目录
[一、Shell 是什么](#一、Shell 是什么)
[二、 .sh 脚本调用 .py 脚本](#二、 .sh 脚本调用 .py 脚本)
[Python 核心逻辑脚本(data_processor.py)](#Python 核心逻辑脚本(data_processor.py))
[Shell 脚本(pipeline.sh)](#Shell 脚本(pipeline.sh))
[1. 简单例子](#1. 简单例子)
[2. 进阶例子](#2. 进阶例子)
[3. 猜数字游戏](#3. 猜数字游戏)
一、Shell 是什么
Shell 的本质是 "命令行解释器(Command-Line Interpreter)",其核心功能是:
- 接收用户输入 :用户在终端(Terminal)中输入命令(如
ls查看文件、python train.sh启动训练脚本); - 解析命令含义:Shell 把用户输入的 "人类可读命令" 翻译成内核能理解的 "机器指令";
- 调用内核执行:Shell 将解析后的指令传递给内核,让内核调度硬件完成任务(如读取磁盘文件、分配 GPU 资源);
- 返回执行结果:内核执行完任务后,将结果通过 Shell 反馈给用户(如在终端显示文件列表、训练日志)。
简言之,如果把 操作系统内核(如 Linux 内核、Windows 内核) 看作 "电脑的发动机"(负责硬件调度、资源分配等核心工作),那么 Shell 就是 "发动机的操作面板"------ 它是用户与操作系统内核之间的 "桥梁",让用户能通过输入命令,间接控制内核完成各种任务(如创建文件、启动程序、管理进程等)。
二、 .sh 脚本调用 .py 脚本
一般用 .sh 脚本调用 .py 脚本,让 Shell 负责搭建执行框架、和系统交互**(如文件操作、环境配置、命令调用)**,Python 负责核心逻辑处理。
因为 Shell 更擅长 "对接操作系统",Python 虽然能通过 os 模块调用系统命令,但本质是 "间接调用"。所以.sh搭配.py效率更高、分工更明确。
假设我们需要实现一个 "数据处理流水线",功能包括:
- 检查输入数据目录是否存在(Shell 负责);
- 创建输出结果目录(Shell 负责);
- 调用 Python 脚本处理数据(清洗、计算)(Python 负责);
- 压缩处理后的结果(Shell 负责);
- 发送邮件通知任务完成(Shell 调用系统工具负责)。
Python 核心逻辑脚本(data_processor.py)
通过命令行参数接收输入 / 输出路径,负责具体的数据处理(如过滤异常值、计算平均值)。
python
# data_processor.py
import sys
import pandas as pd
def main():
# 从命令行参数获取输入文件路径和输出文件路径
if len(sys.argv) != 3:
print("用法:python3 data_processor.py <输入文件> <输出文件>")
sys.exit(1) # 异常退出,方便 Shell 捕获错误
input_path = sys.argv[1]
output_path = sys.argv[2]
try:
# 核心逻辑:读取数据、处理、保存结果
df = pd.read_csv(input_path) # 用 pandas 处理 CSV 数据
df_clean = df[df["value"] > 0] # 过滤异常值(假设 value 列不能为负)
df_clean["mean"] = df_clean["value"].mean() # 计算平均值
df_clean.to_csv(output_path, index=False)
print(f"处理完成!结果已保存到 {output_path}")
sys.exit(0) # 正常退出
except Exception as e:
print(f"处理失败:{str(e)}", file=sys.stderr) # 错误信息输出到 stderr
sys.exit(1) # 异常退出
if __name__ == "__main__":
main()Shell 脚本(pipeline.sh)
负责流程控制、系统交互,调用 Python 脚本并处理前后的辅助任务。
bash
#!/bin/bash
# pipeline.sh:数据处理流水线的控制脚本
# 1. 定义参数(输入/输出路径)
INPUT_DIR="./raw_data"
OUTPUT_DIR="./processed_data"
INPUT_FILE="${INPUT_DIR}/data.csv"
OUTPUT_FILE="${OUTPUT_DIR}/result.csv"
ZIP_FILE="${OUTPUT_DIR}/result.zip"
EMAIL="user@example.com" # 接收通知的邮箱
# 2. 检查输入文件是否存在(Shell 系统交互能力)
if [ ! -f "${INPUT_FILE}" ]; then
echo "错误:输入文件 ${INPUT_FILE} 不存在!" >&2 # 错误信息输出到 stderr
exit 1 # 退出脚本,终止流程
fi
# 3. 创建输出目录(若不存在)
mkdir -p "${OUTPUT_DIR}" # -p 确保父目录不存在时也能创建
echo "输出目录已准备:${OUTPUT_DIR}"
# 4. 调用 Python 脚本处理数据(核心逻辑交给 Python)
echo "开始处理数据..."
