🔥作者:it毕设实战小研🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
- 1、景点印象服务系统数据可视化分析-前言介绍
-
- 1.1背景
- 1.2课题功能、技术
- [1.3 意义](#1.3 意义)
- 2、景点印象服务系统数据可视化分析-研究内容
- 3、景点印象服务系统数据可视化分析-开发技术与环境
- 4、景点印象服务系统数据可视化分析-功能介绍
- 5、景点印象服务系统数据可视化分析-论文参考
- 6、景点印象服务系统数据可视化分析-成果展示
- 7、代码展示
- 8、结语(文末获取源码)
本次文章主要是介绍基于大数据景点印象服务系统 爬虫数据可视化分析
1、景点印象服务系统数据可视化分析-前言介绍
1.1背景
随着旅游业的蓬勃发展和互联网技术的深入普及,游客对于旅游信息获取方式提出了更高要求。传统旅游信息服务存在信息分散、缺乏个性化推荐、数据分析能力不足等问题,难以满足现代游客多样化的出行需求;同时景点管理方面也面临着信息管理效率低下、用户行为分析缺失的困扰。基于这些现状,迫切需要构建一个集信息整合、智能推荐、数据可视化于一体的综合性景点印象服务系统。
1.2课题功能、技术
本课题设计并实现了基于大数据的景点印象服务系统,采用Python作为主要开发语言,结合Django后端框架和Vue前端框架构建系统架构;通过爬虫技术从携程旅行平台获取海量景点数据,运用协同过滤推荐算法为用户提供个性化的景点推荐服务;系统功能涵盖用户端的景点查询、路线浏览、在线客服等模块,管理端的信息管理、订单处理、用户维护等功能,并借助Echarts技术实现景点类别统计、热度分析、评分统计等多维度数据可视化展示。
1.3 意义
该系统的成功实现为旅游信息服务领域提供了有效的技术解决方案,不仅提升了用户获取旅游信息的便利性和准确性,还为景点管理者提供了数据分析决策支持;系统所采用的协同过滤算法和大数据可视化技术具有较好的实用价值,对推动旅游信息服务的智能化发展具有一定的参考意义。
2、景点印象服务系统数据可视化分析-研究内容
1、数据采集与清洗:系统运用爬虫技术从携程旅行平台获取景点相关数据,包括景点详细信息、用户评价、评分等级、价格信息等核心数据。采集完成后,利用Python对原始数据进行预处理,剔除无效和重复记录,处理缺失字段,规范数据格式,确保数据的完整性和准确性,为后续推荐算法和可视化分析奠定基础。
