背景意义
研究背景与意义
脑部CT图像的分割在医学影像分析中扮演着至关重要的角色,尤其是在脑部疾病的诊断和治疗中。随着影像学技术的不断进步,CT扫描已成为评估脑部病变的重要工具。然而,传统的手动分割方法不仅耗时,而且容易受到人为因素的影响,导致分割结果的不一致性。因此,开发高效、准确的自动化分割系统显得尤为重要。
近年来,深度学习技术的迅猛发展为医学图像处理带来了新的机遇。YOLO(You Only Look Once)系列模型因其在目标检测任务中的高效性和准确性而受到广泛关注。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更快的推理速度,适合处理复杂的医学图像数据。通过对YOLOv11进行改进,可以更好地适应脑部CT图像的特征,从而提高分割的精度和效率。
本研究基于一个包含5500幅脑部CT图像的数据集,数据集中标注了两类重要的脑部结构。这些图像经过精心的预处理和数据增强,以提高模型的泛化能力和鲁棒性。通过利用深度学习技术,我们希望能够实现对脑部CT图像的高效分割,为临床医生提供更为准确的诊断依据。
综上所述,基于改进YOLOv11的脑部CT图像分割系统的研究,不仅具有重要的学术价值,也为临床实践提供了有力的支持。通过该系统的开发与应用,可以有效提升脑部疾病的早期诊断率,从而改善患者的治疗效果和生存质量。
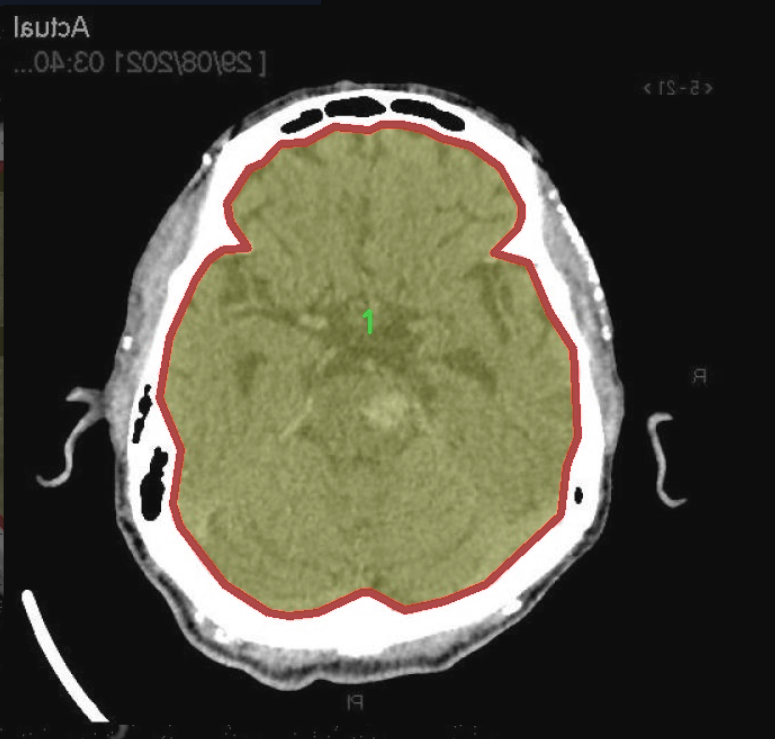
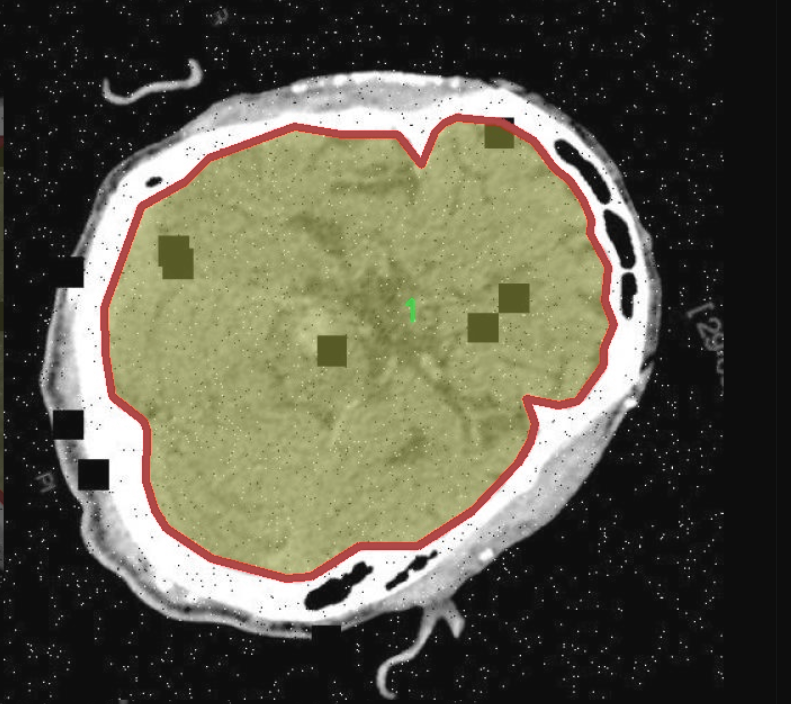
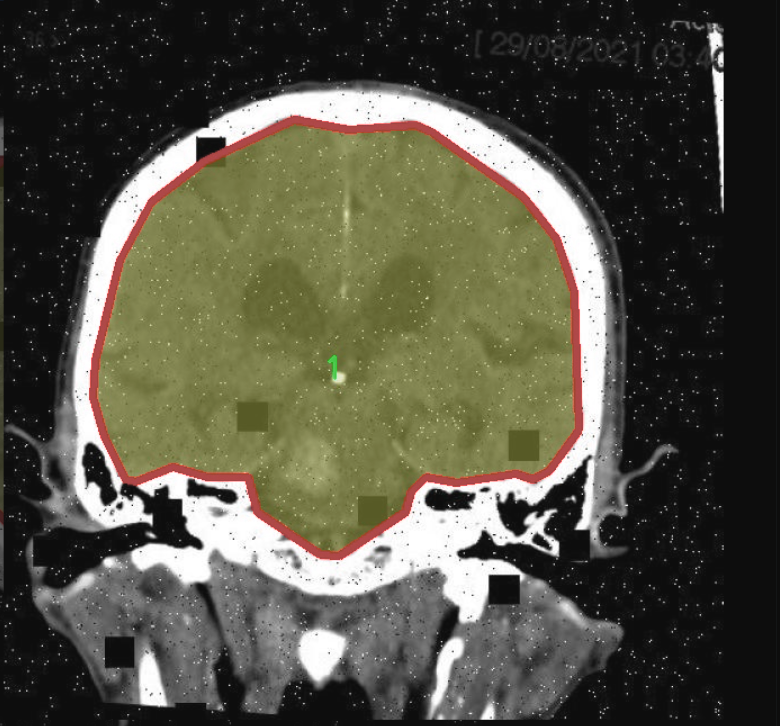
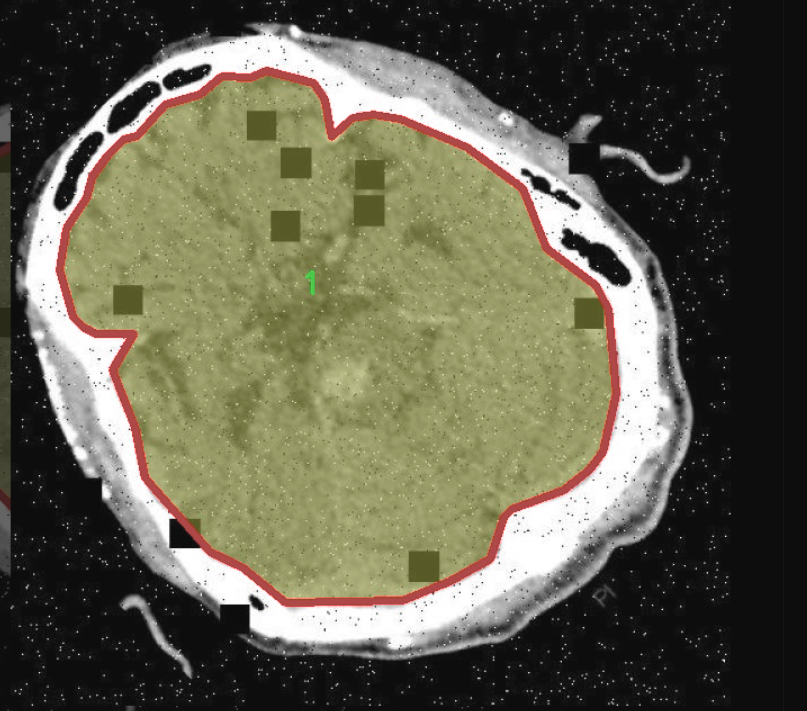
图片效果
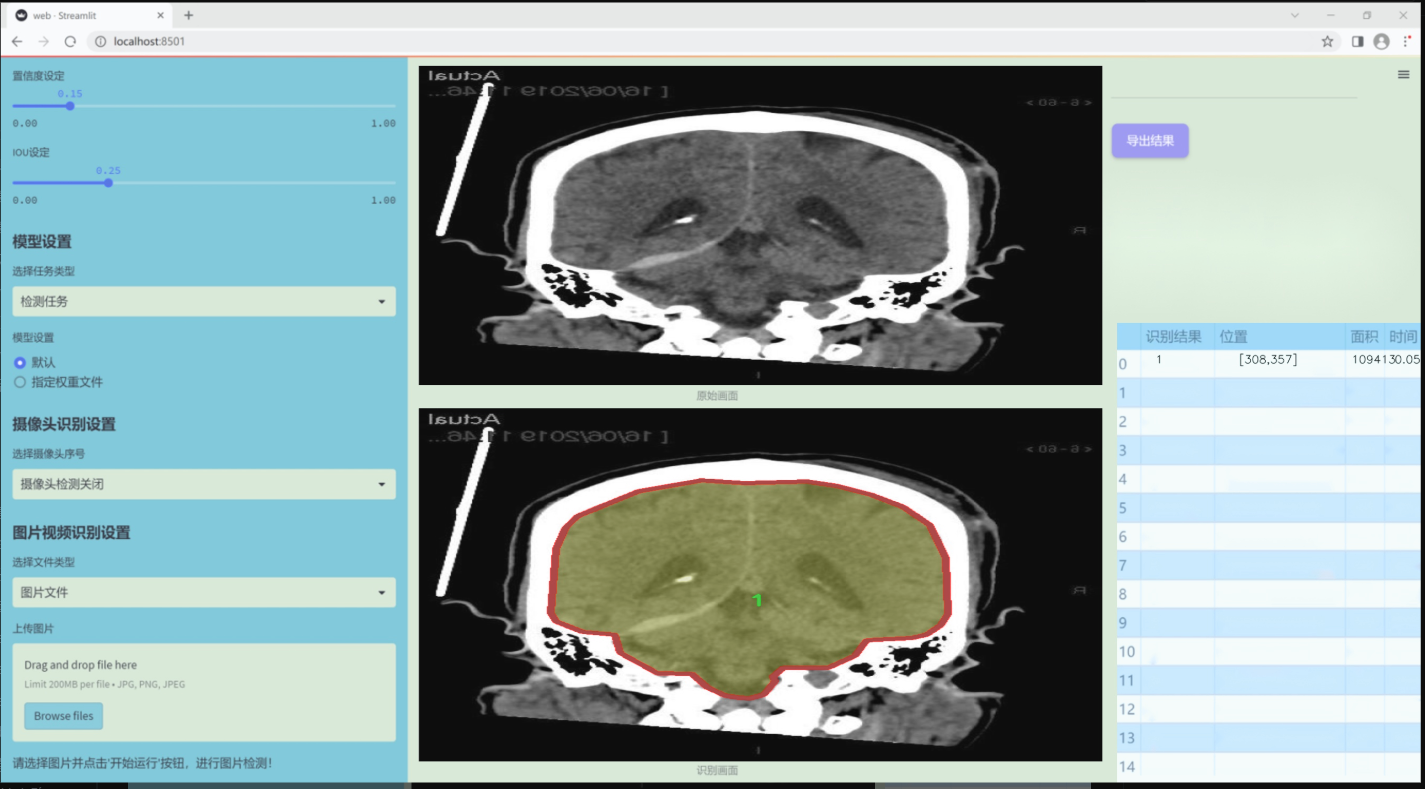
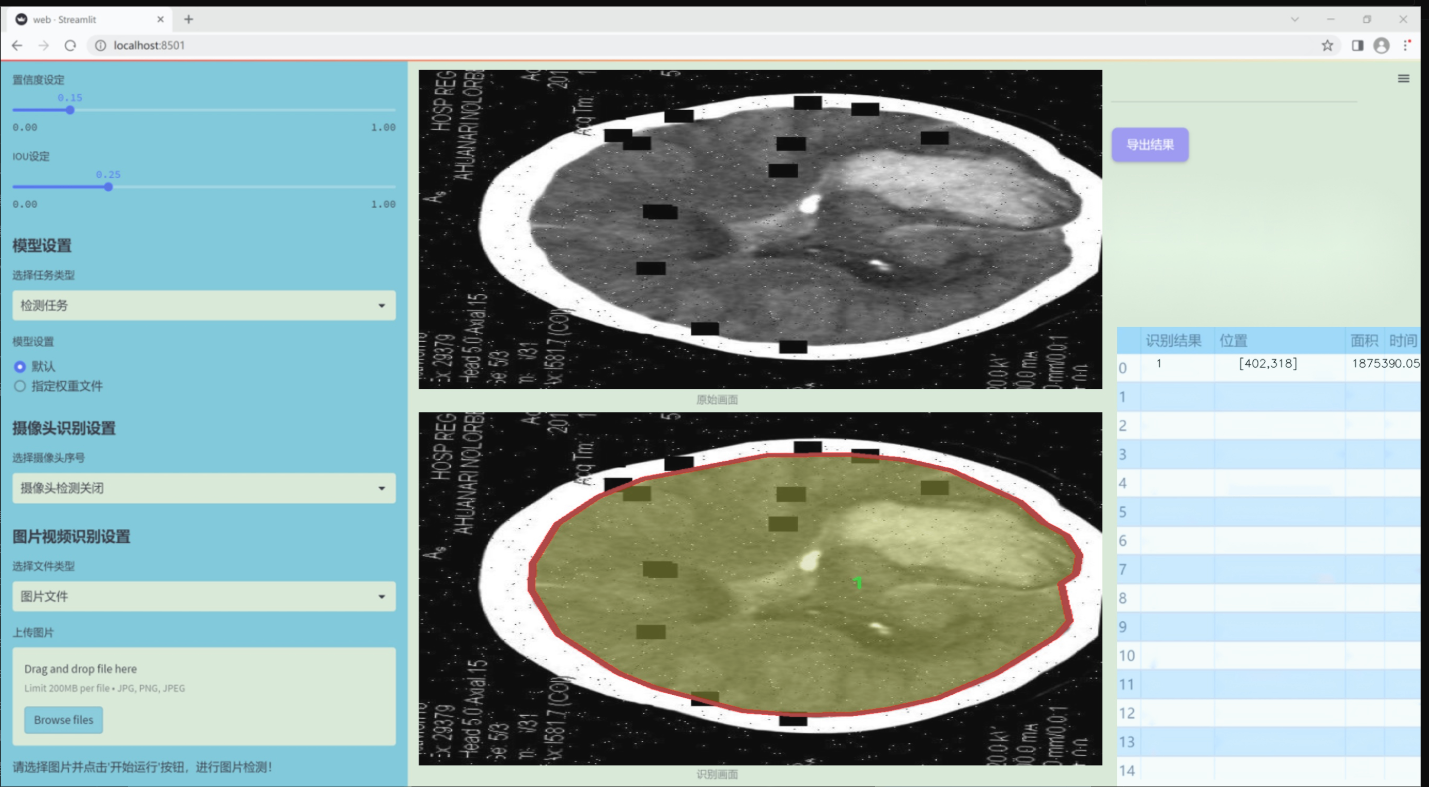
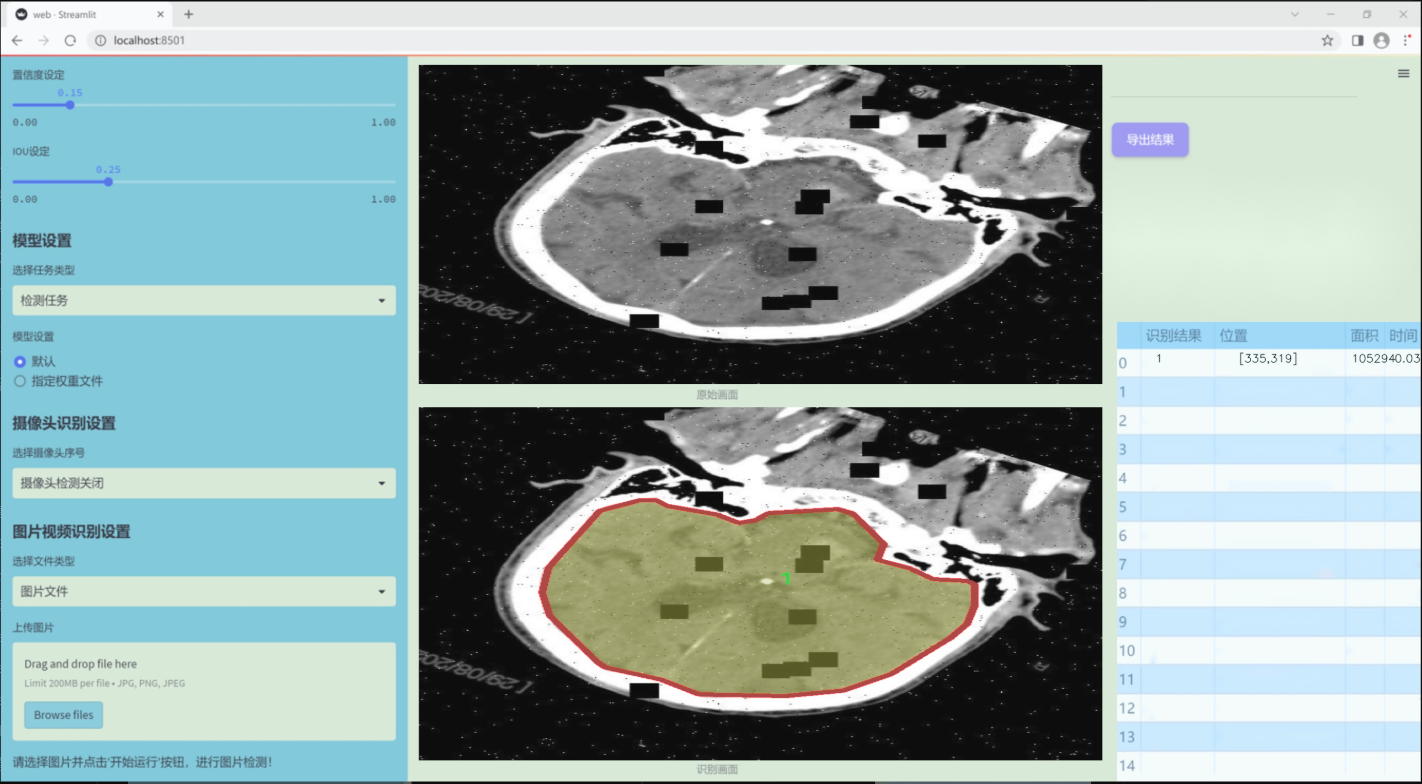
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的脑部CT图像分割系统,因此所使用的数据集专注于"CT脑部分割"这一主题。该数据集包含了大量经过精心标注的脑部CT图像,旨在为模型的训练提供丰富的样本。数据集中包含两个主要类别,分别标记为"0"和"1",这两个类别代表了不同的脑部结构或病变区域。具体而言,类别"0"通常指代健康的脑组织,而类别"1"则可能对应于存在病变或异常的区域,如肿瘤、出血或其他病理变化。
