哨兵机制介绍
哨兵模式的优点
- 监控master库,当master库宕机后会自动进行选主切换;
- 切换过程是应用透明的,因此应用程序无法感知;
- 自动处理故障节点;
高可用原理
当主节点出现故障时,由 Redis Sentinel 自动完成故障发现和转移,并通知应用方,实现高可用性。其实整个过程只需要一个哨兵节点来完成,至少部署三个哨兵是为了保证哨兵的高可用,使用 Raft算法(选举算法) 实现选举机制,选出一个哨兵节点来完成转移和通知。
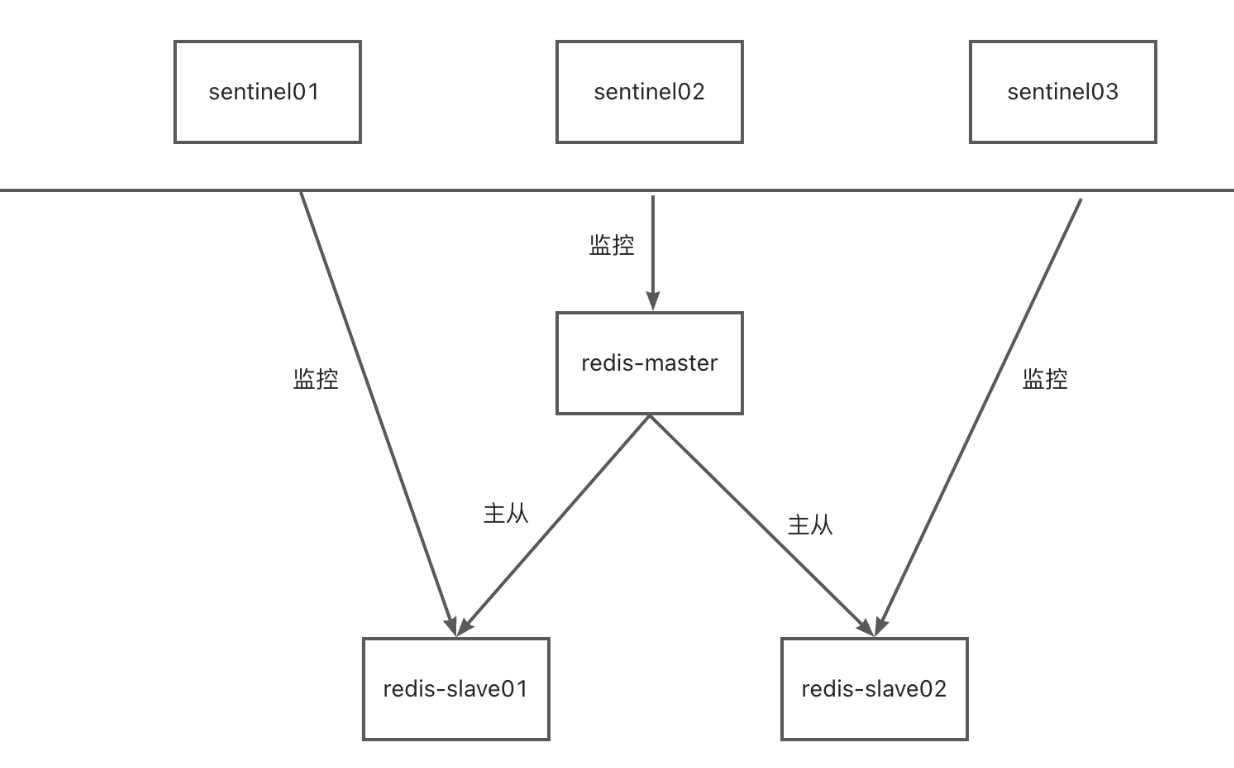
哨兵是如何进行定时监控任务的?
