引言
学习一门新语言,一般第一步都是学习该语言的数据类型 和变量。通过这篇文章,你将了解Go语言中的以下内容:
- 变量的声明和使用
- 常见的数据类型
- 基本类型和引用类型的区别
一、变量
Go 是静态类型语言,变量的类型在声明时确定(或由编译器自动推断),且一旦确定就不能更改,这保证了类型安全。以下从核心特性、声明方式、零值机制、作用域等方面详细介绍:
1.1 变量的核心要素
每个变量都包含三个核心要素:
- 名称:遵循 Go 命名规范(字母、数字、下划线,首字母不能为数字;首字母大写表示 "导出",可被其他包访问;小写仅包内可见)。
- 类型 :决定变量可存储的数据种类(如
int、string等),限制了可执行的操作(如int可加减,string不可)。 - 值:变量存储的具体数据,可通过赋值修改(但类型不能变)。
1.2变量的声明方式
Go 提供了多种声明变量的方式,适用于不同场景,核心是通过 var 关键字或短变量声明符 := 实现。
标准声明(var关键字)
最基础的声明方式,格式为 var 变量名 类型,可单独声明或批量声明,支持只声明不初始化(依赖零值机制)。
- 单独声明
go
var age int // 声明int类型变量age(未初始化,依赖零值)
var name string // 声明string类型变量name(未初始化)- 批量声明
go
var (
count int // 零值为0
isValid bool // 零值为false
message string // 零值为""(空串)
)声明并初始化
声明时直接赋值,可省略类型(编译器会根据右值自动推断类型),更简洁。
- 显式指定类型
go
var score int = 90 // 声明int类型,赋值90- 省略类型(自动推断)
go
var height = 1.75 // 自动推断为float64(Go默认浮点数为float64)
var username = "alice" // 自动推断为string短变量声明(:=,推荐函数内使用)
Go 特有的简洁语法,格式为 变量名 := 值,同时完成声明和初始化,且必须在函数内部使用(包级变量不支持)。
- 基本用法
go
func main() {
age := 20 // 等价于 var age int = 20(自动推断类型)
name := "bob" // 等价于 var name string = "bob"
}- 同时声明多个变量:用逗号分隔,支持混合类型
go
func main() {
x, y := 10, 3.14 // x是int,y是float64
isReady, msg := true, "done" // isReady是bool,msg是string
}- 💥注意 :
:=必须至少声明一个新变量,否则编译错误(避免重复声明):
go
func main() {
a := 10
a, b := 20, 30 // 合法:b是新变量,a是已存在变量(重新赋值)
// a, c := 40, 50 // 错误:若a已存在且c不是新变量(假设c之前声明过)
}1.3 零值机制
Go 的重要特性:用 var 声明但未手动初始化的变量,会被自动赋予 "零值" (不同类型的零值固定),避免了未定义行为(区别于 C/C++ 中未初始化变量的 "垃圾值")。
常见类型的零值:
| 类型分类 | 零值示例 |
|---|---|
| 数值类型(int、float 等) | 0(int)、0.0(float64) |
| 布尔类型(bool) | false |
| 字符串(string) | ""(空字符串) |
| 引用类型(切片、map、指针等) | nil(空引用) |
| 结构体(struct) | 所有字段均为对应类型的零值 |
示例:
go
var a int // 零值:0
var b float64 // 零值:0.0
var c bool // 零值:false
var d string // 零值:""
var e []int // 零值:nil
var f map[int]string // 零值:nil
type Person struct {
Age int
Name string
}
var p Person // 零值:p.Age=0,p.Name=""在 Go 语言中,
nil是一个预定义的标识符 ,表示 "空值" 或 "无引用"------ 它仅用于引用类型 ,是这类类型的 "零值"(对应你示例中e []int、f map[int]string的零值)。与int零值0、string零值""不同,nil不代表具体的数据,而是表示 "该引用类型没有指向任何有效的内存地址或数据结构"。
1.4 变量的作用域