2、数据存储与管理:采用MySQL数据库构建数据存储架构,设计合理的表结构来存储景点信息、用户数据、订单记录等各类信息,通过索引优化提升数据查询效率。
3、推荐算法设计与实现:基于协同过滤算法构建个性化推荐模型,通过分析用户历史行为和偏好特征,计算用户相似度和景点关联度,为用户提供精准的景点推荐服务。
4、数据可视化展示:前端采用Vue框架结合Echarts技术实现多维度数据可视化,通过景点类别统计图、热度分析图、评分分布图、词云展示等形式直观呈现数据分析结果,帮助用户和管理者快速理解数据趋势。
5、系统集成与部署:后端基于Django框架开发用户管理、景点管理、订单处理等核心功能模块,前端通过Vue实现用户交互界面,完成前后端数据交互。系统完成后进行功能验证、性能评测和兼容性测试,确保各模块协调运行和系统整体稳定性。
3、景点印象服务系统数据可视化分析-开发技术与环境
- 开发语言:Python
- 后端框架:Django
- 大数据:Hadoop+Spark+Hive
- 前端:Vue
- 数据库:MySQL
- 算法:协同过滤算法
- 开发工具:pycharm
4、景点印象服务系统数据可视化分析-功能介绍
亮点:(协同过滤推荐算法、爬虫【携程旅行】、Echarts可视化)
1、用户功能:登录注册、查看景点信息、查看热门路线、在线客服、查看热门景点、查看旅游资讯。
2、管理员:景点信息管理、热门景点管理、路线订单管理、用户管理、景点类别管理、套票分类管理、门票订单管理、系统管理。
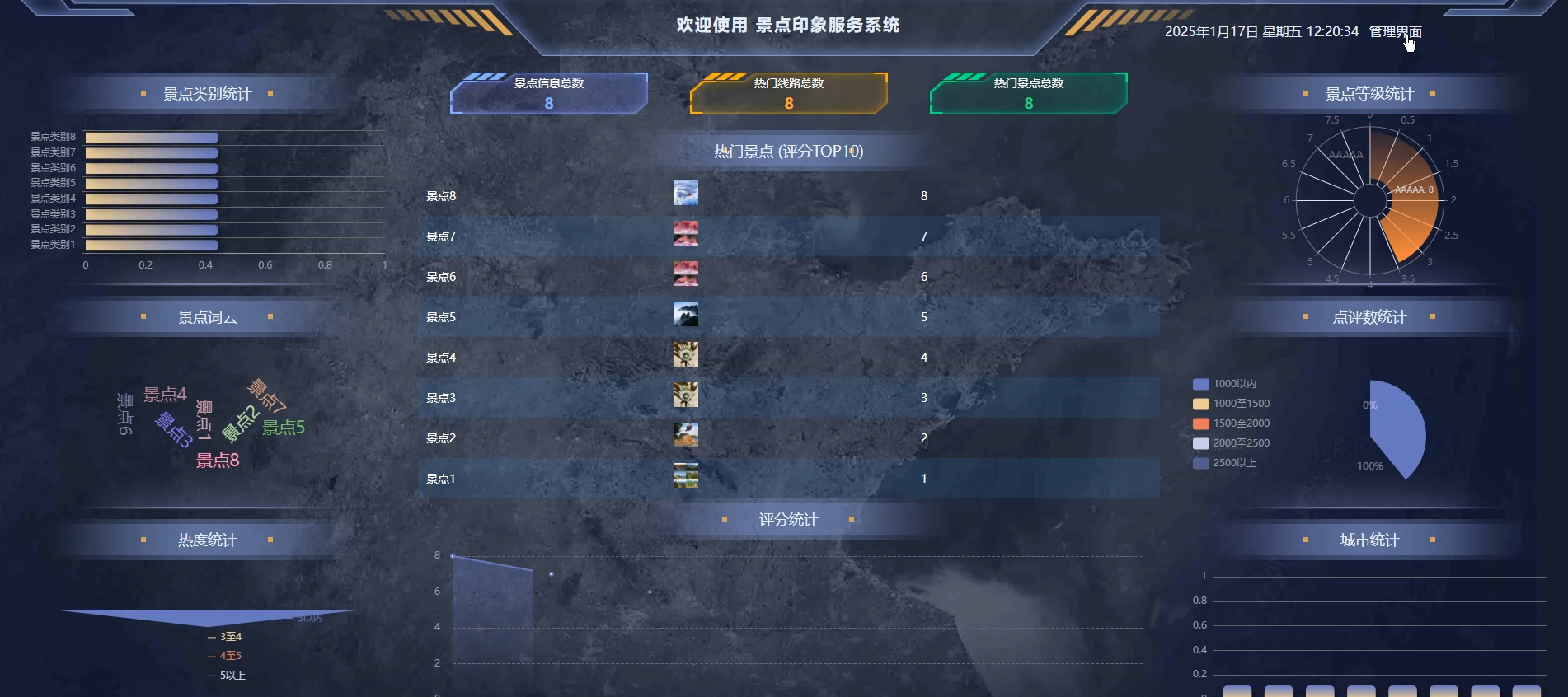
3、大屏可视化分析:景点类别统计、景点词云、热度统计、热门景点评分统计、景点等级统计、点评数统计、城市统计。
4、算法:协同过滤算法。
5、景点印象服务系统数据可视化分析-论文参考
6、景点印象服务系统数据可视化分析-成果展示
6.1演示视频
2026届大数据毕业设计选题推荐-基于大数据景点印象服务系统 爬虫数据可视化分析
6.2演示图片
☀️可视化大屏☀️
☀️登录注册☀️
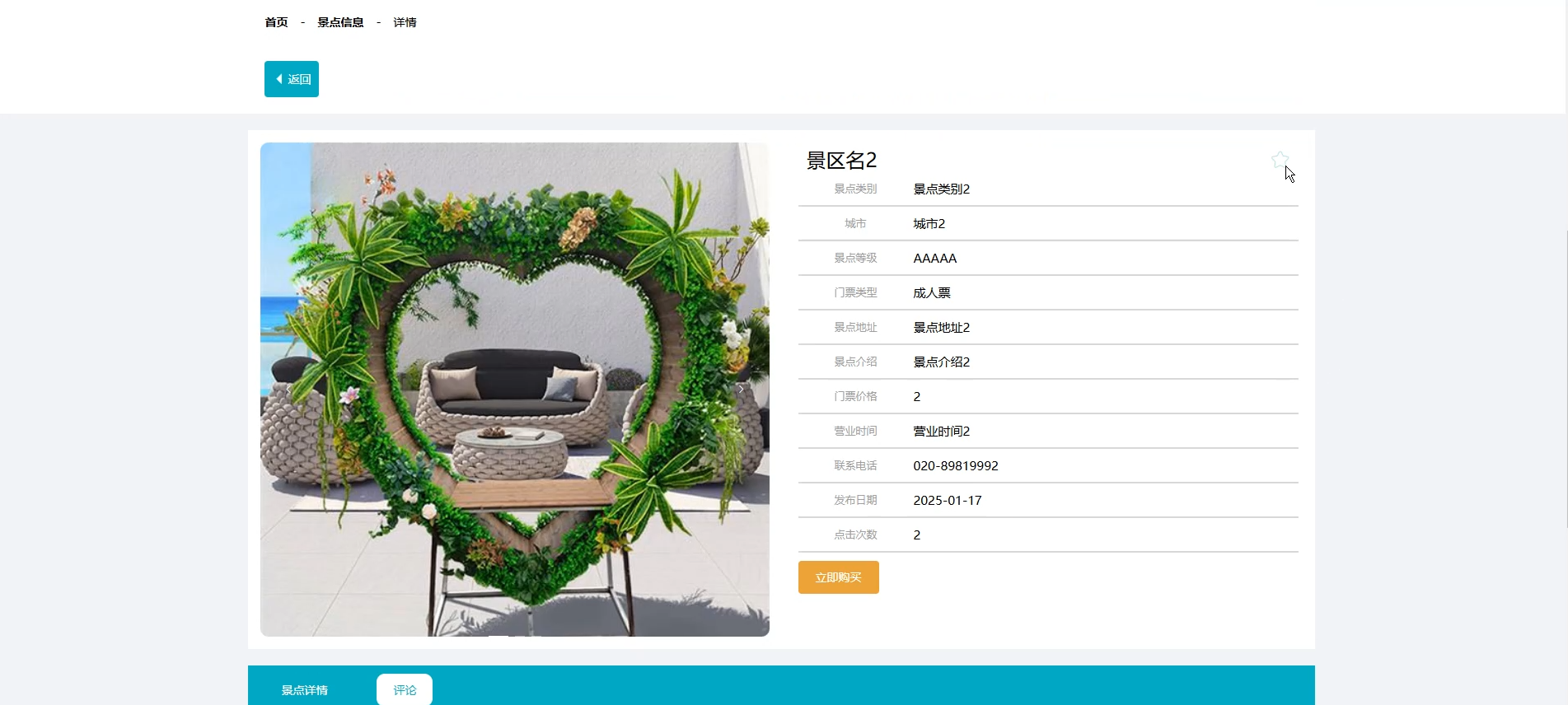
☀️查看景点信息☀️
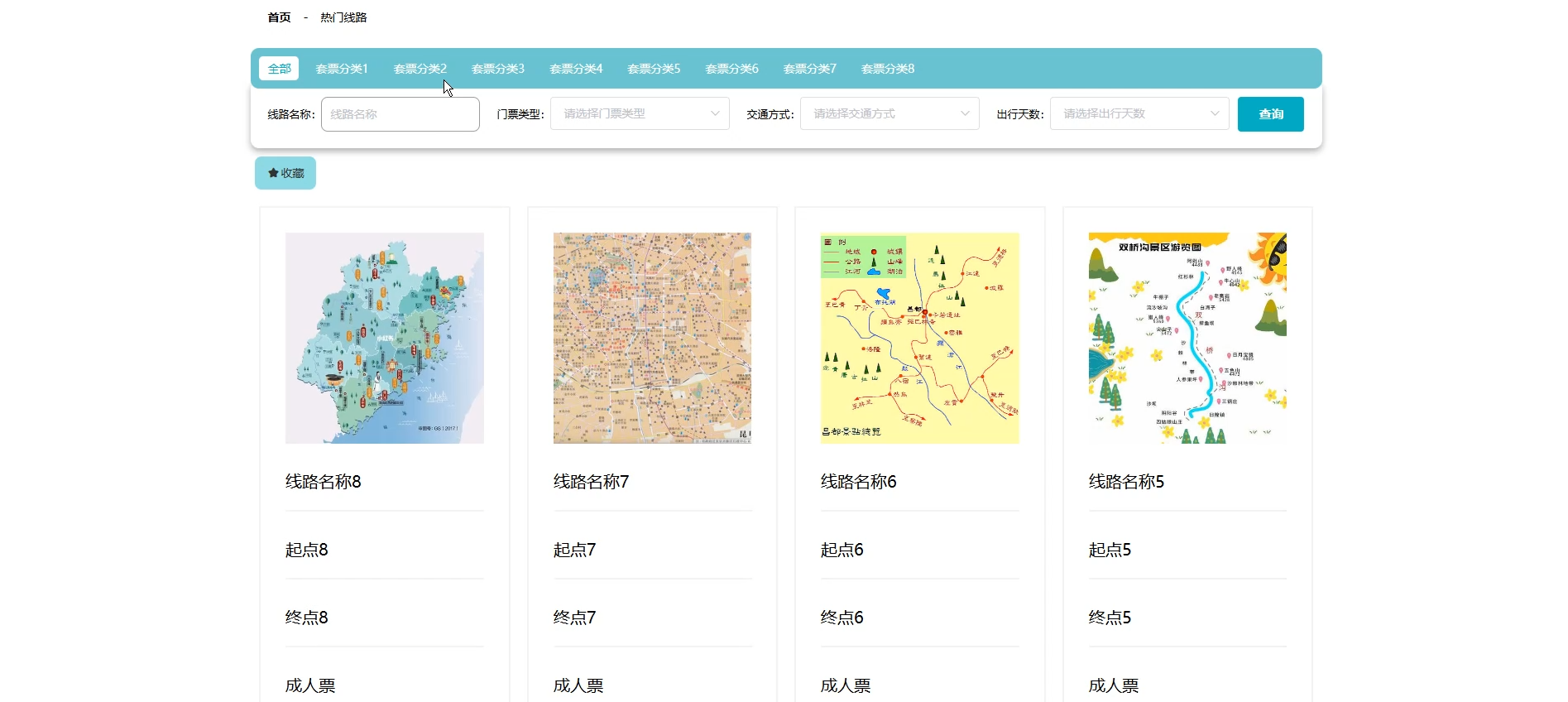
☀️查看热门景点☀️
