🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐是作者创作的最大动力🤞
💖📕🎉🔥 支持我:**点赞👍+收藏⭐️+留言📝**欢迎留言讨论
🔥🔥🔥(源码 + 调试运行 + 问题答疑)
🔥🔥🔥 有兴趣可以联系我。
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
目录
[三、触发执行的机关:SqlSession的commit, flushStatements与Executor的联动](#三、触发执行的机关:SqlSession的commit, flushStatements与Executor的联动)
-
MyBatis执行器深度解析:Simple与Batch的update实现差异与批处理奥秘
-
手写MyBatis(四):Executor的批处理世界,从Simple到Batch的架构演进
-
高并发数据操作的利器:深入MyBatis BatchExecutor实现原理与最佳实践
-
超越Simple:手把手实现MyBatis批处理执行器,揭秘SqlSession提交与刷新的联动机制
在上一篇文章中,我们为SimpleExecutor成功实现了update方法,奠定了增删改操作的基础。然而,在现实的高并发、大数据量场景下,逐条执行SQL语句会带来巨大的网络I/O和数据库开销,成为性能的瓶颈。此时,JDBC提供的批处理(Batch)功能便闪亮登场。本文将深入MyBatis的批处理世界,探讨BatchExecutor的独特实现,并厘清SqlSession的提交、回滚与执行器之间的精妙协作关系。
一、批处理:为何需要特殊的Executor?
JDBC的批处理允许我们将多个SQL语句打包成一个"批次",一次性发送到数据库执行。这极大地减少了网络往返次数,数据库也可以对同一批操作进行优化,从而显著提升性能。
然而,批处理的使用模式与普通执行截然不同:
-
普通执行(SimpleExecutor):
update()->executeUpdate()-> 立即执行 -> 返回结果。 -
批处理执行(BatchExecutor):
update()->addBatch()-> 加入队列 ->commit()->executeBatch()-> 批量执行 -> 返回结果。
这种"延迟执行"的特性意味着,我们不能在BatchExecutor的update方法中立即执行SQL,而是需要将其缓存起来,等待一个统一的"触发信号"。这个根本性的差异,正是MyBatis需要设计不同Executor实现类的核心原因。
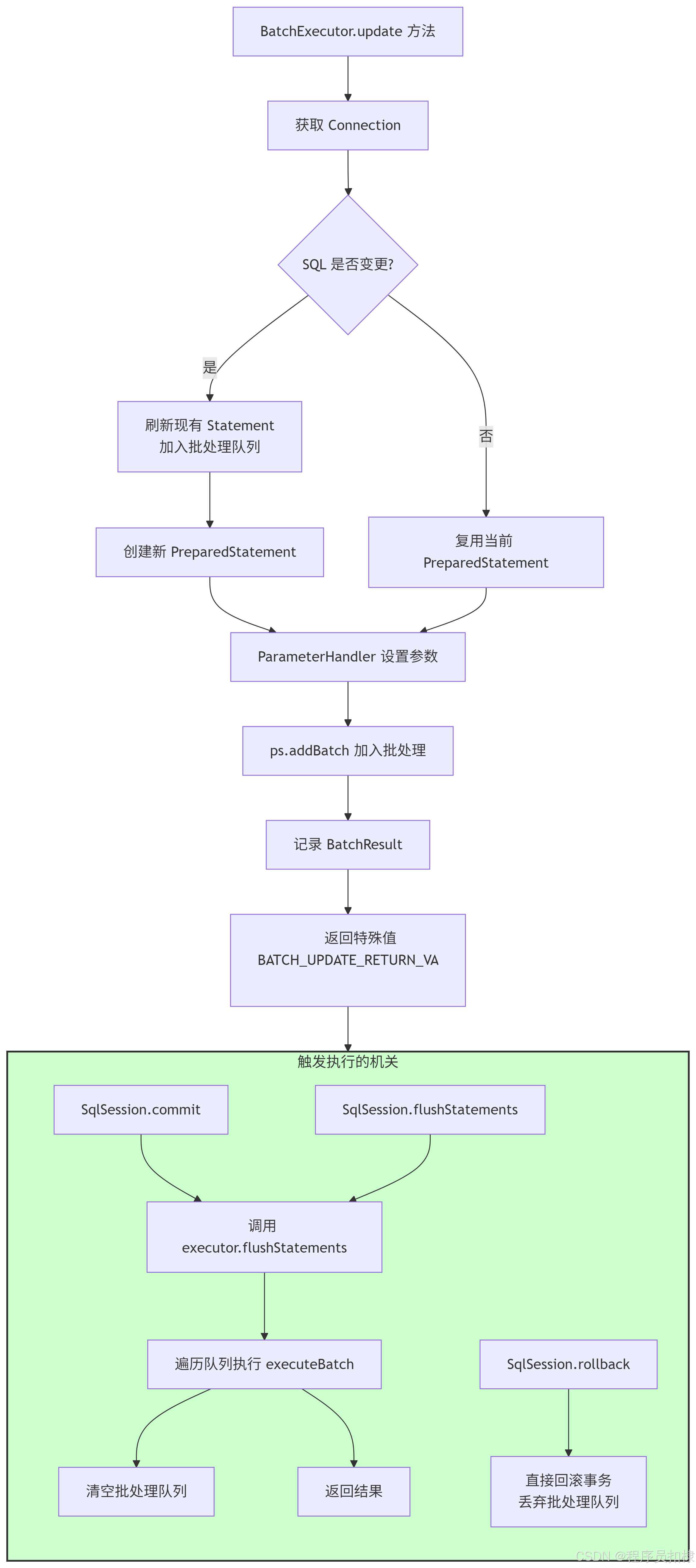
二、BatchExecutor的设计思路:维护批处理队列
BatchExecutor的核心在于维护一个批处理队列。这个队列需要存储什么?它需要存储每一次update调用所对应的PreparedStatement和参数信息,以便在最终执行时能够正确地重现这些操作。
让我们勾勒一下BatchExecutor的骨架:
java
public class BatchExecutor implements Executor {
// 存储批处理任务的队列
private List<Statement> statementList = new ArrayList<>();
private List<BatchResult> batchResultList = new ArrayList<>();
// 当前事务对应的数据库连接
private Connection connection;
// 当前MappedStatement对应的PreparedStatement(简化模型,实际更复杂)
private PreparedStatement currentPreparedStatement;
private String currentSql;
private MappedStatement currentMappedStatement;
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
// 1. 获取连接(通常从关联的Transaction中获取)
if (connection == null) {