变量的可见范围,决定了在哪些代码块中可以访问该变量,分为以下几类:
局部变量
在函数或代码块(如 if、for、switch 内)中声明,仅在该范围内有效。
go
func main() {
x := 10 // main函数内的局部变量,整个main可见
if true {
y := 20 // if块内的局部变量,仅if内可见
fmt.Println(x, y) // 合法:x和y均在作用域内
}
// fmt.Println(y) // 错误:y已超出作用域
}包级变量
在函数外、包内声明,整个包内的所有函数均可访问(首字母大写时,其他包也可访问)。
go
package main
var globalVar = "我是包级变量" // 包内所有函数可见
func foo() {
fmt.Println(globalVar) // 合法:访问包级变量
}
func main() {
foo() // 输出:我是包级变量
}Go 中变量的 "可见性"(能否被其他包访问)由变量名的首字母大小写决定:
- 首字母大写 :变量是 "导出的"(exported),可被其他包通过
包名.变量名访问。 - 首字母小写:变量是 "非导出的"(unexported),仅当前包内可见,其他包无法访问。
示例:
go
// 包:mypkg(文件路径:mypkg/var.go)
package mypkg
var ExportedVar = "我可被其他包访问" // 首字母大写,导出
var unexportedVar = "我仅包内可见" // 首字母小写,非导出其他包访问:
go
package main
import "mypkg"
func main() {
fmt.Println(mypkg.ExportedVar) // 合法:访问导出变量
// fmt.Println(mypkg.unexportedVar) // 错误:非导出变量不可访问
}1.5 变量的类型转换
Go 是强类型语言,不同类型的变量赋值必须显式转换(无隐式转换),格式为 目标类型(变量)。
go
var a int = 10
var b float64 = float64(a) // 显式将int转为float64(正确)
// var c float64 = a // 错误:隐式转换不允许
var s string = "123"
// var num int = int(s) // 错误:string不能直接转为int(需用strconv包)1.6 小结
Go 变量的核心特性可概括为:
- 声明方式灵活:
var适合包级或需显式类型的场景,:=适合函数内的简洁声明。 - 零值机制保证安全:未初始化变量有明确默认值,避免未定义行为。
- 作用域和可见性清晰:通过代码块控制作用域,通过首字母大小写控制跨包访问。
理解这些特性是编写规范 Go 代码的基础,尤其要注意 := 的使用限制和零值对程序逻辑的影响。
二、数据类型
Go 语言的数据类型体系清晰,可分为四大类:基本类型 、复合类型 、引用类型 和 接口类型。每种类型都有明确的内存布局和使用场景,且 Go 是静态类型语言,变量类型一旦确定便不可更改(无隐式类型转换)。以下是详细分类及说明:
2.1 基本类型
基本类型是不可再拆分的 "原子类型",直接对应具体的值,包括数值、布尔和字符串。
整数类型
用于表示整数,按 "符号" 和 "位数" 划分,明确的位数避免跨平台差异。
| 类型 | 范围(示例) | 说明 |
|---|---|---|
int8 |
-128 ~ 127 | 8 位有符号整数 |
int16 |
-32768 ~ 32767 | 16 位有符号整数 |
int32 |
-2³¹ ~ 2³¹-1 | 32 位有符号整数(rune 是其别名,用于表示 Unicode 码点) |
int64 |
-2⁶³ ~ 2⁶³-1 | 64 位有符号整数 |
uint8 |
0 ~ 255 | 8 位无符号整数(byte 是其别名,用于表示 ASCII 字符) |
uint16 |
0 ~ 65535 | 16 位无符号整数 |
uint32 |
0 ~ 2³²-1 | 32 位无符号整数 |
uint64 |
0 ~ 2⁶⁴-1 | 64 位无符号整数 |
int |
与平台位数一致(32/64 位) | 依赖平台的有符号整数(通常优先用明确位数类型) |
uint |
与平台位数一致(32/64 位) | 依赖平台的无符号整数 |
uintptr |
与平台指针位数一致 | 用于存储指针地址(仅在底层操作时使用) |
浮点数类型
| 类型 | 精度 | 范围(约) |
|---|---|---|
float32 |
6-7 位小数 | ±3.4×10³⁸ |
float64 |