数据集的构建过程经过严格的筛选和标注,确保每一幅CT图像都能准确反映其对应的类别特征。这一过程不仅提高了数据的质量,也为后续的模型训练提供了坚实的基础。数据集中的图像涵盖了不同年龄段、性别及病理状态的患者,确保了模型在实际应用中的广泛适用性和鲁棒性。
在训练过程中,数据集将被用于监督学习,模型将通过不断调整参数来优化对不同类别的识别能力。通过引入多样化的样本,模型能够学习到更为复杂的特征,从而提高分割的准确性和效率。此外,数据集的规模和多样性也为模型的泛化能力提供了保障,使其能够在面对未见过的CT图像时,依然保持良好的表现。
综上所述,本项目的数据集不仅为YOLOv11的改进提供了必要的训练基础,也为脑部CT图像的自动化分析奠定了重要的理论和实践基础,期待通过这一研究能够推动医学影像分析领域的发展
核心代码
以下是提取出的核心部分代码,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
定义OREPA模块
class OREPA(nn.Module):
def init (self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, dilation=1, act=True):
super(OREPA, self).init()
# 初始化参数
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding if padding is not None else (kernel_size // 2)
self.groups = groups
self.dilation = dilation
# 激活函数
self.nonlinear = nn.ReLU() if act else nn.Identity()
# 定义卷积层参数
self.weight_orepa_origin = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, kernel_size, kernel_size))