python3 data_processor.py "${INPUT_FILE}" "${OUTPUT_FILE}"
# 检查 Python 脚本是否执行成功(通过退出码判断)
if [ $? -ne 0 ]; then # $? 是上一条命令的退出码(0 为成功,非 0 为失败)
echo "数据处理失败,终止流程" >&2
exit 1
fi
# 5. 压缩处理结果(Shell 调用系统压缩命令)
zip -q "${ZIP_FILE}" "${OUTPUT_FILE}" # -q 静默模式,不输出冗余信息
echo "结果已压缩:${ZIP_FILE}"
# 6. 发送邮件通知(Shell 调用系统邮件工具)
echo "数据处理流水线已完成,结果见附件" | mail -s "任务完成通知" -a "${ZIP_FILE}" "${EMAIL}"
echo "通知邮件已发送到 ${EMAIL}"
# 7. 流程结束
echo "所有任务完成!"
exit 0关键协作方式:
(1)参数传递
Shell 脚本通过 命令行参数 将必要信息(如文件路径、配置项)传递给 Python 脚本,Python 用 sys.argv 接收。
比如:.sh里面的一行
python3 data_processor.py input.csv output.csvPython 中 sys.argv[1] 接收 input.csv,sys.argv[2] 接收 output.csv。
sys.argv[0]→data_processor.py(python脚本自身的文件名)
(2)环境变量共享
Shell 中定义的环境变量(如 export DATA_PATH="./data"),可在 Python 中通过 os.environ 读取:
import os
data_path = os.environ.get("DATA_PATH")(3)状态反馈
Python 脚本通过 退出码 (sys.exit(0) 表示成功,sys.exit(1) 表示失败)告诉 Shell 执行结果。Shell 用 $? 变量获取退出码,判断是否继续后续流程(如示例中 "若 Python 失败则终止脚本")。
三、常见命令
1. echo 打印字符串或者变量值
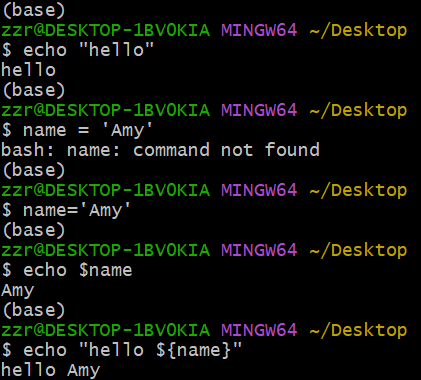
注意:定义变量时,**name="Amy"**中间不能有空格
打印变量时,前面加上标记:**name**
和字符串混合打印时,变量名用{}包裹(解决边界问题):${name}
|---------------|----------------------------------------------|
| echo $HOME | 打印当前用户的主目录(家目录)路径 |
| echo $PATH | 打印$PATH,存储着系统查找可执行程序的目录列表 |
| echo $SHELL | 存储着当前用户默认使用的 Shell 程序路径 。 |
| echo $0 | 当前执行的脚本名称 (1 2 $3 传递给这个脚本的第一二三个参数) |

2. cat 连接文件并打印其内容
查看单个文件内容:cat test.txt
查看多个文件内容:cat file1.txt file2.txt
**创建新文件:**cat > new_file.txt
输入cat > new_file.txt后回车,然后在终端中输入想要写入文件的内容,每输入一行后按回车键换行,输入完成后,按下Ctrl + D组合键,即可将输入的内容保存到new_file.txt文件中。
复制文件内容到另一个文件: cat file1.txt file2.txt > combined.txt
这会把file1.txt和file2.txt的内容合并到combined.txt文件中。如果combined.txt不存在,会创建该文件,如果已存在,则会覆盖原有内容。
