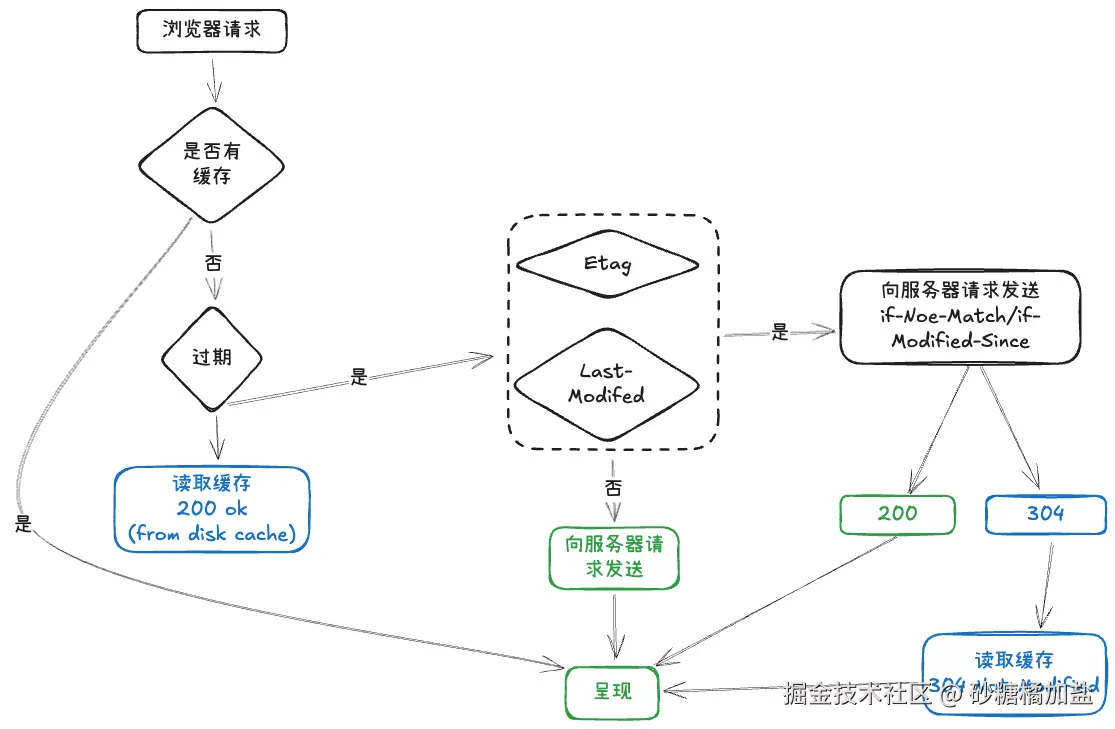
HTTP 缓存机制
HTTP 协议提供"缓存规则说明书",浏览器作为"工程师"按说明书搭建缓存系统。
把已请求并返回的WEB资源(HTML页面、图片、JS文件、CSS文件、数据等)复制到一个副本存储到浏览器的缓存中。
理解了这个缓存机制的过程,才能够知道为什么现在打包工具都会默认给构建之后的结果添加上hash值。
- 缓存的好处:
- 减少网络贷款的消耗
- 降低服务器的压力
- 较少网络延迟
强制缓存
有两个 API 可以实现强制缓存,expires 和 Cache-Control。
它是http/1 时期的属性,通过expires 响应头的属性设置,这个属性表示过期的时间,超过这个时间,资源就从服务器上面取,反之,就从本地内存当中取。
它的判断依据是和本地操作系统的时间进行匹配,所以并不可靠,存在误差以及被修改的可能。
所以http/1.1 退出了cache-control响应头属性来解决这个问题, 值的单位为秒。它的配置方式如下:
http
res.writeHead(200, {
"Cache-Control": "max-age:5",
});这个的含义就是,当你渲染界面之后的 5 秒内,再次刷新当前页面的话,会强制从本地从拿旧的资源,和 \[防抖函数]的逻辑相似。
它是对于expires的补充,两个数据可以同时配置在请求头中。当它们同时存在的时候,http/1.1的权重比http/1.0的高。
当我们借助一些构建工具上自动给有了变化的文件后缀名添加 HASH 值的时候,浏览器认为这个是一个新的资源,绕过了强制缓存的配置,客户端直接从服务器中拉取这个新的资源。
协商缓存
协商缓存顾名思义,就是有条件的缓存。
当同时存在 Cache-Control和expires 这两个强缓存的属性的时候,优先判断是否满足强制缓存的条件,如果不满足再进入到协商缓存的阶段。
last-modified 实现协商缓存
最简单的方案,就是根据文件的修改时间来进行判断。需要last-modified和Cache-Control进行配合, 将Cache-Control配置为no-cache,就可以关闭强制缓存的逻辑,直接进入协商缓存,和它相关的可选值在文章的最后有列出。
mtime是文件最后的修改时间,NodeJs 中通过fs模块的state方法中获取到。
js
res.setHeader("last-modified", mtime.toUTCString());
res.setHeader("Cache-Control", "no-cache");当添加了last-modified的字段之后,响应头会自动生成一个属性,if-modified-since,通关它和mtime的对比,可以判断当前是否配置了last-modified,如下:
js
const ifModifiedSince = req.headers["if-modified-since"];
if (ifModifiedSince === mtime) {
// 缓存生效
res.statusCode = 304;
res.end();
return;
}如此就能够实现协商缓存了。
last-modified 的不足
它能够满足绝大部分的场景。但是还是有如下的不足:
- 它只是根据了时间戳来进行判断。如果只是改变了文件名,实际内容没有任何改变的情况下,还是会进行服务器的请求拿取。不够聪明。
- 它的单位是秒,如果修改文件的速度非常的快,在几百毫秒内就完成了。那么它秒的单位就没有办法通过验证。
为了解决上面的这两点不足的地方,http1.1 之后还提供了,etag的响应头字段来进行解决。
etag 实现协商缓存
逻辑和last-modified基本一致。
js
const etag = require("etag");
const data = fs.readFileSync("./img4.png");
const etagContent = etag(data);
const ifNoneMatch = req.headers["if-none-match"];
if (ifNoneMatch === etagContent) {
// 缓存生效
res.statusCode = 304;
res.end();
return;
}
res.setHeader("etag", etagContent);
res.setHeader("Cache-Control", "no-cache");
res.end(data);etag 表示的是对文件内容的解析进而生成的一个 id,只要文件内容有了改变才会进行变更。自然就能够改变last-modified的两点的不足。它是对其的一个补充方案,而不是替代方案。
etag 依旧带来了新的问题:
- 服务器生成文件资源 Etag 需要付出额外的计算开销,如果资源尺寸比较大,数量较多且修改比较频繁的话,那么生成 Etag 的过程显然会印象服务器的性能。
- Etag 字段值的生成两种类型,一种是强验证,即更具资源内容的每一个字节来进行验证,最可靠,性能消耗也最大。相对应的就是弱验证,它使用资源内容的部分的属性值来进行生成,生成速度快,但是没有办法很高的成功率。尤其是在服务器集群场景下。
所以上面的两种协商缓存的都有不足。根据具体的场景来使用对用的缓存策略才是最好的方案。
同时存在强制缓存和协商缓存的执行策略
描述如下,先判断是否符合强制缓存调节,如果不符合了就走协商缓存的逻辑。
http
Cache-Control: max-age=3600, no-cache # 强制缓存 1 小时,但过期后需协商缓存
ETag: "abc123" # 资源指纹