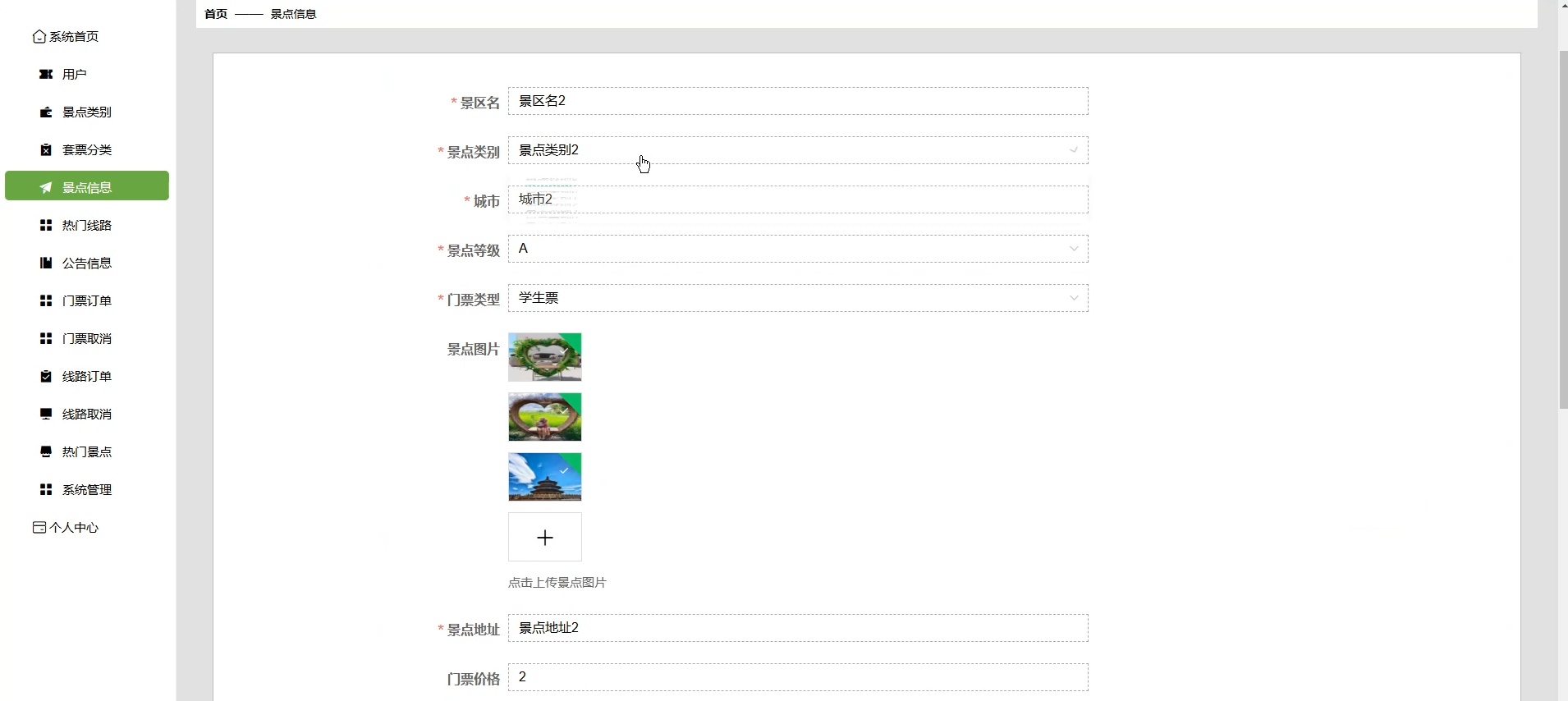
☀️景点信息管理☀️
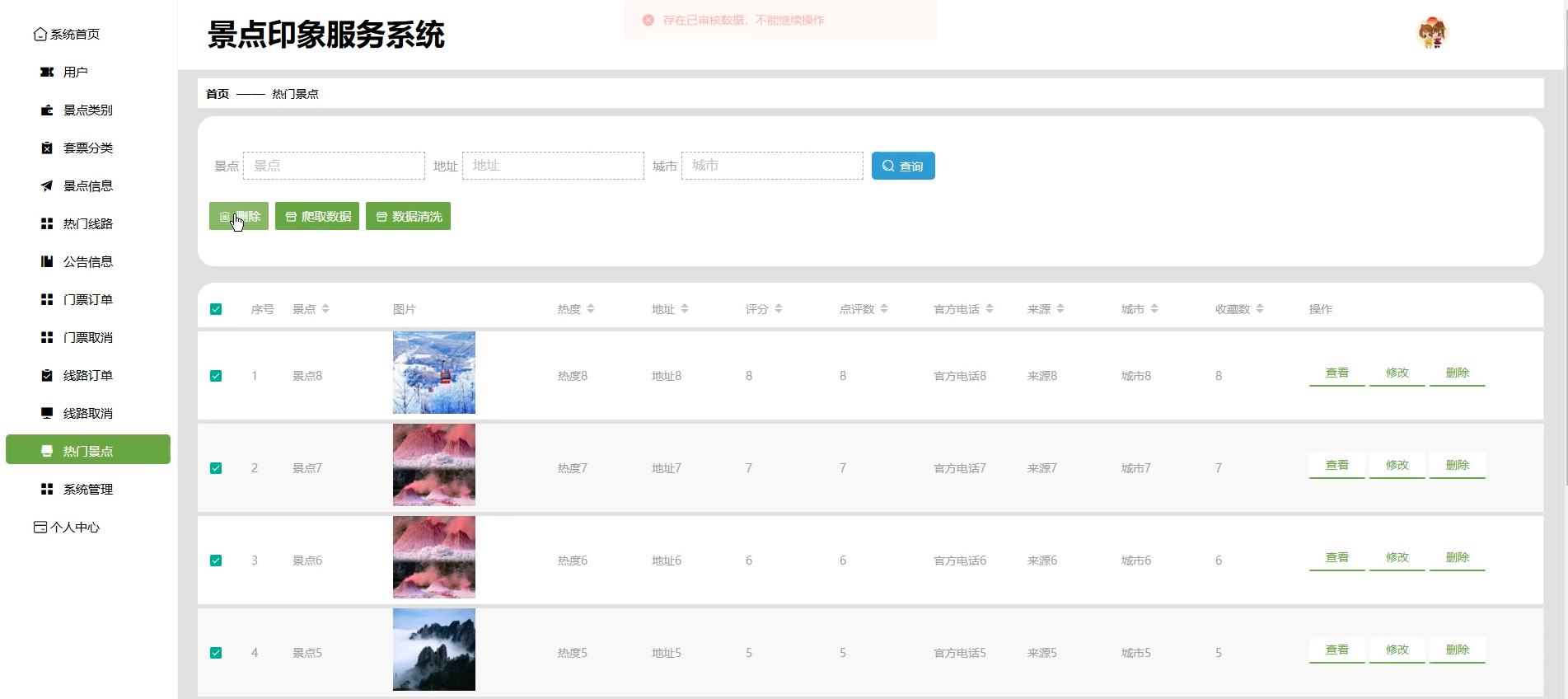
☀️热门景点管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
bash
class AttractionDataCleaner:
def __init__(self, raw_data_path):
"""初始化数据清洗类"""
self.df = pd.read_csv(raw_data_path)
def remove_duplicates(self):
"""去除重复数据"""
print(f"原始数据行数: {len(self.df)}")
# 基于景点名称和城市去重
self.df = self.df.drop_duplicates(subset=['attraction_name', 'city'])
print(f"去重后数据行数: {len(self.df)}")
def clean_price_data(self):
"""清洗价格数据"""
def extract_price(price_str):
if pd.isna(price_str):
return None
# 提取价格中的数字
price_match = re.search(r'(\d+\.?\d*)', str(price_str))
if price_match:
return float(price_match.group(1))
return None
self.df['price'] = self.df['price'].apply(extract_price)
# 填充缺失的价格数据为均值
avg_price = self.df['price'].mean()
self.df['price'].fillna(avg_price, inplace=True)
def clean_rating_data(self):
"""清洗评分数据"""
# 评分范围应该在1-5之间
self.df['rating'] = pd.to_numeric(self.df['rating'], errors='coerce')