self.weight_orepa_avg_conv = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, 1, 1))
self.weight_orepa_pfir_conv = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, 1, 1))
# 初始化参数
nn.init.kaiming_uniform_(self.weight_orepa_origin, a=0.0)
nn.init.kaiming_uniform_(self.weight_orepa_avg_conv, a=0.0)
nn.init.kaiming_uniform_(self.weight_orepa_pfir_conv, a=0.0)
# 其他参数
self.vector = nn.Parameter(torch.Tensor(6, out_channels)) # 用于加权不同分支的权重
# 初始化向量
self.init_vector()
def init_vector(self):
# 初始化向量的值
nn.init.constant_(self.vector[0, :], 0.25) # origin
nn.init.constant_(self.vector[1, :], 0.25) # avg
nn.init.constant_(self.vector[2, :], 0.0) # prior
nn.init.constant_(self.vector[3, :], 0.5) # 1x1_kxk
nn.init.constant_(self.vector[4, :], 1.0) # 1x1
nn.init.constant_(self.vector[5, :], 0.5) # dws_conv
def weight_gen(self):
# 生成最终的卷积权重
weight_orepa_origin = self.weight_orepa_origin * self.vector[0, :].view(-1, 1, 1, 1)
weight_orepa_avg = self.weight_orepa_avg_conv * self.vector[1, :].view(-1, 1, 1, 1)