**追加内容到文件:**cat >> file.txt
手动方式:
bash
cat >> test.txt
这是追加的第一行内容
这是追加的第二行内容
(按 Ctrl + D 结束输入)自动方式(通过管道):
bash
# 把 echo 输出的内容追加到 file.txt
echo "这是通过 echo 追加的内容" | cat >> file.txt
# 把 ls 命令的结果(当前目录文件列表)追加到 file.txt
ls | cat >> file.txt
# 把另一个文件的内容追加到 file.txt
cat other_file.txt | cat >> file.txt- ls
ls -a 显示所有文件(包括以.开头的隐藏文件)
存储环境变量:.profile(用户登录时执行,只执行一次) 和 .bashrc (每次打开一个终端新建一个shell会话时执行)
一般推荐把环境变量放在.bashrc里
四、.sh脚本
1. 简单例子
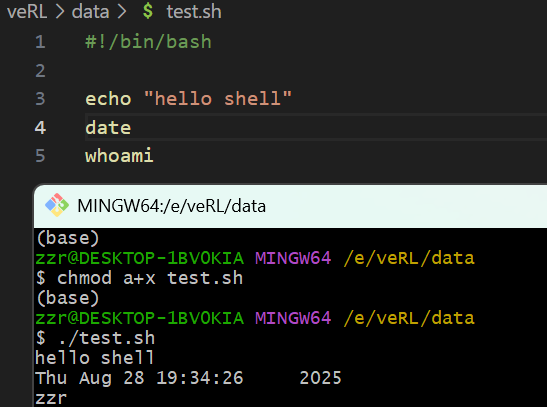
#!/bin/bash: 告诉操作系统"这个脚本需要用哪个解释器来执行",这里指定要用 位于/bin 目录下的 Bash 解释器
注意:要在 linux 环境执行,这里可以用Git Bash
chmod a+x tets.sh: chmod 是 "change mode" 的缩写,专门用于修改文件 / 目录的访问权限

./test.sh:执行当前目录下 test.sh 脚本
2. 进阶例子
bash
#!/bin/bash
# 判断一个数是否为素数
is_prime(){
local num=$1
# 素数判断条件1:小于2的数(1、0、负数)一定不是素数
if [ $num -lt 2 ]; then
return 1
fi
# 素数判断条件2:遍历从2到 sqrt(num) 的所有整数,检查是否能整除 num
for ((i=2;i*i<=num;i++)); do
# 若余数为0,说明 num 有除1和自身外的因数,不是素数
if [ $((num%i)) -eq 0 ]; then
return 1
fi
done
return 0
}
read -p "请输入一个正整数:" number
if is_prime $number; then
echo "$number 是素数"
else
echo "$number 不是素数"
fi在函数中定义局部变量:加上local,比如 local num=1
$1:函数的第一个参数
$变量名:取变量的值(如 $number);
$(命令):取命令的输出结果(如
current_dir=$(pwd) # 执行 pwd 命令(显示当前目录),将结果存入 current_dir);
$((表达式)) :执行算术运算并返回结果(如 $((num%i)) 求余数,注意$((...)) 内部已经能自动解析变量,不需要再给变量加 $)。
-lt:小于,less than
-gt:大于,greater than
-eq:等于,equal to -ne:不等于,not equal to
-le:小于等于,less than or equal to
-ge:大于等于
(以 - 开头的字符串通常表示 "选项" 或 "操作符")
注意:0真(成功)或 1假(失败),是人为规定的历史惯例
对于一个命令 / 函数,"成功执行" 的结果只有一种(比如 ls 成功列出文件),用 0 表示足够;
但 "失败" 的原因有很多(比如文件不存在、权限不足、参数错误),可以用不同的非 0 值区分(例如 1 表示通用错误,2 表示权限错误,127 表示命令不存在)。
bash
if [ 条件判断 ]; then