Last-Modified: Wed, 21 Oct 2023 07:28:00 GMT # 最后修改时间缓存策略
上面的只是缓存的能够使用的工具。最重要的其实是缓存策略。只有使用正确了缓存策略,才能够用户带来更好的体验。
其他相关API
Cache-Control的相关属性
- no-cache: 忽略缓存在本地的副本,强制从服务器上拿资源
- no-store: 强制缓存在任何情况下都不要保留任何副本
- 包括协商缓存的机制也会失效
- max-age=314600: 知识缓存副本的有效时长,从请求时间开始到过期时间之间的描述
- public: 表明响应可以被任何对象缓存(包括:发送请求的客户端、代理服务器等)
- private: 表明响应只能被耽搁用户缓存,不能作为共享缓存(即代理服务器不能缓存它)
no-cache 意味着不强制从直接从本地拿缓存,每次都和服务器打交道之后再来判断是否拿本地换粗资源
为什么存在前端已经配置了 hash,但是用户还需要手动刷新的问题
每一次打包,都对有改变内容生成的 JS、CSS、Img、Font添加 hash 值,拿 vite 构建工具来说,这是一种默认的行为,如下图:
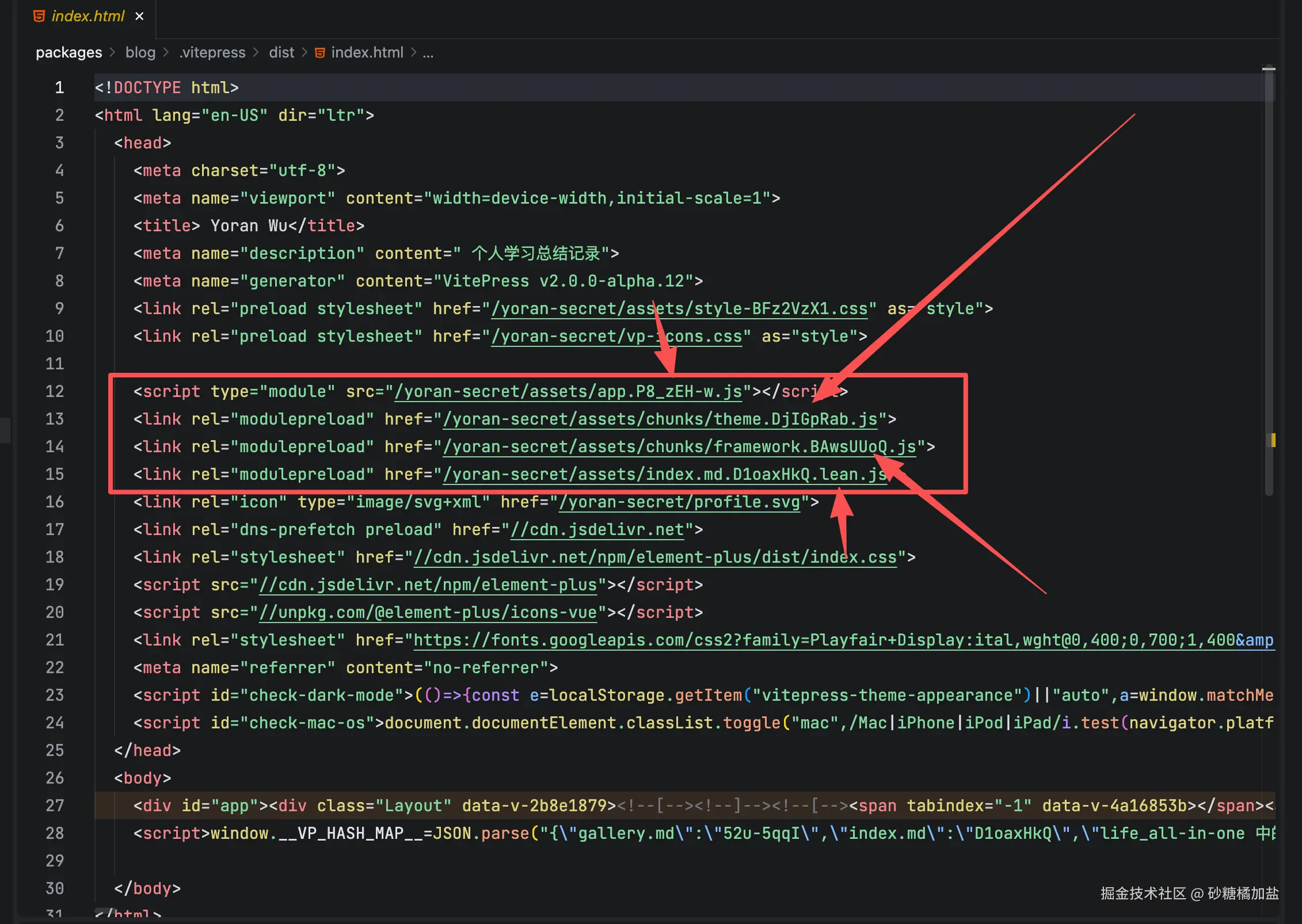
但是,我们常常会忽略一个问题,那就是我们的入口文件index.html没有添加 hash 值。所以根本的问题就出在这里。所以我们需要在 NG 中针对index.html配置cache-control
nginx
server {
listen 80;
server_name yourdomain.com;
root /path/to/your/dist; # 指向构建产物目录
# 1. 入口文件 index.html 禁用缓存
location = /index.html {
add_header Cache-Control "no-cache, no-store, must-revalidate";
add_header Pragma "no-cache";
add_header Expires "0";
try_files $uri /index.html; # 确保 SPA 路由兼容
}
# 2. SPA 路由处理(所有请求重定向到 index.html)
location / {
try_files $uri $uri/ /index.html;
}
# 3. 其他配置
location ~* \.(js|css|png)$ {
add_header Cache-Control "public, max- age=31536000, immutable";
}除此之外,还有 CDN 也是需要修改配置的。如果 ng 不配置,就会采用默认的缓存配置,导致用户本地的 Index.html 拿到的还是旧的。