weight_orepa_pfir = self.weight_orepa_pfir_conv * self.vector[2, :].view(-1, 1, 1, 1)
# 将所有权重相加
weight = weight_orepa_origin + weight_orepa_avg + weight_orepa_pfir
return weight
def forward(self, inputs):
# 前向传播
weight = self.weight_gen() # 生成权重
out = F.conv2d(inputs, weight, stride=self.stride, padding=self.padding, dilation=self.dilation, groups=self.groups)
return self.nonlinear(out) # 应用激活函数示例:使用OREPA模块
model = OREPA(in_channels=3, out_channels=16)
input_tensor = torch.randn(1, 3, 32, 32) # 假设输入为1张3通道32x32的图像
output = model(input_tensor) # 前向传播
print(output.shape) # 输出形状
代码注释说明:
OREPA类:这是一个自定义的神经网络模块,继承自nn.Module。它的主要功能是实现一种新的卷积结构,支持多种分支的卷积操作。
初始化方法:在__init__中,定义了输入输出通道、卷积核大小、步幅、填充、分组数和扩张率等参数,并初始化卷积层的权重。
激活函数:根据参数选择使用ReLU激活函数或恒等函数。
权重生成:weight_gen方法根据不同的分支权重生成最终的卷积权重。
前向传播:在forward方法中,调用weight_gen生成权重,并通过F.conv2d进行卷积操作,最后应用激活函数。
以上代码展示了OREPA模块的核心功能,并通过示例展示了如何使用该模块。
这个程序文件 orepa.py 是一个基于 PyTorch 的深度学习模型实现,主要涉及到一种名为 OREPA(Origin-RepVGG Efficient Pointwise Attention)的卷积神经网络结构。文件中定义了多个类和函数,主要用于构建和训练深度学习模型。