connection = transaction.getConnection();
}
// 2. 检查当前SQL是否与上一次相同
// 如果相同,可以复用PreparedStatement;如果不同,需要创建新的并处理上一个
if (currentSql != null && currentSql.equals(ms.getSql())) {
// SQL相同,复用currentPreparedStatement
} else {
// SQL不同,需要"刷新"上一个Statement(执行或加入队列),并创建新的
if (currentPreparedStatement != null) {
// 将当前的PreparedStatement加入到批处理队列,并记录其影响
currentPreparedStatement.addBatch();
batchResultList.add(new BatchResult(currentMappedStatement, currentSql, parameter));
// 注意:这里并不执行executeBatch,只是加入队列
}
// 创建新的PreparedStatement
currentPreparedStatement = connection.prepareStatement(ms.getSql());
currentSql = ms.getSql();
currentMappedStatement = ms;
}
// 3. 使用ParameterHandler处理参数,设置到当前的PreparedStatement中
ParameterHandler parameterHandler = new DefaultParameterHandler(parameter);
parameterHandler.setParameters(currentPreparedStatement);
// 4. 将当前操作添加到批处理中(注意:不是执行)
currentPreparedStatement.addBatch();
// 5. 记录BatchResult
batchResultList.add(new BatchResult(ms, ms.getSql(), parameter));
// 6. 批处理操作不会立即返回影响行数,所以返回一个占位值(如BatchExecutor.BATCH_UPDATE_RETURN_VALUE)
return BATCH_UPDATE_RETURN_VALUE;
}
}(注:以上为简化模型,真实MyBatis的BatchExecutor实现更为复杂,会用一个statementMap来按SQL分类管理PreparedStatement)
从代码可以看出,BatchExecutor的update方法更像是一个"筹备"阶段,它负责积累操作,而真正的执行则被推迟了。
三、触发执行的机关:SqlSession的commit, flushStatements与Executor的联动
那么,谁负责发出这个"触发信号"呢?答案就是SqlSession。SqlSession作为面向用户的API,其commit(), rollback(), flushStatements()等方法与Executor的生命周期紧密相关。
1. flushStatements():执行批处理的核心方法
这是批处理执行的核心。SqlSession的flushStatements()方法最终会调用Executor的flushStatements()方法。
java
public class BatchExecutor extends BaseExecutor {
@Override
public List<BatchResult> flushStatements() throws SQLException {
try {
// 1. 执行所有批处理操作
for (Statement stmt : statementList) {
// 执行executeBatch,并获取每个Statement的影响行数数组
int[] updateCounts = stmt.executeBatch();
// 将updateCounts与之前记录的BatchResult关联起来
// ...
