一.redis持久化
Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以 Redis 提供了持久化功能!
持久化过程保存什么
(1)将当前数据状态进行保存,快照形式,存储数据结果,存储格式简单,关注点在数据(RDB)
(2)将数据的操作过程进行保存,日志形式,存储操作过程,关注点在数据的操作过程(AOF)
1.1.RDB
1.1.1.RDB手动方式
核心概念
RDB 持久化是指在指定的时间间隔内 ,将内存中的数据集快照(Snapshot) 写入磁盘。它生成一个经过压缩的二进制文件(默认名为 dump.rdb)。这个文件就像是某个时间点上 Redis 数据的一个完整备份。
工作原理
RDB 的创建有两种主要方式:
-
SAVE命令 :同步 操作。执行该命令后,Redis 服务器会开始创建 RDB 文件,在这个过程中,服务器会阻塞 ,不再处理任何其他命令,直到 RDB 文件创建完毕。生产环境几乎不会使用。 -
BGSAVE命令 :异步 操作(BackGround SAVE)。这是最常用的方式。执行该命令后,Redis 会fork出一个子进程 。由子进程负责将数据快照写入临时 RDB 文件,完成后再替换旧的 RDB 文件。而父进程(主进程)继续正常处理客户端请求。fork操作本身在数据量大时可能会短暂阻塞,但整个持久化过程对主进程影响极小。
ps:
Fork:
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
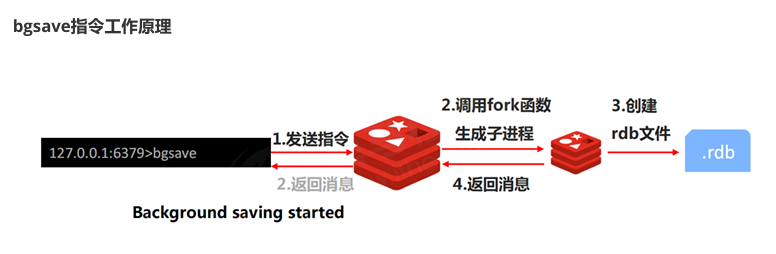
- 除了手动命令,更多的是通过配置文件中的保存点(Save Point) 来触发
BGSAV
1.1.2.RDB 自动
自动触发的核心:保存点 (Save Points)
RDB 的自动触发完全由 Redis 配置文件 redis.conf 中的 save 指令控制。你可以配置一个或多个保存点 。当满足任意一个保存点条件时,Redis 就会自动在后台执行 BGSAVE 操作。
作用:满足限定时间范围内key的变化数量达到指定数量即进行持久化
配置语法
conf
save <seconds> <changes>
<seconds>:监控时间范围【时间窗口(单位:秒)】。
<changes>:数据变化的次数(即至少有多少个键被修改)。含义 :如果在
<seconds>秒内,数据库发生了至少<changes>次写操作 ,那么就会自动触发一次BGSAVE。
在Redis.conf文件中,还看见以下配置
save 900 1 # 在900秒(15分钟)内,如果至少有1个key发生变化,则触发bgsave
save 300 10 # 在300秒(5分钟)内,如果至少有10个key发生变化,则触发bgsave
save 60 10000 # 在60秒(1分钟)内,如果至少有10000个key发生变化,则触发bgsave
dbfilename dump.rdb # RDB文件的名字
dir ./ # RDB文件和AOF文件的保存目录这意味着,只要满足以上三个条件中的任意一个,Redis 就会自动创建 RDB 快照。
1.1.3RDB优点
1. 高性能,对主进程影响小
这是 RDB 最大的优势。RDB 持久化通过 fork() 子进程来完成所有工作。
-
主进程不间断:父进程(Redis 主服务进程)继续处理所有客户端请求,持久化过程不会导致服务停顿。
-
最大化利用多核:子进程在一个独立的进程中执行磁盘 I/O 操作,充分利用多核 CPU 的优势。
2. 非常适合灾难恢复与备份
-
紧凑的单文件 :RDB 生成的是一个经过压缩的二进制快照文件(如