首先,文件导入了必要的库,包括 PyTorch 的核心库、神经网络模块、数学库和 NumPy。接着,定义了一些辅助函数,如 transI_fusebn 和 transVI_multiscale,这些函数用于处理卷积核和批归一化层的参数转换,以及对卷积核进行多尺度填充。
OREPA 类是这个文件的核心类,继承自 nn.Module。在其构造函数中,初始化了多个参数,包括输入和输出通道数、卷积核大小、步幅、填充、分组卷积、扩张率等。根据是否部署(deploy 参数),它会选择不同的初始化方式。如果是部署模式,则直接使用标准的卷积层;否则,它会初始化多个卷积核参数,并通过 Kaiming 正态分布进行初始化。
在 OREPA 类中,定义了 weight_gen 方法,该方法生成最终的卷积权重。它通过多个分支的权重加权组合来生成最终的卷积核,这些分支包括原始卷积、平均卷积、1x1 卷积等。forward 方法实现了前向传播,使用生成的权重进行卷积操作,并通过非线性激活函数和批归一化层进行处理。
OREPA_LargeConv 类实现了大卷积核的 OREPA 结构,允许使用更大的卷积核进行特征提取。它的构造函数和前向传播方法与 OREPA 类类似,但在权重生成和卷积操作上有所不同。
ConvBN 类是一个简单的卷积加批归一化的组合,支持在部署模式下直接使用卷积层,或者在训练模式下使用卷积和批归一化。
OREPA_3x3_RepVGG 类是一个具体的 OREPA 结构实现,专门针对 3x3 卷积核进行设计。它的构造函数中初始化了多个参数,并定义了权重生成方法和前向传播方法。
最后,RepVGGBlock_OREPA 类实现了一个复合块,结合了 OREPA 和 SEAttention(Squeeze-and-Excitation Attention)机制。它在前向传播中结合了多个分支的输出,提供了更强的特征表达能力。
整体而言,这个文件实现了一个灵活且高效的卷积神经网络结构,支持多种卷积配置和参数初始化方式,适用于各种计算机视觉任务。
10.4 transformer.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
from functools import partial
引入自定义的RepBN和LinearNorm模块