15-17 位小数 | ±1.8×10³⁰⁸ |
复数类型
用于表示复数(实部 + 虚部),虚部用 i 标识。
| 类型 | 实部 / 虚部类型 | 示例 |
|---|---|---|
complex64 |
float32 |
3.0 + 4.0i |
complex128 |
float64 |
1.5 + 2.5i |
布尔类型
仅表示 "真" 或 "假",不可与其他类型(如整数)转换(区别于 C/C++)。
| 类型 | 可能值 | 零值 |
|---|---|---|
bool |
true、false |
false |
字符串类型
表示不可变的字节序列(默认 UTF-8 编码),用于存储文本。
特点:
- 不可直接修改(需转换为
[]byte或[]rune后修改,再转回string); - 长度(
len(s))返回字节数(非字符数,如"世界"的len为 6,因每个中文字符占 3 字节 UTF-8); - 支持拼接(
+)、索引(s[i]获取字节)、切片(s[low:high]获取子串)。
示例:
go
var s1 string = "hello"
s2 := "世界" // 自动推断为 string 类型
fmt.Println(len(s1)) // 输出:5(5个字节)
fmt.Println(len(s2)) // 输出:6(2个中文字符,每个3字节)
// 字符串拼接
s3 := s1 + ", " + s2 // s3 = "hello, 世界"2.2 复合类型
复合类型由基本类型组合而成,用于表示复杂结构,包括数组和结构体。
数组
数组是一组具有相同类型且长度固定的数据集合。定义格式 :[长度]元素类型,数组的长度是其类型的一部分,因此 [5]int 和 [10]int 是不同的类型。
特点:
- 长度固定(声明后不可修改);
- 赋值或传参时复制整个数组(效率低,大数组不推荐直接使用);
- 零值为 "每个元素都是对应类型的零值"(如
[3]int的零值为[0, 0, 0])。
示例:
go
var arr1 [3]int // 长度为3的int数组,零值 [0, 0, 0]
arr2 := [4]string{"a", "b"} // 初始化,未指定的元素为零值(""),结果 ["a", "b", "", ""]
arr3 := [...]int{1, 2, 3} // 长度由初始化元素数量自动推断(3)
// 访问元素(索引从0开始)
fmt.Println(arr3[1]) // 输出:2
// 数组是值类型(赋值时复制)
arr4 := arr3
arr4[0] = 100
fmt.Println(arr3[0]) // 输出:1(arr3 未被修改)结构体
多个不同类型字段的集合,用于封装数据(Go 中无 "类",结构体是数据封装的核心)。
定义格式:
go
type 结构体名 struct {
字段名1 类型1
字段名2 类型2
// ...
}特点:
- 字段名首字母大写可被其他包访问(导出),小写仅包内可见;
- 零值为 "所有字段都是对应类型的零值";
- 支持 "结构体嵌套"(组合代替继承,实现代码复用)。
示例:
go
// 定义结构体
type Person struct {
Name string // 导出字段(首字母大写)
Age int // 导出字段
addr string // 非导出字段(仅包内可见)
}
// 初始化结构体
p1 := Person{Name: "Alice", Age: 25} // 按字段名初始化(推荐)
p2 := Person{"Bob", 30, "Beijing"} // 按字段顺序初始化(不推荐,易出错)
// 访问字段
fmt.Println(p1.Name) // 输出:Alice
p1.Age = 26 // 修改字段值2.3 引用类型
Go 语言中的引用类型 是一类特殊的数据类型,它们本身并不直接存储数据,而是存储指向底层数据结构的引用(指针)。赋值 / 传参时复制引用(不复制底层数据),多个变量指向同一份数据:
- 切片(Slice) :
[]T,动态长度的同类型序列(基于数组实现),支持动态扩容,通过make或字面量初始化。 - 映射(Map) :
map[K]V(K为可比较类型),键值对集合,用于快速查找,零值为nil,需make初始化后使用。 - 通道(Channel) :
chan T,用于 goroutine 间通信的管道,分有缓冲和无缓冲,零值为nil,需make初始化。 - 指针(Pointer) :
*T,存储变量地址,通过&取地址、*解引用,零值为nil。 - 函数(Function) :可作为变量、参数或返回值,本质是函数入口地址的引用,零值为
nil。
切片(Slice)
📝什么是切片?