dump.rdb)。这个文件非常紧凑,包含了某个时间点的全部数据。 -
便于传输和归档:单一的文件使得它非常容易:
-
备份 :简单地用
cp,scp命令即可备份。 -
传输:可以轻松地发送到远程数据中心或云存储(如 AWS S3)进行容灾。
-
版本化:可以按时间点保留多个版本的 RDB 文件(例如,每天凌晨的完整备份),便于回溯到某个历史状态。
-
3. 数据恢复速度极快
相比于 AOF,RDB 在重启恢复时有巨大优势。
-
直接加载到内存:RDB 文件是数据在内存中的二进制序列化形式。恢复时,Redis 只需要将文件读入内存即可,速度非常快。
-
与数据量大小无关 :恢复时间只取决于 RDB 文件的大小和磁盘 I/O 速度,与数据集中有多少个 key 无关。而 AOF 需要重新执行每一个命令,命令越多,恢复越慢。
4. 隐藏的优点:性能最大化
在持久化发生时,RDB 对正在运行的 Redis 实例性能影响最小。它只在 fork() 的瞬间可能会有延迟,之后子进程的工作几乎与主进程无关。
1.1.3.RDB缺点
Fork的时候,内存中的数据被克隆了一份,大致两倍的膨胀性需要考虑
虽然Redis在fork是使用了写时拷贝技术,但是如果数据庞大是还是比较消耗性能
RDB方式无论是执行指令还是利用配置,无法做到实时持久化,机油较大的可能性丢失数据
Redis的众多版本中为进行RDB文件格式的版本统一,有可能出现个版本服务之间数据格式无法兼容现象。
1.2.AOF
核心概念
AOF 持久化是通过记录每一次写操作命令 (例如 SET, SADD, LPUSH)来记录数据库状态的。当服务器重启时,会重新执行 AOF 文件中的所有命令,来重建原始数据集。与RDB相比可以简单描述为改记录数据为记录数据产生的过程。
主要作用
解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
工作原理
-
命令追加(Append):每当有写命令执行时,这个命令会以 Redis 协议格式追加到 AOF 缓冲区的末尾。
-
文件写入(Write)和同步(Sync) :根据配置的策略,将 AOF 缓冲区中的内容写入(write)到操作系统内核的页面缓存 ,然后根据策略决定何时将其同步(sync / fsync)到硬盘。
-
appendfsync always:每次 写命令都同步到磁盘。数据最安全,但性能最差,因为磁盘 IO 成了瓶颈。 -
appendfsync everysec:每秒 同步一次。这是一种折衷方案,即使发生宕机,也只会丢失最近1秒的数据。这是默认且推荐的配置,在性能和数据安全间取得了良好平衡。 -
appendfsync no:由操作系统决定何时同步。性能最好,但数据丢失的风险最高(通常可能丢失30秒左右的数据)。
-
-
AOF 重写(Rewrite) :随着时间推移,AOF 文件会越来越大(例如,对同一个 key 操作 100 次,会有 100 条记录,但最终状态只取决于最后一条)。为了解决这个问题,Redis 提供了
BGREWRITEAOF命令(也会自动触发),它会fork一个子进程,根据当前数据库状态创建一个新的、更小的 AOF 文件(包含重建当前数据集所需的最少命令集合),完成后替换旧的 AOF 文件。
appendonly yes # 开启AOF持久化
appendfilename "appendonly.aof" # AOF文件名
appendfsync everysec # 同步策略:每秒一次
auto-aof-rewrite-percentage 100 # 当前AOF文件比上次重写后的大小增长了100%时,触发重写