每个哨兵节点每10秒会向主节点和从节点发送info命令获取最新拓扑结构图,哨兵配置时只要配置对主节点的监控即可,通过向主节点发送info,获取从节点的信息,并当有新的从节点加入时可以马上感知到。
每个哨兵节点每隔2秒会向redis数据节点的指定频道上发送该哨兵节点对于主节点的判断以及当前哨兵节点的信息,同时每个哨兵节点也会订阅该频道,来了解其它哨兵节点的信息及对主节点的判断,其实就是通过消息订阅和发布来完成的。
每隔 1 秒每个哨兵会向主节点、从节点及其余哨兵节点发送一次 ping 命令做一次心跳检测,这个也是哨兵用来判断节点是否正常的重要依据。
Redis 哨兵选举流程(3 个当中,哪个是老大)
每个在线的哨兵节点都可以成为领导者,当它确认(比如哨兵 3)主节点下线时,会向其它哨兵发 is-master-down-by-addr 命令,征求判断并要求将自己设置为领导者,由领导者处理故障转移;
当其它哨兵收到此命令时,可以同意或者拒绝它成为领导者;如果哨兵 3 发现自己在选举的票数大于 50% 时,将成为领导者,如果没有超过,继续选举...
Redis 哨兵故障转移过程
由 Sentinel 节点定期监控发现主节点是否出现了故障,当主节点出现故障,此时 3 个 Sentinel 节点共同选举了 Sentinel03 节点为领导,负责处理主节点的故障转移。
- redis主节点挂了,将 slave01 脱离原从节点,升级主节点
- 将从节点 slave02 指向新的主节点
- 通知客户端主节点已更换
- 原主节点恢复之后,将原主节点变成从节点,指向新的主节点
部署哨兵集群
架构
主机 角色
10.0.0.123 主,哨兵01
10.0.0.124 从,哨兵02
10.0.0.125 从,哨兵03先部署好一主两从
可以参考《redis主从复制详解》章节:https://www.cnblogs.com/zqfstack/p/19039931
配置哨兵
哨兵可以不和Redis服务器部署在一起,但一般部署在一起,所有哨兵节点使用相同的配置文件
# 创建配置文件,三个主机都配置
mkdir /data/redis/sentinel
mkdir /data/redis/sentinel/conf
mkdir /data/redis/sentinel/data
mkdir /data/redis/sentinel/log
cat /data/redis/sentinel/conf/sentinel.conf
# 基础配置
bind 0.0.0.0
port 16379
daemonize yes
logfile /data/redis/sentinel/log/redis-sentinel.log
dir /data/redis/sentinel/data
protected-mode no
# 哨兵配置
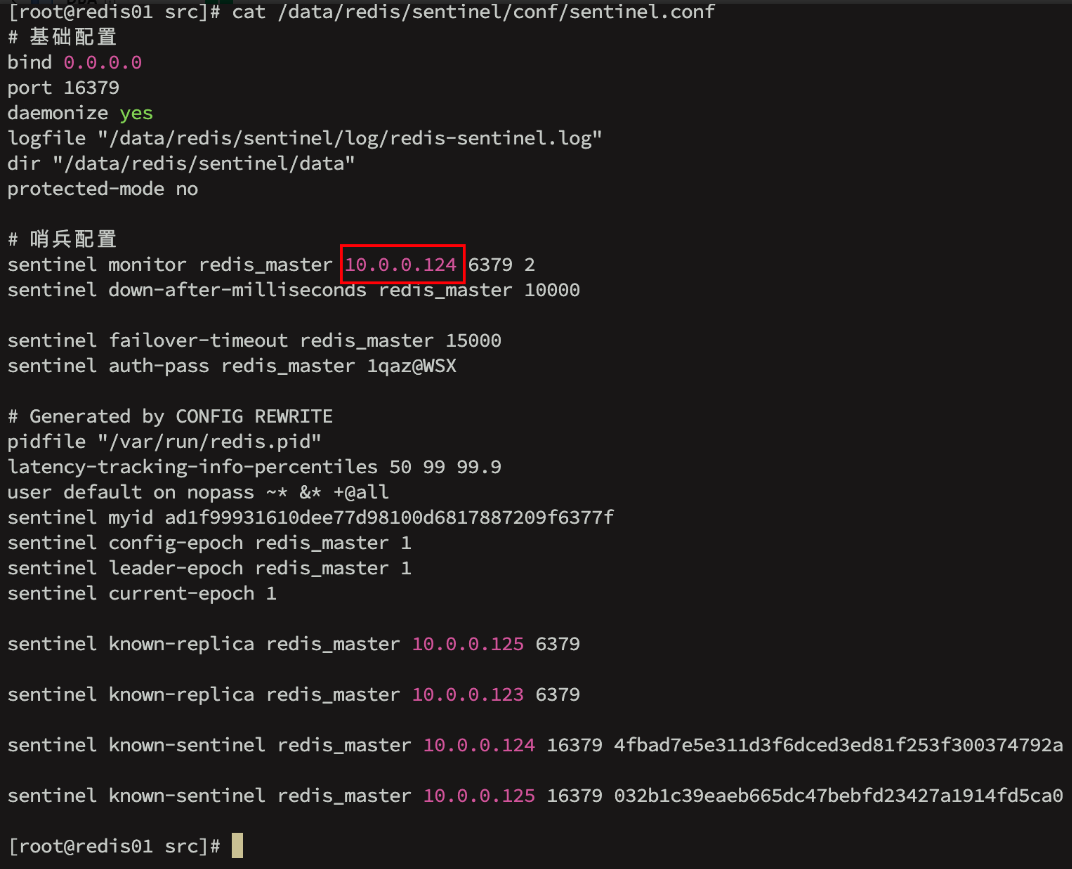
sentinel monitor redis_master 10.0.0.123 6379 2
sentinel down-after-milliseconds redis_master 10000
sentinel parallel-syncs redis_master 1
sentinel failover-timeout redis_master 15000
sentinel auth-pass redis_master 1qaz@WSX启动三台哨兵
redis-sentinel /data/redis/sentinel/conf/sentinel.conf
netstat -lntup |grep 16379
tcp 0 0 0.0.0.0:16379 0.0.0.0:* LISTEN 16966/redis-sentine查看三个哨兵节点信息
redis-cli -p 16379
127.0.0.1:16379> INFO sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=redis_master,status=ok,address=10.0.0.123:6379,slaves=2,sentinels=3