from .prepbn import RepBN, LinearNorm
from ...modules.transformer import TransformerEncoderLayer
定义线性归一化和RepBN的组合
ln = nn.LayerNorm
linearnorm = partial(LinearNorm, norm1=ln, norm2=RepBN, step=60000)
class TransformerEncoderLayer_RepBN(TransformerEncoderLayer):
def init (self, c1, cm=2048, num_heads=8, dropout=0, act=..., normalize_before=False):
初始化父类TransformerEncoderLayer
super().init(c1, cm, num_heads, dropout, act, normalize_before)
# 使用线性归一化和RepBN进行归一化
self.norm1 = linearnorm(c1)
self.norm2 = linearnorm(c1)class AIFI_RepBN(TransformerEncoderLayer_RepBN):
"""定义AIFI变换器层。"""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):
"""使用指定参数初始化AIFI实例。"""
super().__init__(c1, cm, num_heads, dropout, act, normalize_before)
def forward(self, x):
"""AIFI变换器层的前向传播。"""
c, h, w = x.shape[1:] # 获取输入张量的通道数、高度和宽度
pos_embed = self.build_2d_sincos_position_embedding(w, h, c) # 构建2D位置嵌入
# 将输入张量从形状[B, C, H, W]展平为[B, HxW, C]
x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))
