{item["month"]}月' for item in monthly_sales],
'sales': [item['total_sales'] or 0 for item in monthly_sales],
'counts': [item['book_count'] for item in monthly_sales]
}
def get_book_info_statistics(self):
"""获取图书信息统计"""
category_stats = Book.objects.values('category').annotate(
count=Count('id'),
avg_price=Avg('price'),
total_sales=Sum('sales_volume')
).order_by('-count')
return {
'categories': [item['category'] for item in category_stats],
'counts': [item['count'] for item in category_stats],
'avgPrices': [round(item['avg_price'] or 0, 2) for item in category_stats],
'totalSales': [item['total_sales'] or 0 for item in category_stats]
}
def get_publisher_ranking(self):
"""获取出版社排名"""
publisher_ranking = Publisher.objects.annotate(
total_books=Count('book'),
total_sales=Sum('book__sales_volume')
).order_by('-total_sales')[:10]
return [
{
'name': p.name,
'books': p.total_books,
'sales': p.total_sales or 0
} for p in publisher_ranking
]
def get_author_distribution(self):
"""获取作者分布统计"""
author_stats = Author.objects.annotate(
book_count=Count('book')
).order_by('-book_count')[:20]
return [
{
'name': author.name,
'value': author.book_count
} for author in author_stats
]
def get_realtime_statistics(self):
"""获取实时统计数据"""
from datetime import datetime, timedelta
today = datetime.now().date()
yesterday = today - timedelta(days=1)
today_books = Book.objects.filter(created_at__date=today).count()
total_books = Book.objects.count()
total_users = User.objects.count()
total_sales = Book.objects.aggregate(Sum('sales_volume'))['sales_volume__sum'] or 0
return {
'totalBooks': total_books,
'totalUsers': total_users,
'totalSales': total_sales,
'todayBooks': today_books,
'avgRating': round(Book.objects.aggregate(Avg('rating'))['rating__avg'] or 0, 1)
}8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。