最后一行可以看到一个master主节点,两个salve节点状态,三个哨兵节点都正常。验证是否会自动切换
手动停止主库运行,模拟主库宕机
systemctl stop redis
# 查看从库01:
127.0.0.1:6379> INFO REPLICATION
# Replication
role:master
connected_slaves:1
slave0:ip=10.0.0.125,port=6379,state=online,offset=35934,lag=1
master_failover_state:no-failover
master_replid:4670ccaac1081c42fc01e6aef9ada7f1f9d8d41f
master_replid2:51b7a89015d1ce75482a6467ff57bf45d8dc404b
master_repl_offset:35934
second_repl_offset:31297
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:197
repl_backlog_histlen:35738
# 查看从库02:
127.0.0.1:6379> INFO REPLICATION
# Replication
role:slave
master_host:10.0.0.124
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_read_repl_offset:41953
slave_repl_offset:41953
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:4670ccaac1081c42fc01e6aef9ada7f1f9d8d41f
master_replid2:51b7a89015d1ce75482a6467ff57bf45d8dc404b
master_repl_offset:41953
second_repl_offset:31297
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:41953可以看到从库01成为了主节点,并且从库02的主库为新的主节点
手动修复宕机的主库,sentinel会自动发现
systemctl start redis
# 查看宕机的主库状态:
127.0.0.1:6379> INFO REPLICATION
# Replication
role:slave
master_host:10.0.0.124
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_read_repl_offset:60728
slave_repl_offset:60728
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
min_slaves_good_slaves:0
master_failover_state:no-failover
master_replid:4670ccaac1081c42fc01e6aef9ada7f1f9d8d41f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:60728
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:59024
repl_backlog_histlen:1705可以看到恢复后成为了从库,主节点为master_host:10.0.0.124
并且我们可以看到哨兵监听的主库也自动发生了改变:
sentinel管理命令
PING
使用"PING"指令监测Redis或者sentinel实例是否正常工作,如果返回"PONG"说明是可以正常响应的!
