昨天 OpenAI 发布了其史上的首个开源大模型gpt-oss-120b ,虽然风头被隔壁家谷歌的 Genie3 给盖了,但好在模型确实能打,以120B的参数硬刚200B以上的模型,而且还是原生的4BIT 训练出来的,整个模型大小才60多G,是平民都能部署的大大模型了,让我们来看看它在H20上的性能表现吧。
值得表扬的是模型非常小,一张卡就足够完成推理,所以这次的测试我只使用了一张H20 。我们先来看代码生成 的表现吧(短输入)。
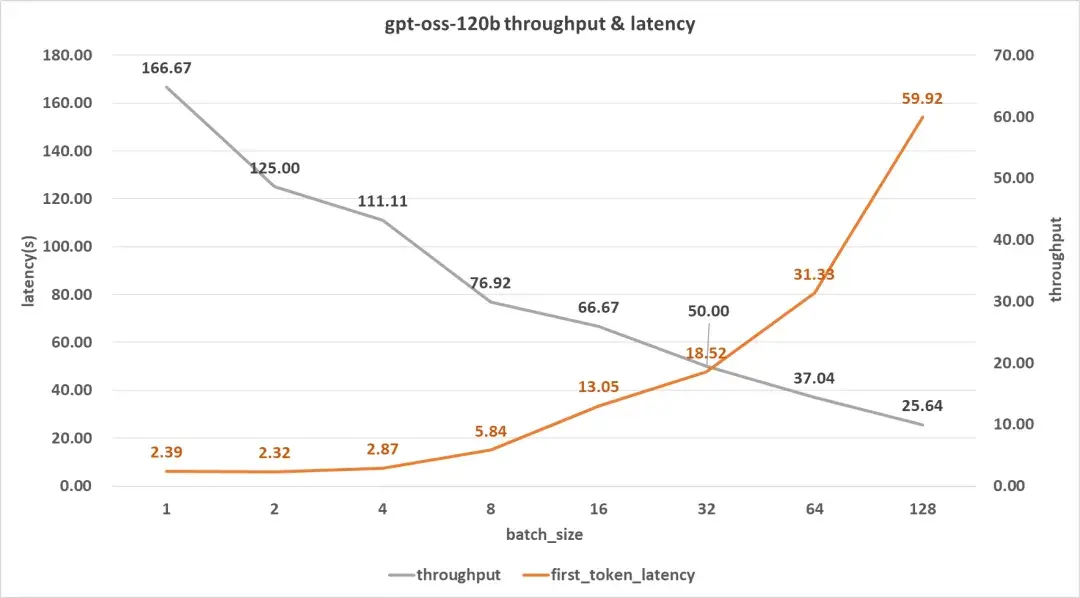
单用户吞吐率相当厉害,一张卡就可以达到166 token/s ,时延方面则表现平平。不过,随着并发数的增加,吞吐率下降明显。然而到了128 并发,还有25 token/s。
再来看看长输入 的表现(也就是知识库应用场景)
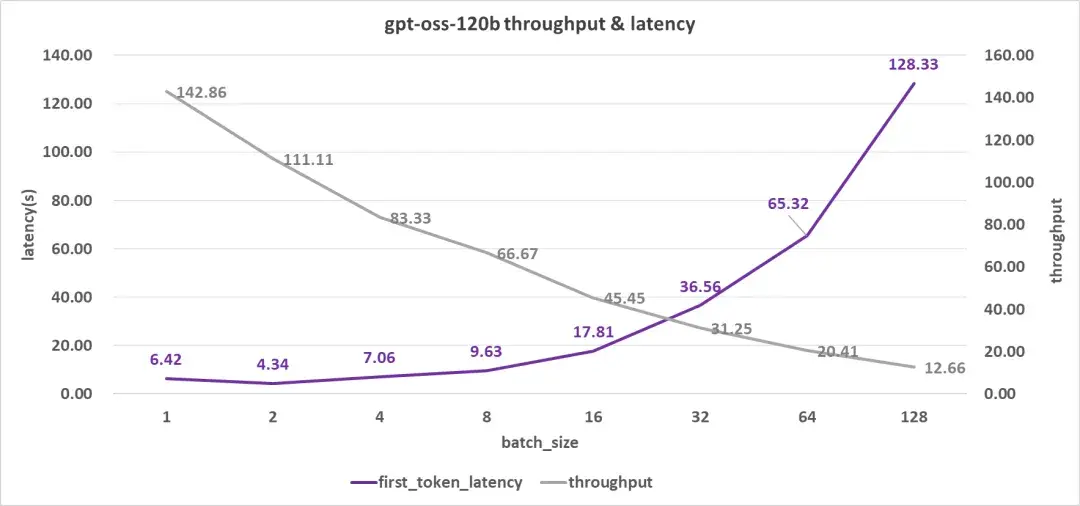
吞吐率还是不错的,但首字时延确实不大好,单用户得有6.4秒 的时延了,要知道我这个测试案例的输入也就才4K的上下文。并发达到8时,首字时延也接近10秒了。再往上首字时延就不大能接受了。
这个性能表现虽然看上去不大好,但考虑只使用了一张卡,所以还是可圈可点的,我们只要把并行开几个实例就可以解决并发的问题。甚至,可以使用 dynamo 这个框架来把 prefill 与 decode 分开,从而大大提高吞吐率。(关于这个主题,我会在后面再分享观点,请关注我以获取最新文章)