}
// 2. 清空批处理队列
statementList.clear();
batchResultList.clear();
// 3. 返回批处理结果
return batchResults;
} finally {
// 关闭Statement等资源
}
}
}SqlSession的用户可以显式调用flushStatements()来强制执行当前积累的所有批处理操作,而不必提交事务。这在需要分批次提交大量数据时非常有用。
2. commit() 和 rollback():事务的终结者
对于BatchExecutor来说,提交事务意味着必须首先执行所有批处理操作。
java
public class DefaultSqlSession implements SqlSession {
private Executor executor;
@Override
public void commit() {
try {
// 在提交事务之前,必须先执行(flush)所有批处理语句
executor.flushStatements();
// 然后才提交事务
executor.commit(true);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
} finally {
// ... 错误处理
}
}
@Override
public void rollback() {
try {
// 回滚事务,批处理队列中的操作会被丢弃,无需执行
executor.rollback(true);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error rolling back transaction. Cause: " + e, e);
} finally {
// ... 错误处理
}
}
}可以看到:
-
commit():必须先行调用flushStatements(),确保所有积压的SQL都被执行,然后再提交数据库事务。 -
rollback():直接回滚事务即可,那些积压在内存中尚未执行的批处理操作直接丢弃,因为没有真正发送到数据库。
四、总结与最佳实践
通过对比SimpleExecutor和BatchExecutor的update实现,我们深刻理解了MyBatis执行器模式的优势:通过抽象接口,屏蔽了不同执行策略的复杂性,并通过与SqlSession的联动,提供了统一而灵活的用户体验。
给开发者的启示:
-
正确选择执行器: 在需要大量写操作的场景(如数据导入、批量更新),务必使用
BatchExecutor(通过SqlSessionFactory.openSession(ExecutorType.BATCH)),性能提升可达数十倍甚至更高。 -
注意批处理的使用方式: 批处理操作需要显式调用
sqlSession.commit()或sqlSession.flushStatements()才会真正执行。忘记提交是初学者常犯的错误。 -
理解事务边界: 批处理操作同样受事务控制。在执行
commit之前,所有操作都可以回滚。合理设置批处理大小(定期调用flushStatements),可以避免超大事务导致数据库锁等问题。
从SimpleExecutor到BatchExecutor,我们看到的不仅仅是一个功能的添加,更是一个框架在性能、资源与易用性 之间做出的精妙权衡与架构设计。在下一篇文章中,我们将探讨执行器的另一重要功能:缓存,看MyBatis如何通过CachingExecutor为性能再次加码。
💖学习知识需费心,
📕整理归纳更费神。
🎉源码免费人人喜,
🔥码农福利等你领!💖常来我家多看看,
📕我是程序员扣棣,
🎉感谢支持常陪伴,
🔥点赞关注别忘记!💖山高路远坑又深,
📕大军纵横任驰奔,
🎉谁敢横刀立马行?
🔥唯有点赞+关注成!