redis-cli -p 16379 ##指定端口为sentinel
127.0.0.1:16379>
127.0.0.1:16379>
127.0.0.1:16379> ping
PONG
127.0.0.1:16379>SENTINEL MASTERS
使用"SENTINEL MASTERS"指令列出所有被监视的主服务器
127.0.0.1:16379> SENTINEL MASTERS
1) 1) "name"
2) "redis_master"
3) "ip"
4) "10.0.0.124"
5) "port"
6) "6379"
7) "runid"
8) "c3be5003c7177b2cf7656c7888adb5243421a4c6"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "666"
19) "last-ping-reply"
20) "666"
21) "down-after-milliseconds"
22) "10000"
23) "info-refresh"
24) "3376"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "324664"
29) "config-epoch"
30) "1"
31) "num-slaves"
32) "2"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "15000"
39) "parallel-syncs"
40) "1"SENTINEL slaves
使用"SENTINEL slaves "指令列出所有被监视的从服务器
127.0.0.1:16379> SENTINEL SLAVES redis_master
1) 1) "name"
2) "10.0.0.125:6379"
3) "ip"
4) "10.0.0.125"
5) "port"
6) "6379"
7) "runid"
8) "f703cd022b4508cd9e126661da7c8d18a8df5b70"
9) "flags"
10) "slave"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "652"
19) "last-ping-reply"
20) "652"
21) "down-after-milliseconds"
22) "10000"
23) "info-refresh"
24) "2994"
25) "role-reported"
26) "slave"
27) "role-reported-time"
28) "364345"
29) "master-link-down-time"
30) "0"
31) "master-link-status"
32) "ok"
33) "master-host"
34) "10.0.0.124"
35) "master-port"
36) "6379"
37) "slave-priority"
38) "100"
39) "slave-repl-offset"
40) "106350"
41) "replica-announced"
42) "1"
2) 1) "name"
2) "10.0.0.123:6379"
3) "ip"
4) "10.0.0.123"
5) "port"
6) "6379"
7) "runid"
8) "f118217c9021f2c7680a1e0e47ccc2e983126e10"
9) "flags"
10) "slave"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "753"
19) "last-ping-reply"
20) "753"
21) "down-after-milliseconds"
22) "10000"
23) "info-refresh"
24) "946"
25) "role-reported"
26) "slave"
27) "role-reported-time"
28) "238239"
29) "master-link-down-time"
30) "0"
31) "master-link-status"
32) "ok"
33) "master-host"
34) "10.0.0.124"
35) "master-port"
36) "6379"
37) "slave-priority"
38) "100"
39) "slave-repl-offset"
40) "106767"
41) "replica-announced"
42) "1"SENTINEL failover
使用场景:主动维护主节点,需停机维护主节点时,手动触发故障转移,避免服务中断。
强制将一个主节点(master)切换到其从节点(slave),而无需等待 Sentinel 自动检测故障。
redis-cli -p 16379
127.0.0.1:16379> SENTINEL failover redis_master之后验证主从角色是否发生改变
SENTINEL reset
强制重置 Sentinel 的监控状态。它可以清除 Sentinel 对某个主节点(master)或所有主节点的旧状态,重新发现其从节点(slaves)和 Sentinel 节点信息。
redis-cli -p 16379
127.0.0.1:16379> SENTINEL RESET redis_master