# 条件为真时执行的代码
else
# 条件为假时执行的代码
fi # 这里的 fi 表示整个 if 语句结束注意:if 空格 ... 空格; then
else
fi(fi 是 if 条件判断语句的闭合标记 ,用于表示一个 if 块的结束,相当于 if 的 "右括号")
- 当调用
is_prime $number时,函数本身已经输出了 "真假" 对应的返回值; if可以直接接收这个返回值,无需再用[]二次判断。
bash
for 变量名 in 列表; do
# 循环体:对列表中的每个元素执行的命令
done
# 例如
# 遍历列表中的水果名称
for fruit in 苹果 香蕉 橙子 葡萄; do
echo "我喜欢吃 $fruit"
done或者:
bash
for (( 初始值; 循环条件; 步长 )); do
# 循环体:对每个数值执行的命令
done
# 例如
# 输出 1 到 5 的数字
for ((i=1; i<=5; i++)); do
echo "当前数字:$i"
donefor ((...)); do
done
bash
函数名() {
# 函数体(一系列命令)
}
函数名 参数1 参数2 ...不需要 is_prime(参数) 的形式
read -p "请输入一个正整数:" number:read 选项 变量名
read **读取用户输入,**并将输入内容赋值给后面指定的变量 number
选项 -p "提示信息" 输入前显示提示信息
3. 猜数字游戏
bash
#!/bin/bash
# 把生成的随机数赋值给number
number=$(shuf -i 1-10 -n 1)
echo $number
while true; do
read -p "请输入一个1-10之间的数字:" guess
if [ $guess -eq $number ]; then
echo "恭喜你,猜对了!是否继续?(y/n):"
read choice
if [ $choice == 'y' ] || [ $choice == 'Y' ]; then
number=$(shuf -i 1-10 -n 1)
echo $number
continue
else
break
fi
elif [ $guess -gt $number ]; then
echo "猜大了"
else
echo "猜小了"
fi
doneshuf -i 1-10 -n 1:从 1 到 10 之间随机选出 1 个整数

bash
# 把生成的随机数赋值给number
number=$(shuf -i 1-10 -n 1)
echo $number\[] 比 \[\] 更加兼容、更强大、不易出错(但是现在好像\[\]很多都可以):
| 特性 | [](test 命令) |
[[ ]](Bash 扩展测试) |
|---|---|---|
| 本质 | 是 /bin/test 命令的简写(外部命令) |
Bash 内置的扩展语法(更强大的内部实现) |
| 字符串比较 | 需用 =,且变量必须加引号(如 [ "$a" = "$b" ]) |
支持 = 或 ==,变量可省略引号(如 [[ $a == $b ]]) |
| 正则匹配 | 不支持 | 支持 =~ 进行正则匹配(如 [[ $str =~ ^[0-9]+$ ]]) |
| 逻辑运算符 | 用 -a(与)、-o(或),且优先级低 |
用 &&、|| |
| 数值比较 | 支持 -eq、-gt 等(与 [[ ]] 相同) |
支持 -eq、-gt 等,也支持 <、>(需注意空格) |
| 变量空值处理 | 变量为空时易报错(需加引号避免) | 变量为空时自动处理,更安全 |
while \[ $guess -ne $number ],虽然在while之前guess还没获取,但是\[]会自动给guess赋值为0