切片是对底层数组的一个连续片段的引用。它提供了对数组序列的动态、灵活的视图。切片本身并不存储任何数据,它只是描述了底层数组中的一个片段。
你可以把它想象成一个结构体,它包含三个字段:
- 指针:指向底层数组中切片开始的元素。
- 长度(Length):切片中当前包含的元素个数(
len(s)可获取)。 - 容量(Capacity):从切片开始位置到底层数组结束位置的元素个数,即切片可以扩展的最大限度(
cap(s)可获取)。
这个结构决定了切片的所有行为。
📝切片的创建和初始化
- 使用字量直接声明
这类似于数组,但是不指定长度
go
s := []int{1, 2, 3, 4, 5} // 创建一个长度为5,容量为5的切片- 使用make函数
当你需要预先分配一定大小的切片时,使用 make是最佳选择。
go
// 创建一个长度为 5,容量也为 5 的切片,所有元素初始化为零值
s1 := make([]int, 5)
// 创建一个长度为 5,容量为 10 的切片
// 这意味着在不重新分配内存的情况下,它可以再追加 5 个元素
s2 := make([]int, 5, 10)- 通过已有的数组或切片切割(使用
[low:high])
切割操作是前闭后开区间,新切片与原数组或切片共享底层数组。
go
arr := [5]int{1, 2, 3, 4, 5}
s1 := arr[1:4] // 从数组创建切片,包含元素 arr[1], arr[2], arr[3]
s2 := s1[1:2] // 从切片创建新切片📝切片的常用操作
- 追加元素
使用append函数在切片末尾添加新元素。
go
s := []int{1, 2, 3}
s = append(s, 4) // s -> [1, 2, 3, 4]
s = append(s, 5, 6, 7) // 可以一次追加多个元素 -> [1, 2, 3, 4, 5, 6, 7]
s2 := []int{8, 9}
s = append(s, s2...) // 使用 ... 将另一个切片的所有元素追加进来 -> [1, 2, 3, 4, 5, 6, 7, 8, 9]扩容机制:如果追加元素后超出了切片的当前容量,
append函数会自动处理扩容 。它会创建一个新的、更大的底层数组,将原有数据复制过去,然后返回指向这个新数组的新切片。这是一个需要性能开销的操作,因此如果能预知大小,最好用make预先分配足够的容量。
- 复制切片
如果你需要两个切片拥有独立、不共享的数据副本,就需要使用 copy函数。
go
src := []int{1, 2, 3, 4, 5}
dst := make([]int, 3) // 创建一个长度为3的切片
num := copy(dst, src) // 将 src 的元素复制到 dst,最多复制 min(len(dst), len(src)) 个
fmt.Println(num, dst) // 输出: 3 [1 2 3]- 遍历切片
使用 for ... range循环是遍历切片最安全、最清晰的方式。
go
s := []string{"a", "b", "c"}
for index, value := range s {
fmt.Printf("索引: %d, 值: %s\n", index, value)
}
// 输出:
// 索引: 0, 值: a
// 索引: 1, 值: b
// 索引: 2, 值: c📝切片的内存模型与"陷阱"
理解切片的内存模型至关重要,可以避免很多常见的错误。
- 共享底层数组
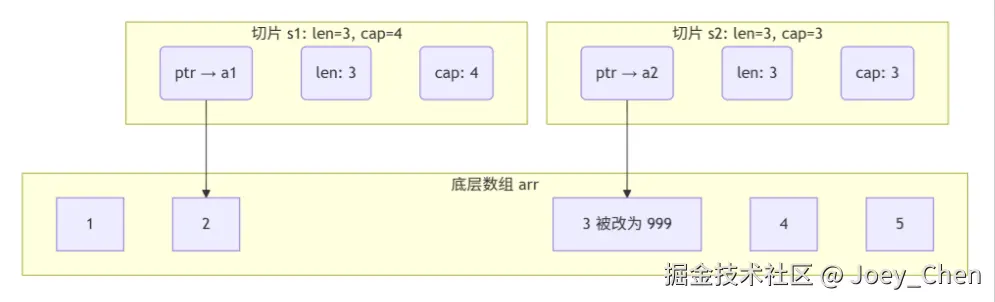
如下面的代码和图解所示,s1和 s2共享同一个底层数组。修改 s2[0]实际上就是修改了 arr[2],因此 s1也会"看到"这个变化。
go
arr := [5]int{1, 2, 3, 4, 5}
s1 := arr[1:4] // [2, 3, 4]
s2 := arr[2:5] // [3, 4, 5]
s2[0] = 999 // 修改 s2 的第一个元素
fmt.Println(s1) // 输出: [2, 999, 4]
fmt.Println(s2) // 输出: [999, 4, 5]
fmt.Println(arr) // 输出: [1, 2, 999, 4, 5]其内存模型可参考下图:
append可能导致分离
继续上面的例子,如果我们向 s2追加元素,会发生什么?