auto-aof-rewrite-min-size 64mb # AOF文件最小要达到64MB才会触发重写
优点
-
数据安全性极高 :尤其是在
appendfsync always模式下,最多丢失一个命令的数据。everysec模式也最多只丢失1秒的数据。 -
可读性:AOF 文件是纯文本格式,记录了所有操作命令,便于理解和人工分析(虽然通常不这么做)。
缺点
-
文件体积大:通常 AOF 文件会比同数据库的 RDB 文件大很多。
-
恢复速度慢:在数据集很大时,重新执行所有命令来恢复数据会比加载 RDB 慢很多。
-
性能相对较低 :虽然
everysec模式很好,但理论上仍会比 RDB 的BGSAVE对性能的影响稍大一些。
总结与选择建议
| 特性 | RDB | AOF |
|---|---|---|
| 持久化方式 | 定时快照 | 记录每次写命令 |
| 数据安全性 | 低,可能丢失分钟级数据 | 高,最多丢失秒级数据 |
| 文件大小 | 小,二进制压缩 | 大,文本格式(可重写优化) |
| 恢复速度 | 快 | 慢(但混合持久化大大改善) |
| 对性能影响 | fork 时可能阻塞,写入时无影响 |
根据 appendfsync 策略,有一定影响 |
| 优先级 | 低 | 高(如果同时开启,Redis 重启优先加载 AOF) |
二.Redis删除策略
数据删除策略目标:在内存占用与cpu占用之间寻找一种平衡,顾此彼此都会造成整体redid性能的下降,甚至引发服务器宕机或者内存泄漏。
数据删除策略的分类:
1.基于过期时间的删除策略
2.基于内存淘汰的删除策略
1.基于过期时间的删除策略
redis是一种内存级数据库,所有数据均存放在内存中,内存中的数据可以通过TTL指令获取其状态
XX:具有时效性的数据
-1:永久有效的数据
-2:已经过期的数据或者被删除的数据或者未定义的数据。
过期数据的删除策略分为:
1.定时删除
2.惰性删除
3.定期删除
定时删除
-
创建一个定时器 ,当key设置有过期时间,且过期时间到达时 ,由定时器任务立即执行 对键的删除操作
-
优点 :节约内存 ,到时就删除 ,快速释放掉不必要的内存占用
-
缺点 :CPU压力很大 ,无论CPU此时负载量多高 ,均占用CPU ,会影响redis服务器响应时间和指令吞吐量
-
总结 :用处理器性能 换取存储空间 (拿时间换空间)
惰性删除
-
核心思想 :只有在访问这个 key 的时候,才去检查它是否过期。 如果过期,则立即删除,并返回空(
(nil));如果未过期,则返回对应的值。 -
工作原理:
-
客户端发送
GET key命令。 -
Redis 在查找 key 之前,先检查该 key 是否设置了过期时间以及是否已过期。
-
如果已过期,则直接删除这个 key,然后向客户端返回
(nil)。 -
如果未过期,则返回对应的 value。
-
-
优点:
- 对 CPU 友好:删除操作只会在真正需要的时候才进行,不会浪费宝贵的 CPU 时间去扫描那些可能永远不会再被访问的过期 key。
-
缺点:
- 对内存不友好 :如果一个过期 key 永远不再被访问,那么即使它早已过期,也会一直占用着内存空间,相当于一种内存泄漏。它无法自己"主动"被清理。
-
总结:用存储空间换区处理器性能(拿空间换时间)
定期删除
-
核心思想 :Redis 会定期地、主动地随机抽取一批 key,检查并删除其中已过期的 key。 这是对惰性删除的补充,旨在减少那些"永远不被访问"的过期键造成的内存浪费。
-
工作原理:
-
定时任务 :Redis 将一个
serverCron时间事件设置为每秒运行 10 次(默认配置hz 10,即每 100ms 一次)。 -
随机抽样 :每次