self.df = self.df[(self.df['rating'] >= 1) & (self.df['rating'] <= 5)]
# 填充缺失评分为平均值
avg_rating = self.df['rating'].mean()
self.df['rating'].fillna(avg_rating, inplace=True)
def clean_text_data(self):
"""清洗文本数据"""
# 清理景点名称
self.df['attraction_name'] = self.df['attraction_name'].str.strip()
self.df['attraction_name'] = self.df['attraction_name'].str.replace(r'[^\w\s]', '', regex=True)
# 清理描述信息
self.df['description'] = self.df['description'].fillna('')
self.df['description'] = self.df['description'].str.replace(r'<[^>]+>', '', regex=True) # 去除HTML标签
def standardize_location(self):
"""标准化地理位置数据"""
# 统一城市名称格式
city_mapping = {
'北京市': '北京',
'上海市': '上海',
'广州市': '广州',
# 可以根据实际数据添加更多映射
}
self.df['city'] = self.df['city'].replace(city_mapping)
def clean_comment_data(self):
"""清洗评论数据"""
# 评论数量应为正整数
self.df['comment_count'] = pd.to_numeric(self.df['comment_count'], errors='coerce')
self.df['comment_count'] = self.df['comment_count'].fillna(0)
self.df['comment_count'] = self.df['comment_count'].astype(int)
def handle_outliers(self):
"""处理异常值"""