go
s2 = append(s2, 6)
s2[0] = 888 // 这次修改还会影响 s1 和 arr 吗?
fmt.Println(s1) // 输出: [2, 999, 4] (未变)
fmt.Println(s2) // 输出: [888, 4, 5, 6] (已变)
fmt.Println(arr) // 输出: [1, 2, 999, 4, 5] (未变)结果:没有影响。因为 append(s2, 6)时,s2的容量(3)已用完,Go 会为 s2分配一个新的底层数组 ,并将原来的 [999, 4, 5]复制过去,然后再追加 6。从此 s2和原数组 arr及 s1就"分离"了,对它们的修改互不影响。
📝切片与数组的对比
| 特性 | 切片 (Slice) | 数组 (Array) |
|---|---|---|
| 长度 | 动态,可变 | 固定,声明时确定 |
| 传递方式 | 引用传递(传递的是描述符,代价小) | 值传递(整个数组被复制,代价大) |
| 大小声明 | 不需要,是运行时概念 | 必须是编译时常量 |
| 声明方式 | s := []int{1,2}或 make([]int, len, cap) |
a := [2]int{1,2}或 a := [...]int{1,2} |
映射(Map)
📝map的创建和初始化
- 使用字面量
go
// 创建一个已包含初始键值对的 map
population := map[string]int{
"Beijing": 2154,
"Shanghai": 2428,
"Shenzhen": 1300, // 注意:最后一个逗号是必须的
}- 使用
make函数
go
// 创建一个键为 string,值为 int 的 map,初始为空
m1 := make(map[string]int)
// 创建并指定初始容量,用于性能优化
// 这并不会限制 map 的大小,只是提示运行时预先分配足够的内存,减少后续扩容次数
m2 := make(map[string]string, 100)- 错误的声明方式
go
var nilMap map[int]string // 这是一个 nil map
nilMap[1] = "Hello" // panic: assignment to entry in nil map (运行时错误!)切记: 必须使用 make或字面量初始化后才能对 map 进行操作。
📝映射的基本操作
- 添加和修改元素
使用 map[key] = value语法。如果 key 不存在,则添加新键值对;如果 key 已存在,则更新其对应的 value。
go
m := make(map[string]int)
m["Alice"] = 90 // 添加
m["Alice"] = 95 // 修改- 查找元素
使用 value, ok := map[key]语法:
-
如果 key 存在,
value是对应的值,ok为true。 -
如果 key 不存在,
value是 value 类型的零值,ok为false。
go
score, exists := m["Bob"]
if exists {
fmt.Println("Bob's score is", score)
} else {
fmt.Println("Bob does not exist in the map.")
}
// 也可以直接判断零值,但不推荐(如果 value 本身的零值也是有效数据,就会混淆)
if score != 0 { // 不推荐的做法
// ...