serverCron运行时,它会从每个设置了过期时间的数据库中随机抽取一定数量的 key(默认是 20 个)。 -
检查并删除:对这 20 个 key 逐一检查其过期时间,并删除所有已过期的 key。
-
自适应过程:
-
如果本轮抽查中,过期 key 的比例超过了 25%,则立即重复步骤 2 和 3,再随机抽取 20 个 key 并删除过期的。
-
如此循环,直到过期 key 的比例降至 25% 以下,或者本次定时任务的执行时间超过了预设的时间上限 (默认 25ms),才会停止本轮检查,等待下一次
serverCron。
-
-
-
优点1 :CPU性能占用设置有峰值 ,检测频度可自定义设置
-
优点2 :内存压力不是很大 ,长期占用内存的冷数据 会被持续清理
-
总结 :周期性抽查 存储空间(随机抽查 ,重点抽查)
2.基于内存淘汰的删除策略(逐出算法)
当 Redis 使用的内存超过了 maxmemory 参数配置的上限时,Redis 会根据配置的内存淘汰策略来删除一些 key,以便为新写入的数据腾出空间。
通过 maxmemory-policy 指令配置。
八大内存淘汰策略
这些策略可以分为几大类:
1. 不淘汰策略
-
noeviction(默认策略):-
行为 :当内存不足时,新写入的操作会报错 (
(error) OOM command not allowed when used memory > 'maxmemory'.)。所有DEL命令和读请求正常执行。 -
使用场景:如果你希望数据集绝对保留在内存中,并且确保不会有任何 key 被意外删除,同时你的应用代码能妥善处理写入错误(例如,重试或降级),可以使用此策略。
-
2. 在设置了过期时间的 key 中进行淘汰
这类策略只会在那些设置了 TTL 的 key 中进行筛选和删除。
-
volatile-ttl:-
行为 :优先删除剩余生存时间 (TTL) 最短的 key。
-
场景:希望尽快清理掉即将过期的"无用"数据。
-
-
volatile-random:-
行为 :随机删除一个设置了过期时间的 key。
-
场景:简单粗暴,快速释放空间。
-
-
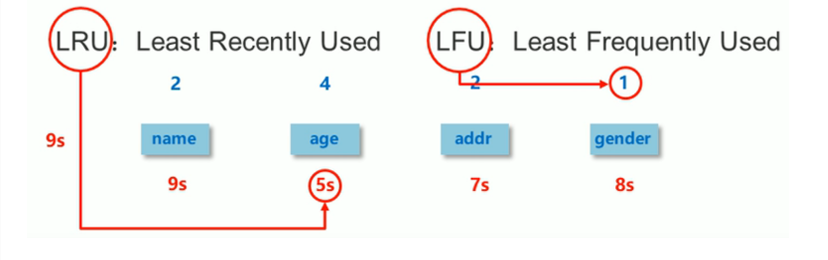
volatile-lru(Least Recently Used):-
行为 :在设置了过期时间的 key 中,删除最近最少使用的 key。(基于近似 LRU 算法)
-
场景 :最常用的策略之一。希望保留那些经常被访问的热点数据,淘汰掉不常用的冷数据。
-
-
volatile-lfu(Least Frequently Used):-
行为 :在设置了过期时间的 key 中,删除最不经常使用的 key。(基于近似 LFU 算法,Redis 4.0 引入)
-
场景:淘汰访问频率最低的 key。例如,某个 key 之前很热,但最近很久没人用了,LFU 会比 LRU 更可能淘汰它。
-
3. 在所有 key 中进行淘汰 (Allkeys-)
这类策略会在所有的 key 中 进行筛选和删除,无论是否设置了过期时间。
-
allkeys-random:-
行为 :随机删除任何一个 key。
-
场景:所有 key 的重要性差不多,没有明显热点。
-
-
allkeys-lru:-
行为 :在所有的 key 中,删除最近最少使用的 key。
-
场景 :极其常用的策略。如果你的数据访问模式存在热点,并且希望将内存用于保留最常用的数据,这是非常好的选择。即使有些 key 没设过期时间,也会被淘汰。
-
-
allkeys-lfu:-
行为 :在所有的 key 中,删除最不经常使用的 key。
-
场景:希望根据访问频率来淘汰 key,保留那些访问频率最高的 key。
-