# 使用IQR方法处理价格异常值
Q1 = self.df['price'].quantile(0.25)
Q3 = self.df['price'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 将异常值替换为边界值
self.df['price'] = np.where(self.df['price'] < lower_bound, lower_bound, self.df['price'])
self.df['price'] = np.where(self.df['price'] > upper_bound, upper_bound, self.df['price'])
def validate_data_types(self):
"""验证和转换数据类型"""
# 确保数值列的数据类型正确
numeric_columns = ['price', 'rating', 'comment_count']
for col in numeric_columns:
self.df[col] = pd.to_numeric(self.df[col], errors='coerce')
def export_clean_data(self, output_path):
"""导出清洗后的数据"""
self.df.to_csv(output_path, index=False, encoding='utf-8')
print(f"清洗后数据已保存至: {output_path}")
print(f"最终数据行数: {len(self.df)}")
def run_full_cleaning(self, output_path):
"""执行完整的数据清洗流程"""
print("开始数据清洗...")
self.remove_duplicates()
self.clean_price_data()
self.clean_rating_data()
self.clean_text_data()
self.standardize_location()
self.clean_comment_data()
self.handle_outliers()
self.validate_data_types()
self.export_clean_data(output_path)
print("数据清洗完成!")2.大屏可视化【代码如下(示例):】
bash
class DashboardAPIView:
"""大屏数据接口"""
def get_category_statistics(self, request):
"""景点类别统计"""
category_data = Attraction.objects.values('category').annotate(
count=Count('id')
).order_by('-count')
result = {
'categories': [item['category'] for item in category_data],
'counts': [item['count'] for item in category_data]
}
return JsonResponse(result)
def get_hotness_statistics(self, request):
"""热度统计"""
attractions = Attraction.objects.all()
hotness_data = []
for attraction in attractions:
hotness_score = (
attraction.view_count * 0.3 +
attraction.favorite_count * 0.4 +
attraction.comment_count * 0.3
)
hotness_data.append({
'name': attraction.name,
'hotness': round(hotness_score, 2),
'city': attraction.city
})
# 按热度排序
hotness_data.sort(key=lambda x: x['hotness'], reverse=True)
return JsonResponse({
'top_attractions': hotness_data[:20],
'hotness_distribution': self._get_hotness_distribution(hotness_data)
})
def get_rating_statistics(self, request):
"""热门景点评分统计"""
top_attractions = Attraction.objects.order_by('-view_count')[:15]
rating_data = []
for attraction in top_attractions:
avg_rating = Review.objects.filter(
attraction=attraction
).aggregate(avg_rating=Avg('rating'))['avg_rating'] or 0
rating_data.append({
'name': attraction.name[:8] + '...' if len(attraction.name) > 8 else attraction.name,
'rating': round(avg_rating, 1),
'review_count': attraction.comment_count
})
return JsonResponse({'rating_data': rating_data})
def get_level_statistics(self, request):
"""景点等级统计"""
level_data = Attraction.objects.values('level').annotate(
count=Count('id')
).order_by('level')
result = {
'levels': [f"{item['level']}A" for item in level_data],
'counts': [item['count'] for item in level_data]
}
return JsonResponse(result)
def get_comment_statistics(self, request):
"""点评数统计"""
comment_ranges = [
(0, 100, '0-100'),
(101, 500, '101-500'),
(501, 1000, '501-1000'),
(1001, 5000, '1001-5000'),
(5001, float('inf'), '5000+')
]8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。