}- 删除元素
使用 delete(map, key)内置函数。即使 key 不存在,该操作也是安全的。
go
delete(m, "Alice") // 删除键 "Alice" 及其对应的值- 遍历元素
使用 for range循环。遍历顺序是随机的,这是 Go 语言故意设计的,以防止开发者依赖其内部顺序。
go
for key, value := range population {
fmt.Printf("City: %s, Population: %d million\n", key, value)
}
// 如果只需要 key 或 value,可以用下划线忽略另一个
for key := range population {
fmt.Println(key)
}📝注意
-
map并发不安全。
-
当 map 的 value 是结构体等类型时,直接取出的 value 是副本。修改这个副本不会影响 map 中的原值。
通道(Channel)
通道是一个类型化的、用于在 Goroutine 之间传递数据的管道。你可以把它想象成一个先进先出(FIFO)的消息队列,发送方(Sender)向一端发送数据,接收方(Receiver)从另一端接收数据。操作默认是阻塞的,这天然地实现了 Goroutine 间的同步。
通道也是引用类型,这意味着当你将一个通道变量赋值给另一个变量或传递给函数时,它们操作的是同一个底层通道数据结构。
通道需要搭配Goroutine一起学习,这里暂时只做一些简单的了解,后续会更新详细的文章。
📝创建通道
使用 make函数创建通道,必须指定其传递数据的类型。
go
// 创建一个传递 int 类型数据的通道
ch := make(chan int)
// 创建一个传递字符串指针的通道
chPtr := make(chan *string)
// 创建一个接口类型的通道
chInterface := make(chan interface{})📝通道的基本操作
通道的操作使用特殊的 <-运算符。
| 操作 | 语法 | 说明 |
|---|---|---|
| 发送 | ch <- value |
将 value发送到通道 ch。如果通道已满或无接收方,发送操作会阻塞。 |
| 接收 | value := <-ch |
从通道 ch接收一个值并赋给 value。如果通道为空,接收操作会阻塞。 |
| 关闭 | close(ch) |
关闭通道。关闭后无法再发送数据,但可以继续接收已存在的数据。 |
示例:
go
func main() {
ch := make(chan string) // 创建一个传递 string 的通道
// 启动一个 Goroutine(发送方)
go func() {
ch <- "Hello from the other side!" // 向通道发送数据
}()
// 在主 Goroutine 中(接收方)
msg := <-ch // 从通道接收数据,并会等待直到有数据到来
fmt.Println(msg) // 输出: Hello from the other side!
}指针(Pointer)
指针是存储变量内存地址的类型,用于间接访问或修改变量的值。
- 通过
&运算符获取变量地址(如p := &x表示p是x的指针)。 - 通过
*运算符解引用(如*p表示访问p指向的变量值)。 - 不支持指针运算:与 C 语言不同,Go 指针不能进行
p++等算术操作,更安全。 nil指针解引用会 panic:未指向任何变量的指针是nil,对其解引用会触发运行时错误。
示例:
go
// 未初始化的指针(nil)
var ptr *int
// fmt.Println(*ptr) // 错误:解引用 nil 指针会 panic
// 初始化(指向一个变量)
x := 100
ptr = &x // ptr 指向 x 的地址
// 解引用修改值
*ptr = 200
fmt.Println(x) // 输出 200(x 被修改,因 ptr 指向 x)
// 赋值:复制引用(指向同一个变量)
ptr2 := ptr
*ptr2 = 300
fmt.Println(x) // 输出 300(x 再次被修改)函数(Function)
在 Go 中,函数是 "一等公民",可作为变量、参数或返回值,本质上是存储函数入口地址的引用类型。
- 函数类型由 "参数类型" 和 "返回值类型" 决定(与函数名无关)。
nil函数调用会 panic:未初始化的函数变量是nil,调用会触发运行时错误。
示例:
go
// 定义一个函数类型
type MathFunc func(int, int) int
// 未初始化的函数变量(nil)
var f MathFunc
// f(1, 2) // 错误:调用 nil 函数会 panic
// 初始化(赋值一个具体函数)
add := func(a, b int) int {
return a + b
}
f = add
// 调用函数变量
fmt.Println(f(2, 3)) // 输出 5
// 函数作为参数
compute := func(a, b int, op MathFunc) int {
return op(a, b)
}
fmt.Println(compute(4, 5, f)) // 输出 9(调用 add 函数)2.4 接口类型
接口定义一组方法签名,任何类型只要实现了接口的所有方法,就 "隐式" 满足该接口(无需显式声明),是 Go 实现多态的核心。
非空接口
包含具体方法签名的接口,定义 "行为规范"。
定义格式:
go
type 接口名 interface {
方法名1(参数列表) 返回值列表
方法名2(参数列表) 返回值列表
// ...