# 将输出张量恢复为形状[B, C, H, W]
return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):
"""构建2D正弦-余弦位置嵌入。"""
assert embed_dim % 4 == 0, "嵌入维度必须是4的倍数,以便进行2D正弦-余弦位置嵌入"
# 创建宽度和高度的网格
grid_w = torch.arange(w, dtype=torch.float32)
grid_h = torch.arange(h, dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing="ij")
pos_dim = embed_dim // 4 # 计算位置嵌入的维度
omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
omega = 1.0 / (temperature**omega) # 温度缩放
# 计算位置嵌入
out_w = grid_w.flatten()[..., None] @ omega[None]
out_h = grid_h.flatten()[..., None] @ omega[None]
# 返回组合的正弦和余弦位置嵌入
return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]代码注释说明:
模块导入:导入必要的PyTorch模块和自定义模块。
归一化定义:使用partial函数定义了一个结合了线性归一化和RepBN的归一化方法。
TransformerEncoderLayer_RepBN类:继承自TransformerEncoderLayer,在初始化时设置了两个归一化层。
AIFI_RepBN类:继承自TransformerEncoderLayer_RepBN,定义了AIFI变换器层的前向传播方法。
前向传播:在前向传播中,输入张量被展平并与位置嵌入结合,然后输出恢复为原始形状。
位置嵌入构建:静态方法build_2d_sincos_position_embedding用于生成2D正弦-余弦位置嵌入,确保嵌入维度为4的倍数。
这个程序文件 transformer.py 定义了一个基于 Transformer 的编码层,主要用于处理图像或序列数据。文件中引入了 PyTorch 库,并且包含了一些自定义的模块和类。