}示例:
go
// 定义接口(规范"可奔跑"的行为)
type Runner interface {
Run() string
}
// 结构体实现接口(隐式,无需声明)
type Dog struct{}
func (d Dog) Run() string {
return "Dog is running"
}
type Cat struct{}
func (c Cat) Run() string {
return "Cat is running"
}
// 接口变量可接收所有实现接口的类型
func main() {
var r Runner
r = Dog{}
fmt.Println(r.Run()) // 输出:Dog is running
r = Cat{}
fmt.Println(r.Run()) // 输出:Cat is running
}空接口
无任何方法的接口,可接收任意类型的值 (类似其他语言的 Object)。
特点:
- 常用于需要 "通用类型" 的场景(如函数参数需支持多种类型);
- 判断空接口存储的实际类型需用 "类型断言"(
x.(Type))。
示例:
go
// 空接口变量可接收任何类型
var any interface{}
any = 100 // 存储 int
any = "hello" // 存储 string
any = []int{1, 2} // 存储 []int
// 类型断言(判断实际类型)
if s, ok := any.(string); ok {
fmt.Println("是字符串:", s)
} else {
fmt.Println("不是字符串")
}类型断言:格式:value, ok := x.(T)
-
返回值 1(value):若断言成功(
ok=true),则value是x底层存储的T类型的值;若断言失败(ok=false),则value是T类型的零值(如string的零值是"",int的零值是0)。 -
返回值 2(ok):
bool类型,true表示断言成功,false表示失败(不会触发panic,推荐在不确定类型时使用)。
2.5 小结
数据类型可以分为值类型和引用类型:
-
值类型:2.1介绍的基本类型,以及数组和结构体
-
引用类型:除了2.3介绍的几种类型,接口类型也是引用类型
值类型和引用类型的对比如下:
| 特性 | 值类型(Value Types) | 引用类型(Reference Types) |
|---|---|---|
| 存储内容 | 直接存储数据本身 | 存储数据的内存地址(一个引用) |
| 赋值/传参 | 复制整个数据(创建独立副本) | 复制引用(地址)(共享同一份底层数据) |
| 修改影响 | 修改副本不影响原值 | 通过引用修改数据会影响所有指向它的变量 |
| 函数参数 | 传递数据的副本(函数内修改不影响外界) | 传递数据的地址(函数内修改会影响外界) |
| 比较操作 | 可比较(如果其字段都可比较) | 不可比较(除了和 nil比较) |
| 内存位置 | 通常在栈上分配(由编译器决定) | 底层数据总是在堆上分配(由 GC 回收) |
💡 怎么理解接口也是引用类型?
接口变量在内存中存储的不是数据本身,而是两个指针:
-
tab:指向接口动态类型信息的方法表(类似 C++ 的 vtable)。 -
data:指向实际存储的动态值(即赋值给接口的那个具体值)。
因为接口变量存储的是指向数据的地址,所以它被归为引用类型。赋值和传参时,复制的是这个"类型-值"对(即两个指针),而不是底层数据本身。
Go 的接口由两个内部字段表示(概念模型):
go
type iface struct { // 非空接口
tab *itab // 类型信息指针,包含方法集等元数据
data unsafe.Pointer // 指向实际值的指针
}
type eface struct { // 空接口 (interface{})
_type *_type // 类型信息
data unsafe.Pointer // 指向实际值的指针
}💡 接口和切片等引用类型的区别?
虽然接口是引用类型,但它和 slice、map 有一个重要区别:接口不能直接修改。 你必须先通过类型断言将其"还原"为具体的类型,然后才能操作该类型的方法和字段。
go
var w io.Writer = &os.File{}
// w.SomeMethod() // 错误!io.Writer 接口没有 SomeMethod 方法。
// w.SomeField = 1 // 错误!接口没有字段。
file := w.(*os.File) // 类型断言:从接口中提取出具体的 *os.File
file.SomeField = 1 // 正确:现在可以操作具体类型的字段和方法了总结
本文介绍了Go语言中的数据类型和变量,这是学习一门新语言首先要掌握的基础。其中重点要理解基本数据类型和引用类型的概念和区别,了解零值机制。