首先,文件导入了必要的 PyTorch 模块,包括 torch 和 torch.nn,以及一些功能性模块。接着,它从其他文件中引入了 RepBN 和 LinearNorm,这些可能是自定义的归一化层。TransformerEncoderLayer 和 AIFI 也被引入,这表明该文件可能是 Transformer 模型的一部分。
在文件中,使用了 partial 函数来创建一个新的归一化函数 linearnorm,这个函数结合了 LayerNorm 和 RepBN,并设置了一个步数参数。接下来,定义了一个名为 TransformerEncoderLayer_RepBN 的类,它继承自 TransformerEncoderLayer。在其构造函数中,调用了父类的构造函数,并定义了两个归一化层 norm1 和 norm2,这两个层使用了之前定义的 linearnorm。
接下来,定义了 AIFI_RepBN 类,它继承自 TransformerEncoderLayer_RepBN,并在其构造函数中初始化了一些参数,如通道数、隐藏层大小、头数、丢弃率、激活函数和归一化标志。这个类的主要功能是实现 AIFI Transformer 层。
在 AIFI_RepBN 类中,重写了 forward 方法,这是模型前向传播的核心部分。输入 x 的形状为 B, C, H, W,表示批量大小、通道数、高度和宽度。首先,提取出通道数、高度和宽度,并调用 build_2d_sincos_position_embedding 方法生成二维的正弦余弦位置嵌入。然后,将输入张量展平并调整维度,传递给父类的 forward 方法进行处理,最后将输出重新排列为原始的形状。
build_2d_sincos_position_embedding 是一个静态方法,用于构建二维的正弦余弦位置嵌入。它首先检查嵌入维度是否可以被4整除,然后生成宽度和高度的网格,并计算出位置嵌入。最终返回的结果是一个包含正弦和余弦值的张量。
总的来说,这个文件实现了一个自定义的 Transformer 编码层,结合了不同的归一化方法,并引入了位置嵌入的概念,以便在处理图像或序列数据时能够更好地捕捉空间或时间信息。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